
面向多异质用户的分布式动态频谱接入方法
2021-08-10 10:41苗本静潘志文尤肖虎
重庆邮电大学学报(自然科学版) 2021年4期
苗本静,张 余,潘志文,刘 楠,尤肖虎
(1.东南大学 移动通信国家重点实验室,南京 210096;2.国防科技大学 第六十三研究所,南京 210007;3.网络通信与安全紫金山实验室,南京 211100;4.中国人民解放军96941部队,北京 100089)
0 引 言
动态频谱接入作为共享无线电频谱、提高频谱利用效率的有效技术之一,近年来受到广泛关注。主用户(授权用户)和次用户(非授权用户)共存情况下,动态频谱共享方式可以分为频谱覆盖式(overlay)和频谱下垫式(underlay)2种接入模式。Overlay接入模式下,次用户只能接入主用户不使用的那部分授权频段[1],而underlay接入模式下,次用户的传输功率若在给定干扰水平之下,就可以和主用户共同使用频谱资源[2]。文献[4]提出了面向覆盖式和下垫式的频谱接入方案,并对其性能进行了分析,但只考虑了单个主用户和单个次用户存在的情况。文献[5]根据次用户的感知性能推导出次用户的传输功率界限,从而限制其对主用户的干扰,虽然保护了主用户,但是对次用户要求严格,忽视了次用户的需求。
动态频谱接入中用户获取的频谱信息准确程度,会影响次用户频谱接入决策的结果。强化学习不需要系统环境的先验知识,智能体仅需要通过观察环境的状态变化和采取动作后收到的奖励反馈来学习提高性能[6],比如,Q-learning算法就是不基于模型的典型强化学习算法,它通过Q函数值的更新来学习良好的策略,但在解决大的状态和动作空间问题上会呈现出不足,而结合了深度学习与Q-learning的Deep Q-Network(DQN)有更好的优势[7]。目前,强化学习在动态频谱接入技术中的应用研究已取得了一些进展,文献[8] 针对单用户接入问题,提出了一种基于深度强化学习的动态频谱接入方案,但没有考虑主次用户之间的干扰以及用户之间的碰撞问题;文献[9]提出的动态频谱接入方案没有考虑主用户的存在,因此没有将主次用户间的干扰作为约束,并且在多个用户接入信道情况下,成功传输与否仅取决于是否与其他次用户发生碰撞;文献[10]将强化学习与递归神经网络里的储层计算(reservoir computing,RC)相结合应用,提出了一种基于DQN算法的多用户分布式动态频谱接入方案,该方案中没有考虑次用户的服务质量(quality of service,QoS)需求问题。
基于对现有的研究成果分析发现,在认知无线电网络中,通常情况下,为了保证主用户在授权频段内的传输性能,相关研究更倾向于从保护主用户不受干扰的角度来限制次用户。然而在实际工程应用中,受传输环境、链路距离及次用户自身服务需求的影响,不同次用户对于频段的使用需求(异质用户)具有多样化。同时,利用DQN解决动态频谱接入问题的相关研究中,其研究对象多侧重于构建主次用户以overlay接入模式共享频谱的问题模型,对多异质用户的需求考虑也不够,造成了频谱利用不够充分。
因此,本文针对多个次用户存在不同QoS需求的动态频谱接入问题开展了研究,考虑了一个更加贴合实际的场景。场景中存在多个次用户,不同次用户存在不同的QoS需求,主次用户以underlay接入模式进行频谱共享,同时,为了保护主用户正常传输不受有害干扰,将设定限制条件来约束次用户的信道接入。综上所述,本文的主要贡献包括:
1)动态频谱接入场景中考虑存在多个异质次用户,这些异质次用户拥有不同的QoS需求,构建了面向underlay接入模式的频谱共享模型;
2)为了保护主用户不受有害干扰,同时满足次用户的QoS需求,对次用户成功接入信道的条件作出限定,即在强化学习奖励函数的设定上,既考虑次用户发生碰撞时获得不同奖励,又考虑对主用户造成干扰时有不同的奖励,次用户通过反馈的奖励值来不断完善接入策略;
3)本文引入Dueling DQN算法来解决在频谱环境信息未知的前提下的动态频谱接入问题,并将提出的Dueling DQN算法同随机接入算法、短视策略(myopic policy)算法进行仿真对比,结果表明,提出的Dueling DQN算法可以获得更好的性能。
1 系统模型
本文构建的动态频谱接入场景中,主用户网络有N个不重叠的供主用户单独使用的授权信道,K个次用户与N个主用户共享信道,其中N≥K,各次用户单独进行决策。为了减少用户间信息交互带来的开销,本文假设次用户无法获知任何系统先验信息,次用户间也不能进行信息交互。
为简化分析,每个时隙每个次用户只能选择1个信道接入,每个信道也只允许1个次用户接入,否则就视为发生碰撞。主、次用户间以underlay方式进行频谱共享,即只要次用户对主用户造成的干扰小于一定门限,就允许次用户同主用户在同一频段同时进行数据传输[11]。对于次用户的QoS需求,本文利用传输速率作为QoS的评价参数。
(1)


如果次用户i选择信道j作为传输信道,其发射功率Pi,j必须满足
(2)

(3)
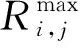
从“动与静”的经营来看,画家着力刻画人物清澈而敏锐的眼神,身上的光斑隐隐绰绰,与窗户外清风吹拂下的微颤枝叶遥相呼应。人们从作品中可以真切地感受到一种行将被打破的暂时静止。而在少女机敏眼神和窗外晓风拂叶的动感之间,穿插着桌椅、墙面、鲜桃、刀具和饰物等各类静物。物象自由分散在房间的各个角落,看似凌乱,实则是画家的一种经意安排。从画面背景可见,少女生活在俄国典型的中产阶级家庭,室内整洁明亮,却没有过度奢华的装饰,画家在此刻意突显的是充满阳光的少女形象。
2.6.1 Lut-PC的制备及纯化 采用溶剂挥发法制备Lut-PC。取Lut和卵磷脂(物质的量比为1∶1.2)置于四氢呋喃中。于45 ℃水浴条件下持续搅拌4 h至溶液体系变澄清。减压旋蒸除去有机溶剂,于真空干燥箱中过夜干燥后即得Lut-PC粗品,置于干燥器保存备用。取制备的Lut-PC粗品,采用二氯甲烷溶解,0.22 μm微孔滤膜滤过,减压旋蒸除去有机溶剂后即得高纯度Lut-PC。继续采用无水乙醇溶解,按相同操作,即得安全性更高的高纯度Lut-PC。
(4)
次用户i发送端通过Dueling DQN输出的不同动作对应的Q值,依照贪心策略独立地做出决策行动,选择接入某一个信道或者不接入任何信道。第i个次用户的动作表示为ai(t)∈{0,1,…,N},若ai(t)=n(n>0)表示次用户i择接入第n个信道。
本文研究的问题主要是如何在满足次用户速率需求、不对主用户产生有害干扰的同时,保证不与场景中其他次用户发生碰撞,提高所有次用户总的成功接入次数。
次用户i在t时刻的动作表示为ai(t),用a-i(t)表示除了次用户i以外的所有其他次用户的动作。
t时刻次用户i是否能够成功接入信道j取决于3个条件:


对峙培养结果表明:菌株CEH-ST79对马铃薯干腐病病原菌青9A-4-13和65B-2-6具有较强抑制活性,抑菌带宽度分别为0.28 cm和0.33 cm,对病原真菌青9A-5-2具有强抑制活性,抑菌带宽度为0.19 cm(表1)。
3)ai(t)≠a-i(t),不与其他次用户发生碰撞。
Dueling DQN算法的训练阶段中,在每个时隙,次用户利用历史状态作为长短期记忆网络层(long short term memory,LSTM)的输入。K个次用户的状态集表示为S={S1,S2,…,SK},其中,Si(1≤i≤K)代表次用户k的状态,是长度为2N+2的二进制矢量序列。Sk={a,m0,m1,…,mN,c1,c2,…,cN} ,其中,第1个二进制数值a表示传输结果的反馈信号,如果传输成功,此值为1,反之,传输失败或者没有选择任何信道,此值为0;mn∈{0,1}(0≤n≤N)表示次用户的信道选择结果,即若mn=1(1≤n≤N),意味着次用户选择了第n个信道接入,m0=1表示次用户没有选择任何信道;cn∈{0,1}(1≤n≤N)表示在所有次用户采取动作后,系统各信道被占用情况,即cn=1(1≤n≤N)表示第n个信道在此次接入过程中被某个次用户成功接入,作为传输信道占用。
2 Dueling DQN 算法
2.1 DQN
强化学习是智能体和环境不断进行信息交互的过程,其原理框图如图2。强化学习的目标是寻找一个策略使得累积折扣奖励R最大化。
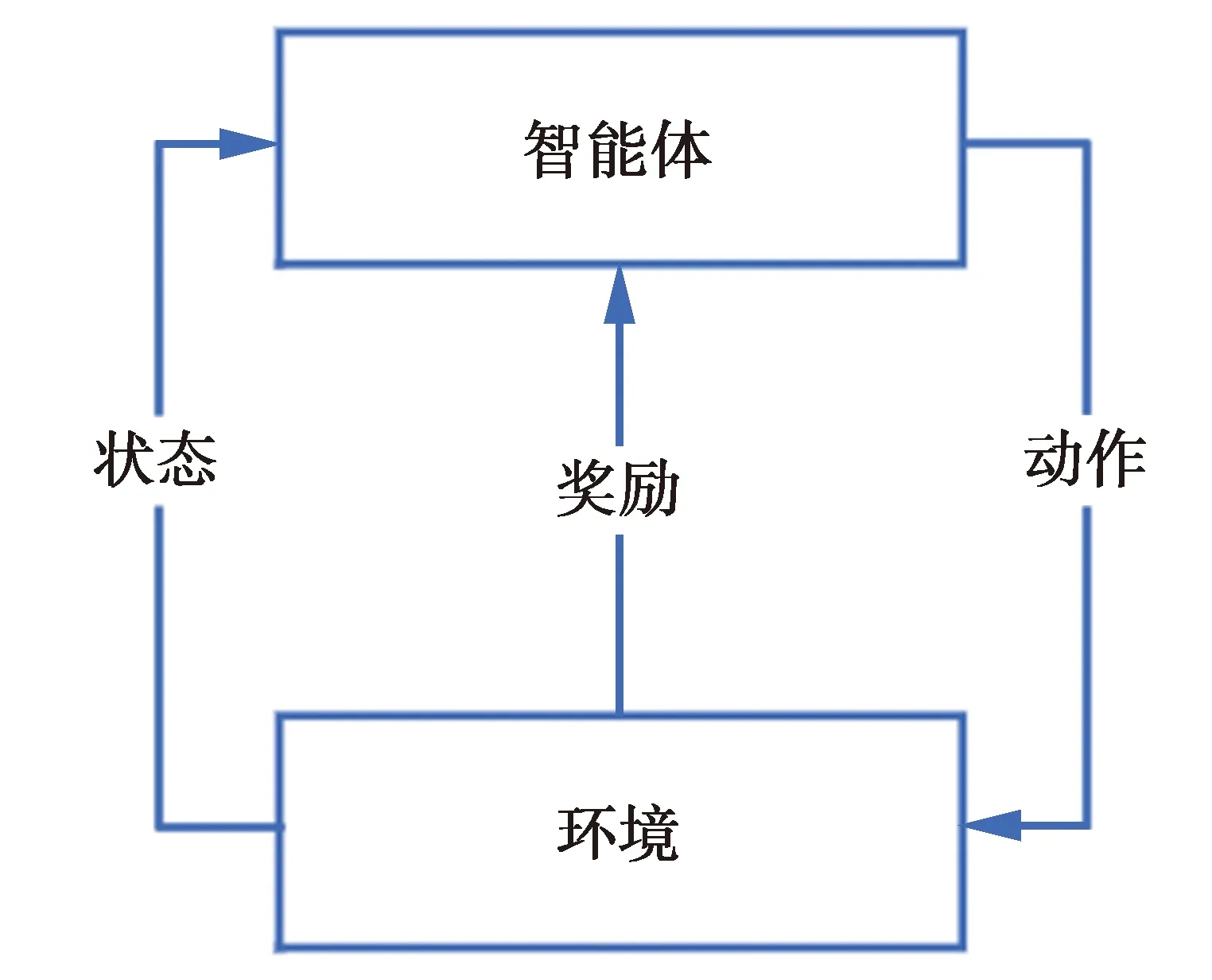
图2 强化学习原理框架Fig.2 Principle framework of reinforcement learning
(5)
(5)式中:γ为折扣因子;r(t+1)为t+1时刻的实时奖励。
宪法是国家的根本大法,是治国理政的总章程。我国自改革开放以来,在中国特色社会主义建设的伟大实践中,逐渐发展出一系列影响深远的宪法理论和制度,中国宪法学也由此获得长足发展。宪法学既从改革开放和法治实践中汲取源源不竭的发展动力,又运用自身的知识和理论为改革开放和法治中国建设提供坚实的学理支撑。
DQN是深度学习与Q-learning的结合,能够利用深度神经网络以状态作为输入,以Q值作为输出,高效地进行策略学习,尤其是高维、大状态空间问题。由于问题模型基于分布式环境,次用户之间不能进行信息交流,因此每一个次用户都独立进行学习,即每一个次用户通过DQN单独进行动作的选择。
在本文的动态频谱接入方案里,环境的状态S输入到深度Q网络中后,会得到在状态S下不同动作对应的动作值函数Q,次用户根据这些Q值依照贪心策略选择动作a。动作a会再输入环境,环境的状态会接着发生变化,并且环境会给出动作的奖励值,从而实现智能体和环境之间不断的信息交互。
2.2 Dueling DQN
Dueling DQN[13]是在DQN基础上优化了网络结构,即将Q网络分为价值函数子网络和优势函数子网络2部分,这有助于加快学习速度,使得收敛效果更好。价值函数V(s,ω,α)只与状态s有关,优势函数A(s,a,ω,β)不仅与状态s有关,也与动作a有关。因此,动作值函数Q(s,a,ω,α,β)的更新可由价值函数V(s,ω,α)和优势函数A(s,a,ω,β)组合表示,即
Q(s,a,ω,α,β)=V(s,ω,α)+
(6)
八五○农场的实测平均水田灌水量405 mm,降水补给外的补给为水田灌溉补给,补给量为107.4 mm,补给系数为26.5%。
本文Dueling DQN的架构如图3。
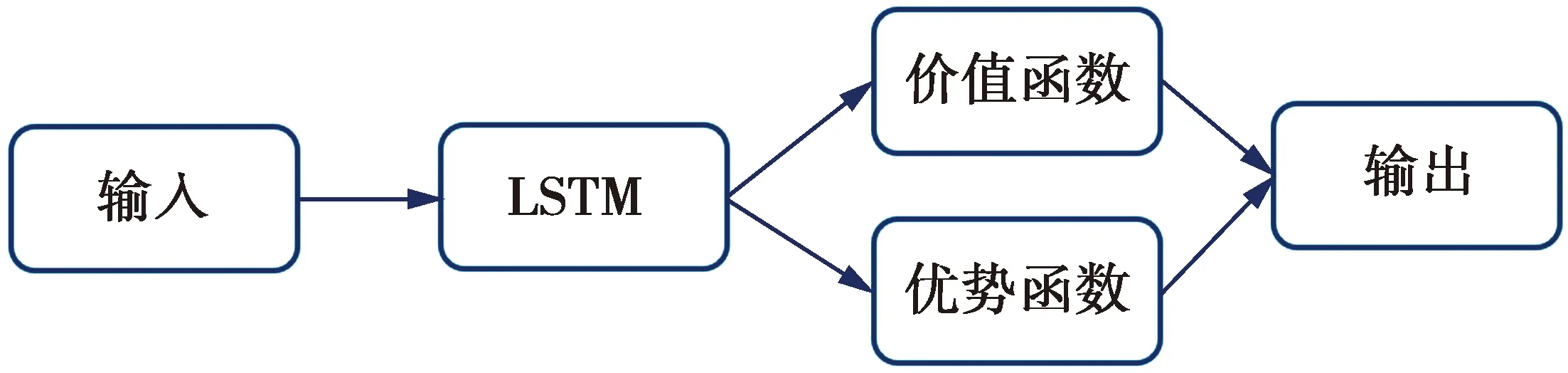
图3 Dueling DQN架构Fig.3 Architecture of the proposed Dueling DQN
3 基于Dueling DQN的动态频谱接入算法
本文构建的系统模型的目标是找到次用户的最优策略π=π1,π2,…,πK,使得系统内成功接入信道的次用户数最多,其中,πi(i∈K)表示次用户i的信道选择策略。
(4)式中:hki,j是主用户k发送端到次用户i接收端信道j的衰落因子;hii,j是次用户i发送端到其接收端信道j的衰落因子;σi,j2是次用户i接收端处信道j内的高斯噪声方差。

1)传输成功,获得的reward记为1,即满足在第1部分提到的3个条件,视为传输成功。
为了能够保护主用户不受有害干扰,同时满足次用户不同的QoS需求,减少次用户之间的碰撞,对奖励函数的设定如下。
2)传输失败,分为以下2种情况:与其他次用户发生碰撞,reward记为-2;次用户的QoS需求得不到满足(指次用户在信道上能获取的最大传输速率小于其最小传输速率需求),reward记为-1。由于多个次用户选择同一信道进行传输,次用户之间或次用户与主用户之间的干扰程度会加重,因此这里考虑次用户之间如果发生碰撞会收到更大的负奖励。
3)次用户未选择任何信道,reward记为0。
因此,第i个次用户获得的奖励可表示为
(7)

为把茅台酱香系列酒打造成为茅台集团“双轮驱动”战略发展的重要支撑点,2016年,茅台继续优化系列酒的战略布局,高屋建瓴出台“系列酒允许3年亏损”的一系列重磅政策,开启了酱香系列酒在销量和增幅上的一路狂奔。
算法实现的主要流程如下:
初始化:随机初始化经验池D,其容量为M;初始化深度Q网络及其环境;
循环遍历step=1,…,T:
1)初始化起始状态序列s,s中包含每个次用户的状态;
2)由于各次用户单独进行决策,记次用户i的起始状态为si;
3)将si输入到Q网络中,得到次用户在该状态下所有动作对应的Q值。用贪心策略在当前Q值中选择相应的动作ai;
4)在状态si执行动作ai:选择K个信道之一作为传输信道;
5)环境根据所有次用户的动作a,产生奖励r、传输结果的反馈信号,并得到新状态s′,在这个步骤中,每个次用户的奖励值ri依照(7)式得出;
6)将(s,a,r,s′)存入到经验池D中;
7)s=s′;
由文献[18]可知,在置信度为η0的条件下,应至少存在一次采样,使得选择出的b个点均为局内点。因此,可以得出最大循环次数m应该满足如下条件:
本文采用的Dueling DQN算法的输入是环境状态所对应的状态s,输出是在状态s下不同动作对应的动作价值函数Q。

10)迭代如果没有结束,返回2)。
4 仿真结果及分析
为验证本文提出的基于Dueling DQN的动态频谱接入方法的性能,本节将其与随机接入法[14]和短视策略法[15]进行仿真对比,其中,随机接入是次用户在不干扰主用户的前提下每次从可用信道中随机选择1个信道作为传输信道;短视策略是在已知信道信息前提下,次用户选择能获得最大当前回报值的动作,即选择一个能给自身带来最大奖励的信道作为传输信道。
假设每个主用户的传输速率在[1 Mbit/s, 5 Mbit/s]随机产生,信道带宽B=1 MHz,每个次用户的最小传输速率需求在[1 Mbit/s,5 Mbit/s]随机产生。学习率α=0.000 1,折扣因子γ=0.9,起止探索率分别为0.1和0.01,随着迭代过程的进行,探索率由0.1逐渐减小至0.01。采用的优化器为 Adam,经验池尺寸是10 000,参与训练的样本经验数为6,LSTM层包含128个神经元。
综合以上的特点,ES 可以有效地提升搜索效率,具有优秀的扩展能力以及数据操纵能力。因此,本文基于ES 进行校内全文搜索引擎的开发。
在齿轮所受各向分力已知的条件下,轴承轴向力由轴承类型、支承形式和安装方式等因素决定,根据已有文献,总结计算方法[7],[11-13]简述如下:
4.1 场景1
场景1为3个信道,2个次用户。采用以下2个参数作为衡量系统性能的指标。
1)次用户的累积碰撞次数:在0~T,每个时隙t次用户之间发生碰撞的次数记为Countt,累积碰撞次数定义为T时间段内,Countt之和。
某城市轨道交通运营线路的部分区段钢轨电位限制装置频繁动作,某些车站的钢轨电位限制装置甚至出现1 d 内动作上百次的情况。在排除了设备等自身故障的可能性后,维修人员最终将故障原因锁定在了“杂散电流”上。该线路运营时间较长,伴随着设施设备绝缘的老化,杂散电流腐蚀情况亦日渐突出,单纯依靠“堵”的方式已不能有效控制杂散电流的增长趋势。但该线路在杂散电流腐蚀防护系统设计时,仅设置了相应的监测设备,未设计排流柜(见图1)。
2)次用户的累积成功接入次数:在0~T,每个时隙次用户成功接入信道的次数记为Successt,累积成功接入次数定义为T时间段内,Successt之和。
考虑在3个信道,2个次用户场景下,次用户之间的碰撞次数及次用户成功接入次数的变化。仿真时,次用户共学习10万次,并分100个相等的学习阶段进行碰撞次数、成功接入次数的统计,即每学习1 000次统计一次碰撞次数和成功接入次数。图4给出了动态频谱接入碰撞次数的变化情况。
图4 碰撞次数的变化情况Fig.4 Changes in the number of collisions
从图4可以看出,利用Dueling DQN算法时,随着学习时间的增长,次用户之间的碰撞次数可以有效减少,且Dueling DQN方法中次用户之间的碰撞次数是3种方法中最少的。采用Dueling DQN算法时,从第10个学习阶段也即从第10 000个时隙左右开始收敛,次用户之间的碰撞次数可降为0,而随机接入算法和myopic policy算法中,次用户之间的碰撞次数一直居高不下,分别稳定在2 000次和500次左右。
图5给出了动态频谱接入累积成功次数。从图5可以看出,Dueling DQN算法的累积成功接入次数随着学习时间的增长而增加,直至收敛。并且,Dueling DQN算法在稳定时达到的累积成功接入次数比另外2种接入方法都要高。Myopic oplicy算法在初始上升幅度较快,这是因为myopic oplicy是在已知系统信道信息(如信道的干扰门限等)前提下设计接入策略,其能够快速找到满足自身QoS需求的信道。采用Dueling DQN算法时,从第10个学习阶段也即从第10 000个时隙左右开始收敛,次用户的成功接入次数稳定在2 000次左右,比随机接入算法和myopic oplicy算法分别高出约67%和98%。仿真结果上,Dueling DQN算法比另外2种算法更好的原因主要在于采用Dueling DQN算法时,次用户不断地与环境进行交互、学习,它是基于经验和学习的累积来不断更新接入策略。另外,由于在Dueling DQN算法奖励函数的设置上,发生碰撞或QoS需求得不到满足时会收到负奖励,因此随着学习过程的进行,次用户之间的碰撞会逐渐减少,且次用户选择到能满足自身QoS需求的信道的次数也会逐渐增多,从而成功接入的次数增多。

图5 成功接入次数的变化情况Fig.5 Changes in the number of successful accesses
4.2 场景2
场景2为信道数和次用户数分别固定的情况。在此场景下讨论的2种情况,Dueling DQN的仿真结果是利用训练好的模型得到的。为了便于分析次用户成功接入信道的情况,本文采用次用户的成功接入概率作为性能指标,在0~T时间内,成功接入概率定义为T时段内次用户累积成功接入次数在所有次用户总的接入次数中所占的百分比。
此外,选择不同的氧化物及硅酸盐等作为载体,在MoS2的形成过程中提供相应的成核位置,可制得大小适中的空心MoS2纳米微球。Xu等[18]选用氧化物TiO2作为载体提供成核位置,将负载其上,制备出粒径更小更均匀的新型MoS2空心微球(如图2所示)。Liu[19]等则选用硅酸盐矿物作为载体,通过水热法将MoS2负载在其上,制备出了双层的中空结构MoS2微球,该种微球不但具有良好的耐磨润滑性能,而且在摩擦使用寿命完成之后,可作为光催化剂用于有机废物的后处理。这些方法都为MoS2微球的制备及应用提供了新的思路,并在一定程度上提高了MoS2纳米微球的使用效率。
1)信道数固定,次用户数变化。
考虑信道数为8,次用户数分别为1,2,3,4,5,6,7,8时,次用户成功接入概率随着次用户数增加的变化情况如图6。从图6可以看出,3种算法的成功接入概率都随着次用户数的增加呈减小趋势,这是由于信道数不变、次用户数不断增加时,次用户之间的碰撞会相应地增多,那么既满足次用户QoS需求,又不与其他次用户发生碰撞的可供选择的信道就越来越少。因此,成功接入概率会逐渐下降。由仿真结果知道,3种算法对比之下,Dueling DQN接入方法下次用户的成功接入概率要高于其他2种接入方法。
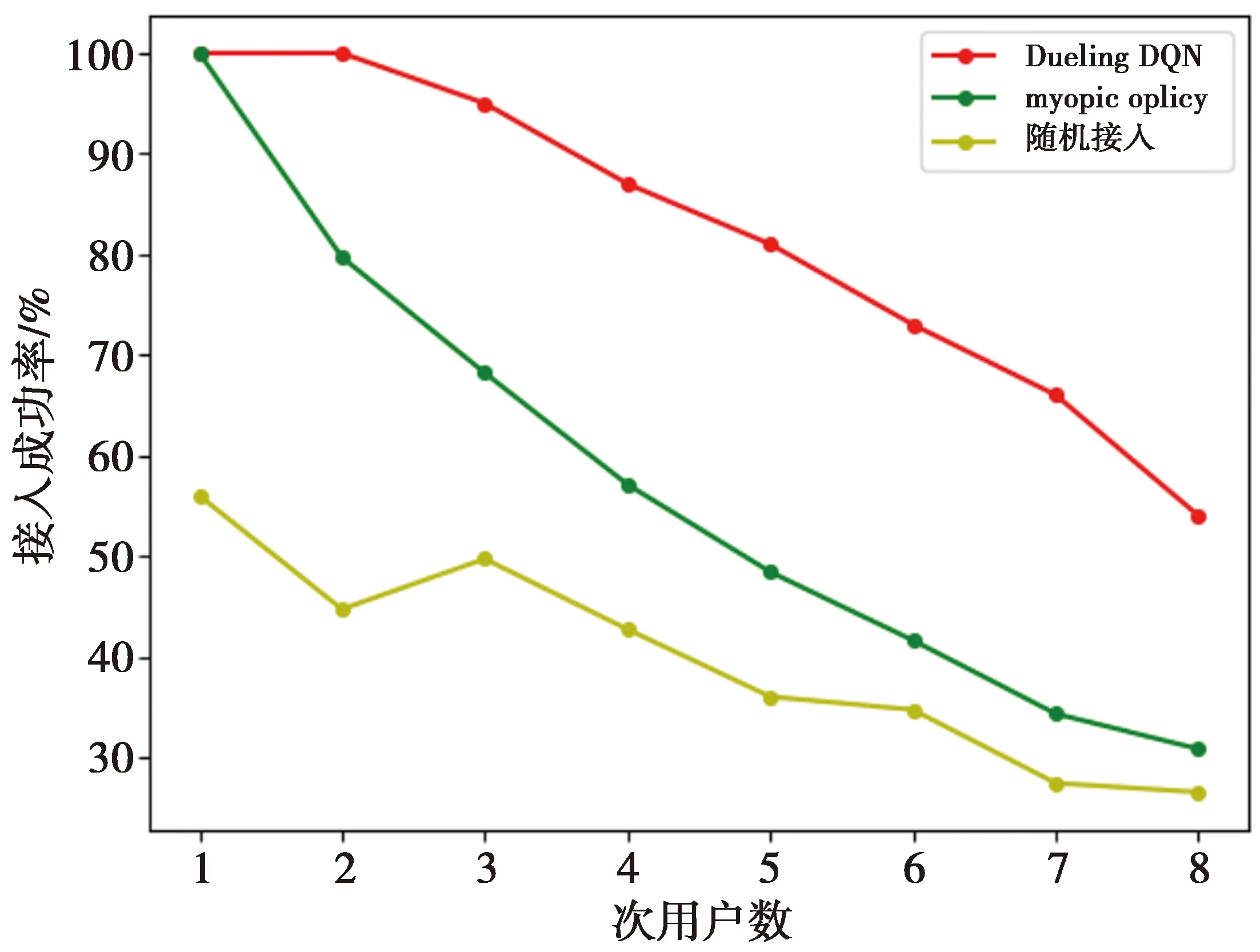
图6 信道数固定时的成功接入率比较Fig.6 Comparison of successful access rates whenthe number of channels is fixed
2)次用户数固定,信道数变化。
考虑次用户数为2,信道数分别为2,3,4,5,6,7,8时,次用户的成功接入概率随着信道数增加的变化情况如图7。由图7可以看出,Dueling DQN算法中当信道数增加到3个以后,次用户成功接入概率能达到100%,这是因为在利用训练好的Dueling DQN来选择信道时,次用户能够准确选择满足自身QoS需求的信道并且能不与其他次用户发生碰撞。Myopic policy算法中,成功接入概率随着信道数增加而增大,原因在于信道数越多,满足QoS需求的信道会相应增多,与其他次用户之间发生碰撞的机会也会相应减少。而随机接入算法的成功接入概率最小。总体看来,Dueling DQN方法要优于另外2种接入方法。
消极面子是指个体拥有自主的权利,有行事的自由,行为不受他人强制或干预。消极不礼貌策略指的是说话人攻击听话人的消极面子时使用的不礼貌策略。

图7 次用户数固定时的成功接入率比较Fig.7 Comparison of successful access rates when the number of secondary users is fixed
综上所述,基于Dueling DQN的动态频谱接入方法能够获得比基于随机接入或短视策略接入的动态频谱接入方法在降低次用户间碰撞次数和提高次用户成功接入次数上面表现出更优的性能,其碰撞次数将分别降低60%和90%,成功接入性能将分别提高30%和50%。
通过对四种燃料的组分分析可以看出,燃料的原料来源及制备工艺的差异对燃料的组分产生重大影响,根据组分分子的碳链长度和碳键特征,组分对比如表6所示。从组分的分子结构上看,复杂组分体系可以简化为饱和脂肪酸甲酯(如 C14:0 ~C24:0),不饱和脂肪酸甲酯(又分单不饱和脂肪酸甲酯如C16:1 ~ C22:1,二不饱和脂肪酸甲酯如C18:2)。
5 结 论
本文研究了面向不同需求的多次用户的分布式动态频谱接入策略,使多个次用户在没有系统信道先验信息及互相之间没有信息交互的前提下,选择既能满足自身QoS需求的信道,又能保证不与其他次用户发生碰撞,并且不对主用户产生有害干扰,实现了频谱资源的有效利用。仿真对比分析证明:本文提出的动态频谱接入方法比基于随机接入或短视策略接入的动态频谱接入方法在降低次用户间碰撞次数和提高次用户成功接入次数上面表现出更优的性能。
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
空间科学学报(2021年6期)2021-03-09
数学物理学报(2020年6期)2021-01-14
测控技术(2018年7期)2018-12-09
中学生数理化·中考版(2017年12期)2017-04-18
系统工程与电子技术(2016年7期)2016-08-21
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
现代防御技术(2014年6期)2014-02-28
