
基于生成式对抗网络的拟态蜜罐特征生成方法
2021-07-27 02:59刘祎豪
计算机与现代化 2021年7期
刘祎豪
(中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580)
0 引 言
随着网络技术的不断发展,网络攻击事件层出不穷,网络安全日益成为人们关注的焦点。传统的网络防御技术如防火墙、入侵检测技术等都是一种敌暗我明的被动防御,难以应对各种各样的攻击与威胁。蜜罐技术[1]改变了这种态势,它可以通过吸引、诱骗攻击者来延缓乃至阻止攻击与威胁,但传统蜜罐仍然有它的局限性,它是一个静态、固定不动的网络陷阱,不仅无法适应网络中的服务环境变化,部署困难,而且面临着一旦被攻击者识破,蜜罐陷阱就立即失效的问题,即“识破即失效”。拟态蜜罐[2]是模仿生物种群斗争中的拟态现象,通过综合运用模拟服务环境的保护色机制和模拟蜜罐特征的警戒色机制进行拟态演化的一种新型动态蜜罐技术,它的“识破即演化”的特性很好地解决了传统蜜罐所具有的问题,从而能够更加有效地迷惑和诱骗攻击者,实现网络中的攻防对抗。
拟态蜜罐的本质是要进行特征演化来迷惑攻击者,特征演化意味着需要产生新的特征,可见如何产生新的特征是拟态蜜罐研究领域的一个关键问题,而生成式对抗网络(Generative Adversarial Networks, GAN)给予了本文启示。GAN是Goodfellow等[3]在2014年提出的一种生成模型,其思想来源于博弈论中的二人零和博弈,GAN的特点是提取总结真实样本的特征,由噪声驱动来生成更丰富的特征样本。在当前的人工智能热潮下,GAN的提出满足了许多领域的研究与需求,同时也为这些领域注入了新的发展动力,同样,GAN也将为拟态蜜罐领域注入新的活力。受此启发,本文提出一种基于生成式对抗网络的拟态蜜罐特征生成方法,可以生成真假难辨的蜜罐或服务新特征,以解决拟态蜜罐中特征生成的问题。
1 相关工作
自蜜罐技术提出以来,相关研究取得了很大的进展,由于传统蜜罐存在部署困难、静态固定、多变性差等不足,研究者近年来进行了诸多有效的改进。Spizner[4]提出了动态蜜罐的概念,动态蜜罐技术能够实时地识别网络环境信息的变化并进行自适应,从而保证了部署的虚拟蜜罐适应当前网络的配置,解决部署蜜罐困难的问题。Naik等[5]提出了一种智能动态蜜罐,利用动态模糊规则插值,使得系统可以基于当前的网络流量条件学习和维护动态规则库,从而识别可能的指纹威胁。Park等[6]提出了动态虚拟网络蜜罐,动态虚拟网络蜜罐可以将攻击重定向到蜜罐从而保护目标系统。Shi等[7]提出基于区块链的动态分布式蜜罐,将蜜罐的动态特性应用于系统的4种服务中,并采用了以太坊平台分散系统以及使用私有链存储数据。Li等[8]提出了一种分布式的蜜罐方案,通过定期更改服务来迷惑攻击者,并实验验证了方案的有效性。Pauna等[9]设计了一个SSH自适应蜜罐系统,通过利用Deep Q-learning算法来决定如何与外部攻击者进行交互。石乐义等[10]提出拟态蜜罐的概念,推理分析了拟态蜜罐诱骗博弈中存在的贝叶斯纳什均衡策略,证明了拟态蜜罐模型具有更好的主动性、有效性和迷惑性,并总结了蜜罐发展的历史[11],对近年来蜜罐技术发展趋势进行了叙述与展望。贾召鹏等[12]提出了基于协同机制的Web蜜罐,设计了蜜罐簇协同算法,有效地增加了蜜罐系统对攻击的捕获能力。杨天识等[13]将openflow与蜜罐结合,能够将攻击者的请求路由到制定的蜜罐中,从而实现网络防御。
在动态蜜罐领域研究中,特征数据生成是关键的策略之一。过去一种比较流行的特征生成方法是遗传算法[14](Genetic Algorithm)。宫婧等[15]提出的基于遗传算法的蜜罐系统,利用遗传算法优化已有的训练规则集,辅助检测分流平台。Yang[16]利用honeyd虚拟蜜罐,捕获网络中可疑流量,然后利用遗传算法优化攻击者的特征规则为入侵检测提供辅助。刘德莉[17]结合遗传算法,提出了基于GA-MHEA算法的拟态蜜罐演化策略,提高了服务的抗攻击性。
可见,当前的蜜罐技术发展趋势,是与新技术应用相结合,提高蜜罐的欺骗能力以及改善传统蜜罐的架构,主要有:1)人工智能技术与蜜罐技术的结合。通过采用人工智能技术,使蜜罐具有智能交互性,可以提高其学习、反识别能力,从而更有利于防御决策。但人工智能模型一旦被攻击者获取识破,相应的防御决策也将失效。2)区块链技术和蜜罐技术的融合。利用区块链分布式、去中心化的技术,可以设计分布式蜜罐、分布式蜜网等架构;通过建立基于P2P架构的私有链或联盟链,可以保证系统数据隐匿性。但如何去治理和维护这样的架构是亟待解决的问题。3)演化技术与蜜罐技术的结合。在复杂的网络攻防环境下,蜜罐可通过演化以适应不同的网络环境,以提高蜜罐的自适应性。目前主要有通过遗传算法进行蜜罐演化,本文使用的基于生成式对抗网络的拟态蜜罐特征生成方法,结合人工智能技术,相比于遗传算法,无需设计复杂的遗传算子,只需通过生成器与判别器之间的对抗博弈,就能生成良好的数据特征,并且GAN更专注于特征生成任务。
GAN目前作为样本生成方法,它的应用非常广泛,包括图像与视觉[18]、语音与语言[19]、网络安全等各个领域。在网络安全领域中,Hu等人[20]提出MalGAN来生成恶意软件的对抗样本,MalGAN借助对抗样本的传递性,使用GAN来构造一个可以模拟判别器的替代模型,生成恶意软件的对抗样本,用来绕过恶意软件检测系统。Hitaj等[21]提出PassGAN来学习密码泄露分布信息,从而生成密码来进行密码猜测,PassGAN与最先进的密码生成工具相比具有竞争力,PassGAN总是能够生成与其他密码猜测工具相同数量的匹配项,且能输出更多的密码。袁辰等[22]提出DGA-GAN来对新产生的DGA域名进行了识别检测。潘一鸣等[23]提出了MNF-GAN模型,解决了恶意网络流训练数据缺乏而导致的检测稳定性差的问题。
2 生成式对抗网络基础
GAN[3]的结构如图1所示,主要由一个生成器和一个判别器组成,任意可微分的函数都可以用来表示GAN的生成器G和判别器D。生成器G是一个生成数据的网络,它接收一个随机的噪声N,通过这个噪声生成数据,记做G(N)。判别器D是一个判别网络,判断数据R是不是“真实的”。输出D(R)代表R为真实数据的概率,如果为1,则代表100%是真实的数据,而输出为0,则代表不可能是真实的数据。
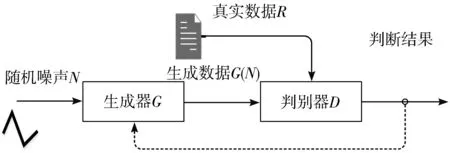
图1 GAN的结构
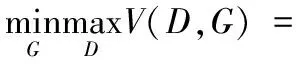
EN~pN(N)[log(1-D(G(N))]
(1)
式(1)展示了GAN的原理,其中G的目的是希望自己生成的数据“越接近真实越好”。即G希望D(G(N))尽可能加大,这时V(D,G)会变小。因此式(1)对于G来说是求minG。D的目的是希望D的能力越强,D(R)应该越大,D(G(R))应该越小。这时V(D,G)会变大。因此式(1)对于D来说是求最大maxD。
3 方法设计
3.1 实验流程
实验流程如图2所示(虚线方框代表流程模块包含的内容),本文提出的方法主要包括4个步骤:特征过滤及数据采集、预处理、MMHP-GAN训练、对生成数据结果的评估。进行训练的前提是拥有数据,因此首先对蜜罐特征数据进行特征过滤以及采集,通过过滤剔除冗余特征后采集数据得到原始数据集,之后进行预处理操作得到MMHP-GAN训练数据集,具体特征数据集获取及预处理过程将在3.2节中详细介绍。然后将数据集作为MMHP-GAN判别器的输入,对判别器进行迭代训练,每迭代训练10次判别器,训练一次生成器,生成器以高斯分布的噪声作为原始输入。每迭代训练一次生成器,生成器将生成的特征数据传给判别器,此时判别器将反馈梯度惩罚值(3.3节中的traindisccost)给生成器,以指导生成器的下一次迭代训练,直到梯度惩罚值下降到趋于一个较为稳定的值为止,此时得到一个良好稳定的生成器,能够用来生成良好的特征数据,具体的MMHP-GAN训练过程及结果将在3.3节中详细介绍。
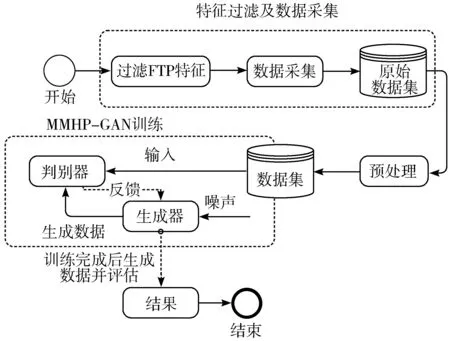
图2 实验流程
3.2 特征数据集获取及预处理
在3.1节提出的实验流程下,本文对蜜罐中的FTP服务特征进行数据采集,将vsftpd软件的FTP服务的配置信息作为服务特征进行收集。为简化研究方案,剔除冗余的特征数据,将vsftpd软件服务配置中41条FTP服务特征过滤出14条特征来进行采集,详细说明见表1所示。
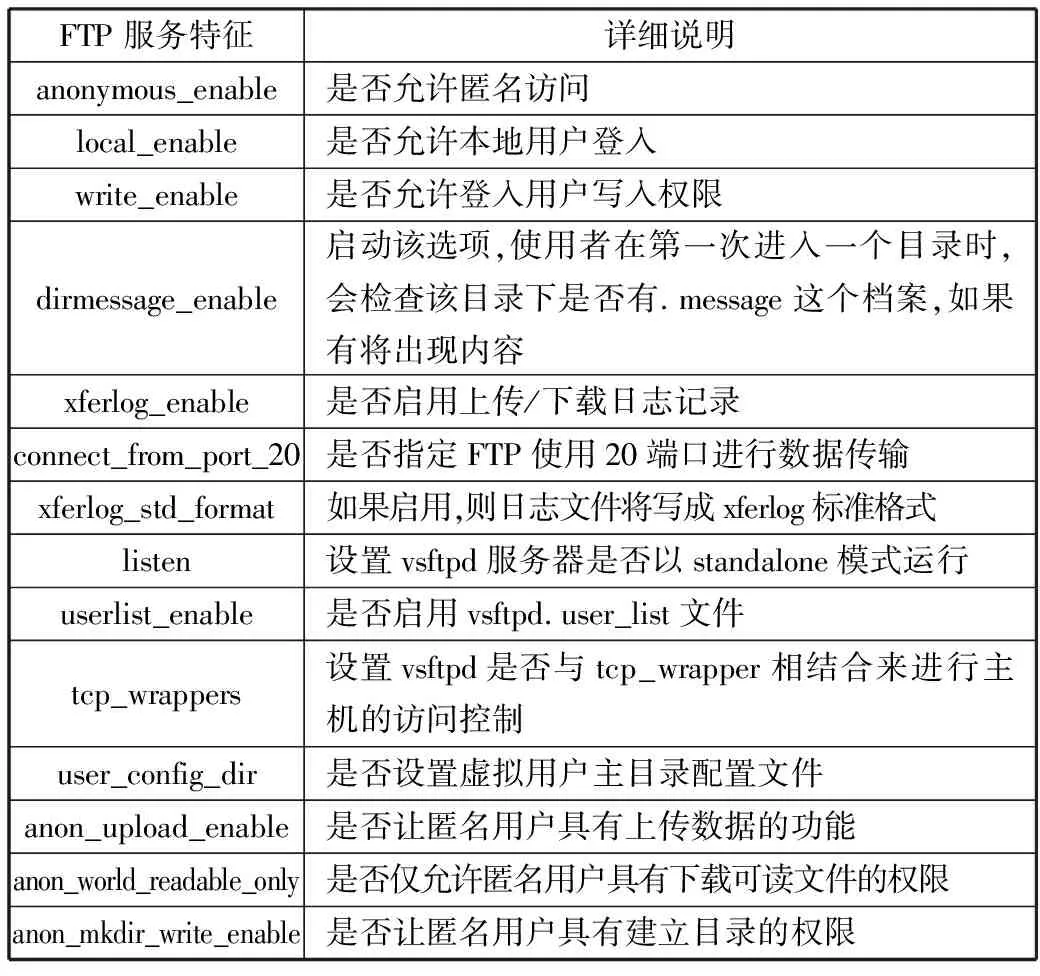
表1 FTP服务配置特征信息
本文数据采集过程中将蜜罐FTP服务配置特征设置变化周期为t=30 s,变化为随机,每变化一次将该时刻的特征数据收集,历经83 h,共收集到10004条特征数据,每一条特征数据模拟同一时刻一个蜜罐的FTP服务配置状态(实际不会部署那么多蜜罐,此处模拟的场景用于数据采集)。由于上述14个特征数据的值只有“yes”和“no”2种分类状态,因此可以将采集的数据集进行简单预处理,预处理过程将特征信息值处理为0和1作为真实数据输入,0代表“no”,1即代表“yes”。假设某条FTP服务特征数据为{anonymous_enable=yes, local_enable=yes, write_enable=yes, dirmessage_enable=yes, xferlog_enable=yes, connect_from_port_20=yes, xferlog_std_format=yes, listen=yes, userlist_enable=yes, tcp_wrappers=yes, user_config_dir=yes, anon_upload_enable=yes, anon_world_readable_only=yes, anon_mkdir_write_enable=yes},那么该条特征数据经过预处理后为{1,1,1,1,1,1,1,1,1,1,1,1,1,1}。
本文经过预处理后得到的训练数据为蜜罐特征数据,因此通过MMHP-GAN生成得到的数据为“伪蜜罐数据”,即可用于真实服务特征的演化,真实服务体现出类似蜜罐的特征,起到拟态蜜罐的警戒色作用,从而吓退攻击者。一般当FTP服务只提供简单的服务且服务功能不变时,攻击者认为蜜罐的可能性较大,比如在连续的一段时间t内,服务都表现出{1,0,0,0,1,1,0,0,0,0,0,1,0,0}的特征,对应表1,即只提供匿名用户的访问及上传数据功能,并启用日志记录功能,那么此时的特征表现类似蜜罐,攻击者放弃攻击。
3.3 MMHP-GAN及超参数设置
本文的MMHP-GAN的生成器与判别器都由1个一维卷积层以及n个残差块(n的数值将通过调整实验来确定最佳值)组成。残差块是Residual Networks(ResNets)[24]的核心部分,在训练一个深度神经网络时,随着网络层数增加到一定程度时,训练错误也随之增加。ResNets解决了这个问题,它在2个卷积层中间包含了一个“快捷连接”,可以将其视为这些层的包装器,并作为标识函数实现。通过连续并联这些残差块,ResNets可以有效降低随着神经网络层数增加带来的训练的错误。本文残差块由2个一维卷积层堆积形成。
MMHP-GAN实现依赖于ADAM[25]优化器来最小化训练误差,其超参数依据IWGAN[26]进行实例化并调整,参数调整详情见4.1节,超参数默认设置如表2所示。
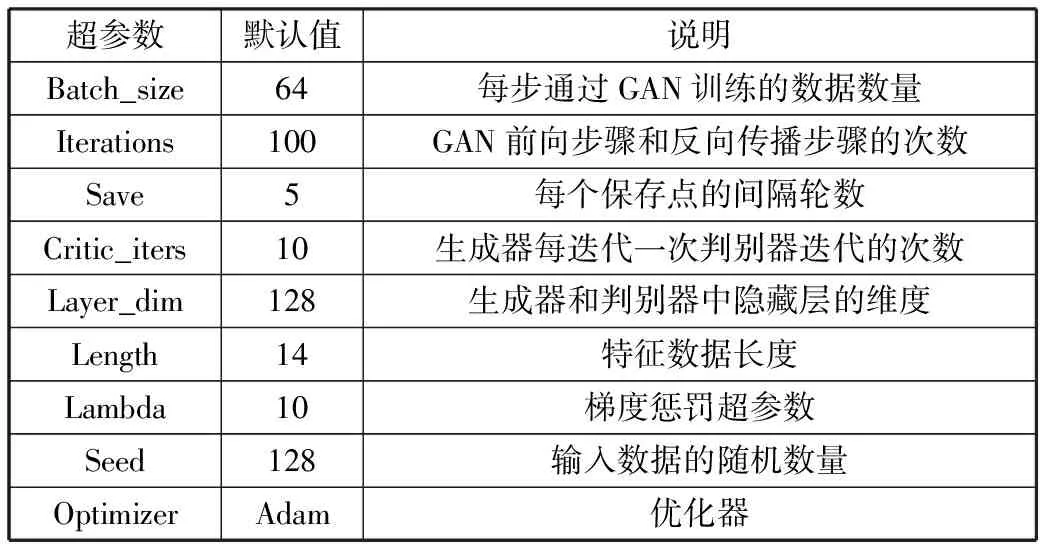
表2 超参数默认设置
4 实验与评估
4.1 MMHP-GAN参数调整及评估
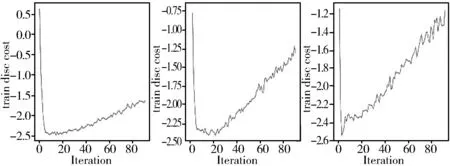
为了得到更好的MMHP-GAN,本文进行了一系列参数的调整以优化其结构,使其得到更好的训练结果,首先将残差块个数n分别设置为n=3,n=5,n=7,并且将Iterations设置为100,得到实验结果分别如图3和图4所示。
图3 不同残差块数量训练每轮时间随训练轮数的变化,Iteration=100
图4 不同残差块数量训练每轮的损耗随轮数的变化,Iteration=100
本文以time(训练每一轮所需要的时间)与train disc cost(训练判别器的损耗)2个指标来判断所训练MMHP-GAN的性能优劣,指标值越低,代表性能越好。train disc cost用式(2)表示,其中lamb表示梯度惩罚超参数,gradi表示第i轮的梯度惩罚数值。
(2)
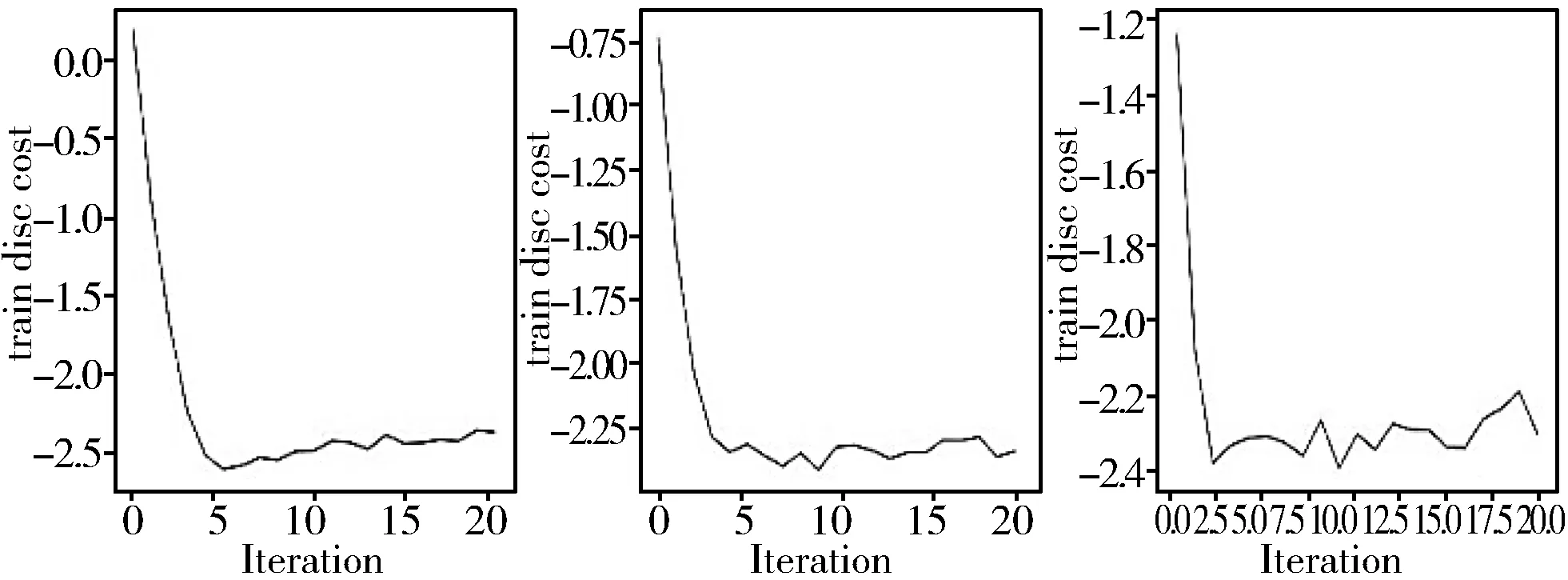
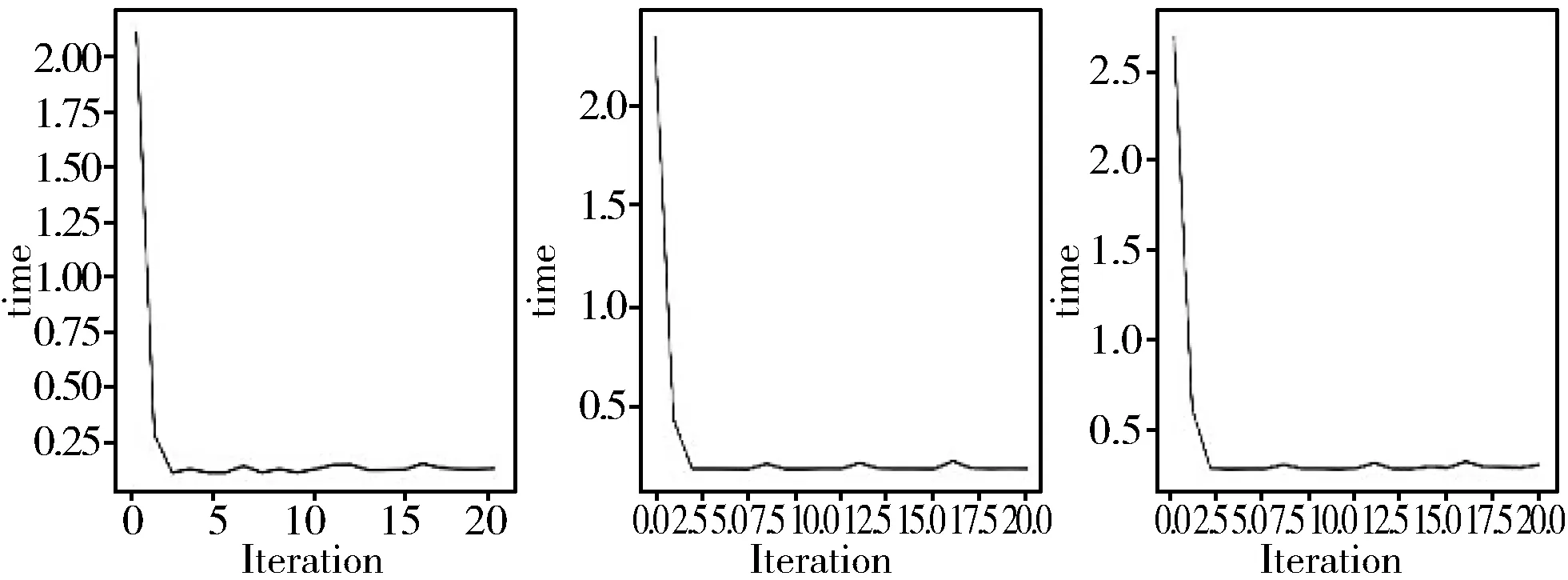
从图3可以看出,图3(a)、图3(b)、图3(c)这3种情况下,训练每一轮的时间随着训练轮数增加迅速下降并收敛到一个稳定值,3种情况下收敛速度基本一致,收敛后的稳定值也基本一致。从图4来看,图4(a)、图4(b)、图4(c)这3个图有较为明显的差距,但曲线趋势基本相同,从20轮左右开始,3种情况的判别器训练损耗随着训练轮数增加逐渐上升,这表明在图4(a)、图4(b)、图4(c)这3种情况下,MMHP-GAN在20轮训练之后逐渐变差,因此接下来将Iteration参数调为20,优化调整得到结果如图5和图6所示。

(a) n=3 (b) n=5 (c) n=7
(a) n=3 (b) n=5 (c) n=7
(a) n=3 (b) n=5 (c) n=7
(a) n=3 (b) n=5 (c) n=7
图5 不同残差块数量训练每轮时间随训练轮数的变化,Iteration=20
图6 不同残差块数量训练每轮的损耗随轮数的变化,Iteration=20
从图5来看,图5(a)、图5(b)、图5(c)这3种情况的收敛速度差别不大,均为2轮左右快速收敛到一个较低值,从收敛后的稳定值看,图5(a)情况稍好于图5(b)与图5(c)。从图6来看,图6(c)的train disc cost虽然收敛速度要比n=3、n=5快,但随着Iteration增加,其值也随之上升,且曲线震荡较大。图6(a)、图6(b)这2种情况收敛速度相差不大,在图6(a)、图6(b)这2图收敛后曲线波动都不大的情况下,图6(a)的train disc cost最小值要小于图6(b)的值,因此图6(a)稍优。综上分析,n=3、Iteration=20时,能训练得到一个较优的MMHP-GAN。
4.2 生成FTP服务特征的评估
为了评估生成FTP服务特征,本文定义重复率指标来进行操作,定义为生成的服务特征中与原数据集中重复数量与剔除无效特征后生成服务特征总数量的比值,重复率低表明MMHP-GAN生成器生成的以假乱真的数据在能够欺骗判别器的前提下,还能够学习到训练样本数据的分布知识,生成优良的特征数据,重复率计算公式如式(3)所示:
σ=α/β
(3)
在训练过程中,通过每5轮的训练作为一个节点进行保存,训练完成后,通过MMHP-GAN中的生成器进行FTP服务特征生成,分别查看不同保存节点生成器生成FTP服务特征的重复率情况,为了便于对比,本文设置生成特征数量统一为9984个,并且需要剔除生成特征中带有“unk”字段的无效特征,得到结果如表3所示。
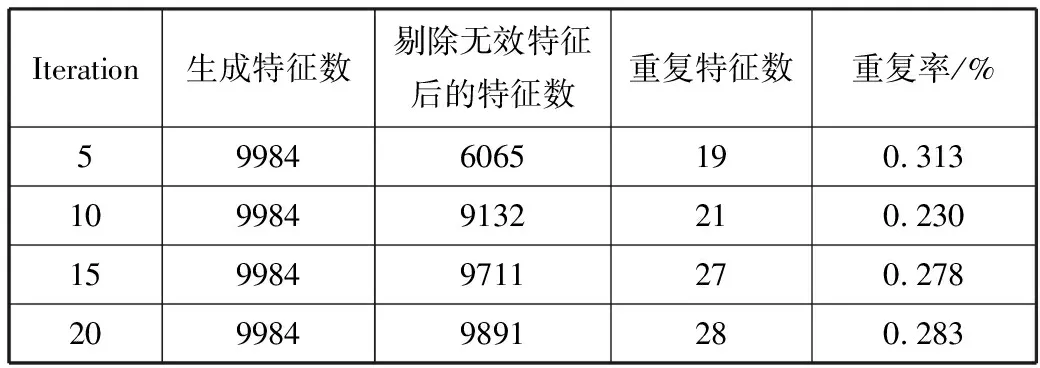
表3 生成FTP服务特征的重复率
从表3可以看出,在Iteration=5保存节点处的生成器生成了大量无效特征,并且重复率在4种情况中最高;Iteration=15以及Iteration=20时保存节点的生成器虽然生成的无效特征较少,但重复率要明显高于Iteration=10的情形。因此综合来看可以得出结论,如果需要生成较多的有效特征数量,还要尽量使得重复率低,那么可以使用Iteration=15节点处的生成器进行特征生成;如果要使得重复率尽可能低,那么选择使用Iteration=10节点处的生成器生成特征,此时为最低值0.230%。
4.3 抗攻击实验
为了进一步验证生成特征的有效性,本节设计抗攻击实验。由于在本章中,MMHP-GAN生成的是“伪蜜罐数据”,因此本节将模拟警戒色,验证警戒色情况下的抗攻击性。
根据4.2节得到的结论,取重复率最低时的特征,即Iteration=10时,得到的9132个特征进行演化,特征演化周期为c=20 s,即每20 s进行一次特征变化。本文设计的抗攻击实验为对FTP服务的syn-flood攻击实验,其中有1台攻击机,2个蜜罐,1台服务机,以及1台客户机。在100 Mbps带宽的局域网中,通过实验测得服务器的最大承载量为60 Mbps。假设实验场景为攻击者知晓环境中存在蜜罐,先进行扫描,若在连续的一段时间t内,服务功能较少且不变,那么认为是蜜罐,不进行攻击,否则进行攻击,实验设置t=60 s。在不同的流量下,每次实验分别进行扫描攻击10次,取平均值进行分析。
图7显示了在不启动警戒色与在30 Mbps时启动警戒色2种情况中,不同攻击流量下,服务所受到的攻击流。在30 Mbps攻击流量之前,服务在2次实验下所受攻击流量相差微小;在30 Mbps攻击流量之后,启动警戒色机制,在启动警戒色后,服务特征进行演化,在攻击者进行10次的扫描攻击之中,平均能够规避3~4次攻击者的攻击,这是由于在t时间内,服务表现出了类似蜜罐的特征,攻击者选择不进行攻击。因此,启动警戒色机制可以有效减少服务器所受到的攻击。
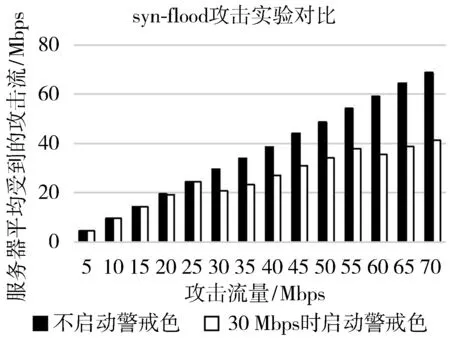
图7 syn-flood攻击实验对比
4.4 其他方案与本文方案的对比
本节从算法技术实现以及实验结果2个方面来与刘德莉[17]的工作进行对比。
1)技术实现上的比较。
刘的工作基于遗传算法进行特征演化,遗传算法的操作是一个迭代的过程:通过选择合适的父代特征,对父代特征向量按照一定的概率进行交叉和变异,从而得到子代新特征,之后通过定义适应度函数去判断新特征是否符合要求,否则继续进行交叉和变异操作,重复上述过程直到迭代停止。但是进行交叉变异的概率通过经验而定,迭代停止的条件由人为设定,当新一代种群特征达到最优解的设定标准时即停止迭代,这是该算法的不足之处。本文的方案同样是迭代的过程,但不同的是,本文方案通过判别器与生成器之间的反馈机制,判别器对生成器的“指导”作用,来训练生成器,从而产生良好的特征。并且,在当train disc cost处于较低且平稳时,终止迭代,该过程是一个自动的过程。从4.2节得出的结论来看,本方案能够生成良好的特征。
2)实验结果对比。
为了从实验上验明本文方案的优越性,本文通过与刘的工作中同样的扫描攻击场景进行对比实验,即攻击者攻击分为扫描加攻击2部分,通过扫描确认是否为蜜罐,若攻击者认为是蜜罐,则不进行攻击,否则进行攻击,连续攻击20次,设定演化周期为20 s。在不同攻击流量下,测量服务所受到的平均攻击流,实验结果如图8所示。
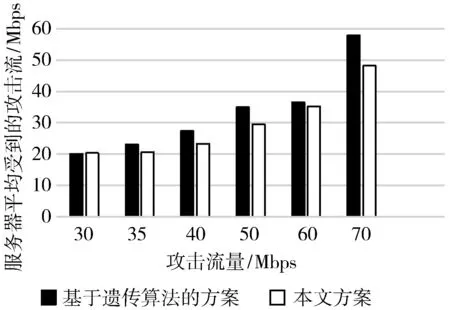
图8 实验结果对比
由于本文方案从30 Mbps攻击流量开始启动警戒色机制,即开始演化,因此攻击流量<30 Mbps的数据不参与对比讨论。图8显示了攻击流量≥30 Mbps,2种方案服务器所受到的平均攻击流情况。通过对比可以看到,除了在30 Mbps攻击流量情况下,本文方案服务器所受到的平均攻击流要略高于基于遗传算法的方案,其他情况服务器受到的平均攻击流都要小于基于遗传算法的方案。因此表明,总体来说本文方案要优于刘的基于遗传算法的方案。
5 结束语
本文结合生成式对抗网络与拟态蜜罐中的“对抗”与“博弈”思想,提出了一种基于生成式对抗网络的拟态蜜罐特征生成方法MMHP-GAN。本文以vsftpd软件中ftp服务配置的特征为例进行数据采集,并且通过剔除冗余数据特征、预处理之后得到可用于MMHP-GAN训练的数据集。通过实验,可以得到较好的特征数据,将生成的特征数据用于蜜罐演化,能够有效抵挡攻击者的攻击,并且对比当前已有的特征生成方案,本文方案更具有优越性。
猜你喜欢
指挥与控制学报(2022年4期)2022-02-17
小哥白尼(趣味科学)(2021年5期)2021-08-13
中外文摘(2019年20期)2019-11-13
知识窗(2019年6期)2019-06-26
学苑创造·A版(2019年12期)2019-01-10
系统管理学报(2018年3期)2018-08-13
爱你(2018年16期)2018-06-21
北方文学(2018年2期)2018-01-27
中国三峡(2017年4期)2017-06-06
指挥与控制学报(2015年4期)2015-11-01
