
一种个性化智慧教育云服务模式的设计
2021-07-02 08:13:56周明芳拜亚萌
焦作大学学报 2021年2期
周明芳 拜亚萌
(焦作大学,河南 焦作 454003)
当前,高校信息化建设进入智慧校园建设阶段,由于上层应用程序的数据分析和处理过程需要建立在庞大的数据服务基础之上,需要由统一的数据服务中心来满足需求,而传统的教育信息化系统数据的处理模式导致信息不能互通,数据很难共享。因此,本文利用Spark架构构建一种新的个性化智慧教育云服务平台来解决上述问题。
1.个性化智慧教育云服务模型需求
1.1 智慧教育云服务模型需求
智慧教育云计算服务平台的设计思路是在云架构的基础上将高校的各种软件﹑硬件资源按照分层架构进行部署,构建基于调度核管理的教育教学服务组件[1],如:用户权限服务﹑系统安全监控服务﹑海量的教育数据存储能力,能够让高校的学生﹑教师﹑各类管理人员等进行协同操作,构建教育资源集成化﹑共享化﹑数字化的生态环境[2]。
智慧教育云平台对用户来讲,是完全透明的,用户不用了解底层服务的构建和部署方式,只需要根据自己的实际需求向服务器提出请求,而平台则根据部署在平台上的业务逻辑组件和一系列复杂的业务逻辑的操作过程,搜索符合的服务接口,并且按照数据计算和传输格式进行封装,最终将符合用户个性化需求的服务资源反馈给用户[3]。
1.2 个性化的智慧教育云服务模式
根据高校智慧教育的需求,一方面要在云平台下将各类资源进行集成,统一为用户提供数据的分析和管理功能[4]。另一方面,根据教育云的部署特征,对海量的数据资源进行分析,从而最大限度地为终端用户提供个性化的学习﹑工作和管理服务[5]。因此,结合开放协同的云服务和可以进行教育大数据部署的架构,将云计算﹑SOA﹑Spark架构进行融合,应用于教育云服务模式中,建立更加符合用户需求的个性化智慧教育云服务模式,如图1所示。

图1 智慧教育云服务平台需求模式
(1)云服务消费者。教师用户和学生用户是平台主要的服务对象,也是评价服务质量的主要参与者;管理人员则是部署在底层的各类子系统的管理员,其权限由服务中心根据各自职务来分配权限。
(2)云服务中心。教育云服务中心是整个智慧教育云服务平台的核心枢纽,负责提供教育云服务的注册﹑查找和访问功能。云服务中心可以根据高校的业务需求,进行协同部署,为不同高校和校区提供统一的云计算服务。无论是服务的提供者还是使用者,在进入服务中心访问系统资源时,都需要提出访问请求,并通过统一身份认证后,经过授权才可以获取接口访问权限。
(3)云服务提供者。智慧教育云服务的提供者分为:应用服务提供者﹑平台服务提供者和基础设施服务提供者。应用服务提供者为终端用户提供远程课堂﹑服务资源维护﹑教务管理﹑学工管理﹑人事管理等应用服务;平台服务提供者主要负责将所有的应用服务组件进行注册和管理,并对平台的服务进行部署和监控,同时负责各类教育服务组件的规范化管理;基础设施服务提供者负责集成云计算服务器﹑大数据存储架构﹑Spark架构的部署,同时,该层还可以租用IaaS服务商提供的优质服务功能,构建系虚拟化的教育资源池,从而为上层的各个应用组件提供基础的服务接口。
2.Spark下数据存储与个性化服务模型
2.1 数据存储与服务模型设计
随着系统中的教育教学资源和用户信息规模的不断增加,传统的数据分析与挖掘算法模型已经无法满足系统用户的需求,因此,本文结合HBase的存储与Spark并行处理框架,构建了一种在Spark下的智慧教育云的数据存储与个性化服务模型架构,如图2所示。从模型图中可以看出,整个数据的处理过程大致可以分为数据采集﹑数据处理与分析﹑数据存储三个过程,每个过程都是建立在不同的处理框架之上,以便于满足教育云平台下的大批量数据的集中处理与分析。
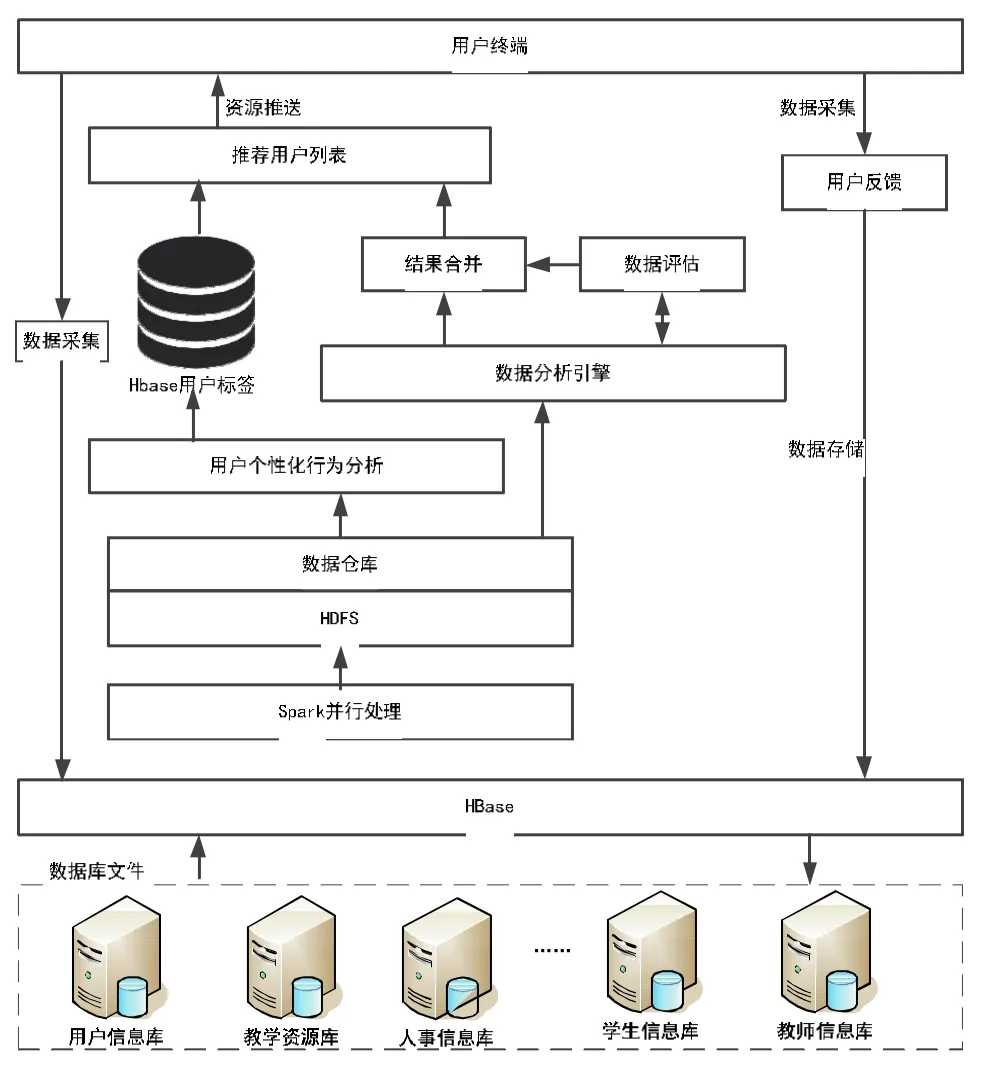
图2 Spark下数据存储与个性化服务模型
(1)个性化数据采集过程:主要是对客户端数据源产生的各种个性化的结构性或非结构性数据信息进行采集,对清洗后的数据进行存储。通常,数据采集模块是由系统的各种终端定期地向文件服务器提交访问日志,文件服务器则对采集到的数据进行汇总和整合。
(2)个性化数据处理与分析:该过程是整个数据存取与服务模型的核心。利用Spark架构的Spark_ETL和Hive机制,对用户的个性化行为数据进行采集﹑清洗﹑筛选﹑过滤处理,并且按照字段建立的时间建立Hive仓库的分区表,以便于区分用户的身份特征和类型。
(3)数据存储:通过对用户信息的挖掘分析,对用户建立各种属性标签,以便于根据用户标签引擎建立数据源与用户历史数据信息之间的连接,并将所有的标签和用户行为信息存入HBase数据库中,从而为数据的可视化分析与上层应用提供结构化数据。
2.2 Spark架构下数据并行处理模式
相比其他计算框架,Spark技术的主要特点是在内存中建立弹性分布式数据集(Resilient Distributed Datesets,RDD),减少多次计算的中间结果写入过程,从而实现基于内存的高效并行处理[6,7]。
本文采用Spark作为智慧教育云服务计算的实时处理框架,可以通过更简洁的配置和方式,实现一些复杂的业务流程处理和数据计算,并保证分析过程的实时性能[8]。其中Spark数据转换流程如图3所示。
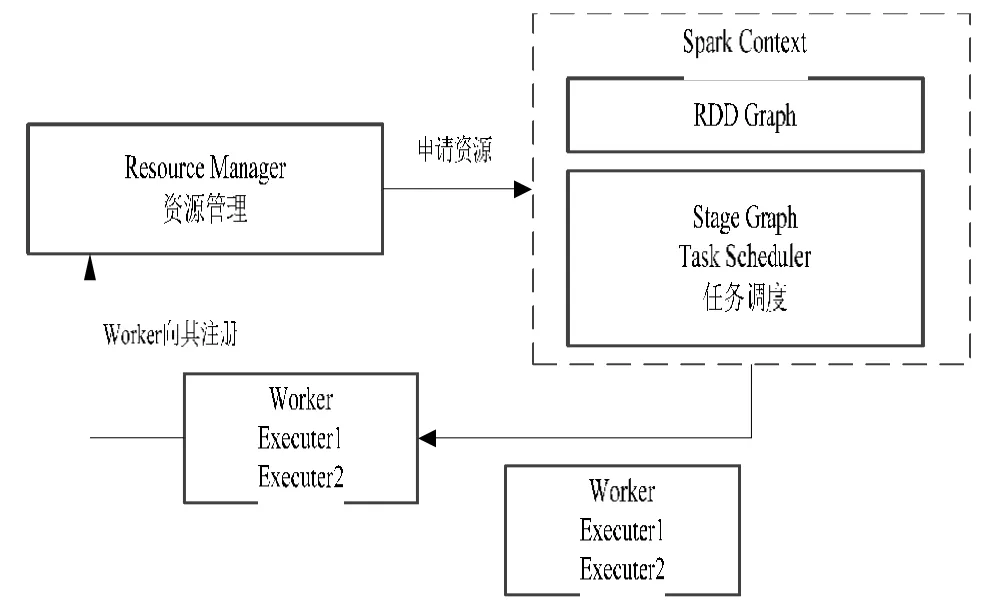
图3 Spark数据并行转换流程
前置输入项:Spark分布式计算集群部署完成。
Step1:集群主节点启动主要进程Master和工作进程Worker,监控整个集群的运行状态;
Step2:Spark Driver接收Task任务指令,对任务进行分发和调度管理;
Step3:Worker接收任务指令,执行任务操作,将指定的分片数存储在RDD的不同的分区中;
Step4:Spark对RDD执行并行处理操作,将指定的任务发送到对应的机器上,并利用多线程控制各个计算节点任务执行和结束;
Step5:一项任务执行完成后,当前RDD立即转向另外一个RDD,对应的用户操作随之依次执行。
3.仿真实验
搭建Spark和Hadoop实验环境,分别对采用Spark和Hadoop的MapReduce框架的智慧校园云服务平台的数据并行处理能力进行对比测试[9-10]。
本文测试环境采用6台虚拟机搭建Hadoop和Spark实验集群,其中,1台为主节点(Master),负责NameNode节点和Master进程,其余5台为工作节点(Worker),负责DataNode和Worker进程,节点之间通过10/100M交换机相连,并通过SSH进行消息认证,具体配置信息如表1所示。
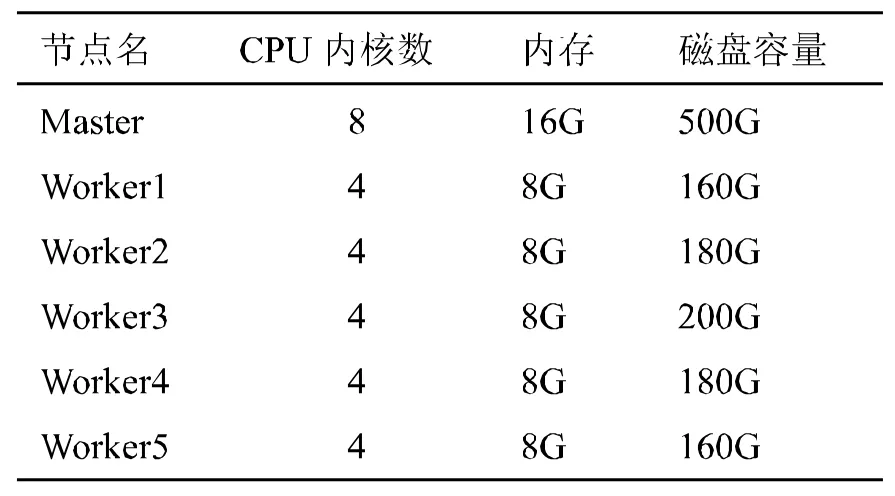
表1 实验平台配置信息
同时,为更好地显示比对效果,选定5组测试数据分别在Spark和Hadoop平台做Kmeans运算,如表2所示。
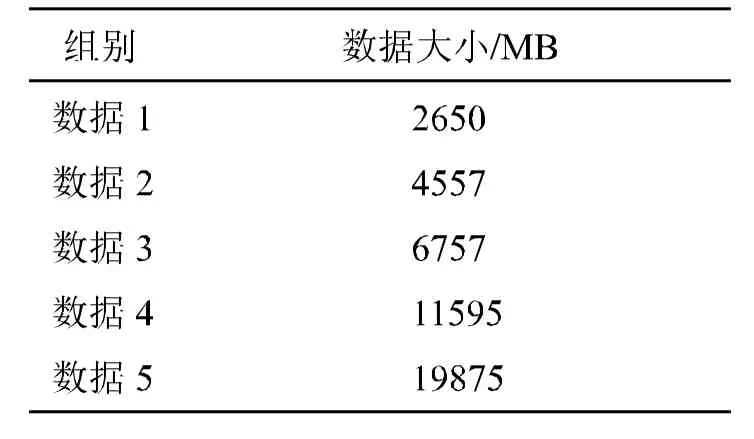
表2 测试数据
采用数据计算时间和执行效率这两项性能指标,对并行数据计算能力和数据处理实时性进行性能分析[11]。图4为Spark和Hadoop计算时间的对比。
从图4可知,总体而言,随着测试数据规模的增大,计算时间不断增加,增长率也逐渐变大,计算效率明显降低。造成该结果的主要原因是计算任务多,平台处于饱和状态,计算资源竞争激烈,任务排队时间长,计算额外开销大。
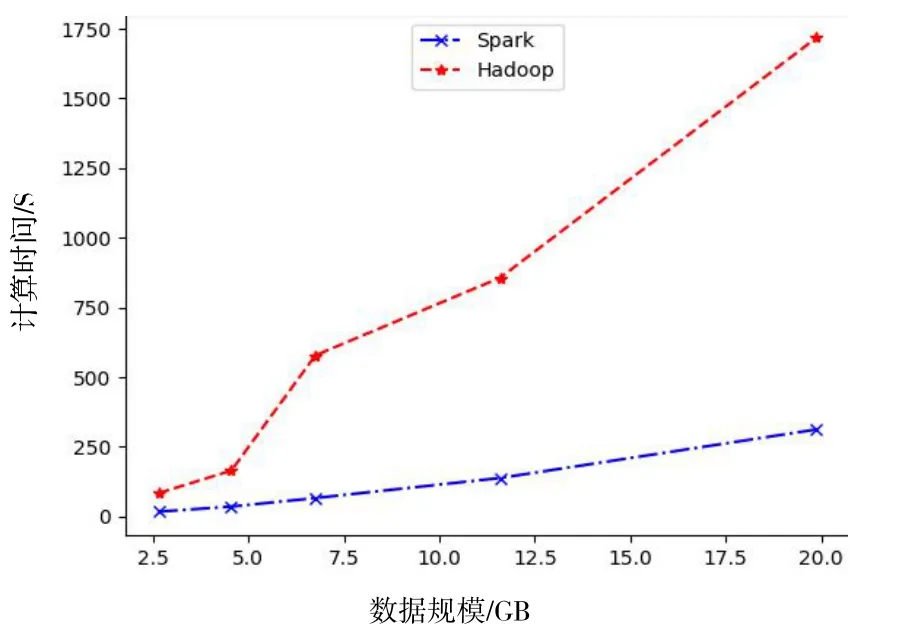
图4 Spark和Hadoop计算时间对比
另外,对于小规模数据而言,Spark集群内存计算优势明显,且计算任务无需排队。Hadoop集群由于需要不断进行迭代计算,每个MapReduce任务都需要重新从HDFS读写数据,而Spark则只需一次读取过程,因此,对HDFS的读写时间,Spark也要明显优于Hadoop。而对于大规模数据而言,Spark集群受限于CPU和内存容量限制,Worker的中间计算结果需要存储到外部存储,导致计算时间延长,计算效率明显降低。
4.结束语
本文讨论了Spark架构下的智慧教育云服务模型的构建,首先对个性化智慧教育云服务模型进行阐述,然后对Spark架构下的数据存储和服务模型进行了设计,同时,对Spark架构下的数据并行处理模式进行了阐述,最后,通过搭建仿真实验环境,分别对采用Spark和Hadoop的MapReduce框架的智慧校园云服务平台的数据并行处理能力进行对比测试,分析不同并行计算架构的并行计算性能。结果表明,采用Spark架构在计算时间和计算效率方面具有明显的优势。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
法制博览(2020年11期)2020-11-30 03:36:52
文苑(2020年4期)2020-05-30 12:35:12
新闻传播(2018年12期)2018-09-19 06:27:10
山东大学法律评论(2018年0期)2018-08-04 09:01:42
电信科学(2017年6期)2017-07-01 15:45:17
法制博览(2017年16期)2017-01-28 00:01:59
汽车与新动力(2016年6期)2017-01-04 10:50:48
湖湘论坛(2015年4期)2015-12-01 09:30:16
