
基于膨胀卷积的多模态融合视线估计
2021-08-10 10:38罗元,陈顺,张毅
重庆邮电大学学报(自然科学版) 2021年4期
罗 元,陈 顺,张 毅
(1.重庆邮电大学 光电工程学院,重庆 400065;2.重庆邮电大学 先进制造学院,重庆 400065)
0 引 言
近年来,随着计算机视觉技术的飞速发展,视线估计技术引起了广泛的研究,并且在很多应用中都有很大的潜力,比如人机交互、心理分析、虚拟显示、人类行为研究等。目前视线估计方法主要有基于模型的视线估计和基于表观的视线估计[1]。
基于模型的视线估计通常需要利用红外线光源照射人眼,基于人眼角膜反射产生高亮光斑,根据光斑的位置和瞳孔中心的位置,结合3D眼球先验知识,估计视线方向。此类方法[2-6]实现了高精度,但为了获得稳定、准确的特征检测,通常要求接近于正面的头部姿态从而提取高分辨率眼睛图像,这限制了用户的移动性,且通常需要专用的硬件,例如多个红外摄像机,多个设备之间的位置关系需要精确地匹配,设备标定带来的误差累计也会影响视线的估计精度,所以难以被广泛应用。
另一方面,基于表观的视线估计是通过提取眼睛的视觉特征,然后训练回归模型学习从眼睛特征到视线方向的映射,从而进行视线估计。如,LU等[7]和MARTINEZ等[8]都是利用支持向量回归训练视线估计的回归模型,其中,文献[7]使用局部二值模式(local-binary-pattern texture feature, LBP)提取眼睛的纹理特征,并结合眼睛的空间坐标作为组合特征,文献[8]提取眼睛的mHOG特征。LU等[9]提出的方法是基于自适应线性回归方法建立的,该方法可以自动选择用于映射的训练样本。随着深度神经网络在图像识别领域的发展和成功,基于表观的视线估计开始直接使用整幅眼睛图像作为高维输入向量,利用卷积神经网络[10]学习其与视线方向之间的映射。例如,KRAFKA等[11]使用从正面拍摄的三原色(red green blue,RGB)的人脸图像来学习智能电话屏幕上的视线估计,将RGB的双眼图像、RGB的人脸图像、以及人脸网格作为卷积神经网络的输入。为了训练设计的卷积神经网络,收集了一个大小为2.5 M的数据集,并在Eyediap数据集上实现了一个8.3°误差的视线估计模型。ZHANG等[12]提出了一种用于视线估计的全脸卷积神经网络结构,利用基于特征映射的带空间权值的卷积神经网络对RGB的人脸图像进行编码,从而抑制或增强不同面部区域的信息,将完整的人脸图像作为输入并直接回归得到视线方向,在Eyediap数据集上的误差为6.0°。ZHANG等[13]将单个RGB的人眼图像输入单列卷积神经网络,并在网络的全连接层结合头部姿态作为网络的输入,从而进行视线估计,在Eyediap数据集上实现了误差为10.5°的视线估计模型。DENG等[14]分别设计2个卷积神经网络来模拟头部姿态和眼球运动,通过注视变换层连接,实现在自由头部运动下的视线估计。尽管有这些进步,但目前大多数研究都是基于RGB图像进行处理,且在头部自由运动的状态下,基于表观的视线估计方法误差较高。同时,目前的视线估计模型通常采用池化层来增大深度特征图中的感受野,导致了人眼的信息损失。
为了解决上述提到的问题,本文提出了一种基于膨胀卷积的多模态融合视线估计模型,利用膨胀卷积核在不增加参数的前提下可增大卷积核感受野这一优点,更好地提取人眼RGB图像和深度图像的特征图,并与头部姿态进行多模态的融合,从而进行视线估计。实验结果表明,膨胀卷积将进一步降低估计误差,且多模态融合可以充分利用多个模态之间的互补信息和复杂相关性,本文提出的模型可以实现误差更低的视线估计。
1 基于卷积神经网络的多模态融合视线估计
一个卷积神经网络[10]通常由卷积层、池化层和全连接层组成。卷积层通过卷积运算来提取图像特征,卷积运算表示为
(1)
(1)式中:y[j]是第j个输出特征图;x[i]是第i个输入特征图;ωij是第i个输入特征图和第j个输出特征图间的卷积滤波器;bj为第j个输出图的偏置项;*为卷积运算;f为激活函数。卷积运算主要通过稀疏交互、参数共享等手段来改进卷积神经网络。卷积神经网络的稀疏连接性极大地降低了计算的复杂度。参数共享可以有效地减少模型需要学习的权值参数,降低模型的存储需求。
池化层常用于下采样特征响应图的局部区域,通常设置在卷积层后。常用的池化方法有均值池化和最大池化,池化操作保证了图像平移、旋转和尺度的不变性,保留主要特征的同时减少了参数数量。
当图像经过卷积层和池化层逐层提取特征后,会获得最终的特征图,将这些特征图与全连接层相连,使每个输入与输出的神经元产生联系,从而最大程度地表示全局特征,所以网络中大部分的参数量在全连接层,有针对性地将提取出的特征表示映射到样本标记空间,进行回归任务。
图1为文献[13]利用卷积神经网络进行视线估计的模型,它使用LeNet网络[10]作为视线估计模型的网络架构,包括2个卷积层、2个池化层,以及一个全连接的层。这个网络将1@36×60的眼睛图像和头部姿态h作为输入,其中,1为眼睛图像的通道数,36×60为眼睛图像的大小,并将头部姿态h与全连接层连接起来,增加模型对于头部自由运动的鲁棒性,最后在全连接层通过训练一个线性回归得到视线方向的二维凝视角参数g∈R2×1,R为2×1的矩阵。

图1 基于卷积神经网络的多模态融合视线估计Fig.1 Convolutional neural network-based gazeestimation via multimodel fusion
与文献[13]类似,目前基于卷积神经网络的视线估计通常采用池化层(如最大池化和平均池化)来增大特征图中像素点的感受野,但同时也极大地降低了空间分辨率,意味着特征图的空间信息丢失。本文采用膨胀卷积算法,即不通过池化获得较大的感受野,并减小信息损失。本文提出的模型是在基于卷积神经网络的多模态融合视线估计模型上进行改进的,考虑到人眼的RGB图像与深度图像分别包含人眼的特征信息和额外的空间中眼睛的位置,从而结合这2种模态进行融合,并设计基于膨胀卷积的GENet网络分别提取其深度特征。
2 基于膨胀卷积的多模态融合视线估计
2.1 膨胀卷积
膨胀卷积[15]的主要思想通过在权值间插入零点来扩展卷积滤波器,从而增加感受野的大小而不增加参数的数目。一般来说,对于每个空间位置i,一维膨胀卷积定义为
o[i]=∑x[i+rl]ω[i]
(2)
(2)式中:o[i]和x[i]表示特征图上位置i的输出和输入;ω是大小为l的卷积滤波器;r是采样输入的膨胀率。膨胀卷积是通过在原滤波器ω的2个连续空间位置之间沿每个空间维插入r-1个零来实现的。对于k×k的卷积核,膨胀卷积核的实际大小为kd×kd,其中,kd=k+(k-1)(r-1)。非零参数的数目与原始参数相同,使计算复杂度保持不变。因此,膨胀卷积能够在增加有效感受野的同时实现参数的显著减少,从而卷积神经网络能够捕捉到更多的上下文信息,有望获得更有鉴别性的高层特征。标准卷积是r=1的膨胀卷积的特例。标准卷积与膨胀卷积的对比如图2。很明显,3×3卷积滤波器在膨胀率r=2时的样本特征映射与5×5标准卷积滤波器类似,这意味着这2个卷积滤波器后输出的感受野大致相同。因此,通过选择不同的膨胀率,可以任意改变膨胀卷积的视场。

图2 标准卷积与膨胀卷积(r=2)的对比Fig.2 Comparison of standard convolution and expansion convolution (r=2)
2.2 基于膨胀卷积的GENet网络
距离信息是深度图像最为直接也是最容易获得的编码,在使用时,通常会以灰度图的形式参与运算。由于人眼的深度图像包含了眼睛在额外空间中的信息,如图3,本文将人眼的RGB图像结合深度图像形成4个通道的人眼图像作为模型的输入,输入大小为4@36×60。同时双眼网络具有相同的结构,在所有卷积层和膨胀卷积层中共享相同的参数。GENet的网络结构如表1,卷积层的参数表示为“Conv-(核大小)-(滤波器数目)-(膨胀率)”。考虑到VGG-16网络在各种计算机视觉任务中显示出越来越优越的性能,Conv1,Conv2,Conv3,Conv4采用了VGG-16网络[16],仅使用3×3的卷积核。并在Convl,Conv2,Conv3,Conv4后接入了步长为2、空间尺寸为2×2的最大池化(max-pooling)操作。网络在Conv5开始引入卷积的膨胀系数,即进行膨胀卷积操作,以扩大神经元的感受野。其中,GENet A的膨胀率为1,即标准卷积。在经过卷积组后均添加Batch Normalization层,即批标准化[17],其能够提高网络的泛化能力,具备更快速的收敛特性。前4个卷积层的权重从在ImageNet数据集[18]预先训练的VGG-16的前4层转移。

图3 基于膨胀卷积的多模态融合视线估计Fig.3 Dilated convolution-based gaze estimation via multimodel fusion

表1 GENet的网络结构
本文将ReLU函数[19]作为卷积层和全连接层的激活函数,其相比于sigmoid函数,tanh函数等激活函数,具有克服梯度消失,加快模型的训练速度以及更好的防止模型过拟合的性质。ReLU激活函数为
f(x)=max(0,x)
(3)
(3)式中:x是输入;f(x)是经过ReLU单元之后的输出。
最后,将双眼分别通过GENet网络形成的全连接层(即FCleft层和FCright层,分别表示为XL和XR)的输出状态串联起来,送入具有1 000个神经元的FCMV层。确保FCMV层的每个节点都可以连接FCleft层和FCright层的所有节点,从而得到FCMV层的活化值为
XMV=(ωL)TXL+(ωR)TXR+bMV
(4)
(4)式中:ωL是连接FCleft层和FCMV层的卷积层;ωR是连接FCright层和FCMV层的卷积层;bMV是偏差。为了增加对于头部运动的鲁棒性,基于文献[12]将头部姿态h加入全连接层FCMV,采用线性回归得到预测的视线方向,得到的视线方向为二维凝视角参数g∈R2×1,由偏航角φ和俯仰θ角组成。
本文利用L2损失函数训练视线估计模型
(5)

3 实验分析
3.1 Eyediap数据
在公开数据集Eyediap[20]上验证提出的视线估计模型。Eyediap利用Kinect相机获取RGB和Depth视频流,视频的分辨率为640×480,帧速率为30 帧/s。记录的视频序列主要包含头部姿态、注视点、参与者(16人)、记录条件(不同的天气、光照、到相机的距离)4种变量。具有2种头部姿态,静止状态和执行平移和旋转的运动状态。其视觉目标包括在计算机屏幕上所记录的离散屏幕坐标(discrete screen target,DS)和连续屏幕坐标(continuous screen target,CS),以及3D浮动目标(floating target,FT)。本文对Eyediap数据集按5帧/s提取一张图片,去掉眼睛闭合的图片,共在Eyediap数据中分别提取86 000张RGB和深度图片。
3.2 预处理
在训练时,将给定的头部姿态和在原始RGB图像和深度图像中利用给定的瞳孔坐标裁剪得到的眼睛区域作为输入,训练模型。在测试时,本文采用文献[21]提出的多任务卷积神经网络(multi-task cascaded convolutional neural networks,MTCNN)算法进行人脸检测。MTCNN算法能同时进行人脸检测以及人脸面部特征点(左右瞳孔、鼻尖、左右嘴角)检测,针对自然环境中的光线、角度和人脸表情变化等,均具有良好的鲁棒性,能够准确地估计视线方向。接着利用面部特征点对人脸区域进行仿射变换[22],从而得到矫正的人脸图像,在矫正的人脸图像中根据新的瞳孔坐标设定眼睛大小的阈值从而得到人眼区域,最后将双眼图像尺度归一化到36×60。采用文献[23]提出的最先进的方法直接利用人脸图像估计出头部姿态。人脸检测和人眼区域定位流程如图4。

图4 人脸检测和人眼区域定位流程图Fig.4 Flow chart of Face detection and humaneye area positioning
3.3 实验评价指标
本文在Eyediap数据集上使用角误差(ε°)作为性能测量,角误差被定义为真实视线方向和估计视线方向之间的夹角,表示为
(6)
3.4 参数设计
算法实验测试的硬件环境为搭载XEON E5 2.4 GHz CPU,64 GB内存,GTX1080ti GPU,配置NVIDIA GTX1080Ti/11 GB,内存为64 GB的计算机,软件环境为Ubuntu16.04操作系统,基于深度学习框架TensorFlow进行。
本文网络权重采取MSRA(microsoft research)初始化。它规定第i层的权值ωi服从均值为0,方差为2/ni的分布,通常采用高斯分布形式,ωi~N(0,2/ni)。采用随机梯度下降算法训练网络,网络的动量和权值衰减参数分别设置为0.9和10-4。训练的批次大小为128,训练次数为60 epoch,训练开始阶段,将初始学习率设置为10-3,随着训练的进行,观察损失函数,动态微调学习率,最低将其降低到10-5。
3.5 实验评估和结果分析
本文将提取的左右眼RGB视图和配套的深度视图随机分成2个部分。70%的训练集用于训练,剩下的数据集用于测试,从而对2个完全不相交的子集进行训练和测试,以避免过度拟合。考虑到数据库的大小相对较小,本文采用3种方法对数据进行在线增强:对训练集图像进行水平和垂直翻转,改变图像的对比度,以及加入高斯噪声。
通过对使用不同膨胀率来提取眼睛特征图进行视线估计评估的结果如表2,运用了膨胀卷积的网络结构标准卷积的角误差更小,其中,GENet C实现的角误差最小。因此,本文使用GENet C作为本文的网络结构进行以下实验。

表2 不同GENet网络结构的角误差(ε°)Tab.2 Angular error (ε°) of different GENetnetwork structures
分别对输入的4种类别进行对比,如表3。实验结果如图5,图6,显示了模型的损失函数和误差变化,网络在迭代60 epoch后损失函数收敛。当输入为RGB+h,Depth+h时,最终角误差分别为6.23°和7.5°,因此,对于视线估计,相比于深度图像,RGB图像能更好地表现人眼特征信息。当输入为RGB+Depth和RGB+Depth+h时,最终角误差分别为10.14°和5.52°。由此可知,当输入只有RGB图像和深度图像,缺少头部姿态时,此时识别效果最差,说明头部姿态对于视线估计起到重要作用。而本文提出的融合人眼RGB信息、人眼深度信息和头部姿态的视线估计模型,相比其他3种类别的输入误差分别降低了45.56%,11.40%,36.00%,角误差最小。

表3 不同输入类别的角误差(ε°)对比Tab.3 Angle error (ε°) comparison of differentinput categories

图5 训练损失函数变化对比图Fig.5 Comparison of training loss function changes

图6 误差变化对比图Fig.6 Comparison of angle error changes
文献[24]通过头部跟踪器给出的眼睛位置提取眼睛图片,并利用基于k-NN(k-nearest neighbor)的方法和基于流形学习的自适应线性回归(adaptive linear regression, ALR)对眼睛图像训练得到视线方向,如表4。
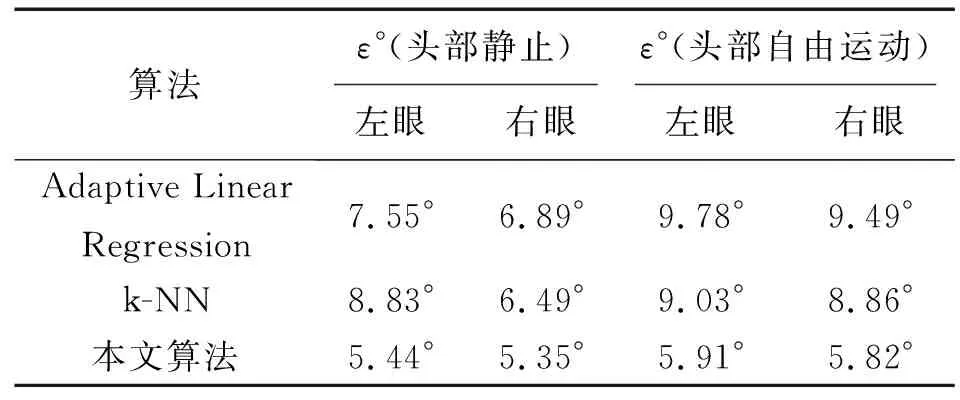
表4 Eyediap 数据集中在不同头部状态时的表现Tab.4 Performance of different head stateson the Eyediap dataset
本文将提出的算法与文献[24]中的2种回归算法在头部静止和头部自由运动2种状态下左眼和右眼的视线估计误差进行了对比。实验结果表明,本文提出的算法在头部静止与头部自由运动时,视线估计误差均低于另外2种算法,且当头部在自由运动时,视线估计误差只有细微的下降,可见,本文提出的视线估计模型相比于利用传统机器学习算法提出的视线估计模型能更好地进行视线估计,且对头部姿态的变化具有更强的鲁棒性。
与基于卷积神经网络的视线估计算法进一步比较,结果如表5。文献[11]和文献[13]中的特征提取器分别为AlexNet网络和LeNet网络,为了更好地进行对比,本文将原始特征提取器替换为GENet C,用*表示替换,所有其他部分均相同。文献[11]改进后得到的角误差为7.9°,误差降低了4.82%;文献[13]改进后得到的角误差为7.3°,误差降低了30.4%。这显示了本文设计的网络具有一定优越性。其中,文献[12]将全脸图像作为输入,以学习用于视线方向预测的Spatial weight CNN,进行视线估计的角误差为6.0°,排在第2。与之相比,由于本文利用RGB信息与深度信息的多模态融合,获得了人眼的特征信息和额外的空间中眼睛的位置,并引入了头部姿态,比单独使用人脸进行估计相比获得了更低的误差。

表5 基于卷积神经网络的视线估计在Eyediap数据集上对比Tab.5 Comparison of gazet estimates based on convolutionalneural networks on the Eyediap dataset
4 结束语
考虑到基于模型的视线估计的应用受限的问题,在本文中,主要对基于表观的视线估计进行研究,引入膨胀卷积,通过对人眼的RGB图像、深度图像和头部姿态进行多模态融合搭建了一个端到端的视线估计系统。实验结果表明,在CNN中膨胀卷积的引入能够进一步降低误差;当输入为3个模态时,估计误差最小;在视线估计这项任务中头部姿态起着重要作用,而本文提出的模型对于头部姿态的变化具有较强的鲁棒性;同时,通过与近几年其他视线估计的先进方法进行对比,本文提出的模型依旧取得了优越的性能。在接下来的研究中,本文将重点研究当人戴有眼镜这类遮挡物时如何降低视线估计的误差。
猜你喜欢
特区文学·诗(2021年6期)2021-12-22
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
动漫星空(2018年9期)2018-10-26
金色少年(奇趣科普)(2017年11期)2017-11-28
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
当代贵州(2015年19期)2015-06-13
