
基于高效用项集挖掘和词义归纳的新闻推荐系统
2021-07-16 08:12:56朱亚进
计算机应用与软件 2021年7期
朱 亚 进
(常州交通技师学院 江苏 常州 213147)
0 引 言
随着移动互联网的蓬勃发展,人们每天花费大量的时间观看互联网的各种信息,其中新闻是一种影响巨大的信息内容[1]。每天产生大量各种类型的新闻,并且新闻存在新颖、不可预估等特点,用户通过搜索来查找新闻内容需要花费大量的时间和精力[2]。为了提高用户观看新闻的效率,许多新闻应用程序集成了新闻推荐系统。当前的主流推荐系统大多针对购物网站和音乐电影等商品而设计,通过建立“用户-项目评分”矩阵,采用相关性指标度量用户之间的相似性,通过协同过滤技术为用户提供推荐列表[3-4]。新闻内容中包含了大量的文字信息[5],利用这些信息能够有效地缓解冷启动问题和稀疏性问题,但是这些文字信息为相似性分析带来了难度。
许多新闻应用将用户点击量作为偏好的评估指标,根据用户的阅读耗时对用户偏好值做调节[6],此类系统能够实时更新用户兴趣模型,达到推新、推准的效果,但存在严重的稀疏性问题和冷启动问题。文献[7]将改进的层次聚类算法用于新闻事件发现问题,引入事件的多重特征计算用户的兴趣模型,该算法利用Spark框架实现了快速的响应,但对用户的兴趣评估不够准确。文献[8]通过已有用户对于新闻的点击浏览记录,提取其在不同环境中的上下文信息,利用兴趣分类记录构建决策树分类模型,该方案能够有效缓解新闻推荐系统中用户冷启动问题。文献[9]通过引入矩阵分解、标题分析和知识图谱对新闻的标题进行了深入的分析,提出了一种细粒度的新闻推荐系统。该系统的实验结果表现出更为准确的推荐结果,并且有效地缓解了稀疏性问题和冷启动问题,但由于利用深度神经网络提取新闻的特征,此过程需要大量的计算成本,并且不具备可扩展性。
新闻推荐系统有两个特殊之处:① 目标权衡。新闻提供商需要权衡广告收益和新闻内容,所以系统应当能够支持不同的商业目标。② 冷启动问题。新闻提供商连续产生大量的新闻,由此导致用户冷启动问题和新闻冷启动的问题。根据文献[9]获得的成果,通过标题词义的分析和新闻内容等信息能够显著提高推荐的准确率,可通过分布式计算解决词义分析所带来的计算成本。新闻推荐领域中包含了大量的词汇和上下文信息,词义归纳机制能够对新闻标题和内容的词汇做归纳处理,提高后续新闻推荐的准确率。本文从语料库和用户交互两个方面分析新闻系统,将用户点击量和其他辅助属性作为指标建立新闻的效用模型,通过效用模型能够支持对系统目标的权衡,并且缓解冷启动问题。另外,给出了基于MapReduce的分布式推荐系统实现方案,从而为用户实时提供推荐列表。
1 新闻推荐系统的模型
设nw为新闻的正文内容,Si为会话i,D为点击量数据集,ψ(nw)为基于nw属性计算的新闻端度量,γ(nw,Sr)为会话Sr中nw的用户端度量,φ(nw,Sr)为会话Sr中nw的效用,σ(nw,P)为新闻阅读模式P中nw的内部效用,φ(P,D)为D中新闻阅读模式P的效用。设N={nw1,nw2, …,nwn}为新闻内容的集合,点击量数据集由若干会话组成,会话S定义为一个排列的新闻列表
定义1新闻端度量。对于新闻内容nw,新闻端的度量定义为:
ψ(nw)=Fψ(f1,f2,…,fk)
(1)
式中:{f1,f2,…,fk}为新闻的属性集;Fψ为聚合函数。
定义2用户端度量。给定一个会话Sr和一个用户-新闻交互属性f′1,f′2,…,f′k,用户端度量定义为:
γ(nw,Sr)=Fγ(f′1,f′2,…,f′k)
(2)
式中:Fγ为一个聚合函数。
定义3新闻效用模型。给定一个新闻nw和一个会话Sr,新闻效用模型定义为:
φ(nw,Sr)=Fφ(ψ(nw),γ(nw,Sr))
(3)
式中:Fφ为一个聚合函数。
上述定义并未限制聚合函数Fψ、Fγ和Fφ的形式。在不同的应用场景下,根据商业目标调整聚合函数。表1所示是包含5个会话{S1,S2,S3,S4,S5}的点击量数据集,假设应用的目标是利用推荐的新闻增加用户的参与度,此时新闻的日期、受欢迎度、社交媒体的活跃度则是用户参与度的重要指标。表2是γ聚合的结果,表3是新闻的点击量数据集,表4是ψ聚合的结果。最终定义了Fφ将γ和ψ的结果相乘,获得最终的效用:φ(nw,Sr)=ψ(nw)×γ(nw,Sr)。

表1 会话的点击量数据集

表2 γ聚合的结果

表3 新闻的点击量数据集
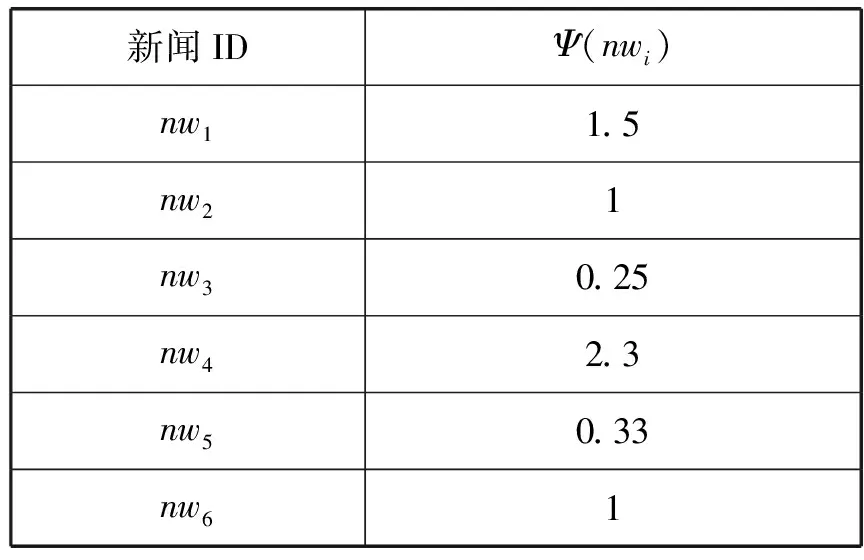
表4 ψ聚合的结果
上述例子是新闻效用模型的一种可能实例,实际应用中存在许多的属性。图1所示是总结的新闻效用模型融合实例。
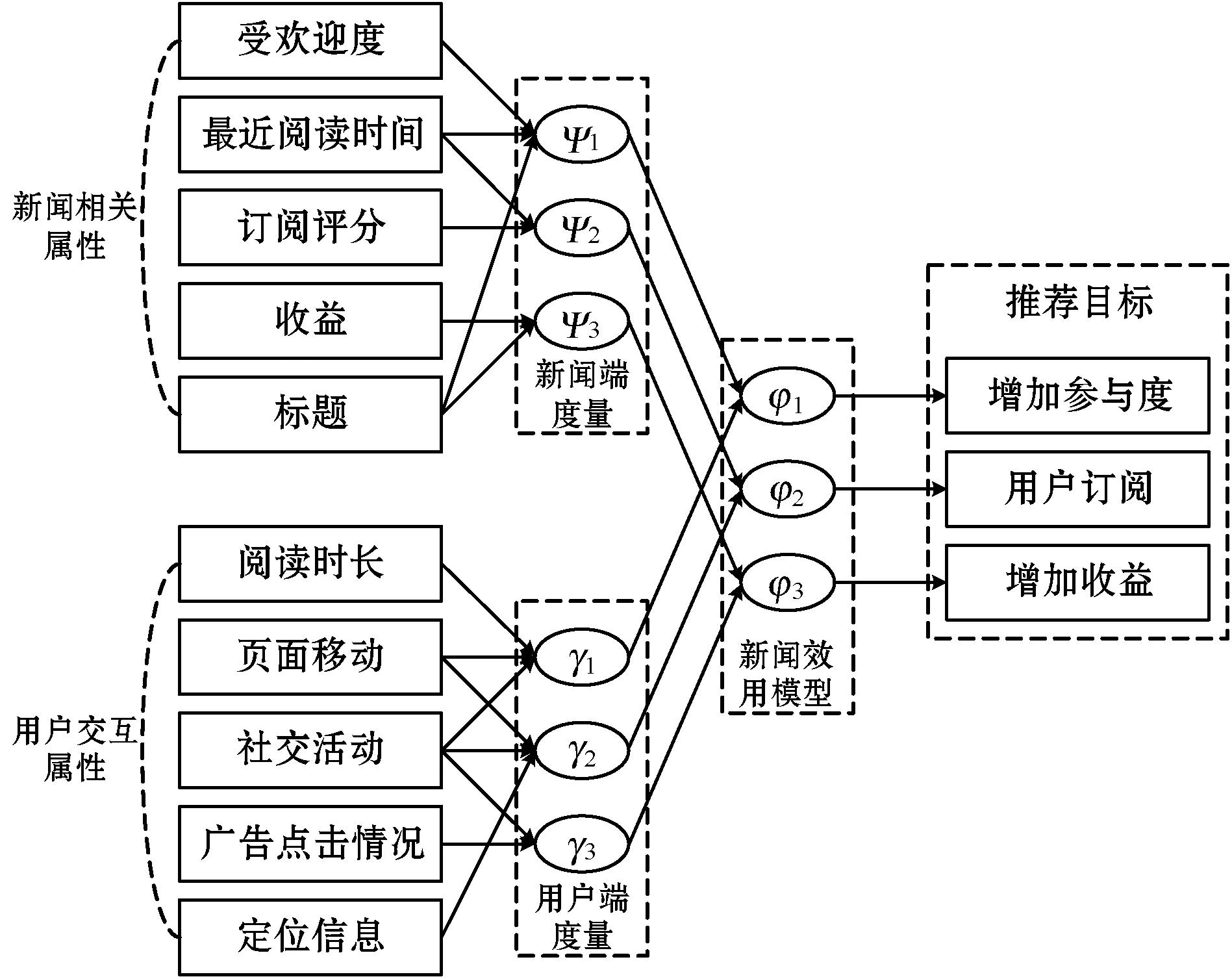
图1 总结的新闻效用模型融合实例
定义4新闻阅读模式。新闻阅读模式P定义为用户阅读的新闻集{nw1,nw2,…,nwL},L为模式长度。
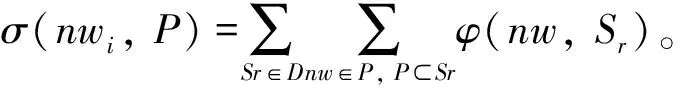
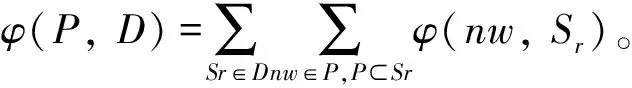
2 基于效用的新闻推荐系统
设计了基于效用的新闻推荐系统,简称为(News Recommendation System, nwrecsys),nwrecsys基于Apache Spark框架和MapReduce框架实现,首先基于点击量数据集学习推荐规则集,然后根据规则集为当前的用户会话推荐新闻列表。图2所示是本系统的总体框架,其中发现规则的部分主要分为两个阶段:① 发现内容级别的推荐规则;② 发现标题级别的推荐规则。
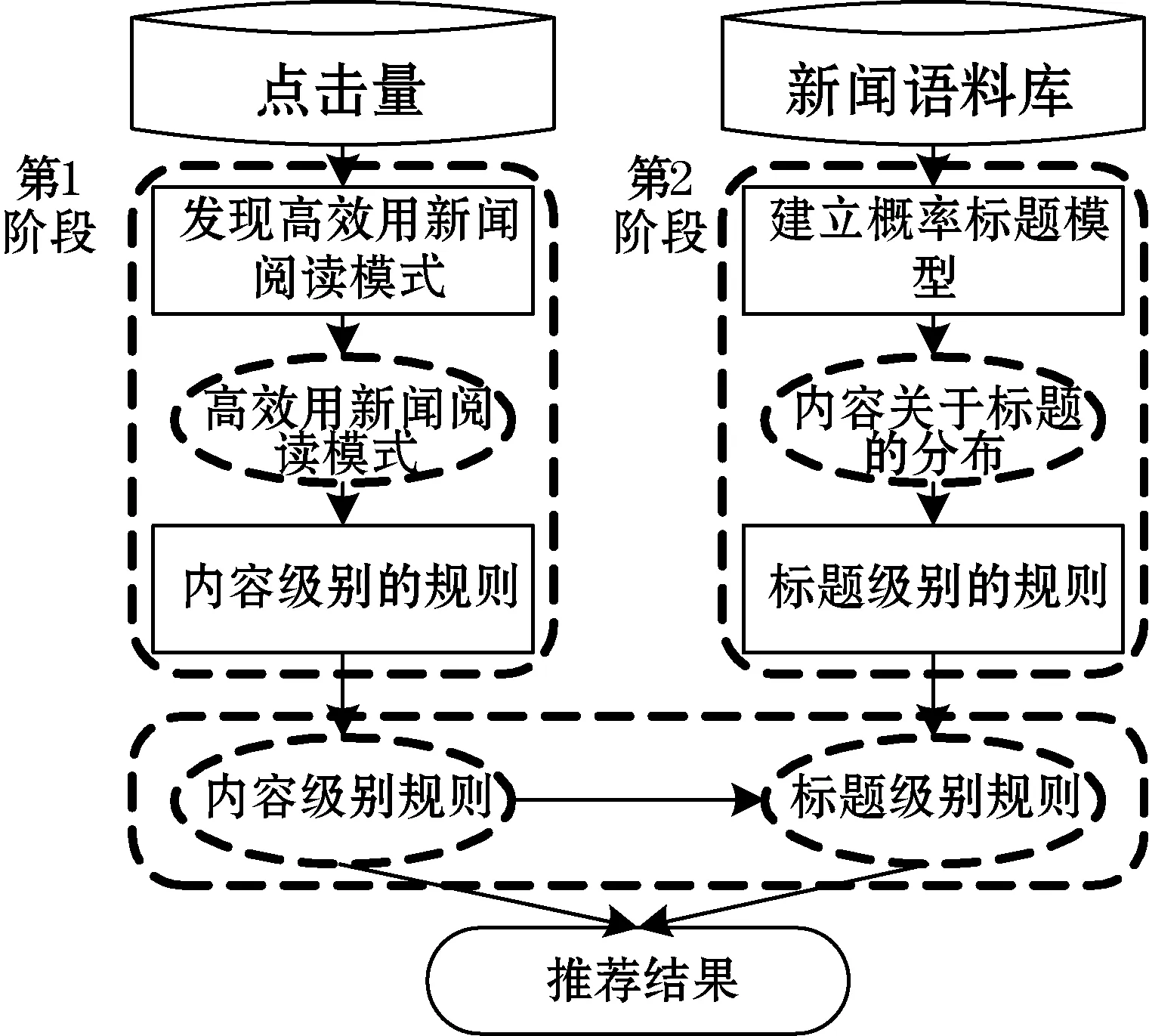
图2 新闻推荐系统的总体框架
2.1 内容级别的推荐规则
大多数基于规则的推荐系统基于数据生成关联规则,首先发现频率不小于最小支持度阈值的新闻阅读模式,给定一个频繁新闻阅读模式P,选出置信度不小于阈值的所有规则集,记为R:A→B。置信度定义为包含模式B的会话占包含模式A会话的百分比。基于本文的新闻效用模型寻找所有内容级别的规则R:A→B。如果达到以下两个条件,则认为推荐的结果较好:(1) 一个会话包括阅读的新闻内容和推荐的新闻列表;(2) 推荐的新闻应当能够提高外部效用值。定义一个内容级别的新闻推荐规则来满足这两个条件。给定两个新闻阅读模式X和Y,如果满足以下3个条件,则认为R:X→Y为一个内容级别的新闻推荐规则:①X≠∅,Y≠∅,X∩Y≠∅;②Y和X∪Y均为高效用新闻阅读模式。③ 规则的效用置信度不小于用户预设的最小阈值。规则的效用置信度定义为:
(4)
规则R:X→Y的效用置信度描述了Y对于新闻阅读模式X∪Y的效用贡献,假设规则推荐Y,而Y与X关联,那么X∪Y构成高效用的新闻阅读模式,置信度越高表示推荐的总效用值越高。发现规则由两个部分组成:满足条件(1)的高效用新闻阅读模式;满足条件(2)的内容级别的新闻推荐规则。从点击量数据集挖掘高效用新闻阅读模式需要消耗巨大的计算资源和存储资源,且此情况的新闻效用模型未必单调,所以不满足向下闭合属性,此情况下剪枝搜索空间的难度远远大于传统的频繁项集挖掘算法。因此本文通过分布式计算提高系统的计算效率。
图3为发现内容级别推荐规则的分布式计算框架。第一个Map-Reduce中应用定义1和定义2建立效用数据集。然后使用一个Mapper和Map-Reduce处理效用数据集,发现高效用新闻阅读模式。最后使用一个Map-Reduce发现内容级别的推荐规则。
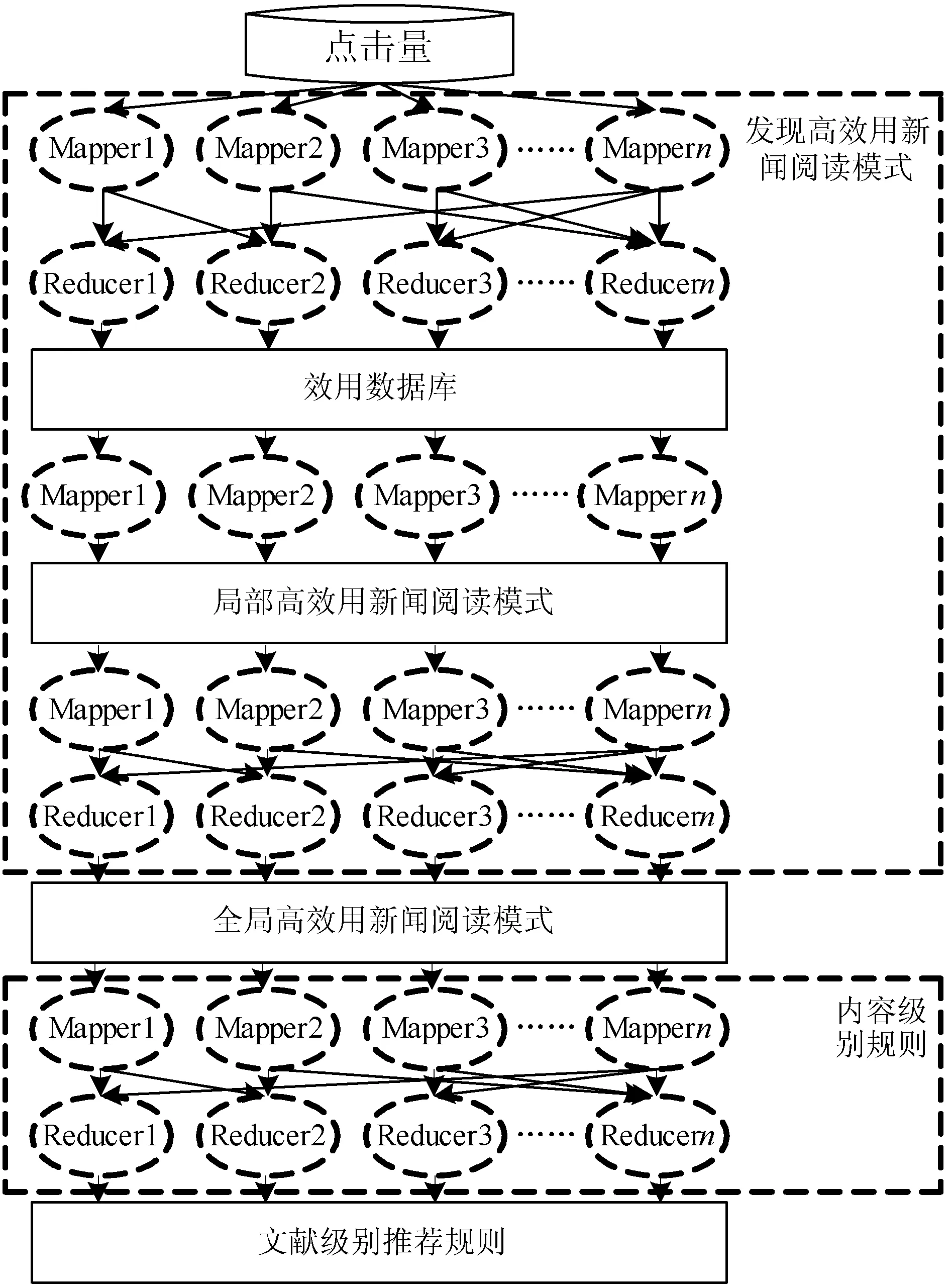
图3 发现内容级别推荐规则的分布式计算 框架(基于Apache Spark 2.3.0)
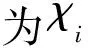
算法1发现高效用新闻阅读模式
输入:效用数据集D,新闻效用模型Fφ,最小效用阈值δ。
1.将D分布于计算机集群的m个节点上{D1,D2,…,Dm};
2.foreach∀Si∈Djdo
3.foreach∀nw∈Sido
4.φ(nw,Si)←Fφ(ψ(nw),γ(nw,Si));
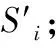
6.endfor
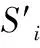
8.endfor
9.χi= 在节点i中寻找高效用新闻阅读模式;
//采用文献[10]的挖掘算法
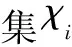
给定一个高效用新闻阅读模式的集合,本文的目标是发现内容级别的新闻推荐规则。
给定一个新闻阅读模式P={nw1,nw2,…,nwn},其中σ(nw1,P)<σ(nw2,P)<σ(nwn,P),X={nw1,nw2,…,nwk}⊂P,k≤n,P中新闻nwi满足以下的关系:
uconf(〈{X-nwk}→nwi〉)>uconf(〈{X-nwk-1}→nwi〉)
(5)
式中:X-nwk表示集合X中删除新闻nwk后的集合。
根据上述思路,提出一种发现内容级别推荐规则的算法,如算法2所示。算法的输入为高效用新闻阅读模式和最小支持度min_uconf,输出为内容级别的新闻推荐规则。第2行将模式P的新闻按会话中的内部效用值升序排列,给定新闻nw,算法2产生所有的内容级别推荐规则。
算法2内容级别的规则发现算法
输入:高效用新闻阅读模式集Pset,最小效用置信度min_uconf。
2.Pset′←新闻内容按σ(nw,P)升序排列;
3.foreachP={nw1,nw2,…,nwn}∈PSet′do
4.foreachi= {1,2,…,n}do
5.ifnwi∈Pset′then
6.X←{nw1,nw2,…,nwi-1};
7.Y←nwi;
9.else
10.returnNULL;
11.endif
12.endfor
13.endfor
14.return;
算法2的第8行调用算法3(algorithm3)检查每个规则的有效性。算法3运用理论1评估内容级别的规则,递归地寻找所有的规则,时间复杂度为O(k),复杂度小于穷举搜索的复杂度O(2k),k为输入高效用新闻阅读模式的长度。
算法3规则检查算法
输入:X,Y,,min_uconf,Pset。
1.uconf=σ(Y,X∪Y)/σ(X∪Y,X∪Y);
2.ifuconf≥min_uconfthen
3.R←{X→Y,uconf,σ(Y,X∪Y)}
6.R加入;
7.endif
8.fornw∈Xdo
9.X’=X-nw;
10.algorithm3(X,Y,,min_uconf,Pset);
10.endfor
2.2 新闻效用模型
设nw为新闻内容,设usr为用户,因为nw的参与度是动态变化的,nw的内容端度量计算如下:
(6)
式中:acc_date为usr点击nw的时间;rel_date为nw的发布时间。
nw的usr用户端度量计算为:①DwellTime:usr在nw上花费的时间;② 社交媒体活跃度(socialact):用户是否在社交媒体分享该内容。γ函数定义为:
γ(nw,Sr)=DwellTime(usr,nw)×socialact(usr,nw)
(7)
最终的效用模型定义如下:
socialact(usr,nw)
(8)
2.3 标题级别的推荐规则
内容级别的新闻推荐规则给出了新闻内容之间基于效用的连接,但无法推荐新发布的内容。如果直接应用基于内容的方法推荐新发布的内容,那么存在两点不足:① 推荐质量低。推荐的内容仅考虑内容的相似性,不考虑新闻阅读模式,用户可能对内容无兴趣。② 多样性不足。
本文开发了基于词汇归纳和概率模型的标题级别推荐规则,包括四个阶段:
第1阶段:上下文建模和上下文嵌入。
第2阶段:上下文嵌入建模为复杂网络。
第3阶段:词义归纳。
第4阶段:标题级别的推荐规则。该算法无需先验知识,利用模块度获得最佳的分簇结果。
2.3.1上下文建模和上下文嵌入
采用Word2vec[11]表示标题的词汇,设计了快速的词汇嵌入训练方法,其次设计了词汇预测模型和词汇的上下文预测模型。Word2vec生成的词汇嵌入能够保存语法属性和语义属性,组合上下文所有的词汇嵌入总结出歧义词汇。
图4所示是产生歧义词汇嵌入的流程。第1步获得目标词汇的近邻词汇向量,采用Word2vec获得嵌入的结果。将Google新闻作为训练集,语料库共包含1 000亿个词汇。获得每个上下文的嵌入表示之后,将结果组合成一个向量,该向量表示了目标词汇上下文的词义特征。

图4 产生歧义词汇嵌入的流程
设wi为标题中位置i的歧义词汇,假设上下文为ci,wi附近共有ω个词汇,即ci=[wi-ω/2,…,wi-1,wi,wi+1,…,wi+ω/2]T,对wi的上下文嵌入结果为ci:
(9)
式中:wi为第j个词汇在ci的嵌入,一个词汇的上下文设为近邻词汇的语义特征组合。
2.3.2上下文嵌入建模为复杂网络
上下文之间的相似性建模为复杂网络,相似词汇间建立连接,如果两个上下文嵌入相似,那么对应的上下文向量间建立连接。采用k-NN算法将上下文嵌入建模为复杂网络,选择较小的k值能够降低网络的复杂度。然后,使用余弦相似性度量两个节点间的距离。
2.3.3词义归纳
Louvain算法的计算成本低,直接对网络的模块度函数做优化处理,无需附加的参数信息。所以运用Louvain社区检测将复杂网络分簇,每个簇为一个归纳的词义。图5所示是词义归纳的一个实例,图中“BEAR”是一个多义词,具有两个词义:① 表示忍耐的动词;② 表示熊的名词。首先考虑上下文词汇的嵌入,第1个句子的上下文词汇为“PAIN”,第2个句子的上下文词汇为“IN”和“FOREST”。通过上下文词汇的嵌入描述多义词,然后,建立相似性词汇嵌入的网络,再使用社区检测算法将词义分簇。
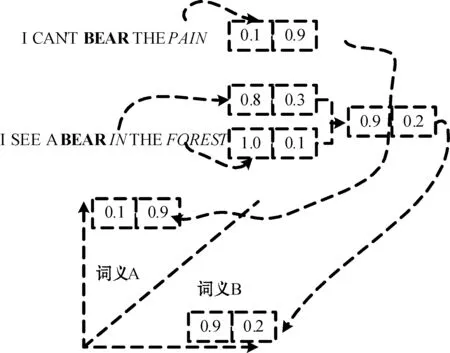
图5 识别多义词的实例
2.3.4标题级别的推荐规则
设计一个标题概率模型从语料库推理出潜在的标题。设新闻标题语料库为N,其词汇为V,标题t是关于词汇wi∈V的多项式分布,记为p(wi|t)。假设每个内容的标题唯一,如果p(ti|tj)较高,则认为标题级别的规则tj→ti为优质规则。新闻的概率p(ti|tj)为:
(10)
采用新闻效用模型估计p(nw):
(11)
式中:D为点击量数据集,Sr为D内的一个会话。 式(10)从标题概率模型获得概率p(ti|nw),标题级别规则R:{tj→ti}的标题效用置信度表示为p(ti|tj)。给定一个标题级别效用的置信度及一个下限值min_tconf。算法4为发现标题级别推荐规则的算法,首先获得两个标题ti和tj,然后计算条件概率p(tj|ti)和p(ti|tj),如果p(tj|ti)或p(ti|tj)不小于阈值,则发现了一个新的标题规则R:{ti|→tj}或R:{tj|→ti}。
算法4发现标题级别推荐规则的算法
输入:点击量D,标题分布T,标题置信度下限值min_tconf。
1.foreachti,tj∈Tdo
2. 计算p(ti|tj)和p(tj,ti);
3.ifp(ti|tj)≥min_tconfthen
4. 规则R:
5.endif
6.ifp(tj|ti)≥min_tconfthen
7. 规则R:
8.endif
9.endfor
10.returnT;
3 生成推荐的新闻列表
本文的新闻推荐系统共计算新闻的3种评分。
(1) 内容级别的新闻推荐评分。给定一个用户会话Sr和阅读模式P,内容nw的推荐评分计算为:AL(nw)=φ(P,Sr)×uconf(P→nw),φ(P,Sr)为阅读模式P在会话Sr的效用值。从P的所有子集中选择最高的推荐评分作为最终的nw推荐评分。假设一个阅读模式P包含k个内容,使用2k个P的子集产生候选推荐,选出评分最高的候选推荐作为最终的推荐。

(3) 新闻推荐总评分。综合上述两个评分作为新闻推荐的依据,融合方法为:com(nw)=AL(nw)×TW(nw)。
4 实验和结果分析
4.1 实验环境和实验方法
实验环境由一个master节点和6个worker节点组成,每个节点装备了Intel Xeon 2.6 GHz处理器和128 GB的内存。分布计算平台为Spark Release 2.3.0。
4.2 性能评价指标
为了保证实验结果的置信度,采用5折交叉验证的实验方案,将数据集随机分为5个子集,轮流选择4个子集作为训练集,剩余的子集作为测试集,最终将5次实验结果的平均值作为最终的统计结果。根据训练集获得算法的最优参数集。
性能评价指标包括平均精度均值MAP@K和多样性。MAP定义为相关内容数量除以数据集的内容总数量,多样性定义为推荐列表中每对新闻的不相似性平均值,假设新闻数量为N,平均不相似性计算为:
diver(N)=
(12)
式中:p为新闻的数量;sim()为余弦相似性。
4.3 实验数据和参数设置
实验中采用Semeval-2013语料库[12],Semeval-2013共有50个词汇,每个词汇的样本数量范围为22~100。数据集包括OANC[13]的4 664个样本,每个样本是字典的一个短语。
采用Google新闻数据集预训练词汇嵌入模型,该数据集包含约1 000亿个词汇。模型共有300万个不同的词汇和短语,采用Word2vec方法训练词汇嵌入模型,词汇嵌入的维度为300。算法的效用阈值min_util设为1万,min_uconf设为0.6,min_tconf设为0.45。
选择NTrecsys、LAPnwrec、PBnwrec、HARTnwrec作为对比方案。NTrecsys[14]是一种考虑新闻标题的相似性推荐系统,该系统评估标题中关键词的相似性,然后简单采用协同过滤推荐算法为用户提供标题相似的新闻内容。LAPnwrec[15]是一种实时的网络新闻推荐算法,该算法将用户的位置作为相似性度量的一部分,以期缓解多样性问题。PBnwrec[16]则提出了新闻内容的隐秘性度量指标,通过检测新闻的隐含信息,缓解推荐系统的稀疏性问题。HARTnwrec[17]是一种基于Apache Spark框架的分布式推荐系统,与本文的实现框架相似。
4.4 推荐准确率和多样性实验
图6为推荐系统的推荐MAP结果。图中nwrecsys在不同K值下的MAP结果均优于其他的推荐算法,这是因为本文算法同时考虑了新闻内容级别的推荐规则和新闻标题级别的推荐规则,基于效用模型将两者关联,对新闻系统的推荐准确率实现了明显的提高。
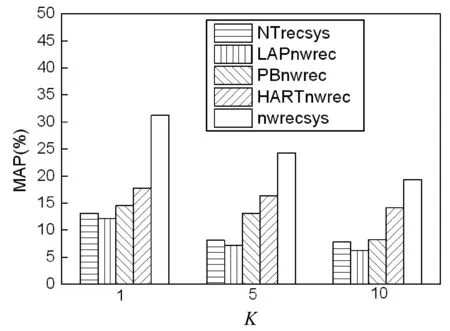
图6 推荐系统的推荐MAP结果
图7为推荐算法的平均多样性结果,可以看出,推荐内容的数量越多则多样性越低。原因在于选择的新闻越多,推荐的新闻越契合用户的兴趣,推荐的新闻相似性则越高。nwrecsys的多样性明显高于其他几个推荐算法。
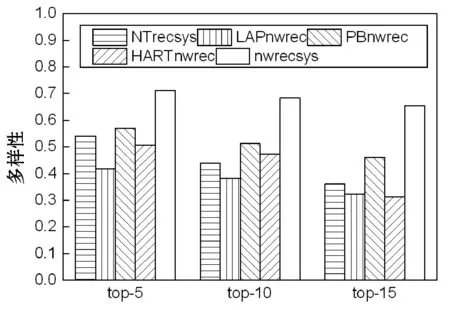
图7 推荐系统的平均多样性结果
4.5 冷启动和敏感性实验
为了仿真新闻系统的冷启动问题,参考文献[18]的实验方法:将70%的新闻内容分为训练子集,30%的新闻内容分为测试子集。训练集包含评分信息、点击量、阅读时长的反馈信息,测试集不包含任何的显式反馈信息和隐式反馈信息,测试推荐系统在不同K值条件下的性能。新闻冷启动问题中,因为新发布的新闻没有被阅读的历史记录,所以大多数推荐算法无法工作。图8为推荐算法对于新闻冷启动场景的平均MAP结果,图中显示,本文算法的MAP结果优于其他的推荐算法,原因在于本文算法设计了标题的概率模型,有助于向用户推荐新发布的新闻。

图8 推荐算法对于新闻冷启动场景的平均MAP结果
最终评测了不同阈值参数对推荐系统性能的影响。图9显示了推荐系统对于阈值的敏感性,可以看出min_uconf和min_tconf的值越低,推荐规则越多,而这些多余的规则导致置信度降低。总体而言,阈值越低,推荐系统的精度越低。

(a) 参数min_uconf的敏感性结果
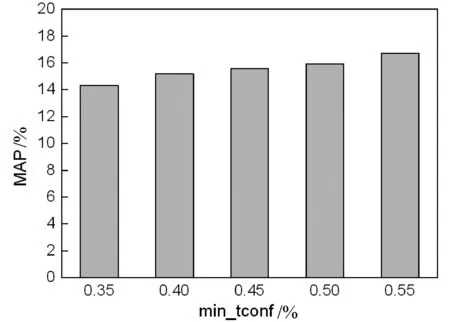
(b) 参数min_tconf的敏感性结果图9 推荐系统对于阈值的敏感性
4.6 推荐系统的时间效率
作为线上应用程序的一部分,计算效率是决定实用性的关键因素。评估了推荐算法的响应时间,结果如图10所示。NTrecsys算法、LAPnwrec算法、PBnwrec算法并未对时间效率做优化处理,对于大数据集的响应时间较长;HARTnwrec是一种基于Apache Spark框架的分布式推荐系统,平均执行时间约为0.4 s;本文算法的平均执行时间约为0.5 s。因此HARTnwrec与本文算法都具有较好的速度。
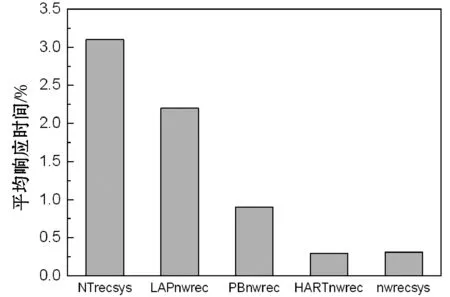
图10 推荐算法的平均执行时间
5 结 语
主流的新闻推荐方法将用户点击量作为隐式反馈信息来理解用户的行为,但点击量无法反映用户的真实兴趣。本文提出了基于高效用项集挖掘和词义归纳的新闻推荐系统,从语料库和用户交互两个方面分析新闻系统,将用户点击量和其他辅助属性作为指标建立新闻的效用模型,通过效用模型能够支持对系统目标的权衡,并且缓解冷启动问题。
本文初步研究了新闻推荐系统,因为英文语料库的数据量较小,并且英文新闻的资源易于获取,因此将英文新闻的资源作为研究对象。未来将收集中文语料库,选择合适的中文新闻数据集作为实验数据集,针对中文新闻的推荐问题做深入研究。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
基层中医药(2021年8期)2021-11-02 06:25:02
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
少儿美术(2019年7期)2019-12-14 08:06:22
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
Coco薇(2017年11期)2018-01-03 20:59:57
中学生(2017年13期)2017-06-15 12:57:48
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
中国塑料(2016年9期)2016-06-13 03:18:48
