
基于艾宾浩斯遗忘算法的间隔重复记忆算法的设计与实现
2021-06-11 05:39:12徐泽禧廖钜新徐泽城
科学与信息化 2021年15期
徐泽禧 廖钜新 徐泽城
1.广州软件学院 电子系 广东 广州 510990
2.广东工业大学管理学院 广东 广州 510520
引言
人类对于世界的认知是基于自身在人脑中建立起的架构,而组成这些架构的正是一个个概念点或者是概念要素,语言学家威尔金斯:“没有语法只能表达很少的信息,但是如果没有词汇,那么什么也将表达不了[1]”。当我们把它精确到英语学习领域上,他的概念要素就可以泛指最基础的单词。桂诗春教授指出:“词汇量测试和智力测试或其他成就测试的结果具有很高的相关系数[2]”。有个共同认识就是,学习一门语言,该语言的单词是入门的基础,所以背单词就是为入门某一门语言的必由之路。
1 基于Ebbinghaus遗忘算法背景介绍
艾宾浩斯遗忘曲线表达的内涵其实是对人脑认知结构的一种研究。一般地,我们人脑会对最近发生的事件有更为清晰的记忆。艾宾浩斯遗忘曲线图如图1所示。
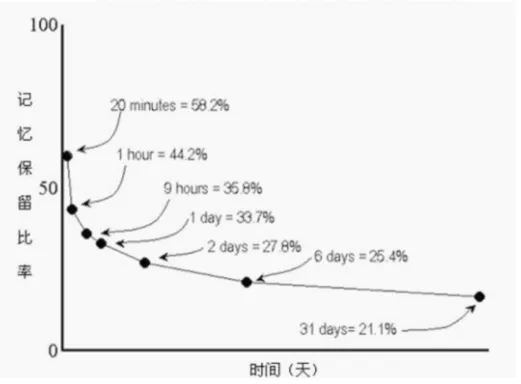
图1 艾宾浩斯遗忘曲线
由艾宾浩斯遗忘曲线图不难发现7个关键的点,我们称之为记忆桩点(Memory pile point),这7点分别代表了对应时间点,人对于一个知识点的记忆保有率。艾宾浩斯认为,人在记忆之后的遗忘过程不是匀称的,即符合先快后慢的规则[3],可以看出若不采取复习手段,知识在第二天只能剩下27.8%,倘若是抽象成一个函数f与t的关系(f为记忆忘却率,t为时间)有以下式1所示。

其中t是时间,e是自然对数底数
我们的遗忘算法就是依据遗忘曲线的桩点来设计的,将用户学习的单词的一个属性字段,通过输入算法中得出具体的复习时间点,之后再在每天的学习复习之后更新下次的复习时间。
2 系统的设计和实现
2.1 软件系统结构简介
软件采用C/S架构,客户端采用硬件终端实现显示学习界面,服务器端主要运行数据库以及py自动化脚本,以及提供后台管理平台接口。服务器采用AB公司的Mysql数据库,自动化脚本采用Python语言,包括数据处理,后台管理,个性化设计等子模块组成。
3 主动回忆与间隔效应
3.1 主动回忆与间隔效应简述
基于艾宾浩斯的研究,发现其本质是间隔效应。间隔效应可以用在各个领域上,较为具体的就是将记忆内容记录在卡片上,可以用这种方式来提醒即将遗忘的内容。而且它们没有那么单调乏味,因为通过抽认卡的形式来学习知识是一项具有足够的挑战性的活动,它能保持使用者感受到乐趣[3]。
主动回忆,即当看到一个问题时,大脑回忆起与之对应的答案,而不是把答案和问题重新阅读一遍,只需要询问自己是否清晰地记得这个问题,若不记得就把复习时间安排在不久的将来。
3.2 间隔效应系统模组的介绍
复习日程。是指在一定的间隔时间内,会让用户提交检查,以确认用户通过,通过该提示就会进入下一个阶段,随着阶段的提升,复习的间隔也会随之变大。
抽卡式记忆。抽卡式记忆的特点是让用户快速的尽可能广泛的复习,提高复习效率。
专注时间。因为人的注意力限制了系统不能过长时间地剥夺用户的自由。
进度表与检查情况。需要有进度表来让用户有更好的全局观并且有成就感。
3.3 遗忘点算法实现
用户首次背诵时,从总表选取A个单词,作为当日运行表,作为启动数据。用户表在数据库有User_Already,User_Right,User_Wrong,User_Tomorrow表。主要操作字段有LT,P,RT三个字段。
用户背完的词数据,从终端传回服务器数据库,数据库执行py脚本,该脚本主要操作是,获取游标对应的某行R,根据R的LT属性即最近学习日计算出建个列表T,T的值是LT+[1,2,4,7,15],RT是复习日,根据P阶段来获取T中对应的日期,之后是对用户的测试未通过的单词P阶段不变,LT设为今日,测试通过的单词P+1,LT不变,RT根据T[P]更改,并且将这些单词数据更新到User_already表。上述操作中P+1表示用户记忆进入下一阶段。
4 总结与展望
在现阶段信息网路爆炸的大时代背景之下,本文介绍了一种基于艾宾浩斯曲线和间隔重复记忆的方法,让高效复习学过的知识提供了一种可行思路。关于该算法的用户在P阶段的复习,是基于用户对于单词的熟悉程度,且单词的推送符合间隔效应的思路,对于下一步的研究是,希望能够将该算法扩展到深度学习,结合协同过滤可以将该背单词的遗忘点改成其他的信息点,就能够扩展到更广的领域中去。
猜你喜欢
数学小灵通(1-2年级)(2020年11期)2020-12-28 00:41:14
黄河之声(2019年1期)2019-12-16 02:09:22
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:44
课程教育研究·学法教法研究(2017年2期)2017-04-26 08:20:41
课程教育研究·新教师教学(2016年1期)2017-04-10 02:21:26
企业技术开发·下旬刊(2016年9期)2016-11-23 02:37:45
考试周刊(2016年37期)2016-05-30 14:31:56
天天爱科学(2015年7期)2015-05-30 10:48:04
科技创新导报(2014年20期)2014-11-10 18:03:22
读写算·小学低年级(2014年4期)2014-07-24 22:42:55
