
基于BERT-FNN的意图识别分类
2021-07-27 02:59郑新月任俊超
计算机与现代化 2021年7期
郑新月,任俊超
(东北大学理学院,辽宁 沈阳 110004)
0 引 言
近年来,信息技术正冲击着传统产业,它为人们提供了便捷的服务,如智能机器人、智能客服、人机对话等,它们的迅速发展为用户提供了一种简单、方便的沟通方式。其中,意图识别分类是问答系统的核心任务,是提高系统整体性能的关键[1-3]。它主要利用句子的语义特征进行分类,是自然语言处理领域非常热门的研究方向和关键技术之一。
意图识别的目的在于理解某一句话的意图,基本思想是:首先根据文本语义信息,定义可能出现的意图类别,然后采用自定义的分类方法,将该语句划分到事先定义的类别中[4]。目前,意图识别分类的研究主要有3种方法。
一是基于规则、模板匹配的正则化方法。该方法针对特定问题,通过人工提取特定规则,来确定问题所属类型。如Ramanand等[5]提出了一种基于规则、模板匹配的正则化方法,将用户的消费意图进行分类。这种方法简单直接,易于解释且不需要大量的数据进行训练,但是规则制定繁琐,可扩展性不强,泛化能力差。
二是基于机器学习的方法。该方法通过对标注语料进行统计学习,把分类模型的选择和分类特征的提取作为重点研究对象[6]。常用的方法有逻辑回归、支持向量机、决策树等。陈浩辰[7]使用支持向量机和朴素贝叶斯进行意图识别分类研究。该方法首先需要构造特征工程,再对文本进行分类,导致理解文本深层的语义信息比较困难,特征的准确性无法得到保证,当数据集发生变化时,需要重新构造特征工程,时间复杂度较高,成本较高。
三是基于深度学习的方法。该方法主要通过自我学习方式,学习句子的内在语义和句法特征[8]。在意图识别分类研究中,常用的深度学习方法有卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)、注意力机制(Attention)、BERT等。
1)基于CNN的意图识别:Kim[9]提出了基于CNN的文本分类模型,Hashemi等[10]利用CNN模型进行特征提取,将用户的查询意图进行分类,该方法减少了大量的特征工程,简化了计算量,加快了求解速度,但只能提取文本的局部语义特征,导致准确率不高。
2)基于RNN及其变体的意图识别:Ravuri等[11]提出了使用RNN及其变体LSTM这2种模型,进行意图识别分类问题的研究,并进行比较分析,发现LSTM模型具有更好的建模能力和记忆能力,缓解了RNN反向传播优化网络权值时产生的梯度消失或爆炸的问题,但却依赖于过去的隐藏状态对当前单词进行预测,导致计算成本较高。RNN的另一个变种GRU是LSTM的一种改进[12],Ravuri等[13]通过实验发现GRU模型在意图分类任务上,性能与LSTM几乎相同,但GRU参数更少,收敛速度更快,可以防止过拟合。
3)基于Attention机制模型的意图识别:Lin等[14]提出了一种自注意力机制,代替LSTM和CNN结构作为特征提取器,使其并不依赖于过去的隐藏状态来对当前单词进行预测,而是从整体上处理一个句子,这样可以从多个角度理解句子的语义信息,对意图识别分类的研究有很大的帮助。Cai等[15]提出了CNN-LSTM模型,并引入Attention机制,捕获全局语义表达和局部短语级别的信息来理解用户意图,取得了不错的效果。
4)基于BERT的意图识别:BERT模型的发布被认为是自然语言处理领域一个新时代的开始,在11项NLP任务中均取得了领先成就[16]。Sun等[17]通过对比BERT的不同微调方法在文本分类任务上的性能,给出了一种较为通用的微调优化方法,并在多个文本分类数据集上进行试验,均取得了显著的效果。
由于结合深度学习方法FNN及BERT在NLP领域的绝对优势,本文提出一种基于BERT-FNN的意图识别分类方法,首先以Google公开的BERT预训练语言模型为基础,进行输入文本的语义表示,再通过FNN对语句进行特征提取,并输入到sigmoid激活函数中进行分类。最后,与逻辑回归(LR)、支持向量机(SVM)、LSTM、BERT进行对比,实验结果表明,本文提出的BERT-FNN模型,在意图识别分类任务上可以获得94%的准确率,具有良好的性能。
1 模型构建
自从2018年10月底,谷歌宣布了BERT在文本分类、命名实体识别等11项自然语言处理任务中的出色表现后,BERT模型就被认为是自然语言处理领域新时代的开始[18]。它将重点集中在通过预训练产生词向量,而不是解决具体下游任务上,通过BERT预训练模型生成的词向量,相对于one-hot、word2vec、glove等静态词向量而言,解决了一词多义的问题;相对于ELMo、GPT等动态词向量而言,加强了提取特征的能力,主要是因为ELMo利用Bi-LSTM提取特征,能力有限,GPT利用单向Transfomer-decoder提取特征,只能处理左侧的上下文,然而BERT利用双向Transfomer-encoder提取特征,可以根据当前词的上下文建模,使模型具有理解语句含义和提取语句特征的能力[19]。
FNN层通过增加隐藏层及神经元节点的数量,来获取更深层次的特征,并通过对前层的特征进行线性加权求和,将特征表示整合成一个值,从而减少特征位置对于分类结果的影响,将特征空间通过线性变换映射到样本标记空间,从不同角度对输入数据进行分析,得出该角度下对整体输入数据的判断,提高了整个网络的鲁棒性。
本文提出的基于BERT-FNN的意图识别模型由输入层、BERT层、FNN层、分类层组成,具体如图1所示。
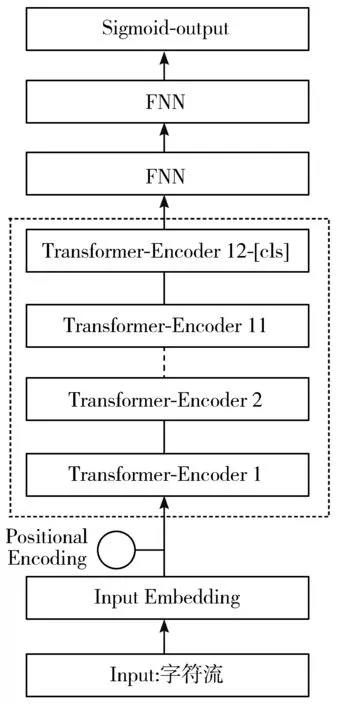
图1 基于BERT-FNN的意图识别模型结构
1.1 BERT层
1.1.1 BERT词向量层
在BERT的词向量层中,将字变量(Token Embedding)、文本向量(Segment Embedding)和位置向量(Position Embedding)三者的和作为模型的输入[20],其中字变量指的是在BERT模型中,通过查询字向量表,将文本信息中的每个中/英文转化为一维向量;文本向量指的是在模型训练过程中,通过自动学习来刻画文本的全局语义信息,并与单字/词的语义信息相融合;由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我喜欢你”和“你喜欢我”),因此BERT模型引入位置向量对不同位置的字/词分别加以区分。
目前,BERT预训练模型直接将单个字词作为构成中文文本的基本单位,并未分词,且在起始位置需要附加一个Token,记为[CLS],对应模型的输出,用于表示整个句子的语义信息,并将其用于具体下游任务。在区分2个句子的句间关系时,BERT预训练模型使用一个特殊标记符[SEP]进行分割,具体如图2所示。
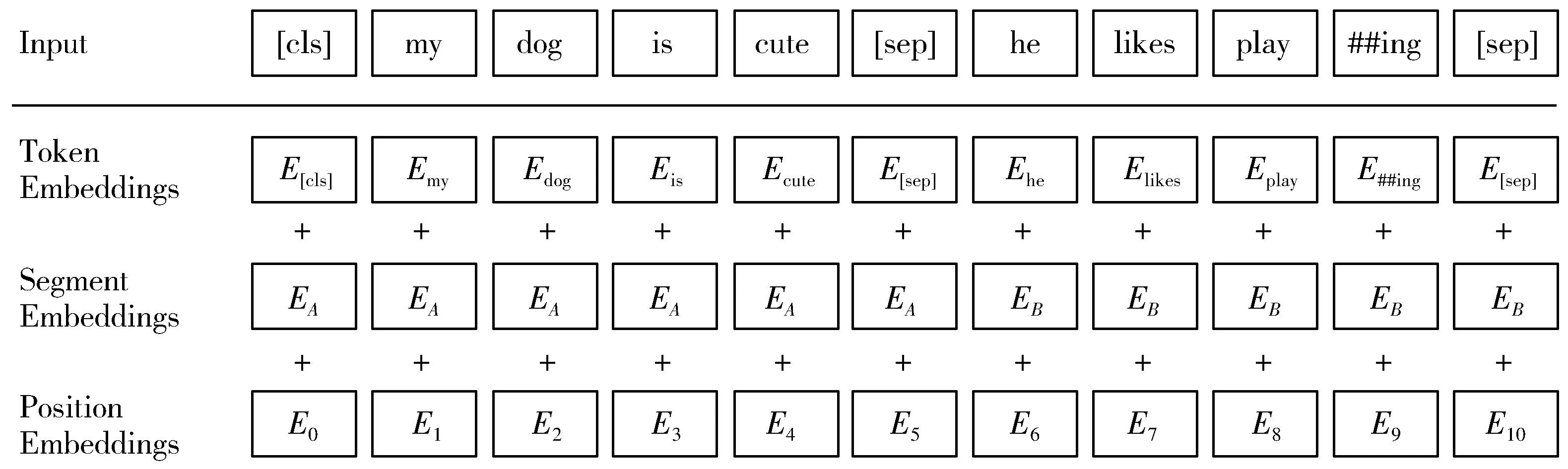
图2 BERT词向量层的具体结构
1.1.2 BERT主模型结构
由于BERT是预训练语言模型,只需要编码学习语义关系,不需要解码完成具体的任务,因此采用Transformer-Encoder模型[21],通过大量文本进行预训练,得到当前序列的向量表示。Transformer是基于自注意力机制(self-attention)的深层模型[22],采用attention代替LSTM结构提取特征,从整体上处理一个句子,而并不依赖于过去的隐藏状态来捕获对当前单词的依赖性,这样可以从多个角度理解句子的语义信息。因此BERT在文本分类、命名实体识别、文本生成等多个自然语言处理任务上取得了不错的效果,基本结构如图3所示。
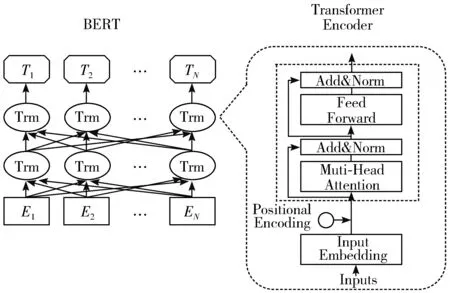
图3 BERT主模型结构
1.1.3 BERT预训练目标
事实上,BERT是语言模型,预训练过程的实质是通过不断调整模型参数,使模型输出的语义特征尽可能地刻画语言的本质。该模型包含2个预训练目标:掩码语言模型(Masked Language Model)和预测下一句文本(Next Sentence Prediction)。
1)Masked Language Model。
Masked Language Model是指在模型预训练的过程中,从原始文本信息中随机遮挡(mask)一些单词,然后通过BERT模型利用上下文的语义信息预测该单词。具体的执行过程是:将一句文本信息多次输入到模型中进行参数学习,然后随机选择15%的单词被Mask,但这些单词并不是每次都被Mask,会有80%的概率直接将其替换为[Mask],10%的概率替换为其他任意单词,另外会有10%的概率保留原始Token不变。这样做的好处是:在模型预训练过程中,对单词进行预测时,模型本身并不知道该单词是否是正确的单词,这就迫使模型依据上下文信息来预测单词,从而增强模型的泛化能力[23],具体过程如图4所示。
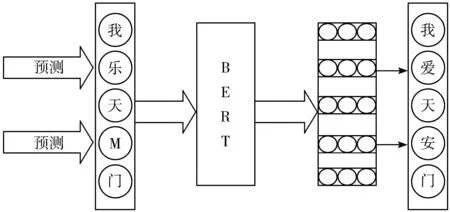
图4 Masked LM过程示意图
2) Next Sentence Prediction。
NSP的主要任务是判断2个语句是否是上下文的关系。如果是,则输出True,否则,将输出False。其中训练数据指的是从语料库中随机抽取的2个连续句子,这2个句子有50%的概率符合上下文的关系,另外50%的概率是从语料库中随机抽取的,它们并不符合上下文的关系。该过程可以增强模型对上下文的把控能力。BERT将2个预训练任务NSP与Masked Language Model相结合,这样做的好处是:能够让模型更准确地理解文本想表达的语义信息,具体过程如图5所示。
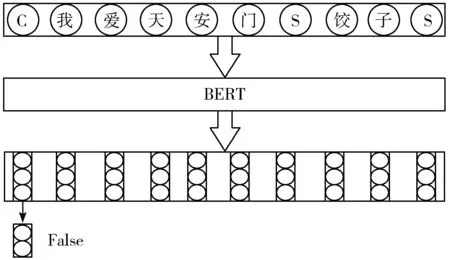
图5 Next Sentence Prediction过程示意图
1.2 FNN层
目前,许多深度学习模型均连接FNN层进行深层特征的提取,并且取得了良好的效果[24],原因在于它不像以往利用模板匹配的方式提取特征,或基于机器学习的方法构造特征工程,而是通过增加隐藏层及神经元节点的数量,获取更深层次的特征,并对前层的特征进行线性加权求和,从而将特征整合,减少特征位置对分类结果的影响,从不同角度对数据进行分析,提高了整个网络的鲁棒性。其核心操作是矩阵向量乘积,若设输入向量为:
X=[X0,X1,…,Xn]T
(1)
设输出向量为:
Y=[Y0,Y1,…,Yn]T
(2)
设偏置为:
b=[b0,b1,…,bn]T
(3)
设经过激活函数计算后的输出向量为:
Z=[Z0,Z1,…,Zn]T
(4)
其中,参数可以表示为矩阵W,矩阵W的大小是m×n,再加上偏置项b于是有:
Y=W×X+b
(5)
Z=sigmoid(Y)
(6)
用反向传播算法来最小化训练模型的误差,根据下式,使用随机梯度下降法对权重和偏置项b进行更新求解:
(7)
(8)
其中,θ为学习率,L为损失函数,T为时间。该函数的选择与激活函数的种类及选择哪种学习类型(如有监督学习、无监督学习)有很大的关系。
1.3 分类层
在该层中,对输入数据通过加权增加神经网络模型的非线性,获取用户意图的语义表示,然后计算每个标签的得分向量,最终输出分类标签。
为了充分利用数据,本文利用拆解法的思想,将多分类问题拆分成多个二分类问题,每次将一个类别作为正例,其余类别均作为负例,产生多个二分类任务,从而实现意图多分类。简单来说,就是将模型的激活函数由softmax调整为sigmoid,输出各类别的概率。softmax计算方法如下:
(9)
sigmoid计算方法如下:
(10)
该模型的损失函数使用的是二分类交叉熵损失函数的累加和,而并没有使用多分类交叉熵损失函数,这样做的好处是:
1) 充分利用“负例”:多分类交叉熵损失函数仅考虑正例损失,丢失了许多有价值的数据,而二分类交叉熵损失函数对于“负例”也计算损失函数,提高了整体数据的利用率。
2)适应真实场景:真实的语料可能会同时表达多个意图,在语料存在多种意图的情况下,使用sigmoid激活函数有机会将意图都识别出来。而使用softmax激活函数则很难将意图都识别出来。
2种模式的损失函数如下:
(11)
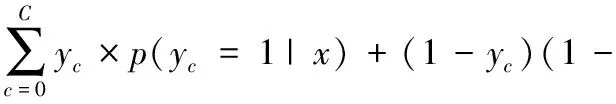
p(yc=1|x))
(12)
2 数据实验与结果分析
本章通过实验来验证本文提出的BERT-FNN模型在用户意图识别任务上的性能,然后将其与其他模型的性能进行对比分析。
2.1 实验数据与评价指标
本文所使用的数据集包含16万条自然语言语句,涉及价格介绍、告知地址、提供官方网站等共10种意图类别,将20名标注人员分成5组,分别对数据集某一部分的意向类别进行标注,然后,通过匹配每组的语料库标注结果,去除不一致的部分,最后,对每组标签一致的数据进行合并,得到15万条语句。其标注结果及实验语料例句如表1所示。
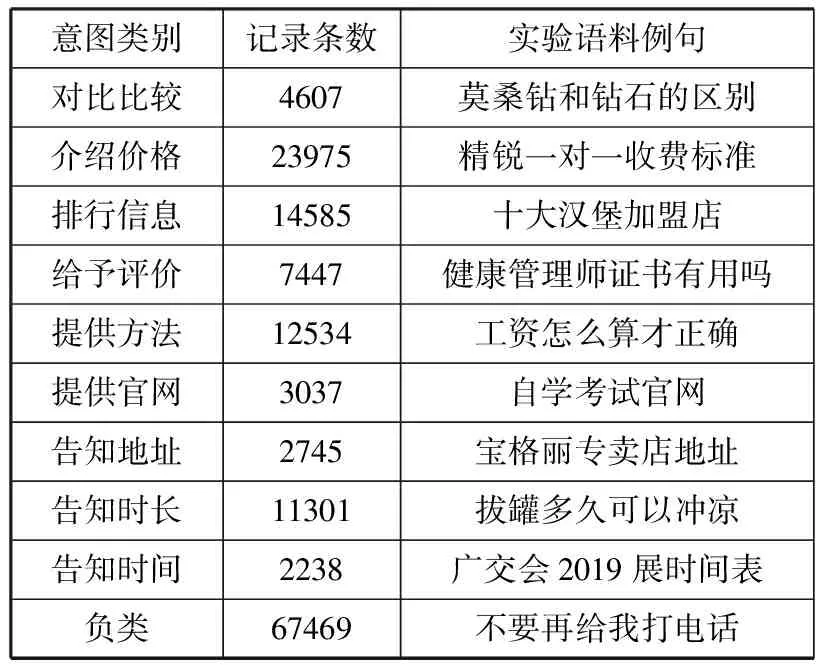
表1 意图类别标注结果
为了验证本文所提方法的有效性,在实验过程中,将训练集分为80%的训练集、10%的测试集、10%的验证集。
因为用户意图识别属于多分类问题,本文采用精确率(precision)、召回率(recall)及F1值对每种意图类别进行评价,具体计算公式如下:
precision=TP/(TP+FP)
(13)
recall=TP/(TP+FN)
(14)
F1=2PR/(P+R)
(15)
其中,TP表示数据集中被判定为正类,实际也为正类的样本数;FP表示数据集中被判定为正类,实际却为负类的样本数;FN表示数据集中被判定为负类,实际却为正类的样本数;P代表精确率,R代表召回率。
2.2 环境配置
本文实验选用的研发环境、电脑软硬件配置详细信息如表2所示。
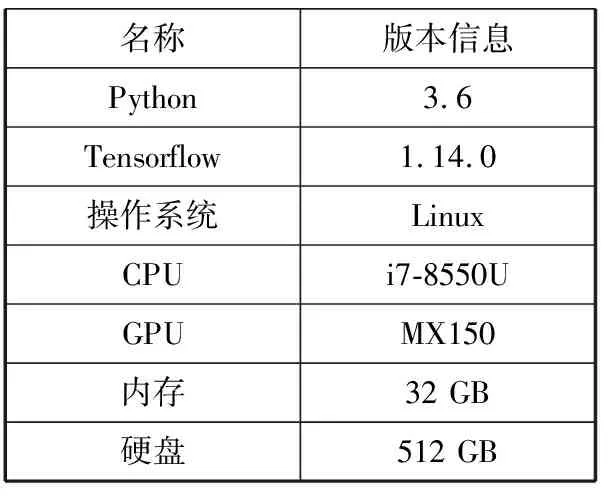
表2 实验环境软硬件配置
2.3 实验参数设置
实验过程中,以BERT预训练语言模型为基础,采用[cls]token对应的向量表示上下文的语义信息,以FNN和sigmoid激活函数为最终分类器,搭建了BERT-FNN模型来识别用户意图。不同参数的组合与设置会对实验产生不同的效果,本文基于Tensorflow深度学习框架,模型参数设置如表3所示。
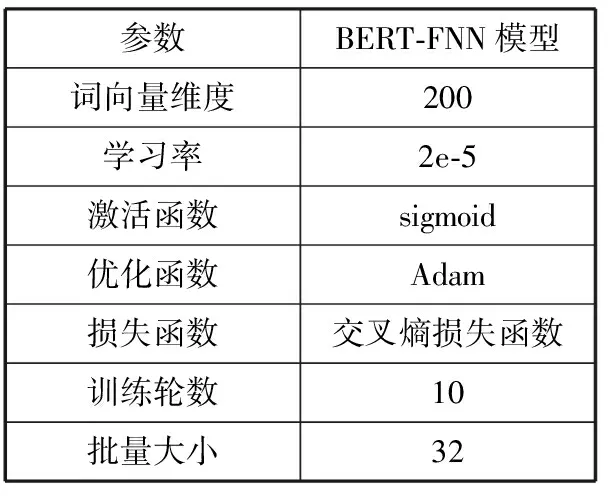
表3 模型参数设置
2.4 实验结果与分析
为了验证上述BERT-FNN模型的可行性和有效性,本节分别选用逻辑回归(LR)、支持向量机(SVM)、LSTM、BERT进行对比实验,并对实验结果进行评估。
其中LSTM使用word2vec方法生成的词向量作为原始输入,相比于利用one-hot生成词向量而言,word2vec会考虑上下文,维度更少,速度更快,效果更好,可以用在NLP各项任务中,通用性更强。
在测试集上,不同方法整体分类性能对比结果如表4所示,不同方法在各个意图分类中F1值比较如表5所示。
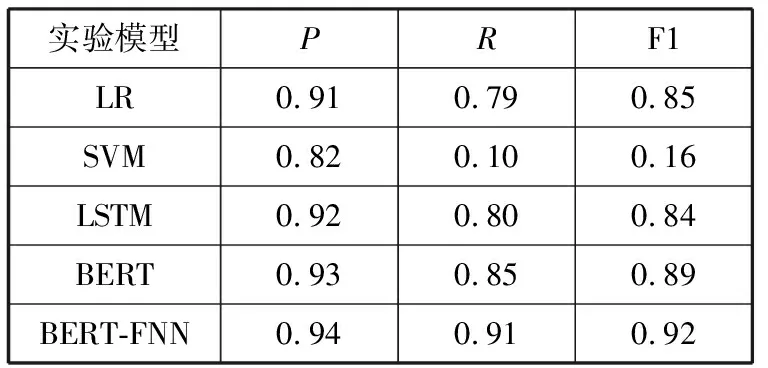
表4 不同方法对比实验结果
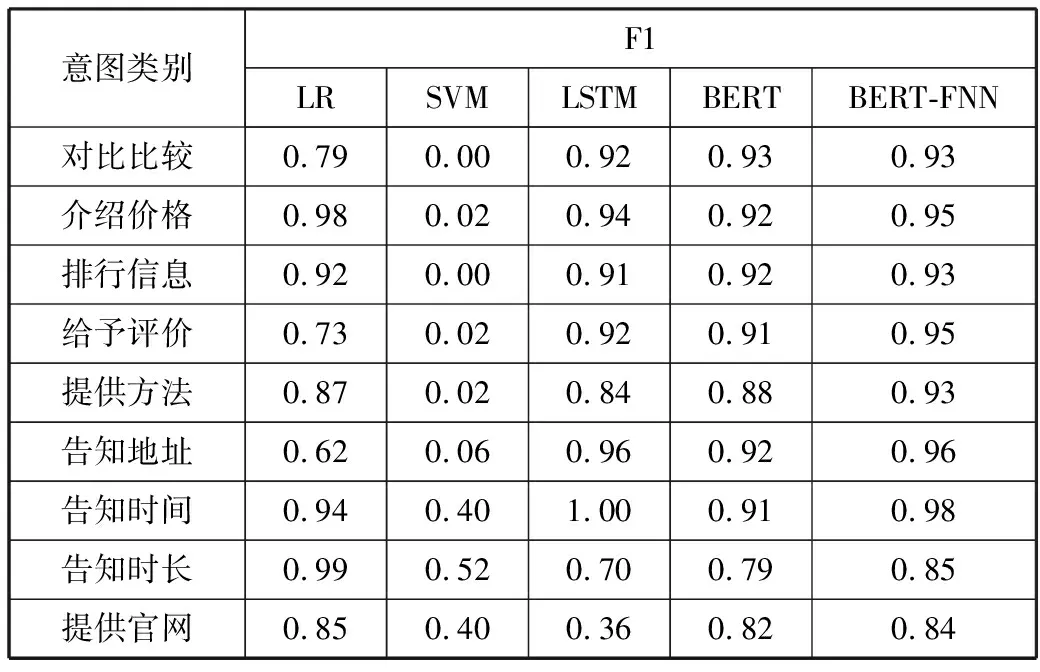
表5 不同方法在各个意图分类中F1值比较
由表4、表5可知,本文提出的基于BERT-FNN的混合神经网络意图识别模型,具有良好的表现,在准确率、召回率及F1值的表现性能均优于其他方法。
SVM方法的意图识别分类效果最差。究其原因在于,SVM难以选择一个合适的核函数解决非线性问题,且SVM基于特征工程,以词或句法结构作为分类特征,难以获取句子的深层语义信息,识别度低。
LSTM方法相比于传统机器学习方法,各项性能均有明显的提升。原因在于其具有可以学习序列信息的能力,更加充分提取句子的特征,从而实现了分类性能的提升,但当序列长度超过一定限度后,仍存在梯度消失的问题。
相比于LSTM方法,BERT模型在意图识别分类问题上更有优势,解决了单向信息流问题,使其并不依赖于过去的隐藏状态来对当前单词进行预测,能够充分捕获句子特征信息,这样可以获取句子的多种语义信息,进而提高分类性能,提高意图识别准确率。
相比于BERT模型,本文使用BERT-FNN模型效果更显著,主要是因为FNN对前层的特征进行线性加权求和,从而将特征整合,减少特征位置对分类结果的影响,从不同角度进行分析,提高了模型的准确率。通过对比实验可以看出,本文提出的BERT-FNN模型在意图识别分类任务上具有良好的表现。
3 结束语
本文提出了一种基于BERT-FNN模型的意图识别分类方法,该模型以Google公开的BERT预训练模型为基础,进行输入文本的上下文建模和句级别的语义表示,采用[cls] token对应的向量代表文本的上下文,再通过FNN进行深层特征提取,与传统模板匹配、机器学习方法以及现有的较好深度学习方法相比,本文提出的方法具有良好的性能,可以较好地理解用户的意图,解决了传统方法在意图识别分类上的泛化能力差、理解文本深层次的语义信息较困难、计算成本较高等问题。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
法律方法(2021年3期)2021-03-16
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
