
A Joint Power and Bandwidth Allocation Method Based on Deep Reinforcement Learning for V2V Communications in 5G
2021-07-14 09:06XinHuSujieXuLibingWangYinWangZhijunLiuLexiXuYouLiWeidongWang
China Communications 2021年7期
Xin Hu,Sujie Xu,Libing Wang,Yin Wang,Zhijun Liu,Lexi Xu,You Li,Weidong Wang
1 School of Electronic Engineering,Beijing University of Posts and Telecommunications,Beijing 100876,China
2 China Unicom Research Institute,Beijing 100032,China
3 Department of Geomatics Engineering,University of Calgary,AB T2N 1N4,Canada
Abstract: Vehicular communications have recently attracted great interest due to their potential to improve the intelligence of the transportation system.When maintaining the high reliability and low latency in the vehicle-to-vehicle(V2V)links as well as large capacity in the vehicle-to-infrastructure(V2I)links,it is essential to flexibility allocate the radio resource to satisfy the different requirements in the V2V communication.This paper proposes a new radio resources allocation system for V2V communications based on the proximal strategy optimization method.In this radio resources allocation framework,a vehicle or V2V link that is designed as an agent.And through interacting with the environment,it can learn the optimal policy based on the strategy gradient and make the decision to select the optimal sub-band and the transmitted power level.Because the proposed method can output continuous actions and multi-dimensional actions,it greatly reduces the implementation complexity of large-scale communication scenarios.The simulation results indicate that the allocation method proposed in this paper can meet the latency constraints and the requested capacity of V2V links under the premise of minimizing the interference to vehicle-to-infrastructure communications.
Keywords: 5G; V2V communication; power allocation; bandwidth allocation; deep reinforcement learning
I.INTRODUCTION
With the swift development of intelligent vehicles and the evolution of mobile communications,Vehicle-to-Vehicle (V2V) communications [1–3]have been recognized as one of the important candidate technologies in 5G communications networks.In the conventional mode,the majority of vehicles communicate with each other via the base station (BS) [4].Each vehicle must pass local information,including local interference information and channel state to the central control unit.Facing the problem of radio resource allocation,the traditional method uses the central controller to receive vehicle information,which makes the transmission overhead very large and its will increase rapidly with the increase of the network scale.This season prevents the tradition methods[5–8]from scaling to the extensive network.
In most previous research,only the latency constraints of the V2V link and the SINR constitute the Quality-of-Service (QoS) of the V2V link.It is difficult for the optimization of the V2V link to consider the delay constraint,so previous studies have not fully considered it.
To solve this problem,we adopt deep reinforcement learning to allocate the radio resources in vehicular communications.Recently,deep reinforcement learning is proposed as an advantageous means to solve problems in the radio resource management[9–13].In[12],a method based on deep reinforcement learning has been put forward to allocate the radio resource allocation in the multi-beam satellite(MBS)to meet the requested traffic.On the base of that,reference [14]introduces a deep reinforcement learning framework into the radio resource management of V2V communications,providing a resource allocation scheme for both the broadcast and the unicast scenarios.To satisfy the strict latency constraints and meet the capacity on V2V link,reference [15]applies deep reinforcement learning(DRL)into the resource allocation and proposes a DRL framework to solve the problem.However,the power is discretized into three levels.To get good performance of the DRL based method,the number of the candidate discrete actions could be large,which make it difficult for traditional DRL based method to converge.These algorithms make the action space discrete,resource allocation problem cannot be regarded as a continuous action execution process,and the complexity of the above algorithm implementation is still high.
To address this problem,we propose a novel radio resources allocation mechanism for V2V communications based on proximal strategy optimization method.In this radio resources allocation framework,a V2V link or a vehicle that is designed as an agent,can learn the optimal policy based on the strategy gradient through interacting with the vehicle network environment and make the decision to select the optimal sub-band and the transmitted power level.By using neural networks to model the strategy,a feasible mapping between states and actions is realized,and the agent to continuously improve its strategy and achieve strategy optimization based on past experience.The simulation results indicate that the allocation method proposed in this paper can meet the latency constraints and the requested capacity of V2V links under the premise of minimizing the interference to Vehicle-to-Infrastructure(V2I)communications.
The remainder of the paper is organized as follows.Section II presents the scene model of the vehicle networks and formulation of the radio resource allocation problem in vehicle-to-vehicle communication.Section III proposes the proximal policy optimization(PPO) algorithm and a deep reinforcement learning framework based joint bandwidth and power allocation for V2V communications.In Section IV,the simulation scenarios are introduced,and the final simulation results are analyzed.In Section V,conclusions are drawn based on the simulation results of the previous section,which proves the effectiveness of the algorithm.
II.SYSTEM MODEL AND PROBLEM FORMULATION
2.1 System Model
In this section,the system model and the problem of radio resource management in V2V communications are presented.From Figure 1,we can see that the vehicular communication network mainly includes two links: one is the V2V link devoted byK={k|k=1,2,...,K}.The other is the V2I link between the base station(BS),which is devoted byM={m|m=1,2,...,M}and the V2V users(VUEs).
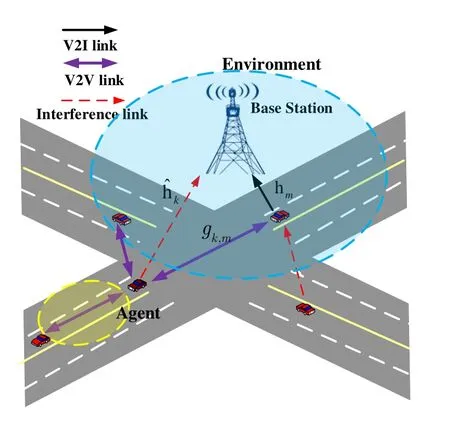
Figure 1.An illustrative structure in the vehicular communication networks.
In the vehicular networking scenario studied in this article,the main scenario we studied is scenario 4 defined in cellular V2X communications [16].With the development of the car networking business diversification,the relevant business to delay requirement is stringent,combined with limited car terminal calculation ability.The traditional algorithm has a larger communication time delay,unable to meet the demand of vehicle network time delay,so how to effectively resolve the calculation problem of vehicle communication low latency business is one of the present study highlights.Since it is difficult to transmit information to the centre due to the fast speed of the vehicle in this scenario,we allocate the resources of the V2I link independently.We scheme to assume that there are M orthogonal spectrum resources in the system and they are allocated to M V2I links in advance.A V2I link can only occupy one sub-band and specify each V2I link’s transmission power,but multiple V2V links can occupy a sub-band.
Assuming that sub-bands with known transmission power are allocated to the V2I uplink,i.e.,themthV2I link occupies themthsub-band,the vehicle can autonomously determine the results of these resource allocations and choose whether to communicate with V2V.Thus,the difficulty is to program an efficient radio resources allocation mechanism for V2V communications underlying high mobility vehicular environments.In the vehicular networking scenario,the single-to-interference-plus-noise ratio (SINR) of themthV2I link over themthsub-band can be expressed as
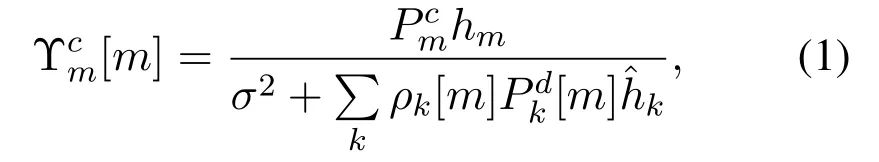
whereσ2is the noise power,PcmandPdkdevote the transmission powers in themthV2I and thekthV2V,respectively,ρk[m]is the bandwidth allocation indicator withρk[m]= 1 if thekthV2V link reuses themthsub-band,andhmis the power gain of the channel which is relevant to themthV2I,is the interference power gain of thekthV2V.
And the SINR of thekthV2V link can be expressed as follows.
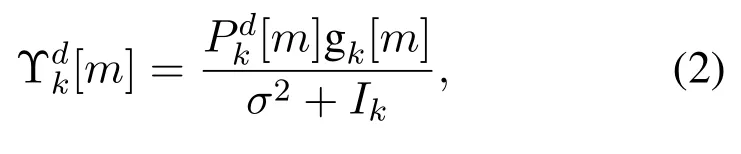
whereIk=Gc+Gddenotes the interference power,anddenotes the total interference power of V2V links that use the same spectrum resource and the interference power of V2I links that occupy the same spectrum resource.gk[m]the power gain of thekthV2V link occupying themthsub-band channel,indicates the interfering power gain of themthV2I link,and[m]devotes the interfering power gain of thek′thV2V link.
Therefore,the throughput of themthV2I link can be expressed as follows.
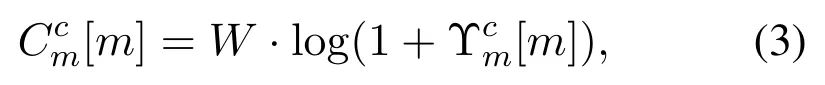
whereWis the bandwidth of each sub-band.
And then,the capacity of thekthV2V link can be written as follows.
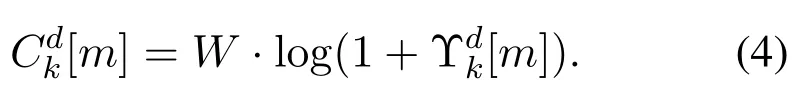
Channel information including V2V link of the instantaneous channel power gain of sub-channels and V2I link channel information transmitter to the base station power gain,namely the interference information for V2I link interference intensity of each channel to receive,transmit messages related to the resource allocation for a moment in the frequency distribution,V2V link information transmission time remaining,and the rest of the transmission of the payload.
2.2 Problem Formulation
Since the purpose of V2I links is to provide services for businesses with large data volumes and high rates,the goal is to maximize the sum throughput of V2I,denoted asThe radio resource allocation of the V2V links and V2I links should be independent of each other,the reason is that the BS has no information about the V2V links.Because the significance of V2V communications in the safety protection system of vehicles,the reliability and stringent latency of V2V links are much more important than the data rate.In this paper,our goal is to meet the delay constraints of the V2V link and the requested capacity while the V2V link has the least impact on the V2I link at the same time.In this situation,the relevant capacity of each link can be written as follows.
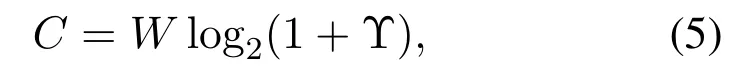
where Υ is the SINR of the relevant link andWis the bandwidth of each sub-band.
This model belongs to the multi-objective optimization problem.The first goal of multi-objective optimization is to reduce the impact of V2V link on V2I link,that is,to maximize the capacity of V2I link.The second goal is to meet the traffic demand of V2V link,and the third goal is to meet the delay constraint of V2V link,that is,to complete the information transmission within the delay constraint time.We formulate the joint power and bandwidth allocation problem in the V2V communication scenario,which can be expressed as
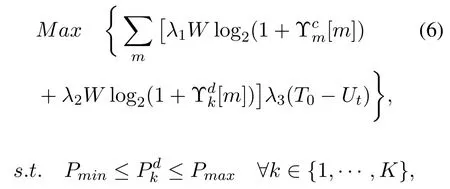
whereUtdenotes the time remaining before the delay constraint is violated andT0is the maximum tolerable latency.λ1,λ2,andλ3are the weight constant used to define the priority between the three targets and the quantity (T0−Ut) is the time used for transmission of V2V communications.The second part of Eq (6)indicates that the power allocated for each link should not exceed the total power limit of the link.
III.DEEP REINFORCEMENT LEARNING FOR V2V COMMUNICATION
This section details the solution to the dynamic resource allocation of the V2V communication system.Firstly,the DRL architecture and PPO algorithm are presented.Then,we developed the dynamic bandwidth and power allocation based on DRL in V2V communication.Finally,we give the design of the state,action and reward in the V2V communication network.
3.1 DRL Architecture
Deep reinforcement learning is a concept extended by the combination of intensive learning and deep learning.Focus more on the reinforcement learning,is still a decision to solve the problem,only when the environment is more and more complex,the decision function to make decisions and to implement more and more difficult.The depth of the neural network has a strong ability to fit,so the depth of the decision function using the neural network can be instead of,thus forming the depth of intensive study.As shown in Figure 2,reinforcement learning (RL) aims to enable agents to enhance their decision-making capabilities through environmental feedback during the process of interacting with the environment.In reinforcement learning,there are two basic elements:agent and environment,and two characteristics: trial and error mechanism and delayed reward.Due to the delayed reward mechanism,the agent takes actions in a trial and error manner at the beginning.And during the continuous interaction with the environment,the agent adapts its strategy according to the feedback received.To use reinforcement learning,the problem to be optimized is usually formulated as a markov decision process(MDP).As shown in Figure 3,the statestat timetof the environment is only related the statest−1at timet −1 and the actionat−1executed on the environment at timet −1.For the action taken by the agent at each time slot,the environment will feedback a corresponding reward.And the goal of the agent is to take actions to maximize the reward function.
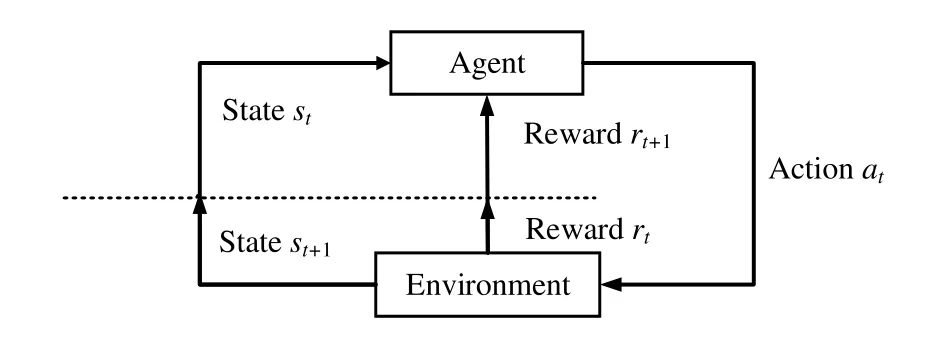
Figure 2.Structure of reinforcement learning.

Figure 3.The realization process of markov decision.
Specifically,at the given timet,the goal of the agent is to find an optimal policy that maximizes the discounted cumulative reward after the given time slot,which is defined as Eq(7).
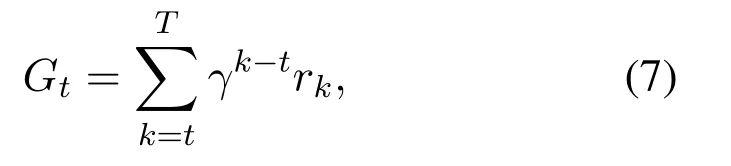
whereTis the length of the episode,rkis the reward obtained at timek,andγis the discount factor.As mentioned above,the agent considers the reward at the current time and the reward in the future.Compared with other methods,reinforcement learning can better solve the sequential decision optimization problem.With the high number of interactions with the environment,it is impossible for the agent to learn every single situation.Through the combination of reinforcement learning and neural networks,the DRL model is able to generalize for unseen situations,and the agent can give the right actions when the situations are similar to the experienced situations.
PPO is one of Policy Gradient(PG)methods,which is more suitable to the problems with continuous state and action space than value-based optimization methods.Furthermore,PPO uses importance sampling to make the samples reusable and limits the range of policy updates to solve the problem that the policy gradient methods are sensitive to the settings of their hyper parameters.For the problems with high-dimensional state and action space,the PPO algorithm can obtain good performance with ease of implementation and low sample complexity.
In PG methods,the policy gradient estimation is calculated,and then the parameters are updated according to the stochastic gradient ascent algorithm.PPO is essentially an actor-critic algorithm; its optimization objective should consider not only the policy but also the value function.What’s more,to ensure sufficient exploration,an entropy bonus should be added to objective function,as shown in Eq(8).
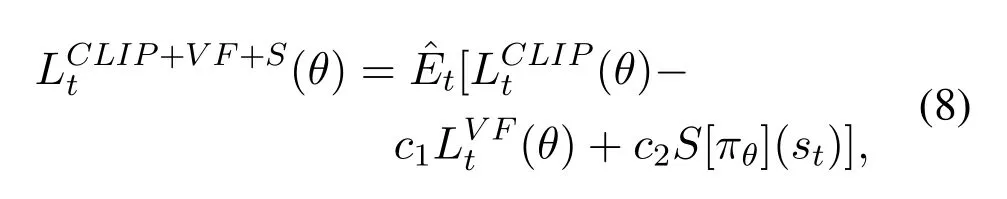
Firstly,PPO algorithm samples data from the interaction of the agent and the environment.Secondly,it uses stochastic gradient ascent to optimize the objective function and update the network parameterθ.Because of the restriction of the policy changes,the PPO algorithm reduces the possibility of obvious deterioration of strategy performance,making the system more stable and less volatile.
3.2 DRL Application
Figure 4 shows the DRL architecture for bandwidth and power allocation in V2V communication.There are V2I links dividing the spectrum into disjoint subbands and V2V links sharing limited bandwidth and power resources.According to the way of occupying spectrum resources by the V2V links,different transmission modes forms.Because the high speed the vehicles move,to collect accurate and complete CSI,the resource management of the V2I links and V2V links should be independent instead of being controlled by the central controller.
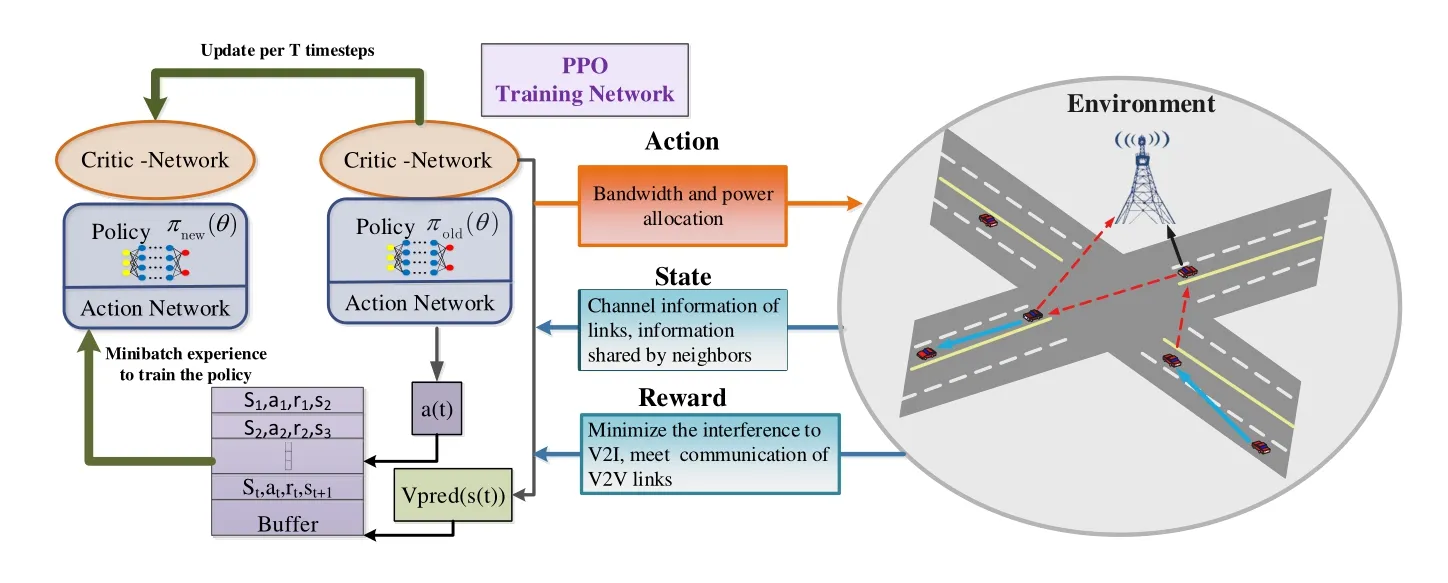
Figure 4.DRL Architecture for bandwidth and power allocation in the V2V communication.
In the cellular-based vehicle communication scenario,V2V links or vehicles are usually considered agents and the others in the scenario are environments.As proposed in Section II,the observable environmental state includes global channel conditions and all behaviours of the agent.
In each V2V link,there is six information to be observed: the interference power It-1= (It−1[1],It−1[2],···,It−1[M]) at timet −1,the instantaneous channel informationGt= (Gt[1],Gt[2],···,Gt[M])at timet,the channel information Ht=(Ht[1],Ht[2],···,Ht[M])at timet,the selected of sub-channel of neighbours Nt-1= (Nt−1[1],Nt−1[2],···,Nt−1[M])at timet −1,the remaining time to satisfy the latency constraintsUt,and the remaining load to transmitLt.Therefore the state for the V2V link can be defined as Eq(9).
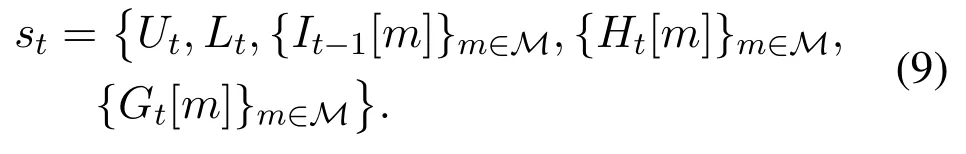
The resource shared in vehicular links are mainly bandwidth and power.In most existing literature about power allocation for V2V communication,the spectrum occupied by V2I links is split intoMdisjoint sub-bands and the transmission power in V2V links is discretized into several power levels.In this paper,the value of the transmission power is set to be continuous to achieve a continuous action space,which is more suitable for the real world.Therefore,the action at time is defined as Eq(10).
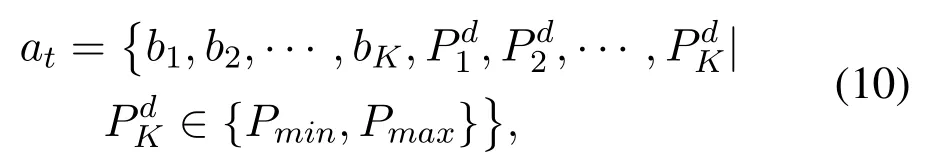
wherebn=mindicates thatm-thsub-band has been selected,PminandPmaxare the minimum and maximum transmission power respectively andPdkis the transmission power of thek-thV2V link.
The objective of the resource management for V2V communication is to maximize the system communication performance while satisfying the QoS constraints.Specifically,as mentioned in Section II,the objectives are to satisfy the latency constraints and the requested capacity in V2V communication and minimize the interference in V2I communication.Therefore,the reward at time is set as Eq(11).
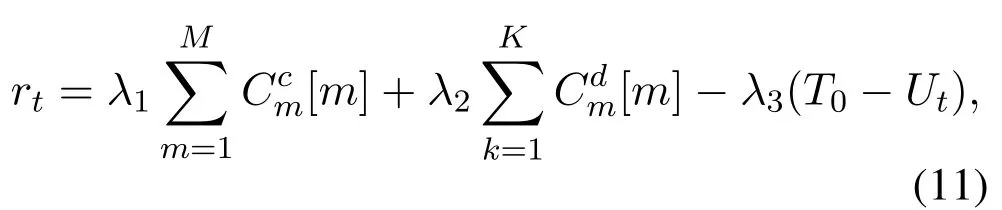

Table 1.Bandwidth and power allocation in V2V communication based on PPO algorithm.
IV.SIMULATION RESULT AND ANALYSIS
This section presents a simulation analysis by simulating real-world V2V communication scenarios and explaining and analyzing the simulated link’s performance.
4.1 Simulation Parameters
First,we design the simulation parameters related to the scene.As illustrated in Figure 1,we design a simulation scenario of a single block with a carrier frequency of 2 GHz.We have compiled the simulator with reference to the urban case assessment method in 3GPP TR 36.885,which describes vehicular channels,speeds,densities,V2V data traffic,the direction of movement,etc.In this paper,we comprehensively consider the large-scale fading and small-scale fading.Firstly,the fading of the channel is caused by the shadow fading and path loss caused by buildings and vehicles,and secondly,the rapid change of the wireless channel caused by the high-speed movement of vehicles in the vehicle-mounted communication sceneneeds to be considered.Specifically,the channels are divided into line-of-sight and non-line-of-sight channels,and vehicles are distributed according to spatial Poisson distribution.
The vehicle needs to determine whether it has arrived at the intersection during driving.If it reaches the intersection,the vehicle has a probability of 0.4 to change direction; if it does not arrive at the intersection,it will go in the original direction.Each street has four lanes distributed in the urban block scene,and the lanes are 3.5m wide.The model grid’s size is determined by the distance between the yellow lines,which is 433m*250m,and the area is 1299m*750m.The simulation is moderately scaled down to 1/2 of the original.The parameters summarized in Table 2 mainly refer to the V2X architecture discussed in 3GPP,and Table 3 describes the design of the relevant parameters of the V2I and V2V links.

Table 2.Simulation parameters.

Table 3.The channel models.
4.2 Simulation Result and Analysis
In order to evaluate the convergence performance of the proximal policy optimization algorithm,we show the reward per training episode as the number of training iterations increases in Figure 5.It can be found that after the training began,the reward rose rapidly,and as the training continued,the reward began to fluctuate slightly and converge to the maximum finally.The cause of communication network fluctuations is the channel fading,which is caused by high dynamics in V2V communication.Although the vehicle can learn the best strategy through the DRL algorithm,the overall environment of V2V communication in the different episode is different,which will lead to fluctuations in rewards.And the actions taken in the face of the same state are not necessarily the same,which leads to the difference between rewards.Figure 5 illustrates that the proximal policy strategy optimization method is suitable for dynamic resource allocation scenarios in the V2V communications network.
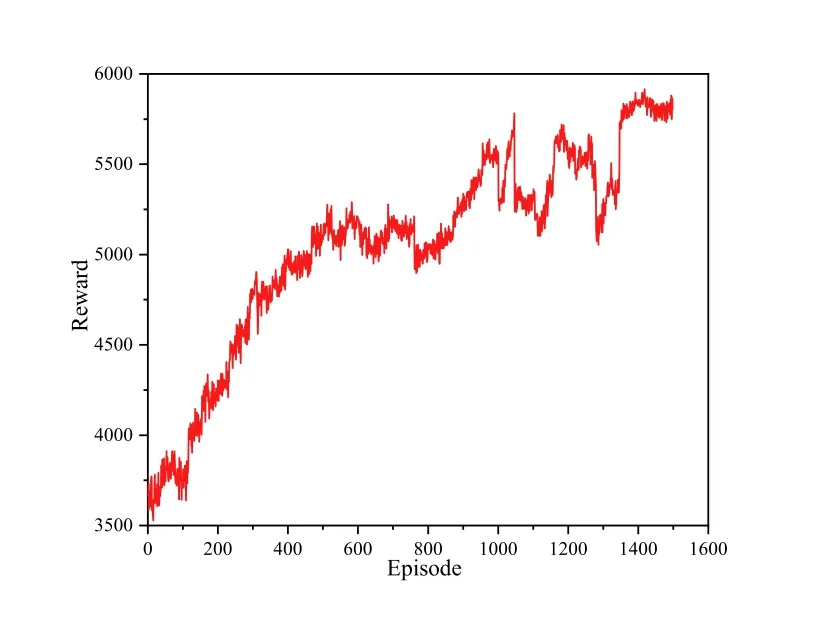
Figure 5.The training reward.
Besides,we studied the impact of different parameter choices of the proximal policy optimization algorithm on the overall performance.Figure 6 shows the different impact of the parameter gammaγ,which is a discount factor.If the discount factor is 0,only the current reward is considered,which means a short-sighted strategy,and strategy learning may end without reaching the expected goal.The larger the value ofγ,the more long-term future benefits we will take into the current behaviour’s value.Meanwhile,the simulation results indicate that if the value ofγis too large,the consideration is too long-term,even beyond the range that the current behaviour can influence.Figure 6 reveals that the discount factor in deep reinforcement learning needs to be designed according to the specific scenario.
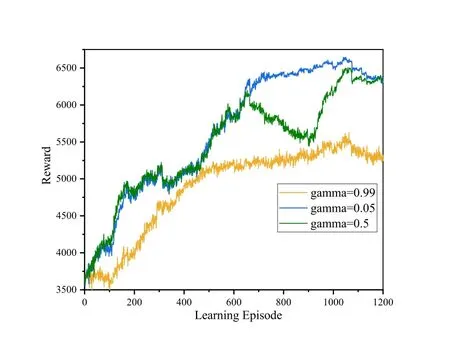
Figure 6.The convergence performance for different gamma.
This paper shows the sum throughput performance of V2I as the training time increases in Figure 7.Figure 7 depicts that after the training began,the total throughput of the V2I link rose rapidly.The extremely high dynamics of V2V communication scenarios lead to the uncertainty of observations,which makes the overall throughput performance fluctuate greatly when the training episode is 600.Continuously improve the allocation strategy based on past experience,and the sum throughput of the V2I link finally reaches the maximum.
Figure 8 shows the remaining payload of V2V communication transmission.Figure 8 illustrates that after the training starts,the remaining payload of the V2V link decreases rapidly,and when the episode of training is 1200,its value is close to 0.This indicates that the method we proposed can successfully transmit V2V link information within the time of delay constraint of V2V communication.
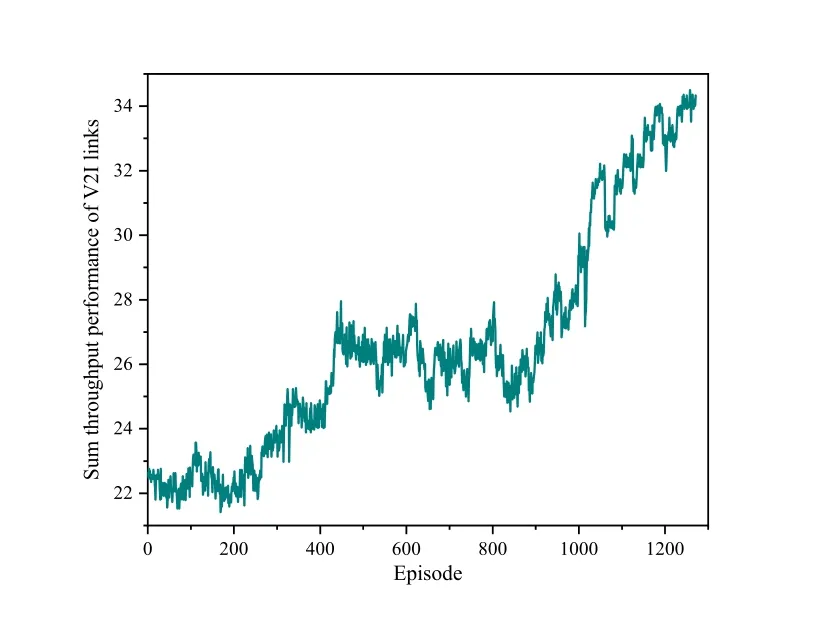
Figure 7.The total throughput of V2I links.
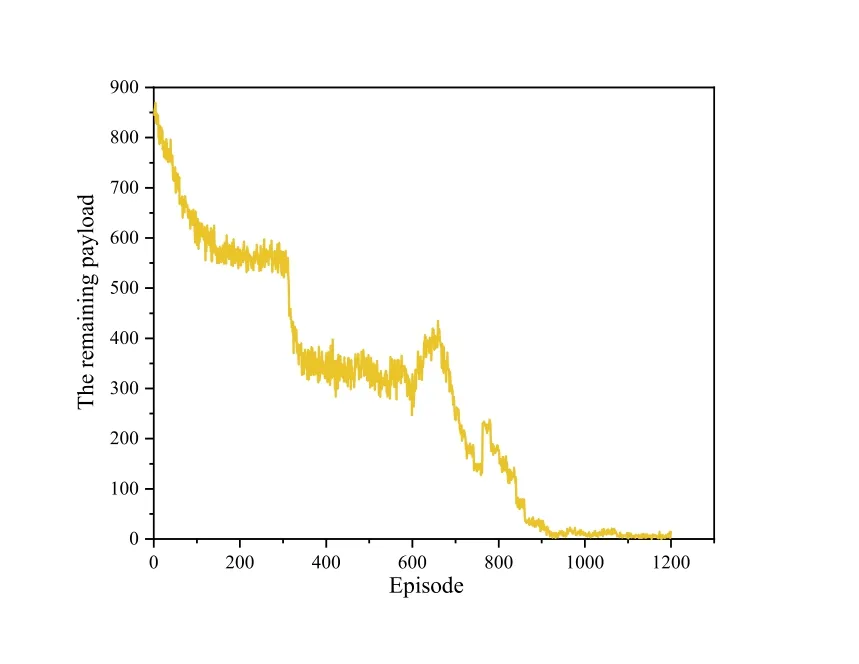
Figure 8.The remaining payload of the V2V communication transmission.
Figure 9 shows the probability that the V2V communication link is satisfied.The relationship between interruption probability and delay and reliability must ensure that the service quality of V2I and V2V links are kept at a small threshold even if the received SINR is maintained.It can be seen from the figure that the probability of satisfying the communication link increases rapidly and approaches 1 as the training time increases.This shows that the proximal policy strategy optimization method proposed in this paper is more robust stable in V2V communications.The probability of satisfying the communication link can converge to the maximum value within 1500 episodes.This reveals that the proximal policy optimization approach proposed in this paper is more robust and stable in the highly dynamic V2V network.
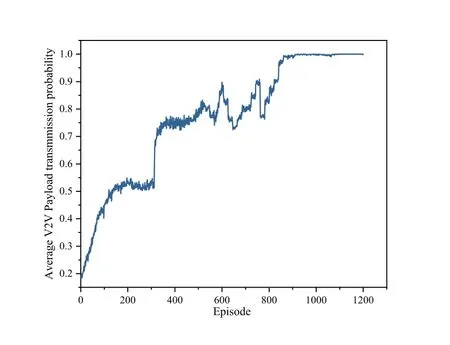
Figure 9.Probability of successful V2V transmission.
Figure 10 and Figure 11 show the effect of the vehicle speed on the convergence and the sum capacity of V2I links.From Figure 10,the convergence of the reward decreases as the vehicle speed increase.When the vehicle speed is low,the reward can quickly converge,and the convergence speed becomes slower and fluctuates obviously when the vehicle speed increases to 60km/h.When the moving speed of vehicles increases,the average distance between vehicles increases.Hence,the sparse demand distribution reduces the power received by the V2V link,resulting in a decrease in overall performance.
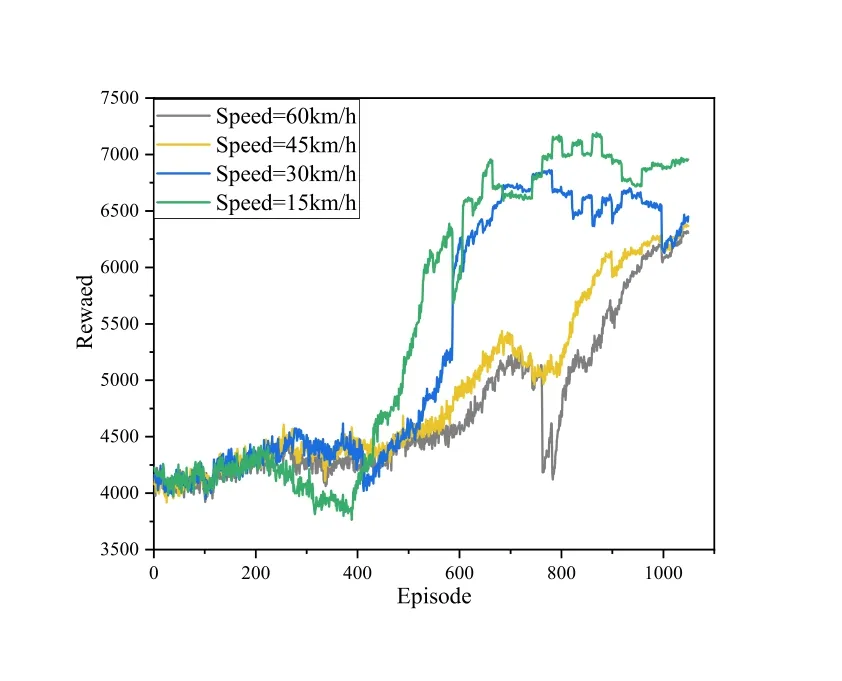
Figure 10.The convergence performance with varying vehicle speed.
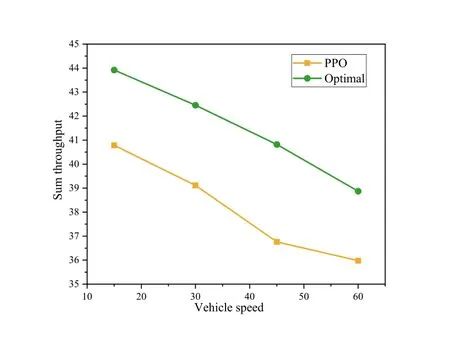
Figure 11.Sum throughput performance with varying vehicle speed.
This paper simulates the maximum V2I capacity of the proximal strategy optimization algorithm and the random algorithm at different speeds,as shown in Figure 11.By observing the changes of the total capacity of PPO algorithm and random algorithm V2I at different speeds,it can be found that the total capacity of PPO algorithm V2I is significantly higher than that of the random algorithm.In Figure 11,the sum throughput of V2I links reduces as the speed increase.This is because the increased speed increases the uncertainty of environmental observations in the V2V communication scene.
V.CONCLUSION
This paper studied radio resource allocation in V2V communication systems and proposed a novel radio resources allocation mechanism for V2V communications based on the proximal strategy optimization method.Our proposed models can output continuous actions and multi-dimensional actions by taking advantage of the proximal strategy optimization method.It greatly reduces the implementation complexity of large-scale communication scenarios.The simulation results show that the proposed allocation method can meet the latency constraints and the requested capacity on V2V links while minimizing the interference to vehicle-to-infrastructure communications.

- China Communications的其它文章
- Joint Topology Construction and Power Adjustment for UAV Networks: A Deep Reinforcement Learning Based Approach
- V2I Based Environment Perception for Autonomous Vehicles at Intersections
- Machine Learning-Based Radio Access Technology Selection in the Internet of Moving Things
- CSI Intelligent Feedback for Massive MIMO Systems in V2I Scenarios
- Better Platooning toward Autonomous Driving: Inter-Vehicle Communications with Directional Antenna
- Reinforcement Learning Based Dynamic Spectrum Access in Cognitive Internet of Vehicles