
一种考虑兴趣偏好的Top-k众包开发者推荐方法
2021-07-02 07:29何亚东梁宏涛杜军威
山东科技大学学报(自然科学版) 2021年3期
于 旭,何亚东,梁宏涛,江 峰,杜军威
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
众包的概念由Howe在2006年提出[1],指以公开呼叫的形式将原本由特定代理人执行的任务外包给非特定的一群人。众包并非针对软件工程提出,但在软件开发中得到广泛应用,软件社区、众包软件平台[2]等在众包机制的推动下迅速发展。近年来涌现出TopCoder、ZhuBaJie等多个众包软件平台[3],通过整合共享资源、降低准入门槛的方式打破了传统的软件开发模式,为软件工程领域带来了新的发展契机[4]。
具体来说,众包平台的用户分为开发者和任务发布者两类:开发者在平台中开发感兴趣的软件任务,赢得丰厚的奖金;任务发布者通过平台找到合适的开发者完成自己的需求。平台开放的在线开发模式在为用户带来极大便利的同时,平台中积累的大量类型复杂、结构异质的数据资源导致其信息超载问题[5]日益严重,此时,想要快速准确地从平台中筛选出合适的开发者或开发任务是相当困难的。为了缓解信息超载问题,平台需要部署推荐系统完成任务与开发者之间的正确匹配。然而现有众包软件平台开发者推荐系统的研究[6-13]只考虑到少量平台特征,推荐时直接采用Top-k的推荐模式,导致推荐覆盖范围太大、推荐精度不高,并且对开发者冷启动问题的研究也不够深入。
针对上述不足,本研究对传统Top-k推荐模式进行改进,提出一种考虑兴趣偏好的Top-k推荐列表生成方法,将个体推荐问题转换为列别分类问题,为任务找到最合适的开发者,并提出两种解决方案有效处理开发者冷启动问题。具体来说,在充分考虑平台特征的基础上,首先提取任务特征和开发者列表综合能力特征;然后利用4种不同的开发者列表分类器实现两类特征的分类匹配,生成候选开发者推荐列表;最后根据候选列表内开发者的相似度情况完成最终列表推荐。
1 相关工作
1.1 传统推荐系统
为解决大数据背景下的信息超载问题,满足用户的各种个性化需求,推荐系统技术[14]应运而生。传统推荐系统能主动为用户寻找感兴趣的产品,减少用户被动选择的时间[15]。
推荐算法是影响推荐性能的最关键因素,现阶段常用的推荐算法可以分为基于内容、基于协同过滤和混合推荐算法3种[16]。基于内容的推荐建立在项目的内容信息上,从特征描述、用户画像等信息中提取用户兴趣生成推荐列表,由于这类模型对特征要求严格,因此特征提取不正确或不完全会严重影响模型性能[17-18]。基于协同过滤推荐的优点是不依赖物品内容,利用用户的各类反馈来挖掘用户深层次的偏好,推荐结果具有多样性,但是冷启动问题和数据稀疏性问题是协同过滤算法的瓶颈[19-20]。混合推荐综合考虑内容信息与交互反馈信息,具有更好的推荐性能,模型参数过多、训练时间过长、所需数据太多是这类算法的弊端[21-22]。
1.2 开发者推荐系统
众包软件平台开发者推荐与传统推荐差异较大,具体来说,对于已经完成交易的任务,开发者推荐系统不会将其再次推荐,并且传统推荐系统是以评分矩阵为基础的,不能直接套用到众包软件平台,因为得到的评分矩阵极度稀疏,推荐结果将大打折扣。
针对众包软件平台的特殊性,Tian等[6]通过隐含狄利克雷分布(Latent Dirichlet allocation,LDA)主题模型分析开发者的兴趣偏好,利用开发者兴趣和协作投票机制相结合的方式为任务推荐高质量的专家。Mao等[7]将开发者分为可靠开发者与合适开发者两类,结合开发者的声誉特征给出任务与开发者的匹配关系和开发者推荐列表。Shao等[8]通过引入神经网络框架以充分挖掘特征间交互关系,并结合LSI语义分析方法推荐开发人员。Ahmed等[9]从语义的角度总结出文本块,采用矩阵分解技术识别共享的潜在因子,找到可靠的回答专家。Zhu等[10]采用排序模型将平台推荐问题转化为排序问题,基于主题计算两个任务以及任务和开发人员之间的相似性生成推荐列表。谢新强等[11]提出多特征融合的开发者推荐模型,考虑开发者的动态行为并将模糊理论引入模型,利用矩阵增强的方法缓解数据稀疏和冷启动问题。此外,Wang等[12]和Fu等[13]分别提出针对开发人员的技能提高意识推荐框架和针对同类竞争关系的开发人员推荐模型。
2 一种考虑兴趣偏好的Top-k众包开发者推荐方法
2.1 方法概述
本研究所提方法框架如图1所示。推荐过程包括以下步骤:①爬取、收集众包软件平台数据;②对数据预处理之后进行特征提取,生成任务特征和开发者综合能力特征表示;③将两类特征输入分类器进行开发者匹配推荐;④根据匹配结果输出候选开发者推荐列表;⑤根据分类结果以及列表内开发者的相似度高低,将最合适的开发者列表推荐给开发任务,生成最终开发者推荐列表。

图1 一种考虑兴趣偏好的Top-k众包开发者推荐方法框架
2.2 任务特征
对于发布的软件任务,不同众包软件平台存在不同的发布标准,为了更全面地概括任务特征,提取6个特征来表示任务,如表1所示。

表1 任务特征选择
对于文本特征(标题、需求),采用LDA模型[23]获取任务的主题向量表示。LDA模型是一种基于贝叶斯理论的文档主题生成模型,将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数值信息。LDA模型公式:
(1)
其中:α、β为狄利克雷分布的语料级别先验参数;θ为文档-主题概率分布;φ为主题-单词概率分布;z、w为单词级别主题分布,z由θ生成,w由z和β共同生成;N为单词个数。θ、φ通过Gibbs采样[24]估计得到:
(2)
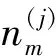
LDA(Q)→Zγ=(t1,t2,…,tT),γ∈Ql,l=1,…,n。
对于数值特征(发布日期、截止日期、奖金),为了消除特征量纲不同的影响,采用Z-score标准化方法对特征值进行处理:
(4)
其中,μ为所有样本数据的均值,σ为所有样本数据的标准差。
对于分类特征(技术标签),利用二进制向量进行特征转换,最终表示为0/1数值组成的n维向量,n的大小取决于技术标签的个数,每一个技术标签代表一个特征。
(5)
2.3 开发者综合能力特征
2.3.1 初始开发者推荐列表构造
传统的开发者推荐模型中,开发者推荐列表的构建是整个推荐流程的最后一步,根据模型输出结果,基于某个评价指标选取最优的前Top-k个开发者完成推荐[25],这种方式简单易行,使用比较普遍,但是Top-k推荐仅将开发者当作独立个体看待并推荐,不利于任务的高效、快速完成。因此,如果能在推荐之前找到开发者的隐藏关联喜好,并基于此完成对开发者的初步分类筛选,在具体应用时就可有针对性地进行组合,为新任务推荐专业能力最优、兴趣偏好相同的开发者,方便任务发布者对比选择。
考虑到众包软件平台的特点,为了更加合理、方便地生成推荐列表,本研究将开发者推荐列表的构造工作提前至建模阶段。分析发现,在同一个软件任务中提交过完成结果的开发者拥有相同隐藏兴趣偏好的概率比未参与过同一任务的开发者要高,因此这类开发者具备共同擅长某种开发技能或某类任务的条件,可以构成同一列表为同类新任务统一推荐。所以本研究将历史完成任务作为划分开发者列表的依据,将参与同一任务的开发者看作同一推荐列表成员,根据推荐所需要的列表大小,每个列表由k名开发者组成。
在任务完成后,ZhuBaJie平台和TopCoder平台均允许任务发布者对开发者的提交成果打分,按分数排名得出最终获胜者并分配奖金。认为得分越高的开发者越适合开发该任务,也越能代表该任务的兴趣偏好,所以在选取列表中的Top-k名开发者时,将参与该任务的开发者按得分从高到低的顺序加入列表,直到满足推荐所要求的列表人员数量为止。需要注意的是,ZhuBaJie平台只展示最终获胜者评分,因此在选取列表成员时,选用成果提交时间作为辅助指标,将最终获胜者加入列表后,其余开发者按提交时间由早到晚顺序加入列表。
2.3.2 开发者能力特征选择
为了更好地分析开发者能力,从是否由开发者主动提供和开发过程中是否动态变化的角度,将开发者特征分为静态特征和动态特征。与任务特征相同,选取3类特征作为开发者综合能力特征的输入,如表2。

表2 开发者特征选择
在静态特征中,对于文本特征(个人描述信息),考虑到开发者的自我描述信息普遍较短,不适合利用LDA处理方式,也不适合单独利用常见的Word2vec模型和Doc2vec模型处理,因此利用Arora等[26]提出的SIF模型来处理。SIF模型是一个无监督的短文本建模算法,主要思想是根据预设的超参数和词频给每个词向量赋予权重,然后使用PCA算法移除句向量中的无关部分。SIF模型公式为:
(6)
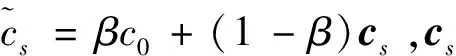
利用最大似然估计方法估计句向量cs,似然函数
(7)
取对数,最大化上式后,得到:
(8)
因此,个人描述集合W中的一篇描述i利用SIF模型最终表示为N维的特征向量Vi:
SIF(W)→Vi=(υ1,υ2,…,υN),i∈Wj,j=1,…,n。
(9)
对于静态数值型特征(加入时间)和分类型特征(技能标签、位置、属性),采用与任务模型相同的处理方式,分别利用公式(4)和(5)转化。
动态特征只有数值型特征,其中ZhuBaJie平台的标准化分数包括完成质量、服务态度、工作速度3种评分,TopCoder平台的标准化分数为所获历史评价总分,利用威尔逊模型和贝叶斯平均模型结合的思路解决分数的置信度问题[10]。剩余动态指标用公式(4)处理。
对于活跃度,两个平台均利用近3个月内完成任务数量表示,统计完成数量越多,证明表现越活跃;而诚信度在ZhuBaJie平台中直接使用其诚信系统展示的量化分数,Topcoder平台中为Reliability指标值;对于社交影响力,ZhuBaJie平台中利用开发者被收藏数来度量,而Topcoder平台通过开发者在相关平台的被关注量体现。
2.3.3 开发者能力加权融合
为了准确地包含列表内多个开发者的能力表示,基于群体决策规则[18]将列表内单个开发者的能力进行融合,生成开发者综合能力特征,获得开发者列表的整体偏好。采用加权融合策略,根据列表内不同开发者对整体偏好的贡献为每个开发者分配不同的权重。
具体来说,根据任务中开发者的得分情况为其赋予权重,得分最高者最适合开发该任务,可以分配相对大的权重,得分越低,权重占比也相应越少。加权综合能力特征定义如下:
Dlist=λ1·d11+λ2·d21+…+λk·dk1,λ1·d12+λ2·d22+…+
λk·dk2,…,λ1·d1i+λ2·d2i+…+λk·dki。
(10)
其中:λk为开发者权重因子,满足λ1+…+λk=1;dki为列表内第k个开发者的第i个特征(非分类型)的取值,分类型特征直接综合即可。
2.4 开发者列表分类器
开发者推荐系统的目的是实现任务与开发者推荐列表的精准匹配,本研究将推荐问题转化为分类问题,如图2所示。第一步,将每个任务本身的任务特征和与其匹配的开发者综合能力特征相结合(以3个任务为例,每个推荐列表选取3个开发者),作为分类器的正分类样本(分类标签为正);第二步,在3个任务之间进行两两交叉组合,构造新的负分类样本(分类标签为负,表示列表内开发者不适合开发该任务)。对于一个新任务而言,只需提取其任务特征,将任务特征与各个开发者综合能力特征进行交叉组合后输入分类器,根据输出结果便可知该任务适合与哪个开发者推荐列表匹配。

图2 分类匹配示意图
为了确保获得高质量的推荐结果,与C4.5决策树算法[27]、朴素贝叶斯(naive Bayesian,NB)算法[28]、支持向量机(support vector machine,SVM)算法[29]和因子分解机(factorization machine,FM)算法[30]进行分类比较,从中选取效果最佳的作为最终分类器。C4.5决策树算法不需要任何领域知识和参数假设,简单实用;NB算法速度快,过程简单,对缺失数据不敏感;SVM算法适合解决高维、非线性问题,泛化能力强;FM算法考虑特征之间的二阶关联关系,处理高维稀疏数据优势明显。
2.5 最终开发者推荐列表选择
经过列表分类器训练之后,根据分类结果得到某一个新任务和多个开发者推荐列表之间的匹配关系,但可能不可避免地得到多个合适的开发者列表,因此,为了进一步挑选开发者,达到推荐质量高、技能强、偏好相同的开发者列表的目的,利用Jaccard相似性系数[31]原理,通过技能标签特征计算列表内开发者的相似性,将候选开发者推荐列表(即分类结果为正的列表)中相似度最高的列表作为最合适的开发者列表进行推荐。公式如下:
(11)
其中,d1和d2表示同一列表内不同的两个开发者,DT1和DT2表示开发者技能标签。例如TopCoder平台中真实的开发者技能标签DT1= {′C#′,′SQL′, ′HTML5′, ′Python′, ′CSS′, ′PHP′},DT2= {′UML′, ′C++′, ′Python′, ′Java′, ′HTML5′},根据公式(11)可得相似度为2/9。
2.6 开发者冷启动问题解决方案
平台中新注册加入的开发者(即冷启动开发者)没有任何历史行为和任务评价信息,如何完成该类开发者的推荐一直是众包开发者推荐系统面临的难题。本研究从不同角度出发提出两种开发者冷启动问题的解决方案。基本思想和思路如下:
一是最大匹配度方案,利用平台活跃开发者的优点来完成辅助推荐,将新开发者推荐到活跃开发者和其自身均擅长的任务中。对于一个新任务,首先通过分类器后得到其与历史开发者列表的匹配程度,将匹配结果以概率形式输出,比较各列表属于正样本的概率(本文称为匹配度),匹配度越大,证明越适合开发该任务,然后从新开发者集合中找到与匹配度最大的历史开发者列表相似度最高的新开发者即可。
二是最大差异度方案,利用平台活跃开发者的缺点来完成反向推荐,将新开发者推荐到活跃开发者不擅长而其自身擅长的任务中。对于一个新任务,通过比较各列表属于负样本的概率(本文称为差异度),差异度越大,则证明越不适合开发该任务。然后找到与差异度最大的开发者列表相似度最低的新开发者即可。
计算冷启动开发者与历史开发者列表的相似度时,因为冷启动开发者缺少动态特征,因此仅利用静态特征构建两类开发者的静态能力模型,选用余弦相似性理论[32]计算相关相似度
(12)
其中,dnew和Dlist分别表示冷启动开发者和历史开发者推荐列表,dnew_static和Dlist_static分别表示冷启动开发者和开发者列表的静态能力特征。
2.7 算法
本研究提出的考虑兴趣偏好的Top-k众包开发者推荐方法的伪代码描述如下:
输入: 原始任务信息Info_Tt(t= 1,…,m1),原始开发者信息Info_Dd(d= 1,…,n1),新任务信息Info_Ttnew(tnew= 1,…,m2),新开发者信息Info_Ddnew(dnew=1,…,n2),C4.5算法、NB算法、SVM算法和FM算法的初始化参数信息Paraori。
输出: 推荐列表相似度值,k名开发者推荐列表。
Step 1TASK1= Task_feature_extraction(Info_Tt|t= 1,…,m1) ∥公式(1)~(5),利用原始任务信息,提取历史任务特征;
Step 2TASK2= Task_feature_extraction(Info_Ttnew|tnew= 1,…,m2) ∥公式(1)~(5),利用新任务信息,提取新任务特征特征;
Step 3DEV1= Developer_feature_extraction(Info_Dd|d= 1,…,n1) ∥公式(4)~(9),提取原始开发者信息,获得历史开发者能力特征;
Step 4DEV2= Developer_feature_extraction(Info_Ddnew|dnew= 1,…,n2) ∥公式(4)~(9),提取新开发者信息,获得新开发者能力特征;
Step 5DEVlist= Developer_list_feature_ fusion(DEV1) ∥公式(10),采用加权融合策略生成历史开发者综合能力特征;
Step 6Paranew= Developer_list_classification_training(TASK1,DEVlist,Paraori) ∥利用C4.5算法、NB算法、SVM算法和FM算法作为开发者列表分类器,训练模型参数;
Step 7 List_candidate= Developer_list_classification_prediction(TASK2,DEVlist,Paranew) ∥利用训练好的列表分类器,预测新任务与历史开发者列表的匹配程度,生成候选开发者列表;
Step 8 List_recommendation_history = Developer_list_similarity(List_candidate) ∥公式(11),计算候选列表内开发者相似度,为任务推荐相似度最高的历史开发者列表;
Step 9 List_recommendation_new = similarity(List_candidate,DEV2) ∥公式(12),计算历史开发者列表与新开发者的相似度;
Step 10 Return developerlist_history, developerlist_new。
3 实验
3.1 工具和数据集
利用Python中的Scrapy工具对ZhuBaJie平台(中国最大竞标软件服务众包平台https:∥www.zbj.com/)和TopCoder平台(国外最知名竞赛众包软件平台https:∥www.topcoder.com/)中的信息进行爬取。
ZhuBaJie平台的爬取思路为:①进入平台主页中的交易中心页面,在一级分类选项中选择与软件开发相关的分类(包括软件开发、网站开发和APP开发),在交易模式选项中选择竞标、比稿和竞赛模式,在需求状态选项中选择交易成功,设置成功后进入到已完成任务的页面;②进入每个任务页面,提取任务的相关信息和所有参与此项目的开发者信息(名称、完成任务量、位置等);③进入每个开发者页面,在人才档案页面中获取开发者注册时间、自我描述和被收藏量等信息,在交易评价页面提取标准化分数(完成质量、服务态度、工作速度)、近3月任务成交量等。
TopCoder平台的任务是以竞赛的形式发布,爬取与软件开发相关的任务(包括系统设计、代码编写等):①进入Past challenges页面,按最近完成排序后爬取所有相关的任务信息(任务标题、报酬等);②进入每个任务页面,在DETAILS页面中提取任务需求描述信息和任务发布日期;③进入REGISTRANTS页面,获取所有注册该任务的开发者信息(开发者名称、开发者所获名次和分数);④进入每个开发者页面,提取其所有静态和动态信息。
为了保证数据集质量,根据以下标准对历史数据进行过滤:①信息不完整和不相关的任务;②开发者数量少于5个的任务(即保证列表内开发者数量k≥5);③信息不完整和重复开发者。本研究使用的数据集如表3所示。

表3 实验数据集
3.2 评估开发者列表分类器
采用精确率(Precision)、召回率(Recall)和F1-Score作为标准[30]来评估分类器的性能。
按照2.4节的步骤对两个数据集中的数据进行交叉,构造操作重构数据集,然后设置4个训练比例{20%,40%,60%,80%},每次抽取不同训练比例的数据作为训练集,剩余数据作为测试集,对于每个训练比例,重复10次实验,取算术均值作为最终结果。
使用Python的scikit-learn库来实现分类。其中C4.5决策树调用DecisionTreeClassifier类,朴素贝叶斯调用MultinomialNB类,SVM模型调用LinearSVC类,FM模型使用libFM工具(http:∥www.libfm.org/)实现,LDA模型调用LdaModel类,使用gensim库实现。迭代次数均设为200。开发者数量k=5,权重分配为λ1=0.45,λ2=0.25,λ3=0.15,λ4=0.1,λ5=0.05。其他参数设置如表4。

表4 对比实验模型及参数设置
实验测得不同列表分类模型的性能如表5所示。
由表5可知,4种模型在TopCoder数据集上的3个指标性能比在ZhuBaJie数据集上普遍表现较好,因为按照本研究的数据筛选要求,TopCoder平台可利用的数据比ZhuBaJie平台多4倍,有利于模型训练和结果的预测。但是ZhuBaJie平台的任务需求、开发者简介等特征描述的非常详细,有利于精准建模,在一定程度上减小了最终分类性能的差距。

表5 不同分类模型性能比较
在2个数据集上,SVM模型的F1-Score指标比C4.5模型平均提升了1.27倍和1.19倍,比NB模型平均提升了1.24倍和1.26倍。FM模型和SVM模型各有所长,FM模型考虑二阶特征交互的方法比SVM模型表现好一些。
综上,没有一种模型在性能上完全优于其他模型。在8组实验中,FM模型的精确率指标取得了6次最佳,召回率取得了5次最佳,F1-Score指标取得了6次最佳。由此认为FM模型是整体表现最好的分类器。下文选用FM模型作为开发者列表分类器。
3.3 评估开发者推荐模型
采用准确率(accuracy)[11]和覆盖率(coverage)[11]作为推荐模型的评估标准。
历史开发者实验,训练集的原始数据集按80%和20%比例随机划分,将80%比例的数据用于训练,而后将其按照2.4节的步骤交叉构造后作为训练集。将20%比例中每个任务的任务特征与每个列表综合能力特征两两搭配后构建测试集。重复10次实验,将算术均值作为最终结果。
冷启动开发者实验,测试集挑选满足以下条件的任务:任务提交成果的开发者中存在新加入开发者,无任何历史评价信息,静态特征完整且最终所获评分位于前5名(本文认为前5名开发者适合开发该任务)。最终,ZhuBaJie数据集得到398个任务、477个新开发者,TopCoder数据集得到1 699个任务、2 101个新开发者。将挑选出的任务特征与历史开发者列表特征交叉搭配后构建测试集,剩余数据全部用于训练集。重复10次实验,将算术均值作为最终结果。
所用FM模型的开发者列表内成员数量k分别取值3、4、5。k=3时,λ1=0.6,λ2=0.3,λ3=0.1;k=4时,λ1=0.5,λ2=0.3,λ3=0.15,λ4=0.05;k=5时,λ1=0.45,λ2=0.25,λ3=0.15,λ4=0.1,λ5=0.05。NN[8]、LR[10]和MFD[11]的实验参数设置分别如表6~8。

表6 NN模型参数设置

表7 LR模型参数设置

表8 MFD模型参数设置
4个模型的准确率对比如图3所示。可以看出:由于NN模型忽略开发者侧的众多特征,仅利用任务侧特征完成推荐,效果最差;与LR模型相比,MFD模型利用开发者行为特征将矩阵空缺项填补,减少了数据稀疏性带来的影响,提升效果比较明显。本研究所提的利用FM模型分类预测的方法在两个数据集上都比采用其他模型的方法有更好的表现,证明本方法的推荐思路是可行的,擅长同一类型任务的开发者之间不是独立的,在技能、兴趣等方面拥有较强的关联性。

图3 准确率对比
4个模型的覆盖率对比如图4所示,可以看出:在两个数据集上MFD模型的覆盖率都比较低,而NN模型的覆盖率较其准确率提升较大,本研究所提FM模型的平均覆盖率是NN模型的1.02倍、LR模型的1.28倍、MFD模型的1.41倍,证明了本研究方法的有效性,可以兼顾到更多的开发者,而非仅仅“热门”开发者。
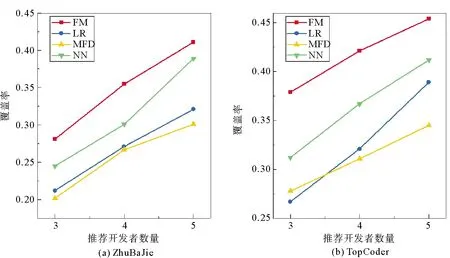
图4 覆盖率对比
冷启动解决方案结果如图5所示,可以看出:①随着推荐冷启动开发者数量增加,两种解决方案都可在一定程度上缓解冷启动问题。综合比较,本研究所提方法在最大匹配度方案下的冷启动处理能力优于最大差异度方案;②总体推荐性能达到预期标准,覆盖率指标取得的效果要优于准确率指标。ZhuBaJie数据集的平均准确率为0.405、平均覆盖率为0.462,TopCoder数据集平均准确率为0.388、平均覆盖率为0.407,证明本研究所提方法结合两种冷启动解决方案能够较好地处理新加入开发者的推荐问题,这对一个完善的众包软件平台开发者推荐系统来说至关重要。

图5 冷启动解决方案对比
4 总结与展望
为充分提取众包软件平台中任务与开发者的异构性特征,提出一种考虑兴趣偏好的Top-k众包开发者推荐方法,并将开发者个体推荐问题转化为开发者列表分类问题,实现新任务与不同类型开发者之间的精准推荐。相较于传统的基于内容的开发者方法,本方法可以将内容与评分有效结合,更好地解决数据稀疏和开发者冷启动问题。对爬取的ZhuBaJie和TopCoder平台数据集进行了实验,验证了本研究方法的有效性。在未来的工作中,将对平台冷启动进行深入研究,进一步提升推荐算法的性能。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23
汽车实用技术(2021年17期)2021-09-23
客联(2021年2期)2021-09-10
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
经济(2016年29期)2016-12-27
CHIP新电脑(2016年3期)2016-03-10
中学生数理化·中考版(2015年10期)2015-09-10
小说月刊(2012年3期)2012-05-08
