
基于概念漂移检测的网络数据流分类
2021-07-27 02:59鞠时光
计算机与现代化 2021年7期
章 恒,鞠时光
(江苏大学计算机科学与通信工程学院,江苏 镇江 212013)
0 引 言
近些年,互联网的迅速发展使得活跃在网络上的用户不断增加,不断增长的数据量为网络数据流挖掘带来了困难和挑战[1-2]。数据流挖掘在网络入侵检测[3]、恶意软件检测等领域[4]都有着广泛的应用。传统的机器学习算法使用在静态的环境中,但在实际情况中,数据流可能受环境影响变成具有动态行为的数据序列,其内在数据分布会随着时间发生变化,这种变化被称为概念漂移[5]。网络数据流中概念漂移的出现,使得传统的机器学习模型显得捉襟见肘,旧的训练数据不含有新的概念,就难以对新的概念有效识别,导致分类性能下降。为了能有效地处理含有概念漂移的网络数据流,就需要提出新的数据流分类算法。
目前,针对存在概念漂移的数据流分类问题,很多学者提出了不同的方案。由于数据流的概念漂移随时可能发生,需要及时更新分类器来适应新的概念。分类器适应数据流的漂移一般分为2种方式[6]:一种是被动更新,无论数据流中是否存在漂移,当有新的数据到来时更新分类模型;另一种方式是主动更新,使用概念漂移检测器来主动检测数据流中的漂移,只有当漂移存在时才更新分类器。
由上可知,被动更新比较消极,虽然能及时应对漂移,但是新概念的出现频率较低,频繁的模型更新会浪费大量计算资源,而主动更新在检测到概念漂移时才去更新分类模型,不会浪费计算资源。
主动更新关心的有2点,一是如何进行漂移检测,二是在检测到概念漂移后如何更新分类模型。
对于数据流的漂移检测,文献[7-9]使用基于误差率的检测方法,度量滑动窗口中的数据流在分类器下的分类性能,判断是否达到漂移阈值来判定漂移的发生与否。文献[10-11]使用基于数据分布的检测方法,使用欧氏距离、余弦相似函数对窗口中的数据流进行统计检验,以此来度量数据分布的变化。
对于分类模型的更新,文献[9]在漂移检测算法检测到漂移后,使用决策树和朴素贝叶斯混合模型训练新的数据得到最新的分类模型。文献[12-13]在集成学习模型中使用更新基分类器的权重和引入注意力机制的方法,优先关注当前的新数据来构建和更新分类器,并利用准确率比较范围参数调整模型对新数据的关注程度。
综上所述,相关研究人员对数据流概念漂移检测及漂移数据流的分类进行了探究,但是仍存在一些不足,主要表现在如下3点:
1) 在概念漂移检测时,使用滑动窗口来接收数据流,往往只关注相邻窗口间的数据分布,而网络数据流中存在多种数据分布,只对比相邻窗口间的数据流而不是所有的历史数据,容易造成漂移的误检和漏检。
2) 含有漂移的新训练数据与历史数据间存在样本不均衡问题时,直接对其进行训练可能会导致更新后的分类器不能有效识别出新的概念,降低分类器的分类性能。
3) 在漂移数据流的分类算法中,通过集成学习得到的新分类模型往往过度关注新的数据,忽略了对旧数据的检测精度,而且基分类器的分类性能作为是否被替换的关键,需要耗费一定的计算资源去关注每个基分类器,对实时数据流检测是一个大的挑战。
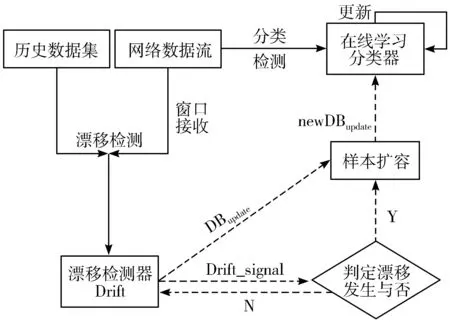
针对以上问题,本文提出一种基于概念漂移检测的网络数据流自适应分类算法。该算法用双重交叉窗口接收新的数据,度量当前数据与历史数据间的分布差异,当差异大于漂移阈值时,认为概念漂移发生;然后对窗口中的数据进行处理,得到漂移数据,对漂移数据扩容后进行处理;最后输入分类器进行在线学习,更新分类模型。
1 概念漂移检测算法
本章以传统网络数据流作为研究对象,提出一种基于历史数据分布的双重交叉窗口概念漂移检测算法(DCW_CDD)。该算法使用2个交叉滑动窗口接收网络数据流,并度量窗口中数据流与历史数据之间的分布差异,考虑到网络数据流中可能存在的噪声影响,应设置合理的阈值来判断此种差异是否达到了概念漂移的水平。
与文献[7-11]一样,本文也使用滑动窗口来接收网络数据流,设图1所示的每个窗口中接收的数据块表示为DB={db1,db2,…,dbn},交叉部分为窗口大小的一半。
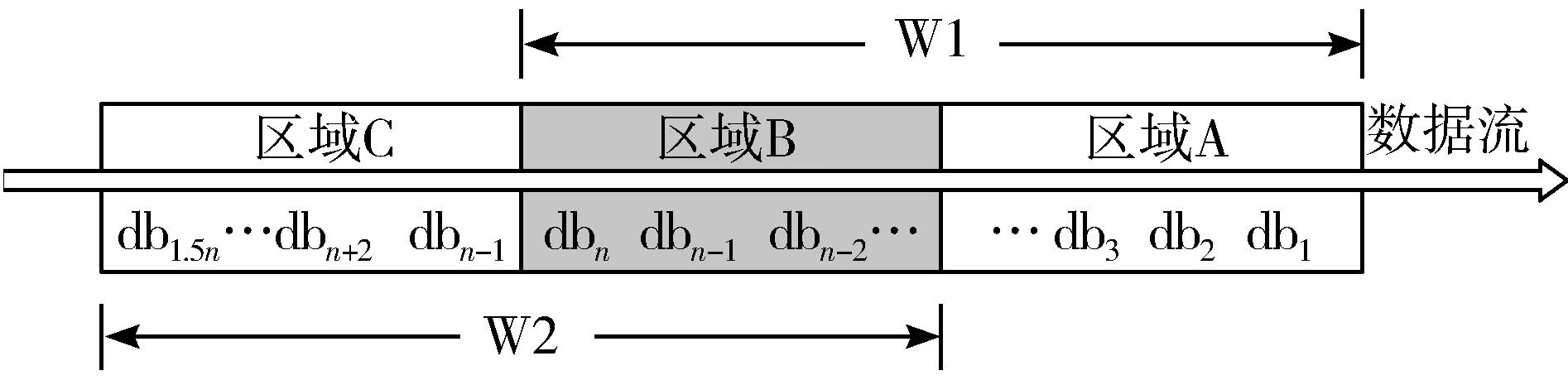
图1 交叉滑动窗口示意图
DCW_CDD算法进行概念漂移检测的步骤如下:
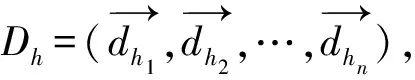
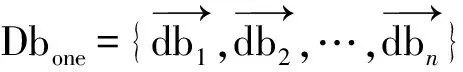
Cnm和Chn每个元素间的距离Disn_to_h的计算方式为:
(1)
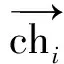
Step3为了应对数据流中存在的噪声影响,本文通过比较数据分布之间的差异来设置警告阈值Warning和漂移阈值Drifting,排除因为噪声而引起的数据分布变化。
对Step2中CDisn_to_h集合的每一个元素进行如下操作:
1)得到Cdi中的每个元素cdij。
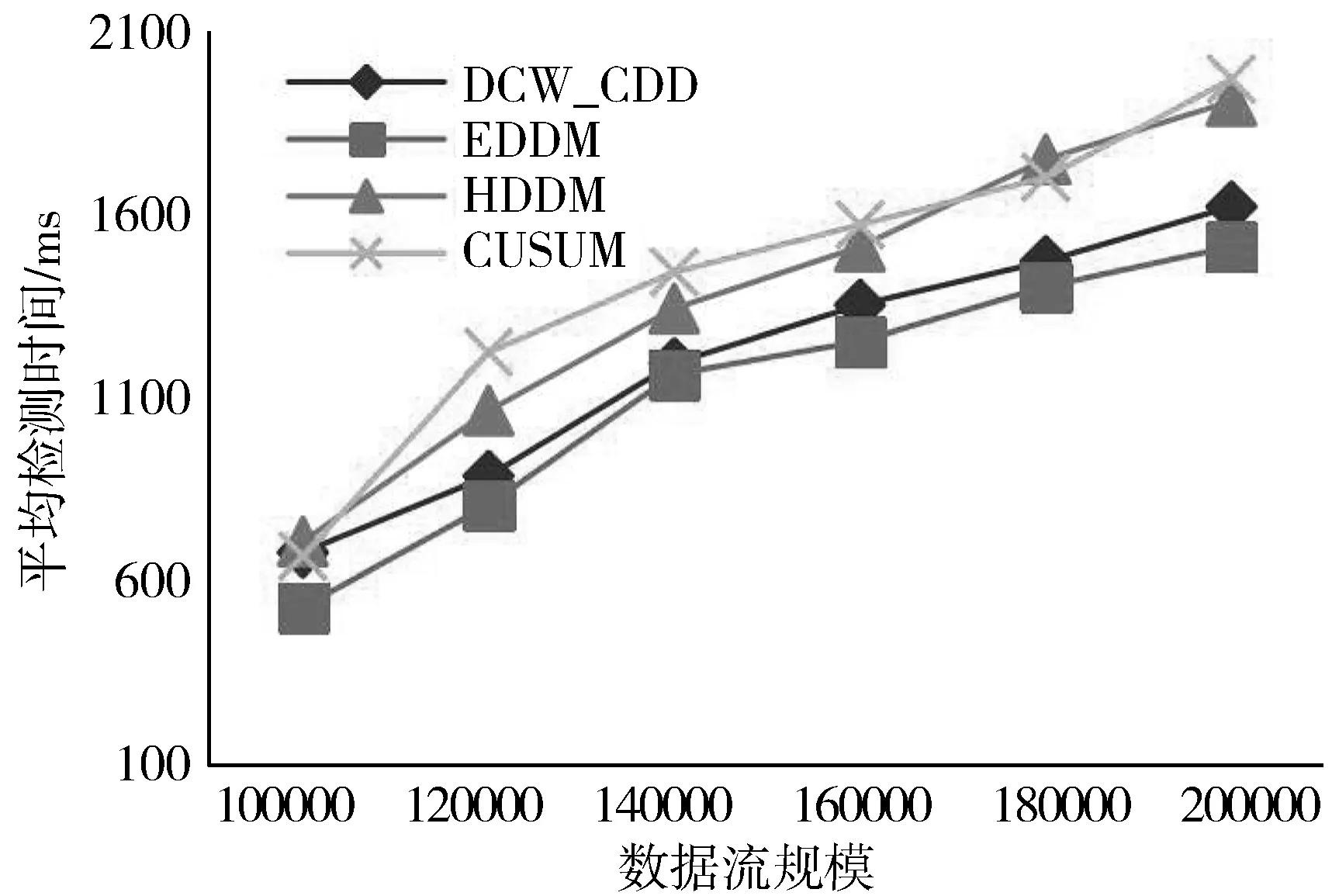
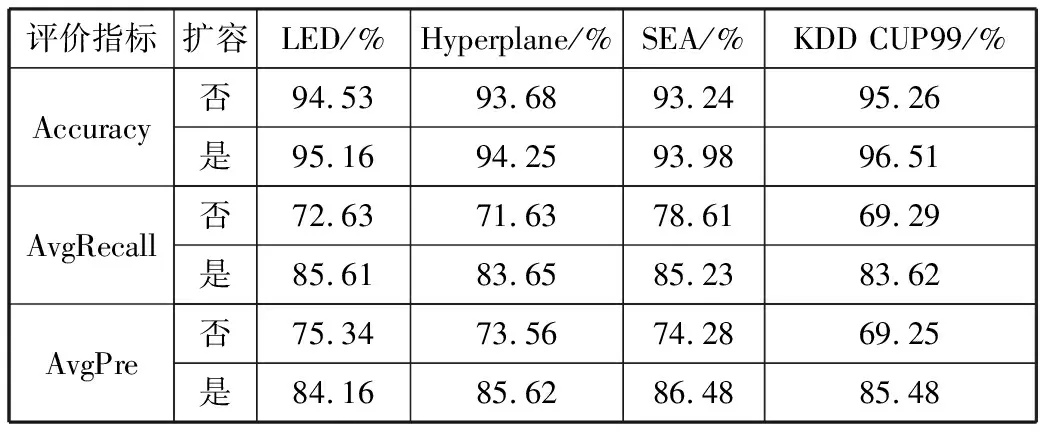
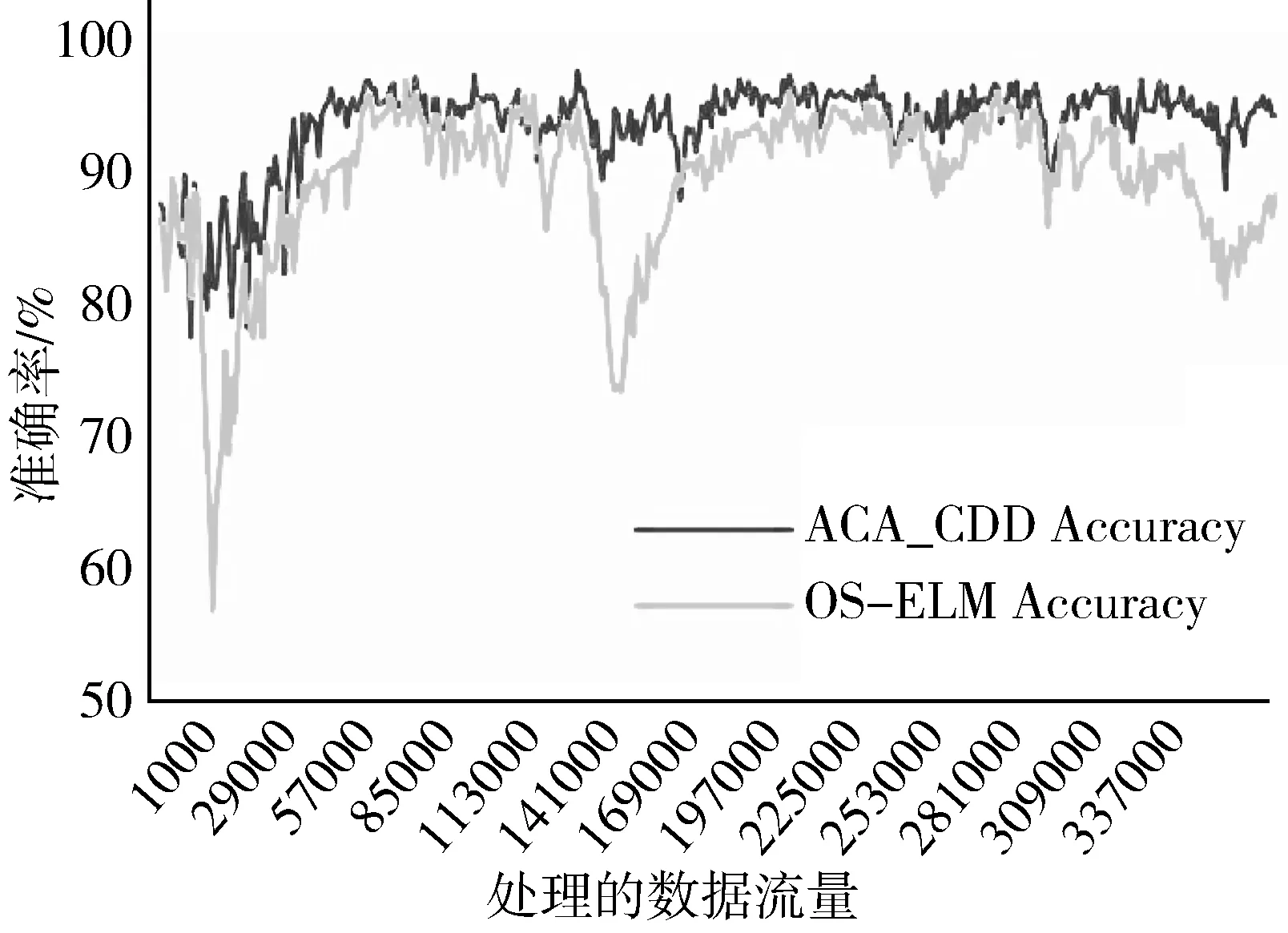
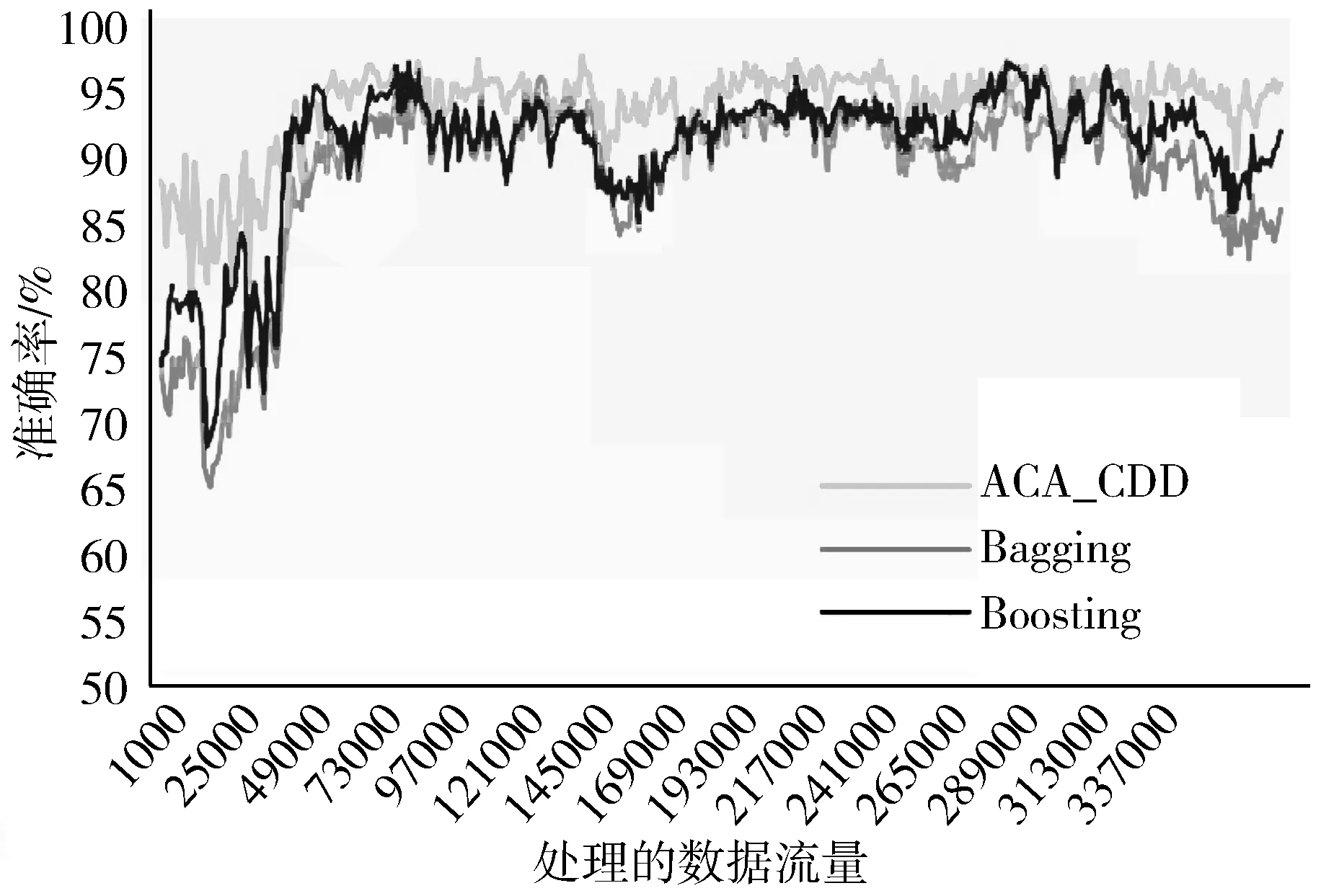
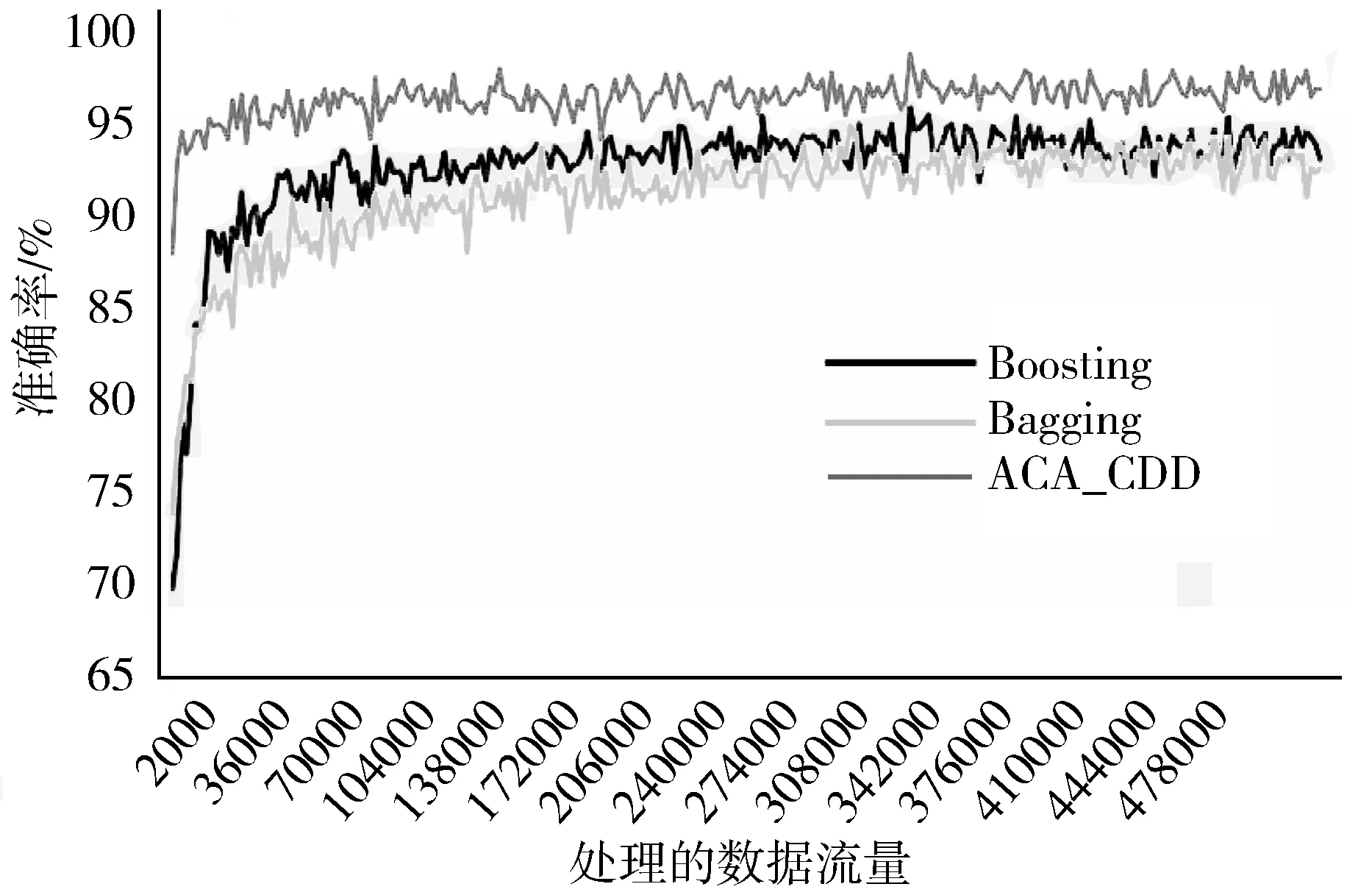
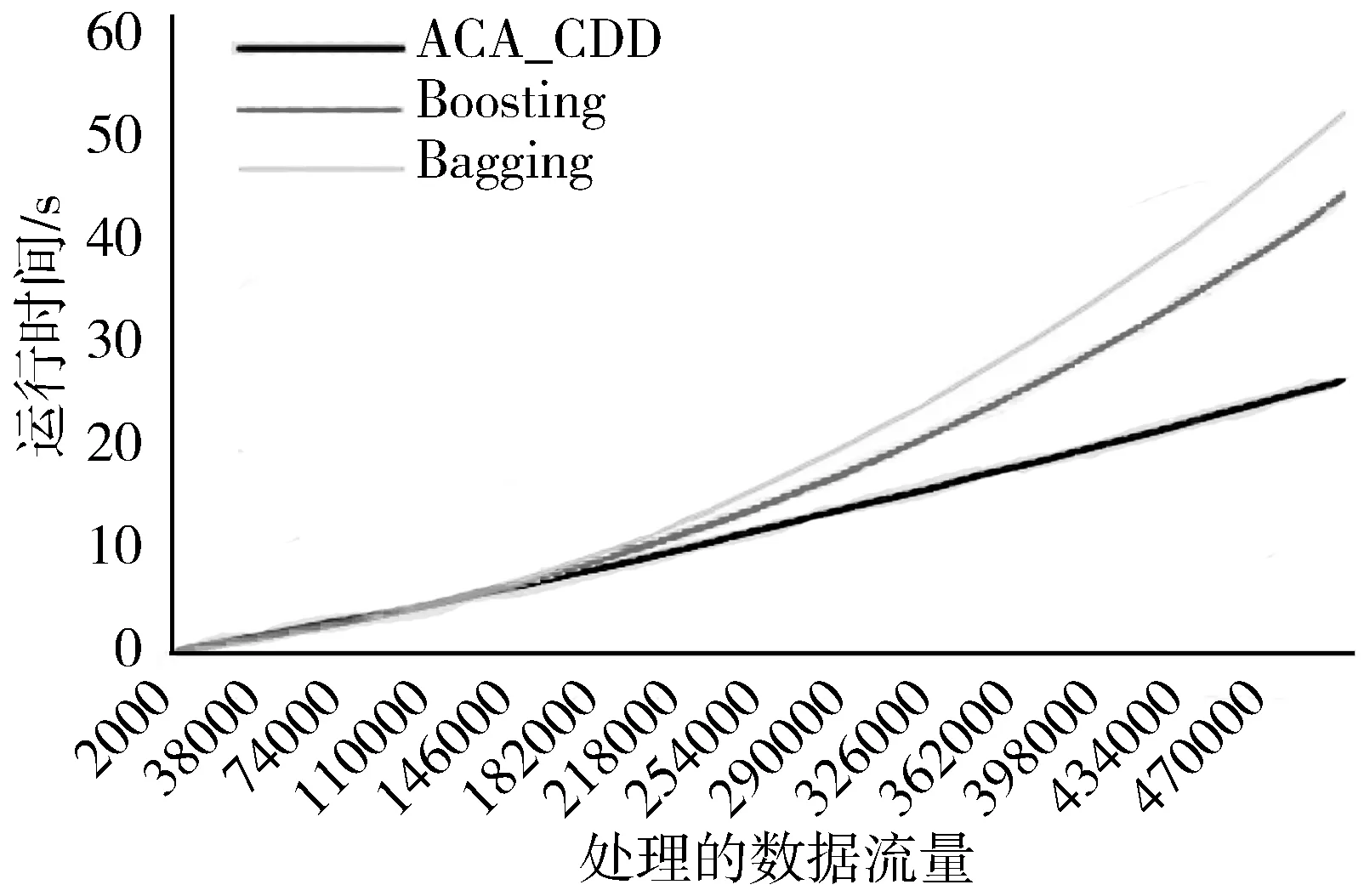
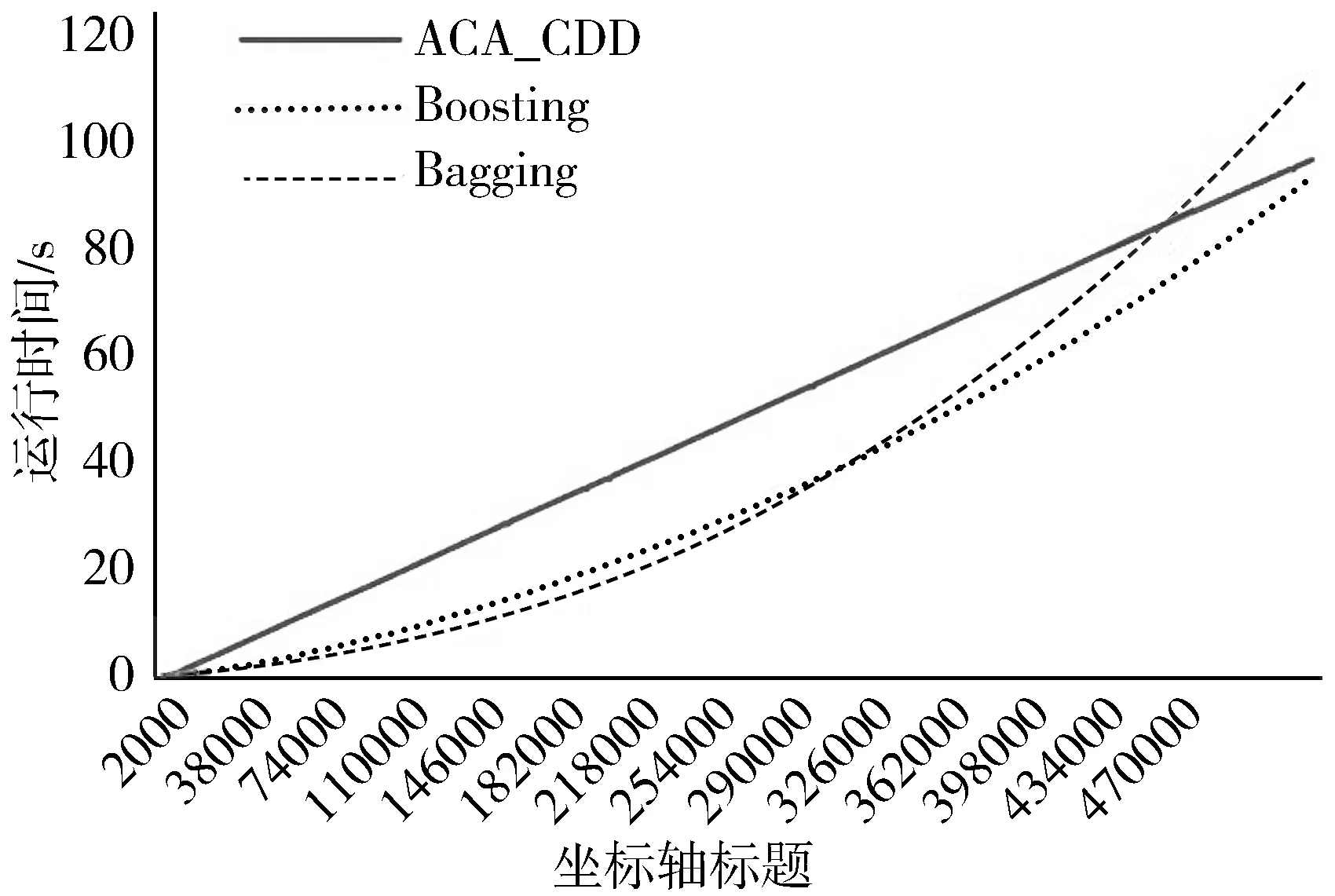
2)若∀cdij 3)若∃cdij≥Warning && ∀cdij 4)若∃cdij≥Drifting,则判定Cdi对应的簇发生了漂移。 5)计算发生漂移的簇占总簇的百分比p_of_d。 Step4当W1中检测到漂移,则对W2中的数据块执行Step2和Step3的过程,判断W2是否检测到漂移,在W1发生漂移的前提下,通过W2中的漂移发生与否,使用下面的判别方式判断漂移发生的区域。 1)若W1中未发生漂移,则漂移出现在图1的区域A。 2)若W2中发生漂移,则漂移在区域B中一定出现,而通过观察Step2中p_of_d的大小来判断在区域C中出现漂移的可能性。 通过判断出漂移发生的区域来获取更新分类器的数据块DBupdate。 Step5若W1中未发生漂移,则同时移动2个窗口,继续接收新的数据,重复Step2。 Step6数据流概念漂移检测结束,发送漂移信号Drift_signal和漂移数据块DBupdate到分类模块,更新分类器。 由以上步骤可知,算法主要的时间消耗是在对样本的聚类上。假设数据的样本数为N,则在最坏情况下,对样本聚类的时间为O(N2),虽然历史数据量较大,但是在检测过程中只需一次聚类,所以花费的时间代价在后续的检测中不需要考虑。而滑动窗口中的数据量较少,即使聚类使用的时间复杂度为O(N2),也不需要花费较大的时间代价,而在后续涉及的距离计算以及判断过程中一般为常数级别,所以在不考虑对历史数据处理所用时间的情况下,该算法所需要的时间复杂度能满足对数据流的漂移检测要求。 网络数据流分类的关键在于分类器的各项性能参数能否应对网络数据流实时、大量和概念漂移等特性,为了不影响数据流分类的实时性,分类器不仅要求训练速度快还需要具有在线学习的能力。 在线序列极限学习机(OS-ELM)是一种单隐层前馈神经网络(SLFNs)算法[14],它继承了ELM[15]算法训练参数少、收敛速度快、泛化能力强等优势,又克服了ELM对新旧训练数据再结合然后重新训练的批处理方式,在处理完当前批数据后会及时释放占用的空间,当有新的数据进行训练时,不用结合历史数据集,只需根据新的训练数据调整单向前馈神经网络的输出矩阵和权重,更新分类模型完成对新数据的学习,在此过程中不需要进行任何分类器的替换。因此,OS-ELM在满足了对漂移数据流学习的同时,又对历史数据分布有着良好的识别能力,符合对复杂多变的网络数据流分类的期望。 在使用OS-ELM分类器时,如果直接将最新的数据处理后输入到分类器进行学习然后更新分类器会存在一些弊端:首先,频繁的更新分类器势必会对分类器的分类稳定性造成影响;其次,在训练初始的分类器时,包含了历史数据集中所有的特征分布,但是新的数据流中出现概念漂移的可能性是较小的,大部分数据流都符合历史数据的分布,所以不需要对这部分数据进行学习,而对该部分数据的处理会极大地浪费计算资源。 因此,本文在分类算法中增加概念漂移检测算法,其作用是对数据流进行过滤,得到存在新概念的漂移数据集,从而能够针对性地对漂移数据集进行处理,使得分类器能够学习到漂移数据集中的新的特征分布,完成分类器的更新,而不需要对所有经过分类器的数据流进行学习。 综上,由于在检测到概念漂移后需要及时更新分类模型,因此,本章在DCW_CDD算法的基础上提出一种基于概念漂移检测的网络数据流自适应分类算法(ACA_CDD),图2展示了该算法流程的整体执行框架,该框架的核心主要包含漂移检测器和在线学习分类器2个部分,这2个部分是并行执行的,概念漂移检测器对数据流的概念漂移检测及稍后的数据处理不影响分类器对数据流的分类。 图2 ACA_CDD的执行流程框架 在进行数据流的分类时,ACA_CDD算法的执行步骤如下: Step1判断DCW_CDD输出的漂移信号Drift_signal和漂移数据DBupdate的值。 若漂移未发生,则不作处理,分类器不更新;若发生漂移,使用DBupdate作为新的训练集去更新分类器。但是,由于漂移数据流的数据量较少,所以DBupdate中样本的数量相对历史数据中其他样本数量的差距较大,会出现不同样本分布之间不平衡的现象。若直接使用DBupdate去更新分类器,可能被分类器当作噪声处理,导致更新后的模型不能识别该漂移,所以需要对DBupdate作进一步的处理。 Step2对DBupdate的扩容处理。 首先根据DBupdate和历史数据中最小样本数量之间的差距计算出需要增加的样本的数量SCnew。然后对DBupdate聚类得到簇集合UC={UC1,UC2,…,UCn}、聚类半径集合Ur={Ur1,Ur2,…,Urn}以及聚类中心集合UCc={UCc1,UCc2,…,UCcn}。 使用式(2)计算每个簇中的样本分布密度,其中Count(UCi)是UCi中样本的数量: (2) 在每个UCi中,密度与生成样本的数量成反比,所以采样权重WUCi由其密度的倒数除以所有的密度倒数之和计算得到,如式(3): (3) 则得到每个簇所需要的新样本数量为:NewUCi=WUCi×SCnew。 为了避免在边界处生成样本过多,对于每一个簇UCi,按照离聚类中心的距离分为H层,最外层以聚类半径Uri处为边界,每层中生成的新的数据的数量与该层距UCci的大小成反比,于是第hi层生成的样本数量如式(4): (4) (5) 通过上述采样步骤,得到newDBupdate,完成对DBupdate样本的扩充。 Step3使用newDBupdate更新分类器。 OS-ELM的训练包含2个阶段,第一阶段会随机初始化神经网络隐藏层节点的输入权重αi和输入偏差bi,对历史数据集中的N0个任意样本(Xi,ti),根据ELM的训练过程,求得满足‖Hoβ-T0‖最小的Β0,H0为隐藏层输出矩阵: (6) 第二阶段是在线学习阶段,newDBupdate经过处理后作为新的样本进行学习。设newDBupdate中的样本个数为Nnew,使用式(6)计算新样本隐藏层的输出矩阵为H1,通过转化可以得到当前批数据训练的输出权重为: (7) 当数据流中发生概念漂移时,还会有更多批次的newDBupdate需要学习,由β0和β1表达式可得到在线学习的输出权重βj+1的递推表达式为: (8) 上述步骤首先解决了漂移数据集的样本不均衡问题,然后通过OS-ELM在线学习新的数据,更新神经网络的输出权重β,从而更新分类器。 实验使用的CPU为Intel i5 7400 3.0 GHz、内存为16 GB、操作系统为Windows10的台式机,并基于Java 8以及开源数据流在线分析平台MOA[17]来实现。 为了验证算法的有效性,实验使用人工合成漂移数据集及真实数据集KDD CUP99网络入侵数据集完成,并对目前主流的算法进行性能对比。 实验使用的数据集描述如下: 1) LED是对数码显示器上数字进行预测的数据集,包含24维属性,可设置7个漂移属性维,包含突变漂移和渐变漂移,实验使用数据流生成器LEDGeneratorDrift生成。 2) SEA是Street等人[18]提出的概念漂移数据集,数据集结构为〈f1,f2,f3,C〉,fi为条件属性,C为类别属性,条件属性取值范围为[0,10],实验使用数据流生成器SEAGenerator生成。 3) Hyperplane是经典的渐进式概念漂移数据集,其样本属性X的值在区间[0,1]上随机生成,通过改变属性对应的权重来模拟数据发生概念漂移,实验中使用数据流生成器HyperplaneGenerator生成。 4) KDD CUP99数据集[19]是网络入侵评估数据集DARPA的扩充版本,有将近500000条数据,共含有42维特征,最后一维表示类别。实验中使用ArffFileStream数据流生成器将该数据集模拟成动态数据流。 除上述数据集外,还使用了MOA实验平台的概念漂移数据流生成器生成的具有不同规模的稳定型、突变型和渐变型漂移的数据流。 算法DCW_CDD使用2个大小相同的滑动窗口对数据流进行接收,因此滑动窗口的大小对漂移检测有着一定的影响,需要对滑动窗口的大小进行界定。 实验使用大小分别为50、100、150、…、400、450、500的窗口来接收数据流,通过比对上述4个数据集中对漂移的误检率和漏检率来确定合适的窗口大小。 图3和图4分别表示滑动窗口大小对误检率和漏检率的影响。由图3可知,当滑动窗口大小约大于200的时候误检率基本上达到稳定,而在图4中,漏检率在滑动窗口大小约大于150的时候能达到稳定,考虑到窗口增大后数据处理所需的计算资源,因此选择能满足误检率和漏检率的稳定点的最合适滑动窗口大小为200。 图3 滑动窗口大小对误检率的影响 图4 滑动窗口大小对漏检率的影响 为验证DCW_CDD算法对含有不同类型漂移数据流的检测性能,实验使用MOA平台的数据流生成器NoChangeGenerator、AbruptChangeGenerator和GradualChangeGenerator生成3种不同类型的数据流,并对比常见的概念漂移检测算法EDDM[20]、HDDM[21]、CUSUM[22]在漂移检测时的误报数、漏报数以及检测时间。 为保证实验的公平性,对比算法的各项参数均使用实验平台默认值。DCW_CDD算法接收数据流的滑动窗口大小为w=200,漂移阈值Drifting=DisCavg-2×CRavg,其中DisCavg是聚类簇心之间的平均距离,CRavg是所有聚类簇的平均半径,均在算法执行时计算得出。 1)误报数和漏报数对比分析。 实验每次生成具有100000个实例的3种类型数据流,重复100次,对比4种算法的误报数、漏报数,得到的实验结果对比如图5、图6所示。 图5 误报数对比图 图6 漏报数对比图 由图5可知,DCW_CDD算法在3种数据流中平均误报次数均低于其他3类算法,因为该算法对新旧数据之间的数据分布变化较为敏感,稳定数据流中数据分布基本不会发生变化,突变型数据流中较少的突变数据实例难以影响数据的分布,而渐变型数据流中,由于渐变漂移的发生往往伴随着多个实例的变化,而这些变化能够导致数据分布的变化,DCW_CDD能够捕捉到这种变化。此外,由于DCW_CDD算法设置了警告和漂移阈值,相比于其他3种算法,能够在一定程度上忽略由噪声引起的假漂移。 图6比较了不同算法在含有概念漂移的2种数据流的漏报数,漏报数由每种算法在每次重复实验中的漏报次数之和除以总的重复实验次数得到。可以看出,DCW_CDD算法对突变漂移数据流中的漏报次数要略高于其他算法,因为发生突变的数据实例较少,容易被识别为噪声,而较少的实例难以影响数据的分布,易被忽略。但在渐变漂移数据流中,由于数据的分布产生变化,明显看出DCW_CDD算法的漏报次数低于其他算法。 2)不同规模数据流的检测耗时对比分析。 实验通过控制数据流生成器生成的数据规模,在数据大小为100000,120000,…,180000,200000的数据流中统计4种算法的检测时间,每个算法进行50次实验,计算平均值,得到了如图7所示的检测消耗时间对比图。 图7 检测消耗时间对比图 由图7可知,4种算法在时间消耗上差距较小,本文算法的时间消耗处于中等水平,因为该算法对数据块进行聚类时需要一定的时间消耗。 1)新的数据样本是否扩容对分类性能的影响。 实验将扩容前后的训练数据分别输入分类器中学习,比较扩容前后分类器的分类性能来验证本文提出的方法对小样本数据学习的有效性。 分类性能指标由准确率、平均精确率和平均召回率组成,其计算公式及说明如下: (9) 其中,TPi表示第i类被分类器正确分类的个数,Ci表示第i类真实出现的个数,N是类别。 (10) 其中ACi表示分类时被分类器分到第i类的样本的个数。 (11) 表1展示了4种数据集在检测到概念漂移后得到的新的训练数据在扩容前后的分类器的分类性能对比。 表1 扩容前后分类性能对比 由表1可以看到,在扩容后,分类的各项指标具有一定的提升,其中Accuracy平均提升了0.79个百分点,AvgRecall和AvgPre平均提升了11.48和12.32个百分点,提升较多,这是因为扩容后,新的训练样本比重提升,再进行分类的时候对该类的检测率也得到了提升,样本不平衡问题得到一定的解决。 2)概念漂移的检测与否对分类性能的影响。 为了验证DCW_CDD对含有概念漂移的数据流分类的有效性,实验比较了传统OS-ELM算法和ACA_CDD算法在含有概念漂移的数据流中的分类精度。 由图8可知,在数据流发生的3次漂移中,不含概念漂移检测的OS-ELM算法的准确率波动较ACA_CDD算法更为明显,准确率也略低;另外,随着数据流的处理数量增加,由于OS-ELM算法本身也具有学习能力,算法在后2次的漂移数据流中的准确率波动较第一次有所减少。 图8 Hyperplane中分类准确率对比 3)概念漂移的检测与否对数据处理时间的影响。 本文提出的ACA_CDD算法与OS-ELM算法的主要不同之处在于对数据流的概念漂移检测以及检测到概念漂移后对漂移数据的处理。因此,实验对比了带有概念漂移检测的ACA_CDD算法和直接使用OS-ELM算法在其数据处理阶段的时间消耗对比。 由图9可知,因为ACA_CDD算法加上了概念漂移检测过程,该过程需要进行聚类等一系列计算,所以相对不含概念漂移检测的OS-ELM算法在数据处理时消耗的时间要更多。同时因为其在检测到概念漂移后需要对数据进行处理,所以在检测到概念漂移后时间曲线有所波动,但是由于漂移检测过程与分类器对数据流的分类是并行进行,所以该过程所造成的时间消耗对分类器分类的时间性能不构成影响。 实验对本文的ACA_CDD算法、集成学习算法Bagging和Boosting进行比较[23],集成学习算法的基分类器使用Hoeffding Tree,数量为10个,均使用MOA实验平台的默认参数。 在准确率方面,图10中3种算法在含有漂移的Hyperplane数据流中平均分类准确率在90%以上,但在遇到概念漂移时,由于ACA_CDD算法在捕捉到新的概念后能较好地学习新的概念并更新分类器,所以相对于集成学习算法仍然能保持较为平稳的准确率。 图10 Hyperplane中分类准确率 图11中3种算法在不包含漂移的KDD CUP99数据流中均取得了较高的分类精度,其中ACA_CDD算法的分类准确率高于另外2种算法;此外,实验在数据集中添加了10%的噪声,3种算法的精确度均能保持稳定,说明ACA_CDD算法也有着另2种集成学习算法的抗噪性。 图11 KDD CUP99中分类准确率 在时间消耗方面,如图12所示,在运行初期3种算法在处理数据流时所用的时间差距甚微,随着数据流的到来,Boosting和Bagging算法运行时间曲线的斜率逐渐增大,而ACA_CDD算法的斜率的变化程度很小,在运行时间上表现得较为平稳。在图13中,在运行初期ACA_CDD算法的运行时间虽然大于Boosting和Bagging算法,随着数据流的到来,约在260000~300000的时候,集成学习算法的时间曲线的斜率慢慢超过ACA_CDD算法,不断增大,甚至在后期Boosting算法所使用的时间超过了ACA_CDD。 图12 Hyperplane中的运行时间 图13 KDD CUP99中运行时间 根据以上分析,ACA_CDD算法在时间性能上表现得也较为良好。 本文提出了一种基于概念漂移检测的网络数据流自适应分类算法,该算法首先使用双重交叉窗口接收数据流,比较其与历史数据的分布异同;其次,通过度量数据分布的差异,来检测数据流中存在的因数据分布变化而引起的漂移;最后,当检测到漂移后,使用漂移数据集更新分类器以此来应对动态数据流。通过理论分析与实验验证,本文提出的算法在含有因数据分布而引起的漂移数据流中有着良好的检测效果,并且在平稳的数据流中也有着较高的分类精度,同时具有一定的抗噪性,当数据流量较大时,该算法在时间性能上也优于集成学习算法。2 数据流自适应分类算法
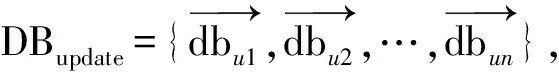
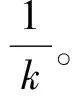
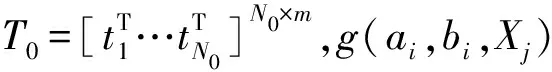
3 实验与分析
3.1 滑动窗口大小对漂移检测性能的影响
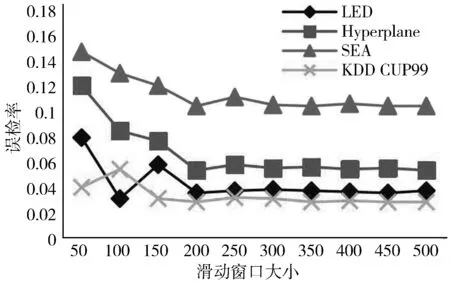
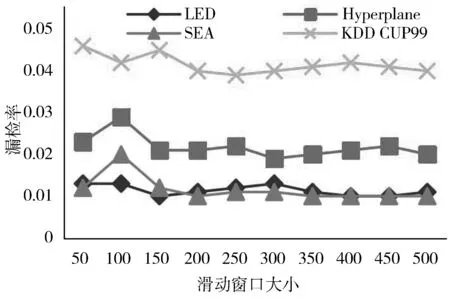
3.2 漂移检测算法性能分析
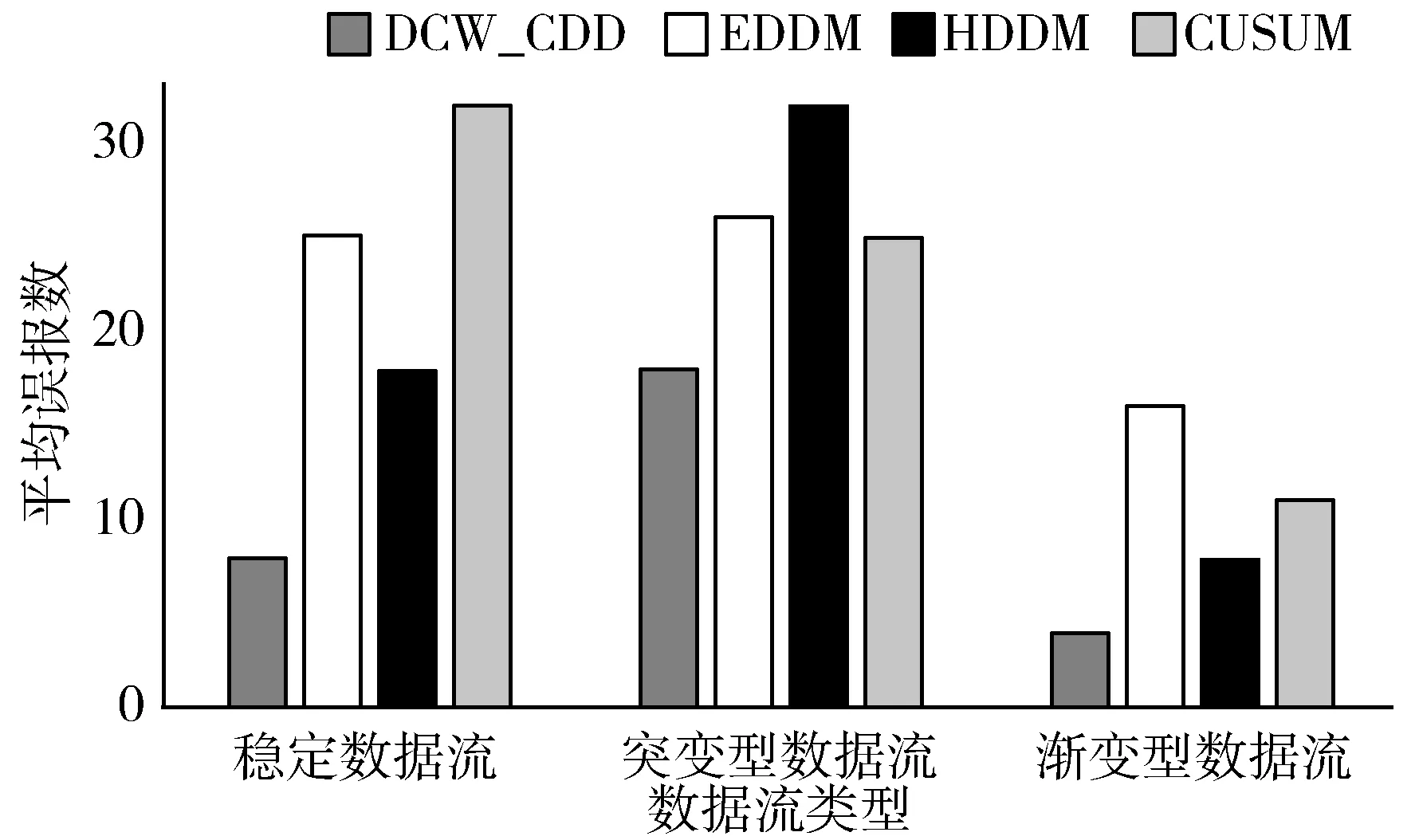
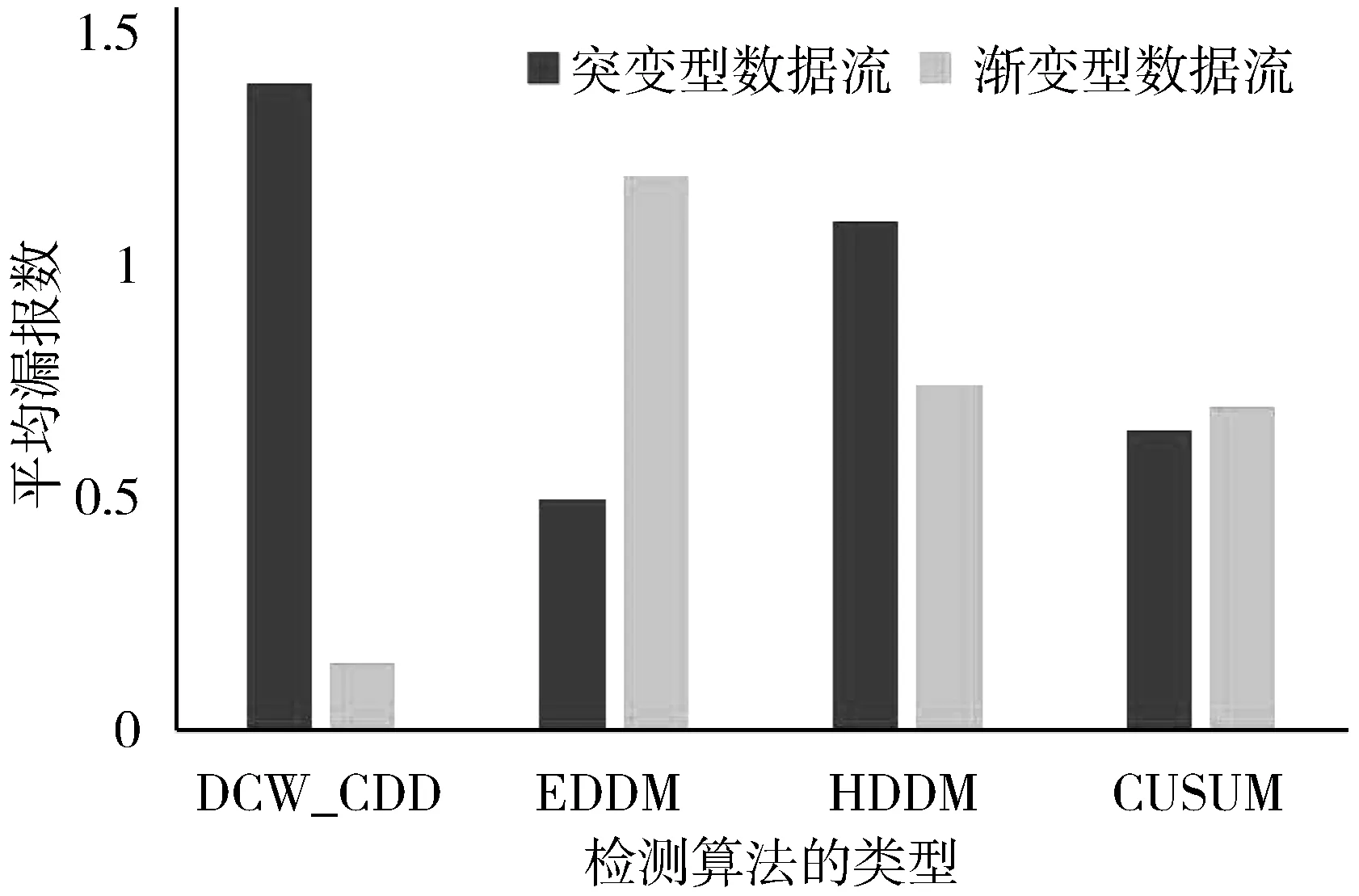
3.3 自适应分类算法性能分析
3.4 不同分类算法的性能分析
4 结束语
猜你喜欢
现代装饰(2022年1期)2022-04-19汽车维修与保养(2020年10期)2021-01-22汽车维修与保养(2020年11期)2020-06-09现代装饰(2020年2期)2020-03-03中学生数理化·高一版(2018年9期)2018-10-09中学生数理化·高一版(2017年9期)2017-12-19光学精密工程(2016年4期)2016-11-07光学精密工程(2016年3期)2016-11-07西北工业大学学报(2015年3期)2015-12-14中国卫生(2014年7期)2014-11-10
