
一种轻量级目标检测算法
2021-06-21 06:58郭昕刚纪超群
长春工业大学学报 2021年3期
郭昕刚, 纪超群
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
目标检测在无人驾驶领域是必不可少的环节[1],通过对道路场景中的目标进行精准检测,可为系统提供更加准确的环境信息,使系统对当前的场景做出更加准确的判断与处理。
目前较好的目标检测算法大多数使用深度卷积神经网络来实现[2]。基于深度学习的主流目标检测算法可以分为两类,即检测精确度较高的基于区域的检测算法(R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5]等)和偏向于检测速度的基于回归的检测算法(YOLO[6]、YOLOv2[7]、YOLOv3[8]、SSD[9]等)。随着两类算法的不断完善,不仅算法的网络结构与模型参数在不断增加,而且模型运行对硬件设施的要求也越来越高。在现实应用场景中使用的移动终端与嵌入式设备往往不能满足模型的运行条件,导致算法不能很好地向移动端或嵌入式设备上进行部署。通常对较大模型进行压缩,进而减小模型中不必要的计算参量,使其能够进行移植,但模型压缩往往会减少模型内部的连接结构,对模型产生一些影响;另一种方法是重新设计算法的网络结构,通过对网络结构进行优化,从而减少网络模型的参量。轻量级网络Mobilenets[10]是Google在2017年提出适用于移动端部署的神经网络,在减少网络层数的同时,使用深度可分离卷积替代标准卷积,减少卷积的计算开销,增强网络计算效率,使模型变小。
在目标检测算法中,SSD算法兼顾速度与精度[11]。SSD相对于two-stage算法在速度上有了极大的提升,虽然在速度上与YOLO依旧存在差距,但在精度方面比YOLO算法提高了很多。SSD使用特征提取网络VGG16浅层输出的特征图对较小的目标进行检测,由于浅层网络对特征提取不充分,导致算法存在对小目标检测不精确的问题。基于SSD的轻量级检测算法,Mobilenet-ssd使用特征提取网络Mobilenet替代VGG16,虽然解决了网络模型较大的问题,但依旧存在算法检测精确度低,特别是对小目标检测精确度较低的问题。文中对Mobilenet-ssd算法进行改进,用Mobilenetv3网络作为算法的特征提取部分,进一步减少网络参量与计算参数,并对Mobilenet网络与SSD算法检测器连接的部分引入特征金字塔(Feature Pyramid Networks)结构[12],增加特征图之间的联系[13],使检测器能够更好地利用特征信息,从而提高算法的检测精确度。
1 相关理论
1.1 残差结构
在研究人员意识到深度神经网络对图像的特征提取有较好的效果后,不断加深网络深度,而随着网络深度的增加,也逐渐出现过拟合现象、梯度爆炸等问题。为了使神经网络能够真正的更加深入,微软在2015年推出了使用多个残差模块堆叠组成的残差网络(ResNet)[14]。ResNet中的残差模块与常见模型不同的是在输入端与输出端增加恒等映射关系,当算法中某一层网络的输出已足够成熟或出现退化现象时,网络通过映射关系把上层网络的输出直接送入下层网络,进而避免出现网络退化与过拟合现象,同时残差结构有效地减少了网络的计算参量。
1.2 Mobilenet网络
Mobilenet[10]网络是一种轻量级卷积神经网络,通过优化网络结构,使模型的计算量与参数减少,使其在移动终端更适合部署。在Mobilenet网络中,将标准卷积替换为深度可分离卷积,即将一个标准卷积运算通过深度卷积(Depthwise Convolution, DW)和逐点卷积(Pointwise Convolution, PW)两部分来完成。
深度可分离卷积看似增加了卷积计算的复杂度,但有效减少了卷积的计算量。深度卷积部分与标准卷积不同,输入图像的通道数与卷积核为一对一关系,即一个通道只对应一个卷积核。其卷积核可表示为M个Dk×Dk×1(Dk为卷积核的维度,M为通道数);逐点卷积使用N个1×1的卷积将特征图进行连接,从而实现对通道数目的变化。其卷积核可表示为N个Dk×Dk×M(M为输入通道数,N为输出通道数)。
标准卷积与深度可分离卷积计算参数数量对比为
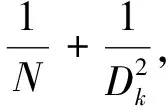
(1)
式中:Dk----卷积核尺寸;
M----输入通道个数;
N----输出通道个数;
Df----输入图片大小。
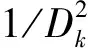
Mobilenetv2[15]在Mobilenetv1的基础上向网络中加入了倒残差结构,在能够将网络变得更深的同时,提高了网络的运行速度。之后的Mobilenetv3[16]网络在Mobilenetv2的基础上加入互补搜索技术,同时将平均池化前的层移除,并用1×1卷积来计算特征图,同时使用H-swish函数替代Relu6作为网络的激活函数,有效提高了网络精度。
1.3 特征金字塔结构
在早期的目标检测算法中,检测器仅根据特征提取网络输出的特征图进行预测,通常使用网络浅层输出的特征图检测小目标,使用深层网络输出的特征图度检测大目标。图像经过特征提取网络后,在深层输出特征图上较大目标的位置信息比较清晰,但语义信息缺失了很多;而浅层输出的特征图恰恰相反。这也就导致检测器在对不同尺寸目标进行检测的时候出现信息缺失或定位不准确的现象,尤其是在浅层对小目标的检测过程中。
为了能够充分利用特征图上的信息特征金字塔结构(FPN)[13],把特征提取网络各层输出的特征图进行融合,对浅层网络输出的特征图添加深层网络特征图上的位置信息,使不同维度的特征图都具有详尽的语义信息,通过不同维度特征图之间的语义信息互补,使特征金字塔结构增加了网络的检测精确度。
特征金字塔结构虽然丰富了特征图的语义信息,但却增加了网络的计算量,文中通过FPN思想对Mobilenet的特征输出层进行处理,对Mobilenet网络输出的6层特征图抽取其中3层进行自上而下的单级融合,在减少计算开销的前提下为检测器提供语义信息更加丰富的特征图。
2 目标检测算法设计
Mobilenet-ssd网络把SSD算法的特征提取网络VGG16替换为Mobilenet,在保留算法兼顾速度与精确度的同时,极大地缩小了网络模型,在此基础上,文中通过对特征提取网络输出的特征图利用特征金字塔结构进行融合,进一步提高算法的检测精确度。
2.1 目标检测模型
SSD算法虽然兼顾速度与精确度,但其使用的VGG16特征提取网络的网络结构较为复杂,训练得到模型较大,并不适合在移动设备或嵌入式设备上使用。VGG16-SSD算法网络结构如图1所示。
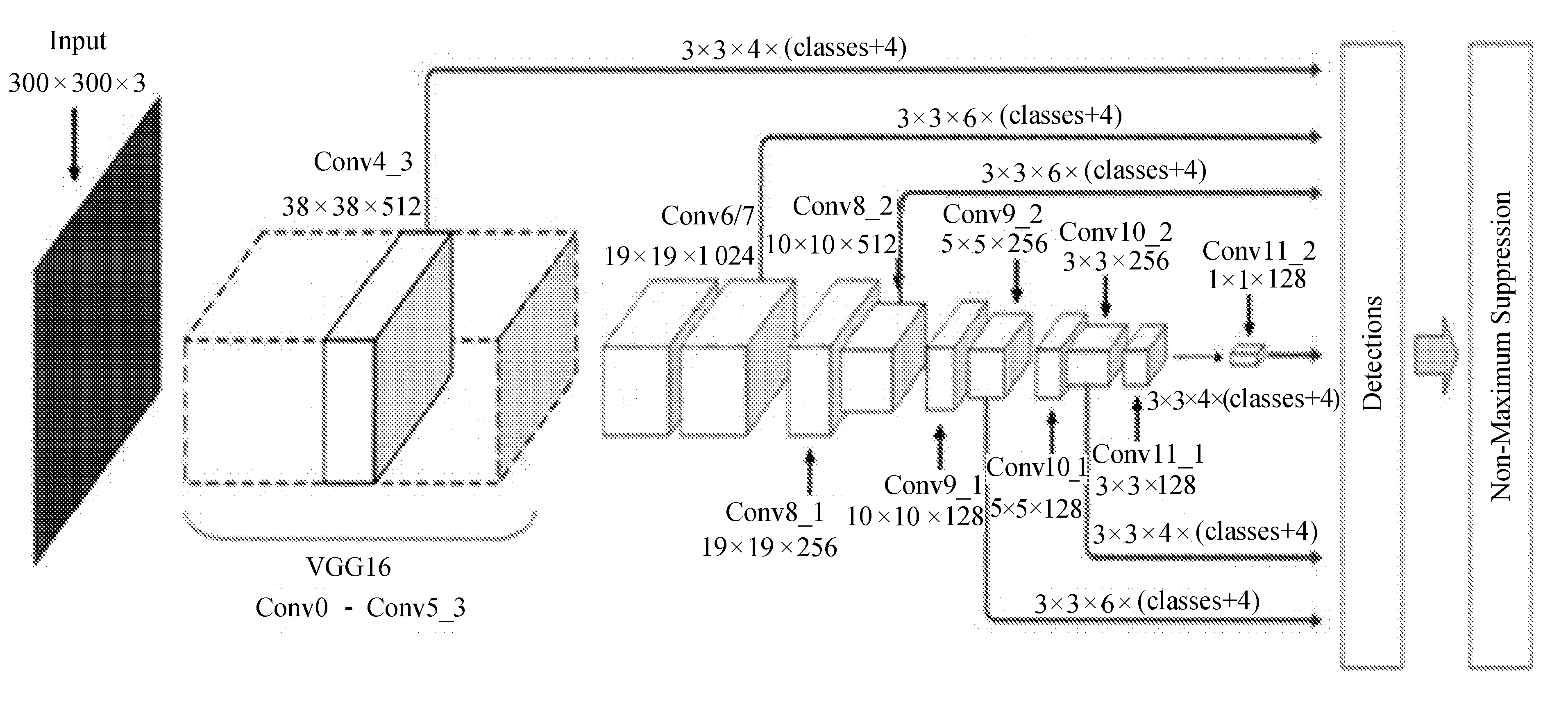
图1 VGG16-SSD算法网络结构
Mobilenet-ssd网络使用Mobilenetv3特征提取网络替代SSD算法中的VGG16网络,文中对算法网络结构进行修改,增加网络层数,并对特征提取网络输出的不同分辨率的特征图进行融合,同时将SSD中所有常规卷积和最后一个盒类预测层替换为深度逐点可分离卷积,进而减少模型的计算参量,使改进后的算法在保留SSD算法兼顾速度与精确度优点的同时,极大地优化了网络结构,最终训练得到的模型可以在移动设备或嵌入式终端上运行。改进后Mobilenet-ssd算法网络结构如图2所示。
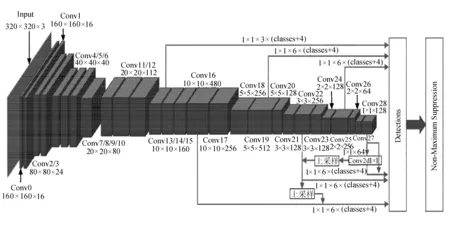
图2 改进算法的网络结构
在VGG16-SSD算法结构中,为了获得更大的视野,改变特征提取网络VGG16的FC6和FC7层,用标准卷积替代。同时,网络分别从不同层输出6种不同大小的特征图送入SSD算法检测器进行边框与分类预测。改进的Mobilenetv3-ssd算法网路结构共包含29层网络,其中前17层为Mobilenetv3的特征提取网络,去掉了原Mobilenetv3网络的最后平均池化、全连接与Softmax层;网络后面的12层是由第17层网络通过卷积变换生成,其作用是为SSD检测器提供不同尺度的特征图。
VGG16网络输入大小为300×300×3的图像,经过特征提取后输出6层分别为38×38、19×19、10×10、5×5、3×3与1×1大小特征图。相比较于VGG16网络,Mobilenet的特征提取层并没有很深入,网络输出40×40大小的特征图最深层是在网络的第7层,由于浅层网络对图像的特征提取不够充分,输出的特征图不能提供足够有用的特征信息使用,所以文中采用特征提取网络Mobilenetv3在第14层输出的10×10大小的特征图作为网络输出的第一个特征图。之后Mobilenet特征提取网络在第17、20、23、26、29层分别输出10×10、3×3、2×2与1×1大小5种特征图。
Mobilenet输出6层特征图的分辨率大小只有VGG16输出的特征图分辨率的一半左右。其原因是与VGG16相比,Mobilenet的网络结构没有VGG16深入,浅层输出的特征图提供的特征信息不够充分,只能选取更深入的部分网络提供特征图,虽然可以使用较高分辨率的输入图像在深层得到维度较高的特征图,但会极大地增加网络的计算量。
在Mobilenetv3的基础上增加类似特征金字塔的结构,再对网络的第17、23、29层输出的特征图进行融合。对第29层输出的特征图进行1×1卷积操作后与原特征图进行融合;并对其进行上采样处理,以增大特征图的分辨率,使其与第23层输出的特征图处于同一维度,使用PW卷积处理经过上采样的特征图,进而改变通道数目,使其与第23层输出特征图的通道数目相同,对第23层输出的特征图与第29层处理过后的特征图进行融合。同理,将第23层输出的特征图与第17层输出的特征图进行融合,之后再把融合后的特征图与第14、20、26层输出的特征图一起输入到SSD检测器中,对特征图进行分类与边框预测,从而增加检测器使用特征图的语义信息,提高对目标的检测精确度,特别是对小目标的检测。
2.2 损失函数
Mobilenet-ssd网络中SSD检测器对第14层输出10×10大小的特征图共有3个长宽比为1、2、1/2的预测框;在其它5层输出的特征图上检测器共有6个长宽比为1、2、3、1/2、1/3、1(与第一个大小不同)的预测框。在训练过程中,每个目标都由与其对应的6个预测框进行预测,最后通过计算预测框与真实框的交并比来选取预测框计算坐标偏差。
在网络中使用与swish相近的H-swish函数,非线性函数在硬件设备上运行时能够避免数值精度的损失已经通过Relu函数得到了证明,而且非线性函数运行速度快,在保持精度的同时带来了很多的方便。H-swith的表达式为

(2)
SSD算法的损失函数为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和,其公式为

(3)
式中:Lconf(x,c)----置信度误差,主要包含正样本误差与负样本误差两项;
Lloc(x,l,g)----位置误差;
α----权重系数,通过交叉验证设置为1。
3 实 验
3.1 实验数据及环境
实验使用的训练数据为公开的PASCAL VOC数据集与补充的道路场景的数据集,补充的数据集为从网络上获取的交通场景图片与视频中有关交通场景的截图;测试数据集使用PASCAL VOC2007test。在PASCAL VOC2007与2012共包含20个类,对道路场景下的bicycle、bus、car、motorbike、person主要5类目标进行检测,通过对PASCAL VOC数据集进行筛选,满足条件的图片为8 110张;通过制作2 000张道路场景下的数据集来弥补数据图片的数量,对获取的图片进行前期筛选,使图片中包含的目标类别尽量平衡,每个类出现的频率接近一致,使训练效果更好。
文中实验平台为Intel Core i7处理器与NVIDIA 2070 super显卡,显存为8 G;软件平台为Ubuntu18.04操作系统与CUDA10.0+cudnn7.6.5。
3.2 训练过程
网络训练在VOC数据集与补充的数据集上进行,使用labellmg图像标注工具制作VOC格式的数据集。在对网络训练过程中设置600个epoch(训练次数),lr(初始学习率)设置为0.01,权重衰减系数在第200个epoch之后进行0.000 5的衰减,batch size(批量处理参数)设置为16,使训练数据能够快速的收敛。模型在训练过程中的损失如图3所示。
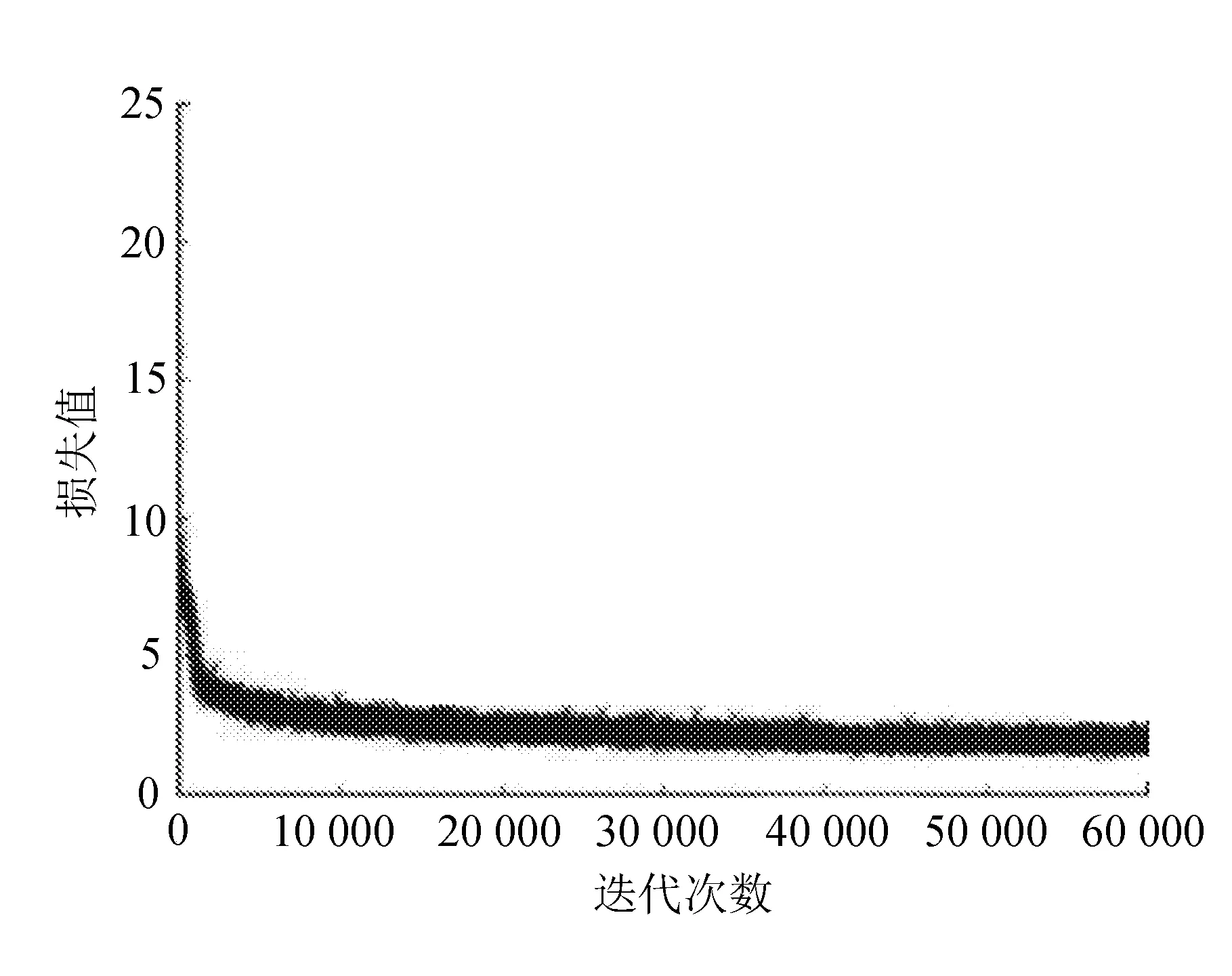
图3 损失函数图
由图3可知,训练模型在前10 000次迭代过程中损失下降比较明显,在迭代45 000次后逐渐趋于平稳,最终损失值在2.3左右趋于平稳。
3.3 实验结果分析
在VOC2007test测试数据集下对文中算法进行测试,检测精确度结果如图4所示。

图4 算法检测结果
文中算法在VOC2007test上的mAP(平均检测精确度)达到78.8%,算法的检测速度达到43.25 fps,在达到了实时性要求的前提下,网络的检测精确度有了较大提高。在对各个单类的测试中,bus与motorbike都取得了较好的检测精确度。为了更好地对实验结果进行对比,在实验室环境下对同类的不同算法在VOC2007test数据集下进行测试。其比较结果见表1。
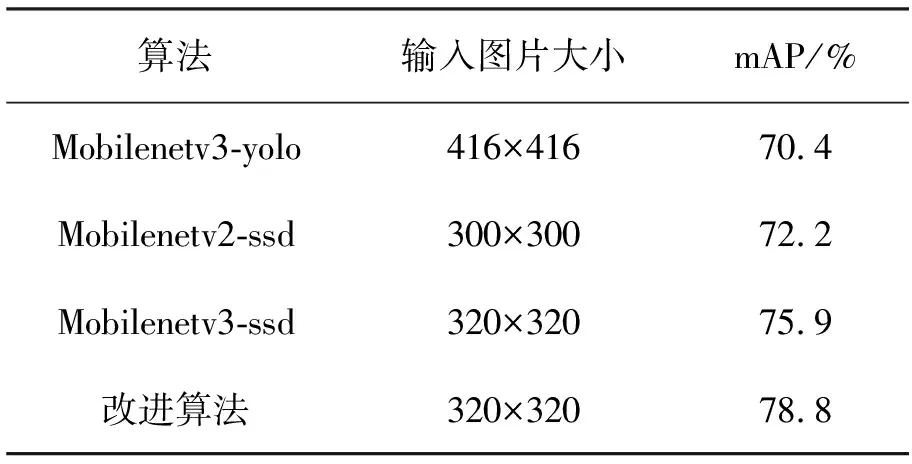
表1 不同模型检测精确度对比
由表1数据可知,文中提出改进后的Mobilenetv3-ssd算法相比较于原有的Mobilenetv3-ssd算法提升了2.9个百分点。通过增加Mobilenet-ssd算法特征提取网络输出层之间的联系,使检测网络输出的特征图具有更多的语义信息,进而提升算法对目标的检测精确度,尤其是对一些小目标的检测精确度。模型对bicycle、bus、car、motorbike、person这5类目标每一小类的AP见表2。

表2 VOC数据集下各类AP对比 %
由表2可得改进后的算法在每一小类上都比原算法有所提高,特别是在对交通场景中行人与自行车的检测上有了很大提高。检测效果对比如图5所示。

图5 检测效果对比
由图5可知,改进后的算法与原算法对比,在检测精确度与检测效果上都有所提高,对一些复杂场景下的目标进行检测时也有较为良好的表现。
4 结 语
为解决轻量级目标检测模型在交通场景下检测精确度不高的问题,提出一种基于Mobilenet-ssd网络改进算法,对Mobilenet特征提取网第17、23、29层输出的特征图进行特征融合,为检测器接通更多的语义信息,从而达到提高目标检测的精度。在VOC与扩充的数据集上对网络进行训练,并对得到的模型进行测试。实验结果表明,改进算法在对特定类进行检测时,与同类型其他算法相比具有一定优势,在模型大小可接受的情况下,提高了目标的检测精确度。
猜你喜欢
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
噪声与振动控制(2015年4期)2015-01-01
