
A Federated Bidirectional Connection Broad Learning Scheme for Secure Data Sharing in Internet of Vehicles
2021-07-14 09:07XiaomingYuanJiahuiChenNingZhangXiaojieFangDidiLiu
China Communications 2021年7期
Xiaoming Yuan,Jiahui Chen,Ning Zhang,Xiaojie Fang,Didi Liu
1 Qinhuangdao Branch Campus,Northeastern University,Qinhuangdao 066004,China
2 Department of Electrical and Computer Engineering,University of Windsor,Windsor,ON N9B 3P4,Canada
3 Department of Electronics and Information Engineering,Harbin Institute of Technology,Harbin 150006,China
4 College of Electronic Engineering,Guangxi Normal University,Guilin 541004,China
Abstract: Data sharing in Internet of Vehicles(IoV)makes it possible to provide personalized services for users by service providers in Intelligent Transportation Systems(ITS).As IoV is a multi-user mobile scenario,the reliability and efficiency of data sharing need to be further enhanced.Federated learning allows the server to exchange parameters without obtaining private data from clients so that the privacy is protected.Broad learning system is a novel artificial intelligence technology that can improve training efficiency of data set.Thus,we propose a federated bidirectional connection broad learning scheme(FeBBLS)to solve the data sharing issues.Firstly,we adopt the bidirectional connection broad learning system(BiBLS)model to train data set in vehicular nodes.The server aggregates the collected parameters of BiBLS from vehicular nodes through the federated broad learning system(FedBLS)algorithm.Moreover,we propose a clustering Fed-BLS algorithm to offload the data sharing into clusters for improving the aggregation capability of the model.Some simulation results show our scheme can improve the efficiency and prediction accuracy of data sharing and protect the privacy of data sharing.
Keywords:federated learning;broad learning system;deep learning;Internet of Vehicles;data privacy
I.INTRODUCTION
In the 5G era and beyond,low-latency and highefficiency networking make it possible to share data in mining to improve user experience or system performance [1].Artificial intelligence technology is used widely in data sharing.However,data mining and sharing will lead to data privacy issues because the collected data belongs to the private data of customers,which usually includes the habits of driving experience,and can cause privacy leakage.Therefore,efficient solutions are needed to solve the problem of privacy protection in data sharing in Internet of Vehicles(IoV).
Wang et al.[2]proposed a data-sharing scheme based on semi-supervised learning in federated learning environment.Xu et al.[3]proposed a data sharing framework of double-masking protocol that enables clients to verify the operation of cloud servers.Wei et al.[4]proposed a novel framework to solve data sharing problem for privacy between two clients.With the increasing number of vehicles in the IoV,the efficiency of applying these works to IoV will become relatively low.
Federated learning [5]is a novel distributed learning technology widely used to solve the privacy problem of data sharing in IoV.Lu et al.[6]proposed a blockchain empowered asynchronous algorithm based on federated learning.Ye et al.[7]proposed a selective model aggregation approach in order to overcome asymmetry problem in federated learning.All these works are based on deep learning methods which involve complex data training.Compared with deep learning method,broad learning system (BLS) is a novel efficient and reliable network technology which does not need complex and deep network [8].Although the BLS structure is relatively simple,it can handle many problems such as image processing [9],text classification [10,11].Thus,federated learning combined with BLS has great potential to improve the data sharing in IoV.
However,the IoV environment is a complete dynamic system [12,13].The mobility of vehicles and unreliable inter-vehicle communication.Firstly,the efficiency of models in federated learning environment should be considered.At present,data sharing is based on deep learning models in federated learning which are time consuming to wait local vehicular clients to upload parameters.Secondly,we should guarantee the reliability of shared data.When providers share unqualified data such as few slot data and redundant data,it is necessary to improve the utilization of these data as much as possible.Finally,BLS is an efficient technology,but not much work has been reported on data sharing in IoV by using BLS.
In this paper,we propose a federated bidirectional connection broad learning scheme(FeBBLS)to solve data sharing problem in IoV.In FeBBLS,we propose the bidirectional connection broad learning system model (BiBLS) to train data set in local vehicular nodes.In order to aggregate the parameters collected from vehicle nodes by server,we propose federated broad learning system (FedBLS) aggregation algorithm.Because there may exist unbalance data phenomenon in some vehicle nodes,we use transfer learning and unsupervised clustering approach to optimize FedBLS algorithm.In a nutshell,the contributions of this work can be summarized as follows:
• Firstly,we propose the federated bidirectional connection broad learning scheme (FeBBLS) to solve data sharing in IoV.In local vehicular nodes,we adopt BiBLS to train data set in order to improve the efficiency of communication for server.
• Secondly,the proposed FedBLS algorithm enables servers to aggregate parameters uploaded from vehicle nodes in IoV environment in realtime.The server downloads the parameters and uses the weighted average method according to the size of the data set in the vehicle for parameters aggregation.
• Thirdly,we adopt transfer learning to optimize FedBLS algorithm,namely TF-FedBLS algorithm,when vehicle nodes have unbalanced data phenomenon.We add the dense layer after BiBLS and adopt gradient-descent method to fine-tune the parameters.
• Finally,we use an unsupervised clustering approach to enhance the ability of FedBLS.We carry out unsupervised clustering according to the distance between vehicles and road side unit(RSU),then we use TF-FedBLS algorithm to deal with the data sharing of vehicle-to-vehicle(V2V),and finally we use FedBLS algorithm to conduct the data sharing of vehicle-to-RSU(V2R).
The rest of the paper is organized as follows.Related works of BLS and federated learning are reviewed in Section II.In Section III,the federated bidirectional connection broad learning scheme is proposed to solve the data sharing in IoV.In Section IV,simulation results are provided to evaluate the performance of the proposed scheme.The conclusions of the paper and future work are given in Section V.
II.PRELIMINARIES
2.1 Related Work
With the development of BLS,there are some novel BLS structures that can modify or extend the traditional structure in order to improve the performance.Chen et al.[9]proposed cascade BLS to extract the features of data set.Zhang et al.[14]analyzed the shortcoming of traditional BLS,extended the structure of the traditional model and increased its functions.In order to prevent the BLS model from over fitting during training,the authors in [14]adopted the method which randomly discards the node groups of the enhancement layer.Chu et al.[11]adoptedL2 penalty on the parameters in order to prevent over fitting.Han et al.[15]proposed structured manifold BLS (SMBLS)to solve chaotic time series prediction problem.Liu et al.[16]proposed a modified BLS model based on K-means algorithm to supervise learning.
In addition to considering the efficiency of the model,the network layer should also pay attention to the efficiency in order to shorten response time.Because the IoV is a mobile and complex environment,some computations with large tasks can be offloaded to multi-access edge computing (MEC).Typically,it can be offloaded to cloud computing servers [17]or fog computing[18]servers to improve computing efficiency.Rihan et al.[19]proposed an AI-enabled vehicular network architecture based on fog computing which can achieve low-latency communications in vehicle-to-everything (V2X).Quan et al.[20]proposed a scheme to vehicular content sharing based on edge computing.Wu et al.[21]proposed a routing scheme to solve multi-access vehicular problem in edge computing.Zhan et al.[22]used deep reinforcement learning(DRL)to solve computation offloading scheduling problem.DRL based on 5G can optimize the mobile network slicing [23].In [24],the authors proposed a deep learning method based on software defined network(SDN)to control the network traffic.Liu et al.[25]proposed a scheme that used DRL to optimize resource allocation in vehicle edge computing(VEC).Quan et al.[26]proposed a framework to fuse the traffic data such as traffic flow data and information flow data for path planning based on edge computing.
In IoV,content-centric data dissemination takes place between vehicles in V2V.The content-centric networking (CCN) [27,28]enables centric data dissemination without knowing the IP address.Gulati et al.[29]used convolutional neural networks (CNN)to identify the ideal vehicle pairs in the vehicular network.Dai et al.[30]proposed a vehicular edge computing network framework based on DRL and blockchain to cache content which can protect the data privacy.In [31],the authors adopted spectral clustering method [32]to cluster vehicular nodes.Effective clustering of vehicle nodes is beneficial to the cooperative work of vehicles in the same cluster in federated environment.
As for the privacy of data sharing in federated learning,most of current works focused on data security and parameters aggregation effectiveness.Xu et al.[3]proposed a federated learning framework of doublemasking protocol that enables clients to verify the operation of cloud servers.Lyu et al.[33]proposed a fairness-based federated learning framework to ensure the reliability and exclusiveness of the model while contributing to the server.Synchronous federated learning [34,5]is a new distributed learning to solve parameters aggregation problem,while ensuring the privacy of client data,these local clients train the model,and then parameters are sent to the server.In order to prevent the server from waiting for a long time to upload parameters from clients,Chen et al.[35]proposed a temporally weighted asynchronous aggregation algorithm in order to reduce the communication cost.Zhu et al.[36]adopted multi-objective evolutionary algorithm to optimize synchronous federated learning.
Federated learning is often used in conjunction with other technologies for data sharing is widely used in IoV to preserve privacy.The authors in [6]proposed blockchain empowered federated learning scheme in data sharing for data security.The combination of federated learning and IoV enable the IoV environment to have better efficiency,and better privacy,shorter response time and stronger utility [13].The authors in[37]proposed a novel scheme for traffic flow prediction in vehicular networks based on federated learning.Zhang et al.[31]adopted DRL to process resource allocation and mode selection in federated environment.Chai et al.[38]proposed a scheme to share knowledge based on federated learning in IoV for preserving privacy.To improve the efficiency of federated learning,we propose a federated bidirectional connection broad learning scheme.
2.2 Definition of Broad Learning System
The BLS is a novel model which does not need the deep neural network layers.In BLS,gradient descent is not required for parameters training,which greatly improves the efficiency of the model.
Figure 1 shows the structure of the traditional BLS,the BLS includes mapped feature nodes layer and enhancement nodes layer.The mapped feature nodes layer includesngroup nodes.Each group is connected to the inputXby the formulaZi=φ(XWei+βei),i= 1,2,...,n,whereWeiandβeiare the random weights and biases.φrepresents the activation function.
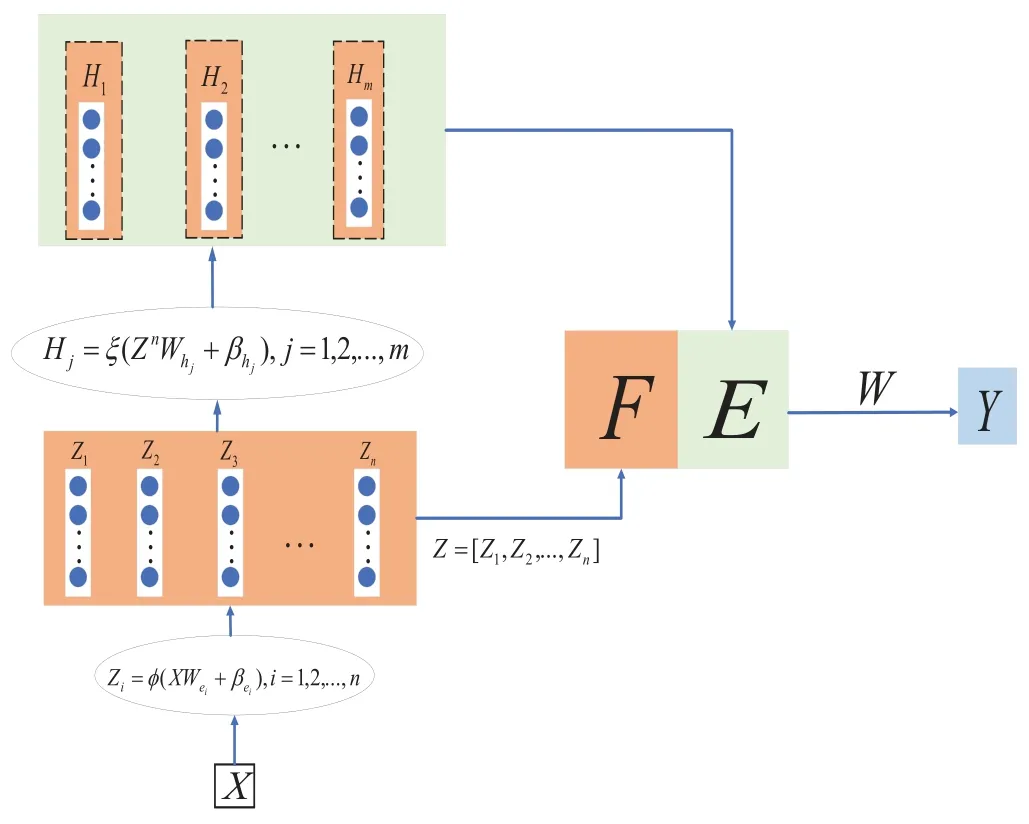
Figure 1.The BLS Structure.
All of the feature nodes can be represented asZn=[Z1,Z2,...,Zn].Then,the output of mapped feature nodes layer is connected to the enhancement nodes layer.In the enhancement nodes layer,it includesmgroup nodes.The value of each group of enhancement nodes is expressed as the formula:Hj=ξ(ZnWhm+βhm),j= 1,2,...,m,whereWhmandβhmare the random weights and biases with the proper dimensions.ξrepresents the activation function.
Therefore,the generalized BLS model can be expressed as the formulaY=[Z1,...,Zn|H1,...,Hm]Wm,andY= [Zn|Hm]Wm,whereWm= [Zn|Hm]+Yis the weight that needs to be required,andYis the output of data set.We can use the ridge regression algorithm [39]to get the value ofWmby the next formula:
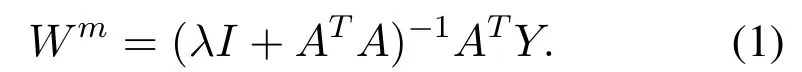
Finally,we have:
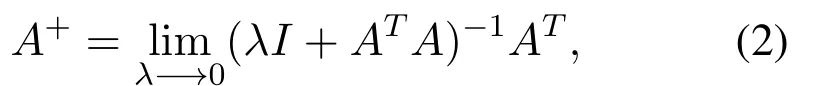
whereA= [Zn|Hm]denotes the expanded input matrix andA+is the pseudo-inverse ofA,(·)+means the pseudo-inverse operation,andλdenotes the regularization coefficient.
When defining the model,initializing the parameters of BLS,such asWei,βei,Whmandβhm.X ∈RN×Fmeans theXhasNsamples,each sample has F features.Thus,Wei ∈RF×BandZi ∈RN×B,where B is the parameters we need to initialize.In the same way,Hi ∈RN×Bcan be obtained fromZi ∈RN×BandWhm ∈RB×B.
Therefore,if we have training data setXtrainand it corresponds to outputY train,we can use BLS to get theWm.Then,we can use the test data setXtestby the (1) and (2) to getA,and use the formulaY predict=AWmto get the predicted outputY predict.
2.3 Definition of FederatedAveraging
The FederatedAveraging (FedAVG) algorithm is widely used in federated learning.In the following,we briefly introduced the FedAVG algorithm.In the federated learning environment,the deep learning model adopts the gradient descent to update parameters.
The Algorithm 1 includes two componentsServerExecutionandClientUpdate.In the subfunctionServerExecution,line 2 initializesω0for deep learning model.Line 3 indicates that the server will do multiple rounds of communication.Line 4 indicates that the server randomly selectsmdevices in each round of communication.For formulam ← max(C · K,1),Cis the constant of [0,1],which is mainly used to adjust the number of devices participating in the parameters of server update in each round.Lines 5-7 indicate that the server selectsStdevices frommdevices for synchronous communication to update server parameters and device parameters.Line 8 shows the globalWkt+1is updated by weighted average method,the weighted coefficient is related to the total data sizenand the size of the data setnkowned by each client.

Algorithm 1.FedAVG.1: function SERVEREXECUTION 2: initialize ω0;3: send the initial parameters to the clients;4: for each round t=1,2,...do 5: m ←max(C·K,1);6: St ←(random set of m clients);7: for each client k ∈S in parallel do 8: Wkt+1 ←ClientUpdate(k,Wt);9: end for 10: Wt+1 ←K k=1nk n (Wkt+1);11: end for 12: end function 13: function CLIENTUPDATE(k,ω)14: B ←(split Pk into batches of size B);15: for each local epoch i from 1 to E do 16: for batch b∈B do 17: ω ←ω −η∇l(w;b);18: end for 19: end for 20: return ω to server;21: end function
In the subfunctionClientUpdate,line 14 divides the device dataPkinto samples of sizeB.Lines 15-19 use the gradient descent to conduct multiple rounds of training for the samples and update the parameters by minimizing loss functionl(w;b).Line 20 sends the final parameters to the server.
III.FEDERATED BIDIRECTIONAL CONNECTION BROAD LEARNING SCHEME(FEBBLS)
The Figure 2 shows that our proposed scheme.The vehicle and RSU use long term evolution(LTE)technology for communication.RSU preprocesses the received data and sends it to server.The server will initialize the parameters according to the BiBLS model structure defined by (1),and then send it to local vehicle nodes via RSU.Some nodes are not disconnected from the server,the unsupervised clustering method is used to unload the data sharing to the cluster head and the nodes within the cluster for data sharing.In each cluster,these vehicular nodes can fine-tune the parameters obtained by BiBLS based on transfer learning to solve unbalanced data phenomenon and enhance the performance of the local model.The cluster can share parameters with RSU based on FedBLS algorithm.
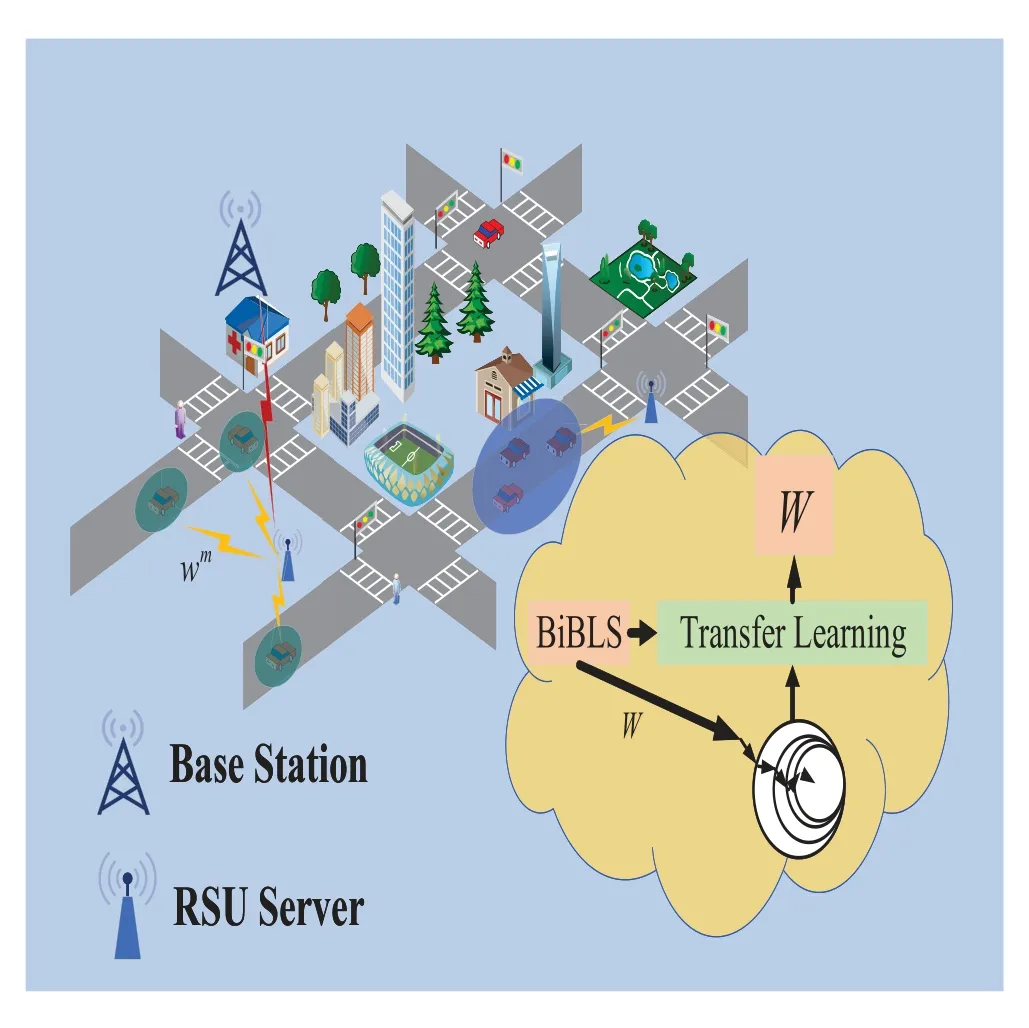
Figure 2.Federated bidirectional connection broad learning scheme.
3.1 Bidirectional Connection Broad Learning System Model(BiBLS)
In order to capture the hierarchical features in both directions,we propose the BiBLS.As seen in Figure 3,the forward mapped feature nodes layer and the backward mapped feature nodes layer all havennode groups.We divideXinto forward inputXfand backward inputXb.We feedXfinto the forward mapping layer to obtainZf i,i= 1,2,...,n,and then feedXbbackward into the backward mapping layer to obtainZbi,i=1,2,...,n.The each group of forward mapped feature nodes layer by the following formula:
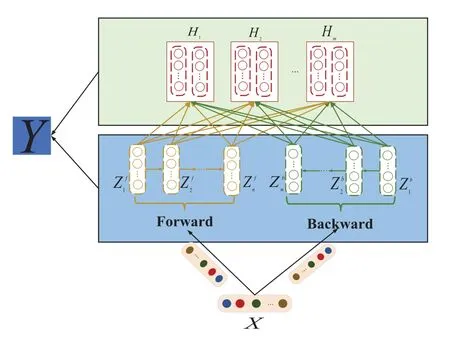
Figure 3.The BiBLS Structure.
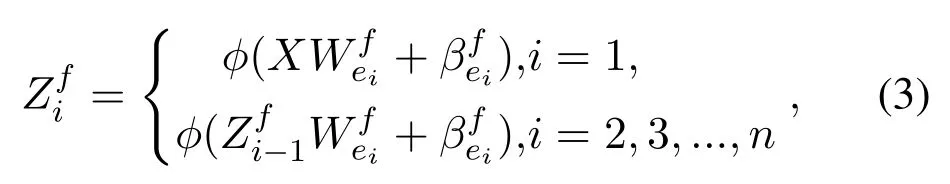
whereWfeiandβfeiare random parameters with the proper dimensions.φrepresents the activation function.
The each group of backward mapped feature nodes layer by the following formula:
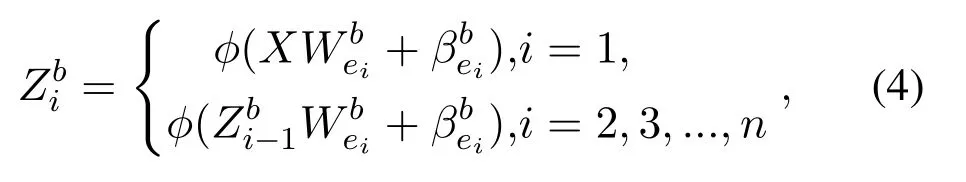
whereWbeiandβbeiare random parameters with the proper dimensions.φrepresents the activation function.
Thus,we defineZnf= [Zf1,Zf2,...,Zfn]andZnb=[Zb1,Zb2,...,Zbn].So we feedZnfandZnbinto the enhancement nodes layer to get the forward and reverse hidden states respectivelyHif,i= 1,2,...,mandHbi,i= 1,2,...,m.TheHf iandHbiare updated as follows:
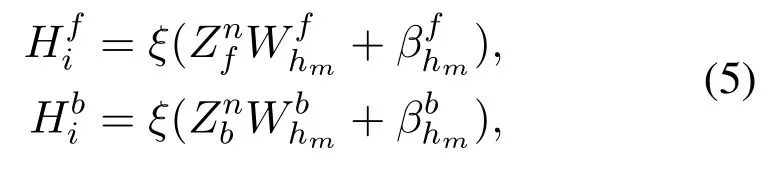
Our model can be summarized asY=[Zn|Hm]Wm,andZn,Hmare obtained by follows:
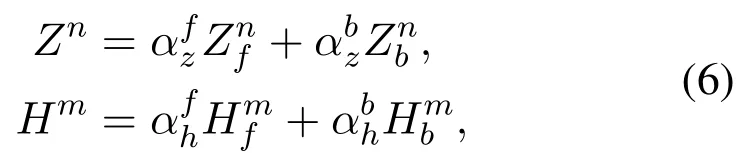
whereαfzandαbzare adjustable coefficients ofZnfandZnb.The different values ofαbzandαbzindicate the different importance ofZnfandZnbtoZn.αfhandαbhare adjustable coefficients ofHmfandHmb.The different values ofαfhandαbhindicate the different importance ofHmfandHmbtoHm.
The traditional BLS model can do incremental learning.Thus,BiBLS uses some efficient ways to increase the enhancement nodes,mapped feature nodes and the training data,without retraining all parameters.
3.1.1 Increment of Additional Enhancement Nodes Suppose that adding the(m+1)th enhancement node groups to the model.DenoteA=[Zn|Hm],such that the input matrixAis updated by:
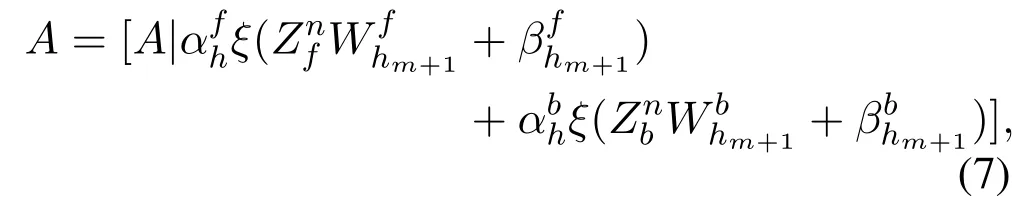
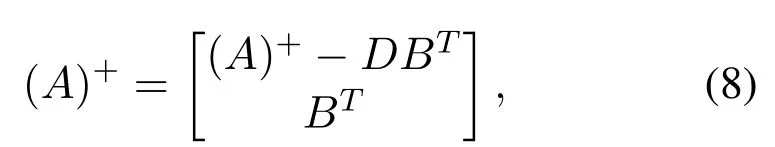

Algorithm 2.BiBLS: increment of m+1 Additional Enhancement Node Groups.Input: training samples X;Output: W;1: Set the forward feature mapping group Znf by (3);2: Set the backward feature mapping group Znb by(4);3: for j =1 to m do 4: Random Wf hj,βfhj;5: Calculate Hfj =ξ(Znf Wfhj +βfhj);6: Random Wbhj,βbhj;7: Calculate Hbj =ξ(Znb Wbhj +βbhj);8: end for 9: Set the enhancement nodes group Hm by (6);10: Set A and calculate(A)+with (2);11: while The number of enhancement nodes increased is less than the set number do 12: Random Wf hm+1,βfhm+1;13: Calculate Hfm+1 =[ξ(Znf Wfhm+1 +βfhm+1)];14: Random Wbhm+1,βbhm+1;15: Calculate Hbm+1 =[ξ(Znb Wbhm+1 +βbhm+1)];16: Set A by (7);17: Update(A)+and Wm by (8),(9),(10);18: Set W =Wm;19: end while
whereD= (A)+(αfhξ(Znf Wfhm+1+βfhm+1) +αbhξ(Znb Wbhm+1+βbhm+1)),which represents the intermediate variable.
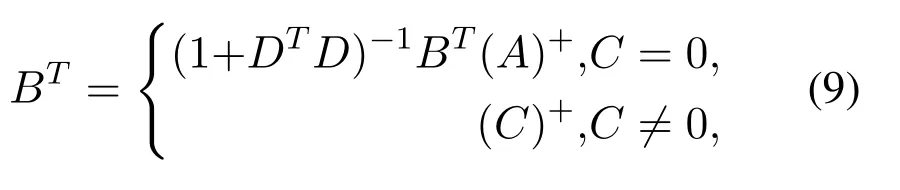
andC=αfhξ(Znf Wfhm+1+βfhm+1)+αbhξ(Znb Wbhm+1+βbhm+1)−AmD,which represents the intermediate variable.
Finally,the new connection weightsWmcould be updated by:
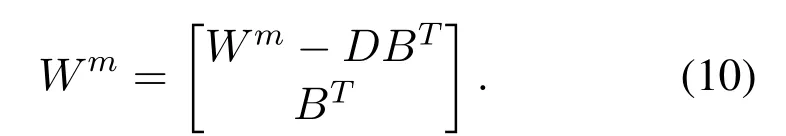

Algorithm 3.BiBLS:increment of n+1 Mapped Feature Node Groups.Input: training samples X;Output: W;1: Set the forward feature mapping group Znf by (3);2: Set the backward feature mapping group Znb by(4);3: for j =1 to m do 4: Random Wf hj,βfhj;5: Calculate Hfj =ξ(Znf Wfhj +βfhj);6: Random Wbhj,βbhj;7: Calculate Hbj =ξ(Znb Wbhj +βbhj);8: end for 9: Set the enhancement nodes group Hm by (6);10: Set A and calculate(A)+with (2);11: while The number of feature nodes increased is less than the set number do 12: Random Wfen+1,βfen+1;13: Random Wben+1,βben+1;14: Calculate Zn+1f and Zn+1b by (11);15: Random Wfexi,βfexi,i=1,...,m;16: Random Wbexi,βbexi,i=1,...,m;17: Set Hfexm and Hbexm by (12);18: Update A;19: Update A+and Wm by (13),(14),(15);20: Set W =Wm;21: end while
3.1.2 Increment of Mapped Feature Nodes
Simply,if we want to add the(n+1)th feature mapping node groups,we denote as:
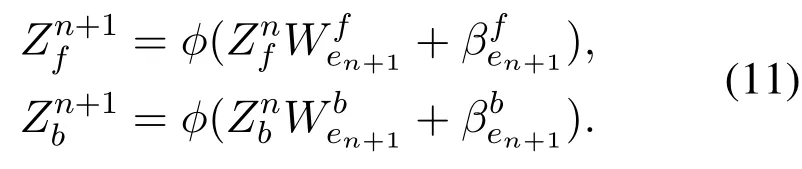
The corresponding bidirectional status of enhancement nodes are randomly generated as follows:
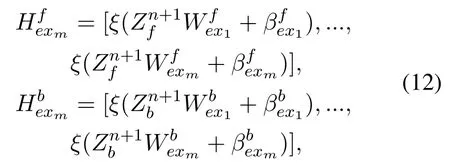
whereWfexi,βfexi,Wfexiandβfexiare randomly generated.DenoteAn+1= [A|αfzZn+1f+which is the upgrade of new mapped features and the corresponding enhancement nodes.The relatively upgraded pseudo-inverse matrix can be achieved as follows:
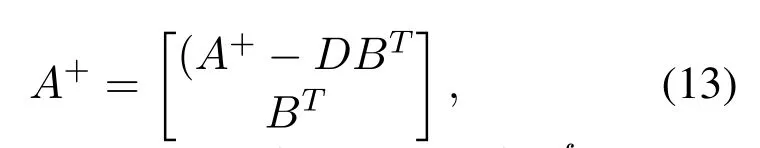
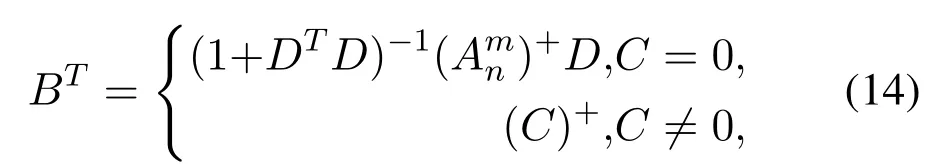
Finally,the new weights can be defined as:
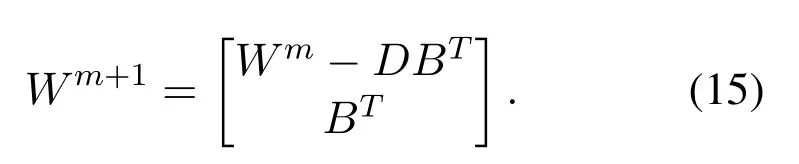
3.1.3 Increment of new training data
If we need to add the new training data into the model,Xarepresents the input matrix of the new data.The initial model includesngroups mapped feature nodes andmgroups enhancement nodes.TheAmnis the expanded input matrix.The extended input matrix of the new additional training data is defined as follows:
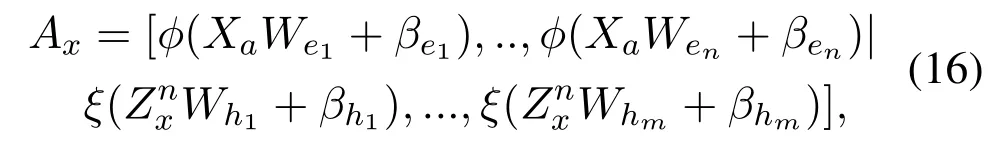
whereZnx=[φ(XaWe1+βe1),..,φ(XaWen+βen)],andZnxis the mapped matrix of theXa.Wei,βei,Whj,andβhjare random parameters.Thus,the new extended input matrix(Amn)xcan be calculated as:
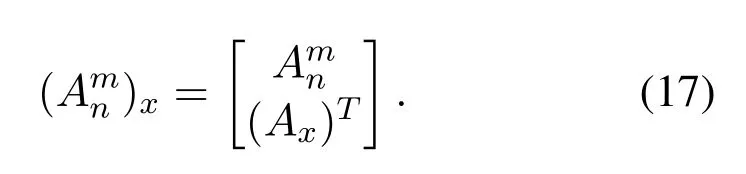
The pseudoinverse ofAmncould be updated as follows:
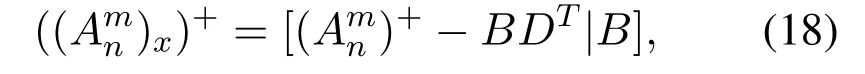
whereDT= (Ax)T(Amn)+,which represents the intermediate variable.
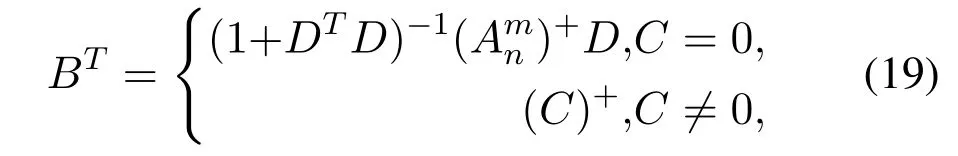
andC=(Ax)T −DTAmn,which represents the intermediate variable.
Finally,the new connection weights could be expressed as:
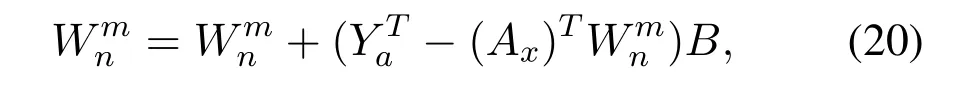
whereYais the output matrix of the new training data.

Algorithm 4.BiBLS:Increment of new training data Xa.Input: training samples X;Output: W;1: Set the forward feature mapping group Znf by (3);2: Set the backward feature mapping group Znb by(4);3: for j =1 to m do 4: Random Wf hj,βfhj;5: Calculate Hfj =ξ(Znf Wfhj +βfhj);6: Random Wbhj,βbhj;7: Calculate Hbj =ξ(Znb Wbhj +βbhj);8: end for 9: Set the enhancement nodes group Hm by (6);10: Set Am and calculate(Am)+with (2);11: Calculate Ax by (16),update Amn by (17);12: Update(Amn)+and Wmn by (18),(19),(20);13: Set W =Wm+1;
Algorithm 2 and Algorithm 3 show that when the BiBLS could not achieve the desired effect with the given number of node groups,we can increase the number of node groups in order to update the parameters that need to be uploaded to the server of the model,which greatly improves the efficiency of the model.Algorithm 4 shows the BiBLS model can be fed the training data efficiently.In federated learning,with the client’s permission,more data can be used to participate in the training of the model,which can improve the training effect of the model while keeping the number of model parameters unchanged.
3.2 Federated Broad Learning System (Fed-BLS)Algorithm for V2R
Local participating nodes rely on a large number of computing resources to update the model.Traditional FedAVG algorithm is the limited network resource that bottlenecks of aggregated local parameters from mobile nodes in IoV.In order to reduce the delay of data sharing in IoV,we use BiBLS and federated learning to achieve accurate and timely data sharing without privacy disclosure.The description of FedBLS is shown in Figure 4,and the main steps of the algorithm are as follows:
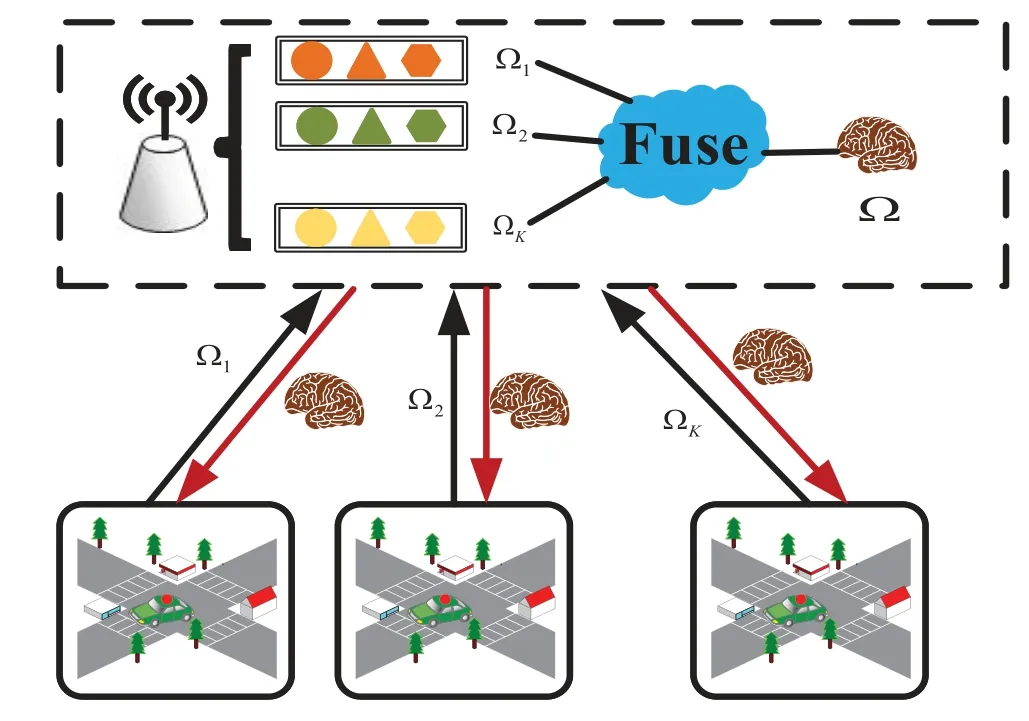
Figure 4.The FedBLS for data sharing.
1)Model initialization.Vehicles and RSU use LTE technology for communication.RSU acts as a server for data exchange with vehicle nodes which act as clients.It initializes the parameters of BiBLS,and sends model Ω to mobile nodes.The local BiBLS of node is defined as Ωi.
2)Participate Nodes Selection.In each communication,the RSU exchanges data with mobile nodes that meet certain conditions.Then,it randomly selectsmclients from a certain proportionCof the total clientsK.These vehicle nodes participate communication in parallel.
3)Update parameters.The vehicle node calculatesWbased on the local data set and sends it to the server.Without increment learning of BiBLS,they just upload the trained parameters to the server.
4) Model Aggregation.When training the model,there is no need for batch size segmentation of the data set.Thus,the server gets the global parametersWgfor each round of communication to aggregate the parameters of local vehicle nodes by the formulaintth round.

Algorithm 5.FedBLS algorithm for data sharing in IoV.Input: Vehicle participate nodes V ={V1,V2,...,Vk};Output: Parameters W;1: Initialize wxi,βxi,whi,βhi,αfz,αbz,αfh,αbh;2: S ←(random set of V clients);3: for each round t do 4: Send the initial parameters to all Vs ∈S;5: for each Vs in ∈S in parallel do 6: Calculate Ws according to the model Ωs in this round by local data set;7: if Iter!=0 then 8: for i=0:Iter do 9: Use Algorithm 2 and Algorithm 3 to update Ws;10: end for 11: else if New training data set Xa is needed to add then 12: Use Algorithm 4 update Ws;13: end if 14: return Ws to server;15: end for 16: Wg =�S Vs∈Snsn(Ws);17: end for
The FedBLS does not make use of the gradientdescent method to update the model.If there is no increment learning of the local model in the data sharing,the node and RSU can update the global model with only one communication round.If the local training is not satisfactory or a new data set is added to the local node,incremental learning is required.Algorithm 5 shows the FedBLS algorithm withIterrounds incremental learning.In Algorithm 5,lines 6-14 show that the node uses BiBLS for incremental learning.
3.3 FedBLS with Transfer Learning for V2V
BiBLS improves the training effect of the model by increasing the node group of the internal structure.Although multiple groups of node can be added in mapping feature nodes layer or enhancement nodes layer when the learning of BiBLS is not ideal,parameters’size increases with the increasing of nodes,and the solution time of theWalso increases.Thus,Gao et al,in[40]proposed a end-to-end BLS structure based on deep learning.However,when the samples of the node that can be trained are relatively less,parameters directly trained by BLS model may not achieve the expected effect.
The IoV has inter-vehicle communications.Thus,a vehicular node can share data with other nodes.In inter-vehicle communications,there are differences in the data between each node.For example,when a vehicular node has few samples,or when the client only contains samples of a certain label,the trained model parameters have no generalization.In order to solve these issues,we use transfer learning[41,42]technology to improve the generalization ability of models.From the Figure 5,we use transfer learning combined FedBLS,dubbed (TF-FedBLS) algorithm to apply in the IoV in order to enhance the ability for aggregation.In inter-vehicle communications,a node uses a weighted average aggregation method to aggregate parameters from other nodes.However,there may be bad parameters from other nodes,so we add a neural network layer after the model to fine-tuneWwith freezing other parameters of the model.From the Figure 5,the first stage is that the vehicle use the local data setXto train the local BiBLS model.Through the mapped feature nodes layer and enhancement nodes layer,we can get theZnandHmby the (3)-(6).In the second stage,we feed theWinto the neural networks.
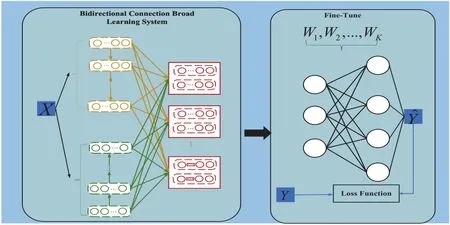
Figure 5.FedBLS with Transfer Learning for V2V.
First,we initialize the neural networks to fine-tune model parameters.The full connection (FC) layer is defined in the TF-FedBLS.The weights and biases of the FC is set toWand zero,respectively.The purpose of this is to be able to update the model parameters using gradient-descent method.The updating process is described as Algorithm 6.From the Algorithm 6,theClientUpdateof TF-FedBLS is the same as the FedBLS.InServerExecution,line 10 defines the one layer neural networkLinearNetand resets the weights.Lines 12-14 use gradient-descent method to update parameters.

Algorithm 6.TF-FedBLS.1: function SERVEREXECUTION 2: Initialize wxi,βxi,whi,βhi,αfz,αbz,αfh,αbh of BiBLS model;3: Send the initial parameters to the clients;4: m ←max(C·K,1);5: S ←(random set of m clients);6: for each client k ∈S in parallel do 7: Wk ←ClientUpdate(k);8: end for 9: W ←�K k=1 nkn Wk;10: Set LinearNet().weight=W;11: B ←(split Pk into batches of size B);12: for each epoch i from 1 to E do 13: for batch b∈B do 14: Update W by gradient-descent method;15: end for 16: end for 17: end function 18: function CLIENTUPDATE(k)19: Calculate Wk by (1);20: return Wk to server;21: end function
3.4 Clustering Federated Broad Learning Data Sharing Algorithm in IoV
There is a distance requirement for the connection between RSU and the vehicle networking node.Theith vehiclevicommunicates with the RSU beyondd0,and then it communicates with the nearest vehicle node.If it is within the communication distance range with the RSU,it will directly communicate with the RSU.
The vehicle connection topology graphG(V,E).Denotes the set of nodes isV,andEdenotes the set of weights in inter-vehicle.We define thedijas the distance between nodeviand nodevj.We use FINCH Algorithm[43]which is an efficient unsupervised clustering algorithm to aggregate the vehicular nodes by the next formula:
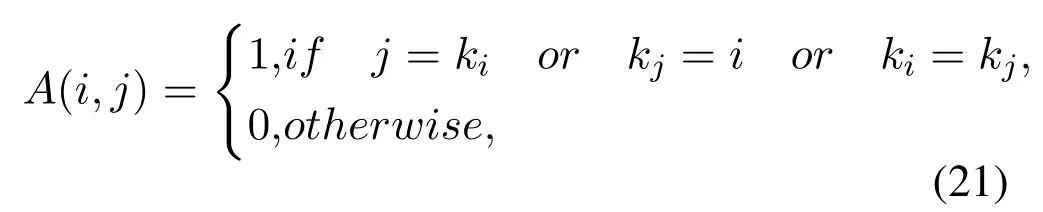
wherekirepresents the nearest neighbor of theith node,kjrepresents the nearest neighbor of thejth node,andAis the adjacency matrix of IoV networks topology graph.
From the (21),the value in the adjacency matrix is one as long as the following:
1)j=ki:It means the nearest neighbor representing theith node is thejth node.
2)kj=i: It means that the nodeiis the nearest neighbor to nodej.
3)ki=kj: It means that the nearest neighbor of theith node and the nearest neighbor of thejth node are the same.
Figure 6 shows the relationship between TFFedBLS and FedBLS.In the inter-vehicle communications,the vehicular nodes will use TF-FedBLS algorithm to share parameters.The vehicular nodes will share parameters based on FedBLS.Algorithm 7 lists the process of cluster-based FedBLS algorithm.Assuming that nodes are divided intoKcategories.For each class,the node closest to the RSU is selected as the cluster headChk,k= 1,2,..,K,and then the RSU collects the uploading parameters by these cluster heads for federation aggregation.Each cluster head aggregates other vehicular nodes in the same cluster bywherenkis the size of data set in thekth local node,Wkis the parameters which thekth node needs to share,andWimeans the parameters of theith cluster head.
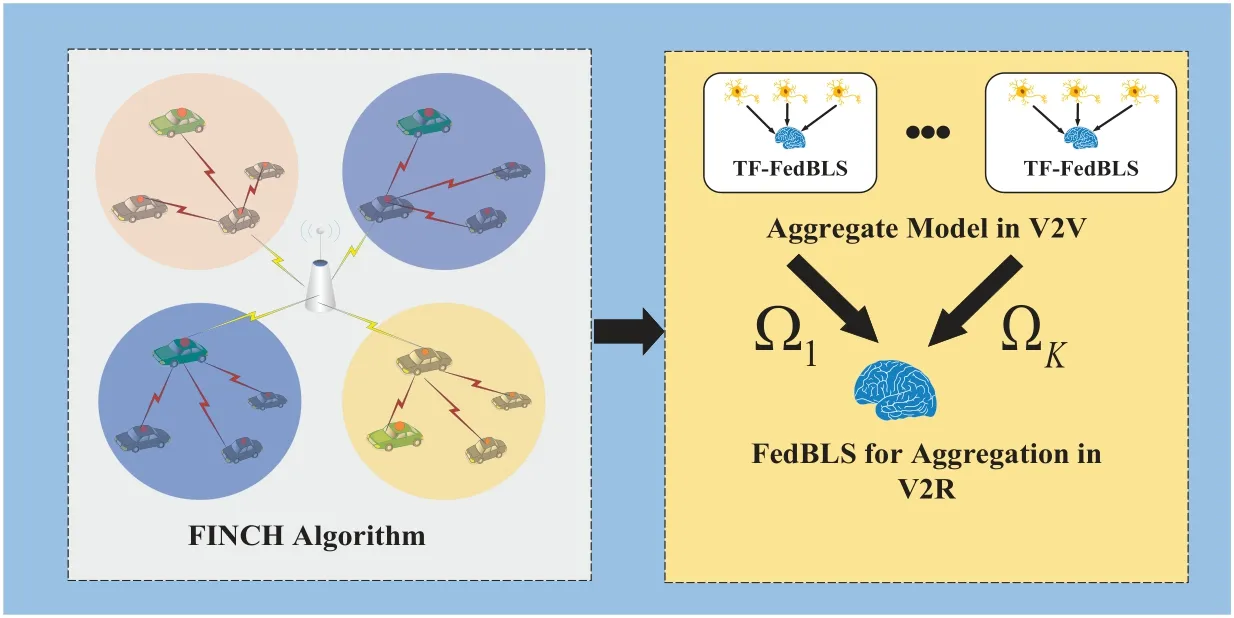
Figure 6.Clustering FedBLS in IoV for Data Sharing.
IV.SIMULATION RESULTS AND ANALYSES
4.1 Simulation Design
We use MNIST data set to evaluate our model,randomly allocate 80% of the training data and assign it to local devices as privacy data,and assign 20%to the server for test data.Each device selects 90%of the data to train models,10% for test data.We useOMNET++combinedVEINSto randomly generate the number of vehicle nodes on the map based on Simulation of Urban MObility(SUMO)[44].The simulation scenario plotted byOpenStreetMap.The network layer parameters involved in IoV are shown in Table 1.Through the simulation of the IoV environment,we will obtain the connection status of V2X at each episode of IoV.All algorithms are running inPytorch,and our stimulation environment is Intel(R)Core(TM)i7-5500U CPU,and 8GB RAM.

Algorithm 7.Clustering FedBLS(cFedBLS)algorithm.1: Initialize K and get the graph G(V,E);2: Calculate A by (21);3: Calculate the cluster sets {C1,C2,..,CK} by FINCH Algorithm[43];4: for k =1,2,...,K do 5: Take the node closest to the RSU as the Chk in Ck;6: end for 7: for each clustering center Chk do 8: for each node v in category Chk do 9: Execute TF-FedBLS algorithm;10: end for 11: Execute FedBLS algorithm;12: end for 13: The server downloads the parameters and update the BiBlS model;14: The server sends the model to the clustering of each category;15: The client returns W to server;

Table 1.System parameters.
In this paper,the simulation parameters of models are set as follows:
FedAVGThe architecture of the CNN used for the MNIST recognition tasks has two convolution layers (the first one has 6 output channels and the other has 16 output channels) and each convolution layer needs 2×2 max-pooling layer.Then,we add three full connected layers with Relu activation function,which have 120,84 neurons,respectively.
FedBLSThe enhancement nodes layer includes 10 group nodes and the mapped features nodes layer includes 10 group nodes.In increment learning of BiBLS,we add 5 and 2 groups for each step of mapped features node groups and enhancement node groups.
TF-FedBLSThe number of mapped feature node groups and enhanced node groups are the same as the FedBLS algorithm.In TF-FedBLS algorithm,we set one neural network to fine-tune the parameters of BiBLS.
4.2 Results And Analysis
We evaluate the performance of BiBLS under different adjustment coefficients.The different adjustment coefficients of mapped feature nodes layer and enhancement nodes layer means that we assign different attention to them.From the Figure 7,when the adjustment coefficients areαfz= 1,αbz= 0,αfh= 0.5,αbh= 0.5,the better effect of BiBLS can be obtained for 10-30 vehicles.However,when the adjustment coefficients areαfz= 1,αbz= 0,αfh= 0.8,αbh= 0.2,the best effect of BiBLS can be obtained for 15 vehicles.Particularly,when the adjustment coefficients areαfz=1,αbz=0,αfh=1,αbh=0,BiBLS structure becomes the traditional BLS structure.Thus,we believe that the bidirectional mechanism has a catalytic effect in BLS.In some cases,assigning different attention to hidden states can make the model work better.
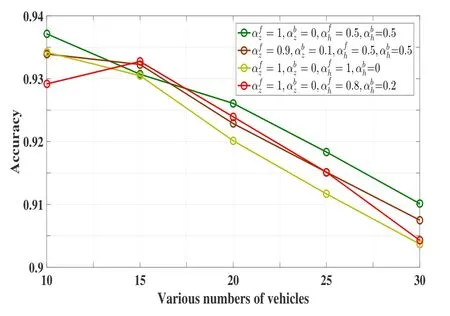
Figure 7.The performance of BiBLS under different adjustment coefficients.
Meanwhile,we also compare FedBLS with BiBLS.We use the BiBLS model for training in the vehicle node and validate the test data of the server.From the Figure 8,we can see the number of vehicle clients increases,the average accuracy decreases significantly.When we use FedBLS algorithm for parameters sharing,the accuracy varies steadily which proves that our algorithm works well in federated parameter sharing.With the increasing of local clients,the average accuracy is decreasing,because the local test data set is less.If we don’t share the parameters,the loss of precision will be more serious.We use FedBLS to share parameters,the average accuracy is less affected by the number of clients,because each local client can have global parameters which means the predictive power of the model is enhanced.
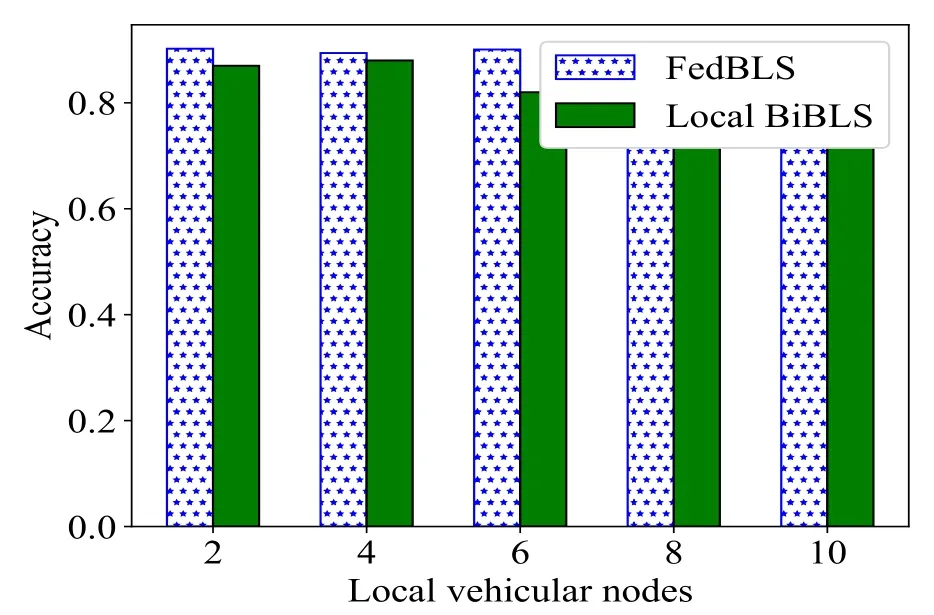
Figure 8.The prediction effect of local BiBLS and FedBLS in the different local vehicles.
We compare our FedBLS algorithm with FedAVG.In federated learning,the training of models is generally based on CNN,but the disadvantage of CNN is that the model training takes a long time.BiBLS updates parameters to achieve a certain effect by increasing the number of node groups,instead of updating the parameters through gradient descent.From the Figure 9,when we use the FedBLS to test the global data set of the server,we can see the model converges quickly and with the increasing of episodes,the prediction effect of the global model has little change,and the effect is better than that of FedAVG algorithm with different nodes.
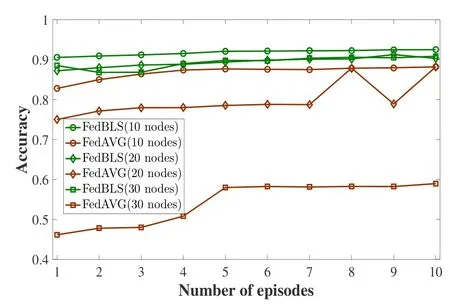
Figure 9.The performance of increment learning under the FedBLS different for the number of vehicles.
In V2V,vehicular nodes use TF-FedBLS to share data.Thus,we compare FedBLS with TF-FedBLS.We also use the BiBLS model for training in the vehicle node and validated the test data of the server.From the Figure 10,with the increasing of clients,TFFedBLS algorithm is always better than FedBLS.This indicates that TF-FedBLS algorithm can improve the average accuracy of the global model in server to a certain extent when some vehicle nodes have sample imbalance issues.At the same time,distributed computing can also improve the efficiency of our algorithm.
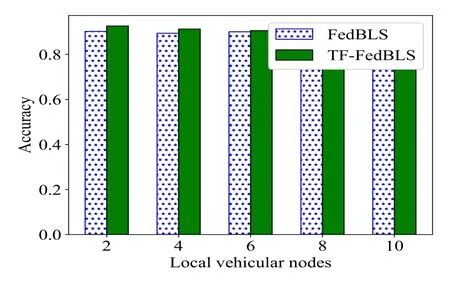
Figure 10.The prediction effect of local TF-FedBLS and FedBLS in the different local vehicles.
In some cases,the data volume of the local client may be fewer,the model may be less than ideal after only one round of training,or the server may require the client to upload parameters which has a certain accuracy based on the needs of the IoV environment.Thus,we evaluate the performance of FedBLS to combine with deep learning.From the Figure 11,with the increasing of the number of training iterations,the prediction accuracy of TF-FedBLS algorithm first decreases and then increases,and finally improves significantly compared with the original prediction accuracy.However,with the increase in the number of IoV clients,although the average prediction accuracy of the BiBLS model is relatively low with out iterative training.After the certain number of iterations,it can be seen that the accuracy has been greatly improved.
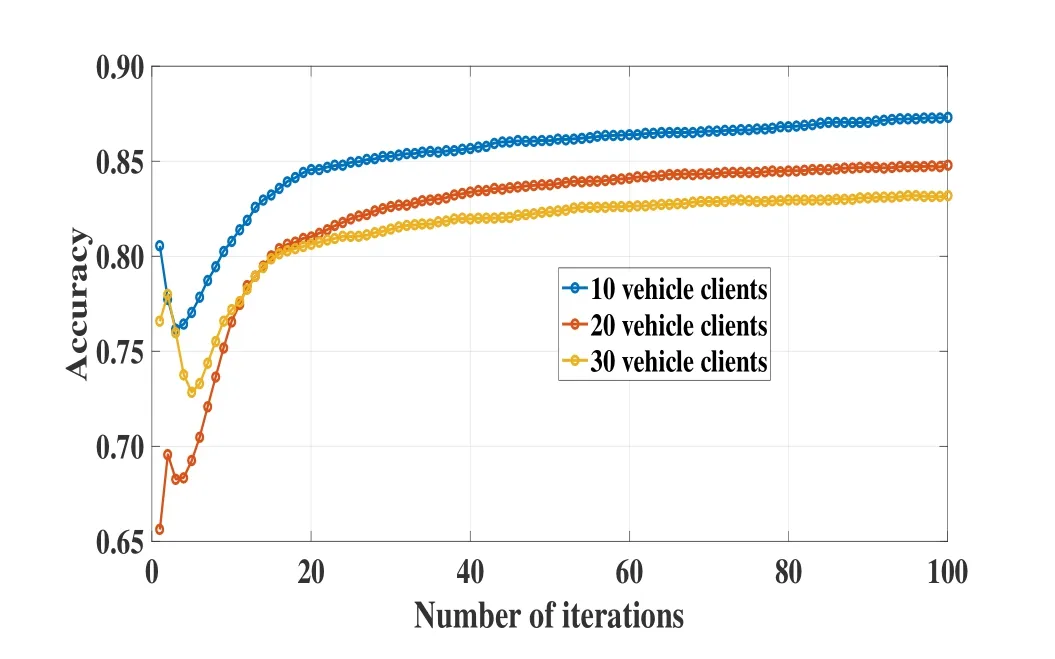
Figure 11.The performance of TF-FedBLS with various numbers of data clients.
From the Figure 12-13,when some samples are fewer,the performance of FedBLS and TF-FedBLS of various vehicular nodes are better than the FedAVG.Compared with FedAVG algorithm,our TF-FedBLS algorithm has significant improvement in few-shot learning.Compared with FedBLS,TF-FedBLS has certain improvement in parameter aggregation effect.Especially when there are 10 nodes,the improvement effect is obvious.The main reason is that when some nodes have very little data to train the model,the effect trained by BiBLS model alone may be poor,because there is under fitting phenomenon,and sending the parameters to the server for aggregation may make the effect of the model lower on the server.
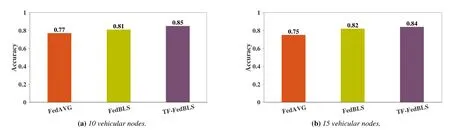
Figure 12.The global accuracy results of FedBLS,TF-FedBLS and FedAVG for 10 and 15 vehicular nodes.
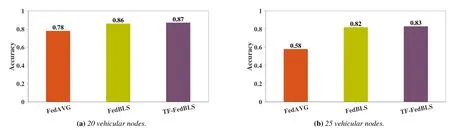
Figure 13.The global accuracy results of FedBLS,TF-FedBLS and FedAVG for 20 and 25 vehicular nodes.
From the Figure 14-15,we evaluate the FedBLS algorithm based on clustering.The FedBLS is used to make comparison algorithm.The performance of Fed-BLS with clustering of various vehicular nodes are better than the FedBLS.If FedBLS is used only,some vehicle nodes do not share data with the server while moving,so the average accuracy results of BiBLS model lag far behind FedBLS with cluster.When some nodes are not disconnected from the server,the unsupervised clustering method is used to unload the data sharing to the cluster head and the nodes within the cluster for data sharing.Thus,FedBLS with cluster can use the transfer learning to enhance the effectiveness of data sharing in V2V.This approach in various of nodes can enhance the effectiveness of local BiBLS model.
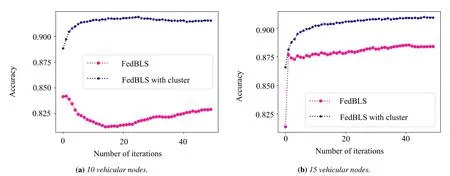
Figure 14.The global accuracy results of FedBLS and FedBLS with clustering for 10 and 15 vehicular nodes.
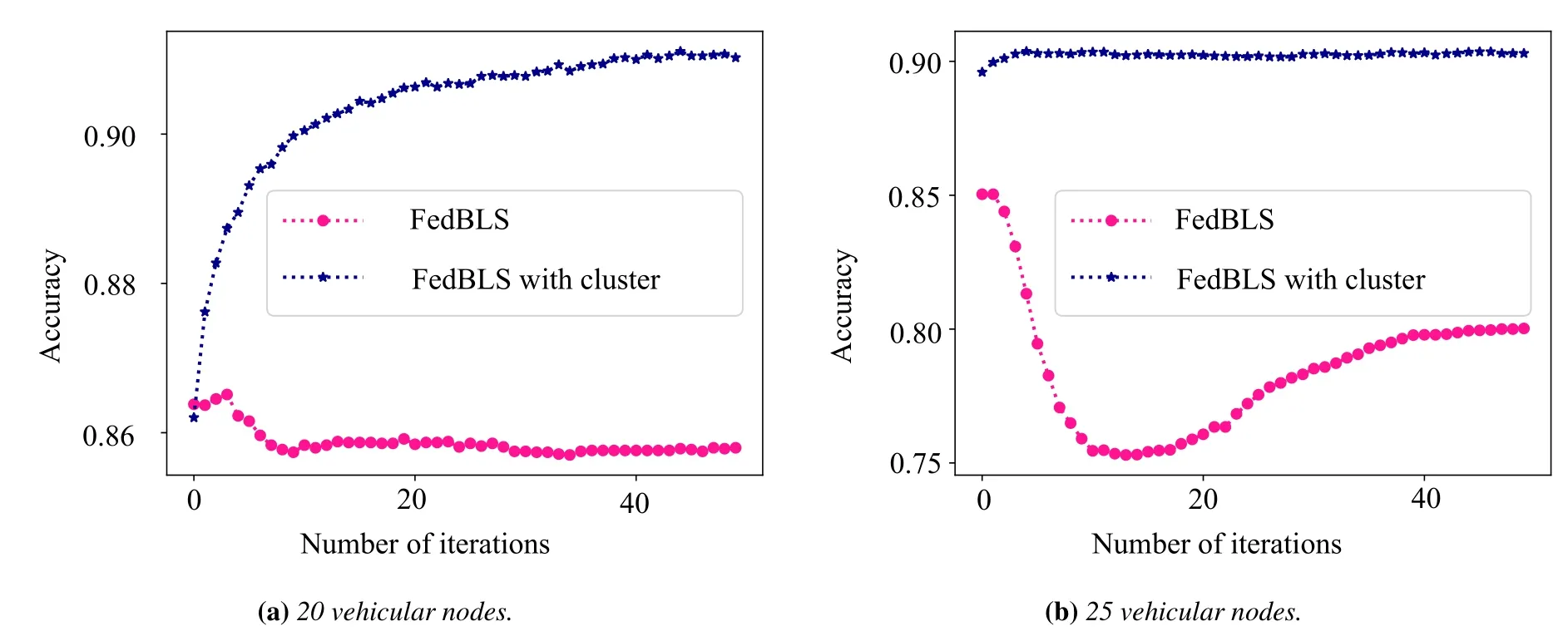
Figure 15.The global accuracy results of FedBLS and FedBLS with clustering for 20 and 30 vehicular nodes.
We also compare the performance of FedBLS and FedAVG in training time,the size of model parameters and communication time.The local clients use CNN to train model based on FedAVG.From the Table 2,it takes a lot of time to train CNN 100 times in CPU.Due to the deep structure of CNN,there are many parameters,which makes the size of model large.Therefore,without considering the communication delay and packet loss rate in an ideal situation,it takes a lot of time to communicate.Since the IoV is a real-time and mobile environment,it takes lots of time to train the model,and it is likely that uploading parameters to the server are not real-time.The FedBLS algorithm only uploadsW,so the size of the parameters is small and the communication time is negligible.

Table 2.The parameters size and efficiency of baseline models.
V.CONCLUSION
In this paper,we have proposed the federated bidirectional connection broad learning scheme for data sharing in IoV.Vehicular nodes use BiBLS to train local data set in IoV.The server uses FedBLS algorithm to aggregate the parameters of vehicular nodes.Moreover,we use FedBLS algorithm based on transfer learning to solve unbalanced data problems.Compared with the benchmark algorithms,our simulation results show that our proposed scheme has improved the average accuracy of prediction on the server by about 5%,and the efficiency has improved by more than 3 times,while greatly reducing the size of parameters sharing between the server and vehicle nodes.In the future,we will continue to discuss the communication efficiency of our scheme at the network layer.At the same time,we will continue to study that our scheme can be dynamically adjusted according to the environment through deep reinforcement learning.
ACKNOWLEDGEMENT
This work was supported by the National Natural Science Foundation of China under Grant No.61901099,61972076,61973069 and 62061006,the Natural Science Foundation of Hebei Province under Grant No.F2020501037,and the Natural Science Foundation of Guangxi Province under Grant No.2018JJA170167.

- China Communications的其它文章
- Joint Topology Construction and Power Adjustment for UAV Networks: A Deep Reinforcement Learning Based Approach
- V2I Based Environment Perception for Autonomous Vehicles at Intersections
- Machine Learning-Based Radio Access Technology Selection in the Internet of Moving Things
- A Joint Power and Bandwidth Allocation Method Based on Deep Reinforcement Learning for V2V Communications in 5G
- CSI Intelligent Feedback for Massive MIMO Systems in V2I Scenarios
- Better Platooning toward Autonomous Driving: Inter-Vehicle Communications with Directional Antenna