
Framingham 及其改良模型在新疆牧区哈萨克族牧民中的应用研究
2021-06-17 03:44由淑萍徐月贞郑彦玲陈清杰樊琼玲詹怀峰
医学信息 2021年11期
由淑萍,徐月贞,陶 宁,郑彦玲,陈清杰,向 阳,樊琼玲,詹怀峰
(1.新疆医科大学护理学院,新疆 乌鲁木齐 830011;2.新疆医科大学公共卫生学院,新疆 乌鲁木齐 830011;3.新疆医科大学工程学院,新疆 乌鲁木齐 830011;4.新疆医科大学第一附属医院,新疆 乌鲁木齐 830011;5.乌鲁木齐县水西沟卫生院体检中心,新疆 乌鲁木齐 830000)
哈萨克族牧民高血压发病率高已达成共识,乌鲁木齐南山牧区居民以哈萨克族牧民为主,课题组前期研究发现该牧区人群高血压患病率为48.88%[1],如何更早预测高血压发病概率,发现高血压的高危人群,对高危人群进行风险管理至关重要。Framingham 高血压发病风险预测模型(以下简称Framingham 模型)是国外推荐使用的高血压发病分析预测模型[2],该模型是否可用于预测乌鲁木齐南山牧区哈萨克族牧民高血压发病风险值得研究,本研究以乌鲁木齐县南山牧区哈萨克族牧民体检数据为数据源,探索适合该人群的高血压发病风险预测模型,现报道如下。
1 对象与方法
1.1 研究对象 2008 年~2010 年采用方便整群抽样法选择乌鲁木齐南山牧区6 个乡镇的哈萨克族牧民11252 人作为基线队列人群;排除基线调查中高血压、冠心病等心脑血管疾病及拒绝随访者4950 人,共6302 人受邀参加两年一次的随访。纳入标准:①18 岁以上牧民;②居住时间3 年以上。排除标准:①失访人员;②患高血压等慢性病者;③拒绝参加及中途退出者。按要求完成随访者5763 人,失访539 人,排除随访中血压测量值和结局缺失436 人,最终符合条件的5327 例研究对象为本研究的数据源,队列数据的有效率为84.53%。
1.2 研究工具《居民健康体检表》和《乌鲁木齐南山牧区哈萨克族高血压及其危险因素调查问卷》,内容包括研究对象基本特征;影响高血压的生活方式,如盐、油、水果蔬菜摄入量等;血常规检查。
1.3 高血压诊断标准 根据《中国高血压防治指南(2010 年)》,在未服用降压药物情况下,收缩压≥140 mmHg 或舒张压≥90 mmHg,或者收缩压和舒张压均高于正常水平;随访血压值有3 次达到高血压诊断标准者或者接受高血压药物治疗者,确诊为新发高血压。休息15 min 后进行血压测量,连续测量2~3 次,每次间隔时间至少1 min,取3 次测量血压的平均值。
1.4 判断标准 抽烟:每天吸烟≥1 支且吸烟时间≥1年者;饮酒:平均日饮酒量≥50 ml 且饮酒时间在≥1 年。每日摄盐量(g)为家庭年摄盐总量除以家庭人员总数除以365 d。
1.5 Framingham 模型和改良模型公式 采用Framingham 模型[3]和改良模型公式[4]两模型对本研究队列人群进行高血压发病风险预测,从区分能力和标定能力两个方便判断两模型在该人群的预测效果。


1.6 观察指标 采用随访新发病例数、累积发病率描述基本情况;受试者工作者特征(ROC)曲线下面积(AUC)判断Framingham 模型和改良模型区分能力;Hosmer-Lemeshowχ2(H-Lχ2)判断模型的标定能力;根据改良模型计算本研究队列人群中未来高血压发病风险概率,按照ATPⅢ所提出高血压发病风险分组:<5%低危、5%~10%中危、10%~20%中高危、>20%高危标准[5],将年龄分为5 组:18~34、35~44、45~54、55~64、65~岁;对研究队列高血压的患病风险进行危险分层。
1.7 统计学方法 采用EpiData 建立数据库,采用SPSS 17.0 统计学软件进行数据分析。计数资料采用频数和构成比;通过MedCalc 软件采用ROC 曲线下面积AUC 验证模型区分能力;采用十分位数将队列人群中高血压的患病率和预测概率由小到大排序后,将全部数据分为10 等份,与每个点位置上相对应的数值,H-Lχ2判断模型的预测概率和实际发病率之间的区别,其中H-Lχ2检验值<20,P>0.05 认为标定能力较好。检验水准α=0.05。
2 结果
2.1 研究队列的基本情况 本研究队列的入队人群为6302 人。2014 年1 月~11 月首次随访,6017 人完成;2016 年1 月~11 月第2 次随访,5824 人完成;2018 年1 月~11 月第3 次随访,5763 人完成;排除随访中血压测量值缺失和结局缺失436 人,最终5327 人为本研究的数据源。经过随访新发高血压1985 人,高血压累积发病率为37.26%,见表1。
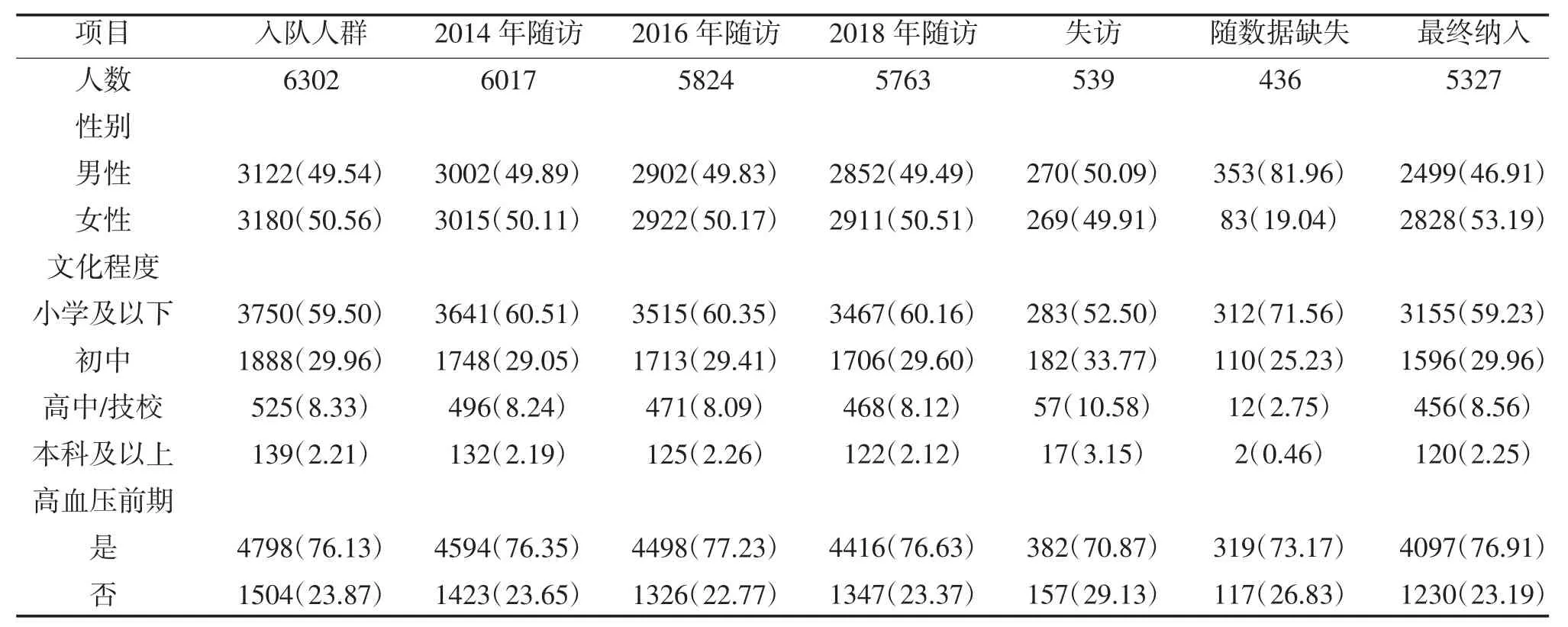
表1 随访、失访及研究对象的一般情况[n(%)]
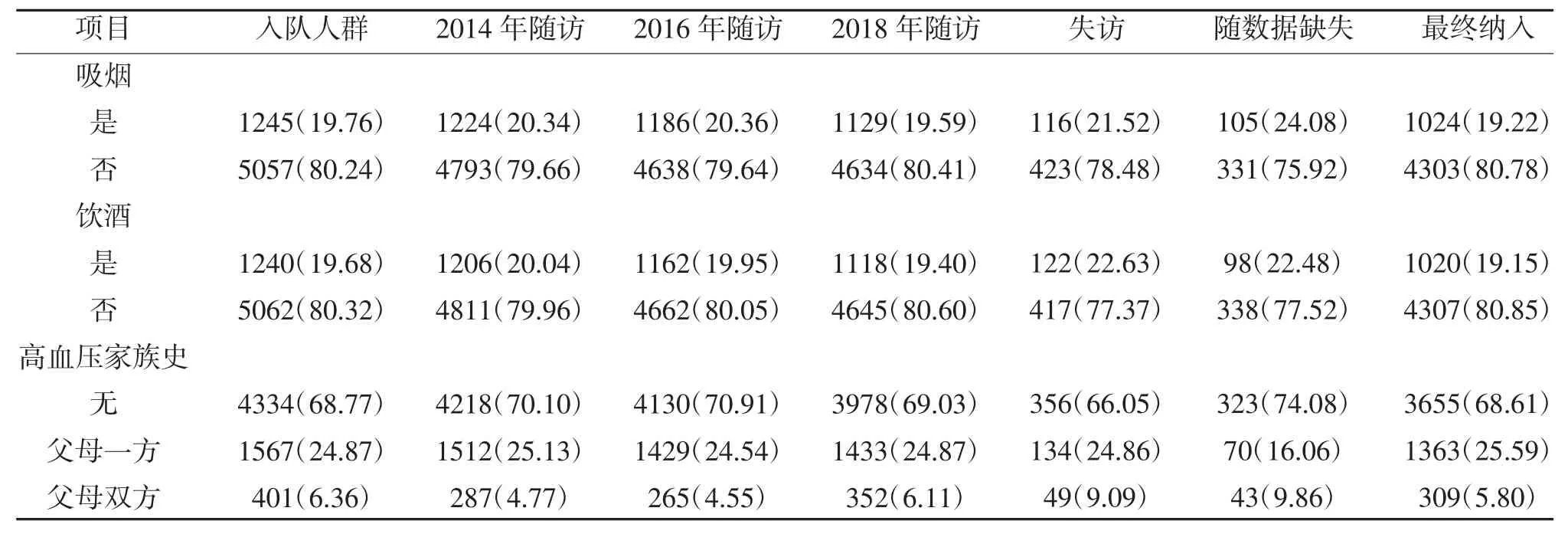
表1(续)
2.2 Framingham 模型和改良模型的预测ROC 曲线结果 队列人群是否发生高血压的AUC 分别为:AUCFraminghamm模 型=0.666(95%CI:0.653,0.679)和AUC改良模型=0.797(95%CI:0.786,0.808),见图1。

图1 Framingham 模型和改良模型的预测ROC 曲线结果
2.3 Framingham 模型和改良模型的预测标定能力结果 Framingham 模型与改良模型预测概率与实际发病人数比较,改良模型预测概率与实际发病人数的一致性较高H-Lχ2=18.54(P>0.05),Framingham 模型预测概率与实际发病人数存在偏差较大,H-Lχ2=423.541(P<0.05),见图2。

图2 Framingham 模型与改良模型对队列人群高血压发病风险的标定能力分析
2.4 队列人群未来十年高血压发病风险概率危险分层和高血压新发病例的实际分布情况
2.4.1 不同年龄组危险分层情况 按照年龄进行危险分层发现,45~54 岁及以上,随着危险层级升高、高危人数逐渐增加;35~44 岁及以下危险层级人数变化不大。本研究共筛选出中高危人群1363 人,高危人群1866 人,通过随访共有1985 人发展成高血压,见表2。

表2 本研究队列人群高血压发病预测概率不同年龄的危险分层(n=5327)
2.4.2 队列人群高血压新发人群在不同年龄和不同危险分层的分布情况 根据年龄和发病风险将实际高血压发病人群进行分层,1985 人高血压新发病例中1592(80.20%)人为高危人群,218(10.98%)人为中高危人群,121(6.10%)人为中危人群,54(2.72%)为低危人群,见表3。

表3 队列人群高血压实际发病人数在不同的危险分层和不同年龄分布情况[n(%)]
3 讨论
随着生活水平的提高及世袭的不良饮食方式,导致新疆南山牧区哈萨克族牧民高血压发病率高;本队列研究发现:新疆南山牧区哈萨克族高血压发病率较高,高血压累积发病率为37.26%。虽然医疗卫生事业发展和公共卫生三级预防重视程度逐渐加强,但因牧民文化程度不高,健康自我保健意识淡薄,因此高血压的防控仍任重道远,探索适合新疆南山牧区哈萨克族牧民的高血压发病风险预测模型具有重要的应用价值。
Framingham 模型在Framingham 研究中心具有较好的预测能力,但该模型的7 大危险因素没有摄盐、血脂、饮酒等变量,南山牧区哈萨克族牧民生活环境特殊,生活方式独特,前期研究发现该地区人群的人均摄盐量的中位数为16.66 克[6],同时,该地区人群饮食中脂肪含量高,故Framingham 模型会影响预测效果。区分能力[7]可正确地把病人和非病人区分开的能力,一般情况下采用ROC 曲线下面积(AUC)进行检验区分能力,AUC 越大就表示模型的区分能力越好。标定能力[8]能利用H-Lχ2来评价预测模型,与区分能力不同,标定能力是评价预测模型正确预测人群发病风险的能力。Framingham 高血压发病风险模型对新疆南山牧区哈萨克族研究队列10 年是否进展为高血压进行预测,其区分能力、标定能力较弱,原因可能是由于研究对象的基本人口学特征不同,同时也和不同地区高血压的危险因素有关,危险因素的分布不同可能在一定程度上解释模型预测能力的不同。首先,从基线数据上看,本研究队列人群在基线收缩压、年龄方面要高于Framingham 研究模型;其次,本研究队列人群与Framingham 子代研究人群所处的环境不同,民族也不同,具有不同的文化背景和生活习惯;最后,本研究人群的摄盐量、吸烟人数、饮酒人数、高血压家族史等也不同于Framingham 子代研究人群。但是在Framingham 高血压发病预测模型中并没有等相关危险因素。
本研究中,改良模型是根据乌鲁木齐南山牧区哈萨克族牧民高血压的影响因素,在Framingham 模型基础上增加了摄盐量、饮酒和血脂(TC、TG、LDLC、HDL-C)变量,具有较好的预测能力;摄盐量、饮酒和血脂作为预测因素纳入改良模型中,可对危险因素的动态变化进行监测,更加客观的评价预测过程中危险因素,保证哈萨克族牧民高血压危险因素的有效控制,从而可为促进新疆牧区哈萨克族牧民改善不良的饮食生活方式提供依据。同时,《国家基本公共卫生服务规范》和《关于进一步明确自治区全民健康体检工程体检项目的通知》(新卫办基层卫生发〔2016〕3 号)内容中规定,血脂为必查项目,可为高血压风险预测模型的使用提供便利条件。
针对新疆南山牧区哈萨克族人群进行高血压预防,筛选出高危人群,通过本研究改良模型对本研究人群进行高血压风险预测并进行危险分层,从未患病人群中筛选出高血压高危人群,与高血压新发病例实际分布比较可知,改良模型可对危险因素的动态变化进行监测,可以更加客观的评价干预过程中危险因素的改善情况,更适合于该地区人群的高血压风险预测,保证哈萨克族牧民高血压危险因素的有效控制,从而可为促进新疆牧区哈萨克族牧民改善不良的饮食生活方式提供依据,针对高危人群制定高血压预防措施。
综上所述,乌鲁木齐南山牧区牧民高血压的患病率较高,通过Framingham 模型及其改良模型在乌鲁木齐南山牧区牧民中运用,发现Framingham 模型会低估该地区人群高血压的发病率,但改良模型的预测概率与高血压的实际发病率的趋势一致,改良模型更适合于在该人群中应用。
猜你喜欢
西藏艺术研究(2021年3期)2021-06-02
小学生学习指导(低年级)(2020年4期)2020-06-02
西藏农业科技(2019年1期)2019-07-25
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
敦煌学辑刊(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2017年3期)2017-06-11
兽医导刊(2016年6期)2016-05-17
启蒙(3-7岁)(2016年10期)2016-02-28
地理教学(2015年20期)2015-12-17
