
基于对抗学习的强PUF安全结构研究
2021-06-30 05:27李艳刘威孙远路
网络与信息安全学报 2021年3期
李艳,刘威,孙远路
基于对抗学习的强PUF安全结构研究
李艳,刘威,孙远路
(信息工程大学,河南 郑州 450001)
针对强物理不可复制函数(PUF,physical unclonable function)面临的机器学习建模威胁,基于对抗学习理论建立了强PUF的对抗机器学习模型,在模型框架下,通过对梯度下降算法训练过程的分析,明确了延迟向量权重与模型预测准确率之间的潜在联系,设计了一种基于延迟向量权重的对抗样本生成策略。该策略与传统的组合策略相比,将逻辑回归等算法的预测准确率降低了5.4%~9.5%,低至51.4%。结合资源占用量要求,设计了新策略对应的电路结构,并利用对称设计和复杂策略等方法对其进行安全加固,形成了ALPUF(adversarial learning PUF)安全结构。ALPUF不仅将机器学习建模的预测准确率降低至随机预测水平,而且能够抵御混合攻击和暴力破解。与其他PUF结构的对比表明,ALPUF在资源占用量和安全性上均具有明显优势。
物理不可复制函数;对抗样本;延迟向量;对抗学习PUF
1 引言
物理不可复制函数(PUF,physical unclonable function)作为一类独特的轻量级硬件安全机制,以其防篡改、低资源占用等特点,在密钥生成、身份识别和轻量级认证等领域拥有广阔的应用前景。
尽管PUF被定位为无法复制,但研究表明PUF能够通过机器学习的方法建模。逻辑回归(LR,logistic regression)、支持向量机(SVM,support vector machine)、进化策略(ES,evolution strategy)、深度学习(DL,deep learning)和集成学习(EL,ensemble learning)均能攻击一种或数种PUF[1-3]。为了应对机器学习建模带来的安全威胁,研究者设计了多种PUF结构,如异或仲裁器PUF、混淆类PUF等,但其中绝大多数被证明无法抵御机器学习攻击[4-5]。机器学习已成为强PUF最大的安全威胁之一。
自2005 年Lowd 等首次提出对抗学习(adversarial learning)的概念以来,机器学习算法自身的安全性就引起研究者的关注,对抗机器学习逐渐成为人工智能领域的研究热点之一。目前,针对深度神经网络的对抗攻击已经对人工智能在图像识别、自动驾驶等领域的应用构成了严重威胁[6]。
为了抵御PUF的机器学习建模攻击,本文基于对抗机器学习理论定义了强PUF的对抗机器学习模型,在模型框架下设计了一种基于延迟向量权重的对抗策略。根据新策略设计了对抗学习PUF(ALPUF,adversarial learning PUF)电路结构,并通过实验验证了新策略和ALPUF在抵御机器学习攻击时的优势。
2 PUF建模与对抗机器学习
2.1 PUF建模
仲裁器PUF是广泛使用的强PUF之一,异或仲裁器PUF、受控PUF和混淆类PUF等安全结构使用仲裁器PUF作为基本组件。
仲裁器PUF采用多路选择器级联结构,如图1所示,激励向量的每一位对应控制一级多路器,用于选择平行路径或者交叉路径,输入信号沿两条不同路径传输,最终由仲裁器比较传输时延,形成响应。激励和响应作为PUF的输入输出,被合称为激励响应对(CRP,challenge response pair)。
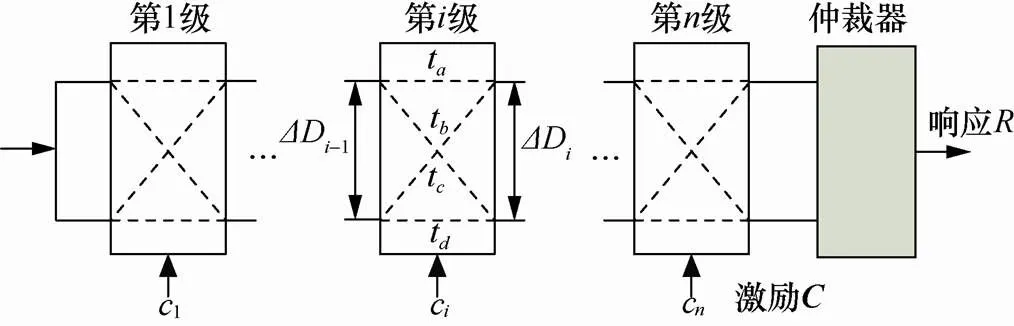
图1 仲裁器PUF电路结构
Figure 1 PUF circuit structure of arbitrator

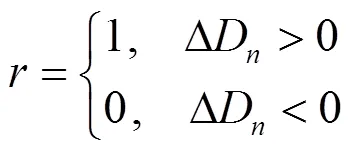

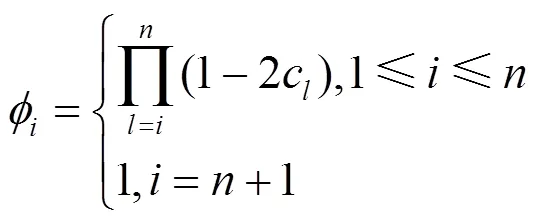
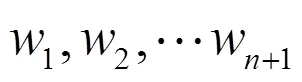
2.2 对抗机器学习
2006年,机器学习系统的攻击分类和对抗建模的概念首次明确被提出,Biggio等[7]在2014年进一步完善了机器学习的对抗模型,提出从对抗目标、对抗知识、对抗能力、对抗策略4方面来建立模型。早期的对抗方法主要针对SVM、朴素贝叶斯、聚类和特征选择等机器学习方法[8],而目前研究热点主要针对人工神经网络。
按照对机器学习模型造成的安全损害可以将对抗机器学习方法分为完整性攻击、可用性攻击和隐私窃取攻击;按照攻击目标阶段可分为针对训练过程的攻击和针对测试/推理过程的攻击。投毒攻击属于针对训练过程的攻击,攻击者通过注入一些精心伪造的对抗样本(adversarial sample),破坏原有的训练数据的概率分布,从而使训练出的模型的分类或者聚类精度降低,达到破坏训练模型的目的。
对抗样本指的是一类人为构造的样本,通过对原始样本添加特定的扰动,使分类模型对新构造的样本产生错误的判断。对抗样本生成算法主要有快速梯度(fast gradient sign method)攻击和雅克比映射攻击(Jacobian-based saliency map attack)和深度欺骗(deep fool)攻击[9]。快速梯度攻击的主要思想是寻找机器学习模型的梯度变化最大的方向,按照此方向添加扰动,导致模型进行错误的分类。
2.3 抗机器学习的PUF研究现状
从早期的异或PUF、受控PUF到目前广泛研究的混淆类PUF,研究人员为对抗机器学习建模设计了多种PUF结构。但是,异或PUF和受控PUF被证明易受到机器学习和侧信道混合攻击[10]。2019年,Delvaux[5]对新提出的PUF安全结构进行了分析,针对性地设计了攻击方法,指出混淆类PUF难以抵御机器学习建模攻击。
对抗机器学习在PUF安全领域的应用研究相对较少,2019年,Wang等[11]提出了针对PUF建模的对抗攻击方法,设计了PUF投毒攻击的机制,实验结果表明,基于投毒的对抗攻击将LR的预测准确率由99.89%降至56.7%,将CMA-ES的预测准确率由99.97%降至65.68%,但对抗样本生成策略主要基于设计者的经验,缺乏相关的理论分析,且实验测试对象规模相对较小,只涵盖了64 bit的PUF。
2018年,Prado等[12]将PUF的所有CRP按汉明重量分类后按类别对外提供,通过CRP的对抗性选择将AdaBoost算法的预测准确率由89%降至74%,但并未提及该策略的物理实现方法。
利用对抗学习提高PUF的建模难度,降低机器学习模型的预测准确率,是保护PUF应用安全的有效途径。但目前的研究尚存在对抗样本生成策略缺乏理论支持、对抗效果未达到最优性能、物理实现方式考虑不足等问题。
3 基于延迟向量权重的对抗样本生成
3.1 强PUF的对抗机器学习模型
在对抗学习领域,针对分类问题的对抗样本生成策略通常基于梯度上升算法,通过运算不断调整样本中的输入值,最终生成最优的有毒样本。但是,目前的对抗模型和样本生成算法无法适用于生成PUF对抗样本,主要原因有:PUF的激励是布尔向量,无法在其原有值上再叠加较小的数值,只能做翻转操作;攻击模型中通常设定攻击者可以物理接触PUF,激励由攻击者选定,样本中的激励无法修改。因此,需要重新建立适用于PUF安全领域的对抗模型,在模型框架下设计新样本生成策略。
基于Biggio的对抗机器学习理论,结合强PUF的特性、应用场景和攻击模型设定,给出强PUF对抗机器学习模型。
模型1 强PUF对抗机器学习模型
对抗目标:以破坏机器学习算法的可用性为主要目的,通过向PUF的CRP集中加入伪造的CRP,即有毒数据,在训练阶段阻碍机器学习算法生成正确训练模型。
具备知识:对抗者作为PUF安全防护方,知悉PUF相关的所有知识,包括PUF模型、训练数据、PUF延迟向量等。
拥有能力:对抗者可以对PUF结构、物理实现等进行改进,具备在机器学习算法运行前修改训练集、投放有毒数据的能力,且不受传统对抗方法对训练集中有毒数据所占比例的限制(传统方法为了达到最优性能,有毒数据在训练数据集中比例通常小于20%)。
对抗策略:以大幅降低机器学习建模方法的预测准确率为目的,兼顾实现时的资源占用量设计最优策略,根据激励各位的组合运算结果调整响应值,生成有毒CRP。PUF的有毒数据生成与传统对抗方式不同,在攻击场景中,机器学习建模攻击者被认为能物理接触PUF并拥有控制权,激励由攻击者选定,对抗者无法对激励进行调整,因此只能通过修改响应的方式篡改真实CRP,达到降低模型预测准确率的目的。
强PUF对抗机器学习模型要求使用者掌握目标PUF的结构、参数信息和训练数据,通过这些信息构造对抗样本,属于白盒模型。该模型通过产生有毒CRP的方式,增加机器学习算法预测PUF参数的难度,降低算法预测准确率,具有一定的普适性。
3.2 对抗样本生成
生成合适的对抗样本是决定对抗效果的关键。PUF建模属于机器学习中的分类问题,逻辑回归、支持向量机和深度学习等方法被广泛应用于仲裁器类PUF的建模。其中,LR是众多PUF攻击方法中研究最多、使用最广泛的方法之一。逻辑回归攻击仲裁器PUF,按照式(6)对训练集中的CRP使用梯度下降法,学习出延迟向量即完成建模。
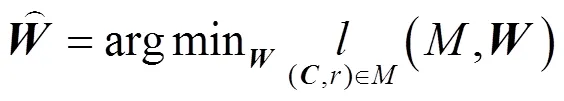
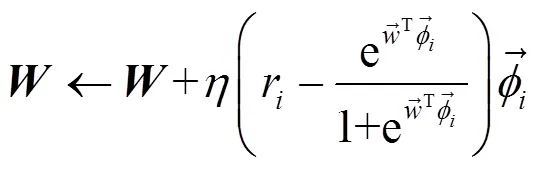
响应的翻转条件是策略设计的主要内容,翻转条件可以与激励无关,也可以是中一位或多位的运算结果,设计时主要遵循以下原则。
原则1 选择权重小的延迟分量所对应激励位作为基本元素,可以获得更好的对抗效果。原因是尽管中各延迟分量同步更新的数值完全相同,但对中绝对值较小的分量来说,该数值产生的影响更大,而对绝对值较大的分量,错误更新的影响则相对较小。
原则2 策略中同一激励位触发翻转的条件需保持一致。即如设定某激励位c为1时触发响应翻转,则不能同时将该位为0作为触发翻转条件。原因是同时作为翻转条件意味着所有CRP均翻转,这将导致机器学习算法训练得到只是参数符号相反的正确模型。
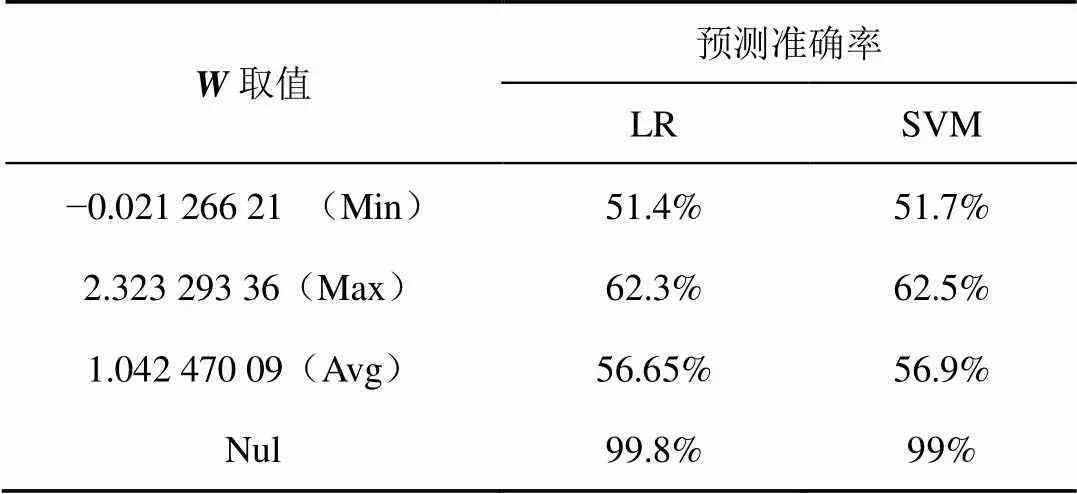
表1 延迟向量权重与策略对抗效果的关系
使用对抗样本后,LR的预测准确率由未使用时的99.8%下降至62.3%以下,SVM的预测准确率由未使用时的99%下降至62.5%以下。其中,选择中权重小的分量所对应激励位作为翻转条件,可以进一步将预测准确率降至51.4%和51.7%。
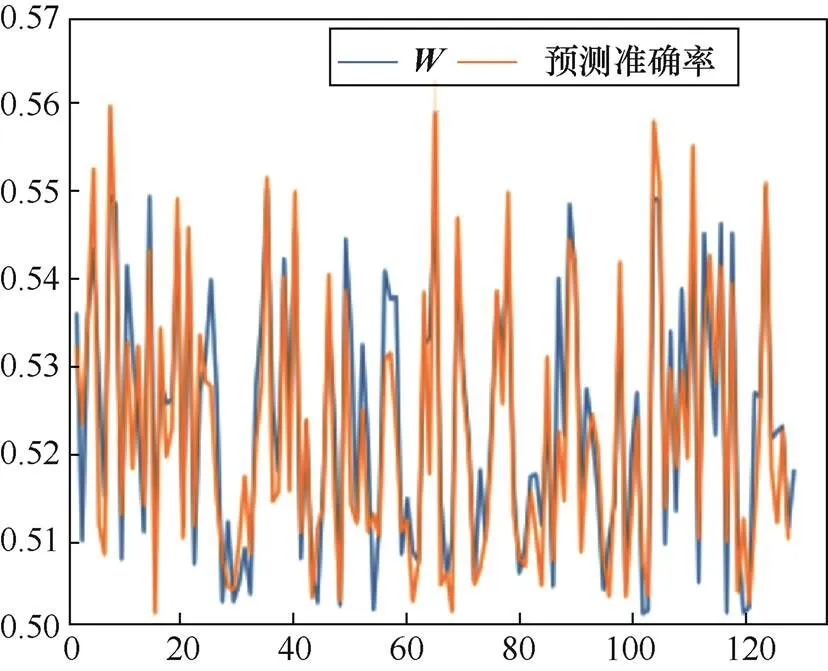
图2 W权重与预测准确率对比
Figure 2 Comparison ofweight and prediction accuracy
算法1 基于延迟向量权重的对抗样本生成算法
3.3 生成策略性能对比
文献[11]中提出了随机翻转、组合翻转等对抗样本生成策略,这些策略与本文策略的最大区别是没有参考延迟向量的权重。
随机翻转策略是将响应按照一定比例随机翻转,翻转行为和PUF的激励无关,由设置的随机数发生器决定。
组合翻转策略是将激励的不同位进行逻辑运算,由运算得到的最终结果决定是否翻转响应。
在相同条件下对4种策略进行测试,结果如表2所示,可以看出,随机翻转性能最好,其次是基于延迟向量权重的生成策略性能,基本可以使LR和SVM的预测准确率降低至随机预测的水平,组合翻转策略的性能随着参与逻辑运算位所对应的延迟向量权值变化。
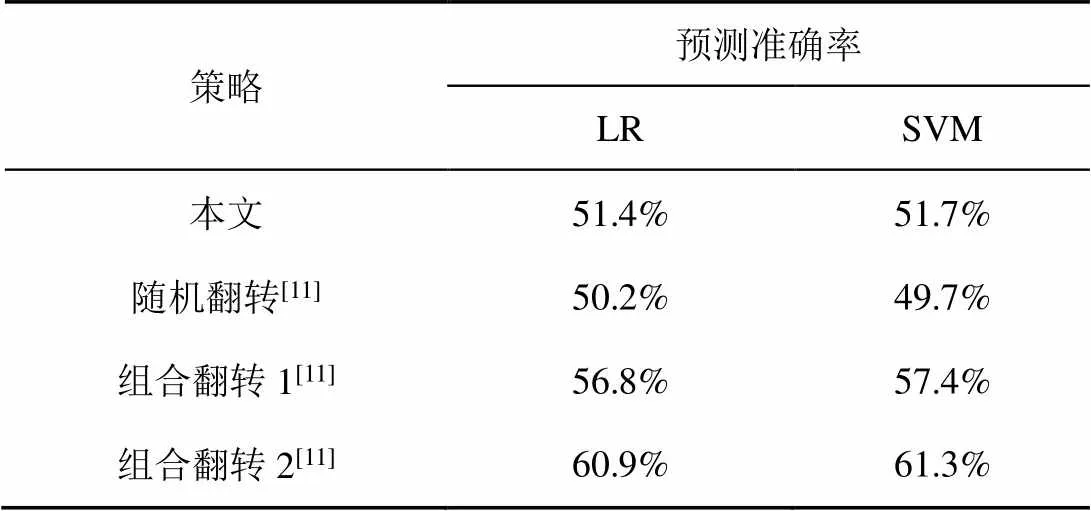
表2 不同对抗样本生成策略的效果对比
随机策略尽管性能最好,但其抵御机器学习的能力来自随机数发生器,对手无法攻破的同时,使用者也难以判定,因此难以实用。组合策略中选取了不同权重延迟参数对应的激励位,根据原则1判断,其性能介于最大权重和最小权重对应预测准确率之间。
根据对抗样本的可转移性理论,被一种机器学习算法错分类的对抗样本对其他算法也适用,使用本策略生成对抗样本,也能够降低其他机器学习算法的预测准确率。表2的数据结果显示,4种策略对SVM和LR两种算法都显示出了性能近似的对抗效果。
3.4 投毒比例影响分析
按照强PUF对抗学习模型,对抗者可向训练集中投放任意比例的有毒数据,根据PAC理论,有毒数据比例对机器学习算法的预测准确率具有决定性的影响。
根据实验结果可以看出,预测准确率受到投毒比例和对抗数据生成策略两方面的影响,投毒比例很大程度上决定了分类算法的预测准确率。但在相同比例的情况下,不同策略的对抗效果存在较大差距。例如,分别采用组合翻转和本文策略生成有毒数据占25%的训练集对LR算法进行训练,得到模型的预测准确率分别是78.2%和73%。文献[11]中所论述的不同组合策略对预测准确率的影响,其实主要由投毒比例不同所导致。

表3 训练集成分和对抗策略对预测准确率的影响
4 对抗学习PUF
4.1 基于对抗策略的PUF结构
对抗样本生成策略必须能在满足低资源占用量的前提下形成物理电路结构,才能够保证策略能够推广应用。

图3 基于对抗策略的PUF电路结构
Figure 3 PUF circuit structure based on countermeasure strategy
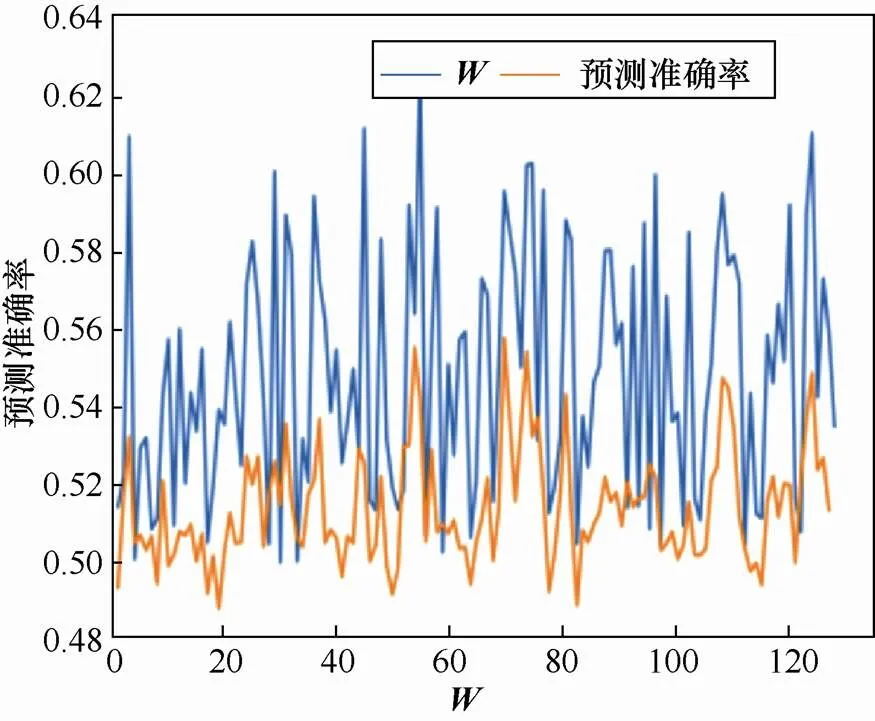
图4 按C测试W权重与预测准确率对比
Figure 4 Testweight and prediction accuracy according to
4.2 抗复杂攻击的对抗学习PUF
机器学习并非强PUF的唯一威胁,一些复杂的攻击方法仍可能威胁到基于对抗策略的PUF。例如,多数抗机器学习建模的PUF结构被证明难以抵御的机器学习/侧信道混合攻击[13]。以异或PUF为例,因为构成异或PUF的仲裁器PUF用触发器实现仲裁,响应为“1”时触发器发生翻转,其功耗远高于响应为“0”不发生翻转时。测量供电引脚上的电压/电流值,就能够确定响应值。测量得到响应为“1”的仲裁器总数后,可以使用机器学习对异或PUF建模。
混合攻击也能成功攻击对抗PUF。在功耗分析面前,基于对抗策略的PUF的真实响应值无法隐藏,攻击者可以轻易剔除或者转化有毒数据。为了防止混合攻击,可以通过增加电路的对称性以防止侧信道信息泄露。在实现时对应设置两个触发器,两条路径的信号分别进入两个触发器,形成两个相反的值,无论响应为何值,功耗都一样,以此防御混合攻击。
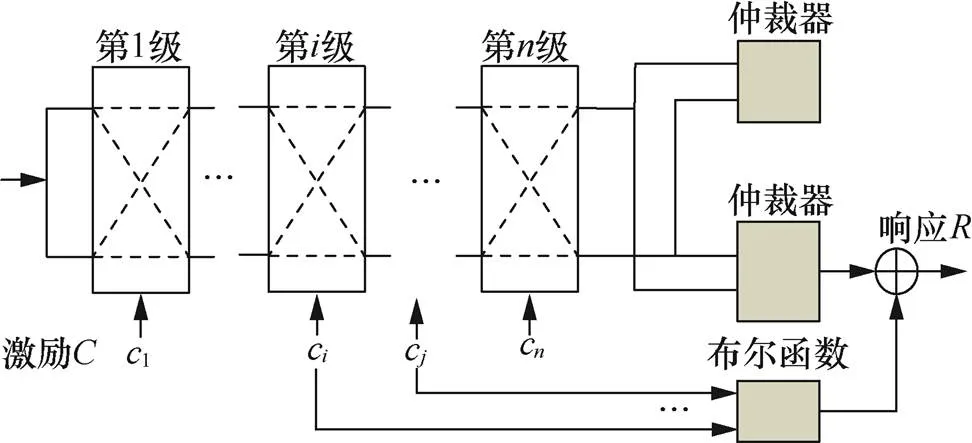
图5 ALPUF电路结构
Figure 5 ALPUF circuit structure
与近年来提出的PUF安全结构对比,ALPUF在对抗性能和资源占用量等方面均具有优势。表4中列出了PUF安全性和硬件资源占用上的对比。资源占用以基本的仲裁器PUF为标准,列出实现对应结构额外所需的组件,从表4中可以看出,ALPUF在仲裁器PUF的基础上只增加了3个异或逻辑,资源占用量最低。安全性评估中使用逻辑回归算法攻击所列出的PUF,对比预测准确率。其中,对ALPUF的预测准确率仅为51.4%,接近随机预测,远低于其他PUF结构,而且ALPUF的对称结构能够抵御功率混合攻击,由此可以看出ALPUF 具备更强的对抗机器学习攻击的能力。
ALPUF不仅能单独使用,而且可以作为基本组件,替代仲裁器PUF参与组成复杂的PUF安全结构。例如,将异或PUF中的仲裁器PUF换成ALPUF,可进一步提高其抗机器学习的能力。以2-XOR PUF为例,相同条件下使用LR建模的预测准确率为99.2%,将组件替换为ALPUF后,LR建模的预测准确率下降至随机预测水平。
5 结束语
为了提高强PUF抵御机器学习攻击的能力,本文基于对抗学习理论定义了强PUF对抗学习模型。在模型框架下,本文设计了基于延迟向量权重的对抗样本生成策略,按照新策略设计了ALPUF电路结构。实验结果表明,与现有策略相比,使用新策略生成的对抗样本能将LR、SVM等分类算法的预测准确率降至随机预测水平;ALPUF在低资源占用的前提下,能够抵御复杂的机器学习建模攻击。

表4 PUF安全性及硬件资源占用上的对比
[1]SAHOO D P, NGUYEN P H, MUKHOPADHYAY D, et al. A case of lightweight PUF constructions: cryptanalysis and machine learning attacks[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2015, 34(8): 1334-1343.
[2]LIU Y, XIE Y, BAO C, et al. A combined optimization-theoretic and side-channel approach for attacking strong physical unclonable functions[J]. IEEE Transactions on Very Large Scale Integration Systems, 2017, 26(1): 73-81.
[3]RÜHRMAIR U, SÖLTER J, SEHNKE F, et al. PUF modeling attacks on simulated and silicon data[J]. IEEE Transactions on Information Forensics & Security, 2013, 8(11): 1876-1891.
[4]YE J, GUO Q, HU Y, et al. Modeling attacks on strong physical unclonable functions strengthened by random number and weak PUF[C]//2018 IEEE 36th VLSI Test Symposium. 2018: 1-6.
[5]DELVAUX J. Machine-learning attacks on PolyPUFs, OB-PUFs, RPUFs, LHS-PUFs, and PUF–FSMs[J]. IEEE Transactions on Information Forensics and Security, 2019,14(8): 2043-2058.
[6]宋蕾, 马春光, 段广晗. 机器学习安全及隐私保护研究进展[J]. 网络与信息安全学报, 2018, 4(8): 1-11.
SONG L, MA C G, DUAN G H. Machine learning security and privacy: a survey[J]. Chinese Journal of Network and Information Security, 2018, 4(8): 1-11.
[7]BIGGIO B, NELSON B, LASKOV P. Poisoning attacks against support vector machines[C]//ICML'12.2012. 1467 -1474.
[8]JAGIELSKI M, OPREA A, BIGGIO B, et al. Manipulating machine learning: poisoning attacks and countermeasures for regression learning[C]//2018 IEEE Symposium on Security and Privacy. 2018. 19-35.
[9]BIGGIO B, ROLI F. Wild patterns: ten years after the rise of adversarial machine learning[J]. Pattern Recognition, 2018, 84:317-331.
[10]BECKER G T. The gap between promise and reality: on the insecurity of XOR arbiter PUFs[C]//Cryptographic Hardware and Embedded Systems. 2015: 535-555.
[11]WANG S J, CHEN Y S, KATHERINE L, et al. Adversarial attack against modeling attack on PUFs[C]//DAC2019. 2019:1-6.
[12]PRADO H, PATIL C. Defeating strong PUF modeling attack via adverse selection of challenge-response pairs[C]//AsianHOST2018. 2018: 25-30.
[13]XU X, MAHMOUD A, MAJZOOBI M, et al. Efficient power and timing side channels for physical unclonable functions[C]//International Workshop on Cryptographic Hardware and Embedded Systems. 2014: 476-492.
[14]GAO Y, LI G, MA H, et al. Obfuscated challenge-response: a secure lightweight authentication mechanism for PUF-based pervasive devices[C]//Workshop in Conjunction with IEEE International Conference on Pervasive Computing and Communications. 2016: 1-6.
[15]JING Y, YU H, LI X. RPUF: physical unclonable function with randomized challenge to resist modeling attack[C]//Hardware-oriented Security & Trust. 2016: 1-6.
[16]徐金甫, 吴缙, 李军伟. 基于敏感度混淆机制的控制型物理不可复制函数研究[J]. 电子与信息学报, 2019, 41(7): 1601-1609.
XU J F, WU J, LI J W. Research on the control physical non-clonable function based on sensitivity cofounding mechanism[J]. Journal of Electronics and Information Technology, 2019, 41(7): 1601-1609.
Research on security architecture of strong PUF by adversarial learning
LI Yan, LIU Wei, SUN Yuanlu
Information Engineering University, Zhengzhou 450001, China
To overcome the vulnerability of strong physical unclonable function, the adversarial learning model of strong PUF was presented based on the adversarial learning theory, then the training process of gradient descent algorithm was analyzed under the framework of the model, the potential relationship between the delay vector weight and the prediction accuracy was clarified, and an adversarial sample generation strategy was designed based on the delay vector weight. Compared with traditional strategies, the prediction accuracy of logistic regression under new strategy was reduced by 5.4% ~ 9.5%, down to 51.4%. The physical structure with low overhead was designed corresponding to the new strategy, which then strengthened by symmetrical design and complex strategy to form a new PUF architecture called ALPUF. ALPUF not only decrease the prediction accuracy of machine learning to the level of random prediction, but also resist hybrid attack and brute force attack. Compared with other PUF security structures, ALPUF has advantages in overhead and security.
strong physical unclonable function, adversarial sample, delay vector, adversarial learning PUF
TP393
A
10.11959/j.issn.2096−109x.2021026
2020−02−04;
2020−07−02
刘威,shivaree@163.com
国家自然科学基金(61871405, 61802431)
The National Natural Science Foundation of China (61871405, 61802431)
李艳, 刘威, 孙远路. 基于对抗学习的强PUF安全结构研究[J]. 网络与信息安全学报, 2021, 7(3): 115-122.
LI Y, LIU W, SUN Y L. Research on security architecture of strong PUF by adversarial learning [J]. Chinese Journal of Network and Information Security, 2021, 7(3): 115-122.
李艳(1988− )女,河南郑州人,信息工程大学讲师,主要研究方向为网络空间安全。

刘威(1982− )男,湖北随州人,信息工程大学讲师,主要研究方向为硬件安全。
孙远路(1974− )男,河南商丘人,信息工程大学副教授,主要研究方向为管理科学与工程。

猜你喜欢
环球时报(2022-07-13)2022-07-13
新高考·高一数学(2022年3期)2022-04-28
环球时报(2022-03-14)2022-03-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
兵团工运(2019年6期)2019-12-13
电子制作(2018年19期)2018-11-14
电影(2018年8期)2018-09-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
仲裁研究(2015年4期)2015-04-17
