
基于用户信息向量聚类和改进SAMME的推荐算法
2021-07-27 02:59王杉文马万民陈建林
计算机与现代化 2021年7期
王杉文,欧 鸥,马万民,陈建林
(成都理工大学信息科学与技术学院(网络安全学院),四川 成都 610051)
0 引 言
随着互联网日新月异发展,Web技术得到了广泛的运用,在线社交平台得到了快速发展,各类平台在推动信息传播方面起着重要作用[1]。据CNNIC发布的《第45次中国互联网络发展状况统计报告》,截止到2020年3月,微信朋友圈、微博使用率较2018年底分别上涨1.7和0.2个百分点;QQ空间使用率接近50%;过去的一年各类社交产品不断创新,社交平台助力社交公益,社交网络持续发展[2]。在线社交平台大量信息资源在为用户提供各式各样信息的同时,对社交平台的使用用户搜索信息的能力与精力也提出了相应的挑战,使得使用平台的用户不得不投入更多时间和精力来搜索其所需要的信息,尤其是在线社交平台的核心是用户交互,如何为用户进行有效的好友推荐是社交平台增加用户粘性的关键。因此社交平台的个性化推荐对于提升社交平台用户体验、给用户提供准确好友推荐具有十分重要的现实意义。
在推荐系统中,用户兴趣的获取是系统个性化推荐的关键,决定着最终推荐质量的好坏。目前推荐系统分析数据的方式主要有2种,一种是可以通过使用矩阵进行表示的数值型数据,包括用户对网页的浏览次数、用户对项目的评分、可用0和1表示的用户对其他用户的赞和踩等。另一种类型的数据是文本数据,包括用户的留言、评论、标签、背景信息等。根据实际情况对数据类型进行分析。推荐技术大体上可以分为基于领域的协同过滤推荐技术、基于内容的推荐技术以及混合推荐技术。基于领域的协同过滤推荐技术主要是分析数值矩阵;基于内容的推荐算法主要是分析文本数据;本文采用的推荐算法是一种混合推荐算法,综合了两者的优势,将用户文本数据转化为用户向量进而构建矩阵数据进行分析,提高推荐效果。
近年来在推荐系统领域,国内外学者为提高推荐系统的质量先后对传统推荐算法尝试了许多改进,做出了不同程度的研究。在用户兴趣与偏好挖掘方面,苑宁萍等[3]通过获取用户对社交活动的兴趣度得到用户之间的综合相似度并与用户信任度结合进行推荐。姚彬修等[4]基于微博平台数据集的博文内容、社交信息和交互关系等多源信息进行相似度计算。但微博平台的博文内容长度有限以至于通过该方法构建的用户特征向量并不能完全衡量用户之间的相似度。黄贤英等[5]基于微博平台从用户标签中提取用户兴趣,对于没有标签的用户,则根据用户性别、年龄和地点等构件的用户相似度提出了一种融合兴趣的用户相似度研究方法(BIBS)。Liu等[6]提出了一种在用户评分很少时,基于LDA模型考虑用户评分的上下文信息,以此挖掘出用户的全局偏好,进行推荐。Yu等[7]提出了一种利用用户之间共识达到向其他用户推荐目的的高效角色推荐算法。
在大数据时代,随着平台用户的数量增长,寻找和计算用户之间的相似度所需时间越来越长,对用户进行推荐时系统的消耗产生了一定的挑战。为提高推荐系统的可扩展性、减少系统在线推荐消耗,融合机器学习思想的推荐算法也随之诞生。目前主要的结合机器学习思想的推荐算法包括聚类模型[8]、矩阵分解[9]、贝叶斯网络[10]等。杨尊琦等[11]用K-means聚类算法处理微博用户数据,将用户关注的内容分成不同类别,研究不同类别之间的相关性,揭示了不同内容之间的相似性。Katarya等[12]提出了基于粒子群优化技术优化模糊C均值聚类算法对用户聚类。王永贵等[13]通过花朵授粉优化模糊聚类算法,增强了用户聚类效果,提高了推荐准确性。杨兴雨等[14]使用随机森林离线训练模型提高了在线推荐效率。范奥哲等[15]从用户维度和项目维度分别聚类,提出了一种双向聚类算法,提高推荐精度。Najafabadi等[16]将聚类技术用于关联规则挖掘中,提高了关联规则挖掘效率。Koohi等[17]将重心去模糊化模糊聚类和皮尔逊相关系数相结合提高了推荐准确率。
上述文献对获取用户信息以及推荐算法做出了不同程度的改进,引入机器学习思想的推荐算法能有效地提升推荐准确率和减少推荐时间。本文提出一种基于用户信息向量和改进SAMME的推荐算法。本算法的优点有:一是充分利用平台用户基本信息(地域、时间、兴趣、标签等)进行推荐,相较于传统协同过滤推荐算法考虑更细致、全面;二是结合机器学习的方法,本算法可以离线训练保存模型,线上推荐时只需要调用模型即可,相较于传统协同过滤节省了寻找用户相似度的时间,大大提升了推荐效率。
1 相关研究
1.1 传统方法
传统协同过滤推荐算法是最为常见的推荐算法之一,广泛运用于各类电商平台、社交平台。其核心思想是找到和目标用户的兴趣相似度较大的用户集合,将用户集合中的用户关注的物品、人物等推荐给目标用户。运用该思想诞生的算法有Jaccard相似度系数、余弦相似度、共同邻居(Common Neighbors, CN)模型等,Jaccard相似度系数为:
(1)
余弦相似度为:
(2)
其中,给定用户m和用户n,wmn表示用户之间的相似度,N(m)是用户m给过的正反馈的物品集合,N(n)是用户n给过的正反馈的物品集合。用户相似度wmn越大,则表明2个用户之间兴趣相同程度越高。共同邻居CN相似度计算:
(3)
其中,给定用户m和用户n,wmn表示用户之间的相似度,CN(m)为用户m关注的用户集,CN(n)为用户n关注的用户集,当用户m、n共同关注的用户集越大,则用户m、n相似度越高。该类算法可以在一定程度上反映用户之间的喜好,但由于该类算法完全忽略了用户内在的背景信息和潜在的兴趣,实际推荐效果并不是很好。并且在计算相似度时会消耗大量时间,在线上推荐时,用户体验并不友好。
1.2 基于K-means算法聚类推荐功能研究
K-means是一种基于划分、容易实现、收敛速度快的聚类算法,上述优点使它在实际应用中具有较强优势,成为最广泛运用的聚类算法之一。杨尊琦等[11]使用K-means聚类算法处理微博用户数据,将用户关注的内容分成不同类别,研究不同类别之间的相关性,揭示不同内容之间的相似性。研究结果表明,聚类之后可将用户兴趣分为不同类别,包括娱乐、体育、教育等,不同用户可能关注多个不同的类别内容,根据用户关注的原因,不同类别的内容之间存在某种联系。实验表明,通过聚类分析挖掘出了用户兴趣之间的隐性关联,相关研究人员给后来推荐算法研究者提出建议:改进推荐功能时可以通过改进推荐算法,全面挖掘用户信息,这样给用户进行推荐时更人性化,推荐结果更好。
2 基于用户信息向量聚类和SAMME的推荐算法
2.1 构建用户信息向量
微博用户的信息包括地域、时间、标签、兴趣等,传统的推荐算法没有完整地考虑用户基本信息。本文从用户基本信息中提取关键词,构建用户信息向量进行用户好友推荐,弥补传统推荐算法考虑不周的问题。
根据用户的基本信息获取关键词,构建用户的信息向量[(u1,w1),(u2,w2),(u3,w3),…,(un,wn)]。其中ui为用户信息关键词,wi为对应关键词的权重。文本中用户关键词权重基于TF-IDF词频-逆向文本频率构建。词频(Term Frequency, TF)一般指的是给定的某一个词语在该文本中出现的次数,该次数会被正则化避免偏向长文本。在本算法中词频用于计算用户关键词在该用户向量du中出现的次数,结果同样将会正则化,其公式为:
(4)
其中,分子ni,u表示该关键词在该用户信息向量中出现的次数,分母表示该用户信息向量中所有出现的关键词总和。逆向文本频率(Inverse Document Frequency, IDF)指关键词普遍重要性的度量,某用户信息关键词在所有用户信息中出现次数较低,则获得较高的逆向文本频率,其公式为:
(5)
其中,分子|U|表示所有用户的所有关键词总数,一般称之为语料库,分母表示含有关键词tu的用户个数,为了防止语料库中不存在该关键词导致被除数为零,因此将分母加1。在用户信息中某用户信息关键词有高词频,并且该关键词在所有用户信息中低频率出现,则获得高权值的TF-IDF。其具体定义为:
TF-IDFi,u=TFi,u×IDFi
(6)
2.2 基于K-means的用户信息向量聚类
聚类算法是对数据中的对象进行分组,被分为同组的对象之间相似度高,而不同组的对象之间相似度低。常见聚类算法主要分为3类:基于划分聚类、基于层次聚类、基于密度聚类。上述3类聚类算法中分别最常见的算法为:K-means算法[18]、BIRCH算法[19]、DBSCAN算法[20]。
K-means算法是最为经典的聚类算法,其算法数学原理简单、易于理解、容易实现。本文采用K-means算法对用户进行聚类分析。具体聚类流程如下:
1)在用户样本集中随机挑选k个样本作为种子样本,以这些种子样本为聚类的初始中心。
2)分别计算其余样本到种子样本的距离,将样本划分到离种子样本最近的簇中。
3)重新计算各个簇中所有样本的均值,将新的均值作为新的聚类中心。
4)重复步骤2和步骤3,直到聚类中心不再变化或者达到循环次数,形成最终的k个聚类。
5)将聚类最终的结果输出。
图1为K-means聚类流程图。
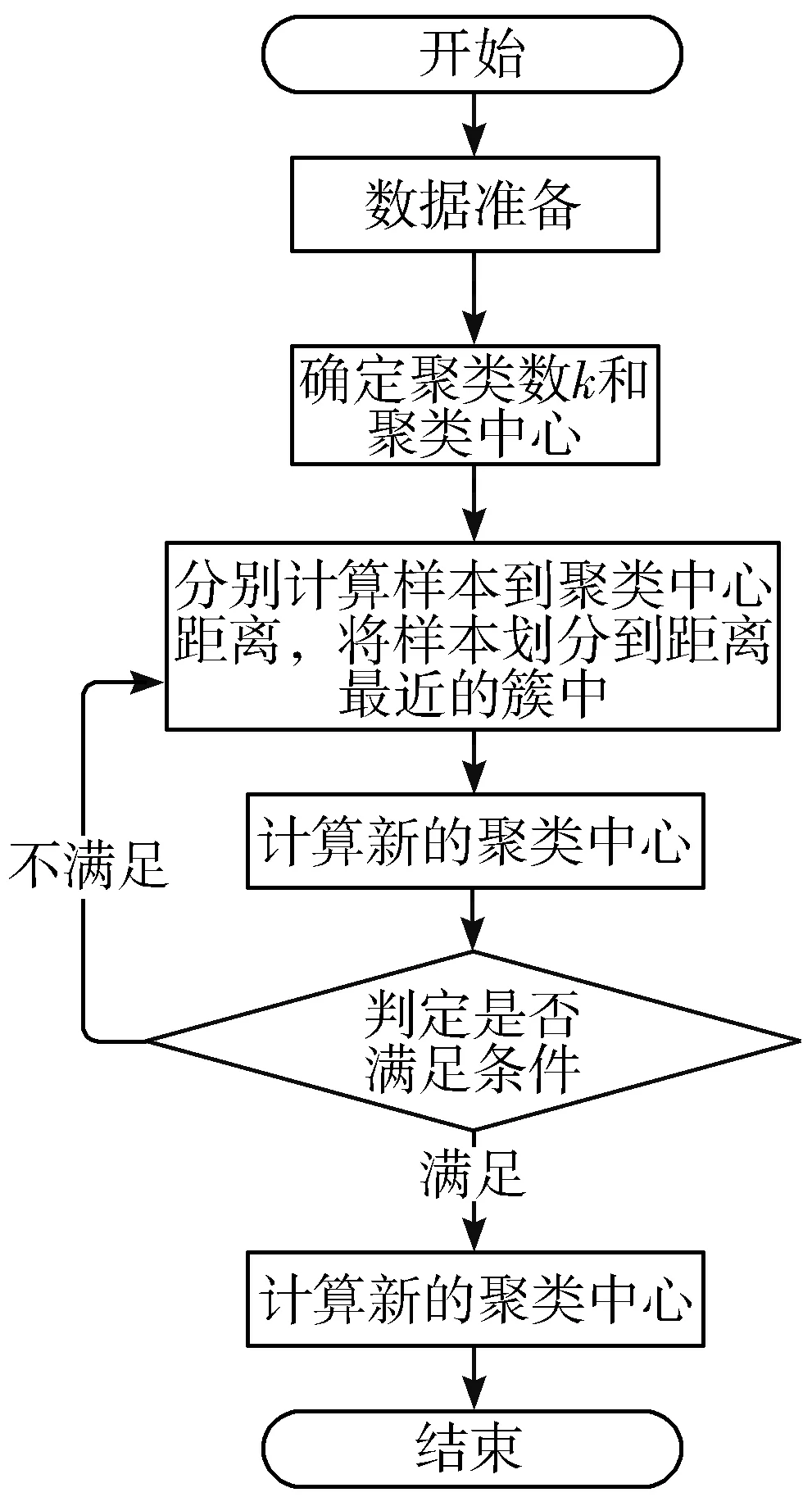
图1 K-means聚类流程图
2.3 基于改进SAMME的好友推荐
集成学习方法主要分为Bagging和Boosting这2种。Bagging的基本原理是从原始样本集中根据均匀概率分布有放回的取值生成训练样本,对于每一个抽样生成的样本集都训练出一个基础分类器;对训练过的样本进行投票,将训练后的样本指派到获得投票最高的类中。Boosting方法是均匀取样,根据错误率不断地调整样例的权值,使得正确率高的分类器有更大的权值,能较好地降低偏差。AdaBoost是Boosting算法的一种,AdaBoost通过学习,可对弱分类器赋予不同的权值,给予分类效果较好的弱分类器高权值,而给予分类效果较差的分类器低权值,通过迭代成为强分类器。AdaBoost算法示意图如图2所示。
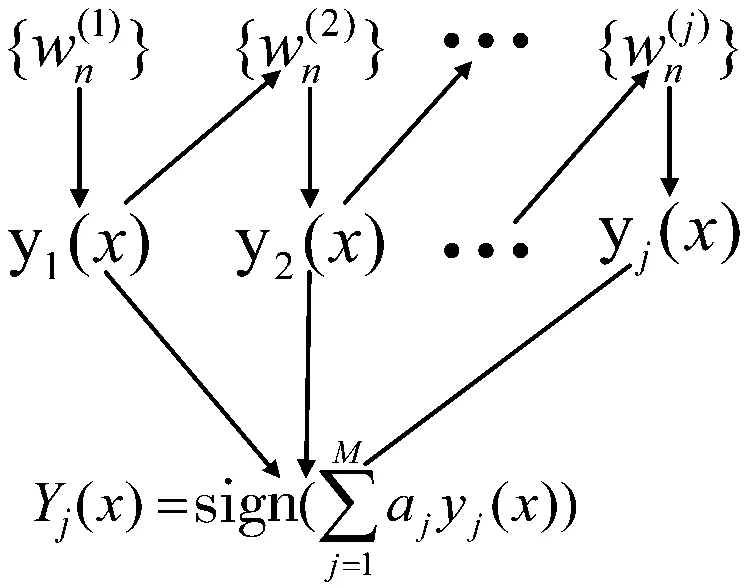
图2 AdaBoost算法示意图
AdaBoost算法主要流程概括为:
1)初始化用户样本权重,将所有用户权重设置为相等。
2)多次循环迭代弱分类器,每次循环中计算当前弱分类器的误差率,根据误差率调整权重。如果用户样本被分类错误,则用户样本的权值会增大,让后面的弱分类器更加受关注。对于弱分类器而言其权重与正确率成正相关。
3)将多个弱分类器聚合成为强分类器,将误差小的弱分类器设置为权重较大。
SAMME[21]将AdaBoost提升到多分类问题上。SAMME弱分类器正确率要求从传统的AdaBoost算法的1/2降到1/k,使得SAMME算法在多分类任务中能利用更多的弱分类器的计算结果。SAMME算法概念简单、容易实现且在实际分类任务中能找到足够多的弱分类器。
但经典SAMME算法的弱分类器要求的正确率大于1/k仅仅只是比随机选取正确率高,并不能保证训练样本中分类到正确分类的样本数量大于分类到错误分类的样本数量。若在训练样本中分类到某错误分类的样本的弱分类器比分类到正确样本的分类器多,经过组合形成最终强分类器后仍然会偏向分类错误的分类器。因此本文中SAMME算法的弱分类器的正确率要求不仅要大于1/k,其分类正确率还要大于其余任意分类错误的概率,以此提高弱分类器的正确率要求。但提高SAMME算法的弱分类器要求后,同样数目的弱分类器训练下其最终起作用的弱分类器会减少,因此要达到最终起作用的弱分类器数目尽量不变的情况下得增加初始弱分类器数量,这样会致使训练效率降低。因此本文在调整弱分类权重的时候引入学习率,通过设置学习率可以快速更新弱分类器权重。
给定m个用户训练样本为:
U={(x1,y1),(x2,y2),…,(xm,ym)}
(7)
其中,xi为用户信息向量,yi为上文中通过K-means聚类后的用户类别。本文算法过程如下:
1)初始化用户训练数据权值分布。每一个用户样本数据在最开始时被赋予相同的权值,则对于第j个弱分类器用户样本初始权值D(j)为:
D(j)=(wj1,wj2,…,wjn);w1i=1/m;i=1,2,…,m
(8)
2)Forj=1,2,…,J执行以下步骤。J是弱分类器总数。
3)使用第j个弱分类器对用户样本进行训练,并计算第j个弱分类器的分类正确率是否满足要求,若不满足则该弱分类器不参与后续计算。
4)计算第j个弱分类器的加权错误率:
(9)
其中[Gj(xi)≠yi]取值为0或1,0表示分类正确,1表示分类错误。
5)第j个弱分类器Gj(x)权重系数为:
(10)
其中,L是学习率,R是K-means聚类后用户样本分类总数。容易看出,当误差率ej减小的时候aj增大,因此误差率越小的分类器的权值越大。
6)样本权重更新过程如下:
(11)
其中Zj是规范化因子,主要作用是将wji的值规范到0-1之间。从公式(11)不难看出当分类正确时wj+1,i取值较小,分类错误时wj+1,i取值较大。分类错误权重较大的样本在之后的弱分类器中会得到更多的重视。
7)最终强分类器:
(12)
最终强分类器表示为所有弱分类器模组的整合。其中,aj是第j个弱分类器权重,J为弱分类器总数。整个训练过程为离线训练,训练结束后将最终训练出的强分类器模型进行保存。在线推荐时只需导入离线训练后的模型进行预测推荐,这个过程耗时远小于传统方法计算用户相似度。
3 实验与分析
3.1 实验数据与评价标准
本文实验所使用的数据集是新浪微博数据集MicroblogPCU,官方下载地址:https://archive.ics.uci.edu/ml/datasets/microblogPCU。该数据集中主要分为weibo_user.csv、user_post.csv、follower_followee.csv。weibo_user.csv存储用户ID、昵称、性别、地域、标签等基本信息,user_post.csv存储用户微博内容,follower_followee.csv存储用户之间相互关注的关系。该数据集中包含59191个用户,超10万条用户相互关注信息。在所有用户中781位用户包含基本信息,有268位用户有标签,标签中包含强烈的个性化信息。本文算法先提取含有标签的268位用户的基本信息,构建用户信息向量,使用K-means进行聚类,为改进SAMME算法提供初始训练数据。再对其余拥有基本信息的用户构建用户信息向量,使用改进SAMME算法训练后模型进行分类推荐。在聚类之后的具体推荐实验过程中,对于没有任何基本信息的用户数据不予以考虑,重点关注781位有基本信息的用户,该781位用户之间有6630条相互关注数据。最后选取有基本信息的90名用户及其关注用户数据作为测试集进行算法评测,验证算法可行性。
推荐最终效果评价指标使用准确率(precision)、召回率(recall)、综合值(F)。准确率定义为:
(13)
其中,R(u)为给用户推荐的用户集合,T(u)为用户关注的用户集合。准确率表示准确推荐的用户集合基数与所有推荐的用户集合基数的比值。准确率(precision)越高则推荐结果越精确。召回率定义为:
(14)
其中,R(u)为给用户推荐的用户集合,T(u)为用户关注的用户集合。召回率表示准确推荐的用户集合基数与用户本身关注的用户集合基数的比值。召回率(recall)越高推荐给用户的覆盖面积越大。综合值定义为:
(15)
综合值F用于平衡召回率和准确率,使其同样重要。综合值F越高推荐效果越好。
3.2 实验过程与结果分析
观察下载好的微博用户数据集不难发现,用户的ID信息存储在user.csv的user_id字段,昵称信息存储在user_name字段、性别信息存储在gender字段。用户的其余基本信息都存储在user.csv文件的message字段中,其存储顺序依次为:用户等级Lv、居住地域、毕业学校、任职公司、出生日期、简介、个性域名、博客地址、标签。message字段中的所有信息以空格隔开,最后一个为标签信息。虽然在数据集中大部分用户的message字段实际存储的信息只含有上述message字段信息中的一部分,但该message字段中大部分信息均有固定格式用于提示,比如毕业学校信息前会有“毕业于”这3个字,标签信息前会有“标签”2个字。可将“毕业于”“标签”等后面的词作为关键词提取。将user.csv文件读取成DataFrame,清洗掉其中的乱码数据,然后根据上述数据存储的规律和格式提取用户信息关键词,使用TF-IDF构建用户信息向量。并将有标签的268位用户单独提取出来,使用K-means进行聚类。K-means聚类后的效果使用CH分数进行评价,CH分数的计算公式如下:
(16)
其中,n为聚类数目,k为当前聚类,trB(k)为类间离差矩阵的迹,trW(k)为类内离差矩阵的迹。得分值越大代表类内越紧密,类间越分散,效果越好。聚类结果如图3所示,可以看到,本文算法和文献[5]算法都随着聚类数k的增加,聚类分数总体趋势趋于逐渐下降,最后逐渐稳定,本文聚类效果总体好于文献[5]算法的聚类效果。但聚类数过少会导致推荐准确度下降,经过权衡与多次实验,本文最终选取聚类数k为10。
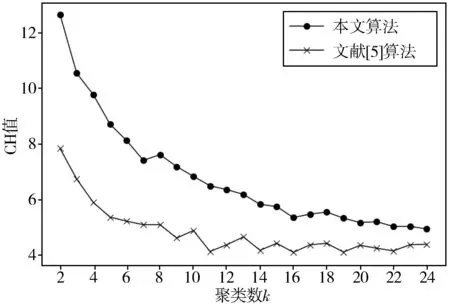
图3 聚类效果CH值
本文推荐结果将与CN算法、文献[5]提出的综合用户兴趣相似与背景相似的计算方法(BIBS)、经典SAMME算法在相同数据集上进行对比。在实验过程中推荐人数分别选取5、10、15、20、25这5种情况,可以看出,本文的推荐算法在不同推荐个数时的推荐指标明显好于其他2种推荐算法,说明该算法取得了较好的推荐效果。图4为3种推荐算法在微博用户数据集上的准确率,可以看出,随着推荐人数的增加3种算法的推荐准确率均在逐渐下降,本文推荐算法的推荐准确率相较于经典SAMME算法、文献[5]算法和传统CN算法分别提升了约3.2%、7.2%、14.9%。图5为3种算法在微博用户数据集上的召回率,可以看出,随着推荐人数的增加3种算法的召回率均在逐步上升,本文推荐算法的推荐召回率相较于经典SAMME算法、文献[5]算法和传统CN算法分别提升了约4.3%、7.4%、13.2%。3种算法的F值如图6所示,可以看出,本文算法最有效,F值最高,F值相较于经典SAMME算法、文献[5]算法和传统CN算法分别提升了3.3%、6.4%、12.9%。综上所述,本文基于用户信息向量和改进SAMEE推荐算法优于其他对比算法。
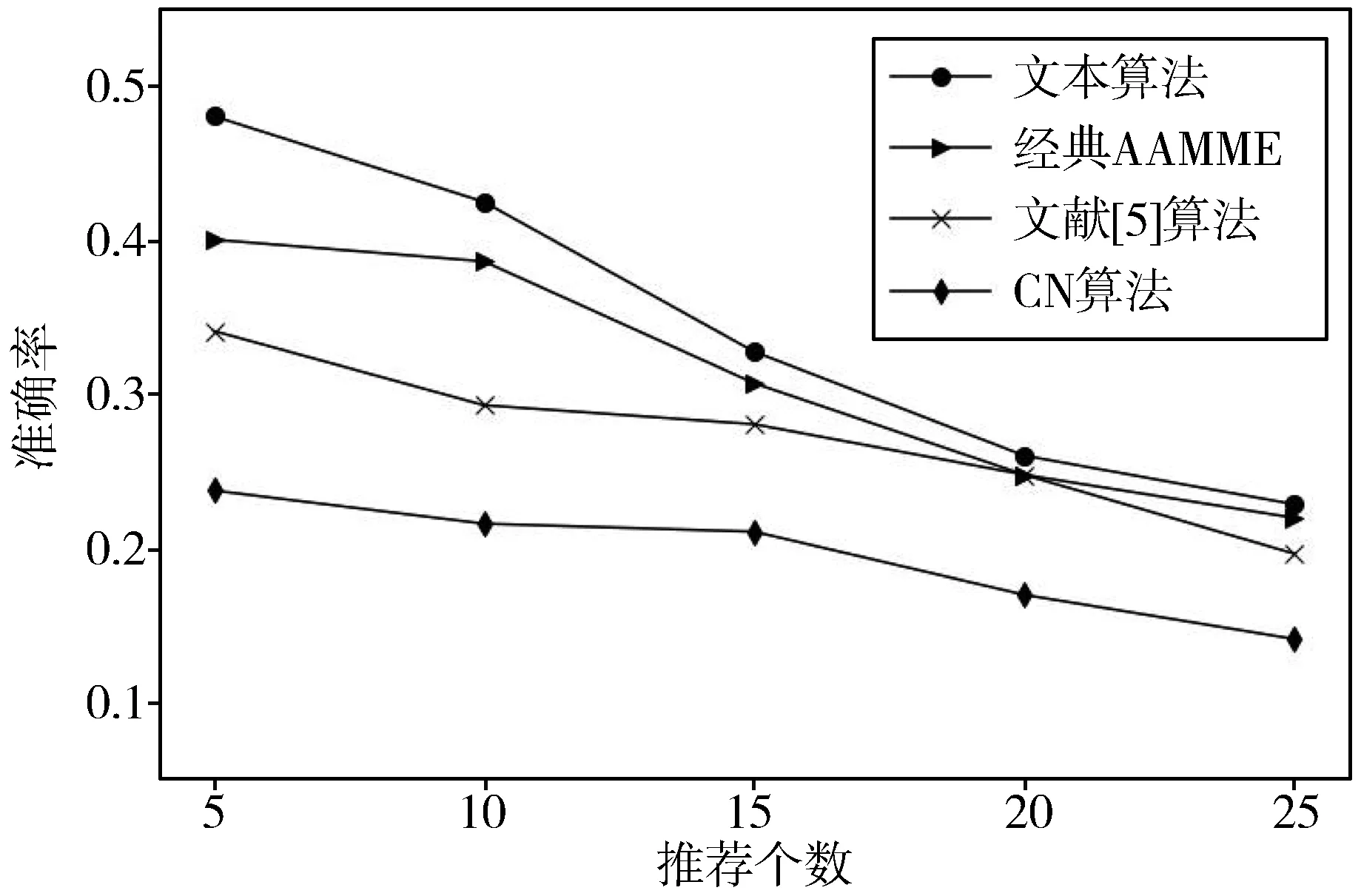
图4 准确率
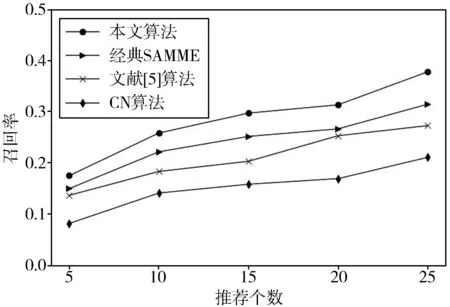
图5 召回率
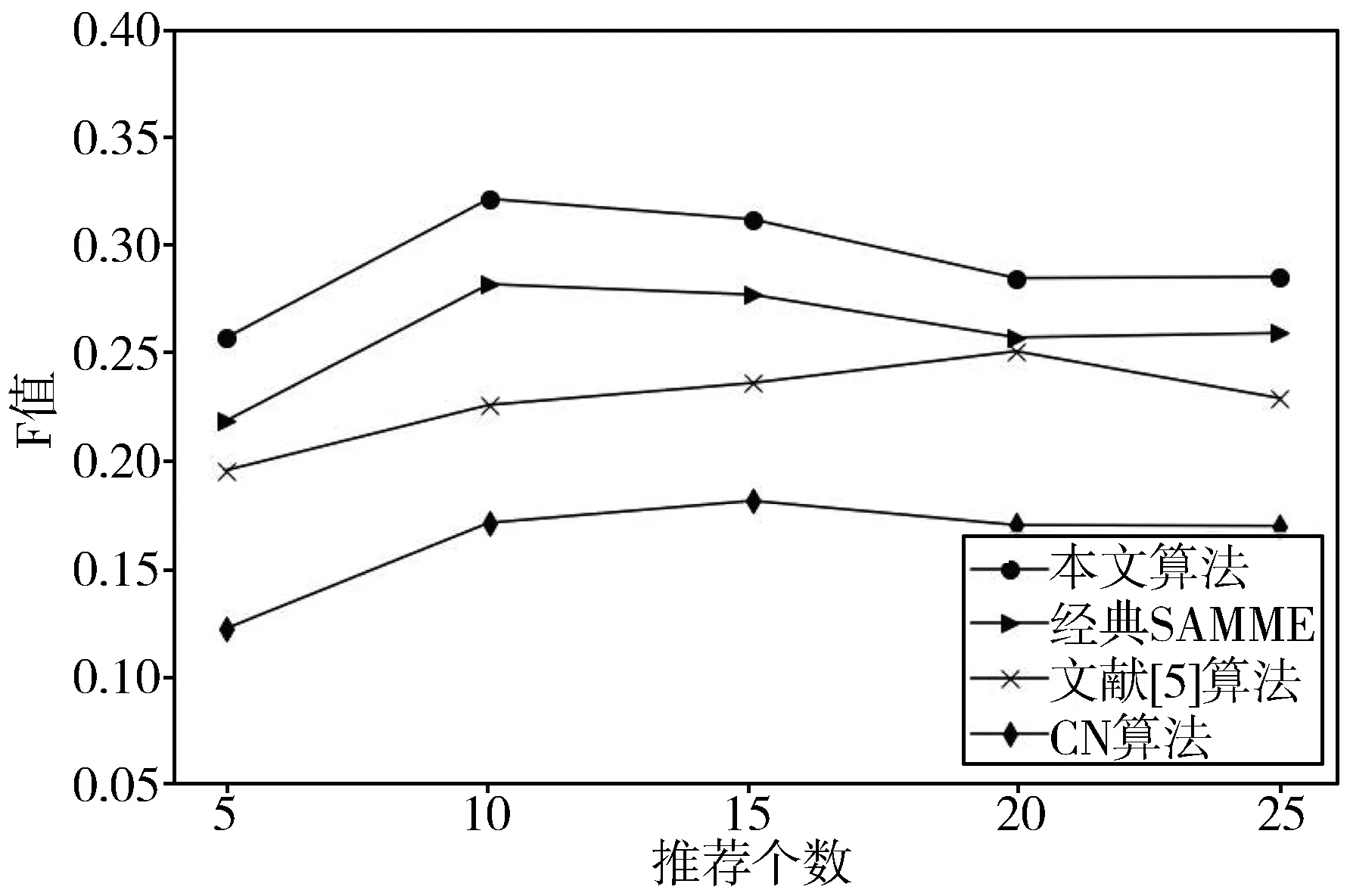
图6 F值
本文算法在不同推荐人数下的详细推荐效果数据如表1所示。
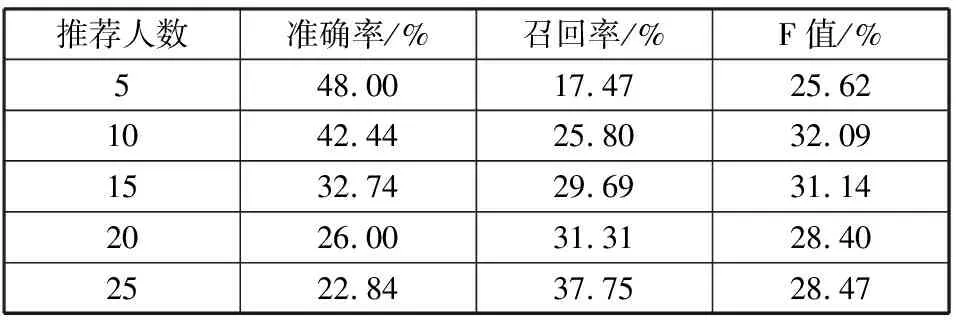
表1 本文算法在不同推荐人数下的推荐效果
在对该用户进行推荐时,对本文算法和对比算法推荐耗时进行统计,结果如图7所示。随着推荐人数的增加,文献[5]算法和CN算法的推荐所需时间均在缓慢地增加。而经典SAMME算法和本文算法的推荐所需时间几乎不受影响,推荐时长远远小于其余对比算法。其原因是经典SAMME算法与本文算法进行推荐时无需实时进行用户相似度计算,只需根据SAMME算法事先训练出的模型得到的规则进行推荐即可。
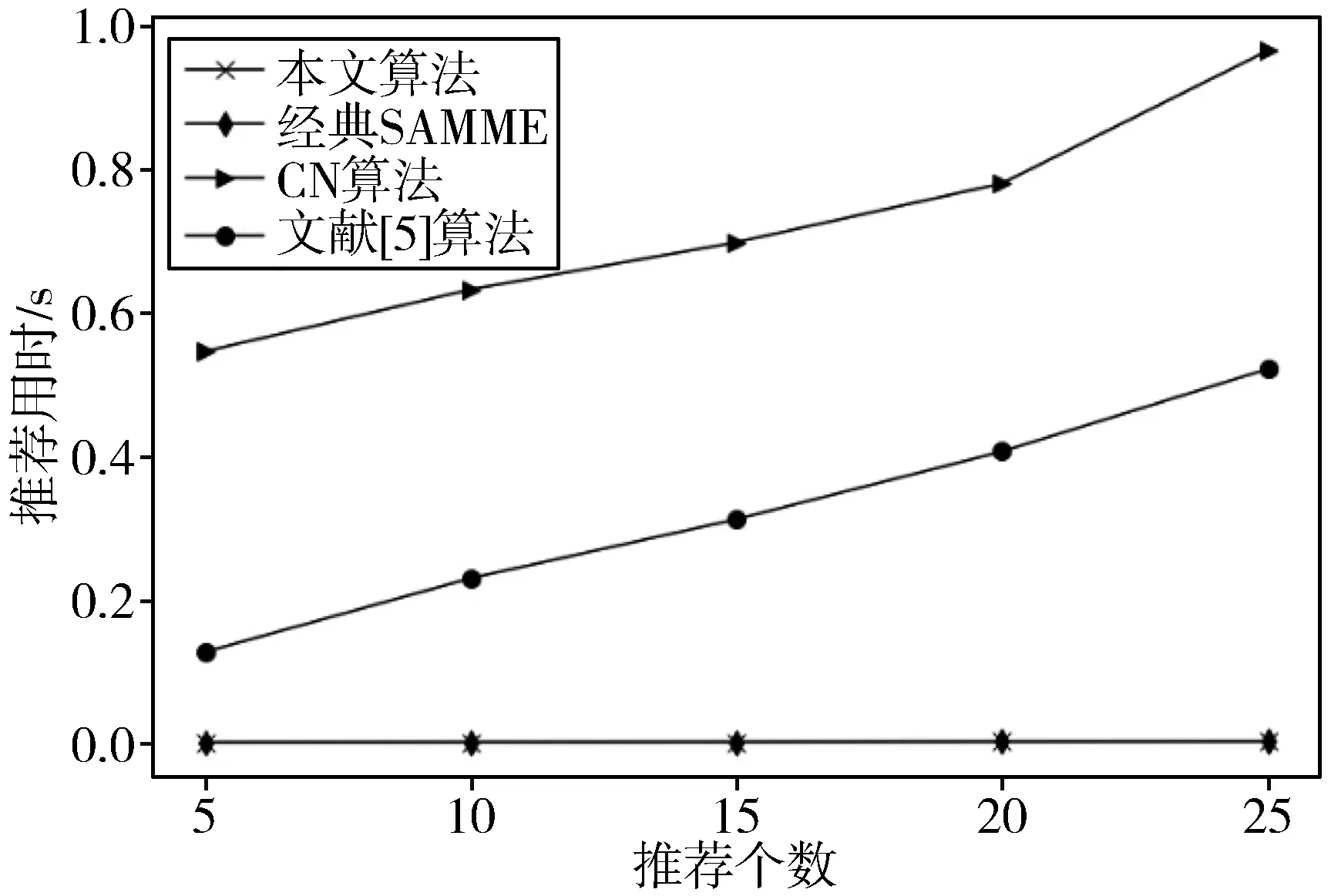
图7 推荐耗时
4 结束语
本文提出了一种基于用户信息向量聚类和改进SAMME的推荐算法,充分利用用户基本信息,在线推荐时只需要调用离线时训练出的SAMME模型进行预测,而不需要像传统的基于协同过滤推荐算法那样去在线查找相似度最近的用户,因此大大提高了推荐效率。最后在真实公开的新浪微博数据集上通过实验验证了该模型的有效性。实验结果显示与其他主流的推荐算法相比较,本文算法在准确率、召回率、F值方面都有所提升,能进一步提高推荐质量。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
电子设计工程(2015年6期)2015-02-27
电测与仪表(2014年15期)2014-04-04
