
一种WM多模匹配算法的研究与改进
2021-07-16 08:02:58周延森张维刚
计算机应用与软件 2021年7期
周延森 张维刚
1(国际关系学院网络空间安全学院 北京 100091) 2(哈尔滨工业大学计算机科学与技术学院 山东 威海 264200)
0 引 言
模式匹配算法在搜索引擎、DNA比对、入侵特征检测中得到广泛的应用。根据每次参与匹配时模式串数量的不同可分为单模和多模匹配算法。单模匹配算法主要有具有线性匹配性能的KMP、BM、BMH、 BMHS和BMHS2,以及字频和hash等匹配算法;在多模匹配算法性能改进方面,除了增大失配时移动距离以及减少每次匹配次数之外,大幅度减少每次参与匹配模式串数量对算法的影响尤其重要。目前,主流的多模匹配算法主要有AC和WM等算法,其中AC算法是KMP算法在多模式匹配算法中的应用,而WM算法是BM算法在多模匹配算法中的应用, WM算法的时间性能优于AC算法[1]。
当前,每一种模式匹配算法性能的改进已经遇到一定的瓶颈。为此,需要将各种模式匹配算法进行组合,吸取各算法的优点,从而能够以一定幅度提高模式匹配算法的性能[2]。基于此,本文提出一种新的改进WM算法,该算法采用前缀表和后缀表的二次过滤以及平衡二叉树减少了每一次参与匹配的模式串数量。为了尽快找到文本串中的失配字符,减少每次匹配字符比较次数,改进算法引入字频的模式匹配算法。此外,匹配窗口每次匹配失配时,改进算法引入BMHS算法,采用了BMH和BMHS算法中较大的右移距离来移动匹配窗口。
多模式串匹配定义:在给定长度为n的文本T=T[1]T[2]…T[n]中同时查找l个模式串P={P1,P2,…,Pl}的过程。其中T[i]∈Σ(1≤i≤n),对于∀p∈Pj(1≤j≤l),有p∈Σ(Σ为字符集)。若Pj在T中出现,则称Pj匹配成功,否则称Pj匹配失败。
1 模式串预处理
假设字符串为T=″knowledge is better than money to the human″。模式串为P={blank, fund, minded, hand, than, plan, thread, this, that, think, there, these}。
模式串预处理阶段的主要分为:① 通过遍历所有模式串,计算出最短模式串的长度,并将该长度作为文本串匹配窗口的尺寸;② 采用匹配窗口长度内的模式串后缀字符块对所有模式串进行物理排序,得到一个模式串的有序序列;③ 为模式串集创建3个表,分别是字符块跳跃表Shift、字符块前缀表Prefix和字符块后缀表Suffix[3]。
在WM算法中,只使用Suffix后缀表中对应的模式串子集参与文本串匹配,没有利用Prefix表进行模式串的二次过滤,因此需要Suffix中后缀相同的所有模式串都参与匹配,匹配性能较差[4]。目前,在主要的WM的改进算法中,主要采用基于后缀表和前缀表的二次地址过滤以及多次hash来减少每次参与匹配模式串的数量,如文献[3]提出的改进算法DHSWM。但是,当模式串数量众多并且存在大量前缀字符块相同的模式串时,还会有较大数量的模式串参与每次匹配,匹配时间性能会受到较大的影响。针对文献中改进算法存在的问题,本文在保持前缀表和后缀表两次地址过滤的基础上,提出将前缀表中的模式串采用平衡二叉树存储结构,从而有效地减少每次匹配模式串的数量。
(1) 根据匹配窗口长度内的模式串后缀字符块进行模式串集的排序[5]。在上述模式串集合中,模式串最短长度为4,因此设置匹配窗口长度为4。假设字符块B长度为2,根据匹配窗口长度内的模式串最后2个字符进行排序,则上述模式串经过排序之后的存储顺序为:
blank, plan, than, that, there, these, think, this, fund, hand, minded, thread。
假定模式串blank的存放地址为P,则plan的地址为P+1,以此类推,最后一个模式串thread地址为P+11。这种处理能确保后缀字符相同的模式串地址是相邻的,便于在匹配时容易实现模式串的地址过滤。图1为模式串集经过排序之后得到的有序序列。
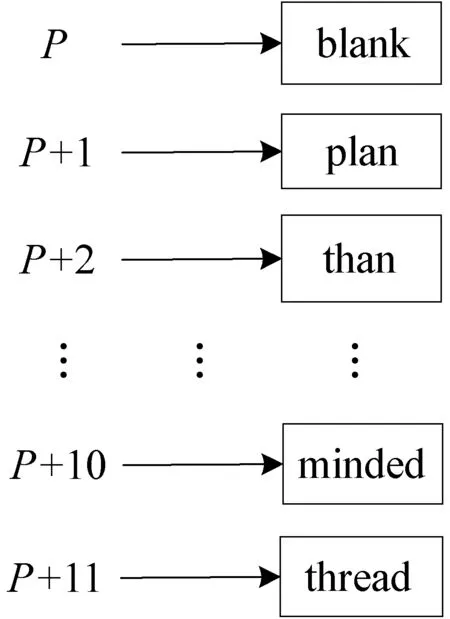
图1 模式串的顺序结构
上述建立的模式串顺序存储结构主要针对的是英文字符环境。在中文字符匹配环境中,由于汉字采用Unicode编码,每个汉字需要用两个字节进行存储。通过分析汉字的双字节码发现,汉字第一个字节码相同的概率较大,而第二个字节的编码相同的概率相对较低[6]。例如:“兰”的二字节编码为:0x5170,而“江”的编码为0x51ae。基于此,为了适用于中文字符匹配,将采用双汉字中每个汉字的第二字节作为B长度的后缀字符块进行排序,建立有序的存储结构。
(2) 跳跃表Shift。跳跃表Shift存放[7]着模式串集中所有后缀块字符在匹配时的跳跃距离,字符块移动距离的存放数组位置由字符块经过hash计算得到。假设X是模式串中连续2个字符组成的字符块,则设计的hash函数为:hash(X)=(unsigned short) (X[0]<<8)|X[1]),此hash函数能够保证不同的字符块经过hash之后不会有冲突,确保不同的后缀字符块映射到不同的数组位置。
假设字符块X=p[j]p[j+1]hash值为i=hash(X),其中p[j]p[j+1]为任意字符组成的字符块,最短模式串的长度为m,则任意字符块X跳跃距离存储在ShiftP[j]P[j+1]中,其值由算法1得出。
算法1WM中求shift值算法
for(i=0;i<=255;i++)
for(j=0;j<=255;j++)
shift[i][j]=m-B+1;
for(i=1;i<=n; i++)
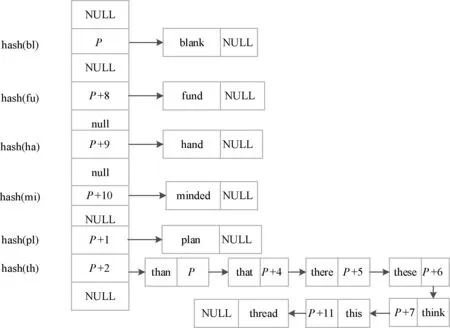
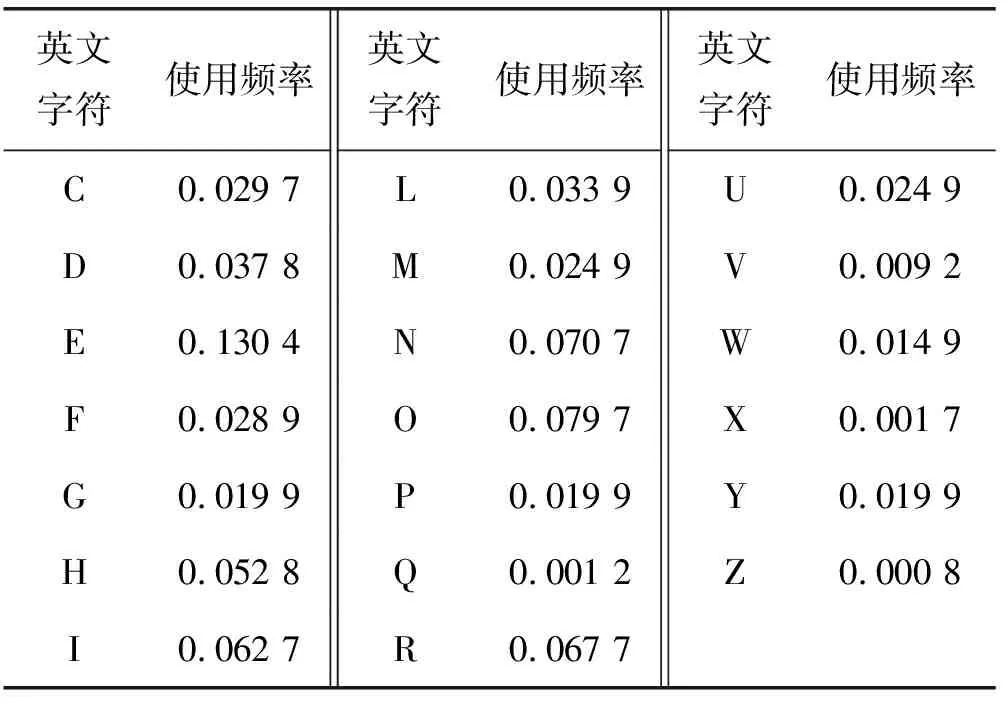
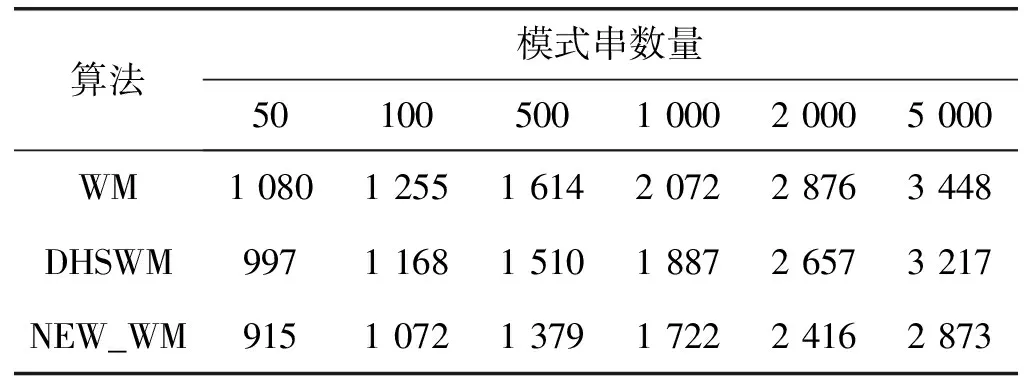
for(j=0;j if(shift[pi[j]][pi[j+1]]>m-j-2) shift[pi[j]][pi[j+1]]=m-j-2; 算法1中采用BMH算法来计算字符块在失配时向右移动的距离。B为字符块的长度,m为最短模式串长度,n为模式串的数量,m-j-2为字符块离匹配窗口最右边的距离。根据算法1对所有模式串的字符块右移距离进行计算,得到的右移距离Shift表如表1所示。 表1 模式串Shift表 在中文字符匹配环境下,跳跃表Shift采用双汉字来设计后缀字符块,但是只采用每个汉字的第二字节构成长度为2的字符块,从而计算得到双汉字后缀字符块的跳跃距离。由于篇幅有限,在表1中没有列出双汉字字符块的跳跃距离。后续的Suffix表也采用双汉字的第二字节建立中文模式串的Suffix表。 (3) 后缀表Suffix。后缀表[8]类似于hash查找中的拉链法,具有216个头节点,最多有216个单链表将所有的模式串连接起来,每个单链表存放着后缀字符块相同的模式串子集。后缀表的创建过程如下:对于每个模式串,计算匹配窗口内模式串后缀字符块的hash值,确定该模式串加入哪个单链表。Suffix表中某个头节点如指向一个单链表,则该头节点指针域用链表中的第一个模式串的地址填充,而该头节点之前所有空链表的头节点都用该地址填充。例如所有以“an”作为匹配窗口最后两个字符的模式串,它们的地址范围为:[suffix[hash(an)]→next, suffix[hash(an)+1]→next),也就是需要参与匹配的模式串的地址范围为[P,P+3)。 Suffix表如图2所示。 图2 Suffix表存储结构 在中文字符匹配环境下,为了建立基于双汉字的前缀表,分别提取中文模式串的最前面两个汉字的第二字节构成字符块进行hash,建立中文模式串的Prefix表。但可能会出现不同双汉字字符块存储在一个单链表中,造成地址冲突。冲突概率为1/216。 利用后缀表Suffix中确定后缀相同的模式串地址范围,从前缀表中取出前缀相同的模式串时,首先取出模式串所对应的物理地址,判断参与匹配模式串的地址是否在后缀表确定的地址范围之内;如果不在,该模式串不用参与比较。但是,如果前缀表所对应模式串过多,还会影响到NEW_WM算法的匹配性能。例如:案例中以“th”开头的模式串有7个可能需要参与匹配,前缀表所对应的单链表过长。针对此问题,有必要引入改进算法,将单链表存储的模式串改为平衡二叉树存储。图3是基于单链表结构的前缀表,图4是将图3修改为平衡二叉树形式的物理结构。 图3 基于单链表结构的前缀表 图4 基于平衡二叉树的前缀表 在上述平衡二叉树的前缀表中,如果需要查找“than”,采用二次地址过滤和平衡二叉树前缀表,由于具有“an”匹配窗口后缀的模式串地址范围为:P≤p 改进算法时间性能分析:假设前缀表Prefix中每个单链表的平均长度为n,如采用单链表物理结构进行模式匹配,则平均时间复杂度为O(n/2),而采用平衡树二叉树存储结构之后,该二叉树的深度为log2n,时间复杂度为O(log2n)。 模式串中各个字符在文本串中出现的频率差别较大。在模式匹配中,如果每一次匹配时先用模式串频率最低的字符与文本串匹配窗口对应的字符进行比较,尽快找到失配位置,就能有效地减少每一次匹配时的平均比较次数[9]。 基于字符频率的匹配算法首先需要计算出每个模式串中最低频率字符的位置,然后采用该位置字符与文本串匹配窗口中对应的字符进行比较,从而有效地减少每轮匹配字符比较次数。 根据表2统计的英文字符在文本串中出现的频率值,按照各个字符出现的频率值,采用从小到大的排列顺序为:zqxjkvbpygfwmucldrhsnioate。根据上述字符频率的排序,设计字符数组char CFValue[26]=″zqxjkvbpygfwmucldrhsnioate″。上述字符数组第一个字符出现的频率最低,最后一个字符频率最大。 表2 IT专业英文字母的出现频率 续表2 假设模式串数量为1个,最短模式串的长度为m,i代表频率数组元素下标,最大值为25,j为各个模式串数组下标,i的初值为0,j的初值为1。算法2能够实现将每个模式串字符频率最低的位置存放在各个模式串的第1个位置上。 算法2字频统计频率最低字符位置定位算法 void GetMinFrePos(char CFValue[26], char &*pat[l]) //函数功能是确定所有模式串pat中频率最低字符出现的 //位置 { pos=0; m=4; for(k=1;k<=l;k++) for (i=0;i<=25;i++) { for (j=1;j<=m;j++) if (CFValue[i]==pat[k][j]) { pat[k][0]=j; break; } } 在中文字符匹配环境中,提取双汉字中的第二字节组成二维数组,可以采用双汉字组成词的词频进行统计,统计各个词语的使用频率,但会导致表2的字符块的个数为216。另外,如果需要计算每个中文模式串各自的最低词频的位置,则需要设置三维数组,如果有1 000条中文字符模式串,则存储空间为1 000×216,约等于65 MB内存空间。 WM算法在失配时采用BMH算法实现匹配窗口的移动。如果在失配时有更大的跳跃距离,则能够提高模式匹配算法的性能[10]。 双字符数组跳跃距离Skip[c1][c2]的计算过程为:先将任意两个字符组成的字符块的跳跃值初始化为模式集中最短模式的长度加1,即m+1;若文本匹配窗口最右端的下一个字符与任一模式串中的第一个字符相同,为避免漏掉模式串的匹配,将此种情况下的B字符块的跳跃值初始化为最短模式的长度m;对于出现在模式串集中的B字符块,通过遍历所有的模式串,计算出该字符块在模式集中的最右端位置,然后用最短模式串长度m减去该位置,从而得到该字符块的最终跳跃值。初始化跳跃数组skip[i][j]的主要算法描述如算法3所示,为了简化计算,采用B=2情况进行块字符处理。 算法3双字符数组跳跃距离Skip[][]的计算 while(i=0;i<256;i++) while(j=0;j<256;j++) skip[i][j]=m+1; //将所有字符块的跳跃值初始化 for(k=1 ;k<=N; k++) //N模式集合中的模式串的数量 for(i=1;i if ((m-i) skip [Pk[i]][Pk[i+1]]=m-i; for(k=0;k for(i=0;i<=255;i++) if (skip [i] [Pk[0]]=m+1) skip [i] [Pk[0]]=m; //模式串的第一个字符与文本串匹配窗口最右端的下一个 //字符相同,如跳跃距离为m+1,则将跳跃距离调整为m 由于WM算法已经有一个Shift数组存放着基于BMH字符块的跳跃数组SHIFT,在改进算法中建立基于BMHS算法的另外一个跳跃表skip,此表用来存放文本串匹配窗口最后B-1个字符与匹配窗口下一个字符组成的字符块B的右移距离,每次失配时采用上述跳跃数组的较大者。 在中文匹配过程中,skip的二维数组下标来自于双汉字的每个汉字第二字节,从而实现skip数组的计算。 NEW_WM的改进主要在以下三个方面:① 采用后缀表和前缀表进行模式串地址过滤以及对前缀表存放采用平衡二叉树存储结构,减少了每次需参与匹配模式串的数量;② 对参与匹配的模式串采用字频匹配,尽快找到失配字符,减少模式串的字符比较次数;③ 在失配时将匹配窗口采用BMH和BMHS算法中的较大距离向右移动。 改进算法流程如下。 假定匹配窗口尺寸为4个字符,即m=4,字符块包含两个字符,即B=2,文本串长度为n,改进算法匹配过程如下: (1) 首先从文本串的前端取出m个字符作为初始匹配窗口字符,将文本串匹配指针Tp指向当前匹配窗口中的第一个字符。 (2) 如果Tp>n-m+1,结束整个文本串的匹配,否则,转向步骤(3)执行。 (3) 计算当前文本串匹配窗口中后缀块字符的hash值hash(scb),查跳跃表Shift得到该块字符对应的跳跃距离Shift[hash(scb)]。如果Shift[hash(scb)]==0,转步骤(4)执行;否则(也就是Shift[hash(scb)]>0),判断skip[Tp+m-1][Tp+m]是否大于Shift[hash(scb)],如果大于,则Tp=Tp+skip[Tp+m-1][Tp+m],否则Tp=Tp+Shift[hash(scb)],返回到步骤(2)。 (4) 设置指针变量p=Suffix[hash(scb)],指针变量p指向链表中第一个模式串地址,并得到指针变量p的地址取值范围为:Suffix[hash(scb)]≤p (5) 计算文本串匹配窗口内前缀块字符的hash值hash(pcb),查表头节点Prefix[hash[pcb]]元素值,该值指向平衡二叉树的根节点,p=Prefix[hash[pcb]]→next。如果p为空,则意味着在模式串中找不到与文本串相同的前缀,转步骤(8);如果p非空,转步骤(6)。 (6) 判断p所指的节点指针域存放的模式串地址是否在[Suffix[hash(scb)],Suffix[hash(scb)+1]区间之间。如果地址指针p (7) 将文本串匹配窗口子串与p所指的模式串进行大小比较,如果子串值小于模式串,p=p→lchild;否则p=p→rchild;然后判断p是否为空,如果为空,转步骤(8),否则转步骤(6)。 (8) 判断skip[Tp+m-1][Tp+m]是否大于1,如果大于,则Tp=Tp+skip[Tp+m-1][Tp+m],否则Tp=Tp+1,然后执行步骤(2)。 在上述匹配过程中,参与匹配的模式串经过了后缀表和前缀表的两次过滤和前缀表平衡二叉树的设计,相对于WM算法,每次需要匹配的模式串数量进一步减少;另外,在每次失配时,采用BMH和BMSH算法较大的向右跳跃距离,加快了模式串向后移动的速度。改进算法的性能得到了一定幅度的提高。 算法4改进算法NEW_WM的匹配算法 ti=0; while(ti { x=shift[ti+m-2] [ti+m-1]; if(x==0) //匹配窗口最右端字符块在模式串的右端 { low=suffix[hash([ti+m-2] [ti+m-1])]; high=suffix[hash([ti+m-2] [ti+m-1]))+1]; p=prefix[hash([ti] [ti+1])]->next; if(p==0) move(ti) //没有相同前缀的模式串 else { while(p!=NULL) //穷举所有前缀相同的模式串 { if( low<=p->next&& p->next //在后缀地址范围之内 { k=p->data[0]; //找到p所指模式串频率最低字符位置 if(t[i+k]!=p->data[k]) //频率最低字符失配 p=next(p) //指向下一层模式串 else //频率最低字符匹配 { for(j=3;j<=m;j++) //穷举当前模式串所有字符进行匹配 { if(p->data[j]==t[i+j-1]) continue; else //如有失配 p=next(p); } if(j>m) //找到匹配模式串 { postion[k++]=i; move(i); break; } } } else //模式串不在地址范围之内 p=next(p); //不在地址范围之内,p指向下一层模式串 } if(p==NULL) //在前缀表中没有找到匹配的模式串 i=move(i); } int move(int ti) //匹配窗口移动距离的计算函数 { if(skip[ti+m-1][ti+m])>shift[ti+m-2][ti+m-1]) ti=ti+skip[ti+m-1][ti+m]; else ti+=shift[ti+m-2][ti+m-1]; return ti; } Link *next(Link p) //p指向下一层模式串函数 { if(p->data p=p->lchild; else p=p->rchild; return p; } 为了将上述算法的思想在中文匹配中实现,需要进行一定的改动。当计算得到skip[i][j]等于0时,还需要对双汉字中每个汉字的第一个字节进行匹配,只有这两个字节相同,才需要进行完全匹配;否则,需要将文本串匹配窗口根据计算好的skip数组向右移动。 下面将通过一个匹配实例来说明NEW_WM算法的匹配过程,假设匹配窗口尺寸为4,块字符大小为2。 (1) 开始时匹配窗口位于文本串的前端,后缀块字符为″ow″: 计算″ow″的散列值hash(ow),查表Shift得到Shift[hash(ow)]=3,表明当前匹配窗口没有模式串与其匹配,然后查询BMHS算法中的skip[w][l]的值为5>Shift[hash(ow)]=3,匹配窗口向后移动5个位置: (2) 匹配窗口最后两个字符为“e”,Shift[“e”]=3,skip[e][]=5,匹配窗口向后移动5个位置: 经过5轮匹配之后,匹配窗口内字符串为“than”,查询Shift[hash(an)]=0,说明“an”在模式串中存在,通过后缀表Suffix[hash(an)]得到具有后缀“an”模式串的地址p范围满足以下关系:Suffix4[hash(an)] ≤p 为了验证改进算法的时间性能是否得到提高,采用了WM和DHSWM两种匹配算法作对比,分别在模式串数量和长度变化两种情况下进行时间性能对比。待测目标文本串为某科技互联网网站下载的10 MB的信息技术专业的相关文档,模式串从信息技术专业文件中随机抽取。 实验测试环境:为保证测试实验数据的准确和有效性,WM、DHSWM和NEW_WM算法均使用 Visual Studio 2017 集成开发工具,采用C++语言进行编程实现。测试主机的配置为:Intel® CoreTMi7-7500U CPU,3.10 GHz主频,16 GB内存,Windows 10操作系统,使用精确到微秒的时间函数clock()。 测试数据:模式串长度为40个字符,待匹配的文本串长度为10 MB。 测试方案:依次选取100、200、500、1 000和2 000个模式串,分别测试WM、DHSWM和NEW_WM算法的时间性能,时间性能与文本匹配完成所需时间成反比。 表3 模式串数量变化时匹配时间 ms 从表3可以看出NEW_WM算法的匹配性能相对于WM提高了18%左右,相对于DHSWM算法而言,匹配时间性能提高了10%左右。这说明了NEW_WM算法的改进方面发挥了作用。随着模式串数量的增加,NEW_WM算法的时间性能改善越明显,二次模式串过滤机制和平衡二叉树发挥的作用更加明显,原因是随着模式串数量增加,WM算法中的后缀表Prefix形成长链表的概率增加,而采用双表二次过滤以及平衡二叉树减少了每次需要匹配的模式串的数量。因此模式串数量越多,改进算法的时间性能提高得越明显。 测试数据:固定模式串数目为2 000个,固定待匹配的文本串为10 MB。 测试方案:依次选取长度为20、40、60、80、100、120、140的模式串,分别测试WM、DHSWM和NEW_WM匹配算法的时间性能,时间性能与文本匹配完成所需时间成反比。 表4 模式长度与算法性能关系表 ms 从表4可以看出,WM、DHSWM和NEW_WM算法会随着模式长度的增加,时间性能都会逐渐提高,NEW_WM算法较WM算法性能提高了20%左右,较DHSWM算法性能提高了8%左右。 NEW_WM算法在匹配过程中采用了后缀表和前缀表的模式串的二次过滤以及平衡二叉树,减少了每次匹配模式串的数量,在文本串匹配窗口匹配时采用最低频率字符先进行比较,并在失配时采用BMH和BMHS算法计算得到的模式串向后移动的较大距离。相对于WM和DHSWM算法来说,减少了每次参与匹配模式串匹配的数量,也减少了每个模式串比较字符次数,并在失配时加快了模式串向后移动的速度,因此,时间性能得到了一定幅度的提高。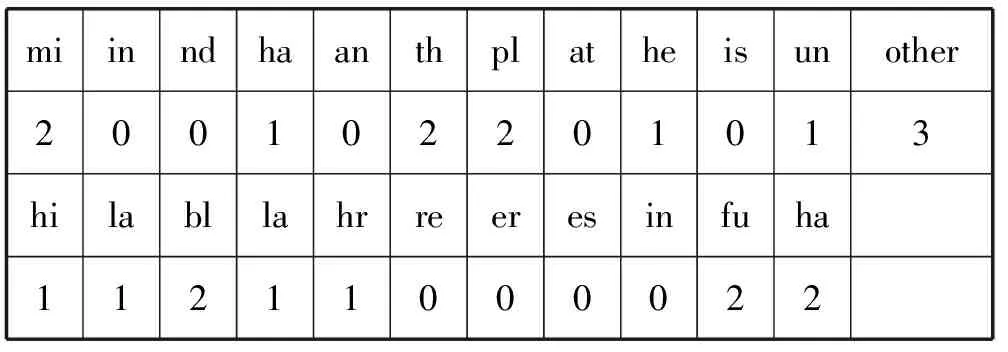
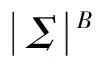


2 字频统计的模式匹配算法
2.1 算法思想
2.2 各模式串频率最低字符位置的计算

3 改进算法NEW_WM
3.1 失配时移动距离的改进
3.2 改进算法的流程
3.3 算法实现
3.4 改进算法匹配实例
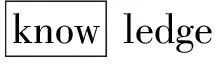
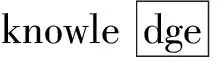
4 实验测试分析
4.1 模式串集数量对算法时间性能影响
4.2 模式串长度对算法时间性能的影响

5 结 语
猜你喜欢
电脑报(2022年37期)2022-09-28 05:31:07电机与控制应用(2022年4期)2022-06-27 06:29:22现代计算机(2021年14期)2021-07-09 17:19:40雷达学报(2018年3期)2018-07-18 02:41:26武汉轻工大学学报(2016年4期)2017-01-16 08:53:03现代语文(2016年21期)2016-05-25 13:13:35意林(绘英语)(2016年5期)2016-04-09 10:55:20辽金历史与考古(2016年0期)2016-02-02 01:34:10电源技术(2015年5期)2015-08-22 11:18:12电子与信息学报(2015年2期)2015-07-18 12:04:47
