
GPU的QC-LDPC码译码器设计与实现
2021-08-10 10:42:16张晓芳
重庆邮电大学学报(自然科学版) 2021年4期
张晓芳,黎 勇,2
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2. 重庆大学 计算机学院,重庆 400044)
0 引 言
基于量子力学的物理基础即测不准原理和量子不可克隆原理,量子密钥分发(quantum key distribution, QKD)系统给合法的通信双方提供了绝对安全可靠的“一次一密”通信[1]。量子密钥分发系统是量子信息在实际生活中的第一个应用。在离散变量量子密钥分发(discrete variable QKD, DV-QKD)中,由于单光子检测器的速度和效率的限制,使其实现成本很高;而连续变量量子密钥分发(continuous variable QKD, CV-QKD)系统可以采用现有的标准电信技术,因而被认为更有前景。连续变量量子密钥分发系统利用连续变量例如相干态的正交基编码密钥信息。量子密钥分发系统一般主要有2个阶段:①量子比特的传输过程;②量子后处理过程。后处理过程分为2个步骤:密钥协商和隐私放大。其中,通过提升译码纠错速度实现高效地密钥协商尤为重要。在较远距离,较低信噪比的情况下,通信双方只有传输码率较低、码长较长的码字才能获得高效的密钥协商。
R. Gallager[2]博士于1962年提出了一种带有稀疏奇偶校验矩阵的线性纠错码——低密度奇偶校验(low density parity check, LDPC)码。Tanner于1981年将LDPC码用Tanner图表示:一类节点是校验节点,代表码字的一组校验方程;另一类是表示码字元素的变量节点,变量节点和校验节点通过边连接。D. Mackay和R. M. Neal等[3]于1999年发现采用迭代置信传播译码算法,LDPC码纠错性能接近香农极限。LDPC码主要有2类:随机LDPC码和结构化LDPC码,随机LDPC码性能较好,但是没有结构的校验矩阵增加了编码复杂度。因此,在实际系统中通常采用结构化LDPC码,比如准循环低密度奇偶校验(quasi-cyclic LDPC, QC-LDPC)码[4]。
Paul Jouguet[5]提出利用图形处理器(graphics processing unit,GPU)实现LDPC译码器,在0.161的信噪比下,码率为0.1的随机多边型低密度奇偶校验(multi-edge type LDPC, MET-LDPC)码的译码速度达到了7.10 Mbit/s。Mario Milicevic等[6]针对码率为0.1,扩展因子为512的准循环多边型低密度奇偶校验(quasi-cyclic MET-LDPC, QC-MET-LDPC)码,在信噪比为0.161,具有提前终止的条件下,达到了9.17 Mbits/s的速度。XIANGYU WANG等[7]提出只在最后一次迭代时才更新度为一的变量结点,大大减少了计算量,在码率为0.1,信噪比为0.161的条件下,获得了30.39 Mbits/s的速度。以上方法都是基于GPU实现的传统置信传播(belief propagation, BP)译码器,在每次迭代过程中,首先更新所有的变量节点的对数似然值(log likelihood ratio, LLR),再更新所有校验节点的对数似然值。GPU译码器的译码速度由拷贝耗时、单次迭代译码耗时和总的迭代次数等因素决定。传统的BP译码算法收敛速度较慢,需要更多的迭代次数才能达到较好的译码性能,降低了译码速率[8]。本文设计了一种基于分层置信传播译码(layered BP, LBP)算法的GPU译码器,在码率为0.1,码长为106,循环50次的条件下,该译码器速率达到了41.50 Mbits/s。
1 分层译码算法
LDPC码通过节点之间消息可信度的传播进行译码,即BP译码算法。最初的BP算法含有大量的乘法和指数运算,为了降低运算的复杂度,进而提出了对数域的BP算法[9]。分层BP译码算法不同于传统的BP算法,分层BP译码算法可以将整个校验矩阵按行划分为不同的层,每层的列重小于等于1,层内依然使用的是传统的BP译码算法,层与层之间,下一层利用上一层获得的数据依次进行运算。分层BP译码算法收敛速度更快,只需要传统BP译码算法约一半的迭代次数就可以达到同等的纠错效果[10]。
本文采用的译码算法为分层BP译码算法[11],其流程如下。
1)初始化。
(1)
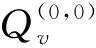
2)校验节点更新。
(2)
(3)
(4)
(5)

3)变量节点更新。
(6)
(7)
4)更新下一层。
l=l-1
(8)
5)译码判决。
(9)
(9)式中,Cv表示根据第v个变量节点判决出的码字。如果满足C·HT=spc或者达到最大迭代次数则停止迭代,反之返回1.2节中进行迭代。
2 译码器实现和优化
2.1 译码器整体结构
分层译码器整体结构可分为数据处理模块、数据拷贝模块、纠错译码模块和误码统计模块,整体结构框图如图1。

图1 译码器结构框图Fig.1 Structure diagram of decoder
数据处理模块通过读取基矩阵获取基矩阵非‘-1’元素的总数、移位量、基矩阵非‘-1’元素对应的列的位置和基矩阵的行重等信息,并将纠错译码模块所需的基矩阵信息处理合并。数据拷贝模块将纠错译码模块所需信息从主机端拷贝至GPU端,如:基矩阵信息和码字信息。纠错译码模块结构框图如图2。
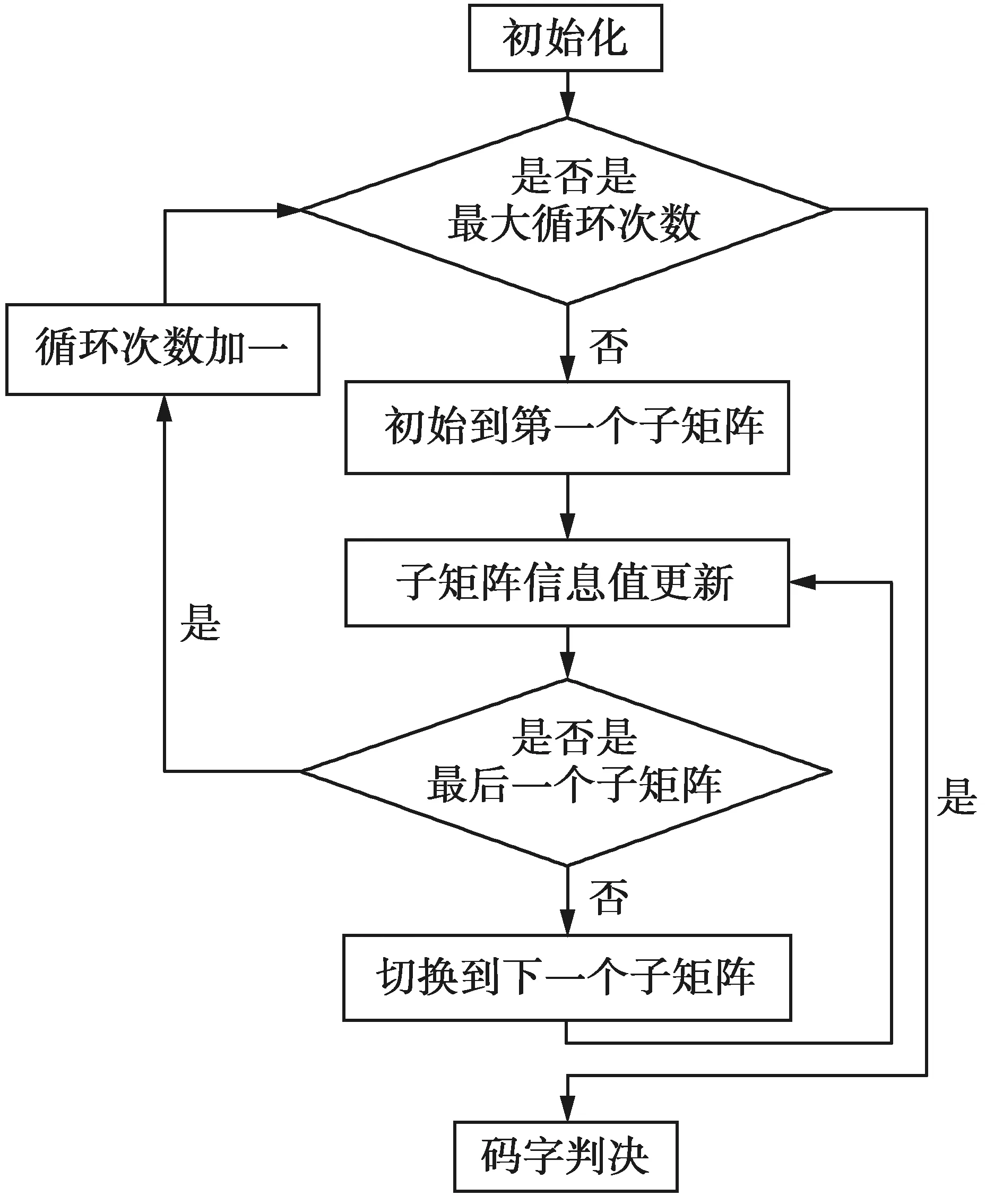
图2 纠错译码模块结构框图Fig.2 Structure diagram of error correction decoding module
纠错译码模块利用分层BP译码算法迭代更新变量节点和校验节点的信息值进行纠错译码。初始化部分计算了校正子和信道传输到变量节点的信息的LLR值。子矩阵信息值更新部分利用一个核函数,找到对应的索引号,更新变量节点传给校验节点的LLR值,再更新校验节点传给变量节点的LLR值,最后更新变量节点的LLR值。一个子矩阵的信息值更新完毕,则换到下一个子矩阵进行更新。遍历所有的子矩阵完成一次完整的信息值更新。当循环到下一次迭代时,又从第一个子矩阵开始遍历,直至更新完所有的子矩阵,跳到下一次迭代,达到最大迭代次数时结束循环。码字判决部分通过变量节点的LLR值是否大于等于零进行判决,若LLR值大于等于零则判决码字为0,否则为1。接下来再次利用数据拷贝模块将GPU上的数据拷贝回主机端。最后,误码统计模块在主机端统计错误帧数。
2.2 节点并行方案
由分层BP译码算法可以看出,节点与节点之间在更新LLR值时互不影响,因此,可以利用GPU线程的并行处理方式,将Tanner图中的每一个变量节点的计算量对应于一条线程,因为分层后每个子矩阵的变量节点度小于等于1,亦即每条边上传递的信息对应于一条线程,使变量节点可以同步并行更新,获得更快的译码速度。
在节点并行译码方案中,根据以上线程的映射方式,节点的计算分2步进行:①校验节点的计算。线程先映射于每条边上传递的信息,计算出变量节点与该校验节点相连的边传递的LLR值,再更新一组子矩阵的所有校验节点;②变量节点的计算。线程先映射于每条边上传递的信息,根据子矩阵校验节点的信息,并行计算与该校验节点相连的每条边所传递的信息,然后线程映射于变量节点的信息,更新该子矩阵的所有变量节点。在同次迭代中,该子矩阵更新的值传递到下一子矩阵,下一子矩阵采用和该子矩阵相同的处理方式,重复利用线程资源更新子矩阵对应的校验节点和变量节点的LLR值,直至所有子矩阵更新完毕,完成一次迭代。
为方便理解,采用图3举例说明节点并行LLR值更新方式。其中,thv表示线程,Qvc表示由变量节点传递给校验节点的LLR值,Rc表示校验节点的LLR值,Rcv表示由校验节点传递给变量节点的LLR值,Qv表示变量节点的LLR值,对应图3代入了具体的数据。
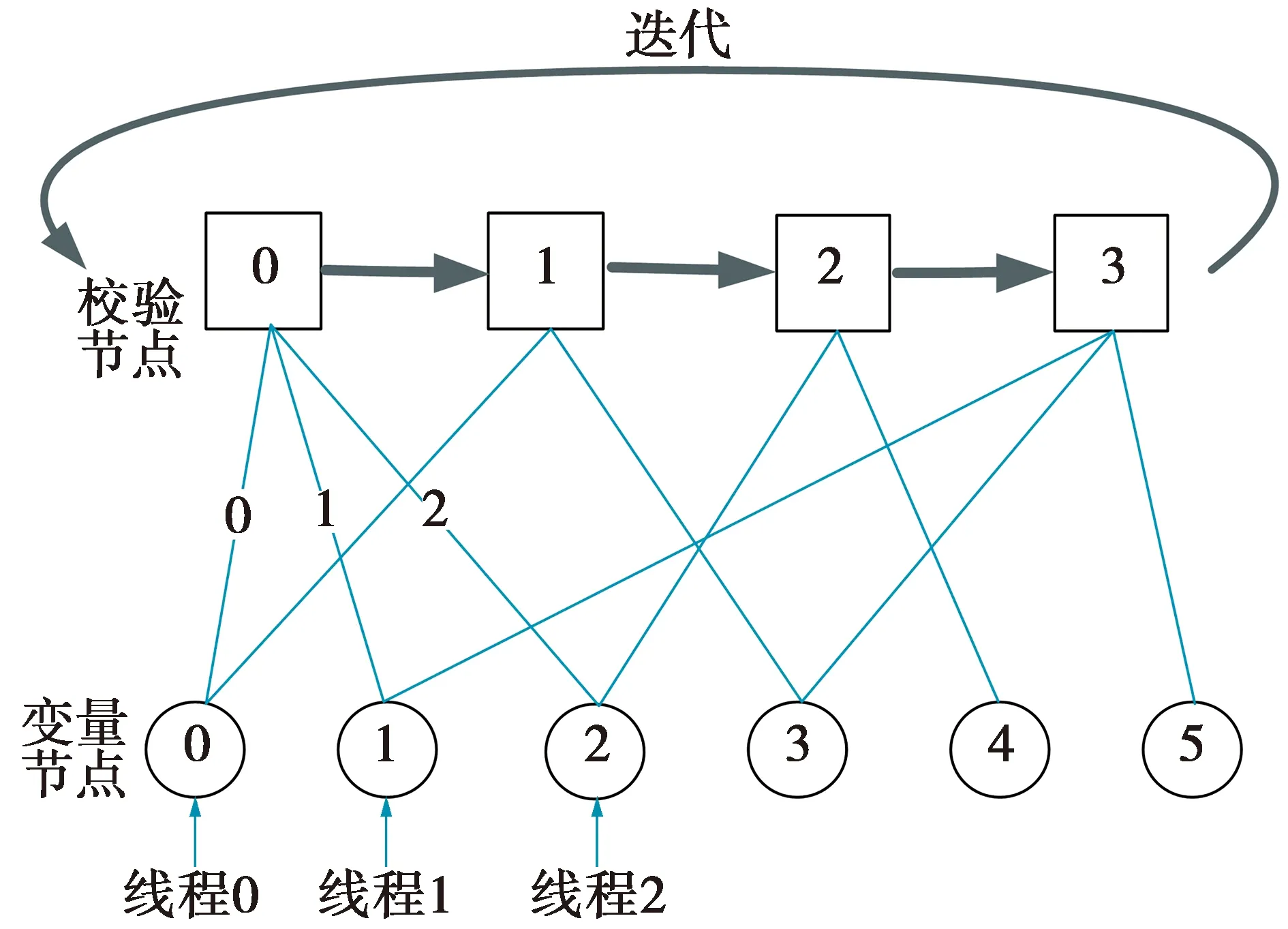
图3 节点并行译码方案Fig.3 Node parallel decoding scheme
Begin
映射th0、th1、th2→Q00、Q10、Q20
更新Q00、Q10、Q20
映射th0、th1、th2→R0
更新R0
映射th0、th1、th2→R00、R01、R02
更新R00、R01、R02
映射th0、th1、th2→Q0、Q1、Q2
更新Q0、Q1、Q2
End
2.3 核函数数据流
图4是本文提出的分层BP译码器核函数数据流的图示。
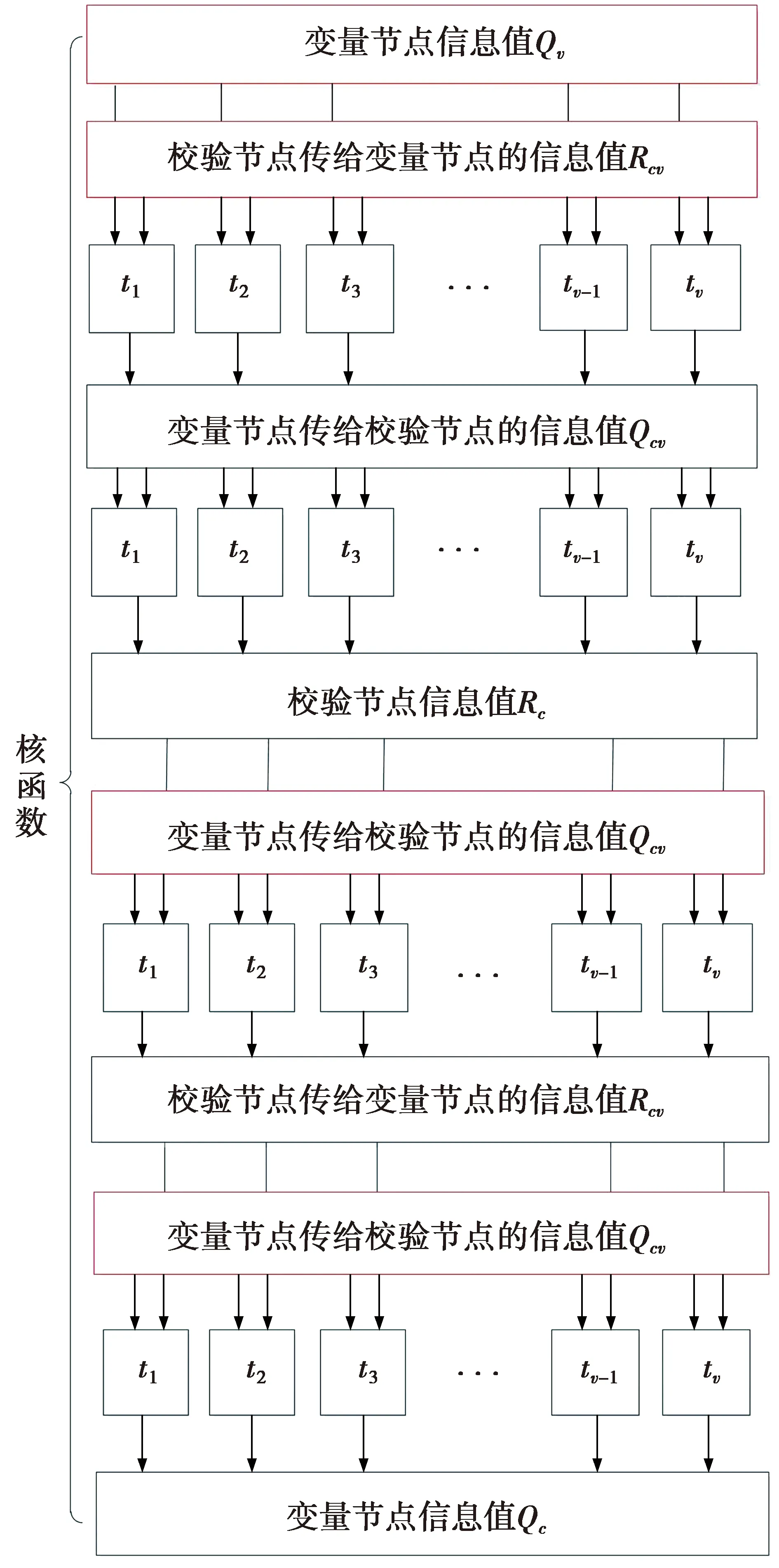
图4 核函数数据流Fig.4 Data flow of kernel
图4中,在一次迭代译码一个子矩阵时,进行纠错译码的核函数需要v个线程。v为该子矩阵的变量节点的个数,所有的数据处理都用了v个线程。所利用的线程对应变量节点个数,也对应由变量节点传递给校验节点或由校验节点传递给变量节点的消息个数,即2类节点的连接边的数量。因为线程对应变量节点而不是校验节点,码字的校验节点的度大于等于1,即子矩阵的变量节点数量大于等于校验节点的数量,所以增加了利用的线程的数量。在计算校验节点的信息时,v个线程也对应的计算出v个与变量节点对应的校验节点的LLR值,虽然这部分重复计算出校验节点的值,过多的存储校验节点的数据,但是在下一步需要找到对应的校验节点的值、计算由校验节点传递给变量节点的信息值时,不用再次索引。此外,线程不会进入不同的分支,不产生线程阻塞的情况。当在该次迭代译码至下一个子矩阵时,可以重复利用线程资源。
译码器初始化时,利用同变量节点数量相同的线程初始化变量节点的信息值。译码完所有子矩阵而且达到最大迭代次数后,也利用同变量节点数量相同的线程判决码字。这2部分没有在图4中画出。
2.4 优化
QC-LDPC码的奇偶校验矩阵是通过基矩阵扩展而来的[12],基矩阵包含了所有的矩阵信息。如图5,为了减少基矩阵存储占用的空间,将基矩阵内非‘-1’元素的移位量信息、非‘-1’元素对应的列的位置信息和基矩阵每一行的行重信息3个数据存放在同一变量内,减少变量内未利用的空位带来的存储空间消耗。

图5 基矩阵信息存储结构Fig.5 Structure of base matrix information storage
移位量的数值表示单位矩阵循环向右移的位数。元素‘-1’则表示该元素是一个全零矩阵。如果最大移位量为x,则用该变量从最高位开始的「lbx⎤位表示移位量,「x⎤表示大于等于x的最小整数;基矩阵若具有y列,即变量节点的个数为y,则用该变量内表示前一信息后的「lby⎤位表示基矩阵的列信息;基矩阵的最大校验节点的度若为z,则用该变量内表示前两类信息后的「lbz⎤位表示基矩阵对应行的行重。存储3个数据信息总共需要sum=「lbx⎤+「lby⎤+「lbz⎤位,所以存储数据的变量的位数需要大于等于sum。该变量通过位运算存储和读取矩阵信息,减少了基矩阵信息所占用的GPU存储空间,同样减少了数据拷贝模块需要拷贝的数据量,从而减少了译码总耗时。
Hbase=

(10)
(10)式是一个行数为4,列数为8的基矩阵,其扩展因子为100,即基矩阵中的每个元素可扩展为100×100的矩阵,该扩展后的奇偶校验矩阵行数为400,列数为800。基矩阵中的非‘-1’元素表示移位量,移位量的数值表示单位矩阵循环向右移动的位数,因为扩展因子为100,移位量的取值为0~99,最大移位量为99,26<99<27,所以至少用7位存储移位量信息的值。元素‘-1’则表示该元素是一个全零矩阵,不存储元素为‘-1’的基矩阵信息。基矩阵列数为8,列号由0至7,最大列号为7,22<7<23,所以用3位存储基矩阵中的非‘-1’元素所在的列号。基矩阵从第0行至第3行的行重分别为3、2、4、3,则最大行重为4,22=4<23,则需要3位存储基矩阵非‘-1’元素所在行的行重。存储这3个关键信息共需要:7+3+3=13位,一个short int型变量共16位,则一个short int型变量可以存下所有信息。通过对该变量进行位运算就可以存储和读取所需的基矩阵信息。此方法很大程度减少了GPU存储空间的开销,加快了主机端到GPU端的拷贝速度,而且简便的位运算不会增加运算的复杂度。
3 仿 真
本文以NVIDIA公司的TITAN Xp GPU为硬件平台,以CUDA 9.0 + Visual Studio 2017为编译器。表1为NVIDIA TITAN Xp GPU资源。寄存器/线程表示每条线程所分配到的寄存器个数。FLOPS为floating-point operations per second的缩写,表示每秒GPU所能够进行的浮点运算数目(每秒浮点运算量),T为tera的缩写,表示一万亿(=1012),TFLOPS则表示每秒一万亿次的浮点运算。

表1 GPU资源Tab.1 Resource of GPU
本文利用该GPU,同时译码纠错多个码字,实现了高速纠错译码,码字个数与译码速率对比如图6。由图6可以看出,译码器译码率为0.1,码长为106的码字,循环迭代50次时,不同码字数量对应的译码速率。从1个码字至16个码字,随着码字数量的增加,译码速度逐步增加。在同时译码16个码字时,内存读写的等待时间与更新消息的等待时间相同,译码器达到最大的译码速度。码字数量增加后,线程所需的寄存器资源短缺,数据存入全局内存,增加了内存读写的时间,所以在32个码字至64个码字时,译码器速度降低。随着码字数量的继续增加,降低了内存读取等待时间的影响,所以译码器在同时译码128个码字时,译码速度稍有增加。当超出128个码字时,数据量超出GPU的存储空间大小,译码器无法实现译码。

图6 码字个数与译码速率对比Fig.6 Comparison of the number of codewords and decoding speed
表2展示了本文提出的分层译码器译相同码长不同数量的连接边的码字的译码情况。码字连接边的数量越大,译码需要计算的信息值就越多。由表2中数据可看出:3个不同的码字,连接边的数量从上至下逐渐增加,计算的边的信息值的数量对应有所增加,即校验节点传递给变量节点的信息值的数量和变量节点传递给校验节点的信息值的数量有所增加。在相同码长相同扩展因子相同码字个数的条件下,码字连接的边的数量越大,消耗的译码时长越长,吞吐量越小。

表2 分层译码器译同码长不同数量的连接边的码字的译码速率Tab.2 Decoding speed of a layered decoder for decoding codewords with different numbers of connectededges of the same code length
图7展示了具有和不具有提前终止功能的分层译码器的性能。由图7可知,当该译码器译码率为0.1,码长为106,扩展因子为2 500的码字,且同时译16个码字时,不具有提前终止功能的分层译码器固定循环次数为50次,不论信噪比为多少,吞吐量都约为41.50 Mbit/s。而具有提前终止功能的分层译码器在不同的信噪比条件下需要的译码迭代次数不同,相应的吞吐量也不同。当信噪比小于0.161时,具有提前终止功能的分层译码器不仅需要执行50次译码迭代,判别是否译码成功还需要额外的消耗时间,所以具有提前终止功能的分层译码器速率略小于不具有提前终止功能的分层译码器,信噪比大于0.161后,前者需要的迭代次数逐渐减少,吞吐量逐渐增大,在信噪比为0.191时,译码速率达到了90.047 Mbit/s。因此,在传输环境较好,信噪比较大时,偏向于选择具有提前终止功能的译码器。
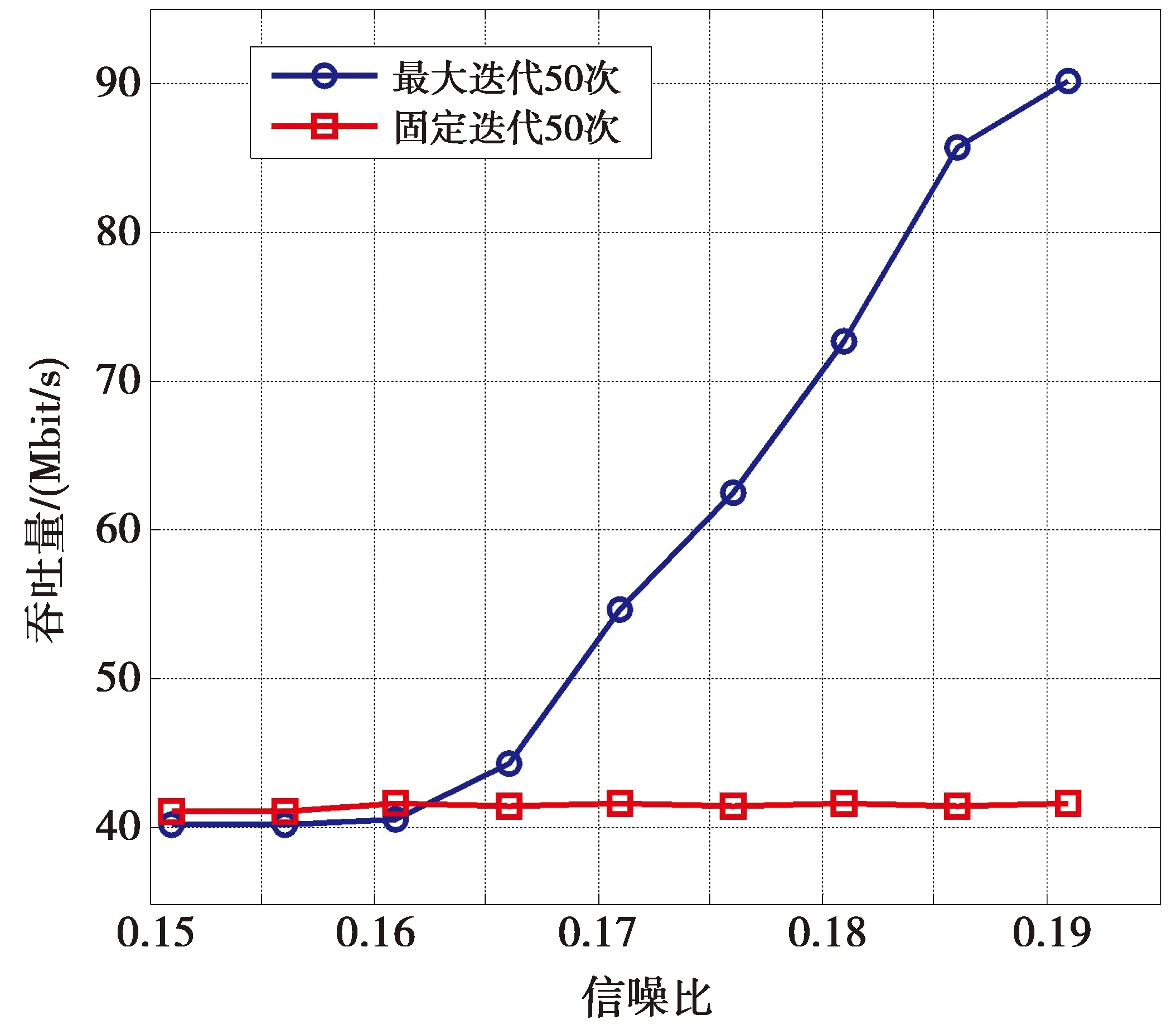
图7 具有/不具有提前终止功能的分层译码器译相同码字的译码速率Fig.7 Layered decoder with/without early termination decoding speed for the same codeword
表3为本文与文献[5-7]中实现的译码器性能对比。可以看出,文献[5]利用AMD Tahiti Graphics Processor实现的GPU译码器,在码长为220,码率为0.1时,吞吐量为7.10 Mbit/s,而文献[6]在同样的码长同样的码率下,引入提前终止条件,利用NVIDIA GeForce GTX 1080实现的GPU译码器达到了9.17 Mbit/s的译码速率;文献[7]利用NVIDIA TITAN Xp实现的GPU译码器通过减少迭代过程中度为1的变量节点的更新,译码速率达到了30.39 Mbit/s。本文采用与文献[7]同样的GPU硬件,采用分层BP译码算法,在码长为106,码率为0.1时,实现了41.50 Mbit/s的译码速率。

表3 译码器性能对比Tab.3 Decoder performance comparison
4 结 论
本文针对CV-QKD系统中低信噪比下传输超长码的特点,设计出一种基于分层置信传播译码(layered BP, LBP)算法的GPU译码器,该译码器译码具有较长码长的QC-LDPC码。本文采用收敛速度更快的分层置信传播译码算法,并且优化了核函数内线程的分配方式及QC-LDPC码基矩阵的存储方式,提升了译码速率。在码长为106,码率为0.1,循环50次,同时译16个码字的条件下,该译码器的速率达到了41.50 Mbit/s。该译码器的纠错译码速率比之前的文献所提到的速率提升10 Mbit/s左右,实现了更高效的密钥协商过程。虽然该译码器速率有提升,但是也存在缺点,例如,存储了多份同一个校验节点的LLR信息,同时译码的码字个数只有16个等等。通过Nsight还观察到该译码器受限于寄存器和warps。今后的工作将集中于减少不必要的信息存储,增加同时译码的码字个数和消除译码器受限因素。
猜你喜欢
现代计算机(2021年36期)2021-03-14 00:50:38
成都信息工程大学学报(2018年4期)2019-01-23 06:57:08
扬子江诗刊(2018年1期)2018-11-13 12:23:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
时代英语·高一(2017年5期)2017-11-14 21:39:42
新闻传播(2016年3期)2016-07-12 12:55:27
遥测遥控(2015年2期)2015-04-23 08:15:19
电视技术(2014年17期)2014-09-18 00:15:48
电测与仪表(2014年20期)2014-04-04 11:58:08
