
基于单应性与相似度矩阵的运动分割
2021-08-02 03:35吴骁伦
计算机技术与发展 2021年7期
吴骁伦,杨 敏
(南京邮电大学 自动化学院、人工智能学院,江苏 南京 210023)
0 引 言
运动分割[1]是计算机视觉中最重要的研究领域之一,在机器人技术的许多应用中是一项重要的预处理任务。它已被用作预处理步骤应用在智能交通系统,如视觉监控、动作识别、场景理解等。根据不同的运动模式认知和分离不同的运动物体(如移动的车辆或移动的人),其中每个移动的物体被识别为一个连贯的实体。
描述这个问题的经典方法如下[2]:给定一组特征点,通过一系列图像跟踪,目标是根据它们所属的不同运动将这些轨迹聚类。假设场景中包含多个物体,它们在三维空间中独立地移动。传统的运动分割方法或多或少都会存在一些问题,比如处理高维数据时计算复杂,实时性差,抗噪声能力差,无法兼容相机运动等等。最近提出了许多运动分割方法,有些已经在一些流行的测试数据集上展示了出色的性能,例如Hopkins155数据集[3-4]。
运动分割方法可以分为基于两帧[5]和基于多帧[6]的方法。后者由于能够从视频序列的所有帧提取运动信息以进行精确的运动分割,所以现在大多算法都运用多帧的方法。一般大致将以前的基于多帧的运动分割方法分为两类:基于子空间的方法[7-9]和基于相似度矩阵[10-11]的方法。基于子空间的方法利用视频序列的所有特征点轨迹构造数据矩阵,对不同的运动进行聚类。另一方面,基于相似度的方法是基于特征点轨迹对构造的相似度矩阵来分割不同的运动。尽管在Hopkins155数据集上已经展现了良好的性能,但是在实际应用中,基于子空间的方法可能无法处理一些特殊情况。例如,当运动物体被暂时遮挡时,用基于子空间的方法得出的结果一般不会很理想。在这种情况下,被遮挡的物体的特征点轨迹就会丢失,而基于相似度的方法能有效处理这些问题。例如,稀疏约束的运动分割(MSSC)[12]方法针对这个问题取得了不错的效果。
在运动分割问题[13]中,多种几何模型被用来对不同类型的摄像机、场景和运动进行建模。在这个问题上,正如通常所说的那样,基本矩阵模型通常被认为是适用于不同的情景和不重叠的背景。例如,当场景是全局运动时,基本矩阵被用来描述极上几何,当场景是平面场景或者运动是纯旋转的时候,单应性是首选。在Hopkins155数据集中,这并不是最主要的问题,因为大多数序列的视场都很小,也许场景距离足够远,可以用基本矩阵来近似,基于仿射矩阵或单应矩阵的各种方法所获得的良好结果验证了这些想法。
该文旨在利用单应变换与相似度矩阵的优势在Hopkins155数据集上取得更好的聚类效果,并且能处理一些遮挡问题。
1 单应变换
该文采用的是单应性模型[14],先进行单应性的计算。单应映射是描述物体在世界坐标系和像素坐标系之间的位置映射关系。单应性模型能够有很好效果的原因在于单应性假设过程中产生了很多的平面切片,这些在场景中不一定是真实的物理平面,但只要这些虚拟平面属于相同的刚体运动,显然就可以用单应性来拟合。这样的切割在多个真实平面表面的点之间建立了强大的连接,从而产生了一个不会被过度分割的相似度矩阵。如果场景只包含紧凑的物体或分段光滑的结构,那么创建的这种连接足以将刚性运动的各个表面绑定在一起。所以在Hopkins155数据集中,大部分的视频序列的场景都比较小,运动的物体的结构比较规则,所以用单应性去拟合其数据集中的场景是比较适合的,如图1所示。

图1 Hopkins155中的示例
如图2所示,记m=(x,y,1)T,m'=(x',y',1)T为一对匹配点,映射的形式为:m'=Hm。这是一个齐次坐标的等式,H乘以一个非零的比例因子上述等式仍然成立,即H是一个3×3的齐次矩阵,具有8个未知量。
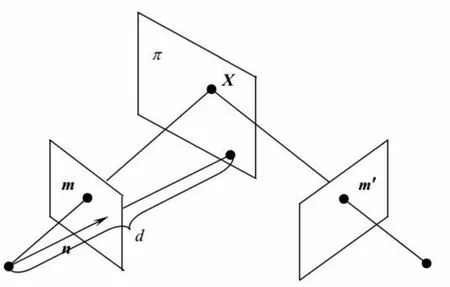
图2 单应变换原理
写成矢量形式为:[m']×(Hm)=0,H称为单应性。记H为hT,则有Ah=0,其中A为包含图像点坐标变量的2×9的矩阵,h有九个变量,自由度为8个。
假设已经取得了两图像之间的单应,则可单应矩阵H可以将两幅图像关联起来,其中(x,y,1)T表示图像1中的点,(x',y',1)T表示图像2中的点,也就是可以通过单应矩阵H将图像1变换到图像2。
所以场景中的点都在同一个平面上,可以使用单应矩阵计算像点的匹配点。相机的平移距离相对于场景的深度较小的时候,单应矩阵也比较适用。
2 基于相似度矩阵的运动分割算法
2.1 运动分割的目标
用tfp∈R2表示在F帧中跟踪P条轨迹的二维坐标的集合,f对应帧,p对应轨迹。在多目标运动分割中,tfp对应于运动的刚体表面上的点。运动分割目标是将轨迹的点按它们所属的运动分类。换句话说,在下面的数据矩阵中安排坐标,目的就是排列矩阵中的列,使同一个运动物体上的轨迹都能归属到同一类,这样就完成了聚类。
(1)
2.2 假设估计
由上一节所讲,单应变换的部分可见H的未知量为8,所以需要至少四对已知的对应点,也就是说在一对帧中抽取4个点。因为模型是四维空间,所以上面的a=4,假设值是通过使用直接线性变换从四个不丢失特征对应的最小子集中估计出来的,并随机抽取S个假设,θ={θ1,θ2,…,θS}为使用随机采样从第f对连续帧生成的假定假设集。
2.3 用有序残差核计算相关性
有序残差核(ORK)对严重的采样不平衡有很强的适应能力,这一观点得到了普遍的认可,所以用有序残差核来处理各种各样的场景是一个重要的优势。因此,该文采用有序残差核来计算各个轨迹之间的相关性。

(2)
R(*)表示为所做的残差运算。
(3)

(4)


(5)


(6)
这样进一步地使计算更加简便。
2.4 累加相关性构造相似度矩阵
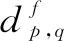
(7)
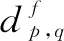

2.5 用谱聚类进行运动分割
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看作空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
该文利用上述方法已经求得了相似度矩阵D,接着需要求得度矩阵:
(8)
即相似度矩阵D的每一行元素之和。M为mi组成的n×n对角矩阵。
D为相似度矩阵,求得度矩阵M,标准的对称拉普拉斯矩阵如下:
L=M-1/2DM1/2
(9)
然后用如下公式进行特征求解:
mintr(UTLU),s.t.UUT=I
(10)
其中,tr(*)表示迹运算。
计算L的特征值,将特征值从小到大排序,取前k个特征值,并计算前k个特征值的特征向量u1,u2,…,uk,将上面的k个列向量组成矩阵U={u1,u2,…,uk},然后作为原始点的新特征表示处理。然后使用k-means算法进行聚类,最后得到聚类结果。
3 仿真实验
3.1 数据集
3.1.1 Hopkins155
在实验中,是针对Hopkins155数据集进行的算法设计。Hopkins155数据集是运动分割最流行的基准之一。它由120个二运动视频序列和35个三运动视频序列组成。
3.1.2 62-clip
62-clip数据集主要来自于Hopkins155数据集,包括来自Hopkins155的50个视频序列,另外12个有物体遮挡的视频序列已经添加到62-clip数据集中。在12个视频序列中,有9个视频序列具有透视效果。在62-clip数据集中有26个双运动视频序列和36个三运动视频序列。
3.1.3 KITTI
KITTI数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据。该数据集比较契合真实场景,可以在此数据集上验证文中算法的精度。
3.2 评价指标
运动分割性能是根据点轨迹的标记误差来评估的,其中序列中的每个点都有一个真实值标签。
分类错误率=被错误分类的特征点/总特征点
在Hopkins155数据集中,分别在两运动序列、三运动序列与所有序列上进行实验,以此来比较各个方法的优点。
在62-clip中,分别在12有遮挡序列和50无遮挡序列以及所有序列上进行实验,来测试各个模型应对遮挡问题的能力。
在KITTI上,用平均与中位数这两项指标比较各方法的稳定性。
3.3 实验结果
在表1中,将文中方法与之前的算法(GPCA[9],SSC[15],LRR[16],ALC[7],ORK[8],TPV[5])进行对比。这些算法在发表的时候都是在Hopkins155数据集上有着很好的表现,但是随着研究进一步深入,其局限性也显露了出来。

表1 在Hopkins155数据集上的实验结果
文中方法针对有遮挡的视频做出了一些改进,在62-clips数据集中,有12个视频是有遮挡的。在表2中可以看出,在12个有遮挡的序列中,只有文中方法有很好的效果,在其余50个不被遮挡的序列中,可以看到分类错误率的差距不是很大,说明文中方法在处理有遮挡问题时,确实起到了作用。

表2 在62-clips数据集上的实验结果
表3是在KITTI数据集上进行的实验。由于KITTI多是透视视角,更加趋近于真实场景,而且KITTI多是用于自动驾驶,所以文中方法也存在很高的错误率,但相对于别的方法具备一些优势。

表3 在KITTI数据集上的实验结果
图3展示了最后的聚类效果,这是Hopkins155数据集中的一帧,可从图中看出背景,卡车与小轿车被分为了不同的类别,说明聚类取得了一定的成功。

图3 聚类效果
4 结束语
设计了一个基于相似度矩阵与单应变换的运动分割算法。为了在Hopkins155上发挥更好的效果,该文选择了用单应矩阵模型来拟合。用相似度矩阵并且使用了累加的方法,使此方法在处理有遮挡的视频时有着更好的鲁棒性。仿真实验结果表明,该方法在Hopkins155数据集上具有不错的效果,但是在更加接近于真实世界与大的场景的KITTI数据集上,此方法表现不佳,所以还需进一步改进,以适应更多变的视角。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年4期)2022-03-07
计算机研究与发展(2022年1期)2022-01-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
读与写·教育教学版(2017年10期)2017-11-10
文苑(2015年9期)2015-09-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
