
基于多视图半监督集成学习的人体动作识别算法
2021-06-30 05:49陈圣楠范新民
网络与信息安全学报 2021年3期
陈圣楠,范新民
基于多视图半监督集成学习的人体动作识别算法
陈圣楠1,2,范新民1,2
(1. 福建师范大学,福建 福州 350117;2. 网络安全与教育信息化福建省高校工程研究中心,福建 福州 350117)
移动设备上难以获取大量标签样本,而训练不足导致分类模型在人体动作识别上表现欠佳。针对这一问题,提出一种基于多视图半监督集成学习的人体动作识别算法。首先,利用两种内置传感器收集的数据构建两个特征视图,将两个视图和两种基分类器进行组合构建协同学习框架;然后,根据多分类任务重新定义置信度,结合主动学习思想在迭代过程中控制预测伪标签结果;使用LightGBM对扩充后的训练集进行学习。实验结果表明,算法的精确率、召回率和F1值较高,能稳定、准确地识别多种人体动作。
人体动作识别;半监督学习;小样本;LightGBM
1 引言
随着电子信息技术的发展,各类移动智能终端,如智能手机、智能手表在价格、计算能力、电池寿命等方面有了显著提升,而其应用领域也由单一的功能使用拓展到了运动管理、医疗保健、智能家居和安全监控等[1],拥有巨大的潜在市场需求和影响。这类移动设备大多内置加速度计、陀螺仪、肌肉电传感器等多种传感器,可在特定场景下产生并收集不同的数据,进而分析识别人体动作,判断人们的活动状态。
目前,人体动作识别算法在应用时仍需依赖大量的标签数据,大规模的标注工作不仅耗费了大量的人、财、物力,数据质量也难以保障,降低了人体动作识别算法的推广价值。为解决这一问题,充分利用有限的标签数据和大量无标签数据,在智能移动终端的多传感器场景下,本文提出一种基于多视图半监督集成学习的人体动作识别算法,算法分为两个阶段。
(1)伪标签数据生成。利用不同传感器产生的标签数据构建多视图下的特征,利用协同训练框架扩充训练集,根据多标签场景定义新的置信度以改进协同训练框架中的标签生成策略,同时利用主动学习策略增加样本的复杂性。
(2)多标签集成学习。将LightGBM模型应用于扩充后的训练集以识别多种人体动作。
实验结果发现,本文算法能够克服训练样本标签数据不足、分类不平衡的问题,稳定、准确地识别多种人体动作,在各项指标上表现良好。算法可直接部署在计算资源有限的移动终端,具有广阔的应用前景。
2 相关工作
如前所述,人体动作识别技术在健康监测、智能家居、军事训练等领域有重要的应用前景。根据传感器与人体的位置关系,可将人体动作识别分为非接触式算法和接触式算法[2]。
非接触式算法可进一步分为基于视觉图像的和基于射频信号的。前者主要使用摄像头和光学传感器捕捉人体动作[3-5],对视角、照明条件、温度的干扰较为敏感,且在采集时对用户的隐私造成一定的入侵,不适用于日常生活或长时间追踪。后者主要基于Wi-Fi系统分析无线信号特性进行工作[6-7],需要使用外置的特定工具和专用网卡,因此多用于室内场景下的动作识别。
接触式算法主要以佩戴在人体特定部位的传感器收集到的数据作为研究对象。这类算法不受光线、障碍物的影响,能相对获得用户的活动数据,同时兼顾用户隐私的保护,有利于长时间的监测。Cao等[8]利用手机中的IMU传感器,对手臂运动轨迹进行还原,并联合RNN和DTW对多种手臂动作分类。Liu等[9]利用DTW和姿态度量计算测试动作序列和各个动作模板序列之间的相似百分比对人体动作进行分类。殷晓玲[10]等提取了手机加速度计上时域特征,并训练层次支持向量机识别人体动作。Wang等[11]从使用场景、活动类型、复杂程度分析归纳了数据集,并测试了多种分类器的分类性能。Alejandro等[12]利用CNN从加速度计的原始数据中学习特征提升人体动作识别的性能。张儒鹏等[13]对CNN中的卷积结构进行优化,并将其与长短神经网络进行融合,能更精准捕捉原始数据中的动作序列。
虽然现有研究在人体动作识别领域取得了诸多成果,但大多是建立在数据集标注完备的情况下,鲜有考虑现实中广泛存在的无标签数据对算法的影响。本文提出一种基于多视图半监督集成学习的算法,旨在利用有限的标签数据和大量无标签数据使分类模型得到充分训练,继而提升识别的精确率。
3 算法框架
本文将基于可穿戴设备的人体动作识别问题视为一个多标签分类的问题。可穿戴设备通常内置有多种传感器,可从多角度收集使用者的行为数据,构成多组特征。简单的方法主要是将多组特征直接拼接成一个视图,然后使用分类算法建模。但这种方法不仅容易忽略视图之间潜在的互补、判别信息,还可能由于维度太多导致维灾。针对这一情况,本文提出一种半监督集成学习的方法,整体算法框架如图1所示。首先,对不同传感器采集的数据进行预处理和特征工程。特征工程主要是对平滑、去噪后的传感器信号进行切片操作,从时域、频域角度分析波形特点。然后,利用协同训练框架生成伪标签集扩充初始训练集。最后,利用扩充后的训练集重新训练LightGBM模型进行预测获得最终的识别结果。
3.1 第一阶段:主动协同训练框架
本文在协同训练框架的基础上叠加主动学习,以此扩充初始训练集样本。协同训练的思想是在两个视图上利用少量标签训练分类器,然后每个分类器从无标签样本中挑选若干置信度高的样本进行标记,并把这些“伪标签”样本加入另一个分类器的训练集中,使对方能利用新增的有标签样本进行更新,这种“互相学习、共同进步”的过程不断迭代,直到满足停止条件。协同训练的本质是一种基于分歧的半监督算法,因此基模型的差异性、基模型和视图的契合程度、伪标签策略将影响算法的有效性。
同时,在置信度低的区间中,仍有部分有价值的信息可待利用。如果仅凭置信度添加伪标签数据,这部分数据将难以被利用。因此,根据主动学习的思想,本文在每轮训练中,从置信度低样本中随机选取部分进行人工标注,加入下一轮训练。
(1)基模型
本文使用K最近邻(KNN,K-nearest neighbor)算法和支持向量机(SVM,support vector machine)算法作为协同训练的基模型。
KNN主要依靠邻近有限样本的标签情况判断自身的类别归属,即在特征空间下,对于新的样本,如果在训练集中与该实例最邻近的个实例多数属于某个类别,就把该样本分类到该类别下。一般使用欧几里得距离或曼哈顿距离度量样本距离。KNN在进行类别决策时,只与少量的相邻样本有关,避免了样本的不平衡问题。同时,KNN直接利用了样本间的关系,减少了因特征选择不当对分类结果造成的误差。
非线性SVM的数学描述如下。

(2)伪标签策略
合适的伪标签策略能令扩充后的训练集中加入更有价值的类别信息,提升学习性能;反之,则会引入分类噪声,导致预测偏差。这里的伪标签策略包括两个部分:伪标签数据生成,即如何判决无标签数据所属的类别;伪标签数据添加,即将哪些数据加入训练集。
对于伪标签数据生成,本文根据基模型训练产生的输出概率,选择置信度评估方法生成伪标签。通常认为置信度高的预测结果是正确的。流行的置信度评估方法主要有最大概率、最大概率与次大概率之差等[14-15]。考虑多分类问题的特殊性,为使不同类别的差异最大化,令差异大的类被选出,重新定义并计算置信度。

图1 基于多视图半监督集成学习的人体动作识别算法框架
Figure 1 The framework for human action recognition method based on multi-view semi-supervised ensemble learning
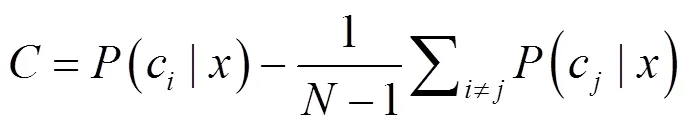
对于伪标签数据添加,现有的协同训练框架大多直接向训练集单调添加伪标签数据,这种方式难以验证添加的伪标签数据对模型的影响,在大多数情况,将降低伪标签样本的精确率。在训练集数据不足的情况下,通过构造伪验证集对模型进行校准。当伪标签数据对模型的影响是积极的,将伪标签数据加入训练数据;反之,则不加入。
算法1 伪验证集构造
3.2 第二阶段:LightGBM集成学习框架
LightGBM[16]是微开源的实现梯度决策提升树(GBDT,gradient boosting decision tree)的轻量级框架。GBDT是机器学习领域中一个经久不衰的模型,其思想是利用CART树作为弱分类器,通过多轮迭代产生多个弱分类器,最终对弱分类器的结果进行加权求和,得到分类结果。GBDT在每轮迭代后计算损失函数的负梯度值,并将其作为残差近似值。同时,在上一轮残差减少的方向上建立一个新的分类器。由于GBDT在训练时需要多次遍历所有样本,它不可避免地存在耗时长、内存占用大的问题。
LightGBM改进了这两个方面。LightGBM包含两个步骤:直方图算法和Leaf-wise策略。直方图算法对特征进行改造,首先对连续特征进行离散,将离散值作为新的特征并以直方图表示,然后通过统计直方图的累计统计值找寻最优分割点。这种方法对原始特征进行了压缩,相近的特征由于直方图类似而被忽略,所以仅需要保存离散后的值,从而减少内存占用。Leaf-wise策略在每轮迭代中,选取所有叶子中分裂增益最大的叶子作为下一轮的分裂点,避免了原始GBDT算法中对所有叶子一视同仁导致的搜索和分裂。Leaf-wise策略同时限制了决策树生长的深度,在保证精度的同时防止过拟合。
算法2 基于多视图半监督集成学习的人体动作识别算法
输出 多分类结果
4 实验与讨论
4.1 数据集
本文使用UCI人体动作识别数据集[17]。该数据来自30名不同的志愿者,包含步行、下楼、上楼、坐着、站立、躺卧6种日常行为动作,包含以50 Hz采样率获取的三轴加速度计、陀螺仪传感器数值。同时,该数据集提供了由原始数据计算的加速度计特征348维,陀螺仪特征211维,构成实验的两个视图。训练集中的活动标签分布如图2所示。
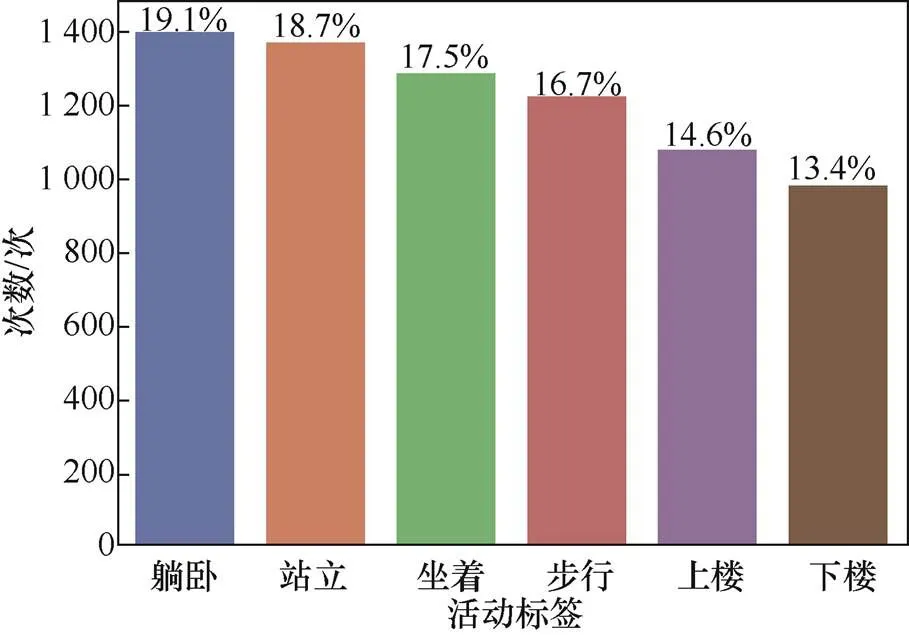
图2 UCI训练集中的活动标签分布
Figure 2 The data distribution of activity label in UCI training data
4.2 评价指标
各评价指标定义如下。
(1)宏平均精确率:精确率是指被模型正确分类的正样本占所有被模型判定为正样本的比例。对所有类的精确率求平均值得到宏平均精确率。
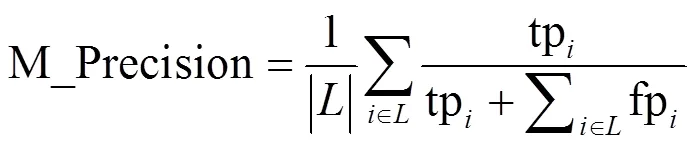
(2)宏平均召回率:召回率是指被模型正确分类的正样本占实际正样本的比例。对所有类的召回率求平均值得到宏平均召回率。
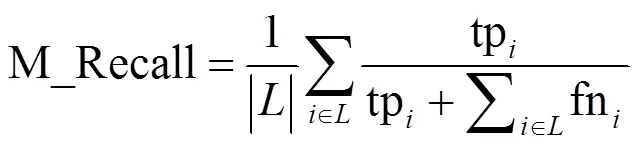
(3)宏平均1值:在精确率和召回率产生矛盾的情况下,使用1值对模型进行综合评估。
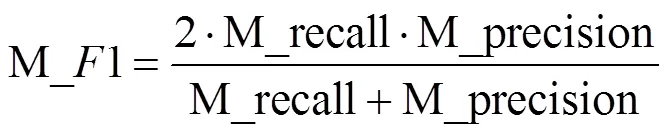
4.3 结果分析
本文实验将数据划分为3个部分:原数据集中的测试集完全保留,将训练集随机划分为有标签集(5%)和无标签集(95%)。同时,将无标签集中的标签部分隐去,以此模拟现实中的未知情况。同时,构建加速度计视图和陀螺仪视图作为协同训练的两个视图。
实验1 协同训练分析
首先,将支持向量机(SVM)、最近邻(KNN)应用于不同的视图和特征联合,以检验基分类器的分类性能,View1为加速度计视图,View2为陀螺仪视图,Both表示直接联合加速度计视图和陀螺仪视图,结果如图3所示。

图3 不同视图特征上分类器的F1值
Figure 3 The1 value of different activities
由图3可知,SVM和KNN在加速度计视图上的表现总体优于陀螺仪视图,SVM和KNN在陀螺仪视图上的表现比较接近。SVM在应用联合特征时,性能略微提升。

表1 不同分类器组合下的实验结果对比
实验2 人工标注分析
本文比较了不同比例(0,5%,10%,15%,20%)的人工标注对检测结果影响。
由图4可知,随着人工标注样本的增加,各指标总体呈增长趋势。但在标注比例10%后,增长趋势减缓,虽然在20%能取得最优的标注效果,但考虑标注的人力和时间成本,选择10%作为标注比例(约350条数据)进行人工标注。
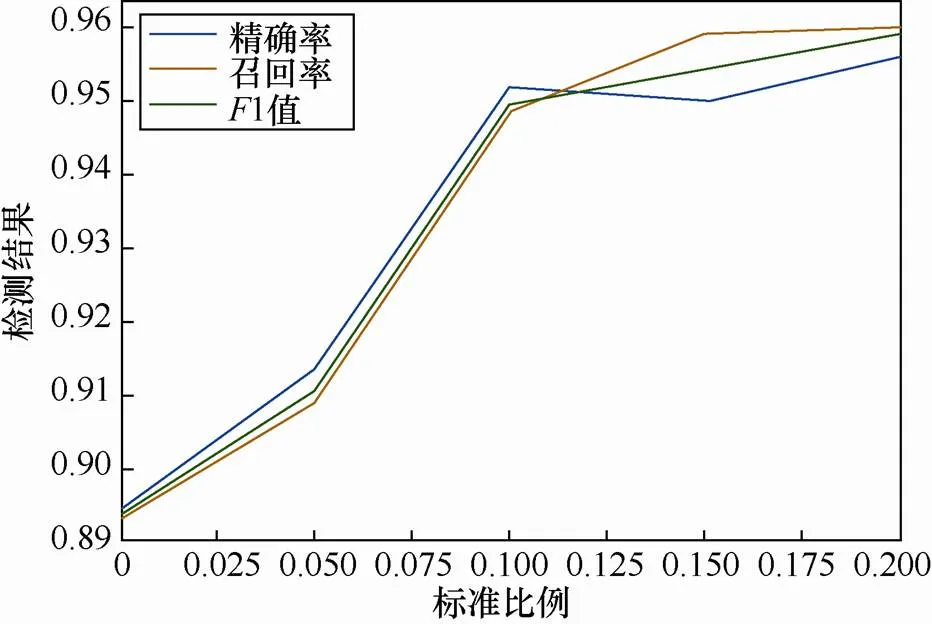
图4 不同比例下人工标注的指标分析
Figure 4 The metrics analysis of active learning with different ratios
实验3 混淆矩阵分析
利用混淆矩阵,进一步分析本文方法在每种动作上的表现。
从图5的混淆矩阵中可以看出,本文算法对所有动作的识别率都在90%以上,说明算法能稳定、有效地区别6种行为。其中,对步行、站立和躺卧的识别率略高于上楼、下楼和坐着。
实验4 特征重要性分析
对特征进行重要性分析,以找出识别人体的关键因素。
从图6中可以看出,加速度计(tGravityAcc和tBodyAcc)比陀螺仪(Gyro)的贡献大,但这并不表示陀螺仪特征不作用,可能是因为数据集中缺少旋转、跳跃这样的大幅度动作,使陀螺仪无法采集到关键特征。在提取加速度计相关特征中,极大值和极小值的有效特征偏多,极大值和极小值一般属于波峰和波谷的位置,划分动作有显著作用。从、和三轴来看,轴的影响明显高于其他两个轴,说明用户行进方向更能反映当前的运动情况。
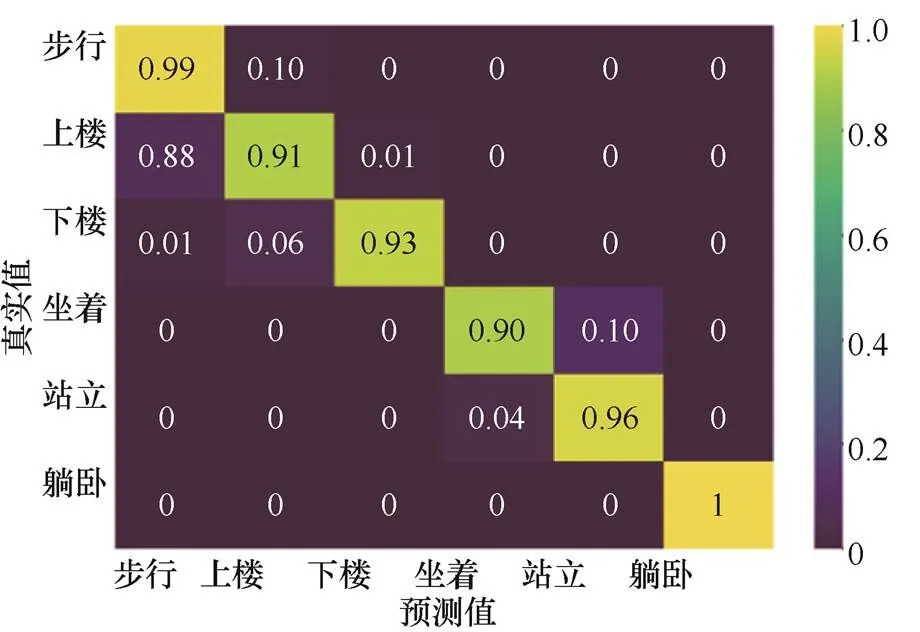
图5 6个动作的混淆矩阵
Figure 5 The confusion matrix of six activities

图6 特征重要性柱状图
Figure 6 The barchart of feature importance
实验5 有效性分析
将本文改进的Co-Training模型对比5个模型以说明模型的有效性。
模型1:利用SVM和有限的标签样本直接训练模型,不使用无标签样本。
模型2:利用KNN(=7)和有限的标签样本直接训练模型,不使用无标签样本。
模型3[18]:Self-Training模型。基于单一分类器进行强化学习,这里选择SVM分类器。首先利用SVM自训练得到扩充的训练集,再利用扩充后的训练集重新训练SVM得到预测结果。
模型4[19]:Co-Training模型。标准的协同训练算法,对协同训练后的伪标签数据不做筛选。扩充后的训练集仍利用协同训练框架得到预测结果。
模型5:利用LightGBM和原始标签数据集训练模型。
模型6:本文算法改进协同训练框架中的伪标签策略,对添加的伪标签数据进行评估筛选。以扩充后的伪标签数据作为输入训练LightGBM得到预测结果。实验结果见表2。
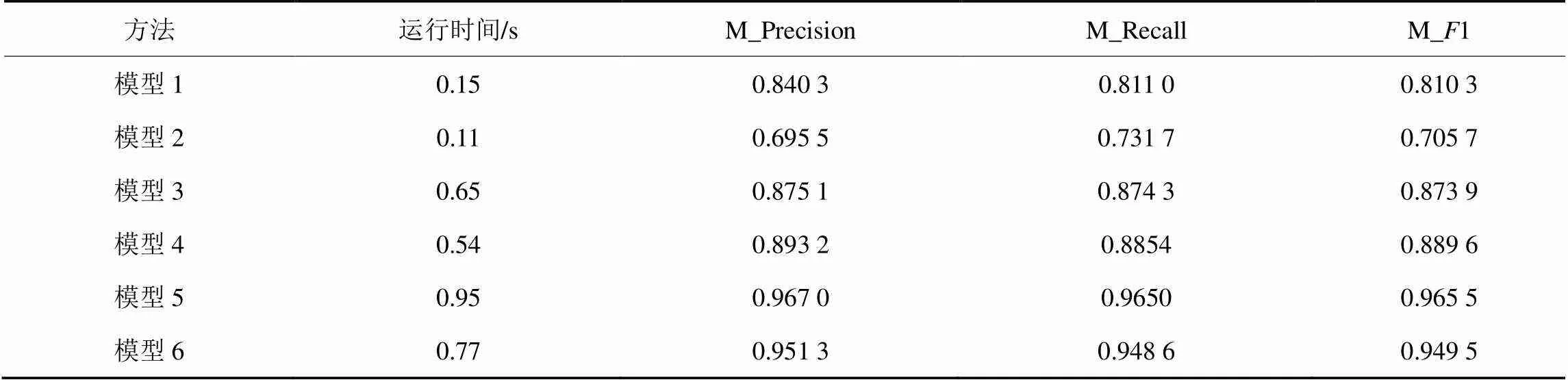
表2 不同模型下的实验结果
从模型1和模型2的结果可以看出,仅采用KNN或SVM与少量标签集进行预测,结果中存在很多误报,1值也比较低。这解释了在训练样本不足的情况下,模型获得的预测结果偏离测试集的真实分布,产生过拟合而导致在测试集上表现不佳。模型3和模型4是两类经典的半监督算法,当加入了未标记样本后,模型性能得到了改善。模型4由于增加了分类器的分歧,1值较模型3提升0.015 7,但模型3和模型4均采用最大置信度作为伪标签的评价方式,且在迭代过程中未对伪标签筛选。模型5验证了全量原始标签训练集在集成学习框架下的表现。本文算法在1值上比模型3和模型4这两种经典的半监督模型分别高出0.075 6和0.059 9,与模型5十分接近,仅低0.016,说明本文方法扩充获得的训练集与全量标签训练集对LightGBM模型的训练效果相当。在运行时间上,本文所提方法与其他半监督模型相差不大。
5 结束语
人体动作识别常常需要大批量、高质量的标签数据才能完成可靠的分类,但完成准确的标注需要耗费大量的时间、人力和财力成本。本文提出基于多视图半监督集成学习的人体动作识别算法仅需要少量的标签样本,利用主动协同学习框架和伪标签策略扩充原有训练集,扩充后的训练集上使用LightGBM进行分类。实验结果表明,本文提出的方法在少数样本情况下能准确识别不同的人体动作,接近于全量标签样本对分类模型的训练效果。然而,本文算法在应用到真实场景下时,提取特征过多将导致耗时长等问题,这部分可作为下一阶段的改进工作。
[1]LIU L J, LEI X L, CHEN B F, et al. Human action recognition based on inertial sensors and complexity classification[J]. Journal of Information Technology Research, 2019:18-35.
[2]周启臻, 邢建春, 杨启亮, 等. 基于连续图像深度学习的Wi-Fi人体行为识别方法[J]. 通信学报, 2020, 41(8): 43-54.
ZHOU Q Z, XING J C, HAN Q L, et al. Sequential image deep learning-based Wi-Fi human activity recognition method[J]. Journal on Communications, 2020, 41(8): 43-54.
[3]钱慧芳, 易剑平, 付云虎. 基于深度学习的人体动作识别综述[J]. 计算机科学与探索, 2021(1): 1-20.
QIAN H F, YI J P, FU Y H. Human action recognition based on deep learning:a review[J]. Journal of Frontiers of Computer Science & Technology, 2021(1): 1-20.
[4]张会珍, 刘云麟, 任伟建, 等. 人体行为识别特征提取方法综述[J]. 吉林大学学报(信息科学版), 2020, 38(3): 360-370.
ZHANG H J, LIU Y L, REN J W, et al. Human behavior recognition feature extraction method: a survey[J]. Journal of Jilin University (Information Science Edition), 2020, 38(3): 360-370.
[5]邹建. 基于BP神经网络的人体行为识别[J]. 网络与信息安全学报, 2017, 3(9): 55-60.
ZOU J. Human action recognition based on back propagation neural network[J]. Chinese Journal of Network and Information Security, 2017, 3(9): 55-60.
[6]WANG Y J, WU K S, LIONEL M N. WiFall: device-free fall detection by wireless networks[J].IEEE Transactions on Mobile Computing, 2017, 16(2): 581-594
[7]肖玲, 潘浩. 基于Wi-Fi信号的人体动作识别系统[J]. 北京邮电大学学报, 2018, 41(3): 119-124.
XIAO L, PAN H. Human activity recognition system based on Wi-Fi signal[J]. Journal of Beijing University of Posts and Telecommunications, 2018, 41(3): 119-124.
[8]CAO S M, YANG P L, LI X Y, et al. iPand: accurate gesture input with smart acoustic sensing on hand[C]//15th Annual IEEE International Conference on Sensing, Communication, and Networking(SECON). 2018.
[9]LIU Y T, ZHANG Y A, ZENG M. Novel algorithm for hand gesture recognition utilizing a wrist-worn inertial sensor[J]. IEEE Sensors Journal, 2018, 18(24): 10085-10095.
[10]殷晓玲, 陈晓江, 夏启寿, 等. 基于智能手机内置传感器的人体运动状态识别[J]. 通信学报, 2019, 40(3): 161-173.
YING X L, CHEN X J, XIA Q S, et al. Human motion state recognition based on smart phone built-in sensor[J]. Journal on Communications, 2019, 40(3): 161-173.
[11]WANG Y, CANG H N, YU H N. A survey on wearable sensor modality centred human activity recognition in health care[J]. Expert Systems with Applications, 2019, 137: 167-190.
[12]ALEJANDRO B , YAGO S, PEDRO I. Evolutionary design of convolutional neural networks for human activity recognition in sensor-rich environments[J]. Sensors, 2018, 18(4): 1288-1312
[13]张儒鹏, 于亚新, 张康, 等. 基于OI-LSTM神经网络结构的人类动作识别模型研究[J]. 计算机科学与探索, 2018, 12(12): 1926-1939.
ZHANG R P, YU Y X, ZHANG K, et al. Research on human action recognition model based on OI-LSTM neural network structure[J]. Journal of Frontiers of Computer Science & Technology, 2018, 12(12): 1926-1939.
[14]韩嵩, 韩秋弘. 半监督学习研究的述评[J]. 计算机工程与应用, 2020(6):19-27.
HAN S, HAN Q H. Review of semi-supervised learning re- search[J]. Computer Engineering and Applications, 2020(6):19-27.
[15]尹玉, 詹永照, 姜震. 伪标签置信选择的半监督集成学习视频语义检测[J]. 计算机应用, 2019, 39(8): 2204-2209.
YIN Y, ZHAN Y Z, JIANG Z, et al. Semi-supervised ensemble learning for video semantic detection based on pseudo-label confidence selection[J]. Journal of Computer Applications, 2019, 39(8): 2204-2209.
[16]GUO L K, QI M, FINLEY T, et al. LightGBM: a highly efficient gradient boosting decision tree[C]//Advances in Neural Information Processing Systems(NIPS). 2017: 3146-3154.
[17]ANGUITA D, GHIO A, ONETO L, et al. A public domain dataset for human activity recognition using smartphones[C]//European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN). 2013.
[18]ROSENBERG C, HEBERT M, SCHNEIDERMAN H. Semi-supervised self-training of object detection models[C]//IEEE Workshops on Applications of Computer Vision (WACV). 2005: 29-36.
[19]ZHOU Z H, LI M. Semisupervised regression with co-training- style algorithms[J]. IEEE Transactions on Knowledge and Data Engineering, 2007: 1479-1493.
Human action recognition method based on multi-view semi-supervised ensemble learning
CHEN Shengnan1,2, FAN Xinmin1,2
1. Fujian Normal University, Fuzhou 350117, China 2. Fujian Engineering Research Center, Network Security and Educational Informatization, Fuzhou 350117, China
Mass labeled data are hard to get in mobile devices. Inadequate training leads to bad performance of classifiers in human action recognition. To tackle this problem, a multi-view semi-supervised ensemble learning method was proposed. First, data of two different inertial sensors was used to construct two feature views. Two feature views and two base classifiers were combined to construct co-training framework. Then, the confidence degree was redefined in multi-class task and was combined with active learning method to control predict pseudo-label result in each iteration. Finally, extended training data was used as input to train LightGBM. Experiments show that the method has good performance in precision rate, recall rate and F1 value, which can effectively detect different human action.
human action recognition, semi-supervised learning, few-shot, LightGBM
TP393
A
10.11959/j.issn.2096−109x.2021061
2020−12−06;
2021−04−18
陈圣楠,csn0423@fjnu.edu.cn
国家自然科学基金(71701019),福建省中青年教师教育科研项目(JAT200071)
The National Natural Science Foundation of China (71701019), Educational Research Projects of Young and Middle-aged Teachers in Fujian Province (JAT200071)
陈圣楠, 范新民. 基于多视图半监督集成学习的人体动作识别算法[J]. 网络与信息安全学报, 2021, 7(3): 141-148.
CHEN S N, FAN X M. Human action recognition method based on multi-view semi-supervised ensemble learning[J]. Chinese Journal of Network and Information Security, 2021, 7(3): 141-148.
陈圣楠(1991−),女,福建福州人,福建师范大学助理研究员,主要研究方向为数据挖掘、网络安全应用。

范新民(1971−),男,福建建瓯人,福建师范大学研究员,主要研究方向为网络安全应用、教育信息化、教育大数据。
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
