
基于ELMO的低资源神经机器翻译
2021-07-27 03:07:42王浩畅孙孟冉赵铁军
计算机与现代化 2021年7期
王浩畅,孙孟冉,赵铁军
(1.东北石油大学计算机与信息技术学院,黑龙江 大庆 163318; 2.哈尔滨工业大学计算机科学与技术学院,黑龙江 哈尔滨 150001)
0 引 言
近年来,随着深度学习的快速发展,在机器翻译(Machine Translation, MT)领域采用了许多深度学习算法[1-3],并取得了很好的效果。这使机器翻译领域内的研究方向从基于统计的机器翻译转向了基于深度学习的机器翻译,被称为神经机器翻译(Neural Machine Translation, NMT)。基于深度学习技术的机器翻译取得很好效果的前提是拥有一个大规模的平行语料库。然而有许多稀缺语言或者特定领域内的机器翻译任务很难构建大规模平行语料库,翻译效果会严重降低。
采用深度学习模型的机器翻译之所以会效果很好,是因为它能从平行语料中提取语句的关键信息,并进行向量化表示。在训练过程中,平行语料的规模决定了模型能否提取更多的语句信息,平行语料规模越大,提取的语言信息就越多,翻译的效果就越好,反之,翻译效果就越差。随着预训练模型的发展,研究人员相继提出了多种预训练模型,如:Word2Vec[4-5]、ELMO[6]、GPT[7]、Bert[8]等。由于预训练模型采用庞大的语料进行自监督训练,使得模型中包含了大规模语料的词法、句法、语法信息,各种自然语言处理任务在使用预训练模型的情况下都取得了很好的效果,预训练模型在自然语言处理领域中变得举足轻重。
本文针对在低资源情况下的神经机器翻译的缺陷,提出一种基于ELMO预训练模型的低资源机器翻译方法。在传统的NMT模型的基础上融合ELMO预训练模型,以少量的平行语料数据去训练模型。在土耳其语-英语翻译任务上相比于反向翻译提升近0.7个BLEU,在罗马尼亚语-英语翻译任务上提升近0.8个BLEU。为验证融合模型在多种语言翻译任务中的有效性,以传统的NMT模型训练出来的结果为基线模型,在中-英、法-英、德-英、西-英这4组低资源翻译任务上相比于传统神经机器翻译模型分别提升2.3、3.2、2.6、3.2个BLEU。
1 相关工作
Koehn等人[9]的实验表明,NMT相比于统计机器翻译无法更好地处理低资源平行语句。但是,通过一些对数据的处理或者对模型的迁移、改进等其他方法有效地改进了低资源神经机器翻译的不足,有些方法甚至超越了统计机器翻译的效果。
其中通过数据增强的方式来改进低资源神经机器翻译的效果较好。由于在统计机器翻译中目标语言的单语数据在语言流畅度上扮演着重要的角色[10],Sennrich等人[11]将目标语言通过训练好的模型翻译成源语言,用来创建并合成平行语料,这一过程被称为反向翻译。他们首先训练了一个目标语言到源语言的模型,通过这个模型将目标语言的单语数据当成输入然后生成源语句,并将单语数据和生成的源语句合并并加入到原始的平行语料中,以此来达到平行语料扩充的目的。Currey等人[12]通过一种很直接的方式去增加目标端的单语数据,该方法将目标语言中的单语语料库复制成平行语料库,使源句与对应的目标句完全一致。然后将复制的语料库与原始的并行数据混合,用于训练NMT模型,其中不区分平行数据和复制数据。Fadaee等人[13]受计算机视觉工作的启发,提出了一种新的数据增强方法,该方法以低频词为目标通过在综合创建的上下文中生成包含稀有词的新句子加入到之前的平行语料中,用于NMT模型的训练。Nguyen等人[14]采用了一种既简单又高效的方法来达到扩充数据的目的。他们将多个源语言到目标语言的翻译模型和目标语言到源语言的翻译模型的推断产生的平行语料加入到原始的训练数据中,从而达到增强训练数据的目的。
还有许多研究人员通过对模型的创新来解决低资源神经机器翻译的难题。Zoph等人[15]使用了转移学习的方式去解决低资源NMT问题。他们首先寻找一组平行语料丰富的语言对,然后构造模型进行训练(称为父模型),训练结束后将模型的参数转移到通过低资源平行语料构建的模型(称为子模型)中,然后在这些参数的基础上进行训练。Niu等人[16]发现采用双向NMT建模的方法可以显著改善低资源NMT的效果。Baziotis等人[17]采用了一种新颖的方法,该方法在NMT模型中融合了先验语言模型,从而达到提升模型翻译精度的效果。Gulcehre等人[18]采用了深融合和浅融合的方式将预训练好的语言模型与NMT模型融合。无论是从模型还是数据方面,都能够较好地解决低资源神经机器翻译问题,甚至在某些方法中取得的效果好于统计机器翻译的效果。本文采用的是预训练模型与NMT模型融合,方法类似于文献[18]。
2 模 型
2.1 NMT模型
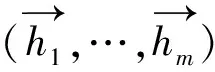
解码器是由循环神经网络组成用来预测目标序列y=(y1,…,yn)。其中每个yi的预测是基于循环神经网络的隐藏状态si、上一个预测yi-1和上下文向量ci。ci的值是编码器输出的加权和。其中编码器输出的每一个权重值αij是通过一个对齐模型计算的。对齐模型是由一个单层的前馈神经网络组成的,通过反向传播算法学习源语言和目标语言中的对齐关系。
2.2 ELMO预训练模
Peters等人[6]提出的ELMO预训练模型,其模型结构如图1所示。
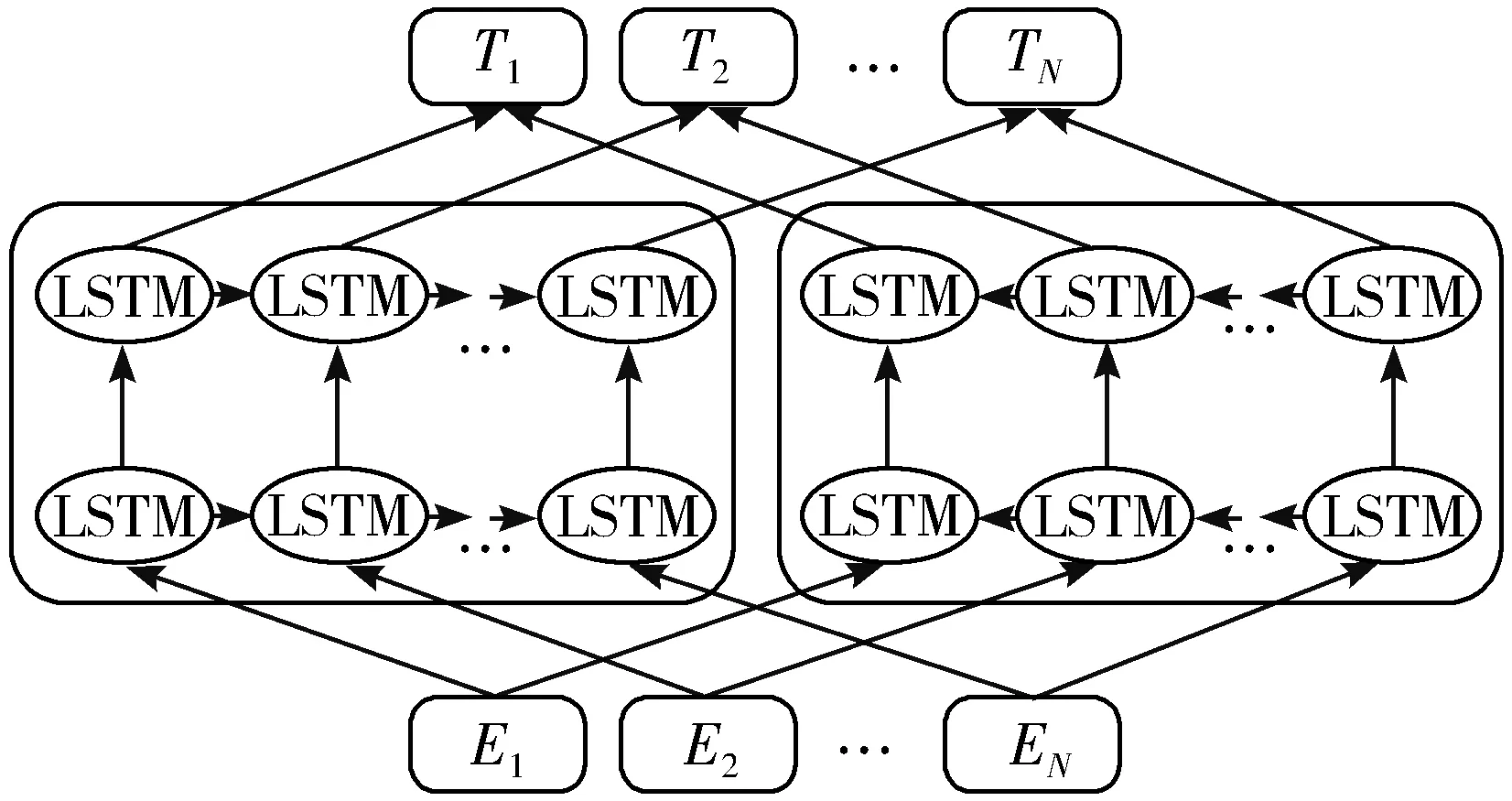
图1 ELMO模型结构示意图
模型采用了经典的2阶段网络结构,第1个阶段是利用语言模型进行预训练;第2个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的词嵌入作为新特征补充到下游任务中。
模型的结构采用了双向长短期记忆网络[20](Long Short-Term Memory, LSTM),预训练的任务目标是根据单词Wi的上下文去正确预测单词Wi,Wi之前的单词序列称为上文,Wi之后的单词序列称为下文。图1中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词Wi外的上文;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文;每个编码器的深度都是2层LSTM叠加。
这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,训练好这个模型后,输入一个新句子Snew,句子中每个单词都能得到对应的3个嵌入:最底层是单词的嵌入,往上是第1层双向LSTM中对应单词位置的嵌入,这层编码单词的句法信息更多一些;再往上是第2层LSTM中对应单词位置的嵌入,这层编码单词的语义信息更多一些。
2.3 融合ELMO的NMT模型
本文提出一种新的模型架构,如图2所示,在NMT模型中融合ELMO预训练模型,编码端和解码端的输入不仅仅输入到NMT模型,还要输入到ELMO模型中。将ELMO的输出矩阵和NMT模型的嵌入矩阵进行连接操作,使用低资源平行语料对模型进行训练。
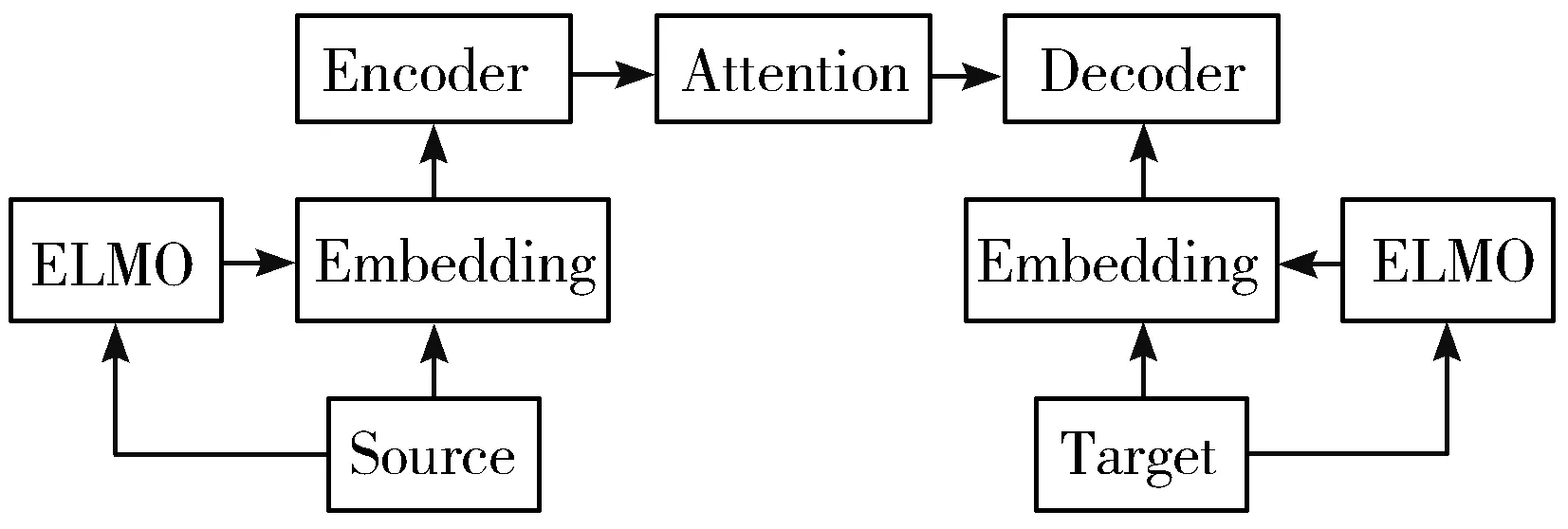
图2 基于ELMO的seq2seq模型示意图
ELMO预训练模型是基于大规模的无标注数据进行训练的,它能够从大规模的数据中学习到语言知识,这使得ELMO能够捕捉到更加通用的语言规律。将编码端和解码端的输入喂给ELMO模型,得到的输出能够捕捉到输入的词性、句法、语法等信息。然后将ELMO的输出和嵌入矩阵进行拼接,将包含词性、句法、语法信息的ELMO输出一起送入模型进行训练,使得模型能够学习到更多的语法表示,从而提高模型的翻译质量。Peters等人[6]使用类似的方法在NLP各领域的任务上均取得了较大的提升。
在编码阶段,将序列x=(x1,…,xm)分别输入到ELMO预训练模型和随机初始化的嵌入矩阵,分别获得输出Eelmo矩阵和词嵌入矩阵Eword,然后将两者的矩阵进行拼接操作得到矩阵E,如公式(1)所示:
E=Concat(Eelmo,Eword)
(1)
将拼接后的矩阵作为嵌入矩阵,在编码阶段经过编码得到输出序列h=(h1,…,hm),计算公式如式(2)所示:
ht=f(xt,ht-1)
(2)
其中,ht代表t时间步的输出,f是非线性函数,这里一般用LSTM或者Gated Recurrent Units。
在解码阶段,输入序列y=(y1,…,yn)的嵌入矩阵与编码阶段做相同操作,而后根据编码端的输出h=(h1,…,hm)和t时间步之前预测的目标语言序列(y1,…,yt-1)来预测时间步t的目标语言,计算公式如式(3)所示:
(3)
其中,p(yt|{y1,…,yt-1},h)=g(yt-1,st,ct),st是解码端t时间步的隐藏状态。ct是经过注意力计算出的上下文向量,计算公式如式(4)所示:
(4)
其中,αtj的计算公式如式(5)所示:
(5)
其中,etj的计算公式如式(6)所示:
etj=a(st-1,hj)
(6)
其中,a的计算公式如式(7)所示:
a(st-1,hj)=vaTtanh(Wast-1+Uahj)
(7)
其中,va、Wa、Ua都是权重矩阵,在训练时可以随机初始化。
3 数据和实验
为验证融合模型的有效性,本文在土耳其语-英语和罗马尼亚语-英语这2组低资源平行语料上进行实验,此外为了验证融合模型在多种语言翻译任务的有效性,分别模拟在低资源情况下中-英、法-英、德-英、西-英翻译任务来评估模型的性能。
3.1 数据和数据预处理
土耳其语-英语平行语料来源于WMT17的新闻翻译任务,共有20万平行句对。罗马尼亚语-英语平行语料来源于WMT16翻译任务[21],共有60万平行句对。在模拟的低资源情况中,主要都是从各种大型开源的平行语料库中随机选取少量的平行句对当做训练集来对融合模型进行训练,使用的验证集合测试集均来自开源语料用于验证和测试的语料,每种翻译任务选取的平行语料数量约为20000对,这些完整的数据分别来源于小牛翻译开源社区的中-英平行语料、WMT14法-英平行语料、WMT13德-英平行语料和WMT13西班牙-英平行语料。
对于所有的平行语料都采用MOSES脚本对其进行预处理,包括分词、大小写转换等。然后使用字节对编码[22](Byte Pair Encoding, BPE)将词转换成亚词单元。
3.2 实验设置
模型训练参数如下:在编码端采用双向循环神经网络作为编码器,在解码端采用双层LSTM作为解码器;词嵌入的维度为512维;编码器和解码器的隐藏层维度为1024维,采用Adam优化算法[23];Minibatch大小为64;学习率随着迭代的次数下降;在推断时采用集束搜索算法[24-25],集束搜索的宽度为10。在使用ELMO预训练模型时,ELMO的输出为3层输出的平均值作为额外的词嵌入矩阵。
在土耳其语-英语和罗马尼亚语-英语翻译任务上,在原有的平行语料上加入反向翻译[11]数据进行模型训练,以此模型作为基线模型。
在模拟的低资源翻译任务中共训练了3种模型:
模型1 使用基本的NMT模型进行训练,源语言和目标语言的词嵌入层均采用随机初始化进行训练。
模型2 使用融合ELMO的NMT模型,并且源语言和目标语言的词嵌入层只使用ELMO输出的参数矩阵进行训练。
模型3 使用融合ELMO的NMT模型、ELMO输出参数矩阵和随机初始化的嵌入矩阵进行拼接进行训练。
4 结果和讨论
4.1 实验结果
所有的实验结果以BLEU[26]分值作为评价标准。在土耳其语-英语和罗马尼亚语-英语翻译任务中实验的详细结果如表1所示。在土耳其语-英语翻译上使用的测试集是newtest2017,在罗马尼亚语-英语翻译任务上使用的测试集是newtest2016。
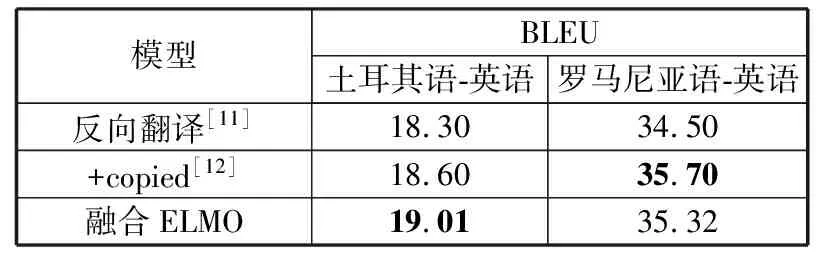
表1 在低资源翻译任务上的详细实验结果
采用反向翻译模型[11]和Currey等人[12]提出的将目标语言中的单语语料库合并到低资源NMT的+copied模型作为本次实验的对比。从表1可以看出,在土耳其语-英语的翻译任务上融合ELMO的模型相比于反向翻译提升了超过0.7个BLEU,同时比+copied模型提升了超过0.4个BLEU。在罗马尼亚语-英语翻译任务中融合ELMO模型虽然比反向翻译的表现好,但是相比于+copied模型差了将近0.4个BLEU,这可能因为低资源NMT主要缺陷是缺乏训练数据,通过数据增强的方式更能够提升效果。在+copied模型中使用了大量的单语语料起到了数据增强的作用,而融合ELMO模型本质上只是捕捉到了训练数据的句法、语义等信息。所以效果没有+copied模型表现的好。
模拟低资源翻译任务的实验结果如表2所示。其中的BLEU值分别表示模型在验证集和测试集上的结果。
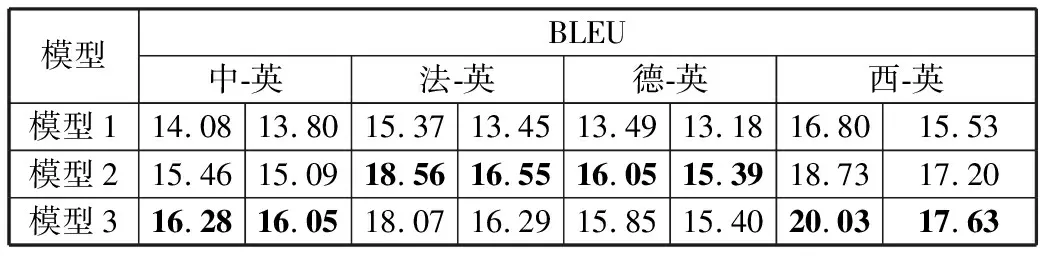
表2 模拟低资源翻译任务的详细实验结果
以模型1的结果作为基线模型,可以发现使用融合ELMO的2种模型的结果相比于模型1的结果提升较大。其中在中-英翻译任务上最高提升了2.3个BLEU,在法-英翻译任务上最高提升了3.2个BLEU,在德-英翻译任务上最高提升了2.6个BLEU,在西-英翻译任务上最高提升了3.2个BLEU。
无论是在土耳其语-英语和罗马尼亚语-英语翻译任务中还是在模拟多种语言的低资源翻译任务中,使用融合ELMO模型的提升是相对较大的,说明ELMO预训练模型和NMT模型的融合能显著改善低资源神经机器翻译的结果。
4.2 讨论
从上述的模拟低资源翻译任务实验中可以看出,每种语言翻译任务在不同的模型上的提升效果也不同。如在中-英翻译任务上,在模型3上的提升相对较大,而在德-英翻译任务上在模型2上的提升相对较大。
在使用ELMO预训练模型时,采用了3层输出的平均值作为参数矩阵,这样可以更好地表示语句的词法、句法、语法信息。下面做一个对比试验,采用每层的输出分别作为参数矩阵,然后与NMT模型融合进行训练,并在测试集上观察模型的表现。
本文分别在4种平行句对上进行实验,实验结果如表3所示。其中第1层表示采用ELMO预训练模型的第1层输出,第2层表示采用ELMO预训练模型的第2层输出,第3层表示ELMO的第3层输出。
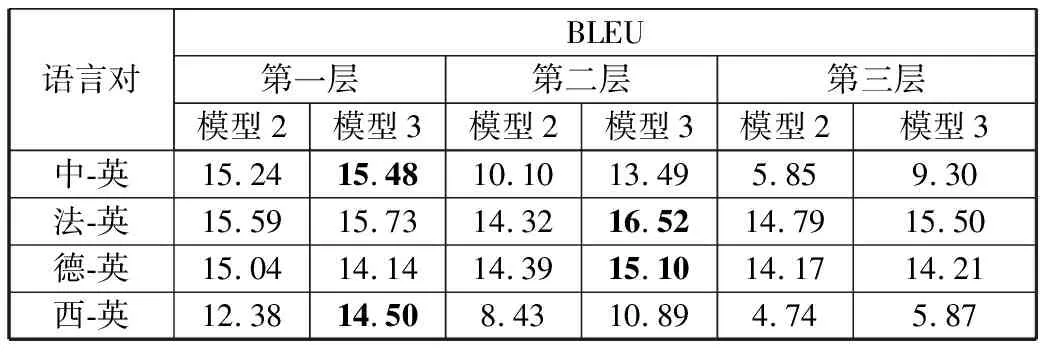
表3 在多种语言对上的实验结果
从实验结果可以看出,采用ELMO的3层输出的结果随着语种和模型的不同有不同的结果,如在中-英平行句对上采用ELMO的第1层输出效果最好,而在法-英句对上采用ELMO第2层输出效果最好。甚至有些模型采用ELMO输出的模型效果比模型1的结果还差。这种情况说明使用ELMO预训练模型时,随着任务的不同每层输出的重要性也有所不同。其次,如果只采用某一层的输出,模型的效果没有使用3层平均的输出效果好。说明了将3层输出进行平均产生新的输出,对模型效果提升较大。
5 结束语
本文提出了一种融合ELMO的NMT模型去解决低资源神经机器翻译问题。主要工作如下:1)提出了一种基于ELMO预训练模型的低资源机器翻译模型,并在多组平行语料上进行实验,结果相对基线模型有较大提升。2)为资源稀缺语言或特定领域的机器翻译提供了一种使用预训练模型的方法去解决相关难题,并分析了ELMO模型每层的输出对模型产生的影响。3)提升了低资源神经机器翻译的精度。
未来的工作将会从以下几个方面进行改进:1)采用加权平均方法对ELMO输出的向量进行计算并应用于翻译任务。2)随着预训练模型的快速发展,一系列表现优于ELMO的预训练模型相继出现,如Bert等,后续将会采用性能较好的预训练模型来对低资源神经机器翻译进行进一步的实验研究。3)本文采用的是传统的神经机器翻译模型,相对Transformer模型[27]来说效果相对较差。后续会采用Transformer模型对其进行改进。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
文理导航(2017年25期)2017-09-07 15:38:18
海外华文教育(2016年1期)2017-01-20 08:21:58
汽车观察(2016年3期)2016-02-28 13:16:36
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
读与写·教育教学版(2015年6期)2015-06-30 20:44:40
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
