
结合Sentinel-2影像和特征优选模型提取大豆种植区
2021-08-04 05:49张东彦杨玉莹黄林生
农业工程学报 2021年9期
张东彦,杨玉莹,黄林生,杨 琦,梁 栋, 佘 宝,2※,洪 琪,姜 飞
(1. 安徽大学农业生态大数据分析与应用技术国家地方联合工程研究中心,合肥 230601; 2. 安徽理工大学空间信息与测绘工程学院,淮南 232001;3. 宿州学院信息工程学院,宿州 234000)
0 引言
大豆是高蛋白食品、牲畜饲料的主要原料以及食用油的重要来源,在世界粮食生产中占有重要地位[1]。中国是世界大豆主产国之一,2019年中国的大豆种植面积达842.6万hm2,位居全球第5位(http://www.fao.org/faostat/ en/#data)。然而国内大豆产量远远无法满足生产生活需求, 2019年大豆的进口依赖度高达83.03%[2],因此需要扩大种植规模,鼓励大豆生产。及时、准确地获取大豆种植面积及其空间分布对于长势监测、灾害评估等具有重要意义。以传统的农业调查方式来估算大豆种植面积通常费时费力,易受主观因素影响,结果数据亦无法提供空间分布信息。遥感技术可以更及时、高效和客观地实现大规模的农作物种植面积监测,且成本低廉[3]。
MODIS数据具有较高的时间和光谱分辨率,适合大尺度的农作物遥感监测研究[4-5]。国内外一些研究表明基于MODIS NDVI/EVI时间序列数据生成的作物关键生育期的物候参数在农作物遥感识别中具有很好的表现[6-9],如Liu等[10]利用随机森林方法(Random Forest,RF)提取位于美国玉米带的大豆和玉米,结果显示基于MODIS时间序列数据获取的38个物候指标在大豆和玉米的识别中具有一定优势。然而,由于不利天气及传感器工作状态等原因,无法保证时间序列数据的连续性,导致现实中的物候参数可能难以完整获取,仅采用物候信息来识别大豆具有较大的挑战。近年来,卫星传感器正逐步向高空间分辨率和多光谱的方向发展,它所增加的红边和短波红外波段在大豆种植区遥感提取中展现出了巨大潜力[11-12]。Zhong等[13]发现在物候指标的基础上,短波红外波段(MODIS波段6,1 628~1 652 nm)的加入可以显著提高大豆和玉米的分离度。刘佳等[14]以黑龙江省五大连池中南部为研究区,利用最大似然方法探究红边和短波红外波段对于大豆和玉米的识别能力,结果表明引入RapidEye卫星的红边波段后,两种作物的总体识别精度提高了7.4%;且多时相Landsat-8 OLI影像可以弥补因缺少短波红外波段而产生的制图精度偏低的不足。Yin等[15]采用RF算法识别中国三江平原地区的大豆、玉米和水稻3种农作物,并提出Sentinel-2数据的短波红外波段可以很好地区分大豆和玉米。植被指数主要基于植被对于红光波段的强吸收和近红外波段的高反射而建立,它可以辅助光谱特征有效地提高农作物的识别精度[16]。da Silva等[17]基于Google Earth Engine平台采用时间序列多光谱数据生成的物候特征和植被指数几乎可以实现巴西中西部地区内大豆种植面积的实时监测。黄健熙等[18]认为多时相GF-1 WFV数据生成的归一化植被指数(Normalized Difference Vegetation Index,NDVI)、归一化水分指数(Normalized Difference Water Index,NDWI)和宽动态范围植被指数(Wide Dynamic Range Vegetation Index,WDRVI)在大豆和玉米识别中表现突出,且RF的提取效果优于支持向量机和最大似然方法。此外,合成孔径雷达(Synthetic Aperture Radar,SAR)数据因其具有较强的云层穿透能力以及全天时、全天候的特点而备受关注[19]。光学影像和SAR数据的协同作用对于区分不同作物具有重要意义,如Ajadi等[20]基于光学影像与Sentinel-1数据的VH极化成功获取了巴西两个生长季内的大豆种植规模和空间分布。
尽管已有不少学者开展了大豆种植区遥感提取的相关研究,但目前的研究多集中在机械化程度高、农田分布规整和大豆种植集中连片的大规模产区,例如美国、巴西、阿根廷以及中国东北地区[10-14,21]。对于以散户种植为主、种植结构较为复杂的地处中国黄淮海大豆主产区的安徽省鲜有关注。《2020年中国农村统计年鉴》的数据显示2019年安徽省的大豆种植面积为63.624万hm2,仅次于黑龙江省和内蒙古自治区,位居全国第3。该地区天气状况多变,云覆盖频繁,农田景观破碎,作物混杂种植严重,给其遥感识别带来了巨大挑战。因此,迫切需要探索出一套适合此类地区的大豆遥感识别方法。合适的卫星影像数据是应用遥感技术提取农作物种植区的基础。目前,应用广泛的MODIS、Landsat和GF-1WFV数据在空间分辨率、重访周期、工作波段设置方面具有各自的局限性。本研究先前的工作已经表明Sentinel-2数据适合种植结构复杂地区的大豆遥感提取,且大豆结荚早期更有利于大豆识别[22]。因此,针对目前大豆遥感识别研究存在的不足,本文基于大豆识别的优选时相(大豆结荚早期)的Sentinel-2影像,在田间调查数据和无人机影像的支持下,探讨ReliefF特征权重评估方法结合多种机器学习方法在皖北地区大豆制图中的表现,以期探索形成一套合理的大豆种植区提取方法。
1 研究区与数据
1.1 研究区概况
涡阳县位于安徽省北部(33°27′~33°47′N,115°53′~116°33′E),是中国黄淮海地区重要的大豆主产地,其大豆种植规模常年超过7.2万hm2,在安徽省所有县级行政单位中一直保持首位。该县的地形以平原为主,平均海拔为29.5 m,属暖温带半湿润季风气候,年平均气温15.1 ℃,年平均降雨量851.6 mm左右,历年平均日照时数为2 015.7 h,适合大豆、玉米、高粱、红薯、芝麻和中药材等多种作物的生长。淮河的一级支流涡河横穿该县中部,涡河两岸呈现出截然不同的作物种植格局。涡河以北地区以大豆和玉米交错种植为主,大豆占比明显高于玉米,而涡河以南玉米规模占据绝对优势。本文选取位于涡河北部的龙山和青疃2个典型镇级行政单位作为研究区(图1)。该地区的大豆通常在6月中下旬播种,8月中旬开始结荚,并于当年的9月末至10月初收获(中国气象数据网http://data.cma.cn/)。
1.2 数据获取
1.2.1 Sentinel-2数据
Sentinel-2是多光谱成像卫星星座,拥有2A和2B两颗相同的卫星,其空间分辨率最高可达10 m,双星协同观测可使重访周期缩短至5 d,有利于获取作物的关键生育期图像并能展现更丰富的田间地块细节。它携带一台多光谱成像仪(Multiple Spectral Instrument,MSI),具有 13个光谱波段,覆盖可见光、近红外到短波红外波谱范围(443~2 190 nm)[23],可实现对地表高频次、持续和动态监测。此外,Sentinel-2还提供了丰富的工作波段,是唯一一个在红边范围内设置3个工作波段的卫星传感器,为农作物精细制图奠定了有利基础。本文通过ESA Copernicus Open Access Hub(http://scihub.coperni cus.eu/)下载了2019年8月18日(大豆结荚早期)的Sentinel-2B LIC级数据进行后续大豆种植区提取研究。
1.2.2 UAV图像
研究区内布设了6个大小为1 km×1 km的样方(图1)来评估基于卫星影像的大豆种植区提取效果。样方的设置在空间上尽可能均匀分布且其内包含的人工地物占比尽可能小,且研究区内空间异质性相对较小,样方具有一定代表性。本文利用DJI Phantom4 Pro无人机,于2019年9月7-9日期间获取了6个样方的航拍影像。无人机平台搭载了视场角为84°、有效像素2 000万的1英寸CMOS相机来获取RGB真彩色图像。无人机飞行期间天气良好,飞行航高均设为200 m,航向和旁向重叠率均设为80%,影像对应的地面分辨率约为6 cm。此外,为了确保获取的无人机影像具有更高的地理定位精度,每个样方都布设了辨识度较高的4个像控点,并且采用RTK(华测i70)测量每个像控点的地理坐标。
1.2.3 地面调查数据
为了充分掌握样方内地物类型及典型其样本的空间位置,在获取无人机影像的同时,同步开展了地面查工作。调查时采用手持GPS(Trimble Geo7X, USA)测量代表性地块的经纬度坐标并记录相应的植被类型。此次调查共获取地面实测点212个,其中大豆、玉米、高粱、裸土和其他植被的样本点个数分别为91、79、13、5和24。
2 研究方法
本文首先对Sentinel-2卫星影像和UAV图像进行预处理。为使得优选得到的遥感判别特征更具有针对性,首先构建决策树筛选规则剔除非农作物分布区域,然后针对田间植被构建 ReliefF-RF、ReliefF-BPNN、ReliefF-SVM组合模型筛选出对于大豆识别最有效的特征,并采用混淆矩阵方法评估3种模型在大豆制图中的表现,确定最优提取模型。
2.1 数据预处理
Sentinel-2数据是经过辐射定标和正射校正的Level-1C级大气顶(Top of Atmosphere,TOA)表观反射率产品。因此,只需再对其进行大气校正,便可得到大气底部(Bottom of Atmosphere,BOA)反射率。该数据的大气校正借助ESA提供的Sen2cor(http://step.esa. int/main/third-party-plugins-2/sen2cor/)来完成。本文采用空间分辨率为10 m的4个波段和20 m的6个波段开展大豆种植区提取(表1)。为保证各波段空间分辨率的一致性,在Sentinel Application Platform (SNAP) 平台下,使用双线性内插法将分辨率为20 m的波段重采样至10 m并输出为ENVI支持的img存储格式。最后,利用ENVI 5.3进行波段合成并采用涡阳县乡镇级矢量行政边界对图像进行裁剪,以获取覆盖完整研究区的影像。
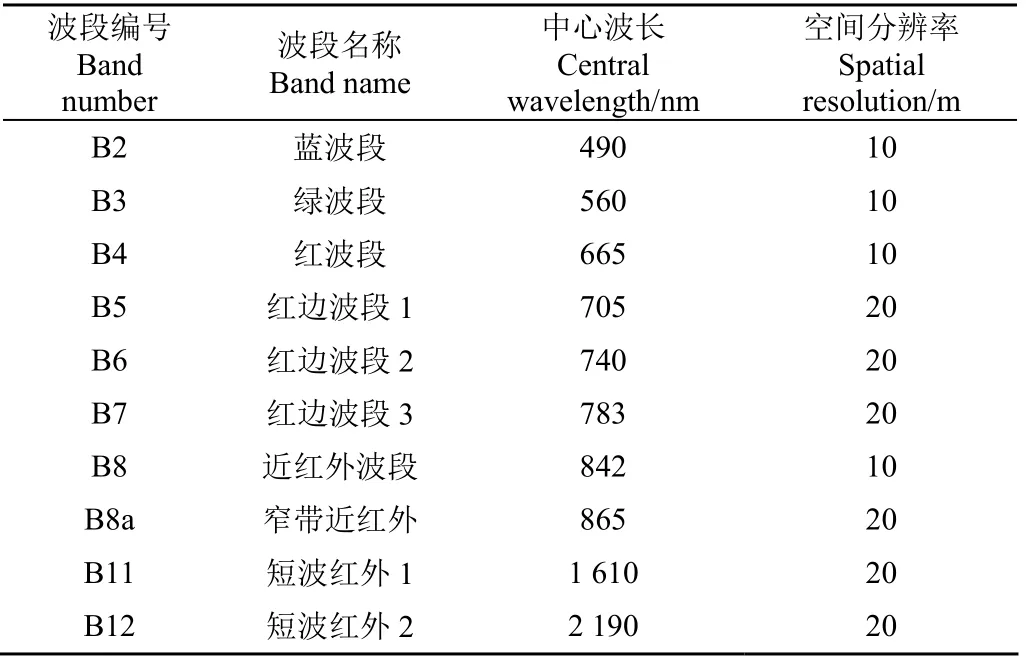
表1 文中所采用的Sentinel-2的10个光谱波段描述 Table 1 Description of the 10 spectral bands of Sentinel-2 employed in this study
对于无人机所获得的航拍影像,首先对数据进行质量检查,剔除成像质量相对略差的影像。将筛选后的影像导入Context Capture Center(version 4.4.9)中自动完成影像匹配、空中三角测量和不规则三角网模型的构建进而生成密集点云。为保证图像的空间定位精度,需要导入像控点坐标,然后基于点云数据生成三维模型,并通过该模型获取数字正射影像(Digital Orthophoto Map,DOM)。最后,使用Global Mapper 14对DOM影像进行拼接。
2.2 非农作物地物类型的剔除
基于Sentinel-2影像,本文采用分层逐级提取策略,首先借助归一化建筑指数(Normalized Difference Building Index,NDBI)[24]、改进的归一化水体指数(Modified Normalized Difference Water Index,MNDWI)[25]以及近红外波段反射率构建决策树筛选规则剔除人工地物(如建筑、道路等)、水体、裸土和林地等非农作物分布区域。
式中R3、R8和R11分别代表绿波段(B3)、近红外波段(B8)和短波红外波段(B11)的反射率值。为了进一步增强结果的可信度,本文借助2017年FROM-GLC10全球土地利用产品[26](http://data.ess.tsinghua.edu.cn/)提供的耕地分布(类型编号10,空间分辨率10 m)作为决策树的附加判别条件,以进一步筛除结果中可能存在的部分非耕地像元。最后基于生成的掩膜文件,对研究区影像进行掩膜处理得到农田植被的总体分布,再执行后续的大豆种植区提取。
2.3 大豆遥感识别模型的构建
2.3.1 机器学习方法
RF算法在遥感制图领域应用广泛,其抗噪能力强,运算速度快,预测准确率高,且能有效抑制过拟合。研究表明,通常情况下RF算法仅需要设置2个关键的用户参数,并且在默认参数下即可取得令人满意的结果[27]。鉴于此,本文的参数保持默认设置即分支节点的特征数为参与分类的特征总数的平方根,决策树的数量为100。
BP神经网络(Back-Propagation Neural Network, BPNN)具有较强的非线性映射能力和良好的网络容错性,可以很好地解决现实场景中非线性建模问题[28]。在农业遥感领域,BPNN被广泛用于土地覆盖分类和植被理化参数定量反演模型的构建。为获得较好的大豆提取效果,通过多次试验探究,本文采用单隐含层BPNN,迭代次数设置为1 000,学习率设置为0.02,训练目标的最小误差为0.001。
支持向量机(Support Vector Machine,SVM)的基本原理是通过构造最优分割超平面,以此实现训练样本分类。已有研究表明径向基核函数(Radial Basis Function,RBF)更适用于区分不同类型的农作物[29]。因此,本研究选择RBF作为分类模型中的核函数来提取大豆种植区。该核函数的Gamma取所用卫星影像波段数的倒数;分类阈值设为0,其他参数保持默认。
2.3.2 候选特征变量
传统意义上通常采用波段反射率作为指定地物的遥感判别特征,然而现实中可能并非所有工作波段对于大豆识别均足够有效,因此本文考虑加入一些扩展特征如多种植被指数参与大豆种植区提取,评估各个扩展特征在大豆识别中的表现。基于Sentinel-2影像,选取了包括9个植被指数(表2)和原始10个波段反射率在内的共19个候选特征因子来执行大豆遥感识别,并且在此基础上对候选特征进行优选。本文将这些植被指数和原始波段一起,统称为“特征”。
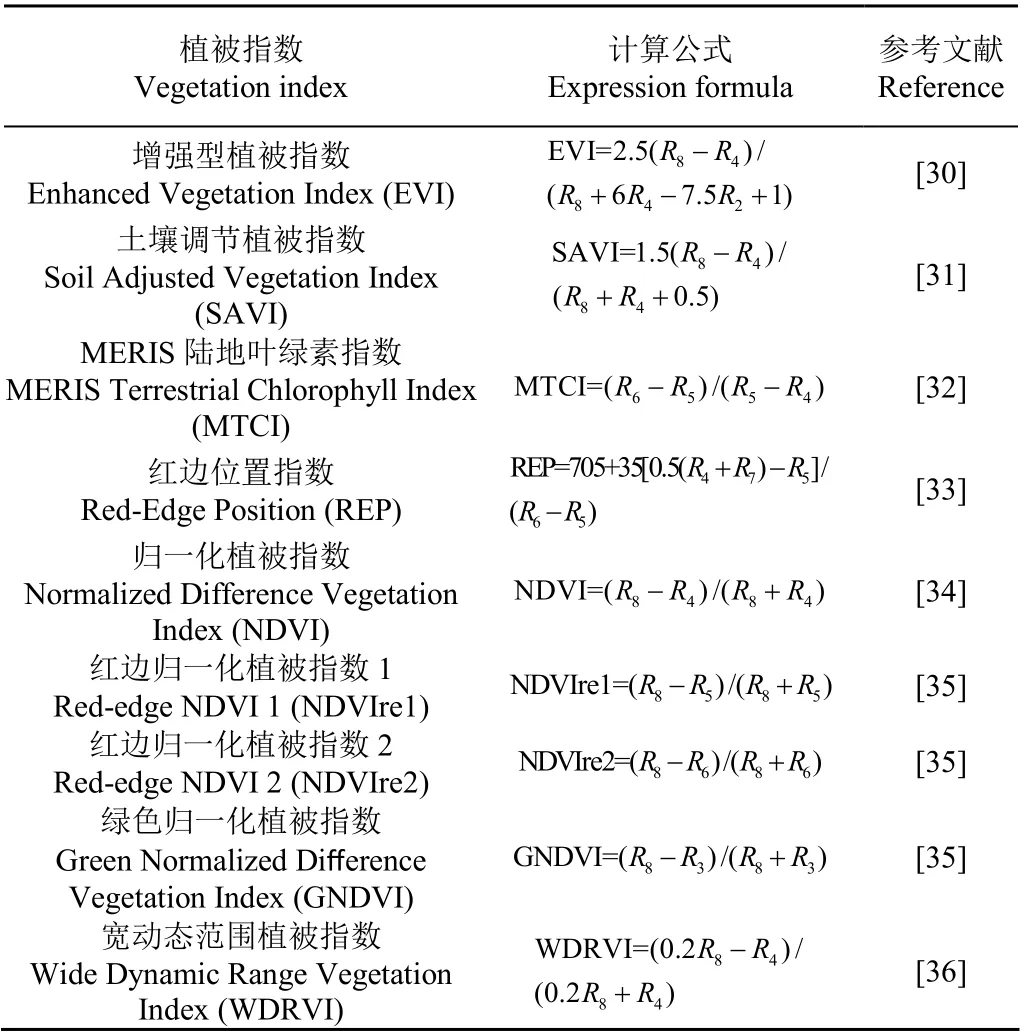
表2 本文所选用的遥感植被指数 Table 2 Vegetation indices employed in this paper
2.3.3 特征变量重要性评估
ReliefF算法的核心思想是通过计算类别之间的假设间隔对候选特征因子进行分类贡献度评价。若特征集A中的某个特征使得异类样本间的距离大于同类样本,说明此特征有利于分类,故增加其权重值;反之则降低其权重。最后将n次计算结果的均值作为每个特征的最终权重,计算公式如下[37]:
式中ω(Ai)表示特征i的权重值,为k个同类最近邻样本与R样本在特征上的距离之和,代表k个异类最近邻样本与样本R在特征i上的距离之和。
本文基于掩膜后的图像,从4种田间作物类型(大豆、玉米、高粱、其他)中选取近2 000个样本进行特征敏感性分析。由于该算法固有的随机性可能导致权重评估结果具有一定的不确定性,本文取20次运算结果的平均值作为各个特征的最终权重值。
2.3.4 不同模型下的特征子集优选
在特征权重评估的基础上,判断特征子集的最佳维度是实现特征优选的关键。鉴于传统的针对特征权重的阈值判定方法存在强烈的主观性,本文提出一种与分类器相耦合的顺序前向选择判定方法。该方法首先将权重最大的特征因子输入某个分类器,得到初始分类精度,紧接着按照特征权重从高到低的顺序依次加入下一个权重略低的特征,与前面已加入的特征组合成新的输入数据,并计算相应的总体分类精度(Overall Accuracy, OA);每次添加一个特征并执行精度评估,直到19个特征全部输入完毕。若某个特征使OA数值降低,则剔除该特征,模型对应的优选特征集合依据OA确定。考虑到机器学习算法的随机性,本文取50次OA的均值作为特征子集的优选结果,最后将不同分类器各自优选出的特征组合作为相应模型的输入数据来提取大豆种植区。本文基于MATLAB 2018实现特征变量优选。
2.4 最优模型的判定
基于研究区内6个样方的无人机影像提取得到的大豆分布来评估不同模型的提取效果。由于航拍工作开展时间稍迟导致不同大豆田的物候期存在差异,部分地块已进入黄熟期,不利于计算机自动提取。而经过预处理后的无人机影像具有足够精细的纹理信息,可以较为容易地对地物进行目视解译和类型归属判断。因此,本文在ArcGIS 10.4软件平台的支持下,基于拼接后的无人机影像采用数字化方式描绘大豆种植地块的边界,并保存为矢量图层,以此作为真值来检验不同模型的提取效果。
借助地面真实数据,通过构建混淆矩阵可以对不同模型的分类结果进行精度评价。由该矩阵派生出的评价指标主要包括4个,即制图精度、用户精度、总体精度和Kappa系数。与其他3个指标相比,Kappa系数是根据所有待评估地类的漏分和错分情况给出的一种更为全面、更权威的分类准确性评估指标,其计算公式如下[38]:
式中N表示像元总数,m是类别数,xii是混淆矩阵对角线上的像元个数,xi+和x+i分别是第i行和第i列的像元总数。
2.5 最佳提取模型的效果评价
为了进一步考查优选模型在大豆制图中的表现,本文设计了3种大豆提取方案。方案A所用的特征为Sentinel-2原始10个波段反射率;方案B包含未经过特征选择的全部19个特征;方案C为上一节得到的优选模型。将不同特征组合形式作为输入,采用优选模型所对应的机器学习算法,基于相同的训练样本和检验样本,评估3种方案各自的分类精度,据此考查优选指标在大豆提取中的表现,分析该工作的实际意义。
3 结果与分析
3.1 非农作物像元的剔除
通过多次对比试验发现,MNDWI指标上建筑与水体的差异更为显著,更容易实现水体的分离。需要指出的是,研究区内树木多沿道路和房屋周围呈零星分布,植被指数(如NDVI或EVI等)数值处于中等水平,简单利用植被指数难以将其与农作物进行区分。而树木在近红外波段 B8(中心波长842 nm)和农作物具有明显差异,因此可基于该指标构建判别规则。具体的决策树筛选规则如图2所示。
3.2 不同模型的最佳特征子集
基于剔除非农作物像元的Sentienl-2影像,采用 ReliefF算法评估了19个候选特征因子在大豆识别中的重要性(图3)。B8权重最高,表明近红外波段对大豆提取的贡献度最大。REP、NDVIre2是有红边波段参与生成的特征因子;B5、B6是Sentinel-2的2个红边波段反射率,从特征权重评估结果来看,这些与红边波段相关的特征因子重要性排序比较靠前,意味着红边波段对于大豆遥感识别具有重要意义;此外,短波红外反射率B12和B11对于实现大豆与其他田间植被之间的分离也十分有效;SAVI和EVI相比其他常用植被指数更有利于此研究区内的大豆识别。
根据前文所述的优选特征变量的最佳维度判定方法,随着特征变量的逐步加入,不同模型的分类精度如图4所示。图4a结果显示当特征个数达到9时,分类精度达到局部最优,随着后续特征的加入,精度略有下降且在一个小范围内波动;当19个特征因子全部参与分类时,分类精度达到最大值,但仅比前10个特征所得精度高0.31个百分点,因此首先舍弃排名在第9位以后的特征;此外,排在第6位(SAVI)和第8位(B11)的特征在加入后未能提升分类精度,同样予以舍弃。最终ReliefF-RF模型选取了特征权重排名前9位的7个特征因子作为该模型的优选特征子集。同理,ReliefF-BPNN模型在特征个数达到9时,精度达到最大值(图4b),舍弃排名在第7位(EVI)和8位(B11)对应的特征以及第9位以后的11个特征,该模型的最佳特征维度为7;ReliefF-SVM模型的最佳特征因子的个数为5(图4c)。表3给出了3种模型的特征变量优选结果。

表3 不同模型的优选特征子集 Table 3 Optimum feature-subsets of different models
3.3 大豆种植区的最佳提取模型
本文将各模型对应的优选特征子集作为输入执行分类得到大豆种植区,并基于各验证样方内UAV影像的大豆种植区分布对不同模型的大豆提取效果进行评估(表4)。结果表明,基于ReliefF-RF模型得出的6个样方的总体精度和Kappa系数均高于其他2种模型,且在样方3上优势最为明显;ReliefF-BPNN模型的大豆制图精度较高但用户精度较低,说明该模型将较多其他地类错分为大豆;ReliefF-SVM模型的制图精度和用户精度在样方2、3、5、6均低于ReliefF-RF,而在样方1内的用户精度比ReliefF-RF高0.06个百分点,但制图精度明显低于ReliefF-RF,这表明该模型在样方1内大豆的漏分情况相对更为严重。3种模型在不同样方内的提取效果具有差异,但得出的大豆空间分布格局总体较为一致(图5)。研究区内大豆的种植规模占据绝对优势且空间分布较为均衡,然而作物间交错混杂种植现象普遍存在,大豆田块集中程度低、分布分散,ReliefF-RF、ReliefF-BPNN、ReliefF-SVM模型提取得到的大豆种植区总面积分别为9 291.16、10 277.70、9 451.24 hm2。
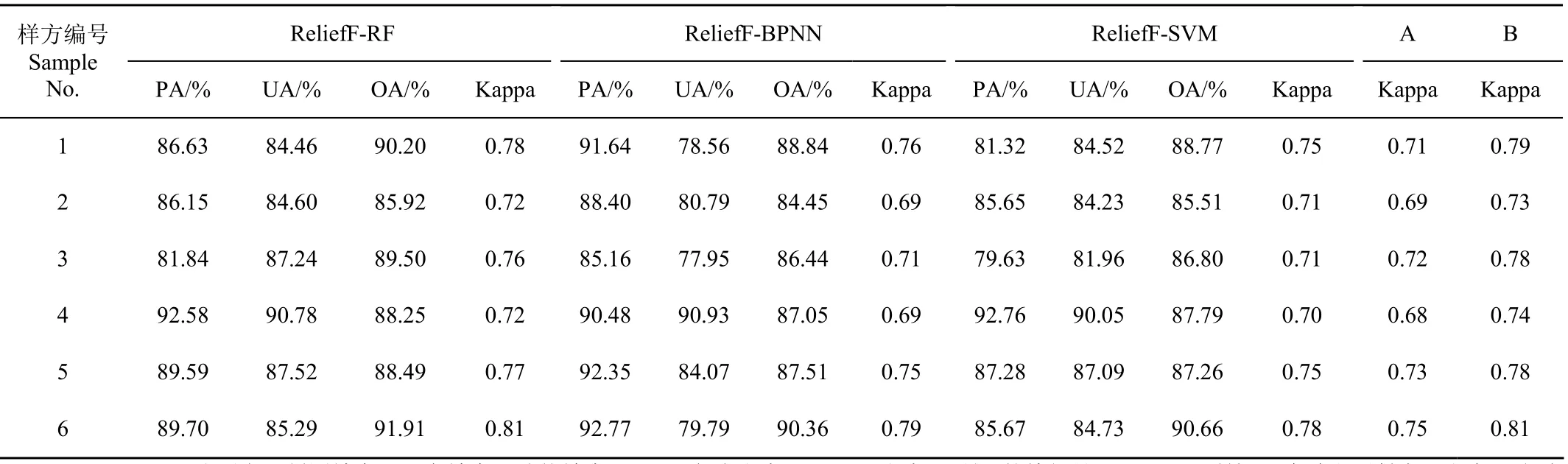
表4 大豆种植区的提取精度 Table 4 Extraction accuracy of soybean planting areas
为了更为直观地展现3种模型在6个验证样方内大豆提取效果的差异,图6给出了各个样方的大豆种植区空间分布。3种模型在局部地块,尤其是在大豆田和玉米田邻接的地块仍存在一定差异。将无人机影像解译得到的大豆种植区作为地面真值(用实线多边形表示),可以看出ReliefF-RF模型的提取结果与真值差距相对较小。除了样方4以外,ReliefF-BPNN模型的大豆高估情况要比其他2种模型更为严重,该模型将更多其他地类错分为大豆,导致用户精度偏低。与ReliefF-SVM与ReliefF-BPNN模型相比,ReliefF-RF模型的提取结果更接近大豆的真实分布,提取效果明显优于其他2种模型,因此,本研究文将该模型作为大豆种植区提取的最佳模型。
3.4 最佳提取模型在大豆识别中的表现
为了进一步评估最佳提取模型ReliefF-RF在大豆识别中的表现,基于RF算法的方案A与B的大豆提取精度如表4所示。与Sentinel-2原始10个波段(方案A)相比,基于优选特征子集的ReliefF-RF模型的Kappa系数在样方1、6分别提高了0.07、0.06,大豆的提取效果有显著改善;在样方2提高了0.03;在样方3、4、5提高了0.04,该模型在所有样方中均实现了精度提升。与未经优选的19个特征的提取结果(方案B)相比,优选模型所得的Kappa系数仅比前者低0.01或0.02。结果表明,基于优选特征建立的ReliefF-RF模型在保障提取精度的同时,相比将所有候选特征作为输入能够减少63.16%的数据量。因此,本文提出的最佳模型ReliefF-RF在大豆种植区提取中具有较为明显的方法优势。
4 讨 论
先前的有关大豆识别的研究多以MODIS、Landsat和高分系列卫星影像为主要数据源,研究区多集中在作物类型简单的美国、巴西等国家[5,12,15,17],且有利于大豆识别的最佳特征的相关研究较少。本文基于单时相Sentinel-2影像采取分层逐级提取策略实现了种植结构复杂地区的大豆种植区提取。分层逐级提取策略可以实现较高精度的大豆提取,该提取策略的研究对象聚焦田间植被,筛选得到的特征针对性更强,理论上所得结果的适用性和推广性更优且不受其他非农地物占比的影响,在大豆卫星遥感提取中具有重要意义。该策略在构建决策树筛选规则时,借助2017年FROM-GLC10全球土地利用产品来修正决策树提取结果,在剔除非农地物类型之后,它所提供的耕地类型的空间分布尽可能多的包含了可耕作地块。经对比分析后发现耕地面积高于实际的农田分布区,因此该产品有助于非农地物像元的剔除来提高大豆识别精度,并且不会对作物提取结果产生不利影响。
本文的特征优选是采用与分类器相耦合的方式自行筛选出与之相匹配的最佳判别特征,这能够在最大程度上兼顾不同分类算法的特异性,并且在一定程度上降低了利用传统阈值方法[39]执行最佳维度判断时所带来的主观性。3种模型的优选特征因子均包含了权重排名前5的特征(B8, NDVIre2, B12, REP, B6),表明红边、近红外和短波红外波段在大豆识别中具有显著优势,与王利民等[12-16]的研究结论一致,同时也说明了植被指数与光谱波段相结合的特征集能有效区分不同农作物。不同模型的最佳特征子集中所删除的特征可能是冗余信息,但是本研究未单独对候选特征以及优选特征子集进行冗余性分析,后续研究将进一步探讨各个特征之间可能存在的信息冗余问题。
本研究采用布设于研究区内的6个样方来检验大豆提取精度,样方的设置同时兼顾了空间地理位置的均匀性、样方内的作物类型以及大豆的占比等情况,且研究区为相邻的2个乡镇,其空间异质性较小,因此验证样方具有一定代表性。由于权威的乡镇级作物播种面积统计数据在现实中难以获取(统计年鉴通常只能提供县区级以上的统计数据),因此本研究未进行种植面积估算精度的检验。最佳提取模型ReliefF-RF在样方1、3、5、6的Kappa系数均大于等于0.76,而在样方2和4仅有0.72,其他2种模型的提取精度和该模型具有类似结果,提取精度尚未达到较高水平。经田间实地调查发现,在散户耕种模式下,研究区内田间种植结构复杂,夏季作物类型多样,大豆的品种、播种时间以及管理方式的不同,导致大豆作物类内差异较为明显,比如肉眼可见的植株高度与叶片颜色的不一致,田间存在杂草和斑秃地块等,这些因素均给大豆遥感提取带来了巨大挑战,尤其是在大豆田和玉米田的邻接地块。由于样方2和样方4内的大豆田和玉米田更为细小和狭长,田间破碎程度相对更高,而所用Sentinel-2波段的像元大小为10 m,某些地块宽度可能不及一个像元,导致“混合像元效应”显著,增加了遥感提取的难度和不确定性,在一定程度上降低了提取精度,今后将探讨混合像元分解方法在该地区内大豆种植区的提取效果。此外,作为验证数据的无人机影像的空间分辨率为6 cm,Sentinel-2影像的空间分辨率为10 m,二者的空间尺度差异十分明显,结果之间不容易实现匹配,必然会对检验精度产生影响。后续研究中考虑采用高分辨率卫星影像如 GF-2 PMS, Superview-1, Pleiades等来评估提取效果。
研究区地处南北方过渡地带,天气变化较为剧烈,阴雨天气出现的频率较高,导致可用光学影像的覆盖频率受限,多个物候期内的光学影像不一定有条件获取。因此,基于单时相数据实现大豆种植区提取在现实中更为可行且更具有实际意义,后续研究将进一步探讨多时相数据在皖北地区大豆精细遥感提取中的应用效果。此外,本研究的田间试验以及地面调查工作还不够完善,尤其是调查样点数量不够充足,覆盖的地物类型不够广泛,对于大豆异谱现象的形成机理尚未进行深入探讨。后续工作需要进行更为系统和全面的田间实地调查。本文的研究区相对较小,仅覆盖2个镇,且只关注了2019年一个生长季,后续将在更大尺度上针对多个生长季开展大豆种植区提取研究,来检验该项研究所得结论的适用性和鲁棒性。
5 结 论
本文基于Sentinel-2影像,以安徽省皖北典型大豆主产区为例,针对种植结构复杂、晴空观测有限以及田间景观破碎的客观实际,提出了一种基于分层逐级提取策略的大豆识别方法。研究结果表明,ReliefF-RF的Kappa系数介于0.72~0.81,相比其他2种模型表现出了更好的大豆识别能力(ReliefF-BPNN和ReliefF-SVM模型的Kappa系数分别在0.69~0.79和0.70~78之间);此外,优选特征子集的提取精度明显高于Sentinel-2原始10个波段参与提取得到的结果(后者Kappa系数在0.68~0.75范围内),尽管略低于全部19个特征因子的结果(Kappa系数相差0.01~0.02),但是降低了63.16%的数据量。因此,ReliefF-RF模型是本研究中大豆提取的最佳模型,该模型筛选出的红边波段B6(740 nm)、近红外波段B8(842 nm)、短波红外波段B12(2 190 nm)和绿波段B3(560 nm)可以有效地识别大豆,且红边归一化植被植数2、红边位置指数和增强型植被指数在大豆识别中相比其他常用遥感植被指数更有优势。该研究弥补了复杂种植条件下大豆提取相关研究的不足,文中所提出的研究思路可以为相似种植条件下的大豆遥感识别相关研究提供有益参考,研究成果可以为当地农业部门开展农情调查、长势评估等工作提供有价值的依据。
猜你喜欢
灌溉排水学报(2022年7期)2022-08-08
九江学院学报(自然科学版)(2022年2期)2022-07-02
航天返回与遥感(2022年2期)2022-05-12
波谱学杂志(2022年1期)2022-03-15
四川农业科技(2021年9期)2021-11-19
中国饲料(2021年17期)2021-11-02
乡村科技(2021年17期)2021-10-20
安顺学院学报(2021年4期)2021-09-16
华北理工大学学报(自然科学版)(2021年3期)2021-07-03
中国科技纵横(2016年15期)2016-12-29
