
基于主动学习的命名实体识别算法
2021-07-27 02:59:54张岑芳
计算机与现代化 2021年7期
张岑芳
(南京理工大学计算机科学与工程学院,江苏 南京 210094)
0 引 言
命名实体识别(Named Entity Recognition, NER)是信息抽取(Information Extraction)的一个子任务,作为自然语言处理领域的关键技术,主要任务目标是在句子序列中提取人名、地名、机构名等命名实体[1-2]。
早期的命名实体识别技术主要通过模式匹配或者统计的方法进行实体提取与标注。模式匹配[3]主要通过基于规则的方法实现,即通过人为构建各类实体的统一规则,再从任意文本序列中提取出符合指定规则的命名实体,例如NTU系统[4]、FAILE系统[5]等,使用这种方法得到的模型虽然能够在一定的范围内发挥作用,但模型规则的制定依赖大量的人工,对于不同的语言需要指定不同的规则,因此费时费力,成本高昂[6]。基于统计的方法实现的模型主要依据概率学的一些假设,从大量文本语言中提取出特征,对人类语言进行建模,通过序列标注[7](Sequence Labeling)将文本序列中的字或词对应到预先设计的标签系统上,实现命名实体识别。统计模型依据语言的统计特性,可以适应不同的语种,具有一定的普遍性[8]。例如隐马尔可夫模型[9](Hidden Markov Mode, HMM)把文本序列看作观测序列,将标签序列看作隐藏序列实现文本建模。最大熵马尔可夫模型[10](Maximum Entropy Markov Models, MEMM)通过加入上下文特征,增强了模型对文本特征的捕获能力。条件随机场[11](Conditional Random Field, CRF)在MEMM的基础上结合HMM加入了对模型输出的约束,提高了模型的准确率。曹波等[12]基于最大熵[13]原理结合最大概率分词法与Viterbi算法分别进行分词和角色标注,在1998年的人民日报语料中取得了89.43%的识别精度。
随着神经网络的复兴,深度学习逐渐成为命名实体识别的重要方法。Collobert等人[14]提出的NN/CNN-CRF是较早应用到命名实体识别的神经网络模型之一,作者在该文中提出了窗口方法和句子方法2种输入层进行句子特征的提取。窗口方法仅使用当前预测词的上下文窗口进行输入;句子方法加入了词在句子中的相对位置。特征的表示通过词袋实现,采用查找表的方式学习隐藏特征。模型的输出采用了传统的Softmax[15]和CRF这2种目标函数。CRF是一种句子级别的对数似然,在处理序列标注问题时有一定的优势。作者也通过实验验证了加入CRF后模型在NER上的效果有明显提升。Lample等人[16]提出了使用字符特征和词特征结合的方法,使用预训练的词嵌入向量作为输入,通过Bi-LSTM-CRF[17]模型实现NER的标签预测。禤镇宇等人[18]提出了通过组合字向量、边界特征和用字特征的Bi-LSTM-CRF模型在影评数据的人名实体识别中取得了89.7%的识别精度和94.26%的召回率。
在命名实体识别的过程中,不论是传统方法还是基于神经网络的方法,都需要大量的人工去制定规则或者对数据集进行标注[19]。主动学习[20]通过选择算法从无标注数据集选择特征明显的数据由人工标注构成适合模型训练的数据子集,减少对类似数据的标注,降低人工标注的成本。文献[21]将主动学习应用于命名实体识别中,通过基于池(pool-based)的主动学习方法,实现了使用40%左右标注样本集达到使用全部样本集的效果,验证了主动学习在命名实体识别这类序列标注任务中的有效性。基于池的主动学习通常是离线、反复的过程,通过迭代不断选择样本加入训练集,直到达到预设条件或者预算用尽为止。基于池的主动学习的选择算法通过评价每个样本对模型的价值,并通过排序选择价值高的样本进行人工标注。基于池的主动学习处理样本的灵活性不高,不能动态地加入样本。本文研究基于流(stream-based)的主动学习,从部分样本集中选择有效的样本进行人工标注,选择算法是建立在对单个样本的价值评价上的。
1 结合主动学习的命名实体识别算法
本文通过2个模型分别进行实体位置标记和实体角色标注。算法基本流程如图1所示,实体位置标记模型从文本序列中提取出可能的实体位置。位置标记模型获取句子序列中值得关注的多个子序列,实现对实体序列位置的获取。实体分类对这些子序列进行分类,实现实体的类别判断。样本价值计算通过构建关于实体位置标注结果和实体分类结果的函数计算出样本的价值,决定是否对其进行标注。当标注样本的增量达到一定的数量后,使用新的标注样本集对模型进行训练。
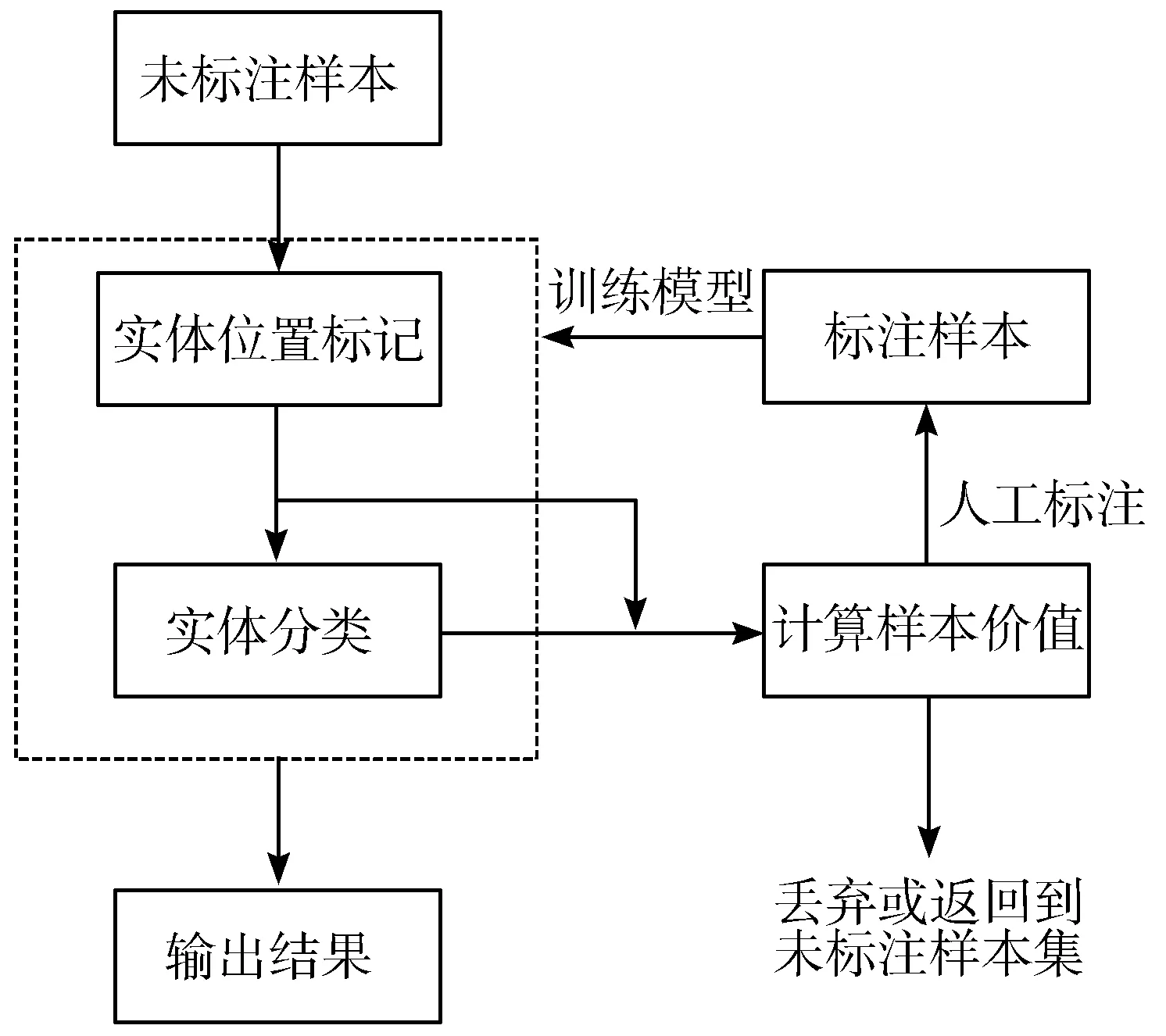
图1 算法训练流程
1.1 实体位置标记
实体位置标记模型主要对实体的位置进行标注。实体位置标记的过程类似于分词,目的是获得目标实体的边界。图2为这一层模型的具体结构。模型的输入是文本序列,输出是标签序列。输出的标签有3个类别:B、I和O。其中B代表实体的开始,I代表实体后续的部分,O表示非目标实体。
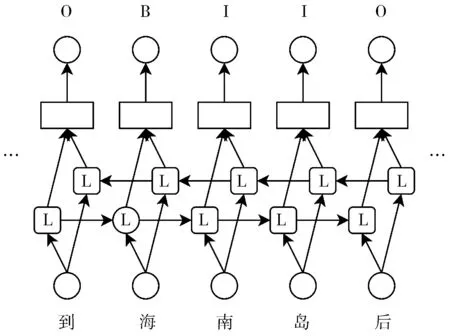
图2 实体位置标记模型
传统的神经网络模型直接预测实体的标签。当使用BIOES的标注方法时,每个实体类别都要对应4个标签,例如对人名的标记需要用到B_nr、I_nr、E_nr和S,分别表示人名实体的开始、内部、结束和单字实体。当需要对多个实体类别进行标注时,就会出现由于标签数量爆炸造成的模型效果不佳。文献[22]中的模型在MSRA数据集(3类实体,7种标签)上的召回率达到了94.48%,而在Weibo数据集(5类实体,16种标签)上的召回率只有66.83%,不排除由于标签数量过多造成模型效果下降。因此将对实体位置和类别的提取更改为仅提取序列中实体的位置,减少标签数量,实现对模型的简化。
1.2 实体分类
在传统方法中,可以通过规则的方法确定实体类别,例如,对于文本序列“***公司”,基本可以确定这是一个机构名。但是规则的构建需要大量的人力成本,且随着实体类别的增多规则会更加复杂。本文使用Bi-LSTM网络[23]进行实体分类,结构如图3所示。将可能的实体序列经过词嵌入后输入到新的Bi-LSTM网络中。将Bi-LSTM网络所有时刻的输出进行拼接,经过线性层输出,来预测实体所属的类别。并且添加了非实体的标签用来检测模型1输出的结果表示不合法的实体序列。
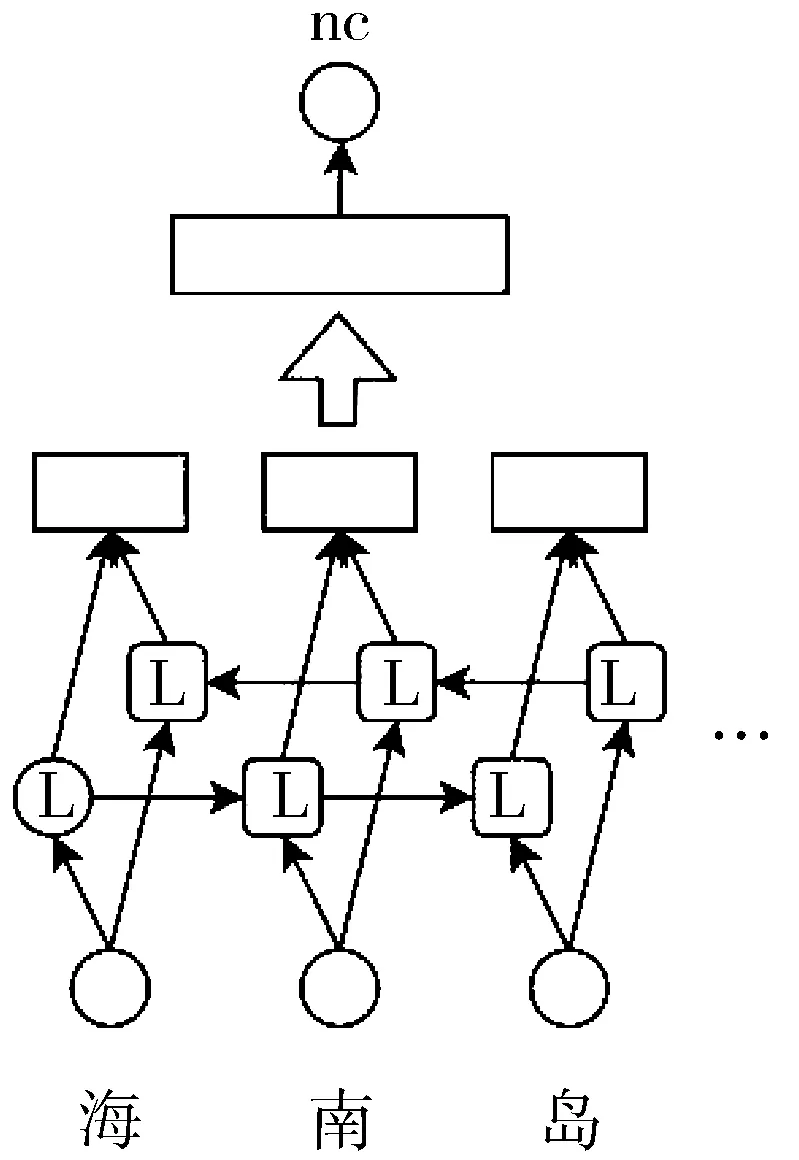
图3 实体分类模型
设hi是模型中Bi-LSTM的输出序列,确定实体与非确定实体类别的判定如式(1)所示。其中W和b分别为线性层的权重和偏置。O为hi拼接后经过激活函数为softmax的线性层后的输出,向量O的维数比实体类别个数多1,分别用来表示每个实体类别和非实体。非实体指从模型1提取出输入的序列是错误的、非法的,不能够对应任何实体类别。而且只有当oi大于阈值σ时,才确定输入序列为确定实体。否则为非确定实体,通过人工进行判定后确定类别,加入已标注实体集对模型2进行迭代训练。
Ο=W·[…hihi+1…]+b
(1)
对于模型嵌入层[24]的选择有2种方案,第1种方案是直接复用实体位置标记的嵌入层,第2种方案是使用新的嵌入层。复用的方法可以实现特征的相互联系,但同时也引入了无用的特征,增加了特征的复杂度。本文建立了新的嵌入层,这样可以区分模型的主要优化目标。实体位置标记关注于句子的上下文和不同实体序列的区分度,而实体分类关注于实体序列内部的信息。
1.3 主动学习
对大量的句子进行NER标注需要昂贵的人工代价,而且对于信息迭代速度快的互联网文本信息来说,从大量文本中获得价值更高的样本来优化模型,是值得研究的内容。传统基于池的主动学习的样本选择的实现通过对样本集中样本的价值进行排序,筛选出价值高的样本进行标注,实现模型从部分样本集中获得全体样本的特征。模型获取全体样本特征的速度取决于样本选择策略,好的选择策略可快速获得价值更高的样本。基于随机采样策略(Random Sampling, RS)是最简单的选择策略,通常作为最基础的对比实验。另一种查询策略是基于不确定性采样的方法,最不确定指标(Least Confidence, LC)将预测概率的最大值的相反数作为样本的不确定性分数,计算公式如式(2)所示。y1,…,yn表示Bi-LSTM解码后最可能的标签序列,因为确定最佳的标签序列是困难的,因此使用最大的概率值来近似不确定分数。
(2)
归一化对数可能性(Maximum Normalized Log-Probability, MNLP)用正则化的对数概率表示不确定分数,解决LC分数中对长句子的倾向。
在进行实体分类时使用边缘采样(Margin Sampling, MS)表示分类结果的不确定分数。这里的y表示实体属于某一类别的概率,用最可能的2个类别的概率的差表示其不确定分数。
(3)
在基于流的主动学习中,由于不能同时对全体样本计算不确定性分数,因此无法通过排序的方法进行样本选择。本文通过维护样本选择阈值σ来决定是否选择样本。
(4)
其中,si为当前样本的不确定性分数,σi为当前阈值,如果si>(1-γ)×σi,当前样本将被选择进行人工标注,否则丢弃当前样本。σi维护了历史所有样本的不确定分数的平均值,γ决定了需要样本标注的比例。样本选择阈值σ维护实现了对任意样本不确定性大小的判断。
2 实验与分析
本文使用2个数据集对提出算法的命名实体识别效果进行测试。一个是SIGHAN 2006竞赛数据集MSRA,另一个是来自中文网络社交媒体微博2010年后的微博正文,通过网络爬虫获得并通过本文的选择算法对样本进行筛选。数据集的详细信息如表1所示。
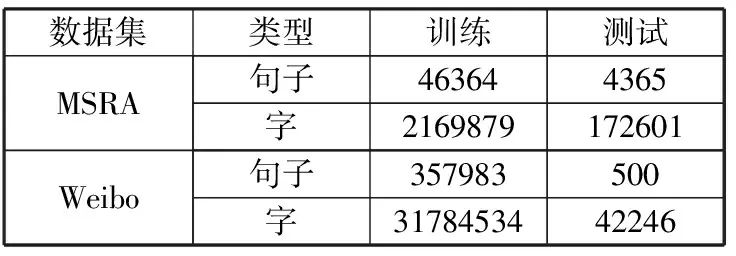
表1 数据集统计
MSRA数据集在训练过程中,为了模拟类似流的样本获取方法,将样本逐一输入模型计算不确定分数,丢弃的样本放回原样本库。来自微博的网络文本通过计算不确定分数后进行人工标注或者直接丢弃。将训练集拆分为10份,以一定比例的数据标注训练集,其他部分以未标注数据集的形式通过迭代依次加入,以此来测试模型对新数据的接受能力。对于微博数据集,将训练集与验证集合并分为3份进行测试。
命名实体主流的标注模式分为BIO标注以及BIOES标注2种方式。本次实验使用BIO标注方式,在实体位置标记中只用B、I和O共3种标签,B表示实体首字,I表示实体非首字,O表示非命名实体。实体位置标记过程不对实体类别进行区分。
MSRA数据集包含人名(PER)、地名(LOC)和机构名(ORG),添加非实体标签(O),实体分类共输出4个类别。对来自网络的微博数据设计了地名(LOC)、机构名(ORG)、人名(PER)和地理政治实体名(GPE)共4类实体,实体分类输出共5个类别。
本文实验采用在测试机上的F1值作为算法准确性的评价指标,正确地识别出一个实体的位置和类别为正例。计算公式如下:
(5)
实体位置标注模型中设置单句最大长度为128,输出共有3类标签(B、I、O)用来区分实体边界。实体分类中设置词的最大长度为10,2个模型都使用交叉熵损失函数。使用Adam优化器进行梯度下降训练,设置学习率0.001,batchsize统一设置为64。在选择算法的使用上,对于MSRA数据集,使用γ=0.5,表示每一个样本被选择的概率期望为0.5。在使用来自微博的数据时,考虑到爬虫能够方便地获取样本,但人工标注成本高,因此设置γ=0.1,进一步提升选择出的样本质量。
图4展示了在MSRA数据集上的不同选择策略的实验结果。所有主动学习的算法都优于随机选择策略。通过对样本的选择性标注,模型使用40%左右标注数据便获得了全部数据集的特征。MNLP指标平衡了句子长度对选择结果的影响,结果优于LC指标。在结合实体位置的标签概率和实体分类结果的概率作为选择依据时(LC/MNLP+MS),增添了对实体类别的考虑,开始时没有仅用LC/MNLP选择的样本质量高,随着实体位置识别准确度提高,选择的样本质量变高。说明在选择样本时综合考虑两者可以提升效果,但需要通过权重或其他方法平衡两者对总的不确定分数的贡献。
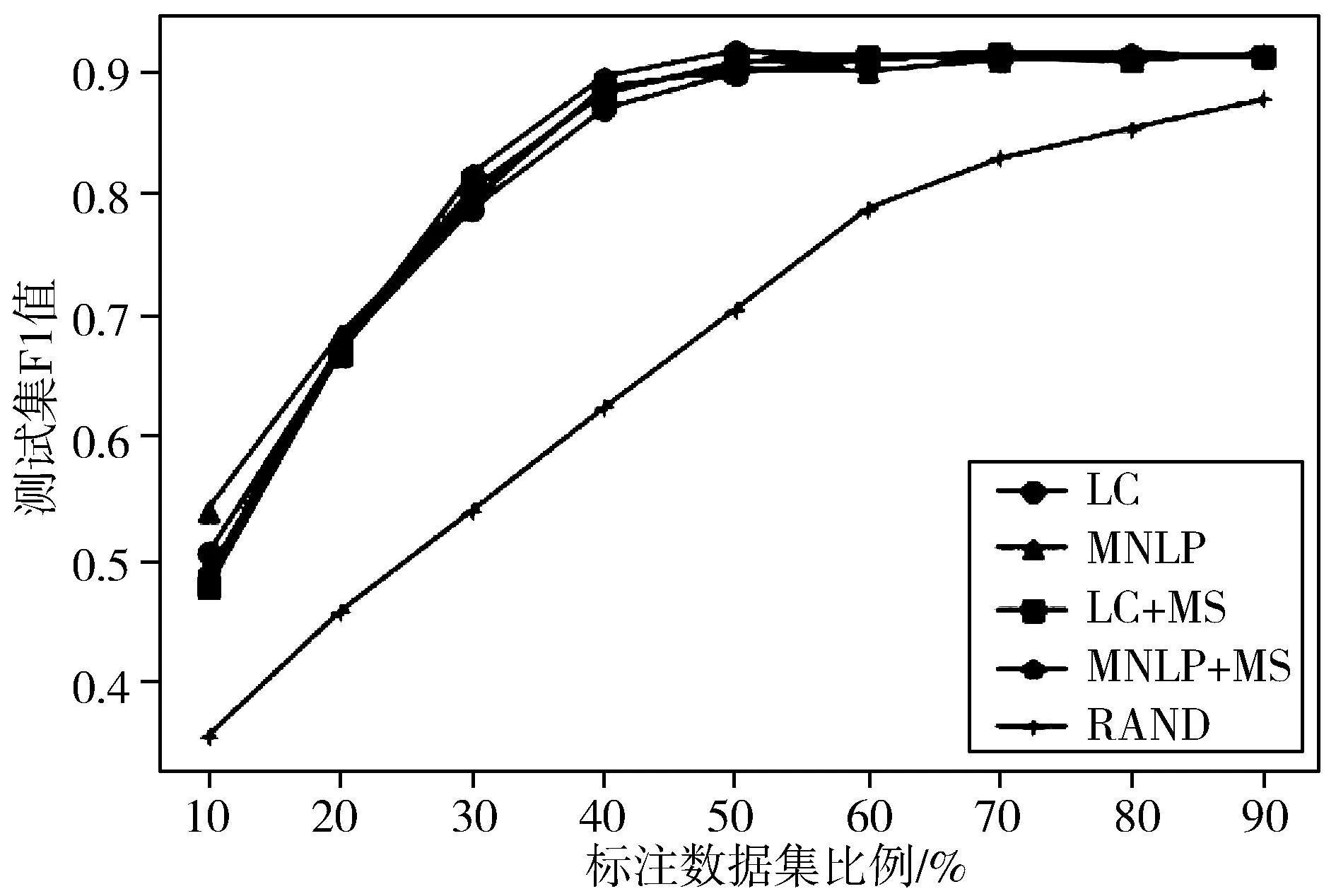
图4 不同选择策略的比较
如图5所示,为了进一步验证该选择算法可以满足基于流的主动学习,首先通过爬虫从微博中获取500个句子通过人工标注作为测试集。然后通过爬虫动态获取样本,分别使用MNLP+MS选择算法和RAND选择算法,验证本文算法的适用性。通过对比可以得出,有效的选择算法能获得更有益于模型的样本。与随机选择相比,基于MNLP+MS的选择算法得到的数据集更具有整体数据的代表性,因此得到的模型能更快达到预期效果。
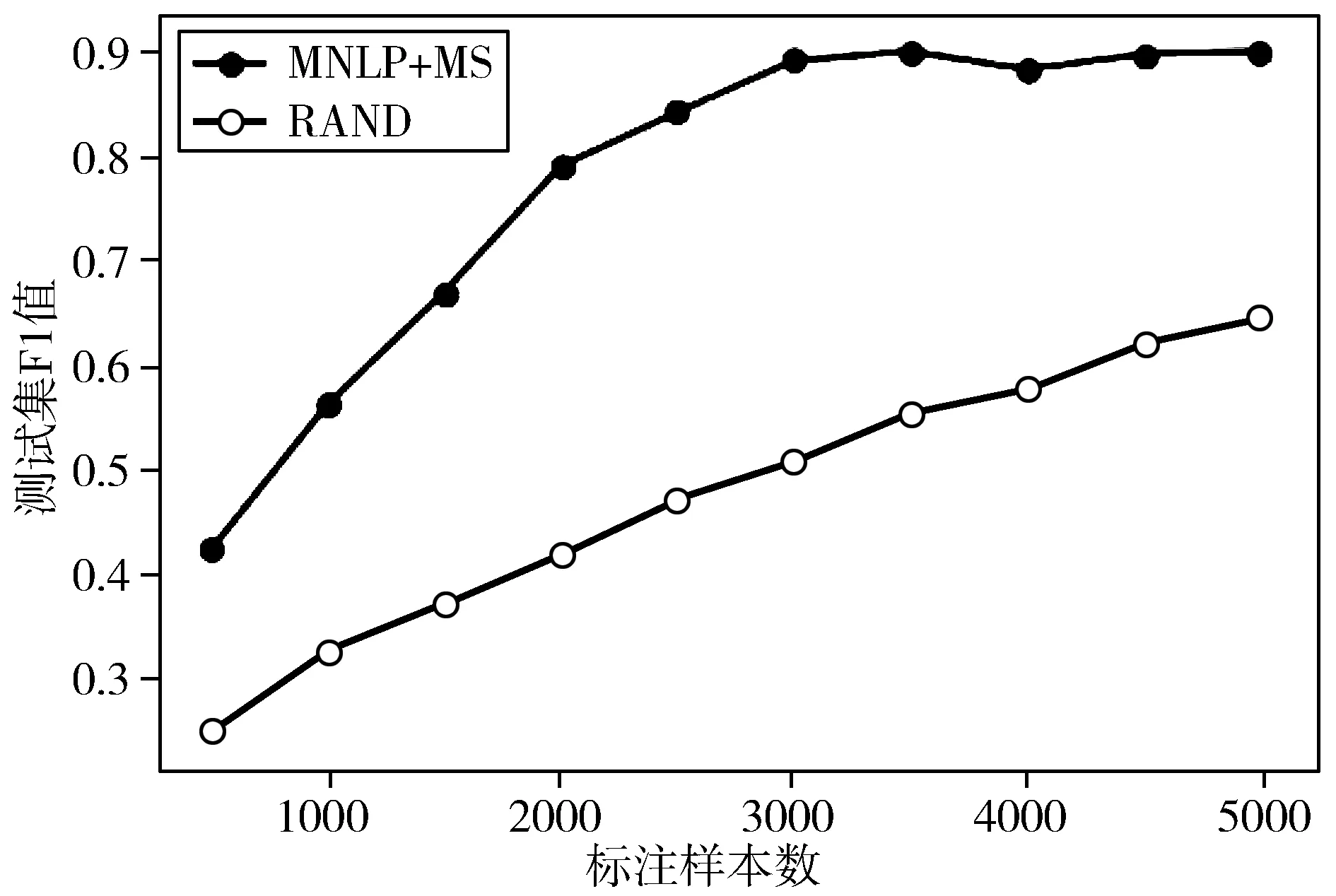
图5 微博数据集的实验结果
在Weibo数据集上的实验主要探索主动学习的效果,以50%的数据集作为预训练数据集,每次添加10%无标签数据集进行迭代训练。表2展示了每次模型收敛后在测试数据集上的效果,并与直接使用全部数据集(100%预训练数据集)的结果进行了比较。从实验结果可以得出,本文算法通过使用部分数据集训练的模型基本可以达到使用全部数据集的结果,并且模型也可以从无标签数据集中学习到一定的特征。
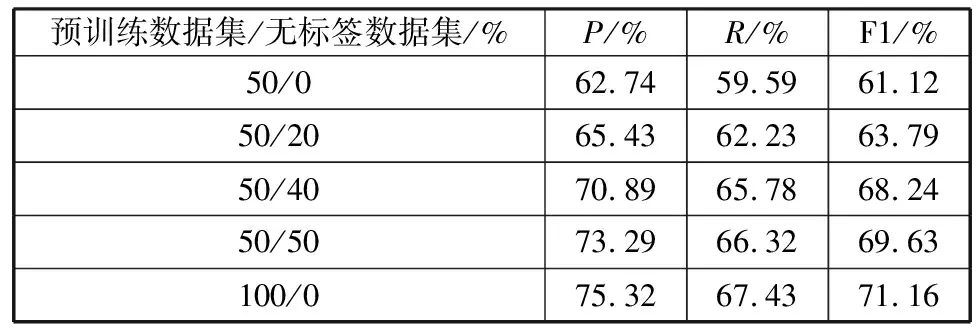
表2 Weibo数据集实验结果
在MSRA数据集的实验结果如表3所示,100%预训练数据集是不使用主动学习,直接在全部数据集上的实验结果。从表3可以看出,本文算法只使用40%标记数据集就可以达到使用全部数据集的效果。对于不确定分数的计算使用,随机选择(RAND)。
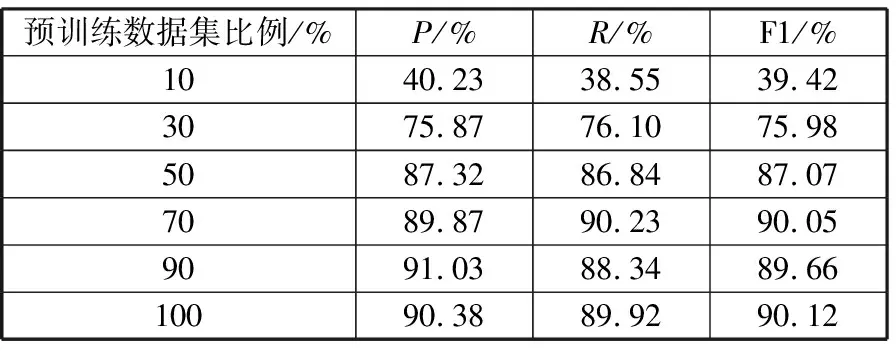
表3 MSRA数据集实验结果
3 结束语
针对命名实体识别人工标记工作量大和多实体类别识别时的标签列表规模过大等问题,本文提出了一种基于主动学习的方法实现流数据中选择更加有效的样本,减少了对重复样本的人工标注。基于流的主动学习更适应快速迭代的互联网数据。使用有效的选择算法,选择出新的样本更新模型,使其适应新的数据,可以针对新出现的数据实现对模型的迭代更新。
由于实体分类时仅提取了实体序列的特征,会出现对部分歧义实体无法分类。歧义实体的分类需要结合句子语境,因此下一步要探索2个模型的结合,从实体位置提取模型中获得一个句子特征向量加入到实体分类模型中,使实体分类模型能获得区分歧义实体的能力。
猜你喜欢
中国外汇(2019年18期)2019-11-25 01:41:54
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
公民与法治(2016年10期)2016-05-17 04:12:58
新校长(2016年8期)2016-01-10 06:43:59
计算机工程(2015年8期)2015-07-03 12:20:27
商事法论集(2014年1期)2014-06-27 01:20:42
