
微震震源定位算法优化研究及应用
2021-08-02 03:35赵德明王海波
计算机技术与发展 2021年7期
赵德明,庞 锐,王海波
(中国石油化工股份有限公司石油物探技术研究院,江苏 南京 211103)
0 引 言
微地震监测是指利用井下或者地表布置的一个个监测检波器接受非常规油气生产过程中的微小的破裂或错断信号,并通过一系列处理方法反推出信号发生位置、延伸方向等信息,最后根据这些信息反过来优化非常规压裂设计方案,降低成本提高出产率[1]。随着中国非常规油气储量不断探明,丰富的储量对微地震监测的需求越来越强烈,而监测的重要目的之一就是精确定位微地震震源。震源位置反演就是利用检波器收集的地震波信息确定事件发生位置,即确定压裂导致的裂点坐标,进而确定压裂形成的裂缝延伸到角度和长度[2]。所以,如何更好更快速地反演出微地震的震源位置,是微地震监测的关键问题之一。
很多学者对微地震震源位置反演方法进行了大量有效的研究。均匀介质微地震位置反演方法主要有纵横波时差法和同型波时差法。非均匀介质反演方法主要有蒙特卡洛法、模拟退火法、遗传算法及牛顿法、共轭梯度法等[3]。为了解决更复杂的反演问题,有的还提出了基于正演模型的反演方法、多个参数联合反演[4]等。文献[5]针对微地震信号信噪比低、浅地表干扰多、不易拾取初值等问题,在传统的线性及非线性反演方法都不能给出可靠结果的情况下提出了贝叶斯反演定位方法。Kao和Shan提出了震源扫描算法(source scanning algorithm,SSA),该算法不需要预先知道断层信息,就能利用波形数据系统地扫描设定的时间及位置是否有震源以发现整个震源序列分布,对波形速度模型的抗干扰能力强,同时由于扫描过程不需要人为干预,能保证结果的客观性和准确性[6]。文献[7]利用面波的特点对SSA的分辨率进行了改进。文献[8-9]对SSA算法进行了详细阐述,并用实际工区资料验证了该算法对微小地震事件能很好的定位。
但随着勘探的深入,遇到的问题越来越复杂,实际生产应用的数据规模也随之增加。为了不断适应这种变化,算法的复杂性和计算量呈指数性增加。在前面的文献中不难看出,大部分研究侧重于定位精度的改进,但实际生产过程中往往需要实时给出压裂破裂点及延伸方向。由于SSA算法的优越性,这里以该定位算法为例进行优化研究。为了能快速地给出定位结果,通过研究扫描算法特点和并行解决方案并结合现场处理条件限制,采用并行化变网格方法加快震源定位速度。
1 SSA算法描述
震源扫描叠加方法(SSA)是地震学中进行微小能量地震震源定位的方法。水力压裂微地震监测信号具有与其相类似的特点,因此,可将震源扫描叠加方法应用于微地震震源定位的实际应用中[10]。
震源扫描算法是一种可以处理分布的震源信号进而成像定位的方法,这种新方法不用预先获得断层的产状和规模,可以根据相对振幅和初至等波形数据,判断出某个知道的时间和坐标有没有发生地震震源。它会利用序列化扫过某个试探性的位置范围和起震时刻,发现整个震源排序分布而不需要拾取初至,也不用计算理论地震图[11]。
SSA算法是由Kao和Shan在2004年提出的,他们用该方法对2003年3月北卡斯卡迪亚俯冲带的慢地震资料处理后得到了意外的结果。在该资料一段时间里发生了几个微地震信号,信号延续范围比一般地震事件长很多,其振幅水平却又与噪声一致,传统的定位方法无法得出同一震源的位置,由于不能找到准确的震源,信号波形反演也无效。最后利用SSA算法的“亮度”函数处理,准确得出了微地震事件的震源坐标和发震时刻[7],其基本原理如图1所示。

图1 震源扫描原理
假设一个微地震信号由N个检波器接收到(图中的1、2、3点),第一步分别对每个检波器记录rn归一化,接着计算某个点(c)某个时刻(t0)的“亮度”函数。

(1)
式中,N表示检波器个数,t0表示开始检测的时间,rn表示检波器n的微地震信号,tcn表示某个信号由空间c传到检波器n经过的时间。地层中的某一点c在t0时刻的“亮度”能通过对应检波器理论到达时刻(即t0加上走时t1c、t2c、t3c)推算得出,如果该处“亮度”较大(空心☆),表示此处有事件,如果“亮度”较小(实心★),说明此处没有事件。假设监测的全部振幅在空间c处和t0时间产生,li(c,t0)=1。如果li(c,t0)=0.5,表示在这点有事件的概率为50%。一般来讲,li(c,t0)等于1的概率很低,所以就以li函数值大小为衡量标准确定微地震事件位置。
但在生产应用过程中,计算走时的实际速度模型与理论速度模型有可能存在一些偏差,进而影响结果的准确性。公式中tcn仅考虑到直达波的理想情况,没有考虑信号传播过程中带来的反射、折射等一系列噪音信号的干扰。因此Kao等人于2007年对上述算法进行了改进,提高了算法的抗噪能力和准确性[2]。首先,在采样点上下开一个时窗,用时窗内的所有点的振幅替换该时刻的振幅。其次,添加权重值Q可以随速度模型准备与否灵活调整,改进后公式如下:
(2)
式中,N表示检波器个数,W表示时间窗口范围,Δt表示信号采集间隔,t0和tcn同上,Un表示归一化记录结果,Q表示理论到达时刻与检测到达时刻差值确定的权重值。
2 并行解决方案
目前比较常用的编程方法有MPI(message passing interface)消息传递方式、基于集群的OpenMP多线程方式、基于CUDA的异构编程方式及混合异构方式。由于实际应用的复杂性,又产生了多级联合编译方式:MPI和OpenMP混合编译方式,MPI和OpenMP及CUDA混合编译方式[12]。另外,基于硬件GPU的多种编程方式也有广泛应用。按数据消息通信方式,以上所有方式大体可以分为数据并行和消息传递两种编程方式[10]。数据并行方式编程相对简单,但对数据可并行化程度有很高的要求,适用范围比较小。消息传递方式编程对数据要求不高,但需要考虑每一步运算的数据间通信,容易产生数据不同步、死锁等问题,编程太过复杂。为了能在编程时兼具以上两种方式的优点,谷歌公司于2004年提出了MapReduce[11]编程模型。这种方式能让编程人员不需要考虑复杂的底层库实现,只需要利用其提供的Map、Reduce和Partition等函数轻松并发处理海量数据[13]。利用MapReduce可以实现自动并发处理数据,可以很方便地利用其提供的接口实现任务调度、负载均衡、容错和一致性管理等[12],执行过程如图2所示。
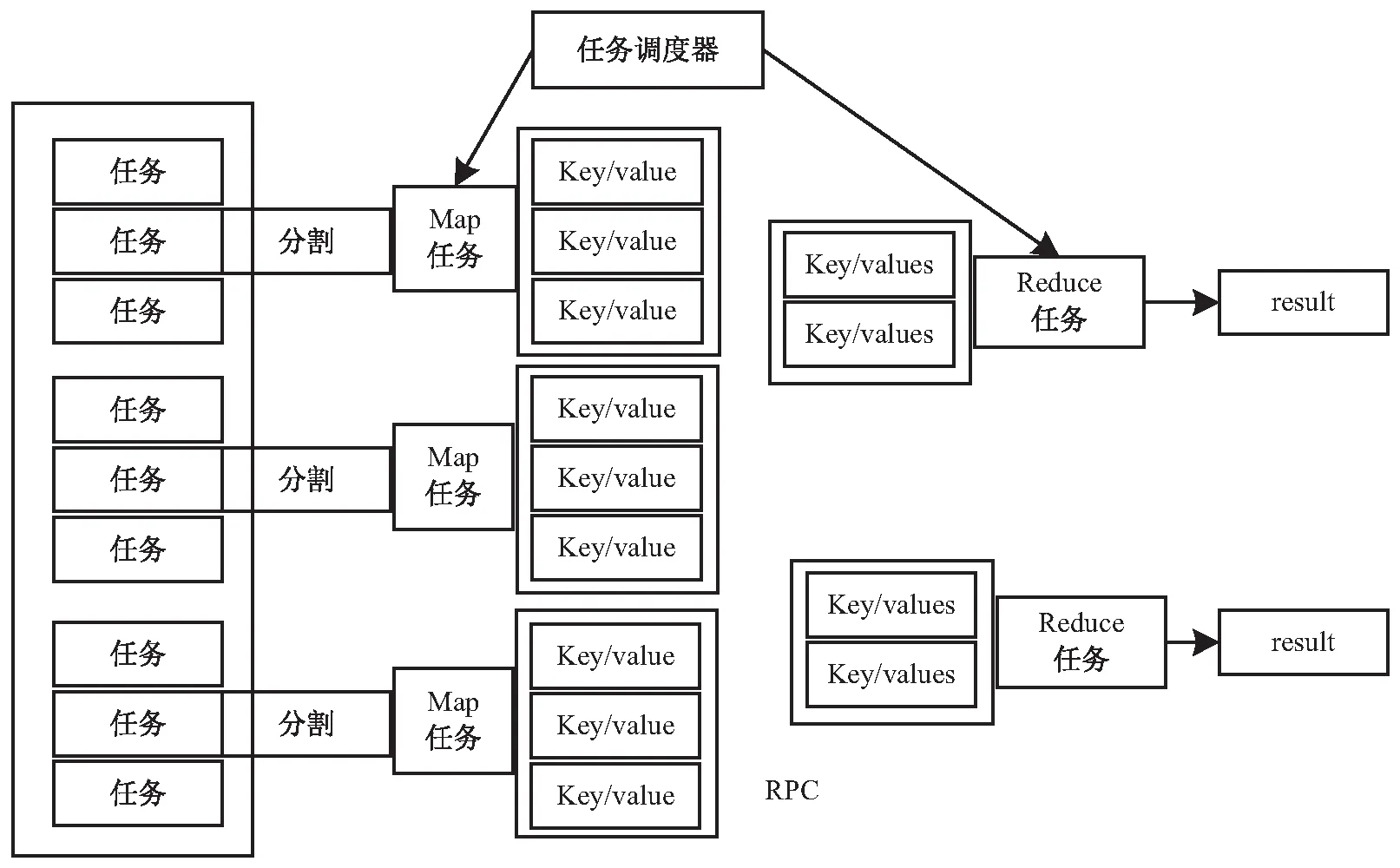
图2 MapReduce执行过程
(1)启动MapReduce运行时库后,程序员可以手动或根据可用工作单元负载情况自动分割数据,并给每份数据分配一个key/value组,同时向即将运算的工作单元复制一份并行程序;
(2)只要有Map运算任务,工作单元会获得对应的key/value组,并把其作为数据的关键字存储在内存中;
(3)程序会定期将内存中的key/value组写入本地存储空间,程序员定义的划分函数将其细分为不同分组,任务调度器会根据Reduce任务执行情况将本地存储空间key/value组的物理地址传给Reduce任务工作单元;
(4)通过RPC(remote procedure call),Reduce任务执行单元读取上面获取的Map执行单元的key/value组;
(5)当Reduce工作单元获得所有需要的key/value组后,将具有相同key的key/value组排序形成key/values组,作为Reduce函数的输入;
(6)Reduce工作单元将函数运算结果发送到指定文件中。当所有的Map、Reduce任务都接受后,任务调度器将结果和代码返回到主程序[14]。
QT编程模型中QtConcurrent机制提供了MapReduce的编程接口,简单编程就可以将任务分发到处理器所有的核上。QtConcurrent命名空间里的run()函数可以实现多线程的并发执行,QtConcurrent提供了map()函数可以自动分配硬件线程去执行各个任务,直到所有任务都执行完。MapReduce和多线程执行代码完全被隐藏在QtConcurrent框架下,所以可以直接使用而不用考虑细节[14]。
3 微地震震源扫描算法优化
为了达到实时处理,该项目针对微地震震源扫描算法进行了优化。现有的微地震震源扫描算法的扫描网格是固定的,该文在已有的定网格震源扫描定位处理的基础上,进行网格插值,将其大范围粗网格扫描范围通过网格插值的方法插值实现小区域的细网格进行扫描,并对细网格进行并行化计算,最终实现粗、细双重网格并行化扫描。其效果上,数据计算量大幅度减少,有效提高了计算效率[15]。
二次插值法亦是用于一元函数f(α)在确定的初始区间内搜索极小点的一种方法。二次插值的基本原理:在求解一元函数f(α)的极小点时,常常利用一个比函数低次的插值多项式p(α)来逼近原目标函数,然后求这个多项式的极小点(低次多项式的极小点比较容易计算),并以此作为目标函数f(α)的近似极小点。如果其近似的程度尚未达到所要求的精度时,可以反复使用此法,逐次拟合,直到满足给定的精度时为止。
插值多项式p(α)如果为二次多项式则叫二次插值法,如果是三次多项式则叫三次插值法。文中采用的是二次插值法,这里以此为例进行介绍。
假定目标函数在初始搜索区间[a,b]中有三点α(1)、α(2)、和α(3)(a≤α(1)<α(2)<α(3)≤b),其函数值分别为f1、f2和f3(见图3),且满足f1>f2,f2>f3,即满足函数值为两头大中间小的性质。利用这三点及相应的函数值作一条二次曲线,其函数p(α)为一个二次多项式。

图3 二次插值示意图
p(α)=a0+a1α+a2α2
(3)
式中,a0、a1、a2为待定系数。
根据插值条件,插值函数p(α)与原函数f(α)在插值节点P1、P2、P3处函数值相等,得:

(4)

p'(α)=a1+2a2α=0
(5)
解式(5)即求得插值函数的极小点。
(6)
式(6)中要确定的系数a1,a2可在方程组(2)中利用相邻两个方程消去a0而得:
a1=
(7)
a2=
(8)
(9)

为便于计算,可将式(9)改写为:
(10)
式中:
(11)
(12)

图4 变网格震源扫描程序流程
变网格震源扫描算法实现步骤为:(1)输入微地震有效事件记录;(2)对微地震记录进行预处理(坏道剔除、强噪音压制等);(3)进行地表高程校正;(4)读入速度模型,计算粗网格炮点在各个网格点上的旅行时文件;(5)进行粗网格震源扫描定位计算每个炮点的亮点值;(6)求得粗网格的亮点值;(7)读取亮点值所在粗网格点的周围网格上的旅行时值;(8)通过插值算法,求得小范围的细网格的旅行时文件;(9)通过震源定位算法进行细网格扫描;(10)对整个微地震事件进行分时窗局部数据叠加;(11)求得细网格范围的扫描亮点值;(12)扫描程序结束。
该文采用Qt的run()多线程机制和map()机制相结合的并行方法对变网格震源扫描方法并行化实现,具体步骤如下:

图5 变网格微震震源扫描并行化流程
(1)创建震源扫描类,在震源扫描类中创建网格参数获取函数获取震源定位处理流程中sx、sy、sz的最大最小值及震源扫描的视窗大小、旅行时文件、速度文件等参数和文件路径。
(2)在震源扫描类中创建多线程run()函数,获取校正量,读文件头参数并检查,如果旅行时文件震源参数和扫描参数不符则返回。读取旅行时文件数据到内存中, 利用事先创建好的震源扫描任务类为每个点构建一个逻辑任务,把任务的数据粒度细化到一个点,这样可以保证震源扫描任务类的数据结构尽量简单明了。如果微地震监测数据的辅助道上没有同相轴,则不进行震源扫描。对本次要扫描的监测数据叠加道进行相关处理获得震源扫描初始数据,将数据与上面构建的逻辑任务进行关联。
(3)调用震源扫描类中的sourcescanxy()函数,利用MapReduce框架进行并行化处理,把任务列表中的任务map出去,qtconcurrent::map()会自动分配硬件线程去执行各个任务,自动调用震源扫描任务类任务类中的sourcescantaskmapfunction()函数,直到所有任务都执行完毕。本来应该等所有任务都结束了,在这里对所有任务的结果进行归约操作,但是如果每个任务都保存结果,则会占用很大内存,因此把归约提前,提前到每个任务中,在每个任务中得到结果后就立即进行归约操作,然后释放结果内存,可以减少内存占用。
(4)每个工作单元的CPU核在接收到任务后执行震源扫描任务类中的runcomputation()函数,调用震源定位算法moveoutstack()和snr_(),并立即执行Reduce操作。为防止数据不一致,在获取Reduce操作需要的数据时进行加锁。等所有的Map和Reduce操作执行完毕,将定位到的微地震压裂事件数据写回到数据文件中。
4 实际资料测试与分析
在一个八核CPU的移动工作站上对某页岩气实际微地震监测资料进行处理,震源扫描定位算法的输入是有事件拾取的微地震剖面,这里每个剖面的时间跨度为三秒,如图6所示。

图6 拾取事件的微地震剖面
为了验证文中优化方法的性能,分别用优化前和优化后的震源扫描算法对不同数据量的拾取剖面进行测试,并计算加速比,结果如表1所示。
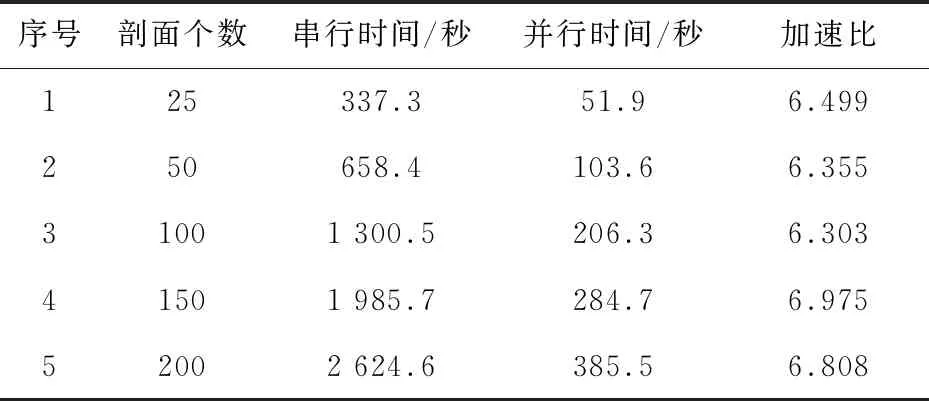
表1 实验结果
从表1可以看出,该文采用的优化方法可以达到较好的加速比。在八核处理器的工作站上,加速比约等于7。同时,拾取剖面数量增加,加速比也略微增加,说明该优化方法具有较好的稳定性和实用性,能很好地处理微地震剖面数据。
通常一段页岩气微地震压裂监测持续5~6个小时,而可以监测到的微地震事件大约可以达到五百个,也就是五百个拾取事件的剖面。从表1可以估算出在对震源扫描算法优化之前,一段压裂监测数据的定位时间需要接近两个小时,优化后执行时间却可以控制在半个小时以内,完全达到现场处理的要求,可以对微地震压裂方案提供实时数据指导。
5 结束语
大多学者对微地震震源定位方法的研究集中在定位准确性的改进上,该文则考虑到现场处理实时性的需求,采用变网格方法和MapReduce并行编程模型,对定位方法中的震源扫描算法(SSA)进行了优化。实际资料测试证明,优化后的震源扫描算法获得了较好的加速比,完全符合现场实时处理的需求。今后的工作主要对影响加速比的因素进行研究,如工作站的内存大小、硬盘容量、CPU处理核数等。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
电脑报(2020年31期)2020-08-20
数学大王·低年级(2020年3期)2020-03-12
中国经济信息(2018年21期)2018-11-29
环境与发展(2018年6期)2018-09-17
知识就是力量(2018年4期)2018-04-13
城市地理(2017年9期)2017-11-02
计算技术与自动化(2014年1期)2014-12-12
