
多特征融合结合机器学习算法快速筛查葡萄膜炎∗
2021-07-24 07:33吕小毅
新疆大学学报(自然科学版)(中英文) 2021年4期
屈 莹,陈 晨,吕小毅
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学 软件学院,新疆 乌鲁木齐 830091;3.新疆维吾尔自治区信号检测与处理重点实验室,新疆 乌鲁木齐 830046)
0 引言
葡萄膜炎是一种很典型的眼科疾病,是睫状体、脉络膜组织以及虹膜炎症的总称[1].根据病因分为感染性葡萄膜炎及非感染性葡萄膜炎;根据其发病位置可分为前葡萄膜炎、中葡萄膜炎、后葡萄膜炎以及全葡萄膜炎[2].葡萄膜炎具有很高的致盲性,极易引起并发性白内障、继发性青光眼等眼科疾病.基于这些原因葡萄膜炎备受国内及国际医学领域的关注[3,4].光学相干断层扫描(OCT)是一种成像技术,眼底OCT提供了眼睛的活体准组织学图像,与视网膜组织病理学有很好的相关性,其分辨率超过任何其他非侵入性技术,使得图像的解释比其他类型的视网膜成像更容易且减少主观的成分.现代OCT技术不仅应用于疾病的诊断调查中,还可以应用在临床过程和治疗反应的监测中,对病情诊断非常有用[4−6].
Fang Leyuan等人提出了一种基于LACNN的视网膜OCT图像分类方法,利用LDN检测到黄斑病变,引导分类网络聚焦于与局部OCT相关区域更具鉴别性的信息[7];Sun Yankui等人提出了一种基于局部特征和移动距离(EMD)的OCT图像自动分类方法,并在正常皮肤和红斑痣两种OCT图像集来评估这种算法[8];Fang Leyuan等人提出了一种具有复合核的主成分分析网络(PCANet-CK),将其用于对三维视网膜OCT图像进行分类,结果始终比HOG-SVM方法表现更好,平均灵敏度提升了9%[9];Lu Wei 等人开发了一种基于深度学习的新智能系统用以对视网膜OCT图像进行自动分类[10].但还没有针对葡萄膜炎的辅助诊断或筛查的研究,因此本文设计了一种更为快速的葡萄膜炎辅助筛查方法.目前,葡萄膜炎的诊断方法包含眼部检查、实验室检查、影像学检查等,荧光素眼底血管造影(FFA)结合光学相关断层成像技术(OCT)在影像学诊断中具有重要的诊断价值[11].对于眼底OCT图像分类的实际操作中依然存在费时、操作复杂、人工依赖性强等问题,因此研究出一种葡萄膜炎的辅助诊断方法具有重要意义.
本文分别对正常眼底OCT图像样本和葡萄膜炎眼底OCT图像样本选取了形态、灰度差分统计、灰度梯度共生矩阵、小波变换等4种187维特征,将其进行串行融合,再通过Lasso(Least absolute shrinkage and selection operator)方法进行特征选择[12];然后利用六种不同核函数的SVM,六种不同距离度量方式的K最近邻(KNearest Neighbor,KNN)及五种集成算法(Ensemble)对特征选择的结果进行分类,最终选取最优分类结果,并通过ROC曲线评价分类效果[13].
机器学习算法广泛应用于医疗领域,既减少了医疗工作者的负荷,也保障了患者治疗过程的高效和安全.许多机器学习或深度学习方法被广泛用于基于图像进行的疾病分类[14,15],如支持向量机[16]、随机森林方法[5]等.本文首次将人工智能分类算法应用于葡萄膜炎眼底OCT图像的实际分类中,结果显示本研究在葡萄膜炎眼底OCT图像的实际应用中具有分类准确与快速便捷的特性.
1 相关工作
采用形态、灰度差分统计、灰度梯度共生矩阵、小波变换4种特征提取方式.其中,形态特征是对图片提取的,将特征进行串行融合,然后利用Lasso算法进行特征选择,Lasso学习后生成的稀疏解用于选择有效特征、消除冗余信息,将选择后的特征串行融合;最后,进行学习器的训练和测试,研究的主要实验流程如图1所示.

图1 实验流程Fig 1 Experimental process
1.1 图像数据的采集和处理
本文所使用的眼底OCT图像片样本均来自新疆维吾尔自治区人民医院,采集均符合医学标准.由于葡萄膜炎是一种较为罕见的疾病,还涉及到病人的隐私信息等,故其OCT图片的采集较为困难.我们经过长时间采集,得到了31张眼底OCT图像用于本文的研究,另外本文是将机器学习算法与葡萄膜炎的诊断相结合的探索性研究,图片数量较少,在以后的研究中,会继续尝试在实验中增加样本量,并结合其他算法研究.样本含有健康人眼底OCT图像18张,葡萄膜炎患者眼底OCT图像13张,见图2.
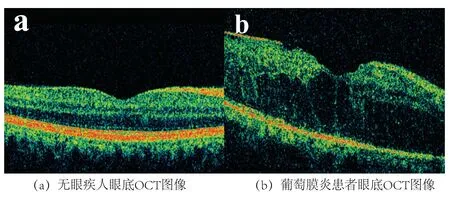
图2 眼底OCT图像样本Fig 2 Fundus OCT image sample
将所有获取的图片像素均设置为580×400,图像的预处理在MATLAB R2016a软件中完成,图像分类在MATLAB分类学习工具箱(MATLAB Classification Learner Toolbox)中完成.
1.1.1 灰度差分统计
灰度差统计是用来描述纹理图像的每个像素与其相邻像素之间的灰度变化的方法,它通过近似图像中相似点的像素值来达到消除干扰像素的目的.设(x,y)为图像中的一点,则该点与相近一点(∆x+x,∆y+y)的灰度差值为g∆(x,y)=g(x,y)−g(x+∆x,y+∆y),其中:g为灰度差分.如果图像灰度级为m,令点(x,y)在所给图像上移动得g∆(x,y)的直方图,由直方图可知g∆(x,y)取值的概率.在此基础上,可用一些特征值对图像进行量化描述,常用特征描述子有对比度、角度方向二阶矩、平均值、熵等.对比度反映了图像的清晰度和纹理沟纹深浅的程度;角度二阶矩反映了图像灰度分布的均匀性;平均值主要反映了图像的整体灰度值;而熵反映了图像具有的信息量.本文选择了平均值、对比度、熵这三个描述子进行特征提取.
1.1.2 灰度梯度共生矩阵
灰度梯度共生矩阵是一种同时利用图像的像素灰度和灰度变化来共同表达纹理特征的方法,它将图像的梯度信息与灰度共生矩阵结合起来,即将像素的灰度与边缘梯度的统计分布联合起来,更能反映图像纹理的微观特征与变化.
设图像为f(x,y),x=1,2,···,N,灰度级为L.利用梯度算子获取其梯度图像g(x,y),再进行灰度级离散化.设灰度级的数目为Lg,则新的灰度为
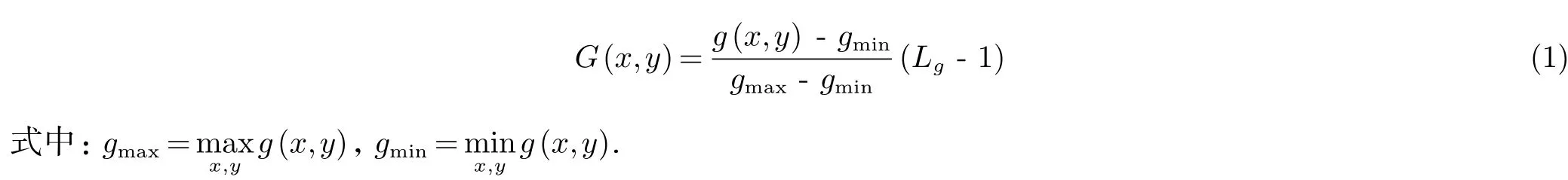
离散化后,梯度影像为G(x,y),x=1,2,···,M,y=1,2,···,N,其灰度级为Lg.灰度-梯度共生矩阵为
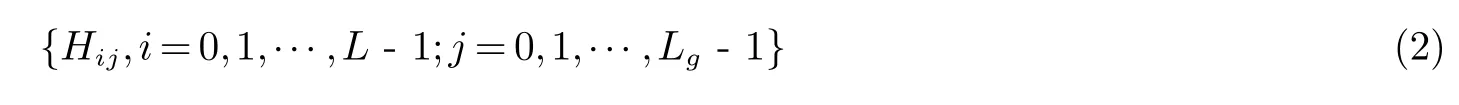
式中:Hij定义为集合{(x,y)|f(x,y)=i,G(x,y)=j}中元素的个数.
在这4种特征提取中,特征维度分别为8维、4维、15维、160维,共187维,不同特征提取方法的详细情况见表1.

表1 不同特征提取方法的详细情况Tab 1 Details of different feature extraction methods
1.2 特征融合和特征选择
本文共提取了187维特征,包括形态特征、灰度差分统计纹理特征、灰度梯度共生矩阵和小波变换.这其中必定包含冗余特征,删除冗余特征可以极大地减少学习器学习的时间,又能够确保准确性.
1.2.1 基于Lasso的特征选择
Lasso算法的主要思想是利用L1正则化产生稀疏回归解,即在构建线性回归模型时添加惩罚项,使得回归系数之和小于某个阈值,残差平方和最小化,将一些特征变量的回归系数压缩为0,达到降维的目的.Lasso算法能够同时进行特征选择和正则化.Lasso能够展现变量选择的详细过程,同时还能有效的处理建模中出现的多重共线性问题.公式(3)是单标记学习中,Lasso算法的最小残差平方和表示方法

式中:阈值γ是可变的,γ是回归系数βj的1范式惩罚,防止过拟合.若γ值取得很小,对于这些相关性较小的特征变量,则可以将其系数压缩为0,然后删除这些特征,保留强相关特征,以达到降低维度的目的.相反,若γ值取得很大,将不再有约束作用,任何特征都不会被删除.
在保证准确率的前提下Lasso特征选择方法具有降低维度、筛选显著特征、寻优时间短、模型复杂度小等优点[6,17,18].基于上述优点,本文选择Lasso算法进行嵌入式特征选择,选择其中3维进行后续的分类实验,同时采用十折交叉验证的方法进行可靠性评估.图3为Lasso特征选择十折交叉验证图.
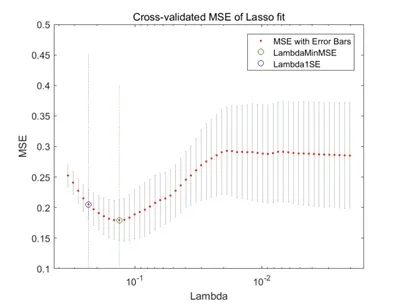
图3 Lasso 特征选择十折交叉验证图Fig 3 10-fold cross-validation diagram of LASSO feature selection
1.3 眼底OCT图像样本的分类
在完成眼底OCT图像样本的特征处理后,通过Lasso算法选出了3维特征作为后续分类实验.本文的思路是分别使用SVM、KNN、Ensemble三种算法,然后对比三种方法的准确率,从而选择出最优的一个.最后通过计算ROC曲线下AUC的大小评估分类效果,从而实现将机器学习应用到眼底OCT图像的实际分类中.
为了更直观的选择不同分类算法中分类效果最好的一种,本文选择了不同核函数的SVM和不同距离度量方式KNN算法,同时还选择了五种不同的Ensemble对眼底OCT图像进行分类研究.
1.3.1 SVM算法
SVM的主要思想是建立一个超平面作为决策曲面,最大化样本的正例和反例之间的隔离边缘[19].将使得样本具有最大间隔的并且能将两类正确分开(训练错误率为0)的平面称为最优超平面,寻找最优超平面即正反例间隔最大化问题,对于近似线性可分问题,引入了松弛变量,使最大间隔问题归结为一个二次规划问题,使用拉格朗日乘子法可得到其“对偶问题”.在现实中,很难确定合适的核函数使得训练样本在特征空间中线性可分,于是引入了“软间隔”的概念,即允许某些样本不满足约束条件.于是优化目标表示为

以上讨论的是线性可分的情况.在数据非线性可分的情况下,通常引入一个能够将样本空间映射到更高维特征空间的非线性映射.由于这个非线性映射是很难知道的,所以我们引入一个核函数K(xi,xj)来代替高维空间中的内积,在高维特征空间中设计线性最优超平面,得到输入空间中的非线性学习算法,使低维非线性问题转化为高维线性可分问题.
下面列出几种常用的核函数:
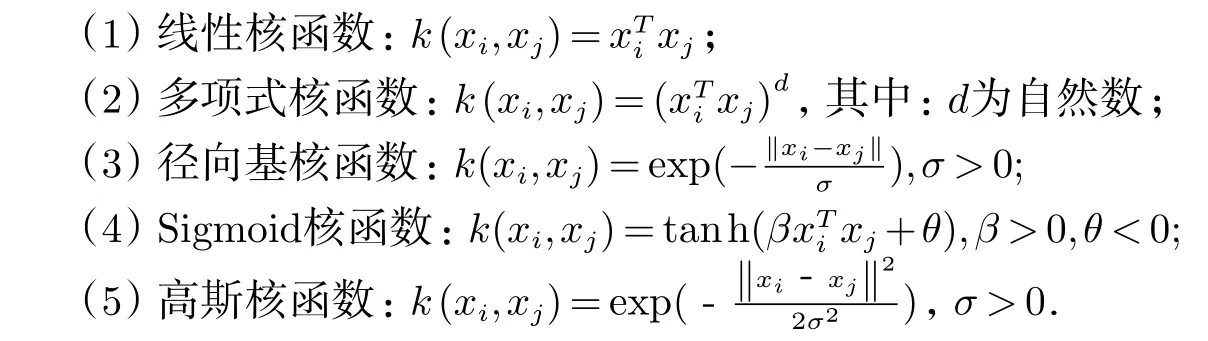
1.3.2 KNN算法
KNN(K-Nearest Neighbor)分类算法也称为K近邻法,是一种稳定而有效的算法,是目前机器学习方法中最为简单的算法之一.其工作原理为给定待分类的测试样本,基于某种度量标准找出训练集中与其最靠近的k个训练样本,然后基于这k个样本的信息来进行预测.
KNN分类算法与其他算法不同,它没有显示出训练过程.它在分类阶段不需要进行训练和学习,只是把样本的特征属性保存起来,没有训练时间开销,等收到测试样本再进行处理,因此也称为“惰性学习方法”.KNN分类算法的优点是原理简单,分类模型相对最为简单有效,实现起来比较容易,在类别分布较复杂的场合中,也能实现较好的效果,是模式识别中比较重要的技术之一.
选择合适并且实用的相似度函数是KNN分类算法最为关键的步骤.常用的相似度函数有以下几种:
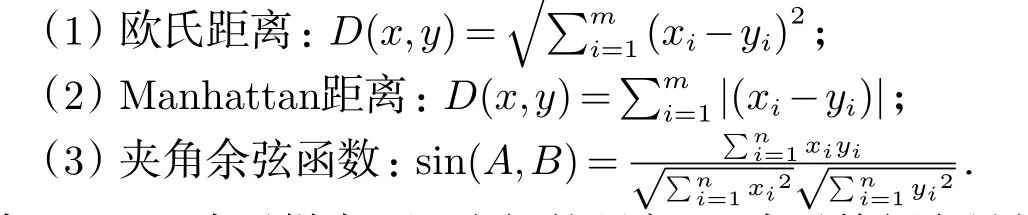
式中:D(x,y)表示样本x和y之间的距离,m表示特征向量的维数.
1.3.3 Ensemble算法
集成学习(Ensemble learning)算法的原理是通过构建多个学习器,并将它们结合起来形成一个集成学习分类器,能够改善单个基学习器泛化能力.根据集成学习系统,可知一个集成学习分类器由两部分组成:产生一组个体分类器和结合个体分类器,若产生的个体分类器是同类型的,则这种集成是“同质”的,每一个个体学习器称为“基学习器”;若个体分类器不是同种类型的,则是“异质”集成,每一个个体学习器被称为“组件学习器”.图4为集成学习算法的示意图.集成系统包括三个重要因素:样本子集、学习器及结合策略.样本子集是基于原始样本集获取的多个样本子集;学习模型是指对样本子集进行学习的模型;如何将多个学习模型的输出相结合就是结合策略.
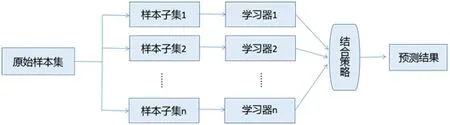
图4 集成学习算法原理图Fig 4 Schematic diagram of Ensemble learning algorithm
通常情况下,若想集成学习的泛化误差优于单个学习器,需要让个体学习器“好而不同”.“好”体现在对集成的个体学习器自身准确率有一定要求,“不同”体现集成系统不仅应该包含一组准确率较高的个体学习器,同时也应该包含一些错误学习分布在不同的样本子集内的个体,即个体学习器之间要具有差异性.如何产生和构造“好而不同”的个体学习器是集成学习算法的关键.集成学习中常用的结合策略有投票法、加权平均法和学习法.
2 图像增强和迁徙学习算法
2.1 图像增强

图像归一化:为了防止低值区域的信息被高值区域的信息所掩盖,对图像进行归一化处理,见式(10).

2.2 迁移学习算法
本文采用在ImageNet数据上预训练的DenseNet121、ResNet50 v2、Inception v3模型进行迁移学习,ImageNet数据集和眼底OCT图像两者之间的差异较大,故迁移模型的二次训练程度较大,由于底层卷积层提取的是图像中低级抽象几何特征,通用性强,可以迁移至眼底OCT图像的识别训练中,故冻结第一层卷积网络.其次在ImageNet上预训练后的深度网络模型的TOP层过度的特异化,其全连接层权重参数明显不适合进行迁移训练,本文所有深度模型均去除预训练模型的TOP层,采用自定义的全连接层和softmax分类器进行模型的迁移训练.迁移训练中,至关重要的还有学习率的设置、损失函数的选择、优化器的配置及过拟合的预防措施.损失函数是迁移训练中的目标函数,是权重变化方向的指标,损失函数选择的优劣直接决定迁移学习训练结果的好坏,本文采用Categorical Cross Entropy (CE)函数作为损失函数,其基本原理见式(11).

其中:x表示输入样本,C为期待的分类总数,yi为第i个真实标签,fi(x)对应为模型的输出值.优化器即训练过程中寻优的算法也是迁移训练中最为重要的参数之一,本文采用Stochastic Gradient Descent (SGD)作为优化器算法,其一次只进行一次更新,没有冗余,速度较快且可以增加新样本,其基本原理见式(12).

式中:η为学习率也称之为步长,也是迁移训练中最为重要的参数之一.本文训练中采用变化学习率的方式,在0~60 epochs时学习率为0.1,在61~120 epoch时学习率为0.01,在121~180 epoch时学习率为0.001,在181及以上的epoch时学习率为0.000 1.本文按提出的图像增强方法进行图像增强.此外,在所设计的TOP层中对卷积核进行正则化处理、在全连接后添加Dropout (DP)层和Batch Normalization (BN)层.本文采用的正则化处理算法是LASSO,在卷积核中实现的基本原理见式(13).

文中采用的Dropout层后的前向计算公式见式(14),(15)

3 实验与结果分析
3.1 分类结果
3.1.1 机器学习算法分类结果
将特征选择的结果用于分类实验中.所有实验均采用了5折交叉验证,即通过将数据集划分为5折然后估计其在分类模型中的准确性,取其平均值.
SVM具有很多优点,如推广能力好、分类速度快、能够解决局部最小问题、结果易解释及适合小样本分类问题等特点[16,20,21].不同核函数的SVM算法具有不同优缺点,本文选择了Linear SVM、Quadratic SVM、Cubic SVM、Fine Gaussian SVM、Medium Gaussian SVM、CoarseGaussian SVM六种不同核函数的SVM算法,不同核函数获得了不同的分类准确率.KNN算法具有思想简单训练时间的复杂度较低,适合大样本的自动分类等优点[22−24].本文选择了Fine KNN、Medium KNN、Coarse KNN、Cosine KNN、Cubic KNN、Weighted KNN等六种不同距离度量方式KNN算法,不同距离度量方式获得了不同的分类准确率.Ensemble算法通过构建并结合多个机器学习器来完成学习任务,这就使得Ensemble在机器学习算法中拥有较高的准确率.加入Ensemble算法可以更全面的对比分类效果,本文选择了Boosted Trees、Bagged Trees、Subspace Discriminant、Subspace KNN、RUSBoosted Trees等五种Ensemble,不同的Ensemble获得了不同的分类准确率,图5为SVM、KNN、Ensemble三种分类器的分类准确率柱状图.

图5 SVM、KNN、Ensemble分类准确率柱状图Fig 5 Histogram of SVM,KNN,Ensemble classification accuracy
结果显示,在不同核函数的SVM分类算法中,Medium Gaussian SVM取得了最好的分类效果,其准确率达到了90.3%;在不同距离度量方式的KNN算法分类中Fine KNN、Medium KNN、Cubic KNN、Weighted KNN所取得的分类效果一致,其准确率均为87.1%,不同Ensemble算法中Subspace Discriminant所取得的分类效果最好,其准确率为83.9%.选取这些分类效果中最好的Medium Gaussian SVM算法用于本研究的结果分析.
3.1.2 迁移学习算法分类结果
迁移学习也称为归纳迁移.它的主要思想就是从相关的辅助领域中迁移标注数据或知识结构,将其用来完成或改进自己的学习模型.这样不仅可以缩短训练时间,还可以在数据量较小的情况下,获得更加适用准确的模型[25,26].
在迁移训练中,较常见的问题是过拟合,它对训练结果影响也是较大的,预防过拟合的最有效的方法是进行图像增强,扩大样本数量,本文将原有的31张样本图像扩大了20倍,为620张.
图6是迁移学习算法的训练和测试准确率结果图,其中图6(a)、图6(b)、图6(c)分别是DenseNet121、ResNet50 v2、Inception v3模型的结果图;表2是三种模型的测试准确率,分别为64.1%、56.4%和56.4%.
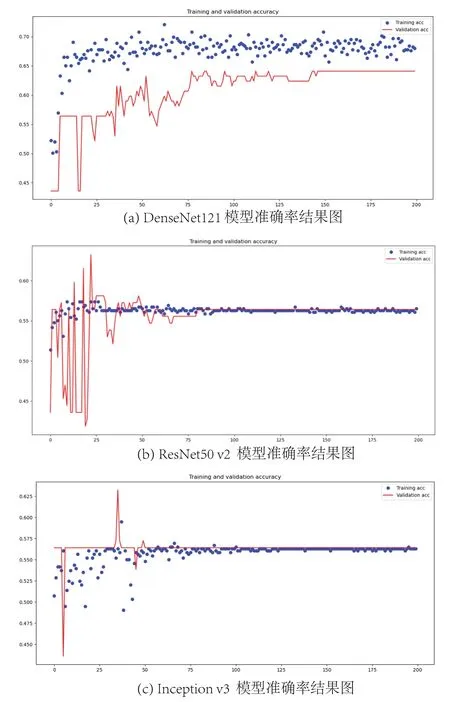
图6 迁移学习分类准确率结果Fig 6 Results of transfer learning classification accuracy

表2 不同迁移学习模型测试准确率Tab 2 Test accuracy of different transfer learning models
由实验可知,迁移学习模型的准确率并不高,由于原始数据样本量较少、类间样本相似度较大等,即使扩大了数据量,还是难以提高其准确率.
3.2 实验结果分析
Medium Gaussian核函数是应用最广泛的核函数,具有较强的局部性,无论大样本还是小样本都有比较好的性能,具有决策边界多样、参数易选择、可映射至无限维等优点.其本质是比较不同样本之间的“相似度”且构造一个描述“相似度”的空间,使得相似的样本可以聚到一起从而达到线性可分的目的,但其缺点是可解释性较差,计算速度较慢,参数选择不好时容易过拟合.在对葡萄膜炎眼底OCT图像的实际分类实验中,Medium Gaussian SVM算法的分类准确率达到了90.3%.
因此,本文通过对该算法分类结果的混淆矩阵以及ROC曲线对结果的精度和可靠性进一步分析.图7为Medium Gaussian SVM算法分类结果图.
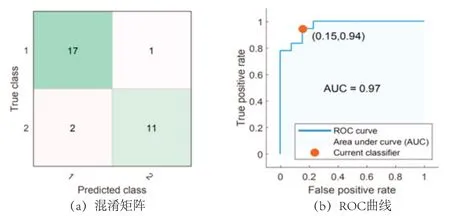
图7 Medium Gaussian SVM算法结果图Fig 7 Results of the Medium Gaussian SVM algorithm
混淆矩阵也叫误差矩阵,是评价分类性能的常用形式.在图像分类中,混淆矩阵中可以直观明了的表示样本的实际类别与分类器的分类结果的关系[27].由图7(a)结果显示判断正确的图像共28张,判断错误的图像共有3张(图中数字“1”为健康人眼底OCT图像,“2”表示葡萄膜炎眼底OCT图像).因此,可以很清楚的从混淆矩阵中发现图像分类误差较小,分类精度较高.
由混淆矩阵引入ROC曲线,ROC曲线以图示的方式将不同界值点时的灵敏度与特异性结合在一起,是用于评价实验准确率的指标.对于分类方法中特异性和敏感性的关系,ROC曲线可以给出评价,二分类问题中ROC曲线是评价分类方法可靠性的综合代表.在ROC曲线中AUC的大小是衡量学习器优劣的一种性能指标,通常AUC值越大代表学习器越优越.如图7(b)所示,Medium Gaussian SVM算法的ROC曲线中AUC值达到了0.97,得到了较好的分类效果,证明该算法分类性能较好.
由上述实验可知,与迁移学习算法相比,Medium Gaussian SVM算法的准确率更高,这体现了SVM适用于小样本量的特点,而受限于图像样本的数量,迁移学习算法无法达到令人满意的效果.
4 结论
本文通过对选取的不同分类算法的准确率对比及ROC曲线中AUC对比发现,基于Medium Gaussian核函数的SVM算法获得了最好的分类准确率以及分类评价指标;迁移学习丰富了本文的研究方法,但没能明显提高分类准确率.但该研究成功的将机器学习分类算法应用于眼底OCT图像的实际分类中.
由于葡萄膜炎疾病较罕见,本研究的缺点是采集数据还不够完备、数据量较小.因此,在后续的研究中,我们将努力获取更多更全面的数据,通过不断的改进和完善实验过程,不断创新实验方法以获得更好的结果.未来,机器学习和人工智能在葡萄膜炎以及其他眼科疾病的诊断中的应用是非常有发展前景的.
猜你喜欢
兵器装备工程学报(2022年8期)2022-09-13
北京航空航天大学学报(2022年6期)2022-07-02
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
集装箱化(2021年1期)2021-04-12
健康体检与管理(2021年10期)2021-01-03
中国信息技术教育(2020年2期)2020-02-02
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16

- 新疆大学学报(自然科学版)(中英文)的其它文章
- On Size,Order,Minimum Degree and Conditional Diameter of Graphs∗
- 给定点数,最小度和条件直径的图的边数的上界∗
- Some Logarithmic Submajorisation Inequalities Related to Heinz Mean∗
- 关于Heinz均值的Log-次优化不等式∗
- Logarithmic Submajorization and Symmetric Quasi-Norm Inequalities on Operators∗
- 有关算子的一些Log-次优化不等式和对称拟范数不等式∗