
Reinforcement Learning Based Dynamic Spectrum Access in Cognitive Internet of Vehicles
2021-07-14 09:06XinLiuCanSunMuZhouBinLinYutoLim
China Communications 2021年7期
Xin Liu,Can Sun,Mu Zhou,Bin Lin,Yuto Lim
1 School of Information and Communication Engineering,Dalian University of Technology,Dalian 116024,China
2 State Key Laboratory of Integrated Services Networks,Xidian University,Xi’an 710071,China
3 Chongqing Key Lab of Mobile Communications Technology,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
4 Department of Communication Engineering,Institute of Information Science Technology,Dalian Maritime University,Dalian 116026,China
5 School of Information Science,Japan Advanced Institute of Science and Technology,Ishikawa 923-1292,Japan
Abstract: Cognitive Internet of Vehicles(CIoV)can improve spectrum utilization by accessing the spectrum licensed to primary user(PU)under the premise of not disturbing the PU’s transmissions.However,the traditional static spectrum access makes the CIoV unable to adapt to the various spectrum environments.In this paper,a reinforcement learning based dynamic spectrum access scheme is proposed to improve the transmission performance of the CIoV in the licensed spectrum,and avoid causing harmful interference to the PU.The frame structure of the CIoV is separated into sensing period and access period,whereby the CIoV can optimize the transmission parameters in the access period according to the spectrum decisions in the sensing period.Considering both detection probability and false alarm probability,a Q-learning based spectrum access algorithm is proposed for the CIoV to intelligently select the optimal channel,bandwidth and transmit power under the dynamic spectrum states and various spectrum sensing performance.The simulations have shown that compared with the traditional non-learning spectrum access algorithm,the proposed Q-learning algorithm can effectively improve the spectral efficiency and throughput of the CIoV as well as decrease the interference power to the PU.
Keywords: cognitive Internet of vehicles; reinforcement learning; dynamic spectrum access; Q-learning;spectral efficiency
I.INTRODUCTION
Internet of Vehicles (IoV),integrating computing,communications and storage functions,has been proposed to provide safe and reliable transportations[1].The IoV can share the driving information and control the driving command by allowing vehicle navigation system,mobile communication system,intelligent terminal equipment and information platform to conduct real-time data interactions between vehicle users (VUs),roadside units (RUs) and base stations(BSs) [2].Hence,IoV as a complex heterogeneous wireless network can achieve the intelligent communications between vehicles and provide the VUs with secure dynamic network services[3].However,with the rapid development of IoV services,the vehicle communication demands are also growing explosively.Especially in the case of heavy traffic flow or congestion,the VUs frequently compete for the limited spectrum resources,which will lead to serious spectrum access delay and packet loss rate.Therefore,the timely and reliable transmission requirements of the IoV services cannot be met currently [4,5].Accordingly,how to guarantee the bandwidth requirements of information transmissions from both VUs to VUs and VUs to RUs in the case of high-speed mobility has become an important challenge for the IoV communications[6].
Recently,cognitive radio (CR) has been developed to improve spectrum utilization by opportunistically using the spectrum authorized to primary user (PU)through detecting the spectrum state of the PU[7,8].Based on CR,cognitive IoV (CIoV) can occupy the idle licensed spectrum by spectrum overlay or access the busy licensed spectrum with the limited interference power to the PU by spectrum underlay.Therefore,the CIoV can solve the shortage of spectrum resources in the IoV communications effectively[9,10].Since,the spectrum state of the PU changes dynamically,the spectrum access of the CIoV must change with the PU to avoid interfering with the normal communications of the PU[11].In addition,the spectrum access of the CIoV is decided by the spectrum sensing results on the PU.And miss detection or false alarm detection will decrease the spectrum access opportunities of the CIoV[12].Therefore,the dynamic spectrum access of the CIoV must be investigated to adapt to the various spectrum states and sensing results for the PU.It should improve the spectral efficiency of the CIoV and suppress the interference power to the PU under the different sensing performance.
In such a dynamic spectrum access scheme,two fundamental problems should be considered:
• How to model the spectrum access of the CIoV under the different spectrum states and spectrum sensing results of the PU?
• How to obtain the optimal spectrum access strategy under the various spectrum states of the PU?
To solve these two problems,a reinforcement learning (RL) based dynamic spectrum access scheme is proposed to improve the spectrum access performance of the CIoV under the long-term spectrum changes,by considering both spectrum access reward and interference cost under different spectrum sensing results.The main contributions of the paper can be summarized as follows:
• A CIoV model is presented to share the spectrum with the PUs by both the spectrum underlay and spectrum overlay modes,providing that the communications of the PUs are not disturbed.The frame structure of the CIoV is proposed to perform spectrum sensing and spectrum access periodically,which can avoid bringing harmful interference to the PUs.
• A Q-learning based spectrum access algorithm is presented for the CIoV,which can make the VUs intelligently select the optimal channel,bandwidth and transmit power according to the dynamic changes of the PU’s spectrum states.
• Both the detection probability and false alarm probability are considered in the reward functions,which can realize the optimal strategy selection under the various spectrum sensing performance for the PU.Therefore,the spectrum access performance under the error sensing results can be guaranteed.
II.RELATED WORK
A CIoV using idle TV spectrum was proposed in[13],whose throughput was optimized via route selection.Considering the channel path loss,a hybrid spectrum access strategy for the CIoV was presented in [14],where the VU adaptively selected different spectrum access methods based on the energy and location information.In[15],given priority to the PU’s services,a spectrum access algorithm based on semi-Markov decision was provided to cope with the channel resource shortage in cognitive vehicular ad-hoc networks.A competitive spectrum access scheme based on game theory was proposed in [16],which could make full use of the spectrum resources by designing a delayed pricing mechanism to achieve the Nash equilibrium.The channel allocation for multi-channel CIoV was presented in[17],which tried to maximize the system throughput under the spatial-temporal changes of the licensed spectrum.In [18],a cluster-based spectrum access scheme was considered to provide enough quality of service (QoS) for the CIoV communications,which was optimized to maximize the channel utility of the VUs while their QoS requirements were met.Most of the existing works focus on the resource allocation for the spectrum access of the CIoV and ignore the impact of spectrum sensing results on the spectrum access performance.It has been indicated that the spectrum access strategy should be adjusted according to the sensing results in order to guarantee the transmission performance of the CIoV under the interference constraint to the PU.In this paper,we divide the frame structure of the CIoV into sensing period and access period.The spectrum access strategy in the access period is optimized according to the spectrum decisions in the sensing period,which may guarantee the spectrum access performance of the CIoV under the various spectrum sensing results.
Recently,RL has been adopted for dynamic spectrum access due to its ability to adapt to the various spectrum environments.By RL,the current spectrum access decision will be made by both the current spectrum state and the learning experiences from the past spectrum access results.Therefore,the optimal channel selection can be achieved by RL to significantly improve the transmission performance of communication systems [19,20].Q-learning as one of the classical RL algorithms can select the optimal action by updating a simple Q-function [21].In [22],a Qlearning based dynamic spectrum access scheme was proposed to realize cognitive spectrum management,which could provide better QoS and higher network throughput.In [23],a Q-learning scheme for unlicensed spectrum access was presented to obtain fair spectrum coexistence under the dynamic changes of wireless environment.Deep RL was proposed to learn a spectrum access strategy with low transmission collision and high spectrum utilization in [24],and the CIoV with deep RL could utilize multiple channels in different spectrum environments.The authors in[25]modeled the spectrum access of vehicular networks as a multi-agent RL problem,which could simultaneously improve the total throughput and payload delivery rate of vehicle-to-vehicle (V2V) links.Accordingly,RL based dynamic spectrum access can select the optimal channels by the spectral learning experiences and thus improve the spectrum access performance effectively under the various spectrum environments.In this paper,Q-learning based dynamic spectrum access is proposed to improve the spectral efficiency of the CIoV and decrease the interference to the PU under the various spectrum environments,by selecting the optimal channel,bandwidth and transmit power.
III.SYSTEM MODEL
The CIoV model is shown Figure 1,which is constitute ofMchannels andNVUs.We assume that each channel is occupied by one PU,and each PU occupies the channel according to a Markov decision process.In the CIoV,the VUs can share the spectrum with the PU,providing that the communications of the PU are not disturbed.When the PU does not occupy the channel,the VUs can use the maximum transmit power for communications in the PU’s channel.However,if the channel is being occupied by the PU,the transmit power of the VUs needs to be limited to avoid causing harmful interference to the PU [26].We assume that each VU selects only one channel for communications in a time slot.By adopting orthogonal frequency division multiplexing(OFDM),each channel is divided into some subcarriers,and each VU transmits data using several subcarriers in one channel.
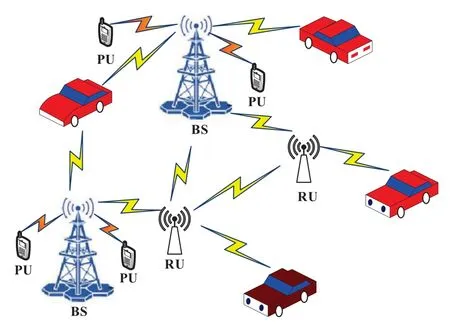
Figure 1.CIoV modle.
To achieve available channels,spectrum sensing process is performed before transmissions,where the detection probabilityPdand false alarm probabilityPfcan be achieved by each VU.Energy detection is commonly used to sense the spectrum state,which can get an accurate spectrum decision with less complexity.In the energy detection,if the detected energy value of the received signal is below the detection threshold,the idle channel will be decided,otherwise,the busy channel will be determined.PdandPfof energy detection can be calculated as follows[27]
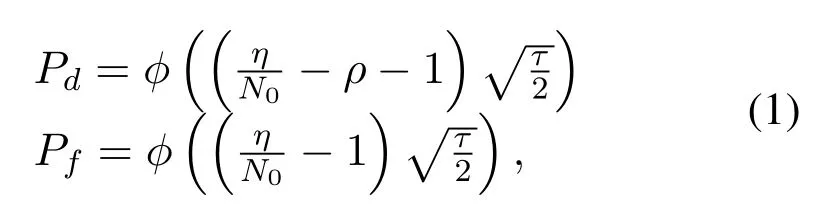
whereηis the detection threshold,ρis the received signal to noise ratio(SNR),N0is the noise power,andτis the number of sampling nodes;the functionφ(x)is described as follows
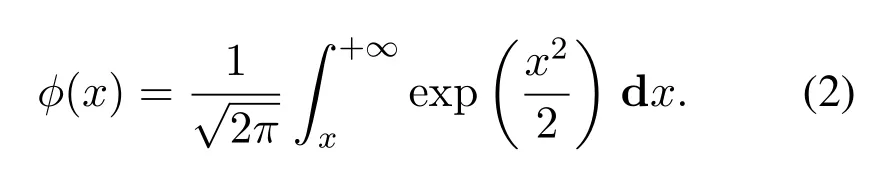
Besides,the subcarrier saturation of each channel can also be obtained.The subcarrier saturation of channelmis denoted asDmas follows

whereq1mis the number of occupied subcarriers in channelm,andq2mis the total number of subcarriers.Dm=1 means that all the subcarriers are occupied by the VUs and no additional subcarriers are available for the other VUs.
Note that each VU obtains the spectrum information via either BSs or RUs,as shown in Figure 1.There is a public channel in the CIoV for the VUs to exchange the spectrum sensing information,which enables the relevant spectrum information to be updated and achieved by each VU in a timely manner.According to the obtained spectrum information,the VUs make reasonable choices and access to the selected channels for communications.
The frame structure of the CIoV is shown in Figure 2.We assume that there areKtime slots during one communication process,each of which contains sensing period and access period.In the time slott,the VUntakes time ofTsto sense the spectrum state in the sensing period,and selectsqtnsubcarriers to transmit with the power ofPtnin the access period.It should be noted that the priority of each VU is different.The low-priority VUs make the spectrum access decisions after the high-priority VUs,which need to sense the spectrum occupancies of both the PUs and high-priority VUs.The priority information can be known by each VU through the public channel.Assuming the time of each slot isTfand there areknVUs with higher priority than the VUn,it takes time of(kn+1)Tsfor the VUnto sense the spectrum and time ofTf −(kn+1)Tsfor the VUnto transmit in the access period.Besides,the reward valueRfrom the spectrum environment andQvalue for the Q-learning algorithm will be updated in the access period.
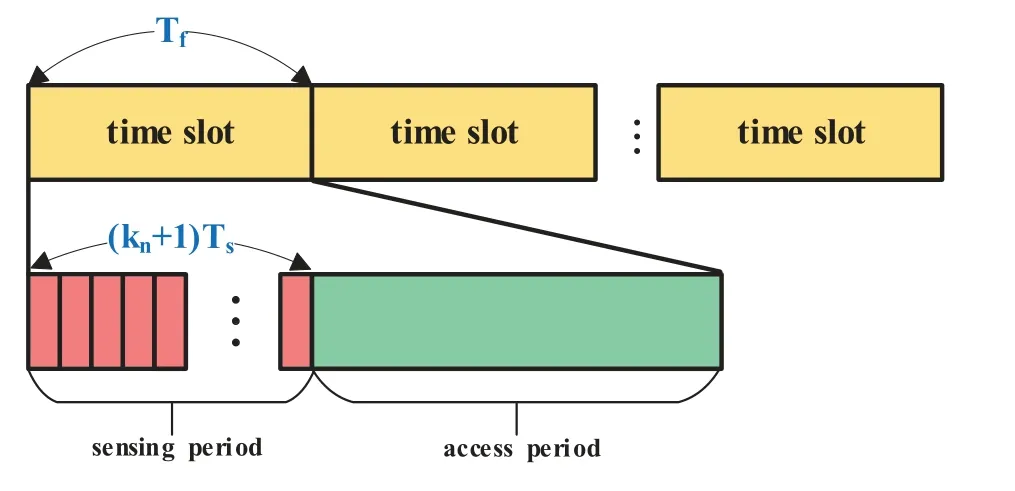
Figure 2.Frame structure of CIoV.
IV.REINFORCEMENT LEARNING BASED DYNAMIC SPECTRUM ACCESS
4.1 Reinforcement Learning
As one of the classical machine learning methods,RL is used to gain the future long-term benefits,which makes the agents learn strategies to maximize returns or achieve specific goals in the process of interacting with the environment[28].In the RL,the agent interacts with the environment to record the rewards of different actions in different states.The recorded rewards will be used to guide the future action selections of the agents.After enough learning experiences,the agent can choose the most profitable action for one specific state.The RL includes four important elements: environment,state,action and reward [29].We use S and A to represent state set and action set,respectively.When the agent is taking an actionain the states,it will get rewardR(s,a)from the environment.And a higherR(s,a) corresponds to a better actiona.The RL can be seen as a trial-and-error searching process,where the agent needs not only to choose the actions with high rewards based on the past learning experiences but also try new actions that may have higher rewards.Therefore,there is a tradeoff between exploration and utilization.The agent should consider both the immediate reward and the cumulative discounted reward in the long-term learning process.Based on the Bellman equation,there exists an optimal action selection strategyπ∗to obtain the optimal reward under the states.Then the expectation of the cumulative discounted reward corresponding to the optimal strategy,v(s,π∗),can be expressed as
whereγis the discount factor,p(s′|s,a)is the probability of the statesgoing to the states′under the actiona.
Q-learning as one of the RL algorithms adopts the action functionQ(s,a) to represent the cumulative discounted reward with the actionaunder the states.The rewardR(s,a) from the environment is used to updateQ(s,a),which is then used to guide future action selections.The update ofQ(s,a) is derived based on the Markov Decision Process(MDP).Since the spectrum occupy of the PU can be regard as MDP,it is suitable to use Q-learning to solve the spectrum access problem of the CIoV.With the actionaunder the policyπ,the cumulative discounted reward beginning with the statesis denoted by
where the optimal policyπ∗can be obtained byv(s,π∗)=maxa∈AQ∗(s,a).
Q(s,a)as the estimation ofQ∗(s,a)can gradually converge toQ∗(s,a) by usingR(s,a) to update its value.The update process ofQ(s,a) is given as follows
whereα ∈[0,1]is the learning rate,which decreases gradually with the learning process.WhenQ(s,a) converges,we can get the optimal strategy for the action selection in any given state,i.e.,v(s,π∗)=maxa∈AQ(s,a).
4.2 Q-learning Based Spectrum Access for CIoV
Based on the transmission frame structure in Figure 2,we propose a Q-learning based dynamic spectrum access scheme to reasonably allocate the spectrum resources for the CIoV.We assume each VU can acquire the state ofMchannels through spectrum sensing in each time slot.The spectrum state obtained by VUnin time slottis represented by Sn,t=where the vectorrepresents the state of channelmsensed by VUnin time slott.The state of channelmin time slottcan be denoted aswhere0,1}represents whether the channelmis occupied by the PU(i.e.= 0 means that the channelmis idle and= 1 means that the channelmis busy) andrepresents the subcarrier saturation of channelm.If= 0,the VUncan access the channelmregardless of the interference to the PU.While ifsm,1n,t= 1,the spectrum sharing access should be adopted by the VUnto use the channelm.can be calculated by Eq.(3).For example,= [1,0.6]means that channelmis in busy state and 60% of the subcarriers in the channel have been used by some VUs.
The action vector of VUnin time slottis represented by An,t,An,t ∈A.An,tcan be denoted aswhere1,2,...,m,...,M}indicates the channel selected by VUnfor communications,denotes the number of the subcarriers used by VUn,andindicates the transmit power selected by VUnaccording to the communication performance of the PU in different spectrum access modes.In addition,the actual number of subcarriers assigned to VUnis equal toor the number of remaining subcarriers in channel,.For example,An,t=[2,8,0.1]means that VUnchooses 8 subcarriers in channel 2 for communications with the transmit power of 0.1W.
After VUnsuccessfully accesses to the channelmand completes its communication in one time slot,the rewardRnis obtained,which is related to both the sensing result and real state of the PU.When the presence of the PU is detected,there are two spectrum access cases for the VU
• If the PU actually exists in channelmand VUnhas sensed the presence of the PU under the detection probability ofPd,VUnwill access the channel by limiting its interference power to the PU.The reward valuer1tin this case is given by
whereis the bandwidth of channelmoccupied by VUn,hmis the channel gain for VU,nm0is the power spectral density of the background noise,nmsis the power spectral density of the PU,gmis the channel gain between the PU and VU,Ttn=Tf −(kn+1)Tsis the communication time of VUnin time slott,σis the price regulator,Cmnis the unit bandwidth price of VUnusing channelm,andλPtn|gm|2is the interference penalty item.
• If the PU actually does not exist in channelmbut VUnhas detected the presence of the PU under the false alarm probability ofPf,VUnwill access the channel with error detection,resulting in the decrease of its transmission rate.The reward valuer2tin this case is given by
whereis the error detection penalty item,coming from the error detection result of the receiver.
When the PU is detected to be absent,there are also two spectrum access cases for the VU
• If the PU actually exists in channelmbut VUnhas detected the absence of the PU under the missed detection probability of 1−Pd,VUnwill access the channel with error detection and cause harmful interference to the PU.The reward valuer3tin this case is given by
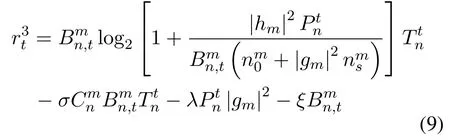
• If the PU is actually absent in channelmand VUnhas detected the absence of the PU under the probability of 1−Pf,VUnwill access the channel without limiting its transmit power and thus gain high transmission performance.The reward valuer4tin this case is given by
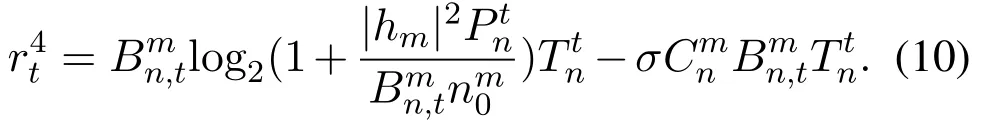
Assuming that the subcarrier bandwidth of channelmisBm,we haveWe also assume that the higher the subcarrier saturationDtmis,the higherCmnfor the channel will be.And the presence of the PU(= 1) also increasesCmn.Therefore,Cmnis calculated by
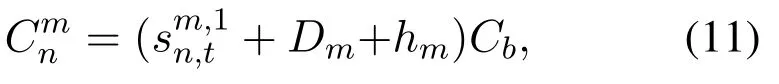
whereCbis the basic bandwidth price.
For the interference penalty item,when PU does exist,VUnneeds to control its transmit powerPtn.Because the biggerPtnis,the greater the interference to PU will be,resulting in a smaller reward value.For the error detection penalty item,if the receiver judges the presence of the PU when the PU does not actually exist,the wrong sensing result may lead to wrong decision,thus reducing the reward value.In addition,the larger the bandwidth used by the VU,the greater the impact on the reward value will be.Meanwhile,if the receiver judges the absence of the PU when the PU actually exists,the wrong sensing result also leads to a smaller reward value.Accordingly,when the PU is detected to be exist,the average reward valueRenis calculated as follows
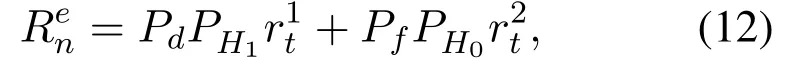
wherePH1is the actual presence probability of the PU,PH0= 1−PH1is the actual absence probability of the PU.When PU is detected to be absent,the average reward valueRinis calculated as follows
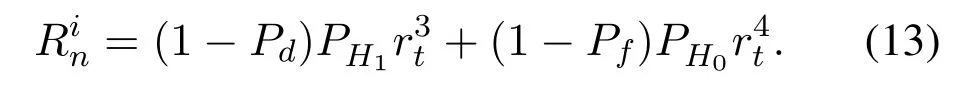
As a result,the total reward value for VUnin time slottcan be expressed as follows
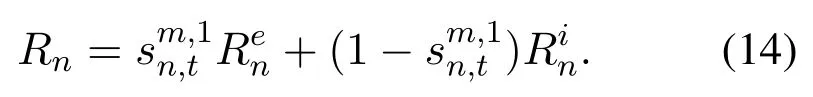
A Q-learning based spectrum access algorithm is proposed to improve the transmission performance of the CIoV under the dynamic spectrum states and various spectrum sensing performance.The proposed spectrum access algorithm is shown in Algorithm 1.
V.SIMULATION AND DISCUSSIONS
The number of subcarriers used by the VU is0,8,16,32,64},where= 0 means that VU decides to access no channel.The transmit power of VUnin time slottis0.1,0.3,0.5,0.7,0.9}W.The values of the other parameters are summarized in Table 1.At the beginning of each time slot,the PU selects to occupy its spectrum with a probability of 50%(PH1= 0.5).We conduct 100 simulation experiments and get the average results.

Algorithm 1.Q-learning based spectrum access algorithm.1: initial Qn(S,A)for each n ∈N 2: for t=1:K do 3: determine the priority of VUs 4: for n ∈N do 5: perform spectrum sensing and get the sensing result Sn,t =[S1n,t,S2n,t,...,Smn,t,...,SMn,t]6: end for 7: for n ∈N do 8: determine the bandwidth Bmn,t for the VU n 9: use some spectrum access policy to access the channel according to An,t =[a1n,t,a2n,t,a3n,t]10: obtain Rn according to Eq.(14)11: end for 12: for n ∈N do 13: perform spectrum sensing and get the sensing result Sn,t+1 = [S1n,t+1,S2n,t+1,...,SMn,t+1]as the next state 14: update Qn(Sn,t,An,t)15: An,t+1 =argmaxAi∈A(Qn(Sn,t+1,Ai))16: end for 17: end for
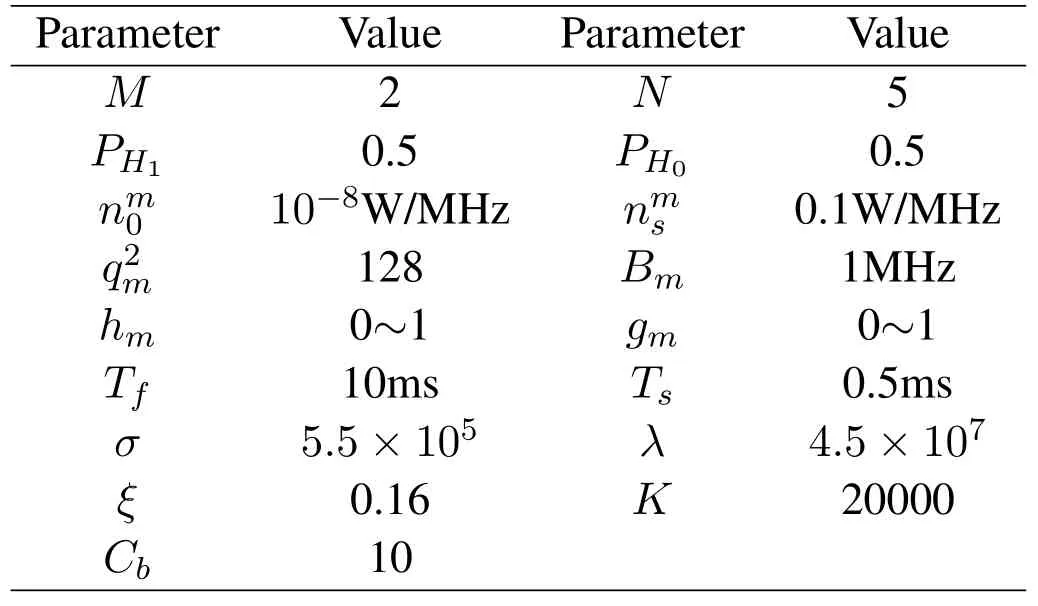
Table 1.Parameter values.
A traditional non-learning spectrum access algorithm is introduced to make a comparison with the proposed Q-learning based spectrum access algorithm.In the non-learning algorithm,each VU also senses the spectrum but selects an idle channel for communications randomly.Meanwhile,there are two cases for the spectrum access of the VU: to access half of the subcarriers in a channel if more than half of the subcarriers are idle,and to access 10%of the subcarriers when less than half of the subcarriers are idle.The transmit power of each VU is either a high value at the absence of the PU or a low value at the presence of the PU.The performance of the Q-learning algorithm is compared with that of the non-learning algorithm as shown in Figure 3,Figure 4,Figure 5 and Figure 6,respectively,where the detection probability isPd=1 and the false alarm probability isPf=0.
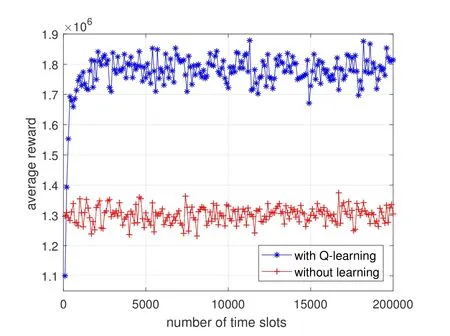
Figure 3.The average rewards comparison between the two algorithms.
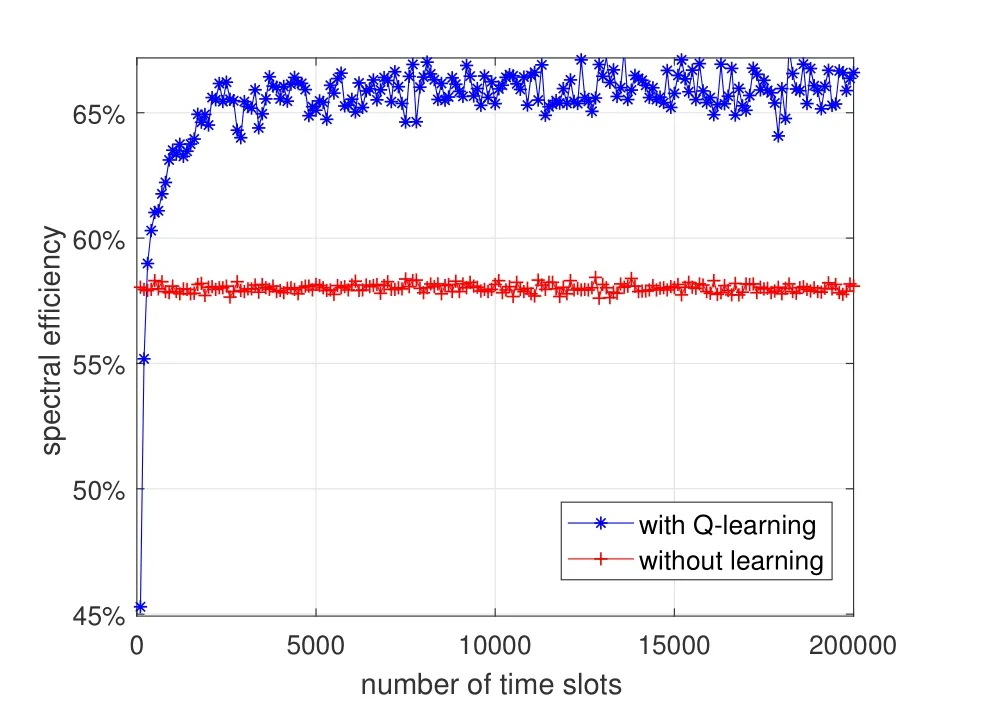
Figure 4.The spectral efficiency comparison between the two algorithms.
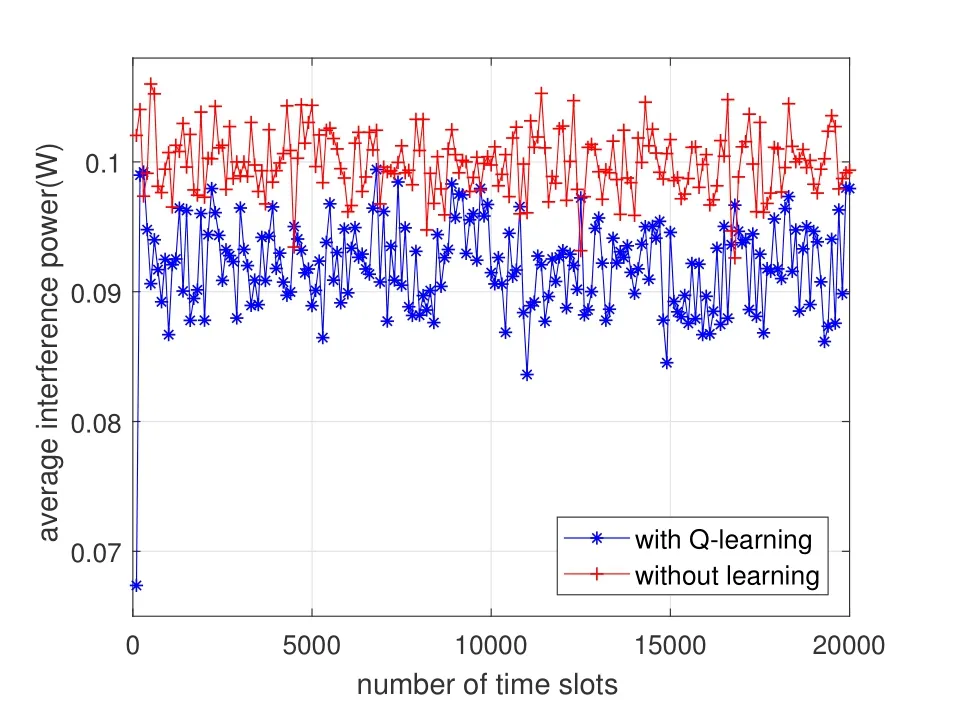
Figure 5.The average interference power comparison between the two algorithms.
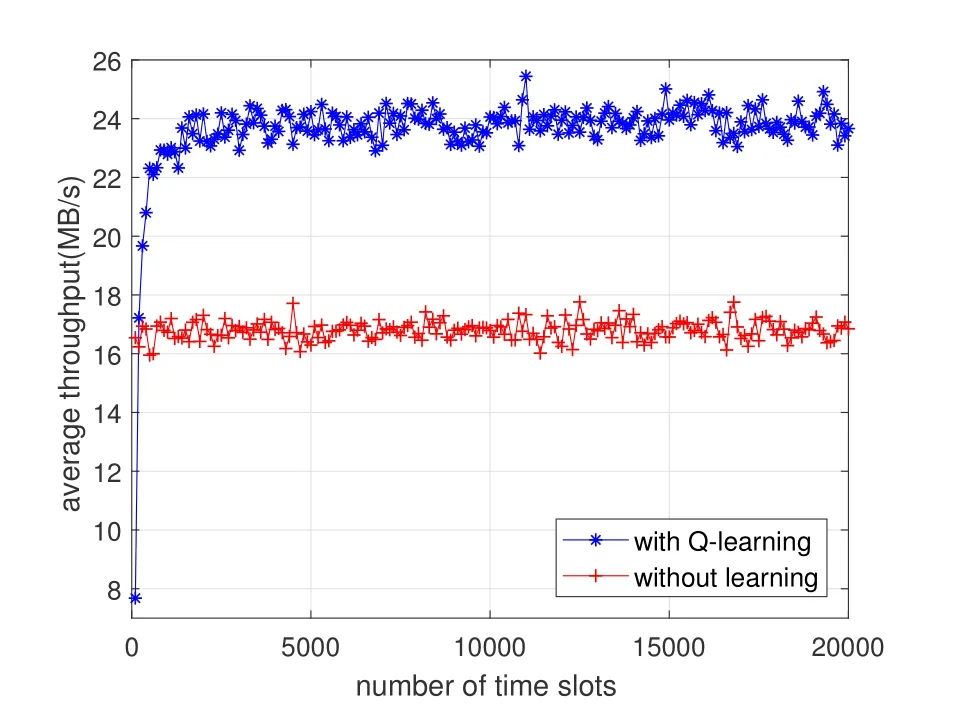
Figure 6.The average throughput comparison between the two algorithms.
Figure 3 compares the average reward of the CIoV between the proposed Q-learning algorithm and the traditional non-learning algorithm.It can be seen that the average reward of CIoV in the Q-learning algorithm increases gradually and then converges as the time goes on.Since the Q-learning algorithm can make the VUs achieve more reasonable spectrum access decisions,the average reward of the Q-learning algorithm is higher than that of the non-learning algorithm when the algorithm converges.Figure 4 compares the spectral efficiency of the CIoV between the two algorithms.It indicates that the spectral efficiency of the CIoV in the Q-learning algorithm is higher than that in the non-learning algorithm when the algorithm converges.Because the Q-learning algorithm can make the VUs select more idle subcarriers to achieve larger bandwidth.However,in the nonlearning algorithm,some VUs may select the same channel due to the random channel selections,resulting in the decrease of the spectral efficiency.Figure 5 compares the average interference power to the PU between the two algorithms.It shows that the average interference power of the CIoV in the Q-learning algorithm is lower when the algorithm converges.Because the Q-learning algorithm can make the VUs get reasonable transmit power according to the spectrum state of the PU,but the transmit power of the VUs in the non-learning algorithm is fixed regardless of the spectrum state.Figure 6 compares the average throughput of the CIoV between the two algorithms.By the Qlearning algorithm,the VUs can learn to select reasonable channel,bandwidth and transmit power for communications,thus getting larger average throughput compared with the non-learning algorithm.
The performance of the Q-learning algorithm is affected by the detection probabilityPdand the false alarm probabilityPf,which is shown in Figure 7,Figure 8 and Figure 9,respectively.
Figure 7 shows the average reward by the Qlearning algorithm with differentPdandPf.It is seen that with the increase ofPdand the decrease ofPf,the VUs can achieve higher average reward due to the improved spectrum sensing performance.Figure 8 shows the average throughput by the Q-learning algorithm with differentPdandPf.It shows that the average throughput of the CIoV decreases asPdandPfincrease.On the one hand,whenPdincreases,the VU will detect the presence of the PU with higher probability,and thus limit both its transmit power and bandwidth to avoid disturbing the PU.On the other hand,asPfincreases,the error detection penalty item becomes more apparent,which may reduce the reward and result in the decrease of the the average throughput of the CIoV.Figure 9 illustrates the spectrum access performance by the Q-learning algorithm with differentPd.When the presence of the PU is detected,the bandwidth price for the VU will be increased to guarantee the transmit bandwidth of the PU and the transmit power of the VU will be controlled to avoid causing harmful interference to the PU.As a result,both the spectral efficiency and average interference power reduce asPdincreases.
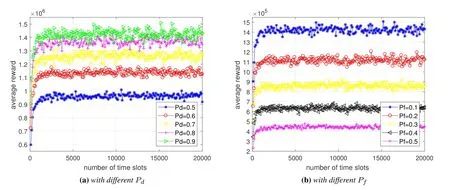
Figure 7.The average reward by the Q-learning algorithm.
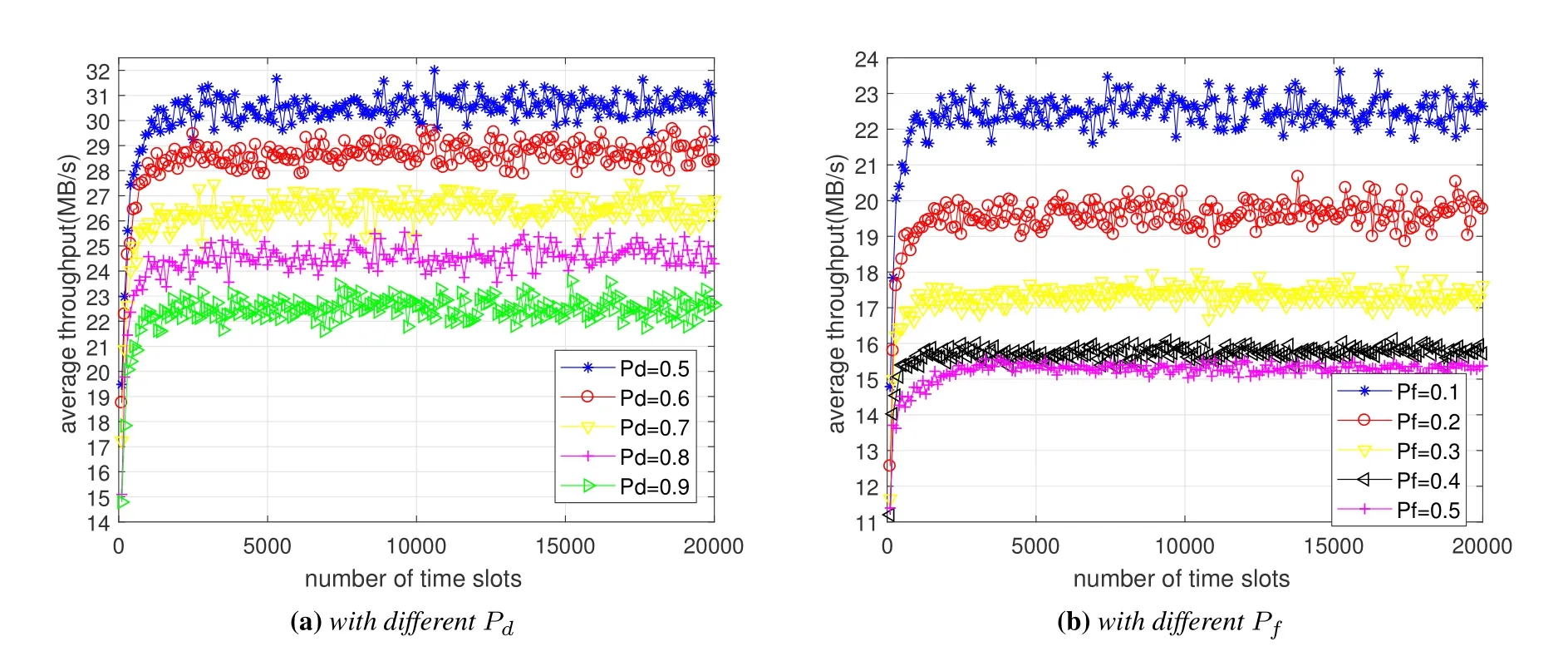
Figure 8.The average throughput by the Q-learning algorithm.
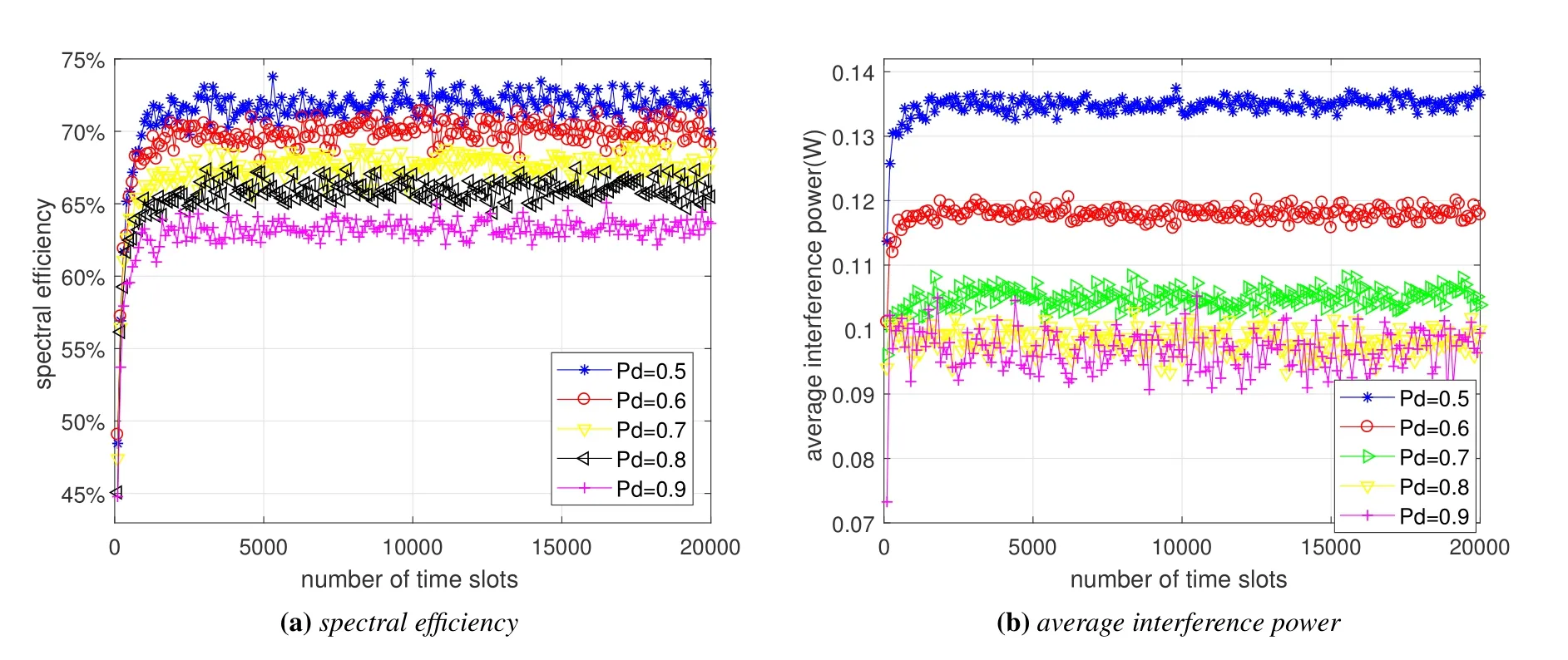
Figure 9.The spectrum access performance by the Q-learning algorithm with different Pd.
VI.CONCLUSIONS
In this paper,a Q-learning based dynamic spectrum access algorithm is proposed to improve the transmission performance of the CIoV in the licensed spectrum under the interference constraint to the PU.The frame structure of the CIoV is divided into sensing period and access period.Considering both detection probability and false alarm probability in the sensing period,the Q-learning reward under the different spectrum states and sensing decisions is formulated.In the simulations,it has been shown that the Q-learning based dynamic spectrum access algorithm outperforms the traditional non-learning algorithm in terms of improving spectrum efficiency and throughput of the CIoV as well as reducing the interference to the PU.In addition,the spectrum access performance of the CIoV can be improved obviously via enhancing spectrum sensing accuracy.
ACKNOWLEDGEMENT
This work was supported by the Joint Foundations of the National Natural Science Foundations of China and the Civil Aviation of China under Grant U1833102,the Natural Science Foundation of Liaoning Province under Grants 2020-HYLH-13 and 2019-ZD-0014,the fundamental research funds for the central universities under Grant DUT21JC20,and the Engineering Research Center of Mobile Communications,Ministry of Education.

- China Communications的其它文章
- Joint Topology Construction and Power Adjustment for UAV Networks: A Deep Reinforcement Learning Based Approach
- V2I Based Environment Perception for Autonomous Vehicles at Intersections
- Machine Learning-Based Radio Access Technology Selection in the Internet of Moving Things
- A Joint Power and Bandwidth Allocation Method Based on Deep Reinforcement Learning for V2V Communications in 5G
- CSI Intelligent Feedback for Massive MIMO Systems in V2I Scenarios
- Better Platooning toward Autonomous Driving: Inter-Vehicle Communications with Directional Antenna