
V2I Based Environment Perception for Autonomous Vehicles at Intersections
2021-07-14 09:06XutingDuanHangJiangDaxinTianTianyuanZouJianshanZhouYueCao
China Communications 2021年7期
Xuting Duan,Hang Jiang,Daxin Tian,Tianyuan Zou,Jianshan Zhou,Yue Cao
1 Beijing Advanced Innovation Center for Big Data and Brain Computing,Beijing Key Laboratory for Cooperative Vehicle Infrastructure Systems&Safety Control,School of Transportation Science and Engineering,Beihang University,Beijing 100191,China
2 School of Cyber Science and Engineering,Wuhan University,Wuhan 430072,China
Abstract: In recent years,autonomous driving technology has made good progress,but the noncooperative intelligence of vehicle for autonomous driving still has many technical bottlenecks when facing urban road autonomous driving challenges.V2I(Vehicle-to-Infrastructure)communication is a potential solution to enable cooperative intelligence of vehicles and roads.In this paper,the RGB-PVRCNN,an environment perception framework,is proposed to improve the environmental awareness of autonomous vehicles at intersections by leveraging V2I communication technology.This framework integrates vision feature based on PVRCNN.The normal distributions transform(NDT) point cloud registration algorithm is deployed both on onboard and roadside to obtain the position of the autonomous vehicles and to build the local map objects detected by roadside multi-sensor system are sent back to autonomous vehicles to enhance the perception ability of autonomous vehicles for benefiting path planning and traffic efficiency at the intersection.The field-testing results show that our method can effectively extend the environmental perception ability and range of autonomous vehicles at the intersection and outperform the PointPillar algorithm and the VoxelRCNN algorithm in detection accuracy.
Keywords: V2I; environmental perception; autonomous vehicles;3D objects detection
I.INTRODUCTION
In recent years,autonomous driving technology has become a frontier hot spot in international automotive engineering.Academia and industry actively engage in devoting a lot of resources to the research of autonomous driving technology worldwide [1].Selfdriving automobiles[2],which rely on artificial intelligence,visual computing,radar,surveillance devices,and global positioning system,can automatically and safely drive without any human intervention.Depending on the advanced environment perception and accurate vehicle control technologies,self-driving automobiles free human hands,reduce the driver’s driving burden,even eliminate human errors,and reduce the rate of traffic accidents.Besides,self-driving automobiles can improve road capacity and reduce the environmental pollution caused by vehicle exhaust through accurate vehicle control.Therefore,the emergence of self-driving automobiles provides an ideal solution to traffic accidents,energy consumption,traffic pollution,and other problems.
Environment perception is one of the core technologies of the autonomous driving system.It provides crucial information about the driving environment for self-driving automobiles,including traffic lights,signs,lines,vehicles,road area,location,speed,and direction of obstacles around roads.It can even predict the changing rule of traffic conditions.It is an important guarantee for the intelligence of automobiles.The environment perception module is located upstream of the self-driving system.Through the analysis of data from different sensors,the analysis results are transferred to the PNC (Planning and Decision Control) module to achieve autonomous driving.The analysis results of the environment perception module include status,position,and trajectory of dynamic and static targets (such as vehicles,people,fences,road edges,etc.),traffic light status (red,yellow,green signals),and road environment status.
Edge Computing is a distributed development platform that integrates network,computing,storage,and application core functions near the edge of a network to provide edge intelligence services to nearby facilities [3].Because edge computing can provide more reliable and efficient services,mobile edge computing has been applied to intelligent water,intelligent building,intelligent security and smart vehicle management system,image recognition,and target detection as a research hotspot in the field of artificial intelligence.It plays a role in the airport and railway station security inspection,community security,mobile payment security,etc.Traditional machine vision and image recognition technologies mainly use cloud computing,which needs to utilize powerful computing and storage capabilities.However,network congestion and transmission delays can lead to a poor user experience.The dramatic increase in access and data volume led to more frequent interaction between users and cloud servers.The massive data that the core network has to transmit makes the network be under heavy communication load.Edge computing deployment eliminates data transmission requirements from users to cloud servers,reduces the load to the core network,and reduces transmission delays from sensors to computing edge to enhance the user experience.
There are still many challenges that need to be addressed to achieve large-scale applications of autonomous driving.The major challenge for the commercial application of autonomous driving is the high hardware cost.The evolution of autonomous driving technology changing from non-cooperative intelligence into cooperative intelligence lays a foundation for advanced autopilot at an affordable hardware cost.The limitation of environment perception for non-cooperative autonomous driving can be improved in a cooperative manner,especially at intersection scenarios.Autonomous vehicles need to establish a cooperative vehicle-infrastructure system (CVIS) through V2I communications and edge computing for the sake of sensing and collaboration enhancement.The redundant design of multiple combinations of sensors prevents a non-cooperative autonomous driving system from failing in emergencies,but this does not overcome the safety and efficiency issues in an environment with blind spots for machine vision.Under the CVIS environment,connected nodes,such as onboard and roadside units deployed on vehicles and roadsides,respectively,enable cooperative group intelligence to make traffic safe and efficient.Specially,cooperative intelligence is the crux of CVIS technology[4].It transforms autonomous vehicles and intelligent roads from isolated units to joint optimization and realizes real-time system response.With limited mobile computing resources onboard,a collaborative strategy for autonomous driving can improve the automobile’s perception ability and traffic efficiency under complex traffic scenarios.
This paper presents a novel autonomous driving environment perception solution,which is suitable for complex road environments.In the scheme,the vehicle-road collaborative system is mainly built through V2I communication at the intersections.The sensors deployed on the roadside are used to sense the traffic environment around intersections in realtime.The object detection results are sent back to the autonomous vehicles by V2I links.Compared with the traditional environment perception methods for non-cooperative autonomous vehicles,this cooperative scheme uses roadside sensors to assist the surrounding autonomous vehicles for perception enhancement.Therefore,the perception range of the autonomous vehicles at intersection environment gets improvement,and the limitation perception range for a non-cooperative autonomous vehicle is solved.Meanwhile,we propose the RGB-PVRCNN framework,which fuses vision features into the PVRCNN algorithm to improve the performance of 3D object detection and recognition for autonomous vehicles.The field-testing results show that our method outperforms the PointPillar algorithm and the VoxelRCNN algorithm in terms of detection accuracy.
II.RELATED WORK
Collaborative intelligence and environment perception are research hotspots in the fields of connected vehicles in recent years.With the development of networked vehicles,the increment in communication and computation capabilities of onboard modules and roadside infrastructures (e.g.,microcomputers,sensors,and base stations),and environment perception and edge computing have made considerable progress in autonomous driving applications.The auxiliary driving functions,including onboard networking,especially the environmental perception functions used in advanced driver assistance systems (ADAS),are originally equipped.To meet environment perception’s real-time and accuracy requirements,it is usually necessary to configure high-performance computing equipment onboard,such as the dedicated automotive industry-level machine vision support platform DRIVE.NVIDIA developed PX.Its powerful performance enables onboard equipment to meet the requirements for a variety of environment perception algorithms.However,due to its price of up to 100,000 yuan,it is difficult to apply them on ordinary vehicles platform for intelligent assisted driving.By combining an environment perception algorithm with an edge computing framework,the cost of object detection in a general vehicle can be greatly reduced,and the applications can achieve a nice tradeoff between real-time performance,accuracy,and cost.
The application of the fusion perception optimization algorithm based on mobile edge computing uses edge computing to provide a server at the edge of the network,transfer the image features extracted by the vehicle-side perception device to the edge server,and receive the feature information database.The feature information of the image to be recognized is extracted through the projection matrix and compared with the feature information database,which can reduce the amount of data transmitted to the cloud server and improve the recognition performance to obtain more real-time image recognition results.It is important to get the precise trajectory prediction on the future in an era of automated and autonomous vehicles [1,2].In collaborative intelligent systems,how to process the information sent by these different sensors has also become the focus of many studies.Researchers have put forward many representative theories from different directions.Data association is particularly important in collaborative intelligence and is the basis of multi-agent joint perception.The process of a multiagent detection association is to determine the corresponding relationship between the detection results of each agent’s sensor.In recent decades,many scholars have made great achievements in collaborative intelligence,multi-target data association,and multi-sensor information fusion.Singer’s first proposed nearest neighbor algorithm (Nearest Neighbor,NN) chooses the target closest to the target prediction location as the correct target.However,in a target-intensive environment,the NN algorithm is prone to errors [5].In 1972,Bar-Shalom and Tse presented a probabilistic data association(PDA)algorithm for clustered environments,which has the disadvantage of not being suitable for multiple targets.Based on PDA,Bar-Shalom proposed Joint Probability Data Association(JPDA) to solve the problem that the PDA algorithm cannot be used for multi-objectives.Although the research on the Collaborative intelligence perception algorithm is relatively late in China,many achievements have been made [6].He You et al.proposed an improved MK-NN algorithm based on the K-nearest neighbor method,ESM,and radar data association algorithm based on fuzzy theory and independent/related double threshold Association algorithm[7].
In recent years,many researchers have made a lot of progress in the research of perceptual fusion under collaborative intelligence.Siddiqui et al.proposed an extensible framework for sensor fusion: using the depth neural network to process the generated volume to generate a depth (or parallax) map.Although the framework can be extended to many types of sensors,Siddiqu focuses on a combination of three imaging systems: monocular/stereo cameras,conventional LiDAR,and SP LiDAR [8].Li et al.focused on distributed clustering to achieve collaborative intelligence perception.When collaborative detection of targets,some labeled data needs to be grouped by similarity so that training data is not needed to complete cognitive tasks of unknown target types[9].Cai presents a highway anti-collision warning algorithm based on road visual collaboration,which can complete the warning by edge calculation [10].Zhang combines the existing edge computing resource allocation schemes for vehicle networking.For the first time,it introduces a new measure,reputation value,to design a new collaborative intelligent edge computing resource scheme based on reputation value [11].LV presents a pedestrian collision avoidance system based on cooperative intelligence and machine vision.The system uses a camera to detect pedestrians in the vehicle and side modules.The roadside module separately fuses pedestrian data in multi-sensor conditions to achieve data fusion and collision risk identification in a multi-source data environment[12].Based on the collaborative intelligent computing control layer,You proposed a traffic awareness service system with centralized cluster awareness and service mode,explored the mechanism of the collaborative intelligence perception of the intelligent transportation system(ITS),studied how to use the collaboration of unmanned vehicle groups for effective traffic information perception,and established an open service system based on team collaborative situational awareness[13].Lu proposed the idea of hierarchical optimization and proposed a new supervised feature extraction algorithm,hierarchical discriminant analysis,to improve performance further and optimize the sum of intra-class and inter-class distances,and demonstrated the use of this image recognition optimization algorithm in the mobile edge computing environment [3].Sun designs an intelligent intersection navigation system based on road collaboration technology.After collecting the corresponding perceptual information data,the system uses ZigBee wireless communication technology to transmit data to the road test unit for analysis and prediction and collaborates on intersections [14].Chen used the camera to acquire images in real-time for lane line detection[15].
III.SYSTEM MODEL AND PROBLEM FORMULATION
The main scene studied in this paper is shown in Figure 1.The scene is set as a crossroads with four entranceways on the campus.When the autonomous vehicle enters the intersection,it cannot perceive the blocked vehicle in front.The autonomous vehicle communicates with the roadside terminal at the intersection,and the roadside terminal sends the global map of the laser point cloud to the autonomous vehicle.The autonomous vehicle uses the NDT registration algorithm to obtain its position on the global map and sends the position to the RSU.Finally,the RSU sends the perception results of the intersection back to the vehicle.The system architecture mainly consists of three parts.The first part is the overall environment perception stage of the system,which realizes the multi-sensor fusion perception of the autonomous vehicle and can obtain the environment information around the entrance of the intersection.The second part is the V2I communication and the data transmission stage,which realizes the communication connection between the autonomous vehicle and the roadside multi-sensor system.The RSU transmits the global point cloud map of the intersection to the autonomous vehicle at the entrance.The third part is acquiring laser point cloud data by the autonomous vehicle and using the NDT(normal distribution transformation)registration algorithm to accurately locate the autonomous vehicle.The point cloud map constructed by the NDT algorithm can be used to plan autonomous vehicles trajectories in the future.The problem to be solved in this paper is to provide accurate and rich environmental perception information for autonomous vehicles by combining the roadside sensing communication equipment,which can overcome the limited condition that the perception range and effectiveness of a non-cooperative autonomous vehicle meets at an intersection.
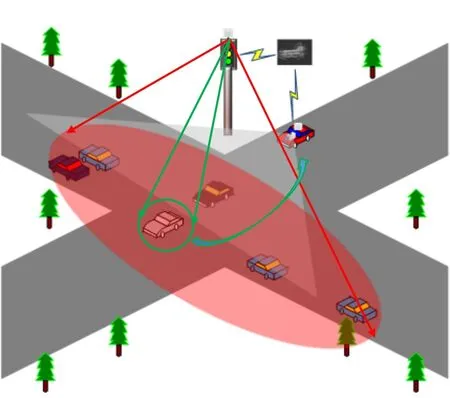
Figure 1.System model and the field-testing scenario.
IV.METHODOLOGY
4.1 V2I-based Environment Perception Algorithm for Autonomous Vehicles
With the rapid development of onboard sensors in recent years,autonomous driving technology has achieved excellent environment perception results.The technology of environment perception based on visual images presents a bottleneck in autonomous driving perception.With wide applications of vehiclemounted LiDAR in the field of intelligent driving,object detection technologies based on 3D point cloud data obtained by vehicle-mounted LiDAR have gradually become a research hotspot.The information carried by point cloud data is mainly based on the spatial coordinates and reflection intensity of LiDAR.Various open-source data sets have successively appeared,providing effective data support for network training and validation.In general,3D point cloud processing methods based on deep learning can be divided into indirect processing,direct processing,and fusion processing.The indirect point cloud processing method is mainly voxelization or dimensionality reduction of point cloud and then input to the existing deep neural network for processing.The direct processing method of the point cloud is to redesign the deep neural network for three-dimensional point cloud data to process the point cloud.The fusion method of point cloud processing is further to process the fusion image and point cloud detection results.With the development of image hardware,the fusion processing point cloud method will be the main technology of point cloud processing.Figure 2 shows the framework of the vehicle-road collaborative sensing system.
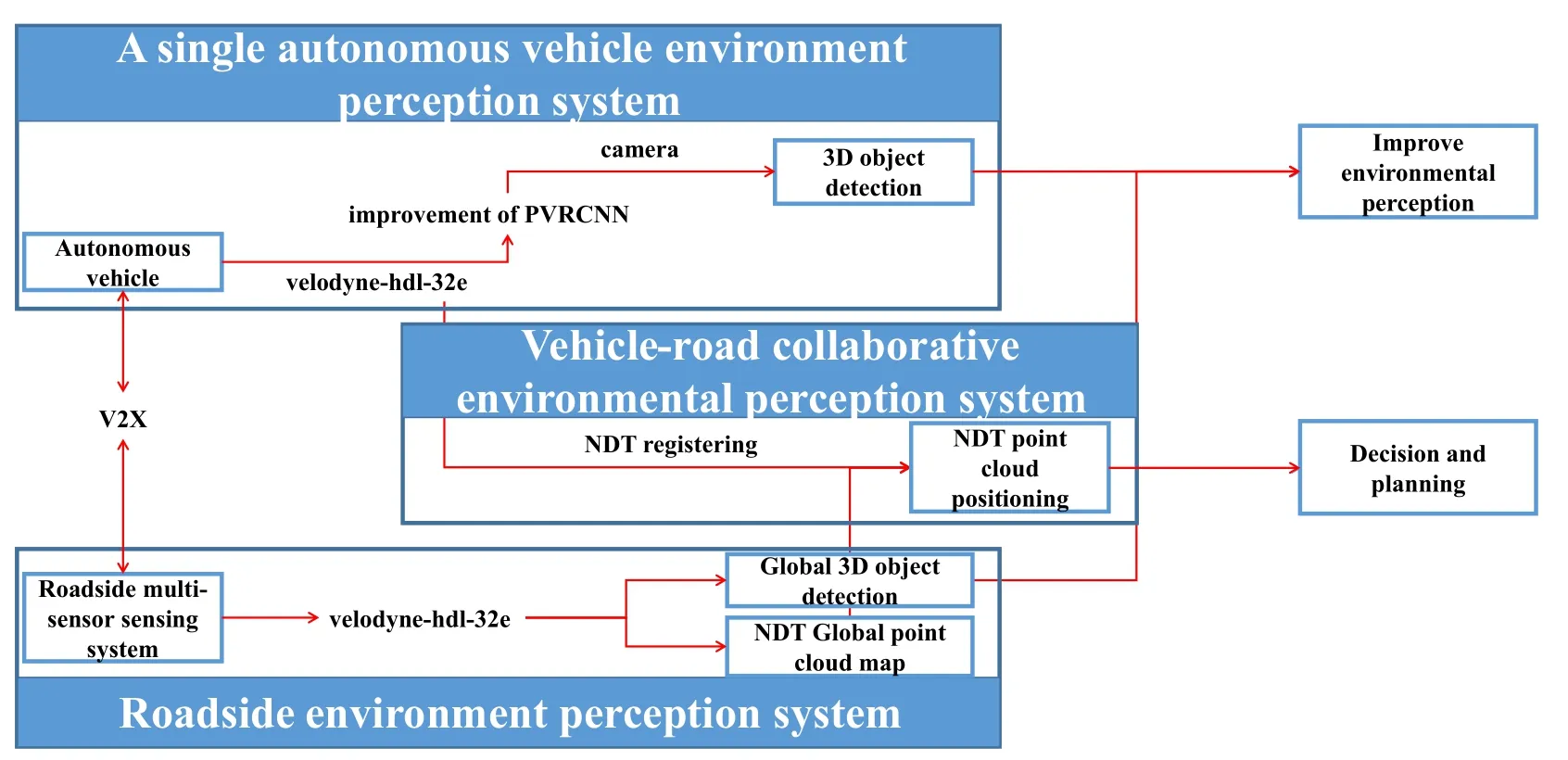
Figure 2.The framework of the vehicle-road collaborative sensing system.
4.2 3D Point Cloud Object Detection Algorithm(RGB-PVRCNN)
The most existing 3D detection methods could be classified into two categories: point cloud representations,voxel-based techniques,and point-based techniques.The voxel-based method has a fast calculation speed,but the detection effect is not ideal because the voxelbased method is sparse.Such methods all use 3D sparse convolution to extract features,such as SECOND and PART A*[16,17].The point-based method reduces the loss of the original point information,but the calculation cost is expensive.PVRCNN combines the advantages of point-based and voxel-based methods to improve the performance of 3D target detection.According to the single-mode 3D target detection framework of the laser point cloud proposed by PVRCNN[18,19],we add RGB image data to realize a multi-mode 3D target detection algorithm based on laser point cloud and image information fusion.
The main framework of the original PVRCNN algorithm is shown in Figure 3 [18].First,the original point cloud is processed in two different ways.One is based on the voxel method,the original point cloud is processed by voxel clustering,and The network utilizes a series of 3×3×3 3D sparse convolution to gradually convert the point clouds into feature volumes with 1×,2×,4×,8×downsampled sizes.Such sparse feature volumes at each level could be viewed as a set of voxel-wise feature vectors.The features obtained by 8×downsampled are compressed to obtain the aerial view features,and then the proposal box is generated using the anchor-based method.As the original point cloud is relatively sparse,the resolution of the feature body obtained by 8×downsampled is lower,which leads to serious information loss of the whole point cloud and makes the proposal box obtained by regression inaccurate.Therefore,PVRCNN ensures the accuracy of the proposal box by increasing the characteristic quantity of the cloud.PVRCNN conducts key point sampling on the original point cloud through FPS (farthest point sampling) algorithm so that the key points are uniformly distributed in nonempty voxels and can represent the whole scene.The VSA voxel set extraction module is respectively under four voxel feature bodies of different scales.By extracting the feature about the key point from the sphere with radius r and center as the key point and splicing it with the original feature of the key point and the bird’s eye view,the extended VSA feature is obtained.The feature has multi-scale information.
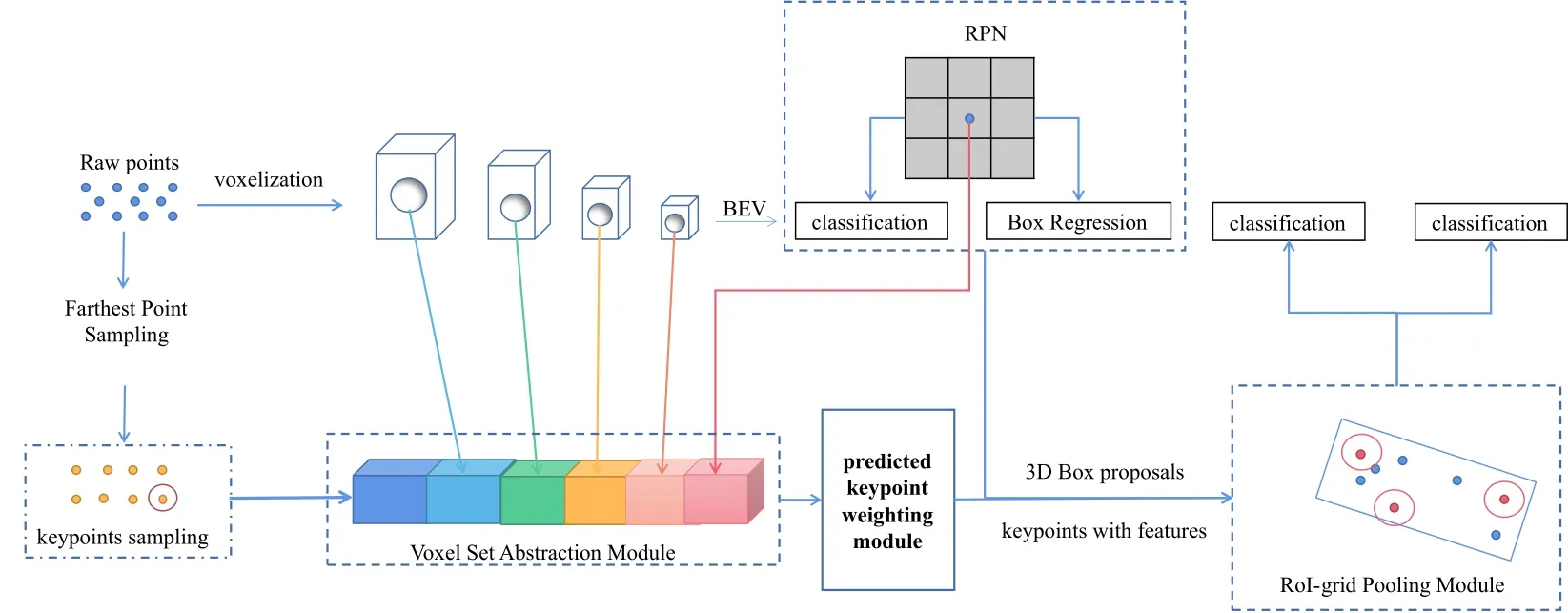
Figure 3.The main framework of the original PVRCNN algorithm.
Figure 4 shows the main framework of the RGBPVRCNN algorithm we propose.The improvement we made is to integrate the features of the image data.Image data is used as input to extract features through a convolutional neural network.Then the feature is used for regression to obtain the two-dimensional boundary box of the target.The 3D bounding box obtained by laser point cloud feature extraction and regression is projected in the x-direction and compressed and then matched with the 2D bounding box generated by the RGB image,further fine-tuning the bounding box.Finally,accurate 3D target detection results are obtained.
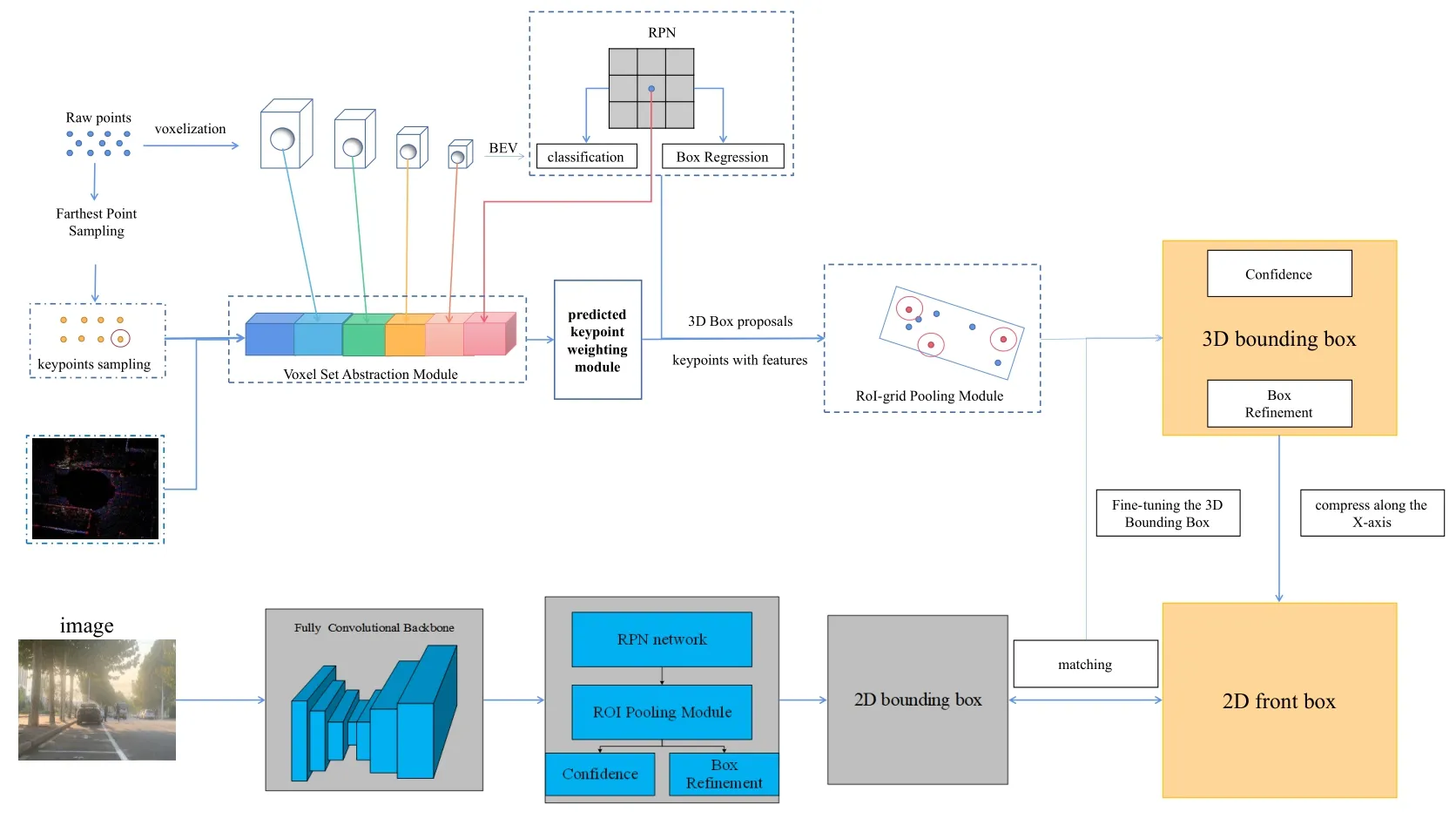
Figure 4.The main framework of the RGB-PVRCNN algorithm.
4.3 Point Cloud Registration Algorithm Based on NDT
The 3D-NDT algorithm can be used for the registration of two laser point clouds.Based on the laser radar scanning adjacent frames,the conversion relationship between frames is obtained by using a large number of repeated point cloud information so that the distance between two frame point clouds is infinitely close.This process is called point cloud registration.According to the 3D-NDT algorithm,we can obtain the global map of the laser point cloud and match each real-time data frame with the global map to obtain the pose of the autonomous vehicle[20].
We know that the NDT algorithm represents a large number of discrete points in a cube data set as a piecewise continuous differentiable probability density function.Firstly,the point cloud space is divided into several identical cubes,and there are at least 5 point clouds in the cube.Then,the mean value q and square of points in each cube are calculated respectively in the matrix[21]:
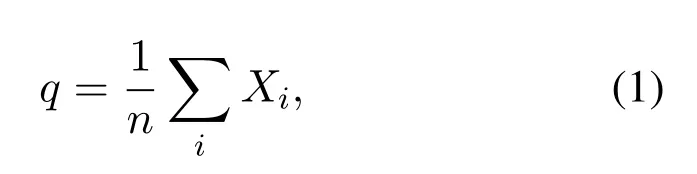
and
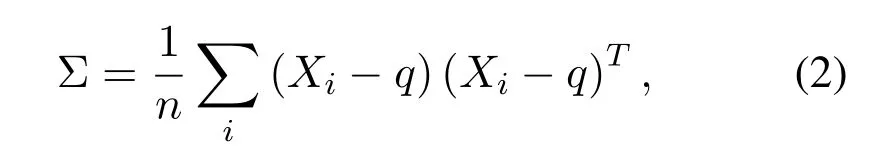
whereXi=1,2,3...,is the point set,nis the number of point clouds.The probability density function ofXifor each point in the cube can be expressed as:
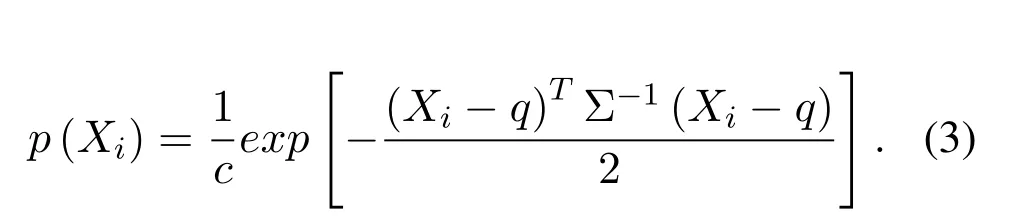
The Hessian matrix method is used to solve the registration between the adjacent frames of the point cloud data scanned by the vehicle-mounted LiDAR.
The essence of the point cloud registration is to obtain the relation of coordinate transformation according to the point cloud data collected by the autonomous vehicle at different positions.The specific algorithm of NDT point cloud registration is as follows:
Step 1.Calculate the NDT of scanning point gathering in the first frame of LiDAR.
Step 2.Initialize coordinate transformation parameter T:
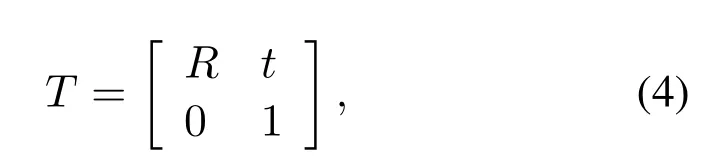
whereRis a 3x3 rotation matrix,andtis a 3x1 translation matrix.
Step 3.The laser scanning point clustering of the second frame is mapped to the coordinate system of the first frame according to the coordinate transformation parameters,and the mapped point clustering is obtained.
Step 4.Find the normal distribution after mapping transformation of each pointp().
Step 5.Add the probability density of each point to evaluate the transformation parameters of coordinates:
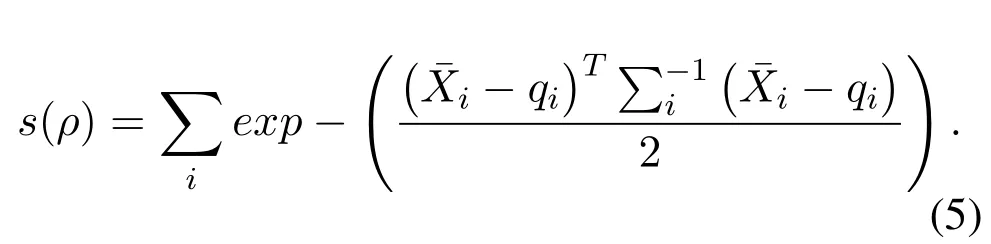
Step 6.Optimization ofs(ρ)using Hessian Matrix Method.
Step 7.Jump to Step 3 and continue until the convergence condition is met.
V.EXPERIMENTAL VERIFICATION
5.1 Introduction of Experimental Equipment
The experimental platform adopted in this experiment is shown in Figure 5,which is Baidu Apollo autonomous driving developer kit.Considering the application value,the leopardimaging 6mm monocular camera was selected as the visual data capture sensor,and the camera could obtain better color images compared to LiDAR.Also,Velodyne Ultra Puck16 LiDAR and Velodyne-HDL 32E LiDAR were used as pointcloud data capture sensors.VLP-16 LiDAR has a 100-meter long-range detection range,±15°vertical field of view,360°horizontal field of view scan,and outputs up to 300,000 laser point data per second.The VLP-16 LiDAR is installed on the roof of the car 1.65m away from the ground.The VLP-HDL32E LiDAR has a distance of 70m for remote measurement and can output 700,000 laser point cloud data per second.The VLPHDL32E is mounted on top of the signal control system.

Figure 5.Experimental equipments.
5.2 Multi-sensor Joint Calibration
The vehicle-mounted sensor should be calibrated jointly before collecting campus actual data,which mainly determines the internal reference matrix of the camera and the external reference matrix between the LiDAR and the camera,to transform the point cloud data obtained by the LiDAR into the image coordinate system.In this experiment,the calibration toolbox in the Autoware open-source autonomous driving framework is used to realize the calibration function of the sensor.The calibration process is shown in figure 6.First,we turned on the VLP-HDL32E LiDAR and the camera at the same time.Then,we placed the calibration board in 9 rows and 7 columns 5 meters in front of the camera and changed the calibration board’s orientation.The calibration plate faces are facing,looking up,looking down,left,and right.Finally,we will save the data collection results as a .bag file.The calibration process is shown in Figure 6.We need to find the calibration plate position in the laser point cloud,grab the calibration plate plane,and finally save the frame data.The calibration results of internal parameters and external parameters of the camera are shown in Table 1 and Table 2,respectively.The matrix of internal and external parameters of the camera is obtained.The reprojection error is 0.321289 less than 1,indicating the ideal effectiveness of the calibration process.
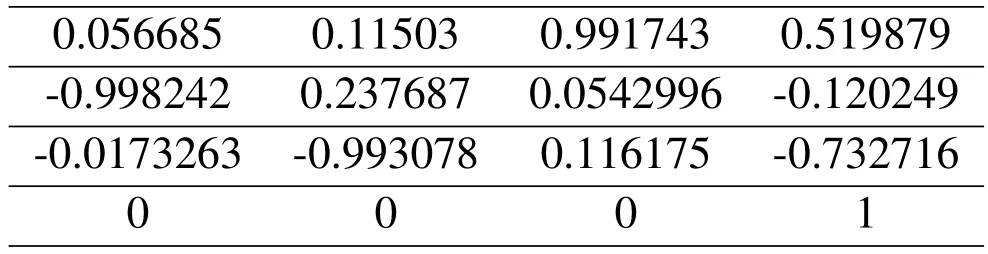
Table 1.Camera internal parameters.

Figure 6.Joint calibration of camera and LiDAR.
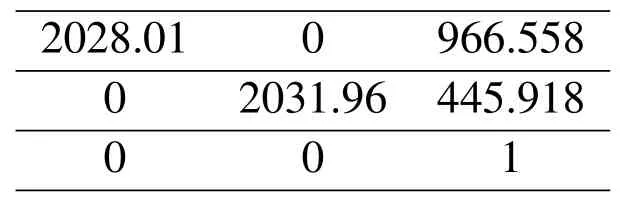
Table 2.Camera external parameters.
The data set collected by the experimental car platform and the signal control system platform is shown in Figure 7.Data set 1 and data set 2 are obtained by the experimental car platform at the campus intersection.Data set 1 is the visual image data of vehicles at the intersection,while data set 2 is the LiDAR point cloud data collected when vehicles are driving through the intersection.Data set 3 is the laser point cloud scanning data of the intersection with a certain height obtained by the roadside multi-sensor detection system,which is used for model training on the one hand and global map generation of the intersection point cloud on the other hands.

Figure 7.Experiment data set.
5.3 Generate the Global Map of Intersection Point Cloud
The point cloud data is critical to the mapping of autonomous vehicles.The point cloud’s initial pose state determines the efficiency and accuracy of the point cloud registration algorithm.During the acquisition of environmental data by LiDAR,due to LiDAR’s interference and environmental factors,the data returned by LiDAR has the characteristics of large data volume,including noise points and uneven data density.
The original sensor point cloud data is preprocessed to improve the high-point cloud registration algorithm’s real-time and accuracy.Firstly,the autonomous vehicle collects the LiDAR’s data,then the Voxel Grid filtering and other processes are carried out.Finally,we input the processed data into the point cloud registration algorithm for subsequent processing.
The roadside multi-sensor detection system along the intersection all imported continuous laser point cloud data.As shown in Figure 8,we use the NDT algorithm to the first frame laser point cloud data as a reference frame,fuse subsequent data frame and the reference frame for normal distribution,find the pose transformation matrix between the two frames by frames splicing when the last frame has matched the data frame,and finally get the final global point cloud maps for the intersection.Figure 9 shows the filtered global point cloud maps.

Figure 8.Original global intersection point cloud maps.

Figure 9.Filtered global point cloud maps.
5.4 Vehicle-road Collaborative Multi-sensor Joint Perception Experiment
Autonomous vehicles enter the intersection through four entranceways and conduct real-time environmental perception through cameras and LiDAR to perceive the surrounding vehicles.There will be occlusion between vehicles.The LiDAR can only scan the laser point cloud data reflected by the unblocked vehicle.Similarly,the camera cannot perceive the blocked vehicle in front,the practical scenario shown in Figure 10.

Figure 10.Image data of occluded vehicle.
The detection results of the 3D object detection algorithm based on RGB-PVRCNN camera and laser point cloud fusion are shown in Figure 11.The algorithm’s object detection results are shown in Table 3:the algorithm can detect the surrounding vehicles well.The accuracy of the algorithm can be seen in the table.The detection accuracy is improved,but the real-time performance of the algorithm and the frame rate degrades.
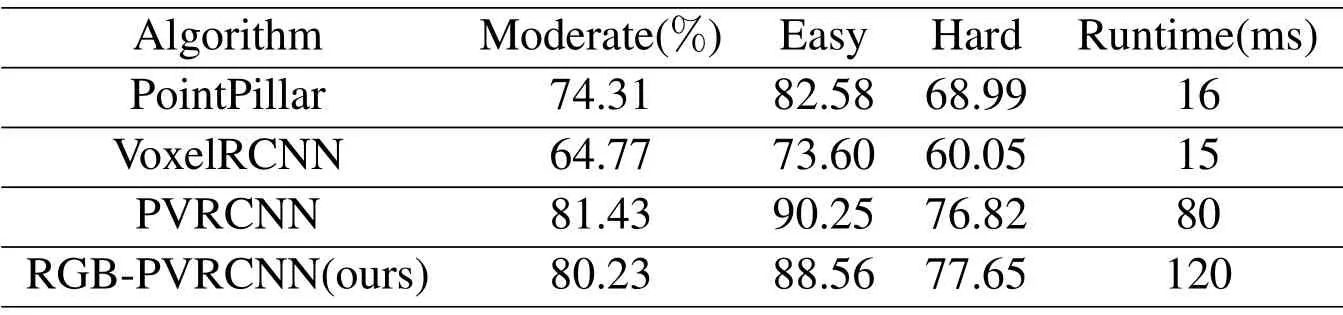
Table 3.Comparison of performance of 3D Object detection algorithms.

Figure 11.The detection results based on the RGBPVRCNN algorithm.
KITTI data sets use the mean average precision(mAP) to evaluate single class target detection models[22].Specifically,KITTI uses the precision-recall curve for qualitative analysis and the average precision(AP)for quantitative analysis of model accuracy.
KITTI utilizes the coincidence degree between the detection box and the ground truth box to evaluate the accuracy of boundary framing,which is defined by
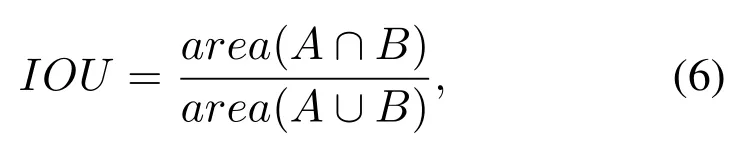
where A and B respectively represent the prediction box and the real box.This fraction represents the intersection part of A and B over the union of A and B.
If IOU>0.5 indicates that the detected border matches the class’s ground truth on the dataset.If the coincidence degree of multiple borders with ground truth is greater than 50%,KITTI takes the one with the maximum coincidence degree as a match to prevent duplicate detection.The remaining repeated predictions are treated as error detection.
We detect and identify vehicle classes,whereNis the number of real vehicles in the vehicle class data set.ThePRcurve andAPvalue evaluate the accuracy of target detection.We can get different recall(the recall is the ratio of correctly identified vehicles to the number of all vehicles in the test set)rates and accuracy rates by giving different threshold valuesTto draw thePRcurve and calculate the detection algorithm’sAPvalue.The calculation formula for the recall is
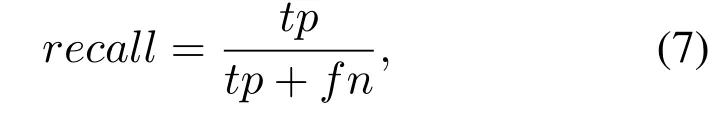
wheretprepresents the number of data correctly identified as a vehicle,fprepresents the number of data incorrectly identified as a vehicle.
The object detection task adopts thePRcurve andAPvalue to evaluate the accuracy of the model.Given different threshold valuesT,different recall rates and accuracy rates can be obtained.Thus,thePRcurve can be drawn,and theAPvalue of each detector can be calculated as follows
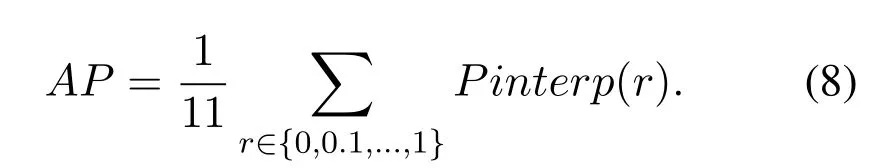
Theris the recall,and thePinterp(r)represents the precision at each recall level r is interpolated by taking the maximum precision measured for a method for which the corresponding recall exceedsr.
The KITTI data set is divided into the degree of detection difficulty based on the vehicle’s degree of occlusion during the data annotation process.The vehicle can be completely regarded as 0.The partially occluded vehicle is 1,the largely occluded vehicle is 2,and the completely occluded vehicle is 3.Therefore,the degree of difficulty of detection corresponds to: the easiness is 0,the moderateness is 1,the difficulty is 2 and 3.We also make our LiDAR data set according to KITTI data set standards.
The object detection results of a single autonomous vehicle are shown in Figure 11.The red proposal box represents the vehicle that is blocked by its right-side vehicle and fails to be detected by the autonomous vehicle.
In Figure 13,it shows the detection results of autonomous driving targets in the vehicle-road collaborative environment,in which the autonomous vehicle accurately perceives the vehicle that is not perceived in Figure 12.

Figure 12.Object detection results for a single autonomous vehicle.
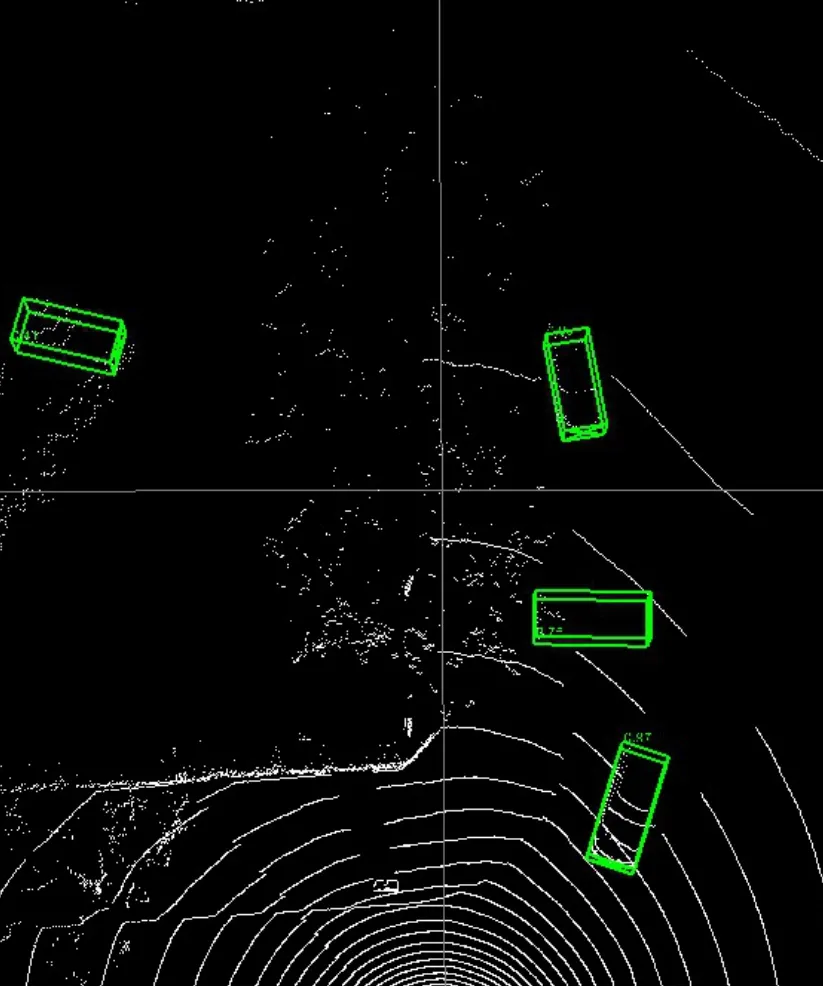
Figure 13.Object detection results for the intersection V2I system.
VI.CONCLUSION
In this paper,a novel vehicle-road collaborative interaction environment is proposed,in which LiDAR is set up at the side of the intersection to obtain the surrounding environment information.When the autonomous vehicle enters the intersection,it communicates with the RSU sensor terminal and receives the global map of the point cloud sent by the RSU terminal.The NDT algorithm is used for accurate positioning.The autonomous driving vehicle uses the vehicle camera and LiDAR for real-time environment perception and receives real-time global intersection perception information from the roadside sensor terminal to achieve the purpose of expanding the automatic driving vehicle perception range and accuracy.The field-testing experiment in the intersection data set collected on the campus shows that the improved multi-sensor fusion algorithm,RGB-PVRCNN,can obtain accurate 3D target detection results,but the real-time performance of the algorithm is affected due to a large amount of calculation.Finally,the experimental results show that this method can effectively extend the intersection’s environmental perception ability and range of autonomous vehicles.The following work aims to improve the real-time environment perception of autonomous vehicles by combining the roadside edge calculation method.
ACKNOWLEDGEMENT
This research was supported by the National Key Research and Development Program of China under Grant No.2017YFB0102502,the Beijing Municipal Natural Science Foundation No.L191001,the National Natural Science Foundation of China under Grant No.61672082 and 61822101,the Newton Advanced Fellowship under Grant No.62061130221,the Young Elite Scientists Sponsorship Program by Hunan Provincial Department of Education under Grant No.18B142.

- China Communications的其它文章
- Joint Topology Construction and Power Adjustment for UAV Networks: A Deep Reinforcement Learning Based Approach
- Machine Learning-Based Radio Access Technology Selection in the Internet of Moving Things
- A Joint Power and Bandwidth Allocation Method Based on Deep Reinforcement Learning for V2V Communications in 5G
- CSI Intelligent Feedback for Massive MIMO Systems in V2I Scenarios
- Better Platooning toward Autonomous Driving: Inter-Vehicle Communications with Directional Antenna
- Reinforcement Learning Based Dynamic Spectrum Access in Cognitive Internet of Vehicles