
多尺度特征融合的目标检测算法
2021-08-11 08:51何婧媛谢生龙田琴琴
河南科学 2021年7期
何婧媛,谢生龙,田 原,田琴琴
(延安大学数学与计算机科学学院,陕西延安 716000)
计算机视觉是人工智能的一个领域,它训练计算机以类似于人类的方式解释视觉世界.由于技术的快速发展和足够大的训练数据集可用性的增加,计算机视觉领域的主题急剧增长,其中最有前途的领域之一是目标检测.随着目标检测技术的发展,精度和准确性不再是唯一的衡量标准,检测速度也是至关重要的.目标检测在机器人导航、智能视频监控、智能交通、医疗服务、人脸检测等领域应用非常广泛[1-3].目前大多数目标检测是基于卷积神经网络的,而如何设计更好的网络结构是当前目标检测的一个非常关键的问题.
1 目标检测算法
1.1 目标检测
目标检测可以看作是由目标定位和目标分类组成的多任务学习问题.目标检测算法分为实例检测和类别检测,在检测过程中最重要的是特征,而人工设计的特征由于可分性差出现较高的分类错误率,低层特征表达能力弱,难以实现多目标检测.传统的目标检测方法大多数都是分为区域选择、提取特征和分类回归这三个步骤,然而这样的过程存在两个问题,一个是区域选择的策略效果差、时间复杂度高,还有一个是手工提取的特征鲁棒性较差.基于深度学习的目标检测算法分为两阶段方法和一阶段方法,两阶段方法主要是指R-CNN系列、SPP-Net、R-FCN和FPN等,该方法通过Selective Search或CNN产生候选框,然后对候选框进行分类和回归,其检测准确率高[2];一阶段方法主要有YOLO系列、SSD系列、CornerNet、ExtremeNet及其变形,该方法使用CNN提取特征后直接对目标物体进行分类和回归,其检测速度快,可实现实时检测,但由于正负样本的不均衡使得准确率较低.大范围的尺度和位置上对多目标进行识别和定位仍然是目标检测主要内容之一,因此也出现了许多利用特征金字塔网络[4]对图像多尺度特征进行表示的目标检测算法.表1对一些典型的目标检测模型进行了对比[3,5-7].

表1 典型的目标检测模型对比Tab.1 Comparison of typical target detection models
对表1中的几种模型进行简单介绍,R-CNN模型结合了候选区域与卷积神经网络,将高容量卷积神经网络应用于自下而上的候选区域,从而对物体进行局部化和分割,同时监督辅助任务的预训练,对特定领域进行微调,从而提升性能.Fast R-CNN模型较R-CNN具有更高的平均精度,将图像作为输入并获得候选区域集,然后使用卷积和最大池化图层处理图像以生成卷积特征图,在每个特征图中对每个候选区域的感兴趣区域池化层提取固定大小的特征向量.Faster R-CNN模型利用候选区域网络实现实时目标检测,提出了一种可以对候选区域任务进行微调,并对目标检测进行微调的训练机制.YOLO模型是单一的神经网络,采用分治思想将输入图像分为S×S的网格,不同网格采用性能优良的分类器进行分类,YOLO模型将目标检测视为回归问题,实时处理速度非常快.YOLOv2是YOLO模型的改进与升级,它的网络包括19个卷积层,5个最大池化层和1个全局平均池化层,在进行目标检测时,只用尺寸大小为13×13特征图进行检测,使得感受野大小有限,导致在处理较远、较小、有遮挡等情况下的目标时,可能会造成漏检或者错检情况.SSD模型是在YOLO上添加了Faster R-CNN的Anchor概念,同时融合不同卷积层的特征做出预测,在准确度上比YOLO更好,而且对于小目标检测效果也相对好一些.
1.2 SSD模型
SSD作为一阶段目标检测的主要方法,不像两阶段方法在得到候选框后再对其实施分类和回归,也不像YOLO一样在全连接后再进行检测,而是直接对物体采用CNN做检测.具体来说,对大物体的检测是通过较小尺度的特征图实现的,而对于小物体的检测则是通过较大尺度的特征图来实现,大量实验表明SSD算法可用于检测小物体,且精确率要高于YOLO算法.SSD[3]算法的思想是对输入图像采用卷积网络来得到特征映射,然后再对边界框和分类概率进行预测,采用的是3×3大小的卷积核实现的.多尺度特征图的采用使得SSD算法对大目标和小目标都能够得到较好的检测精确率,不同尺度和长宽比的先验框一定程度上降低了模型训练难度.在做检测时,偏移的学习是通过不同比例的先验框实现的,而对边界框的预测是在卷积层之后实施的,通过在不同卷积层上采用不同比例的操作来检测不同尺度的目标.
1.3 网络结构
一般的CNN结构,高层网络感受野比较大,语义信息表征能力强,分辨率低,几何细节信息表征能力弱.而低层网络与高层网络恰好相反,感受野比较小,几何细节信息表征能力强,语义信息表征能力弱,下采样定位更准确.SSD采用的基础网络结构是VGG16,同时引入YOLO[3]的回归思想和Faster R-CNN的先验框机制,为了得到多尺度特征图来进行目标检测,采用的方法是在VGG16上增加卷积层实现的.SSD网络结构如图1所示,SSD在进行检测时采用的是多尺度特征图,输入图像大小[3]可以是300×300,也可以是512×512.网络模型从不同的卷积层来提取特征用于目标检测,所采用的卷积层分别是Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,共提取大小分别是(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)的6个特征图[8].
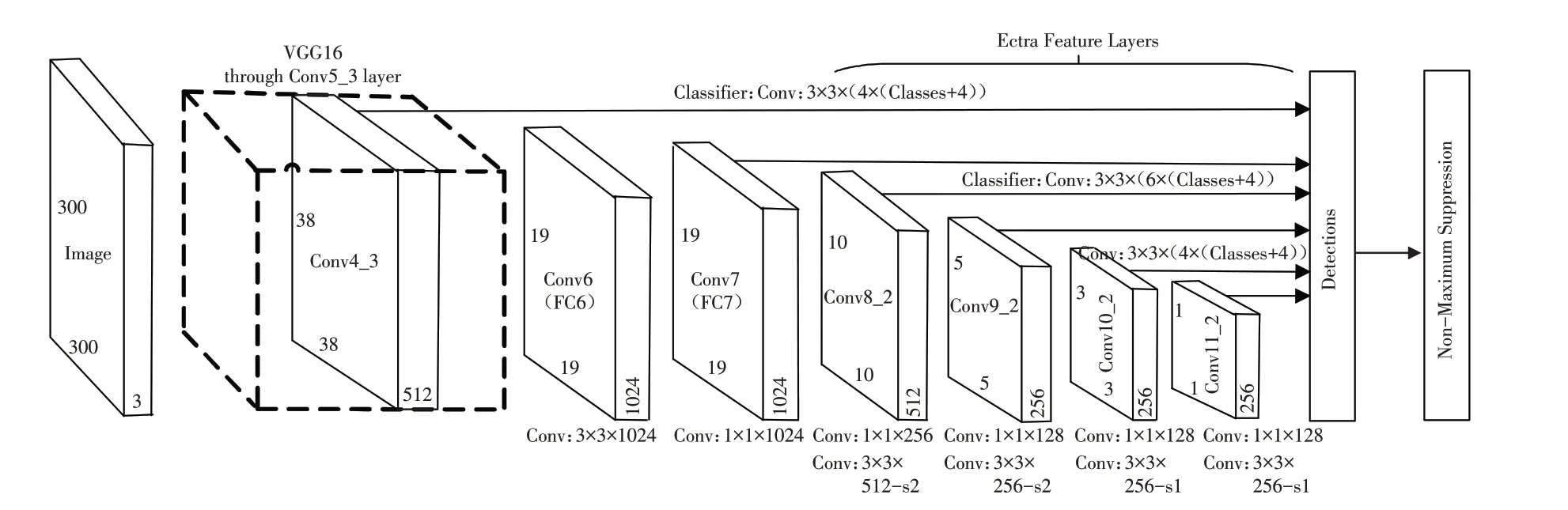
图1 SSD结构图Fig.1 SSD structure
2 算法模型
2.1 MFF-SSD模型
SSD网络生成的预测框质量较低,导致小尺度目标或遮挡目标定位失败,影响检测效果.针对SSD算法在检测小目标物体存在的检测视野范围小、检测图像长宽比单一、检测精度较低、检测实时性较差等问题[1,8-9],提出一种基于SSD结构的多尺度特征融合(Multi-scale Feature Fusion Single Shot Detector,MFF-SSD)模型.MFF-SSD模型对SSD网络结构的后4层进行反卷积,得到MFF-SSD模型的4个反卷积模块(Conv12_2、Conv13_2、Conv14_2和Conv15_2).同时合理利用融合了高层网络和低层网络的优势,将高层反卷积特征图与低层卷积特征图进行多尺度融合,然后将特征融合模块与SSD网络的7~11层同时输入到网络的检测模块进行检测,结构如图2所示.

图2 MFF-SSD模型Fig.2 MFF-SSD model
高层特征图对目标的抽象程度更深,包含充分的全局信息,具有较大的感受野和较强的上下文语义信息表征能力,因此对目标位置的判定更加准确,低层特征图的空间分辨率要高于高层特征图,能够更加准确地识别出更多的边缘、轮廓和纹理等细节信息,对目标类别做出准确判定.MFF-SSD模型从不同的卷积层来提取特征用于目标检测,所采用的卷积层分别是Conv2_2、Conv3_3、Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2,共提取大小分别是(150,150)、(75,75)、(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)的8个特征图.该模型实现了来自不同卷积层、不同尺度、不同特征的多元信息的分类检测与位置回归[8].
2.2 融合模块
MFF-SSD模型有4个融合模块,他们的融合方式是相同的,采用的都是跳跃连接方式.以模块1为例对融合模块进行说明,在特征融合的过程中,对高层特征图Conv15_2进行上采样,使用大小为2×2的卷积核以及256的通道数的反卷积,将反卷积的输出采用大小为3×3的卷积核的卷积层输出到ReLU.接着输出到BN层采用L2正则化对数据进行批量归一化,然后到下一个反卷积层,这个反卷积层与第一个反卷积层不同的是采用的卷积核大小为3×3,卷积层输出后跳过ReLU直接到BN层.对低层特征图Conv2_2不需要进行反卷积,采用大小为3×3的卷积核输出到ReLU层,然后输出到BN层[8].对高层特征图Conv15_2反卷积的输出与低层特征图Conv2_2卷积层的输出做求和操作(Eltw Sum),求和后输出至ReLU层,然后再进行一次卷积和ReLU之后就能够实现融合.融合模块如图3所示.
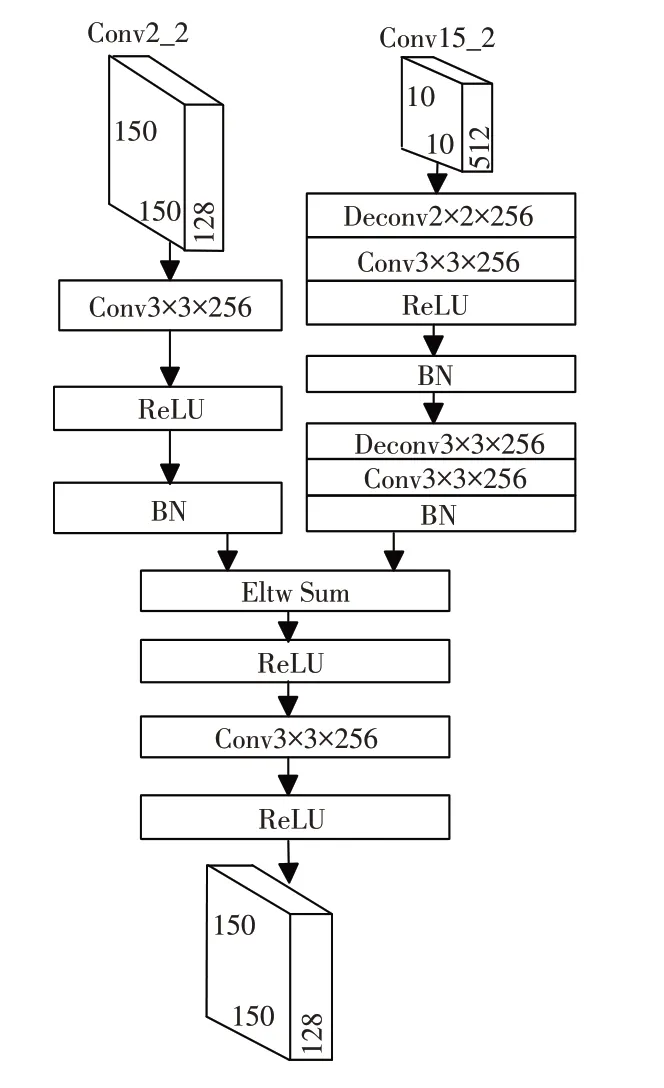
图3 融合模块Fig.3 Fusion module
MFF-SSD模型采用跳跃连接的方式使得模型的运算得到了简化,降低了复杂度,输出的特征图的数量和种类也得到了增加,同时提供的几何信息和语义信息更加准确,主要是网络上下文的语义信息得到了充分利用.
2.3 检测流程
MFF-SSD模型检测流程是首先对输入图像进行预处理,包括尺度归一化,即将图像调整为合适的尺寸,并将其划分为S×S个网格,然后通过卷积神经网络对图像特征进行提取,对提取的特征图进行多尺度融合后再做检测.每个网格检测目标中心位于该网格的目标,预测B个边界框和C个类别,不同尺度的特征图预测的边界框和类别数目是不同的,对于检测结果采用置信度对其做阈值处理,从而得到最终检测结果[10],流程图如图4所示.

图4 MFF-SSD检测流程图Fig.4 MFF-SSD detection flow chart
3 模型训练过程中的关键问题
模型训练过程可划分为两个阶段,第一阶段进行预训练,在SSD模型训练的基础上得到MFF-SSD模型的一些初始化参数;第二阶段进行微调,主要是通过实验数据的训练集对相关权重进行微调.为了确保模型的训练性能,通常对数据采用的方式是通过数据增强来提升模型的训练能力,主要方法有水平翻转、随机裁剪与颜色扭曲、随机采集块域(获取小目标训练样本).
3.1 先验框设置与匹配原则
网络模型在做目标检测时产生不同尺度的特征图,这要求设置的先验框具有不同的尺度和长宽比,先验框设置[8]遵循公式(1)的原则.
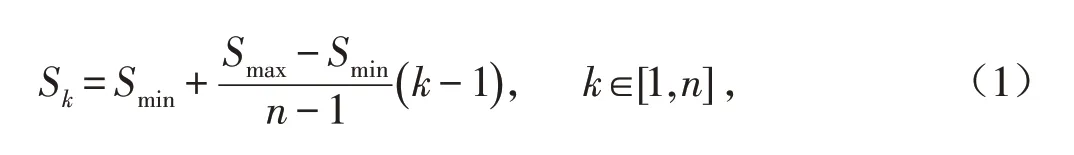
其中:n表示特征图数量,用于目标的预测和分类;S代表特征图的大小;Sk代表第k个特征图上先验框相对于图像的比例;而Smax和Smin代表比例的最大值和最小值,一般取Smax=0.9和Smin=0.2.


先验框匹配[8,11-12]就是要确定哪个先验框与图像中的真实目标进行匹配,相匹配的先验框所对应的边界框将负责预测它.匹配原则有以下两个:
1)图像中每个真实目标与其交并比(Intersection Over Union,IOU)最大的先验框进行匹配,以确保每个真实目标都有一个先验框与之相匹配,与真实目标相匹配的先验框称为正样本,没有与任何真实目标相匹配的先验框称为负样本[8,13].由于先验框数目较多真实目标数目较少,导致正负样本不均衡,因此需要采用另一个原则.
2)如果某个先验框与真实目标的交并比大于给定阈值(0.6),则将先验框与真实目标进行匹配,对于先验框与多个真实目标的交并比大于阈值的情况,与先验框相匹配的真实目标取交并比最大的一个[7].原则1)的优先级高于原则2).
为了使得正负样本均衡,可以通过难例挖掘(hard negative mining)来实现,对置信度误差采取降序排列的方式.设置置信度阈值0.01,将误差较大的top-200作为负样本进行训练,以确保正负样本达到1∶3的比例[13].
3.2 损失函数
损失函数[8,14]由置信度误差(Confidence Loss,LConf)与位置误差(Locatization Loss,LLoc)的加权和构成,如公式(3)所示.

其中:m表示先验框与真实目标是否匹配,若匹配m取值为1,不匹配m取值为0;c为多类别目标的置信度预测值;b为对应于先验框的边界框位置预测值;g是真实目标的位置参数;N是与真实目标相匹配的先验框数量,即先验框的正样本数量;λ是对位置误差与置信度误差之间的比例进行调整的参数,一般是通过交叉验证进行设置,通常取为1.
位置误差[8,15]LLoc的计算使用真实目标和先验框之间的SmoothL1损失,如公式(4)所示.
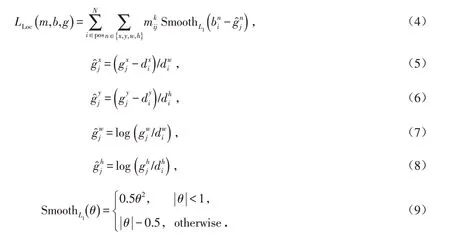
置信度误差LConf是多类别置信度c的softmax损失,如公式(10)所示.

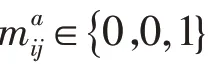
在实际的训练过程中,对损失函数的参数进行改变可以提高预测框的位置以及类别置信度,再对训练结果进行多次优化,能够进一步提高网络模型的目标检测准确率,训练出的网络模型的检测效果也会更好.
4 实验与结果分析
4.1 数据集
通过人脸检测实验验证本文提出的MFF-SSD模型,人脸检测数据集很多,我们采用的是Wider Face数据集,该数据集在人脸检测领域被认为是目前最有难度的数据集,场景丰富,具有不同的尺度、姿态、角度、表情、光照和遮挡,分辨率较高.该数据集的数据量较大、注释丰富,包含许多难以检测的小脸,具有一定的可靠性,同时避免了过拟合现象的出现,广泛应用于性能评估更好的卷积神经网络.实验选取该数据集中所有事件类别,每个类别的训练集和测试集都是随机选择的,其中用于训练集的样本数是158 989,用于测试集的样本数是195 218.
数据增广技术主要有水平翻转、随机裁剪和颜色扭曲、随机采集块域,通过数据增广可以提升算法性能.因此,很多时候可以通过对采集到的数据集进行数据增广来进一步提高算法性能.
4.2 实验结果与分析
实验输入图像尺寸大小为300×300,参数[10]设置为:迭代次数为5000,学习率为0.000 1,动量因子为0.9,权值衰减参数是0.000 5,IoU为0.6.根据检测的难易程度将数据集划分为三个等级:Easy、Medium和Hard.Easy类别的图像尺寸较大,容易检测,且准确率较高;Medium类别场景复杂度一般,人脸尺寸适中,检测难度居中;Hard类别人脸分布密集程度高,场景相对复杂,且人脸尺寸较小,难以检测,准确率较低.对常用的目标检测算法[16]与本文提出的MFF-SSD算法进行对比,实验结果见表2.
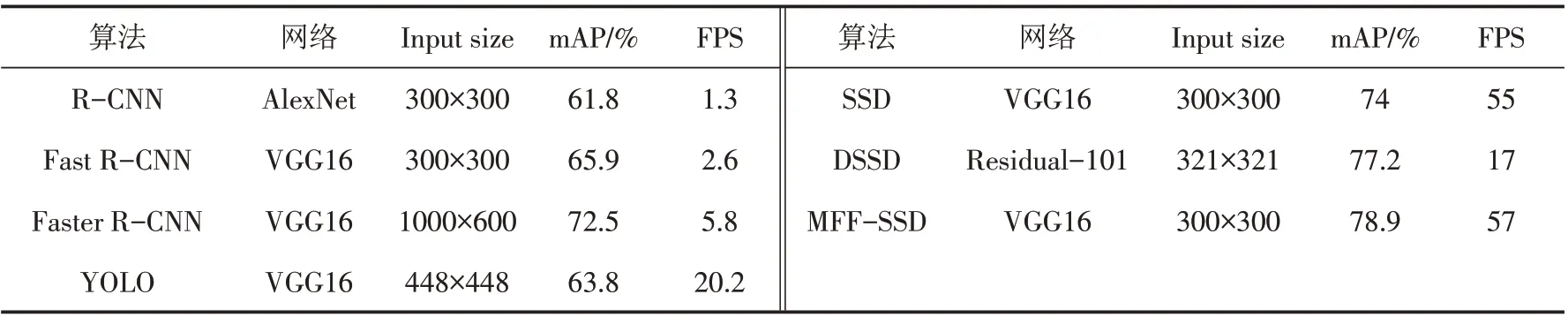
表2 各种算法检测结果对比Tab.2 Comparison of detection results of various algorithms
表2中mAP(mean Average Precision)指的是不同类别下的均值平均精度,用来对模型精度进行定量分析;FPS(每秒传输帧数)是目标检测过程中处理速度的衡量指标.对表2中mAP和FPS两列数据进行对比,在Wider Face数据集中,MFF-SSD模型的目标的检测均值平均精度达到78.9%,检测速度达到57 FPS.实验结果表明,MFF-SSD算法检测分类更准确,定位更精确,总体性能较好,满足了均值平均精度和实时性的双重要求.
5 结论
本文提出的MFF-SSD目标检测算法在满足检测精度的基础上也达到了实时性要求,通过验证实验表明算法达到了对自然场景下人脸进行检测的需求,并且相对于现有的目标检测算法如SSD、DSSD等更加高效,不仅检测精度高、速度快,同时对于智慧城市建设以及采用人脸检测进行识别的各种智能系统等都具有一定的理论依据与现实意义.今后研究中可以利用上下文相关信息、语义信息以及场景信息等设计并实现检测精度与速度更高效、更快速的新的目标检测算法,力求满足更加复杂条件下的目标检测.
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
矿山测量(2020年2期)2020-05-17
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
岁月(2016年5期)2016-08-13
太空探索(2016年5期)2016-07-12
探测与控制学报(2015年4期)2015-12-15
