
一种中国古典文学文本知识图谱构建方法
2021-08-02 03:35杨泽,顾磊
计算机技术与发展 2021年7期
杨 泽 ,顾 磊
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
自从2012年谷歌提出知识图谱(Knowledge Graph)[1]的概念后,越来越多的研究围绕知识图谱构建展开。目前对知识图谱的研究应用主要包含通用知识图谱和垂直领域知识图谱。典型的通用知识图谱包括用于研究领域的DBpedia[2]、YAGO[3]、Freebase[4]等以及用于工程领域的谷歌“Knowledge Graph”、百度“知心”、搜狗“知立方”等。典型的领域知识图谱包括医学病理领域知识图谱CMeKG[5]、地理信息领域知识图谱Geonames、企业领域知识图谱“天眼查”等。知识图谱构建的首要关键步骤就是知识抽取,根据数据来源包含非结构化、半结构化以及结构化数据。通常非结构化数据的处理是难点,以文本为代表的非结构化数据需要进行预处理,如先进行分词与词性标注[6]。古典文学文本的图谱构建就属于非结构化的,由于中古典文学的知识图谱相关研究较少,通常需要大量的人工标注工作。特别是以中国古典文学为代表的古文面临更多的困难,因为古文注重典故、骈骊对仗、音律工整,语法和用词方面相对于现代文更加复杂和讲究,使得计算机很难识别有意义的词语的边界。
通常已有的古文方面的知识图谱构建大都基于规则抽取。文献[7]以农业古籍本体的构建为例,从专业文本及专业词典中抽取关键词,得到本体概念集合,利用软件工具Protégé进行本体构建,并采用Jena实现了对该本体的可视化浏览及检索。文献[8]以《二十四史》为资源基础,利用基于词典的技术和规则模式匹配技术来标注与获取文本中的命名实体及关系,并开发“中华基本史籍分析系统”提供检索。也有少量将规则抽取与机器学习相结合的方式。文献[9]以《左传》语料为基础(该语料进行了人工分词与词性标注),利用条件随机场进行BIO角色标注,并在BIO识别的基础上,根据规则,利用触发词获取属性关系,从先秦典籍中抽取本体实例。总体而言,想要利用自然语言处理技术进行自动抽取需要一些预处理工作,其中一个必要的步骤是对古文进行分词与词性标注。文献[10]利用条件随机场模型,主要对词性、语音特征构建模板,对《诗经》进行分词。文献[11]利用条件随机场模型,通过字词结构、词语拼音和字词长度等特征信息构建组合特征模板,对先秦典籍进行词性标注。条件随机场模型依赖于根据语言特点所人工编写的特征模板,虽然也取得了较好的结果,但是结果性能过于依赖特征模板的简单或复杂程度。
该文提出了针对中国古典文学文本的知识图谱构建方法。与传统的方法相比,其主要特点在于:一是利用联合模型对古文进行分词与词性标注,并在此基础上进行知识图谱构建。利用深度学习方法对古文进行分词与词性标注[12]的研究相对较少,该文采用深度神经网络模型进行联合分词与词性标注,来获得更长距离的上下文关系进行分词与词性标注。二是根据词性标签进行实体抽取,根据丰富的词性标签抽取相应实体。该文主要介绍以《三国演义》为例的中国古典文学文本知识图谱构建的流程步骤,首先根据语料库的网页标签匹配整理生成分词与词性标注数据集,其次训练出更加适用于古典文学文本的联合分词与词性标注模型,并将最佳模型应用于《三国演义》。最终,在分词与词性标注结果的基础上进行实体与关系抽取,并以图数据库作为知识存储,进行《三国演义》知识图谱可视化查询。
1 知识图谱构建步骤
为了从非结构化的中国古典文学文本中构建知识图谱,定义了图1所示的构建步骤。主要分为三个部分:文本及语料库的加工整理、联合分词与词性标注、图谱及可视化查询系统的构建。

图1 知识图谱构建步骤
(1)文本及语料库的加工整理。
首先,从网上获得公开的Sheffield Corpus of Chinese (SCC)语料库[13],进行加工整理后,生成分词与词性标注数据集。关于SCC的介绍放在3.1节。
其次,从网上获得古典文学的电子文本,例如整本《三国演义》,并对其加工整理,去除其中的错误,使其可以作为测试样本输入深度神经网络模型。
(2)联合分词与词性标注。
使用《四库全书》预训练词向量[14],并将由SCC语料库得来的古文分词与词性标注数据集作为训练样本输入深度神经网络模型进行训练,然后对古典文学的电子文本(例如《三国演义》)进行分词与词性标注。
(3)图谱及可视化查询系统的构建。
首先,对《三国演义》分词与词性标注结果进行处理,即删除停用词,停用词包含虚词等无意义的词,得到具有意义的内容词,并进行人工修改错误的分词与词性标签,并且对人名进行匹配替换,将人名的简称词语替换为完整的人名。
其次,根据词性标签进行匹配抽取实体,依据词性标签定义几种实体,如人物、地点实体,并以动词词频信息为基础,人工定义几组关系,作为实体之间的关系。
最后,参照维基百科人工进行实体关系补充,将实体和关系分别作为图的节点和边,构建图谱与可视化查询系统。
2 联合分词与词性标注
2.1 LSTM
长短期记忆(long-short term memory,LSTM)[15]引入了输入门(input gate)、遗忘门(forget gate)、输出门(output gate)的概念,以及与隐藏状态相似的记忆细胞,从而记录额外信息。
t时刻的隐藏状态ht是关于当前时间的输出门ot和当前时间的记忆细胞ct的乘积,定义如下:
ht=ottanh(ct)
(1)
当输出门的值接近于1时,记忆细胞信息被传递到隐藏状态供输出门使用,当值接近于0时,记忆细胞信息只自己保留。其中,输出门定义如下:
ot=σ(Woxt+Uoht-1+Voct)
(2)
其中,σ为sigmoid函数,可以将值变换为0和1之间,Vo是对角矩阵。

(3)
(4)
遗忘门ft调节遗忘现有记忆细胞的程度,输入门it调节新的记忆细胞被添加到记忆单元的程度。遗忘门、输入门定义如下:
ft=σ(Wfxt+Ufht-1+Vfct-1)
(5)
it=σ(Wixt+Uiht-1+Vict-1)
(6)
其中,Vf和Vi为对角矩阵。
2.2 GRU
门控循环单元(gated recurrent units,GRU)[16]被提出来使每个循环单元自适应地捕获不同时间序列的依存关系。通过引入重置门(reset gate)和更新门(update gate)的概念,修改循环网络中隐藏状态的计算方式。
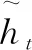
(7)
其中更新门zt决定需要从上一时间的隐藏状态中遗忘多少信息,需要加入多少候选隐藏状态信息。更新门的定义如下:
zt=σ(Wzxt+Uzht-1)
(8)
在现有状态和新计算状态之间进行线性求和的过程类似于LSTM,但是GRU没用单元来控制其状态显示的程度,但是每次都会显示整个状态。
(9)
其中,rt是重置门,⊙是逐元素乘法,当重置门的值接近于0时,那么就会丢弃上一时间的隐藏状态,当值接近于1时,那么就会保留上一时间的隐藏状态。
重置门rt的计算与更新门类似,定义如下:
rt=σ(Wrxt+Urht-1)
(10)
2.3 神经网络结构
该文采用的神经网络结构为BiGRU-CRF(bidirectional gated recurrent units using conditional random fields),如图2所示,汉字作为向量表示,被送入双向循环层。对于循环层,使用GRU作为基本循环单元,因为它具有相似的功能,但与LSTM相比,参数更少[17]。将Dropout[18]应用到双向循环层的输出,接着将输出进行串联并传递到一阶链CRF(conditional random fields)[19]层,最后预测组合标签的最佳顺序。

图2 BiGRU-CRF神经网络结构
2.4 标记工作
根据相关工作,单词边界采用的标签为B、M、E、S,分别代表单词的开头、内部、结尾或单个字符。在给定输入字符的情况下,CRF层对所有可能的组合标签上的条件得分建模。结合连续标签之间的转换分数,可以通过Viterbi算法有效地获取最优时序。
Viterbi算法的时间复杂度O(k2n)相对于句子长度n是线性的,其中k为常数,等于组合标签的总数。对于某些POS(part-of-speech)标签,将它们与完整的边界标签结合起来是多余的。例如,功能词“的”可以标记为FMI,由于它是一个单字,因此B-FMI、M-FMI和E-FMI的组合标签永远不会出现在实验数据中,因此应该进行修剪以减少搜索空间。同时,如果在训练数据中给定的POS标签下的最大单词长度为2,就会进行修剪相应的标签。
2.5 字符表示
通常,普遍的基于字符的神经网络模型假定,比如单词和n-grams形式的较大范围的文本,可以由它们所组成的字符序列来表示。例如,通过字符ci的向量表示vi传递给函数f来获得生成子空间cm,n的向量表示Vm,n。其中f通常是RNN或CNN神经网络。
Vm,n=f(vm,vm+1,…,vn)
(11)
在文中,不完全依赖使用BiGRU从无上下文的字符表示中提取上下文特征,如图3所示,通过使用增量式的级联n-gram模型对字符向量中丰富的本地信息进行编码。例如,给定上下文中的中心字“甚”的向量表示是上下文无关的字“甚”本身的向量表示Vi,i和二元bigram“此甚”的向量表示Vi-1,i,以及同理的三元trigram“此甚好”的向量表示Vi-1,i+1三者的级联。
不同于公式(11)中的字符表示来构造n-gram模型中cm,n的向量表示Vm,n,可以使用不同顺序来表示Vm,n,例如对Vi,i、Vi-1,i、Vi-1,i+1分别进行随机初始化。使用一个特殊的向量来表示每个序列中未知的n-grams,然后将不同顺序的n-grams进行增量式的级联来形成给定上下文的中文的向量表示,接着进一步传递给循环层。如图3所示,中心字两边相邻的字也都被考虑了进去。

图3 给定上下文的中文字符的向量表示
3 构建中各步骤结果展示
基于图1描述的框架来构建古典文学知识图谱,本节主要以《三国演义》为例,介绍和展示每个步骤中产生的重要结果。
3.1 文本及语料库的加工整理
SCC语料库(SCC语料库网址:https://www.dhi.ac.uk/scc/db/scc/index.jsp)选择的文本代表了不同时期发现的多种文本,时间段主要分为先秦、秦汉、魏晋南北朝、隋唐五代、宋元、明清,文本的类型根据不同的主题又可以分为文学类的戏剧、小说、民俗和诗歌,非文学类的传记、政府、历史、法律、医学、战争、哲学、宗教、科学和游记。文学类型的文本包含200 040个字符(46.2%),非文学类的文本包含232 630个字符(53.8%)。SCC语料库使用自然章节来对文学文本进行采样,因此采样文本的长度有所不同。例如,选取《三国志》魏书中的一章包含13 000多个字符,《三国志》蜀书中的两章包含9 000多个字符,《三国志》吴书中的两章包含13 000多个字符。整个SCC语料库中共包含40个文本样本超过42万个字符。词性标注包含18个基本词性类别及82个分类,共112个不同的标记标签。如名词又细分为朝代名、人名、地名、年份等等,分别使用词性标签“NNK”、“NNL”、“NNM”、“NNO”来表示。将网页显示的语料库通过加工整理,使用Xpath进行网页标签匹配,并使用OpenCC将繁体转化为简体,得到分词与词性标注数据集。
3.2 联合分词与词性标注
该文采用BiGRU-CRF神经网络模型,使用古文词向量作为预训练嵌入,这和传统的使用条件随机场模型不同。神经网络模型结构已在2.3节进行了详细的介绍。为了进一步说明使用联合模型的优点,进行了如下实验。对分词与词性标注数据集进行划分,将数据集的70%划为训练集,15%划为开发集,15%划分为测试集,最终,训练集的句子长度为45 070,开发集的长度为9 780,测试集的长度为10 208。对于深度神经网络模型,使用《四库全书》词向量(中文词向量下载地址:https://github.com/Embedding/Chinese-Word-Vectors)作为预训练嵌入,对不在预训练词汇表中的采用随机初始化的向量,使用误差反向传播算法对网络进行训练,在训练期间,所有的词向量都可以通过反向传播梯度进行微调。使用Adagrad[20]算法进行模型参数优化,初始学习率设置为0.1,衰减率为0.05,Dropout为0.5。使用准确率(precision)、召回率(recall)和F1值(F1-score)作为评估标准,Seg表示分词评估结果,Pos tagging表示词性标注评估结果,以词性标注结果作为最终的评估结果。最后,将训练的最佳模型运用于测试集,结果如表1所示。

表1 分词与词性标注结果 %
将BiGRU-CRF模型与CRF++、Bi-LSTM进行了对比,CRF++得到的最终F1值为74.97%,Bi-LSTM模型得到的最终F1值为82.70%,该文使用的BiGRU-CRF联合模型获得了最佳结果,最终F1值为84.21%。由于联合模型取得较好的结果,把它应用于一百二十回《三国演义》中,得到《三国演义》分词与词性标注结果。
3.3 知识图谱
通常在非结构化文本中,可以将句子划分为具有模糊意义的内容词和功能词,内容词所代表的实体是文本中的主要成分,但是功能词构成的句子也占据很大的成分,因此需要在《三国演义》分词与词性标注的结果中将虚词、功能词和标点符号构成的停用词进行删除,通常可以使用匹配的方式来删除。同时,由于分词与词性标注结果中仍然存在错误的分词与词性标签,需要人工进行修正,并且对于人名的简称,需要根据上下文进行匹配替换成完整的人名。该文采用词性标签匹配的方式进行实体抽取。根据古典文学的特点,使用了丰富的词性标签,对于朝代、人名、地名、年份等名词分别对应了不同的词性标签,例如将词性标签“NNL”、“NNM”分别作为人物实体、地点实体。
以第三十回为例,根据词性标签抽取出人物实体、地点实体,并以词云的方式进行展示,如图4所示。同时,参考高质量的数据源,如维基百科,根据维基百科进行实体补充,如添加“阵营”、“事件”、“时间”实体。

图4 人物、地点实体词云
对于实体之间的关系,主要根据人工进行定义。对词性标签带有“V”开头的动词类词语进行统计来确定主要关系基调,并以词云的方式进行展示,如图5所示,可以看出主要关系都是围绕战争主题。同样,根据维基百科人工进行关系定义,作为实体之间的关系。

图5 动词词云
最终,以第三十回为例,主要的实体关系类型如表2所示,根据“实体-关系-实体”的形式构建知识图谱,并以Neo4j[21]图数据库作为知识存储,如图6所示。

表2 实体关系类型
3.4 可视化查询系统
内容词是中国古典文学信息和知识的载体,由内容词派生的关键节点和链接代表了古典文学文本的知识信息。知识图谱的可视化[22]展示清晰地描述了关键内容词之间的关系,《三国演义》知识图谱可视化查询系统实体包含人物、地点、时间、事件和阵营,为了完整地描述《三国演义》知识结构,使用维基百科数据进行知识补充,如添加人物的简介、官职作为人物实体的属性等。其中人物实体共1 191个,地点实体175个,时间实体135个,事件实体83个,阵营实体43个。
《三国演义》知识图谱可视化查询系统使用图数据库Neo4j作为数据存储,使用Flask框架作为后端,使用D3.js框架作为前端可视化展示。前端页面通过jQuery发送查询请求,后端根据不同请求参数对应的视图函数进行处理,根据查询内容的类型,调用与之对应的cypher查询语句,并以json类型返回查询结果给前端。如图7所示,对于查询的实体,会显示该实体的所有属性,以及一跳距离内的相关实体,最后的整体效果为以查询实体为中心,展示出具有语义关系的相关实体形成网状结构。
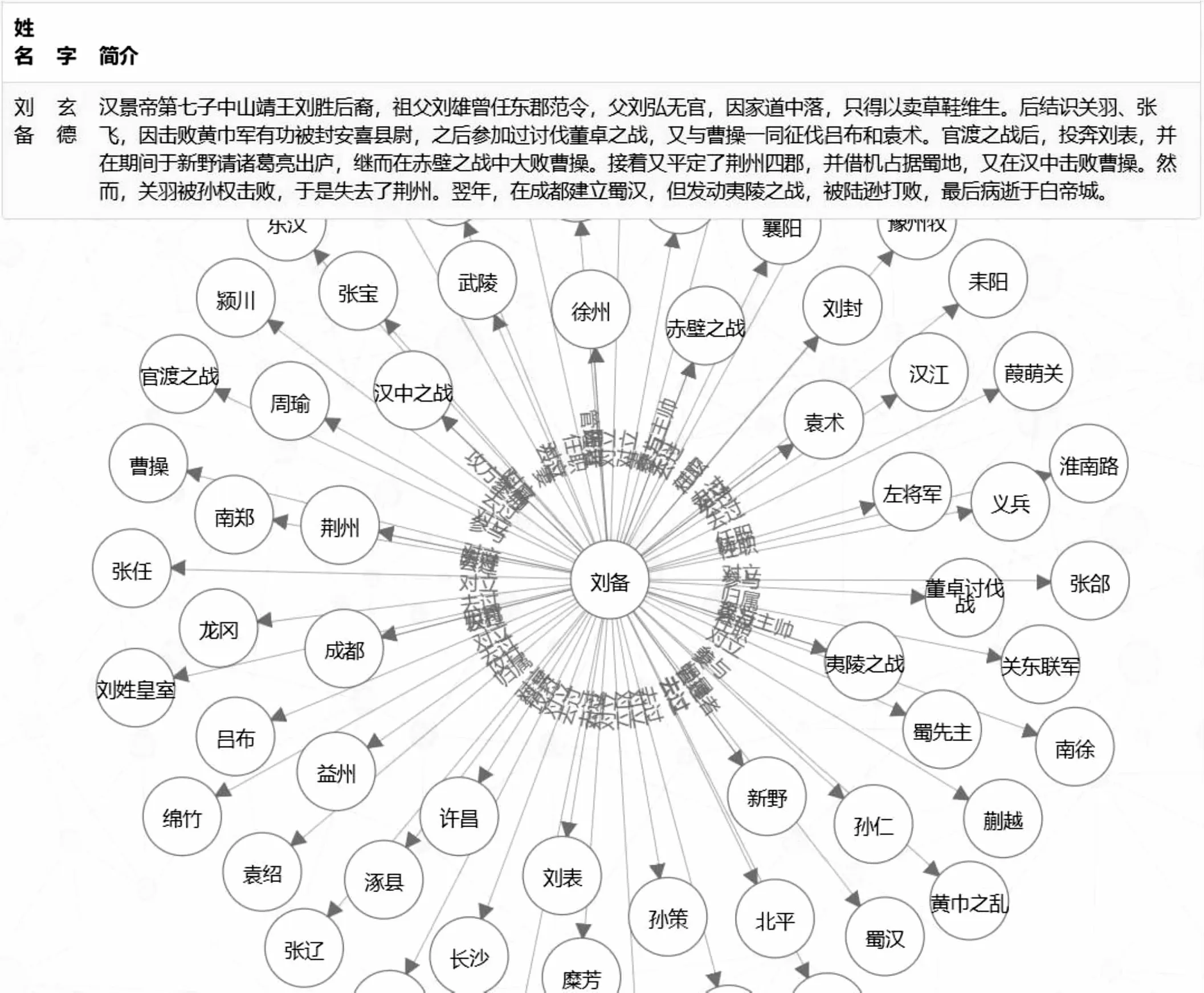
图7 《三国演义》知识图谱可视化查询系统
4 结束语
在这项研究中,采用了自然语言处理技术和知识图谱来抽取和可视化中国古典文学文本中的知识信息。这项工作对非结构化中国古典文学文本进行知识图谱构建提供了新的角度。主要结论:语料库生成的数据集提高了联合分词与词性标注的性能。根据词性标签抽取实体及词云显示了内容词在章节中的分布和比重情况,有助于抽取关键知识信息。知识图谱的可视化展示可以显示非结构化文本的隐藏知识信息。由于古文比较复杂而且相应语料库较少,所有目前这种基于联合模型的方法仅仅只能做到半自动化的构建图谱,一些实体抽取中的错误还需要人为修正。
未来的工作:知识图谱和原始古典文学文本之间的知识检索,知识图谱仅显示了关键节点和它们之间的关系,需要定向查询功能,来将原始文本中的详细描述链接到知识图谱的节点以进行检索。可以进行实体链接、指代消歧,抽取出更多的实体与关系,丰富知识图谱的知识结构。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
古典文学知识(2021年3期)2021-05-28
校园英语·月末(2021年13期)2021-03-15
时代人物(2020年11期)2020-09-26
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
古典文学知识(2018年5期)2018-09-28
新城乡(2018年6期)2018-07-09
古典文学知识(2009年1期)2009-03-19
