
Deep Reinforcement Learning-Based URLLC-Aware Task Offloading in Collaborative Vehicular Networks
2021-07-14 09:07ChaoPanZhaoWangZhenyuZhouXinchengRen
China Communications 2021年7期
Chao Pan,Zhao Wang,Zhenyu Zhou,*,Xincheng Ren
1 Hebei Key Laboratory of Power Internet of Things Technology,North China Electric Power University,Beijing,102206,Baoding,071003,Hebei,China
2 Shaanxi Key Laboratory of Intelligent Processing for Big Energy Data,Yanan University,Yanan 716000,China
Abstract: Collaborative vehicular networks is a key enabler to meet the stringent ultra-reliable and lowlatency communications (URLLC) requirements.A user vehicle(UV)dynamically optimizes task offloading by exploiting its collaborations with edge servers and vehicular fog servers (VFSs).However,the optimization of task offloading in highly dynamic collaborative vehicular networks faces several challenges such as URLLC guaranteeing,incomplete information,and dimensionality curse.In this paper,we first characterize URLLC in terms of queuing delay bound violation and high-order statistics of excess backlogs.Then,a Deep Reinforcement lEarning-based URLLCAware task offloading algorithM named DREAM is proposed to maximize the throughput of the UVs while satisfying the URLLC constraints in a besteffort way.Compared with existing task offloading algorithms,DREAM achieves superior performance in throughput,queuing delay,and URLLC.
Keywords:collaborative vehicular networks;task offloading;URLLC awareness;deep Q-learning
I.INTRODUCTION
The emerging vehicular applications such as autonomous driving,real-time traffic monitoring,and online gaming,generate a large number of computational-intensive and delay-sensitive tasks which pose stringent requirement on ultra-reliable and low-latency communications (URLLC) [1].In the conventional vehicular edge computing (VEC)paradigm,user vehicles (UVs) collaborate with the edge servers deployed at the network edge,e.g.,roadside units (RSUs),by offloading the excessive tasks to the edge servers for computing[2].However,VEC alone is hard to efficiently meet the stringent URLLC requirement due to fixed server location,limited coverage,and prohibitive deployment cost.Besides the collaboration between UVs and edge servers,vehicular fog computing(VFC)brings a new collaborative pattern among vehicles,in which UVs offload part of the tasks to the vehicles with residual computational resources referred to vehicular fog servers(VFSs)[3,4].Moreover,VFC can collaborate with VEC as a supplement to reap the performance gains of delay and reliability in a cost-efficient way.Despite the aforementioned potential benefits,how to realize URLLC-aware task offloading in such a collaborative vehicular network still faces several technical challenges,which are summarized as follows.
First,the vast majority of previous works optimize task offloading through the lens of average-based performance metrics,e.g.,time-averaged delay and the mean rate stability constraints,which results in significant performance fluctuation[5–7].Thus,the reliable URLLC provisioning mandates the further considerations of the characterization of extreme event,delay bound violation probability,and high-order statistics of excess value [8].Second,the global state information (GSI) including channel state information(CSI),server availability,and computational capacity of servers,is unavailable for the UVs due to the high vehicle mobility,prohibitive signaling overhead,and privacy concerns.Therefore,each UV has to optimize task offloading strategy with incomplete information.Last but not least,the problem dimensionality grows exponentially with the numbers of the RSUs and VFSs since the URLLC performances of each UV are jointly determined by the task offloading decision made by itself,the decisions made by the other UVs,and the computational resource allocation decisions made by servers [9].This dilemma is named as the dimensionality curse,which cannot be efficiently solved by approaches designed for low-dimensionality optimization problem.
There exist some works that have addressed the task offloading problems in collaborative vehicular network.In [10],Wanget al.proposed a mobile computing offloading scheme where the mobile devices can offload tasks to nearby smart vehicles serving as cloudlets to reduce energy consumption.In[11],Zhaoet al.considered a cloud computing and mobile edge computing coexisted vehicular network,and presented a joint resource allocation and computing offloading optimization scheme to reduce the task processing delay and the cost of computation resource based on game theory.In [12],Zhouet al.proposed a vehicle-to-everything framework,where the collaboration among edge servers and vehicles with or without on-board unit was leveraged to achieve decentralized task scheduling and provide reliable in-time emergency detection and notification.However,these previous works optimize task offloading with complete GSI,which are not applicable to the real-world collaborative vehicular networks with incomplete GSI.
Q-learning as a model-free reinforcement learning (RL) algorithm has great potentials in solving decision-making problems with large state space[13].In [14],Wuet al.considered an end-edge-cloud collaboration framework and proposed a Q-learning based communication route selection algorithm for the multi-access vehicular environment.However,when applied in highly dynamic vehicular networks,Qlearning requires enormous storage resources to store all the state-action values,i.e.,Q values,which is impractical and inefficient.Deep reinforcement learning(DRL)combines the capability of approximating complex mapping relationship provided by neural network(NN) and the capability of decision making provided by RL.A major category of DRL is deep Q-network(DQN),which employs deep NN to approximate the Q values,i.e.,state-action values,thereby substantially reducing the resource requirement[15].In[16],Liet al.proposed a collaborative edge computing framework to optimize the task offloading,task computing,and result delivery policy for vehicles based on deep deterministic policy gradient in vehicular networks.In[17],Zhanget al.proposed a DQN-based joint transmission mode and target server selection optimization approach to maximize the system utilities in a heterogeneous MEC-enabled vehicular network.In[18],Luoet al.proposed an enhanced DQN-based data scheduling algorithm for VEC,where the data is determined whether to be either processed locally,or offloaded to the edge servers,or the collaborative vehicles.The system-wide cost for data processing was minimized under the delay constraints.However,the aforementioned works mainly focus on average-based metrics and neglect the URLLC constraints,which are not suitable for the mission-critical vehicular applications.
In this paper,we propose a Deep Reinforcement lEarning-based URLLC-Aware task offloading algorithM named DREAM to maximize the throughput of UVs in the collaborative vehicular network under the long-term URLLC constraints.First,we characterize the URLLC constraints in terms of queuing delay bound violation,the conditional mean and second moment of the excess backlog.Then,the stochastic optimization problem with long-term URLLC constraints is decomposed into a series of short-term deterministic subproblems.Afterwards,DQN is leveraged to learn the optimal task offloading strategy in each time slot.
The major contributions of this work are summarized as follows.
• URLLC Awareness: The constraints on occurrence probability of the extreme event,the conditional mean and second moment of the excess backlog are imposed to guarantee URLLC requirements.The proposed DREAM dynamically optimizes task offloading in accordance with the URLLC performance deviations.
• Task Offloading with Incomplete Information and High Dimensionality: DREAM exploits Qlearning to optimize task offloading based on only the observed performance and deep NN to approximate the Q function to cope with the problem of dimensionality curse.
• Extensive Performance Evaluation: We compare DREAM with two state-of-the-art task offloading algorithms,i.e.,EMM and D-QLOA in terms of throughput,queuing delay,and URLLC performances.Simulation results demonstrate its effectiveness and superiority.
The rest of the paper is organized as follows.Section II introduces the system model.Section III elaborates the URLLC constraints and problem formulation.The proposed DREAM algorithm is developed in Section IV.Simulation results are presented in Section V.Section VI concludes the paper.
II.SYSTEM MODEL
Figure 1 shows the scenario of the considered UV-RSU-VFS collaborative vehicular network,which consists of three components,i.e.,RSUs,VFSs,and UVs.The RSUs are fixedly deployed along the roadside and serve as edge servers.The vehicles with residual computational resources to share are referred to VFSs,while the vehicles with tasks to be offloaded are referred to UVs.Both RSUs and VFSs can provide communication and computing services for UVs.The service characteristics between RSUs and VFSs are mainly differentiated in two aspects,i.e.,computational resources and server availability.Specifically,the computational resources can be shared by the VFSs are relatively smaller than those by RSUs,while the availability of VFSs fluctuates less than that of RSUs due to the smaller relative speed when they in the same direction.As shown in Figure 1,u4offloads tasks to RSUs5andu5offloads tasks to VFSs3,which reflects the collaboration between UVs and RSUs as well as that between UVs and VFSs,respectively.u1firstly offloads task to RSUs4and then to VFSs1when it moves away from the communication range ofs4,which reflects the collaboration between VEC and VFC.For simplicity,we rename them as servers thereinafter.Assume that there areNservers andMUVs,the sets of which are denoted asS={s1,···,sn,···,sN}andU={u1,···,um,···,uM},respectively.
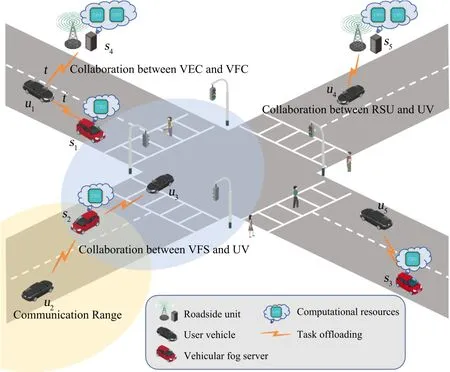
Figure 1.System model.
We adopt a time-slotted model where the total optimization period is divided intoTtime slots with the equal durationτ,the set of which is denoted asT={1,···,t,···,T}[3].Considering the limited communication ranges and mobility,the available servers for a UV are time-varying[19].A quasi-static scenario is considered,where CSI,available servers,and the distances between UVs and servers remain unchanged within a time slot,but may vary across different time slots[20].Denote the set of available servers forumin thet-th time slot asSm,t,andSm,t ⊂S.The task offloading strategy ofumis denoted as the binary indicatorxm,n,t ∈{0,1},wherexm,n,t=1 represents thatsnis selected byumfor task offloading in thet-th time slot,andxm,n,t=0 otherwise.
The traffic models at the UV side and server side are introduced in the following.
2.1 Traffic Model at the UV Side
We assume that tasks arrive atumrandomly in each time slot and are offloaded to the selected server for data computing.Denoting the amount of tasks arriving atumin thet-th time slot asAm(t)(bits),the tasks stored atumcan be modeled as a task queue,the backlog of which evolves as
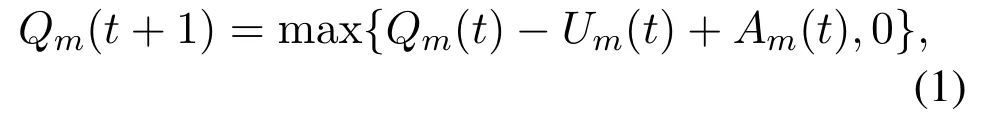
whereUm(t) represents the amount of tasks leaving the task queue ofumin thet-th time slot.
Denote the bandwidth of the allocated orthogonal subchannel betweenumandsnasBm,n.Whenxm,n,t= 1,i.e.,umselectssnfor task offloading in thet-th time slot,the amount of transmitted tasks is given by
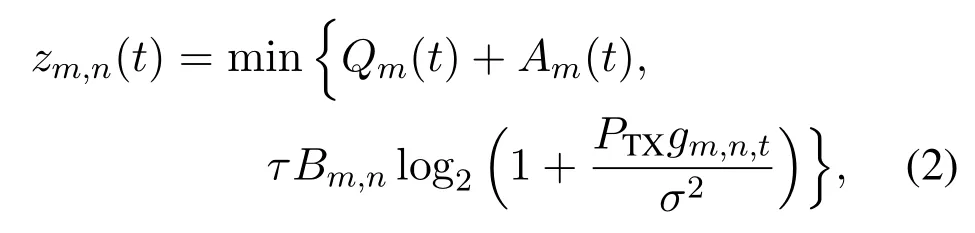
wherePTXis the transmission power,gm,n,tis the channel gain betweenumandsnin thet-th time slot,andσ2is the noise power.Therefore,the achievable throughput ofumin thet-th time slot is given by
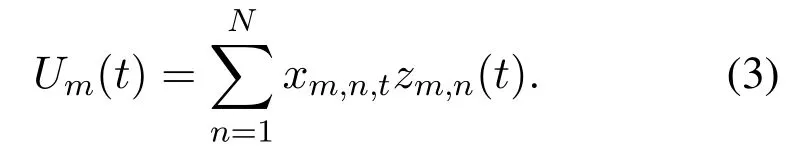
2.2 Traffic Model at the Server Side
Each server maintains a task buffer for each UV to store the offloaded tasks,which can be modeled as a queue.The backlog of the server-side task queue ofumonsnis denoted asHm,n(t),which evolves as
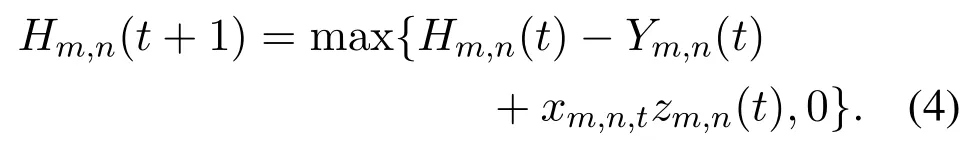
Here,Ym,n(t)represents the amount of tasks that are processed bysnin thet-th time slot,which is given by
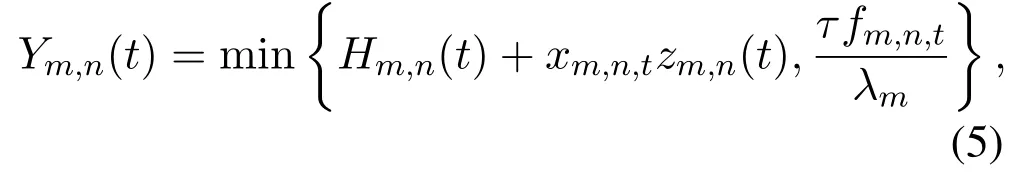
whereλmis the processing density of the tasks offloaded fromum,i.e.,the required CPU cycles per bit.fm,n,tis the CPU cycle frequency allocated bysnto process the tasks offloaded fromum.
III.URLLC CONSTRAINTS AND PROBLEM FORMULATION
In this section,the URLLC constraints and problem formulation are introduced.
3.1 URLLC Constraints
The end-to-end delay of the task offloading process consists of five parts,i.e.,queuing delay in the local task buffer,transmission delay,queuing delay in the server-side task buffer,computational delay,and results feedback delay.Since queuing delay conducts a significant impact on the end-to-end delay,the longterm constraints on queuing delay are imposed to ensure the validity and timeliness of the offloaded tasks.Denote the time-averaged task arrival rates of the local task queue onumand the server-side task queue onsnas(t)and(t),which are given by(t)=respectively.Based on theLittle’s Law[21],the average queuing delay is proportional to the ratio of the queue backlog to the average task arrival rate.To guarantee URLLC,extreme theory [22]is employed to characterize the tail distribution of the queue length.DenotingτLmandτOm,nas the queuing delay bounds of the local task queue and the server-side task queue,extreme events occur when queuing delays exceed the bounds,which are defined in terms of queue lengths asQm(t)>(t −1)τLmandHm,n(t)>(t −1)τOm,n,respectively.Excess backlogs are given by0 and,respectively.
Three long-term URLLC constraints are imposed on the occurrence probability of the extreme event,the conditional mean and second moment of the excess backlog,respectively.For the local task queueQm(t)ofum ∈M,the long-term constraint on occurrence probability of the extreme event is given by
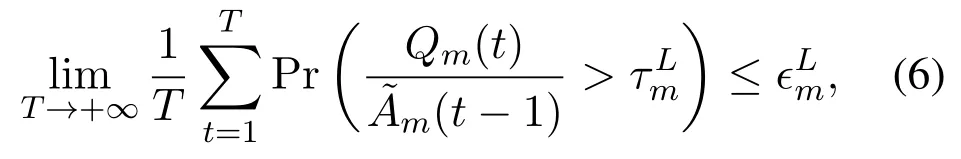
where∊Lm ≪1 is the maximum tolerable occurrence probability of the extreme event.
By introducing thePickands-Balkema-de Haan Theorem[23]of the extreme value theory,the conditional complementary cumulative distribution function (CCDF) of the excess backlogSLm(t)can be approximated by a generalized Pareto distribution(GPD)0 andξLm ∈R are the scale parameter and the shape parameter,respectively.Based on the statistical properties of GPD,the long-term conditional mean and second moment of the excess backlog are constrained as
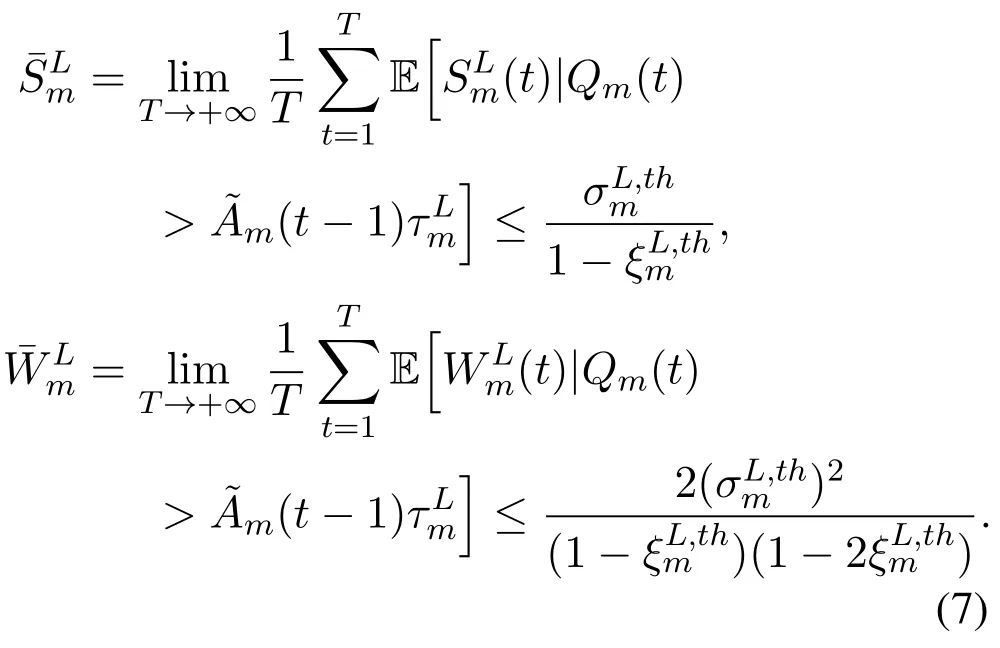
Similarly,for the server-side task queueHm,n(t)ofsn ∈S,the constraints on the long-term occurrence probability of the extreme event,long-term conditional mean and second moment of the excess backlog are imposed as
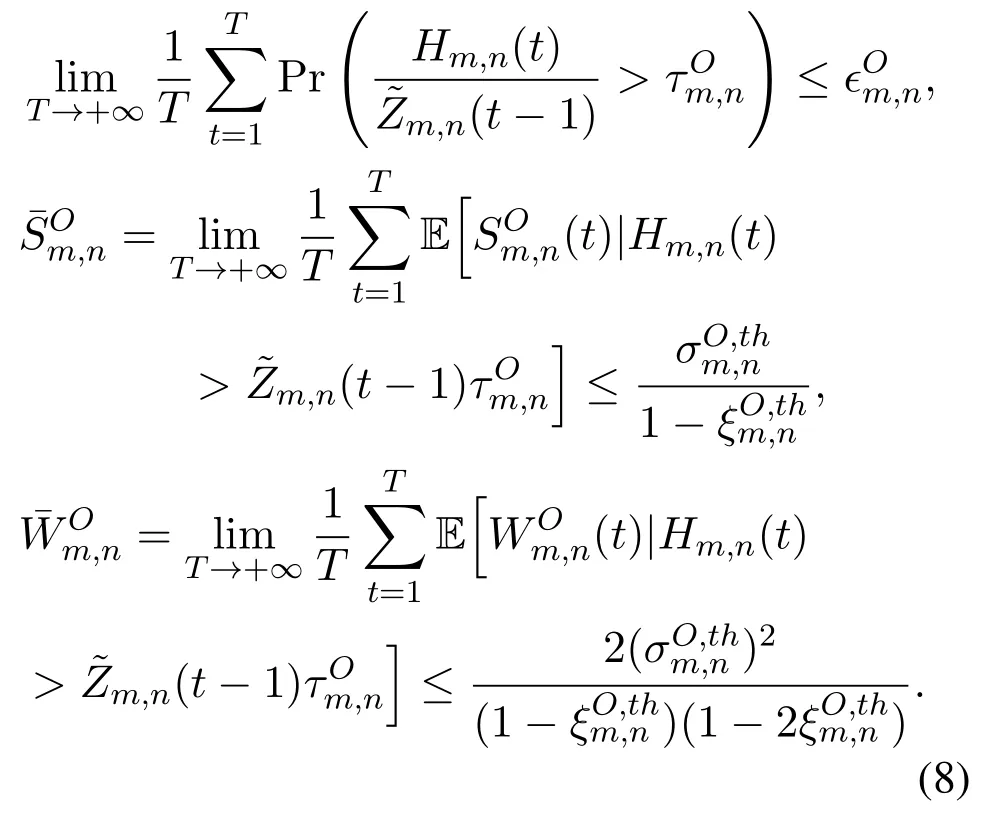
3.2 Problem Formulation
The objective is to maximize the total long-term throughput of all the UVs in the network subjected to the long-term URLLC constraints,which is formulated as
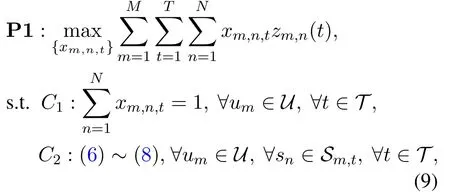
whereC1implies that in each time slot,each UV can select only one available server for task offloading.C2specifies the URLLC constraints.
IV.URLLC-AWARE DEEP REINFORCEMENT LEARNING-BASED TASK OFFLOADING
In this section,we first provide Lyapunov optimization-based problem transformation.Then,we formulate the task offloading problem in the collaborative vehicular networks as an markov decision process (MDP).Finally,the proposed Deep Reinforcement lEarning-based URLLC-Aware task offloading algorithM named DREAM is elaborated.
4.1 Problem Transformation
However,a critical challenge remains in solving P1 since the short-term decision making conducts a significant impact on long-term URLLC performance,and yet the decisions are required to be made without the future information.Lyapunov optimization is resorted to settle this long-term stochastic problem.Based on the concept of virtual queue [24],the longterm URLLC constraintsC2can be converted to queue stability constraints.Specifically,we introduce the virtual queues,,andcorresponding to the long-term URLLC constraints(6)and(7)of the local task queueQm(t),which are given by
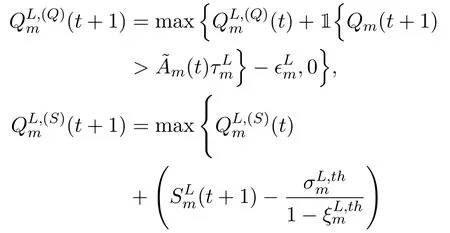
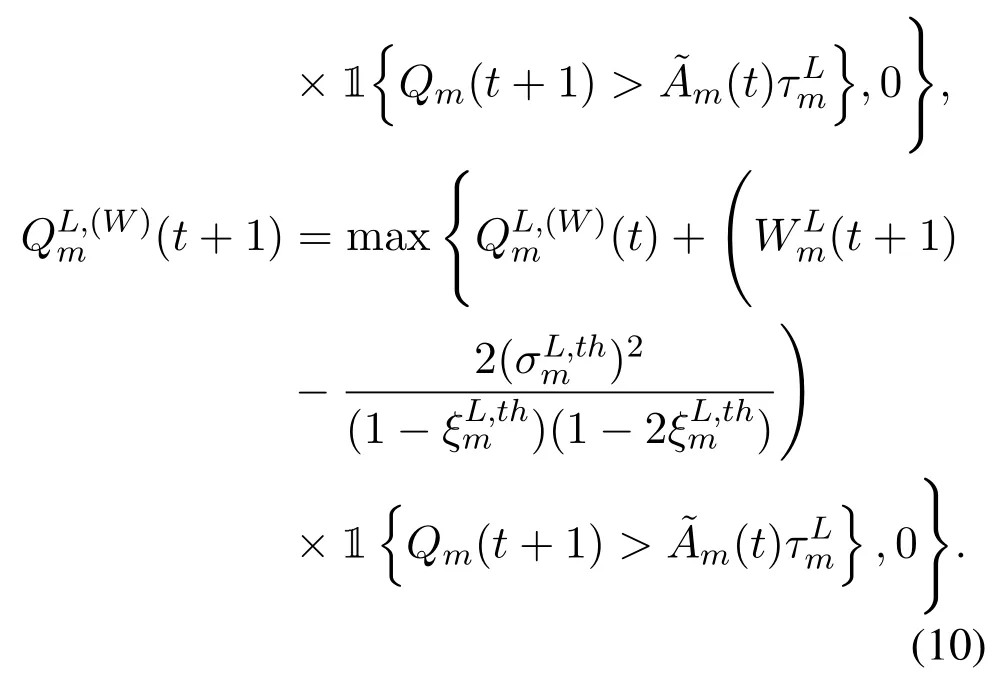
Here,1{x}is an indicator function where 1{x}= 1 if eventxis true,and 1{x}= 0 otherwise.Based on the definitions,the prerequisite of the excess backlog existence is the extreme event occurrence.Therefore,an indicator function related to the extreme event occurrence,i.e.,is multiplied when updating the URLLC constraint deviation queues.
Analogously,we introduce the virtual queues,,andcorresponding to the long-term URLLC constraints (8) of the server-side task queueHm,n(t),which are given by
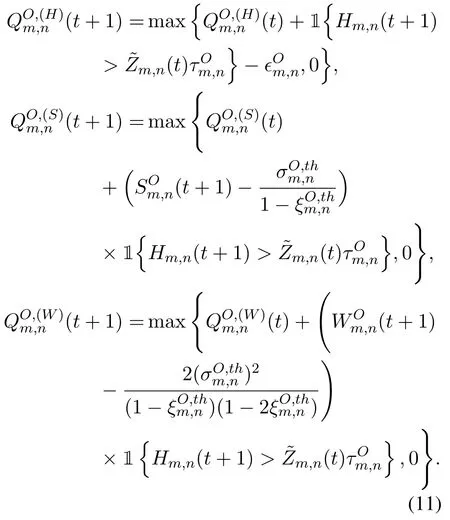
Theorem 1.Whenare mean rate stable,C2auto-matically holds.
Proof.The detailed proof is omitted due to space limitation.A similar proof can be found in[25].
Then,P1 is transformed into a series of short-term deterministic subproblems,which can be solved by each UV in a slot-by-slot manner.The transformed problem P2 aims to maximize the throughput while guaranteeing the URLLC constraints in a best-effort way,which is formulated as
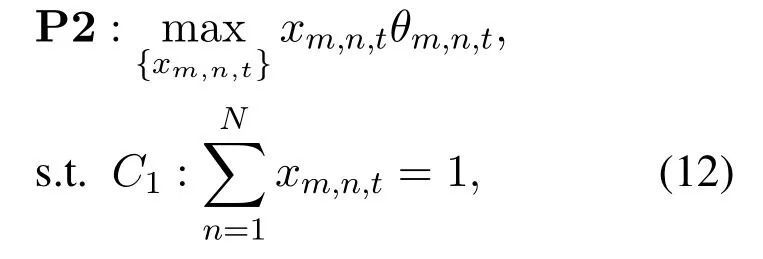
whereθm,n,tis the weighted sum of throughput and URLLC constraints deficits,which is given by
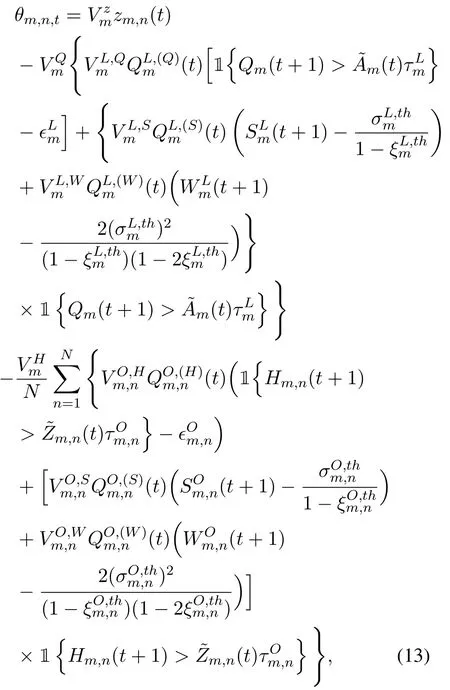
where,,andare t he corresponding positive weights of throughput,URLLC constraint deficits of the local and server-side task buffers,respectively.are the weights to unify the order of magnitude.
We aim at designing an online task offloading approach,where in each time slot,each UV independently selects a server for task offloading in order to maximize the weighted sumθm,n,t.One feasible solution is to model the task offloading decision problem as the MDP process.
4.2 Definitions of State,Action,Reward,and Transition Probability
The MDP process is defined by four critical factors,namely state,action,reward,and transition probability,which are described as follows.
4.2.1 State
At the beginning of thet-th time slot,the network state is determined by the queue information,the vector of which is given by Sm(t) =
4.2.2 Action
In the considered environment,each UV has to select one of the servers for task offloading,e.g.,sn.Accordingly,the action forumis denoted by vector Xm(t)=[xm,1,t,···,xm,N,t].
4.2.3 Reward
To optimize P2,we define the reward ofumselectingsnin thet-th time slot as the optimization objective of P2,i.e.,θm,n,t.
4.2.4 Transition Probability
The transition probability thatumstarts from state Sm(t),selects action Xm(t),and transfers to the next state Sm(t+1)is calculated by
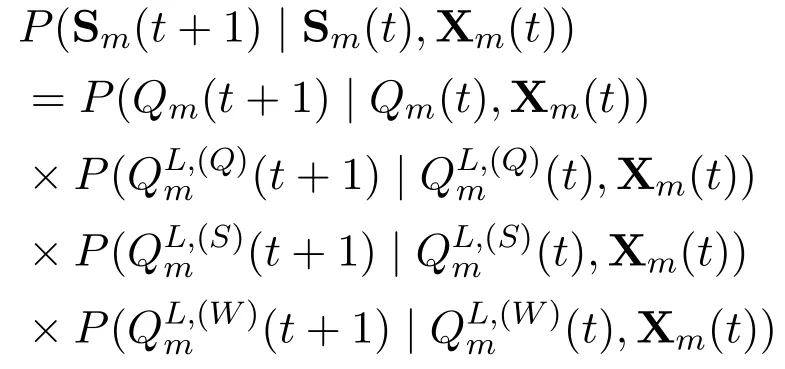
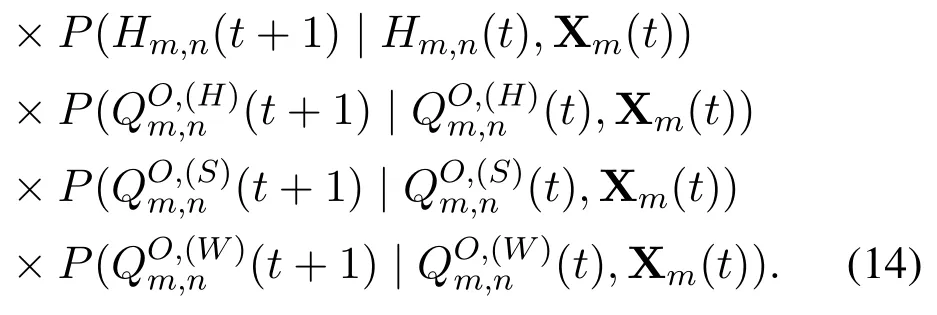
Due to the mobility uncertainty and the combinatorial nature,i.e.,the queue backlog is determined by the task offloading decisions of bothumand the other UVs,the specific value ofP(Sm(t+ 1)|Sm(t),Xm(t)) is unknown.In addition,the state space exponentially grows with the increasing number of servers,which makes the environment intractable.Therefore,the task offloading problem can be solved by the model-free RL-based method.
4.3 URLLC-aware DQN-based Task Offloading: DREAM
To cope with the dimensionality curse,we resort to Qlearning since it has great potentials in solving the task offloading with large state space.It estimates the value of selecting actionain states,i.e.,the Q value,which is defined as
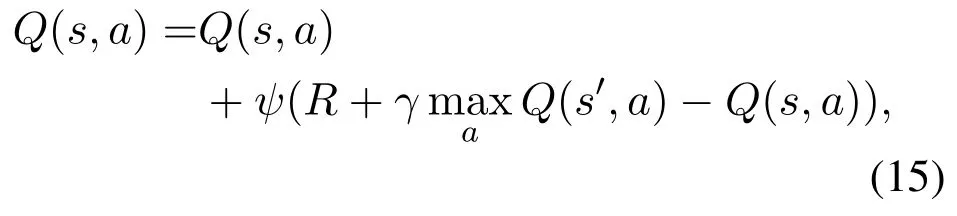
whereψ,R,γ ∈[0,1],s′are the learning rate,reward,discount factor,and the next state,respectively.In each time slot,Q-learning selects the action based on∊-greedy and the estimated Q value.
With the increasing environment scale,huge storage resources are required to store all the Q values for each state-action pair,which results in impracticability and inefficiency.To handle the problem of dimensionality curse,we resort to DQN-based approach,the concept of which is to leverage deep NN to approximate the mapping relationship between state and action to Q values instead of directly calculating and storing them.Specifically,a deep NN is utilized to progressively approximate the parameterωto achieve
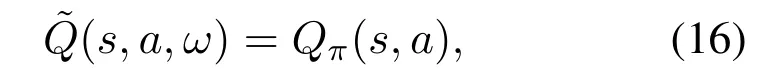
whereπis the policy,i.e.,the mapping relationship between the state and the action.
Experience replay can efficiently improve the performance optimality by relieving the correlation and non-stationary distribution of training data.Specifically,the agent maintains a replay memory pool to store the past and newly obtained experience data,and randomly samples a mini-batch of experience data from the pool to train the DQN periodically,thereby reducing the correlation among training data.
In this paper,UVumis assumed to maintain a replay memory poolVm(t)with a finite size ofVto store the transitionIm(t) = (Sm(t),am(t),θm,n,t,Sm(t+1))between two adjacent states,which consists of four components: the current state Sm(t),the selected actionam(t),the rewardθm,n,tfor taking actionam(t)in the current state,and the next state Sm(t+1).The transitionIm(t)is stored inVm(t)at the end of thet-th time slot and overwrites the old transitionIm(t −V).In each time slot,umrandomly samples a mini-batch of experience data,i.e.,(t)⊆Vm(t)with a size ofto online train and update the DQN.
In addition to the DQN network with parameterωused to make task offloading decisions,we also leverage a target DQN network with parameter ˆω,which has the same structure as the DQN network to assist in training the DQN network.At the beginning of training,initialize the parameter of the target DQN network as=ω.Thereafter,update=ωeveryCtime slots.
The implementation procedure of the proposed DREAM is summarized in Algorithm 1.
First,initialize the replay memory pool and the mini-batch for experience replay.We assume that there areGepisodes and each episode consists ofTtime slots.At the beginning of each slot,each UVumleverages∊-greedy to select a server based on the estimated Q values (line 6~line 7).Then,umoffloads tasks to the selected server,e.g.,sn,calculates the reward,and updates the queue information as(1),(4),(10),and (11).Then,transfer to the next state Sm(t+1).Next,the replay memory pool is updated by the most recent transitionIm(t),and a mini-batch(t)⊆V(t)is randomly sampled(line 12~line 13).Afterwards,umcalculates the loss function as
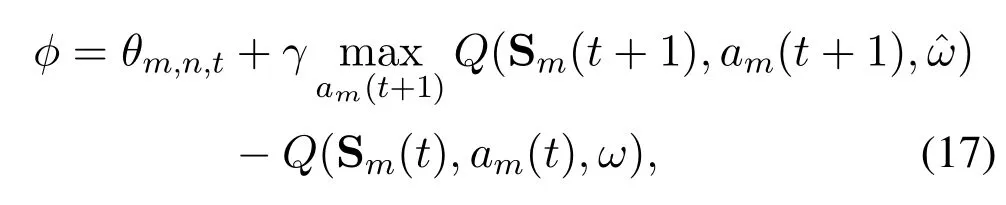

Algorithm 1.DREAM.1: Input: Network state Sm(t),∊.2: Output: Task offloading decision{xm,n,t}.3: Initialize: Replay memory pool Vm(t),minibatch ˜Vm(t).4: For episode g =1,···,G do 5: For time slot t=1,···,T do 6: Randomly select an action am(t) with the probability ∊.7: Otherwise am(t) = arg maxam(t)Q(Sm(t),am(t)|ω).8: Offload tasks to the selected server.9: Calculate reward θm,n,t as(13).10: Update Qm(t), QL,(Q)m (t), QL,(S)m (t),QL,(W)m (t), Hm,n(t), QO,(H)m,n (t), QO,(S)m,n (t),and QO,(W)m,n (t)as(1),(4),(10)and(11).11: Transfer to the next state Sm(t+1).12: Update the replay memory pool Vm(t)with the transition Im(t).13: Randomly sample a mini-batch ˜Vm(t) ⊆Vm(t).14: Calculate loss function φ as(17).15: Update ω =ω −ψ′∇ωφ2.16: Update ˆω =ω every C time slots.17: end for 18: end for
which reflects the estimation error of the DQN network.φ >0 means that the DQN network overestimates the current state,whileφ <0 means that the DQN underestimates the current state.A larger square of loss function,i.e.,φ2,indicates a larger estimation error of the DQN network.
The parameterωof the DQN network is updated based on the gradient descent method,i.e.,ω=ω −ψ′∇ωφ2,whereψ′represents the learning rate,φis the loss function,and∇ωφ2represents the gradient ofφ2with respect toω.It enforces the network to be updated along the direction of loss function reduction.The network updating based on the gradient descent method possesses the advantages of fast convergence,high stability,and low complexity.Compared with updating network with discounted return of costGt=Rt+γRt+1+···+γT−tRTin an episodeby-episode manner,updating the network parameter withφdoes not require the complete action sequence.Therefore,the network can be updated in each time slot which significantly accelerates the convergence speed.Finally,umupdates the parameter of the target DQN network as=ωeveryCtime slots (line 16).The iteration terminates wheng >G.
URLLC awareness is achieved by considering the queuing delay bound violation probability and the high-order statistics of the excess backlog.Specifically,the reward becomes smaller and the loss function becomes larger when the URLLC performance deviates heavily from the requirements.Therefore,the Q value of the selected state-action pair becomes smaller after network updating,and the UV switches to select another server with better URLLC performance.
V.PERFORMANCE ANALYSIS AND SIMULATIONS
In this section,we evaluate the proposed DREAM through simulations.We consider 5 UVs,2 VFSs,i.e.,s1ands2,and 3 RSUs,i.e.,s3,s4ands5,where the VFSs and UVs drive in the same direction.We assume that VFSs are available for UVs all the time,whiles3,s4,ands5are unavailable for UVs whent= [1,200],[201,400],and [401,600],respectively.Referring to [22],the computational resources at the server side are allocated according to the queue backlogwherefn,maxis the amount of the maximum available computational resources ofsn.The channel gain betweenumandsnis set asgm,n,t=127+30×logdm,n,t[26].The sizes of the replay memory pool and the mini-batch are set as 1000 and 50,respectively.The other detailed simulation parameters are shown in Table 1 [27,28].Two state-of-the-art algorithms areleveraged as comparison.The first one is EMM[26],where the energy awareness is replaced as URLLC awareness.The second one is D-QLOA [29],where the optimization goal is replaced by throughput and URLLC is not considered.
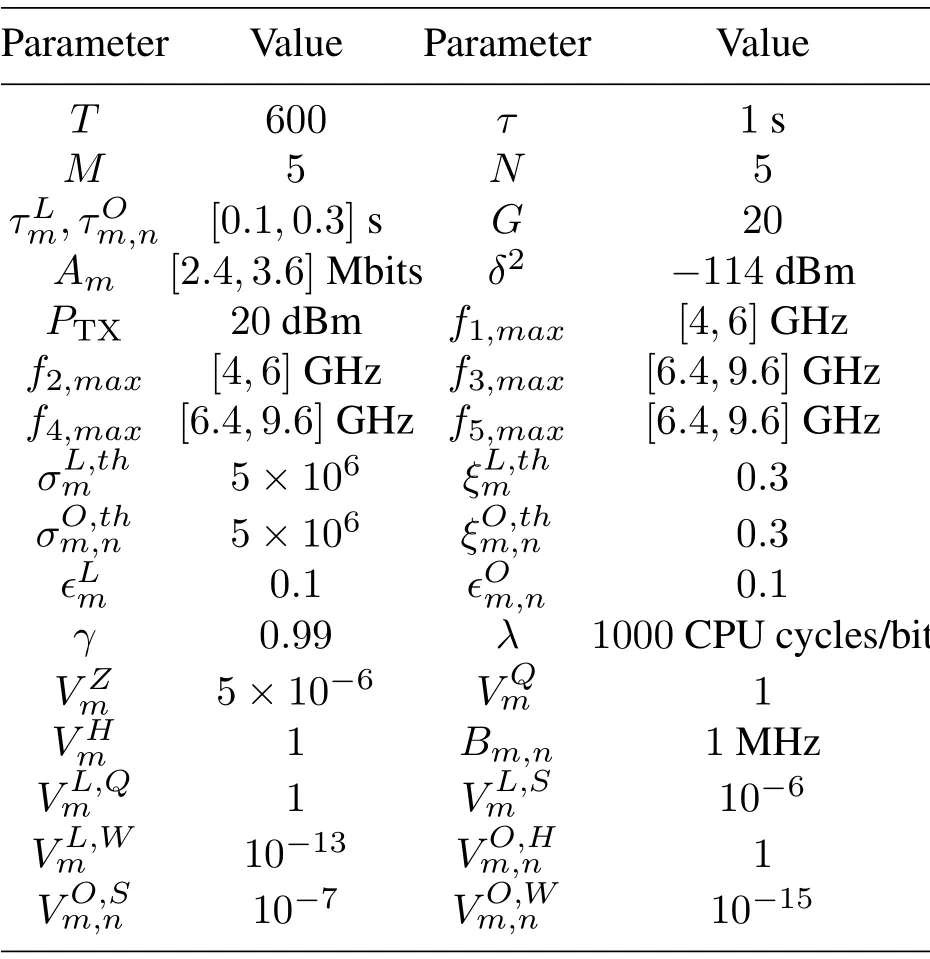
Table 1.Simulation parameters.
Figure 2 shows the average throughput versus time slots.D-QLOA performs the best in throughput because D-QLOA aims at maximizing throughput,therefore more tasks are offloaded from the local task queue to the servers.Although DREAM performs slightly worse than D-QLOA in throughput performance,the performances of the server-side queuing delay and the end-to-end queuing delay are much better as shown in Figures 3(b)-(c).EMM performs the worst due to the weak capability to learn and predict network environment with large state space.
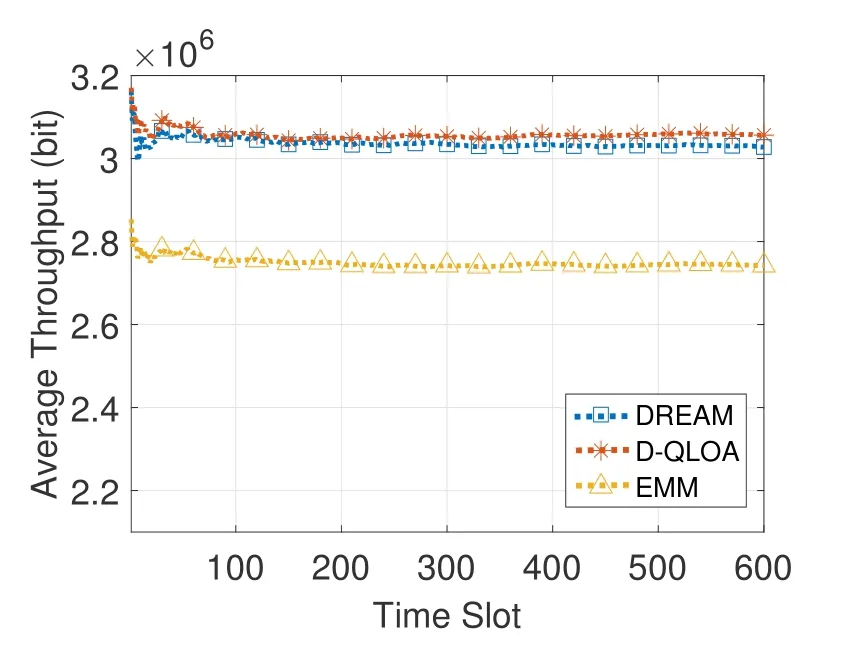
Figure 2.Average throughput performance.
Figures 3(a)-(c) show the box plots of the UV-side average queuing delay,the server-side average queuing delay,and the average end-to-end queuing delay,i.e.,the sum of UV-side and server-side queuing delay.The upper adjacent of the box is defined as the maximum data point located within the interval from the third quartile to the third quartile plus 1.5 times of interquartile range(IQR),and the lower adjacent is defined similarly.The red line in the box represents the median of the data.Numerical results indicate that compared with D-QLOA and EMM,DREAM reduces the server-side queuing delay fluctuation by 68.31%and 71.92%,and reduces the end-to-end queuing delay fluctuation by 52.55%and 62.98%,respectively.
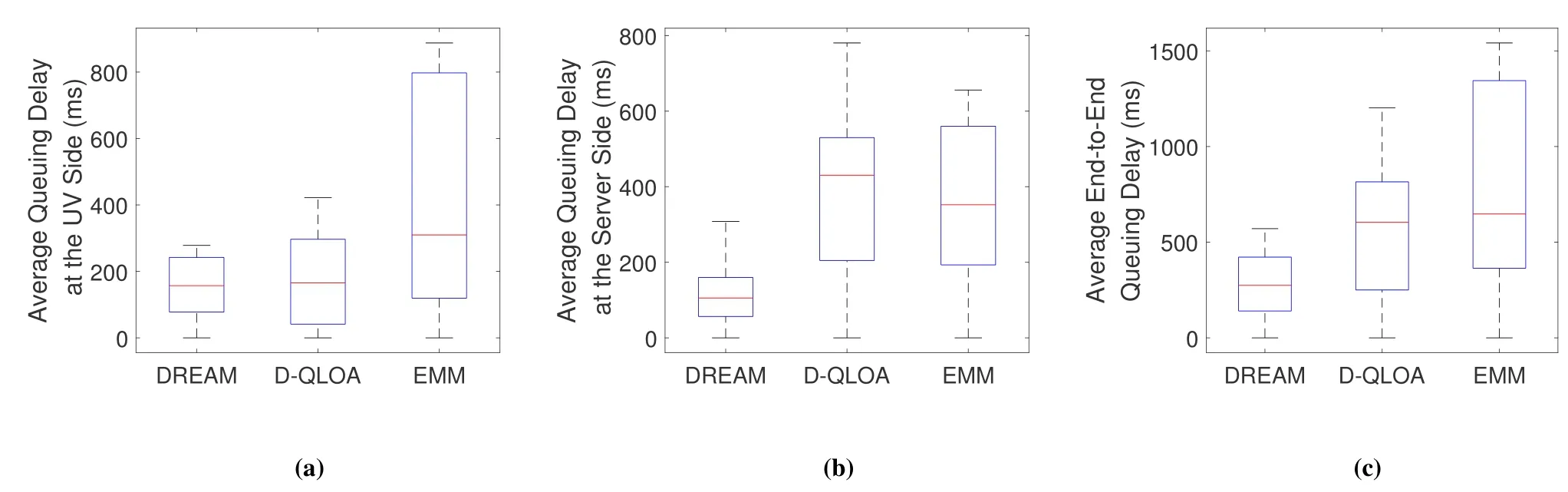
Figure 3.Queuing delay performances: (a)Average queuing delay at the UV side;(b)Average queuing delay at the server side;(c)Average end-to-end queuing delay.
Figures 4(a)-(c) show the average backlogs of virtual queues,,andat the UV side under differentiated URLLC constraints,respectively.D-QLOA achieves the least UV-side virtual queue backlogs since more tasks are offloaded to the servers at the cost of inferior server-side URLLC performance.However,the fluctuation of D-QLOA is larger than that of DREAM since it optimize queuing delay over the lens of average performance and the high-level statistic of excess backlog is not considered.DREAM performs slightly worse than D-QLOA in UV-side URLLC performance while the server-side and end-to-end URLLC performances of DREAM are more superior than those of D-QLOA as shown in Figure 5 and Figure 6(a).
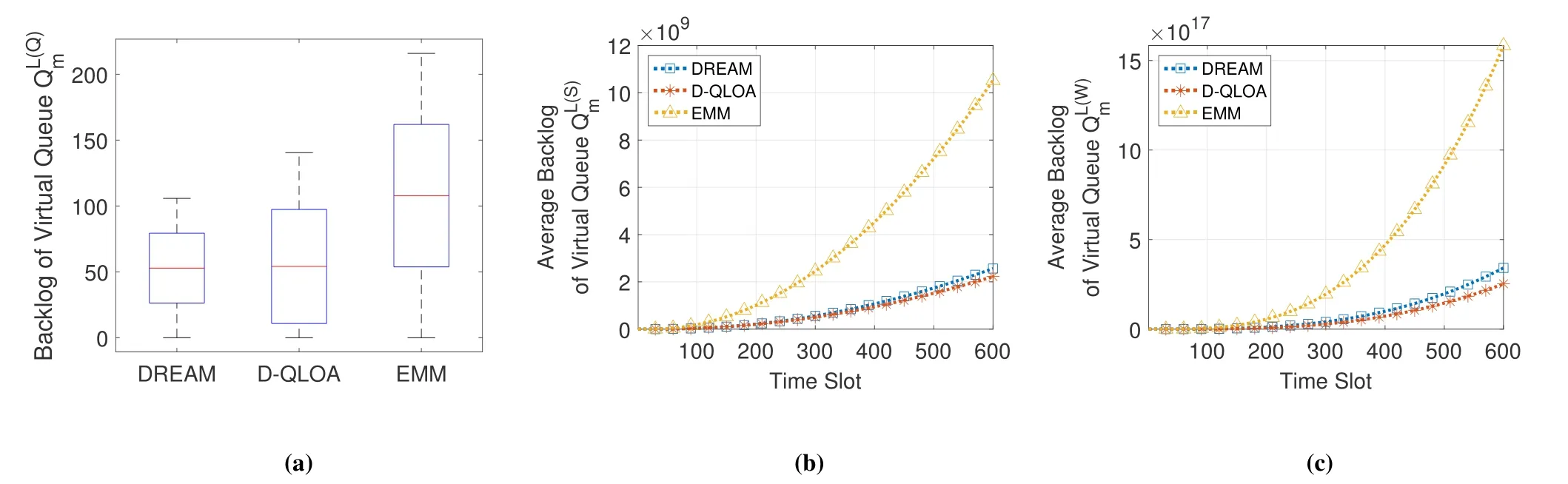
Figure 4.URLLC performances at the UV side under differentiated URLLC constraints: (a) Backlog of virtual queue;(b)Average backlog of virtual queue ;(c)Average backlog of virtual queue
Figures 5(a)-(c) show the URLLC performance in backlogs of virtual queues,andat the server side under differentiated URLLC constraints.The smaller backlog reflects DREAM can better meet the differentiated delay requirements.Compared with D-QLOA and EMM,DREAM reduces the virtual queue backlog ofby 89.07%and 71.43%,and the virtual queue backlog ofby 91.33%and 59.26%due to the URLLC awareness and superior capability to cope with the problem of dimensionality curse.Therefore,from Figure 4 and Figure 5,it can be concluded that DREAM can satisfy the differentiated URLLC constraints of UVs to the maximum extent.

Figure 5.URLLC performances at the server side under differentiated URLLC constraints: (a) Backlog of virtual queue;(b)Average backlog of virtual queue ;(c)Average backlog of virtual queue .
Figure 6(a) shows the numbers of extreme events of the server-side queuing delay and those of the end-to-end queuing delay.Compared with D-QLOA and EMM,DREAM reduces the number of extreme events of the end-to-end queuing delay by 28.13%and 51.06%,respectively.Figures 6(b)-(c) show the CCDFs of the excess backlogsSLm(t) andSOm,n(t) as well as the corresponding approximated GPDs,respectively.It can be seen that the approximated GPD provides an efficient characterization for the excess backlogs,which verifies the effectiveness of applying Pickands-Balkema-de Haan Theorem and GPD to parameterize URLLC.Besides,The GPDs with parametersare given as the thresholds.DREAM achieves the lower CCDF than the thresholds,which indicates that DREAM achieves a lighter tail distribution of the excess backlogs than the thresholds.Therefore,DREAM is suitable for the collaborative vehicular networks.
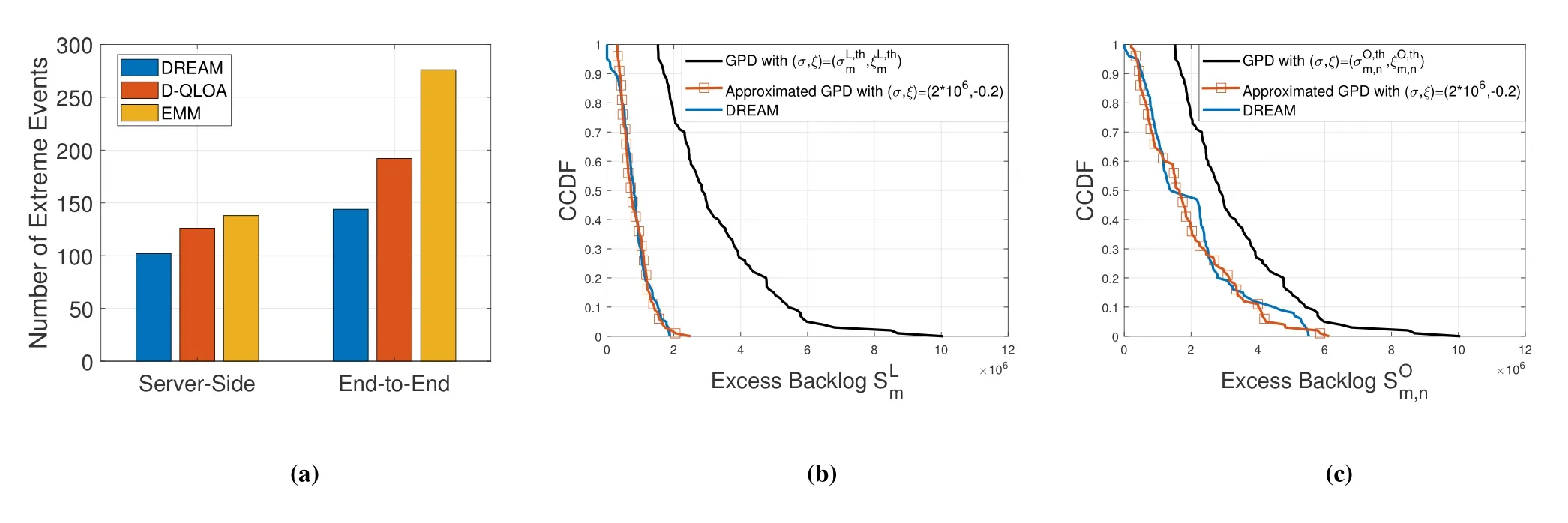
Figure 6.Effectiveness of applying the extreme theory in the collaborative vehicular network: (a)The number of extreme events;(b)Tail distribution of the excess backlog SLm and the approximated GPD of exceedances;(c)Tail distribution of the excess backlog and the approximated GPD of exceedances.
VI.CONCLUSION
In this paper,we investigated the task offloading problem in collaborative vehicular networks.We proposed a URLLC-aware task offloading algorithm named DREAM to dynamically optimize task offloading decision with incomplete information and efficiently cope with dimensionality curse.Simulation results demonstrate that compared with existing DQLOA and EMM,the maximum end-to-end queuing delay of DREAM is reduced by 52.55%and 62.98%,and the number of extreme events of end-to-end queuing delay is reduced by 28.13% and 51.06%,respectively.In the future,the joint optimization of communication and computational resource allocation in collaborative vehicular networks will be considered.
ACKNOWLEDGEMENT
This work was partially supported by the Open Funding of the Shaanxi Key Laboratory of Intelligent Processing for Big Energy Data under Grant Number IPBED3; supported by the National Natural Science Foundation of China (NSFC) under Grant Number 61971189; supported by the Fundamental Research Funds for the Central Universities under Grant Number 2020MS001.

- China Communications的其它文章
- Joint Topology Construction and Power Adjustment for UAV Networks: A Deep Reinforcement Learning Based Approach
- V2I Based Environment Perception for Autonomous Vehicles at Intersections
- Machine Learning-Based Radio Access Technology Selection in the Internet of Moving Things
- A Joint Power and Bandwidth Allocation Method Based on Deep Reinforcement Learning for V2V Communications in 5G
- CSI Intelligent Feedback for Massive MIMO Systems in V2I Scenarios
- Better Platooning toward Autonomous Driving: Inter-Vehicle Communications with Directional Antenna