
GRAPES_GFS四维变分同化预报系统应用特征分析
2021-07-16 08:12:32顾文静张新诺
计算机应用与软件 2021年7期
顾文静 李 娟 张新诺
(国家气象信息中心高性能计算室 北京 100081)
0 引 言
随着气象业务的快速发展,中国气象局业务模式已经蕴含了天气、气候、人工影响天气和公共服务模式等四个主要部分。其中天气模式包含GRAPES集合预报、GRAPES全球预报、台风和海浪预报,以及核应急模式和睿图-STv2.0系统等;气候模式包含月动力延伸预测、季节气候预测、大气污染潜势气候预测、东亚重要环流型预测和厄尔尼诺/拉尼娜监测诊断预测等;人工影响天气模式包含CPEFS和GRAPES_CAMS;公共服务模式包含全国风能太阳能预报、近海海上预报和RMAPS_Wind系统等。
2018年4月,中国气象局派-曙光高性能计算机系统正式提供给用户使用,派-曙光高性能高性能计算机系统分为两个子系统(业务和科研),每个子系统计算性能4 004.25 TFLOPS,存储物理容量23 088 TB。2019年8月,气象业务模式基本完成移植工作,派-曙光系统资源使用量随之增长,业务子系统CPU使用率超过60%,科研子系统CPU使用率高达80%,存储资源使用率近70%。如此规模的高性能计算机系统上线仅一年,资源使用量约三分之二,业务应用的运行特征分析变得至关重要。建立应用软件的运行特征是对业务模式分析的最有效手段。
GRAPES_GFS系统的核心部分是模式动力框架和物理过程,是一类非常具有典型性的科学计算类应用;整个过程不仅涉及密集的计算,同时伴随大量的网络操作,应用运行特征复杂。GRAPES_GFS是目前发展较为完善的业务模式,本文将以该模式作为分析对象,从资源使用情况和运行特征进行分析并提出优化建议。
1 应用运行特征分析方法
随着时间的变化,在特定的负载环境和特定的测试方法下,对业务模式运行时硬件各类资源的消耗情况即为该应用运行特征。采用一种应用运行特征的快速分析架构,从系统级、应用级和微架构级综合出发,应用Paramon和Paratune软件采集真实、准确的性能指标数据,凭借这些指标数据完整呈现应用程序的基本运行特征[1]。
系统级的指标考虑CPU、内存和磁盘网络共计9种特征指标。其中:CPU%为CPU总利用率,衡量CPU资源的使用情况,CPU SYS %为CPU系统开销利用率,衡量CPU资源中系统开销的比例,二者反映出当前应用在CPU资源上的运行特征,Memory%为内存利用率,对应用程序的性能影响很大,MemBW(GB/s)为内存带宽,连接CPU与内存之间的桥梁,决定了内存数据访问的速度,SWAP%为交换分区利用率,在物理内存用尽后,将磁盘空间虚拟成内存来使用,应用程序在用尽内存后,使用SWAP分区后,应用程序的性能一定会降低,三者可以反映出当前应用在内存资源上的运行特征,Disk Read(MB/s)为磁盘读速率(磁盘读带宽),Disk Write (MB/s)为磁盘写速率(磁盘写带宽),IB Send (MB/s)为IB网发送速率,IB Recv (MB/s)为IB网接收速率,派-曙光系统InfiniBand网络双向100 GB/s,四者衡量应用在磁盘和网络上的运行特征标准为速率,即磁盘读写速率以及网络收发速率[1]。
微架构级指标考虑浮点计算、向量化比例、指令执行效率等5类特征指数。其中GFLOPS的峰值与节点CPU主频和核数有关,派-曙光系统每个计算节点包含2个Intel Xeon Gold 6142处理器,每个处理器主频2.6 GHz,浮点运算2 662.4 GFLOPS。VEC%和AVX%为向量化比例,实现单指令流多数据流SIMD,向量化是CPU峰值计算的倍数因子,对应用程序性能影响很大,向量化指令需要根据应用的逻辑,取值范围为0%~100%。CPI(Cycles Per Instruction)表示每条指令平均时钟周期数。GIPS为单位时间内的指令总数,统计每秒钟执行的指令总数。CPI越小或GIPS越高,表示指令执行效率越高。LLCM%为Cache Miss的百分比,在Cache 内存和物理盘中Cache是CPU读写速度最快的,Cache miss表示CPU在Cache中找不到需要读取的页。Cache miss会导致CPU花费更多的时间在查找和读取以及内存替换上,降低了CPU的性能[1]。
2 GRAPES_GFS模式介绍
全球区域一体化同化预报系统GRAPES(Global/Regional Assimilation and Prediction System)是在科学技术部和中国气象局支持下我国自主研发的数值预报系统,该系统是气象与气候研究的基础和核心。在“十一五”科技支撑计划的支持下建立了GRAPES全球同化预报系统试验版,2007年面向业务应用,开始系统的建设和优化全球数值预报系统GRAPES_GFS(GEAPES Global Forecast System)[2]。
随着多核计算技术的发展,基于多核处理器的集群系统逐渐成为主流架构,为了满足GRAPES计算和时效需求,研发部门对GRAPES全球模式进行MPI与OpenMP混合并行方案设计和优化。2018年至2019年GRAPES_GFS由IBM系统迁移到派-曙光系统上,同化方面实现了从三维变分(3DVar)到四维变分(4DVar)的改进,四维变分(4DVar)实现了高低分辨率内外循环、多重外循环和高低分辨率之间的插值精度,优化线性化物理过程使之发挥作用,有效使用卫星等多时次连续观测资料,优化计算效率,保障业务运行的时效[2]。
目前,GRAPES_GFS_V2.4正式业务运行,每天运行四个时次,分别是世界标准时00时次(03:40UTC)、06时次(09:40UTC)、12时次(15:40UTC)和18时次(21:40UTC),业务系统包含数据检索及处理、台风涡旋初始化、同化处理、模式积分、数据后处理和数据备份等模块,其中同化内外循环(4DVar)和模式积分(fcst)是GRAPES_GFS主要的并行应用模块,本文以此为研究对象进行并行应用特征分析。
3 GRAPES_GFS应用特征分析
3.1 特征分析
(1) 算例描述和运行环境。当GRAPES_GFS模式在曙光高性能计算机系统上运行时,收集整个过程的应用运行数据,然后对性能指标数据进行分析。
4DVar使用0.25°/1.0°(外循环/内循环)分辨率算例。模式积分(fcst)使用0.25°算例。00时次和12时次预报240小时,06时次和18时次预报120小时,前120小时3小时输出一次模式面变量modvar,后120小时6小时输出一次modvar。4DVar模块使用1 024进程,fcst模块使用4 096进程。
运行环境是中国气象局派-曙光高性能计算系统。操作系统是Red Hat Enterprise Linux Server release 7.4,配置2路32核Intel Xeon Gold处理器,浮点运算能力为2 662.4 GFLOPS、12通路DDR4 2666的内存(192 GB/384 GB)和双向100 GB/s 的InfiniBand 网络。
(2) 运行特征指标分析。对GRAPES_GFS同化内外循环(4DVar)模块和模式积分(fcst)的各类指标情况汇总如表1和表2所示。
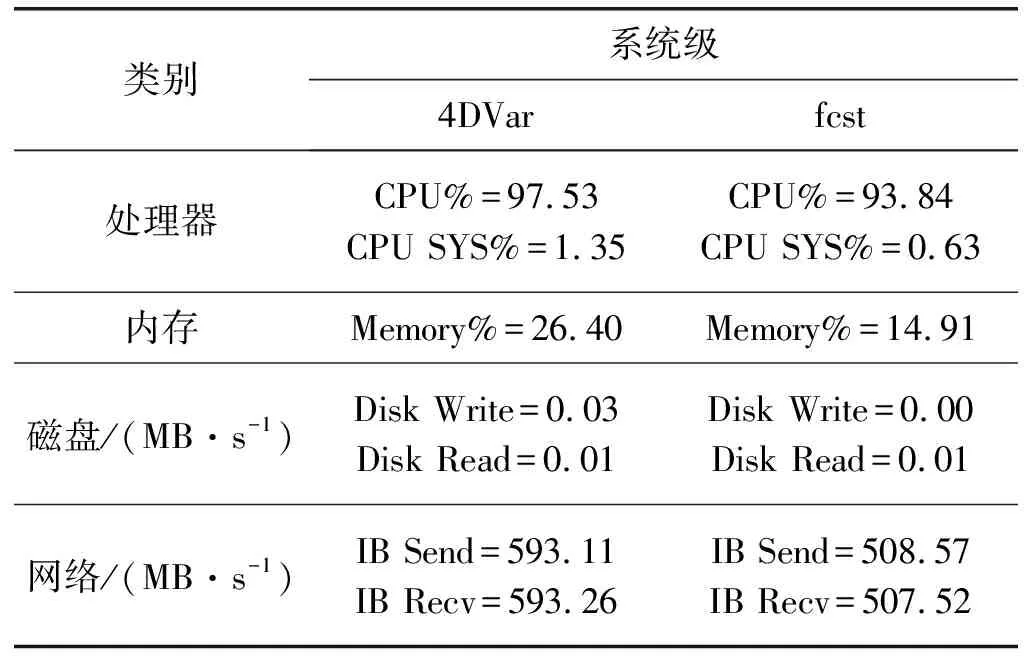
表1 GRAPES_GFS系统级性能指标表
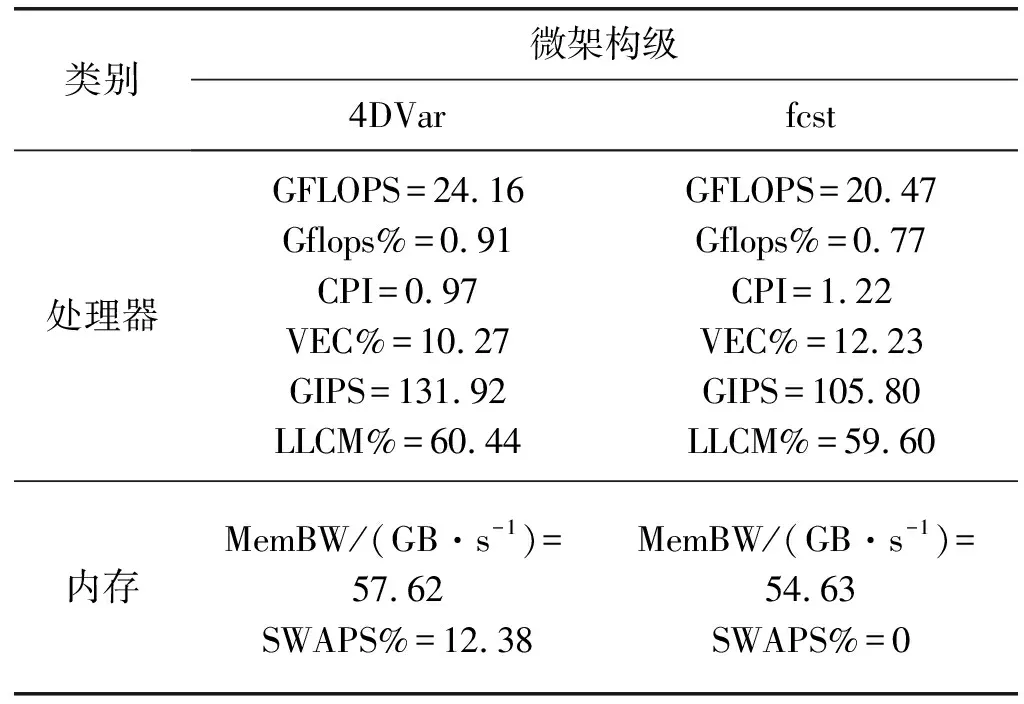
表2 GRAPES_GFS微架构性能指标表
CPU使用效率接近100%,系统开销比例较小,因此CPU绝大部分时间在处理用户程序,说明GRAPES_GFS是计算密集型的应用程序;LLCM%在60%左右,一定程度上影响了CPU性能。
Gflops%和VEC%值偏低,说明浮点计算运算效率偏低,没有充分利用CPU浮点计算部件。AVX%峰值基本为0%,派-曙光系统支持AVX指令,可以通过向量化提高程序性能。CPI方面,4DVar优于fcst模块,但指令执行效率仍有待提升。
整个计算过程持续有网络数据的收发,数据收发是通过派-曙光系统InfiniBand网络完成的,通信传输率方面,二者均达到500 MB/s以上,但相较派-曙光系统100 GB/s网络带宽,仍有可优化空间。
内存使用量仅为峰值的1/3~1/2,说明当前计算规模下,每个进程的逻辑计算较少。4DVar模块使用虚拟内存(SWAP%),会影响应用性能。
(3) F/M和F/C分析。除直接获取的特征数据外,也可以通过计算获得一些指标数据,如F/M、F/C等。F/M,即GFLOPS与Memory BandWidth的比值,每字节内存读写操作对应的浮点计算能力,可以精确定位应用是否为内存带宽敏感型应用;F/C,即GFLOPS与网络通信的比值,每字节网络操作对应的浮点计算操作,可以精确定位应用是否为网络带宽敏感型应用。其他比值操作类似。
通过这些性能指标提供的数据,详细了解应用程序在运行过程中对各类节点上处理器、内存、网络和存储的依赖情况,快速地建立应用的运行特征[3-4]。
通过收集到的定量数据可知,4DVar和fcst模块的F/M和F/C数值如表3所示,F/M、F/C的结果越小表示对CPU之外的系统资源的依赖越明显。
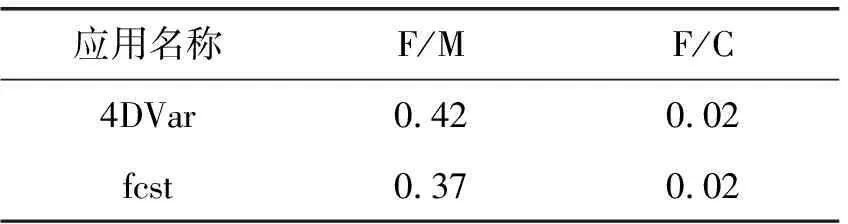
表3 F/M和F/C数值表
(4) 运行特征图分析。GRAPES_GFS模式4DVar和fcst模块运行特征如图1和图2所示。回放各个指标的任意历史时段的瞬时信息,CPU、内存利用率在运行过程中平稳,各进程间运行特征相似,运行过程阶段性强。各进程间运行特征有细微差别,说明负载比较均衡。
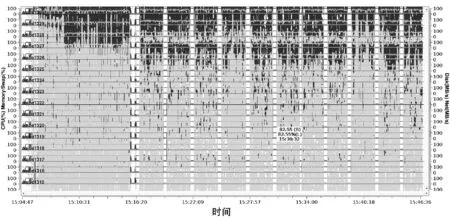
图1 4DVar运行特征
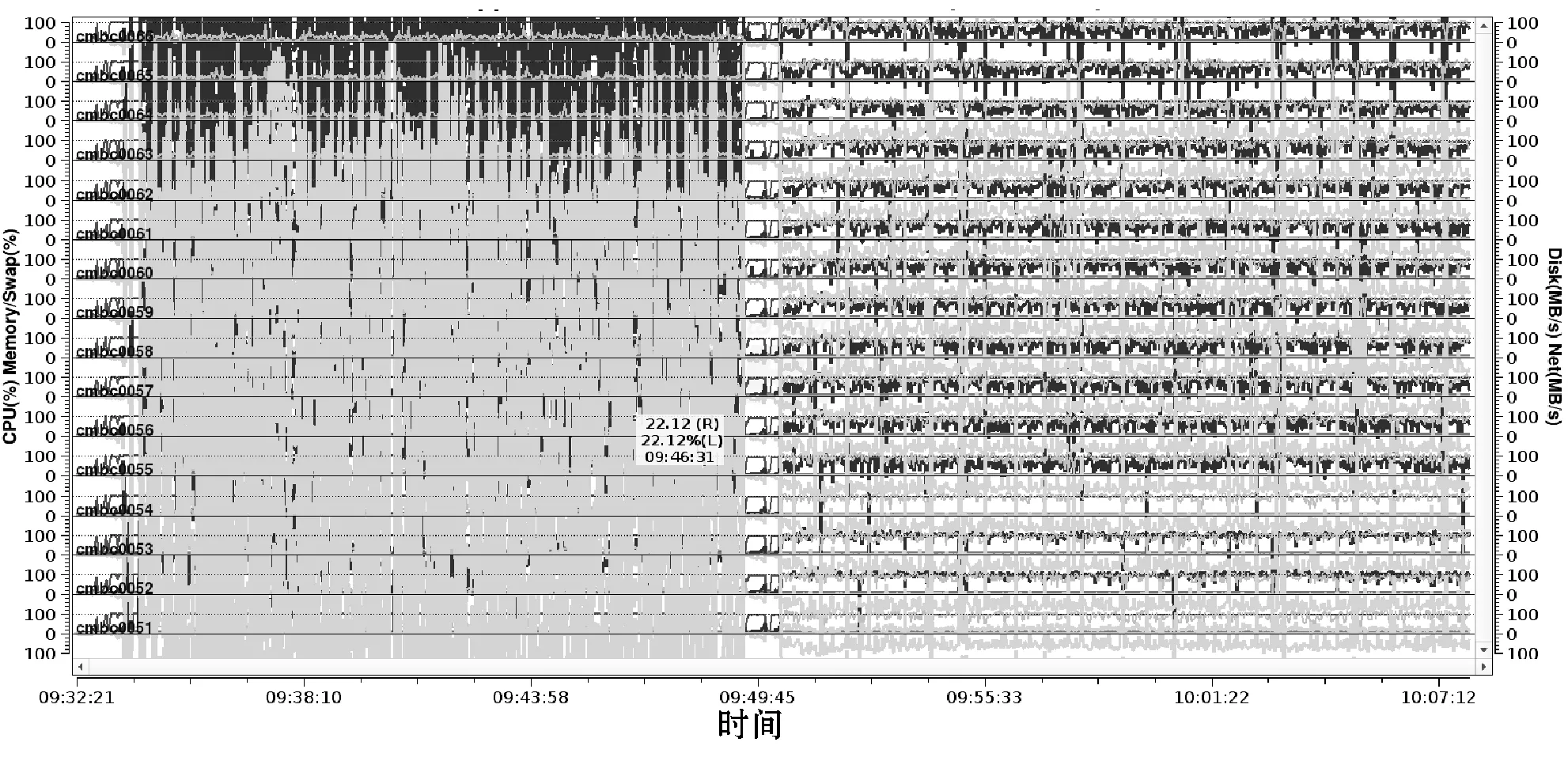
图2 fcst运行特征
3.2 函数级分析
应用Intel itac工具收集GRAPES_GFS运行中逻辑处理函数和通信函数信息,并用Intel VTune分析各通信函数中计算执行效率较低和CPU等待时间(Spin Time)较长的逻辑热点。Spin Time是CPU busy的等待时间,当同步API导致CPU轮询,而软件线程正在等待时,通常会发生这种情况。由于实验资源有限,本文仅以GRAPES_GFS的fcst模块为分析对象,计算规模选择512进程,函数各进程数据分析如下。
(1) 通信函数分析。根据 itac采集数据,fcst模块逻辑处理时间占比为58%,MPI通信时间占比42%。MPI通信中以MPI_Sendrecv、MPI_Allreduce操作居多(见图3),涉及全局范围的同步操作。
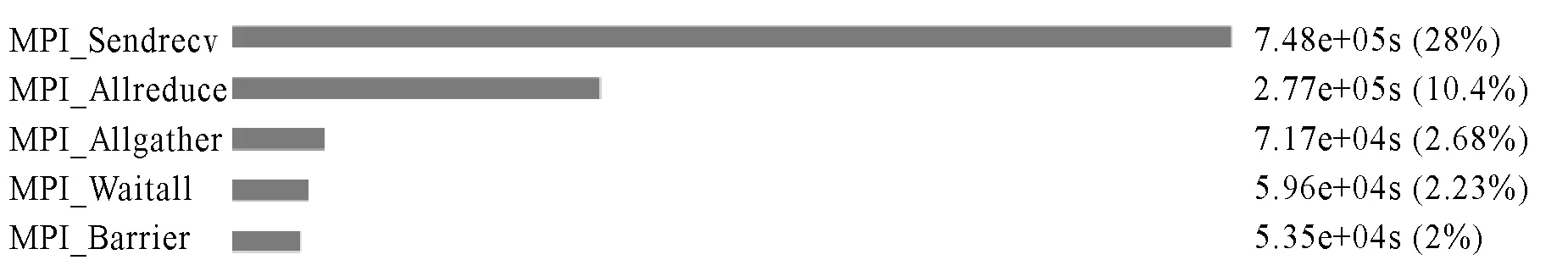
图3 各热点函数耗时比例
对通信函数各进程耗时的统计结果如图4所示。① MPI通信函数MPI_Sendrecv、MPI_Allreduce占比最高。② MPI_Sendrecv函数0-18进程段的计算耗时明显偏低,其他进程段通信函数耗时呈现波浪状周期性变化,波动约15%,负载均衡需要微调。③ 其他通信函数各进程周期性波动较小。
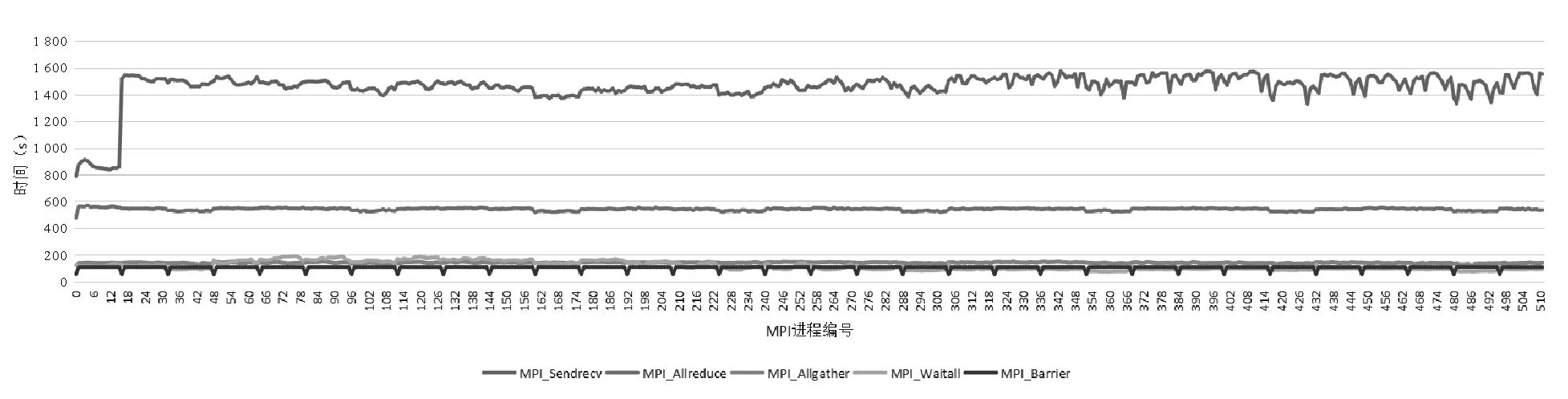
图4 fcst各进程间通信函数耗时变化
(2) 逻辑热点分析。根据VTune采集数据,MPI_Sendrecv通信函数中Spin Time最长的逻辑热点主要集中在module_model_parallel_mp_glob_Updatehalo,占比达24.6%。分析结果如图5所示,其中多个数组元素更新操作,操作热点分散,条件判断操作居多,计算过程中基本为内存访问,访存方式为连续和跨步访存,导致Spin Time时间较多,对应用程序性能和可伸缩性产生负面影响。

图5 热点函数分析
MPI_Allreduce函数的计算效率较低的程序逻辑热点主要集中在module_gcr_mp_psolve_gcr_main,psolve_gcr_main调用的matrixpro函数源码如下,该函数循环逻辑复杂,编译器未能进行向量化。
DO j=jbegin,jend
DO k=kts,kte
DO i=ibegin,iend
c(i,k,j) = &+
a(1,i,k,j)*b(i,k,j) &+
a(2,i,k,j)*b(i-1,k,j) &+
a(3,i,k,j)*b(i+1,k,j) &+
a(4,i,k,j)*b(i,k,j-1) &+
a(5,i,k,j)*b(i,k,j+1) &+
a(6,i,k,j)*b(i+1,k,j+1) &+
a(7,i,k,j)*b(i+1,k,j-1) &+
a(8,i,k,j)*b(i-1,k,j-1) &+
a(9,i,k,j)*b(i-1,k,j+1) &+
a(10,i,k,j)*b(i,k-1,j) &+
a(11,i,k,j)*b(i-1,k-1,j) &+
a(12,i,k,j)*b(i+1,k-1,j) &+
a(13,i,k,j)*b(i,k-1,j-1) &+
a(14,i,k,j)*b(i,k-1,j+1) &+
a(15,i,k,j)*b(i,k+1,j) &+
a(16,i,k,j)*b(i-1,k+1,j) &+
a(17,i,k,j)*b(i,k+1,j-1) &+
a(18,i,k,j)*b(i,k+1,j-1) &+
a(19,i,k,j)*b(i,k+1,j+1)+
END DO
END DO
END DO
3.3 不同进程下运行状况对比
不同进程下运行状况比较可以测试应用的可扩展性,根据各项特征指标变化趋势选择最适合计算的规模,提供模式业务化运行。
(1) 4DVar模块。同化分高低分辨率的内外循环,目前低分辨率的格点数少,分辨率使用0.1°算例,因此计算规模选择512、1 024和2 048进程测试。性能指标如表4所示,随着计算规模的增加,CPU和内存利用率逐渐减少,在进程规模较大时,内存使用率偏低,每个进程的逻辑计算减少,说明在同等计算规模下,可以适当地加大算例规模,进行更大问题的计算;通信方面,计算期间无密集通信时间显著增加(图6),网络通信速率(IB Send和IB Recv)在1 024进程时达最大值。微架构方面,各规模差异不大。各项指标均衡考量,1 024进程的规模比较适合4DVar模块。

表4 不同进程4DVar模块性能指标表

图6 4DVar不同规模应用运行特征示例图
(2) fcst模块。fcst模块使用0.25°算例,分辨率较高,故选择1 024、2 048、4 096和8 192四种规模进行比较测试,结果显示fcst模块相对4DVar模块具有较好的可扩展性。性能指标如表5所示,随着计算规模的增加,CPU和内存利用率较为平稳;通信方面,运行特征图(图7)显示,随着进程数的增多,粒度变小,计算期间密集通信程度减弱,相较4DVar模块,无密集通信网络时间减少不明显;通信速率(IB Send和IB Recv)随进程增加呈增长趋势,到4 096进程后锐减;内存使用率均偏低,未饱和,且与计算规模关联较小;微架构级指标方面,8 192规模浮点计算能力降低,向量化比例和代码执行效率增加,Cache miss对CPU性能影响降低。综合各项指标,4 096进程的规模优势明显。
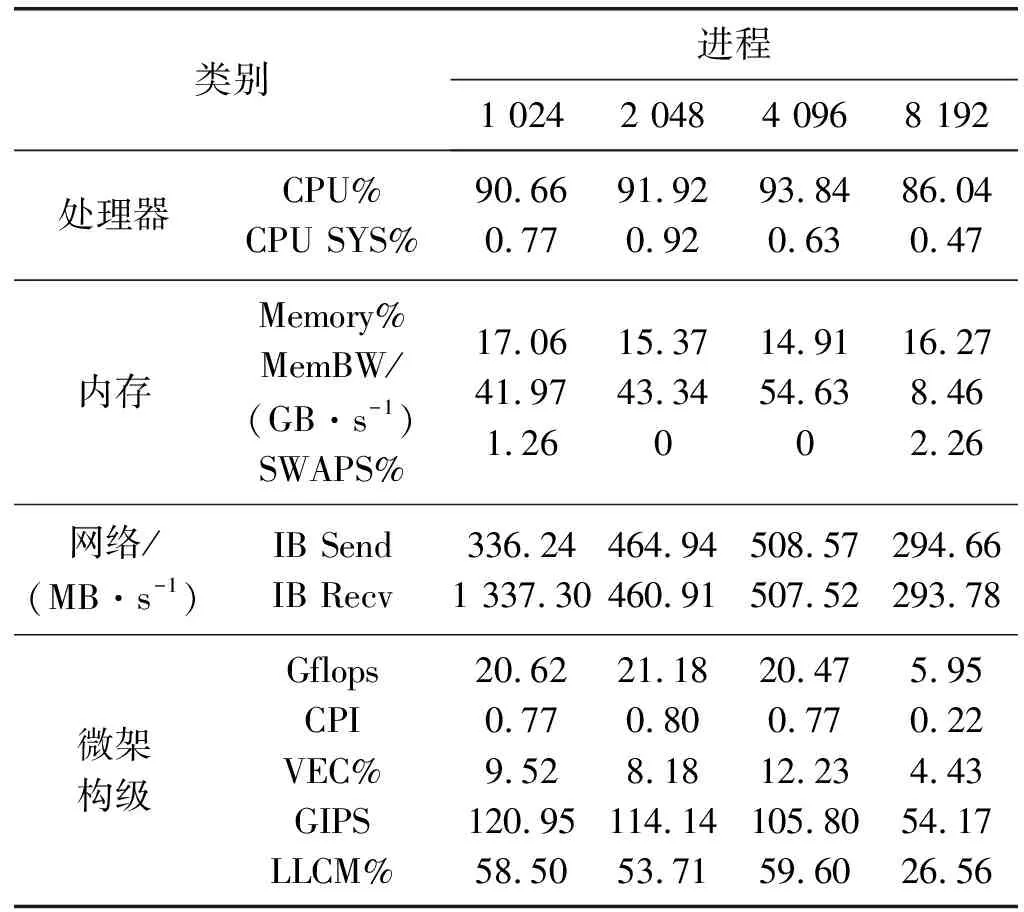
表5 不同进程fcst模块性能指标表

图7 fcst不同规模应用运行特征示例图
4 GRAPES_GFS运行特征分析和优化方向
4.1 运行特征
通过对应用特征和函数级分析,GRAPES_GFS模式CPU%比例较高,属于计算密集性应用。Cache miss比例高,一定程度上影响CPU性能。F/M、F/C值偏小,内存带宽和网络通信依赖明显。浮点计算运算效率和向量化比例偏低,指令执行效率不高。MPI通信负载比较均衡。MPI_Sendrecv、MPI_Allreduce等函数耗时较多。
4.2 优化方向
代码优化是自上而下的,从系统到应用再到处理器,可以通过串行和标量、并行化、内存访问,以及向量化几个方面优化。
进行向量化优化。从应用特征的向量化指标值(VEC,AVX)可以看出应用程序在该算例执行过程中的向量化比率低,导致集群系统的浮点运算效率低。因此需要通过对代码的核心计算部分,深入分析数据操作的依赖关系,进行向量化优化,对于有规律的离散访存,通过数组转置方法将离散访存转换为连续访存[5-7],以提高应用程序整体的运行性能。
降低Cache miss对性能的影响。在处理数据前,尽量使用连续数据。修改数据结构或通过内存拷贝,将非连续数据变成连续数据存储。根据算法模型,调整数据结构,以降低Cache miss对性能的影响。
减少CPU等待时间。从VTune分析数据看出,MPI_Sendrecv通信函数中Spin Time最长的逻辑热点的计算过程中基本为内存访问,访存方式为连续和跨步访存,导致Spin Time时间较多[8]。可调整通信策略和拓扑结构,降低通信时间。对于小的循环,可以展开,或者使用临时空间记录重复使用的数据。
消除负载不均衡。从函数级分析可以看出,在整个运行过程中,应用代码耗时在不同进程间的占比有波动,说明GRAPES对该算例处理过程中有潜在的负载不均衡因素,需要结合代码以及算例的处理逻辑,进行深入的分析,通过负载均衡的改善,提高程序性能。
5 结 语
基于本文的应用运行特征分析方法,实现了对GRAPES_GFS模式主要并行模块的快速分析,通过分析结果,精确定位了应用的类型,完整地建立了应用的运行特征,定位应用运行瓶颈,找到应用优化的方向。本文方法不仅可以针对气象类应用,同样适合其他行业的应用运行特征建立、应用优化,甚至机群方案设计。
猜你喜欢
中国外汇(2019年20期)2019-11-25 09:54:58
电脑报(2019年12期)2019-09-10 05:08:20
当代陕西(2019年13期)2019-08-20 03:54:22
民主与科学(2014年3期)2014-02-28 11:23:03
测绘科学与工程(2014年5期)2014-02-27 07:06:14
教育与职业(2014年7期)2014-01-21 02:35:04
计算机与网络(2013年1期)2013-06-05 05:31:50
电脑迷(2012年15期)2012-04-29 17:09:47
计算机世界(2009年34期)2009-11-17 09:04:02
计算机世界(2009年29期)2009-08-14 09:27:54
