
基于YOLOv3与HOG特征融合的车辆检测算法
2021-08-06 10:15刘砚菊宋建辉孙晓南
沈阳理工大学学报 2021年2期
刘砚菊,秦 阳,宋建辉,孙晓南
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
近年来,随着生活水平的提高,全球各地汽车的数量飞速增长,相应的车辆管控也变得越来越困难。
传统的常用来进行目标检测的特征有Haar-like特征、LBP特征及方向梯度直方图HOG(Histogram of Oriented Gradients)特征。Haar-like特征只对线段或边缘这类的简单图形敏感,而且对于24×24的图形会产生160000多个特征矩阵,计算量过大。LBP特征用于纹理特征提取,对于图片纹理少的物体检测效果不理想。HOG特征通过计算和统计图像局部区域的梯度方向直方图来构成特征,具有很好的几何不变性和光照不变性。
目前,常见的可以对目标进行检测定位的深度学习模型有R-CNN[1-3]系列、SSD[4]系列、YOLO[5-7]系列等。R-CNN系列定位的准确率高,但其时效性与其他模型存在差距,不能实现实时定位。SSD模型运行速率会随着输入数据的增多而显著下降。因此,这两种模型均不能实现实时性。YOLO可以同时预测多个类别物体,在目标检测上可实现端到端,其最大的优势是速度快。YOLO舍弃了proposal和滑动窗口的方式训练网络,直接选用整图训练模型;这样做的好处在于可以更好地区分目标和背景区域。在目前的硬件条件下,YOLOv3实时检测的速度可以达到40~50FPS(每秒图像的传输帧数),完全满足实时检测模型在使用方面的速率需求。在准确性上,YOLO系列虽然略逊色于R-CNN、SSD等网络,但可在保证实时性的情况下,牺牲一定的检测速度增加网络层数,从而提高特定物体的检测准确率。
在以前的目标检测过程中,深度学习的目标检测与传统的目标检测都有各自的检测方法,两者互不掺杂。针对车辆检测中现存的误检错检以及检测率低的现象,本文吸收了YOLOv3与HOG特征的优点,将深度学习的目标检测方法与传统的目标检测方法结合起来,提出一种将YOLOv3与HOG特征融合的车辆实时检测模型;将该模型在自动驾驶数据集和自制数据集上进行测试,该模型在车辆检测方面相比经典模型具有更好的表现。
1 YOLOv3模型概述
YOLOv3的网络如图1所示。

图1 YOLOv3网络图
YOLOv3是Redmon在YOLOv2基础上改进的目标检测算法。YOLOv2所使用的网络结构为Darknet19,而YOLOv3对网络结构进行了改变,使用了Darknet53的网络结构,因其由24个卷积核为3×3的卷积层和23个卷积核为1×1的卷积层以及5个下采样层和一个全连接层组成,因此被命名为Darknet53。同时,由于层数的加深,在训练模型时可能会产生梯度爆炸的现象,为此在网络中加入了大量的残差块来避免此现象。
在Darknet53中每幅图要经过5次降维,降维后采用5次残差网络来强化网络特征提取能力并保持输入输出维度一致。采用残差网络是为保持通道维度不升高的情况下提取深度特征,同时,通过将先升维后降维的张量与输入张量相加的方式控制梯度变化,防止出现梯度爆炸。
2 模型设计
本文提出一种将HOG特征融入YOLOv3模型中的方法。主要方法是在YOLOv3网络对图片进行深度特征提取的同时,对图片提取HOG特征;将提取的HOG特征融入到YOLO层中,再对新的网络进行训练。
2.1 HOG特征预处理
HOG于2005 年在 CVPR(Conference on Computer Vision and Pattern Recognition)会议上被提出,在行人检测中取得了十分显著的效果[8]。HOG的核心思想是所检测的局部物体外形可以被光强梯度或边缘方向的分布所描述。HOG将整幅图像切割成小的连接区域(称为cells),每一个cell生成一个方向梯度直方图或cell中像素的边缘方向直方图,这些直方图的组合可构成特征描述器。为提高准确率,把这些局部直方图在图像的更大范围内进行对比度归一化;所采用的方法是:先计算各直方图在这个范围中的密度,然后根据这个密度对范围中的各个细胞单元做归一化。通过归一化操作,使HOG特征对光照或阴影下的目标有更好的检测效果。
在提取HOG特征时,为保证检测的准确率与实时性,先将图片变换为256×256的灰度图像,再用16×16的窗口对图像提取HOG特征,获得图片的8100×1维列特征向量。将此特征向量与1×8100维且数值全为1的行向量相乘,得到8100×8100维的矩阵;再用5×5的卷积核以5为滑动步长对此8100×8100维矩阵进行卷积处理,得到1620×1620的矩阵;然后再依次使用滑动步长为3、大小为3×3的卷积核对1620×1620的矩阵进行两次卷积操作,得到179×179维矩阵;最后使用步长为2、大小为2×2的卷积核对179×179维矩阵进行卷积,得到90×90维的特征矩阵。
2.2 HOG特征与YOLOv3融合
将处理后得到的90×90维特征先使用3×3的卷积核以3为滑动步长进行卷积,得到30×30×1的特征图;再用5×5的卷积核以1为滑动步长进行卷积,得到26×26×1的特征图。将26×26×1的特征图下采样,得到13×13×1的特征图;将26×26×1的特征图上采样,得到52×52×1的特征图。改进后的模型如图2所示。

图2 改进后的模型
由于YOLOv3是在13×13、26×26和52×52三尺度上进行检测,在网络中加入route层将13×13×1的特征图与原YOLOv3中尺度为13×13的YOLO层的前一个卷积层进行融合,将融合后的特征图输入到YOLO层进行处理。用同样的方法对经过HOG特征处理后得到的26×26×1特征图和52×52×1特征图进行处理。
2.3 Anchor的计算
Anchor box是从训练集的真实框中统计或聚类得到的几个不同尺寸的框,其目的是避免模型在训练时盲目寻找,有助于模型快速收敛。假设每个网格对应k个Anchor,则模型在训练时,只会在每一个网格附近找出这k种形状。
在YOLOv3中,采用3个尺度的特征图作为输出,特征图尺度分别为13×13、26×26、52×52,每个尺度对应3个Anchor,共有9个Anchor。特征图越小,其感受野越大,所以13×13的特征图上感受野最大,应该使用最大的Anchor,适合较大的目标检测,即尺寸为416×416的图片,除以32把尺度缩放到13×13下使用。中等的26×26特征图上由于其具有中等感受野,故应用中等的Anchor,适合检测中等大小的目标。较大的52×52特征图上由于其具有较小的感受野,故应用最小的Anchor,适合检测较小的目标。对于一张图片来说,先将其划分为K×K的网格,则每个尺度下得到的张量数为K×K[3×(4+1+C)],其中4为 Anchor的4维属性,即 Anchor的中心点坐标(x,y)及 Anchor的宽和高(w,h);1为置信度得分;C为需要预测的目标数量。由于融合了不同层的特征,因此能更好地描述高层到低层的信息。
YOLOv3使用K-means算法在训练集所有样本的真实框中聚类,得到具有代表性形状的宽高(维度聚类)。为了解最合适的Anchor数量,采用实验的方式,分别将不同数量的Anchor应用到模型;然后找出模型的复杂度和高召回率间最优的那组Anchor;最终得出9个最佳的Anchor。
为提高检测精度,本文使用K-means算法得到关于自制数据集的9组 Anchor为(15,20)、(25,42)、(35,37)、(35,41)、(63,53)、(69,98)、(95,90)、(135,176)、(275,256)。
2.4 GIOU-YOLOv3
交并比(Intersection Over Union,IOU)是目标检测中常用的指标,用来表示真实框A与预测框B间的相似度,图3是IOU不为0时真实框A与预测框B的位置示意图。

图3 IOU不为0时A与B位置图
IOU计算公式为
(1)
式中:A∩B代表A与B交集的面积,即图3中C区域的面积;A∪B代表A与B并集的面积,即图3中整个图形的面积。IOU指标能够很好解决两框相交时的重合度问题,但如果A与B间的距离明显小于A与C间的距离,此时IOU(A,B)与IOU(A,C)相等,都是0,则不能反映出AB距离与AC距离之间的区别。A、B、C位置如图4所示。

图4 IOU为0时真实框A与预测框B、C位置图
当IOU相等时,IOU值不能反映两个框的相交情况;而GIOU(Generalized Intersection over Union)值会随着两框相交的形状不同发生变化。除此之外,GIOU对尺度变换不敏感,因此可以解决尺度问题带来的误差。本文使用GIOU代替原始均方差损失函数来提高准确性。
GIOU的计算公式为
(2)
式中:A为真实框;B为预测框;D为包含真实框与预测框的最小矩形面积;C(A∪B)代表A与B交集的面积。
YOLOv3使用IOU作为损失函数时,会出现IOU值相同,但回归效果不相同的情况。为解决此问题,本文引入GIOU损失函数替代IOU损失函数,提升了算法检测的准确性。原YOLOv3损失函数表达式为
LOSSold=LOSSIOU+LOSSconf
(3)
本文将GIOU损失函数替换原始IOU损失函数,得新的损失函数为
LOSSnew=LOSSGIOU+LOSSconf
(4)
式中:LOSSIOU为 YOLOv3原始的IOU损失;LOSSconf为 YOLOv3 的分类损失函数;LOSSGIOU为GIOU损失。GIOU损失表达式为
LOSSGIOU=1-GIOU
(5)
3 实验与结果分析
3.1 实验环境及过程
本文实验配置环境为:Nvidia GTX 2080 Ti显卡;9.0版本的CUDA;3.4.1版本的OpenCV;Ubuntu16.04.2的操作系统。本实验首先通过聚类算法计算出Anchor值,再通过修改cfg文件实现网络搭建,最后通过Python语言修改train.py文件代码实现GIOU损失函数。由于本实验对网络结构进行了修改,因此不能使用预训练权重,需要生成自己的权重文件,并对其进行修改。
3.2 评价指标
本文选取平均精确度均值mAP及FPS作为目标检测的评价指标。以待测目标的召回率为横坐标,以待测目标的精确度为纵坐标,绘制一条P-R曲线。曲线下的面积为AP,对每一条PR曲线求AP得到的均值为mAP。精确率的计算公式见式(6);召回率的计算公式见式(7);AP的计算公式见式(8);mAP的计算公式见式(9);FPS的计算公式见式(10)。
(6)
(7)
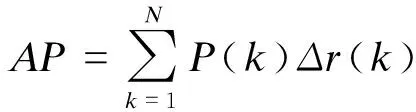
(8)
(9)
(10)
式中:TP为预测框预测正确且GIOU大于设定阈值的预测框数量;FP为预测框预测错误或预测正确但预测框与真实框间的GIOU小于阈值的预测框数量;FN为未被预测出来的真实框数量;N为所有图片的个数;P(k)为识别出k个图片时的精确率;Δr(k)为第k-1张图片到第k张图片召回率的变化;M为总检测类别数;Fcount为处理图片的数量;Etime为处理Fcount所用的时间。
3.3 标准数据集测试
本文使用调整好的网络对KITTI数据集进行训练。含有7481张图片,按照训练集∶验证集∶测试集=8∶1∶1的比例进行试验,得到训练集图像5984张、验证集图像749张、测试集图像748张。每个数据集中标签数量如表1所示,表头中数据集为数据集类别,图片数量为每个数据集的图片数,汽车、厢式货车、SUV、货车为标签在数据集中出现的次数。

表1 每个数据集中标签数量
表2是对R-CNN、Faster R-CNN、SSD300、SSD512、YOLOv3模型及本文提出的车辆目标检测模型在实时性和检测精度上的对比,其中汽车、厢式货车、SUV、货车所对应的数值为在不同算法下此类物体的AP值。
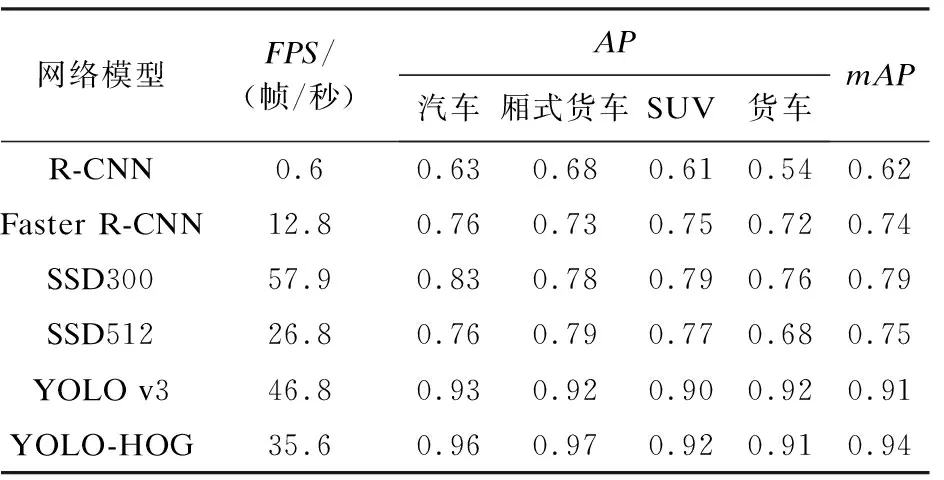
表2 KITTI数据集在不同网络中的实验结果
根据表2中的实验结果可以看出,R-CNN和Faster R-CNN的mAP与FPS普遍不高;SSD300与SSD512有着较高的FPS,但mAP值低于YOLOv3;YOLOv3算法实时性与检测准确率都很高,FPS为46.8,mAP为0.91。YOLO-HOG在传统的YOLOv3网络基础上加入了HOG特征,使得权重文件中含有方向梯度的特性,从而使检测准确率进一步提升,经过多次检测实验,mAP值稳定在0.94。在实时性上,由于YOLO-HOG网络中融入了HOG特征,所以在每一个YOLO层中输入的数据都增加了8100维,且增加了对应的残差网络,算法复杂度提高,FPS保持在35左右,可实现实时性。
改进的YOLOv3网络由于加入了HOG特征,强化了对特征提取效果,使得定位精度进一步提高,部分效果如图5与图6所示。
通过图5可以看到,YOLOv3将图片中间的VAN错认成SUV,而改进后的模型没有发生这种情况;改进后的模型在预测过程中更能避免误判的发生。在图6a和图6b两图中,标签上的类别名代表识别成样本的类别;由图6可以看出,在目标检测上,改进后的网络相比于原始网络置信度降低了,但是识别更加准确。

图5 两种模型检测效果对比图-1

图6 两种模型检测效果对比图-2
通过 KITTI 的实验可以发现,对于图像中遮挡部分少的车辆,YOLOv3 与YOLO-HOG均具有较好的检测能力,YOLO-HOG在复杂道路场景下更易避免错判、误判等情况的发生。
3.4 多种车辆数据集测试
通过整合多种不同数据集,对车辆的类型进行重新汇总与扩充,自制数据集包含4种车辆类型,从VOC2007-VOC2015[9]、KITTI[10]、UA-Detrac[11]以及自主采集等多个渠道进行获取并对训练集的车辆进行手动标注,最终获得12536张数据图像、49000个车辆数据用于训练和测试。表3为本文算法在自制数据集与KITTI数据集上检测实验的对比。

表3 本文算法在自制和KITTI数据集中的检测结果
由表3中数据可以看出,随着数据集中数据的增多,mAP值略有提高。每秒传输帧数方面,由于增加数据集所增加的运算量远低于提高模型复杂度所增加的运算量,因此检测速度基本保持不变。
4 结束语
为解决复杂无约束场景下车辆目标定位及相关信息高效识别的问题,提出了一种基于YOLOv3融合HOG特征的车辆定位识别模型 YOLO-HOG。该模型将HOG特征融入YOLOv3模型中,使训练出的权重文件同时含有HOG特征和深度学习特征,提升了最终的预测精度。同时,由于使用K-means算法重新计算Anchor,使得到的Anchor值符合本文算法,提升了预测精度。
实验结果表明,该模型不但在 KITTI 数据集的测试上拥有较好的定位精度和运算速度,并且在多种车辆的目标检测任务上也有良好表现。
猜你喜欢
黄河之声(2022年10期)2022-09-27
农业工程学报(2022年12期)2022-09-09
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
初中生世界·七年级(2019年5期)2019-06-22
