
运用双向长短期记忆模型的心拍分类算法
2021-06-08 10:09朱彬如万相奎金志尧刘俊杰张明瑞
华侨大学学报(自然科学版) 2021年3期
朱彬如, 万相奎, 金志尧, 刘俊杰, 张明瑞
(湖北工业大学 电气与电子工程学院, 湖北 武汉 430068)
据《中国心血管病报告2018》推算,我国患心血管人数达2.9亿,患高血压人数达2.45亿[1].仅2017年,我国因心血管疾病死亡人数约为350万,远高于癌症致死人数,心血管疾病位居所有致死病因的首位[2].心电图(electrocardiogram,ECG)是临床应用最广泛的心血管疾病检查手段之一.医生可根据心电图结果初步掌握患者的身体情况,诊断心律失常、心肌梗死等疾病.
传统基于机器学习的算法在心电信号分类领域的应用有随机森林[3]、最小相邻[4]、聚类分析[5]、隐含马尔可夫链[6]等方法.这些方法对提取波形特征的要求很高,更多依赖于人工特征的设计.基于深度学习的方法能够从广泛的医疗数据集中自动学习,并能从海量复杂的数据中挖掘有用的信息和规律,无需人工设计特征,可将相关人员从繁重的医疗数据中解脱出来.近年来,卷积神经网络算法不断被应用到心电领域中.Zubair等[7]采用卷积神经网络(CNN)提取ECG信号的有效特征,实现优于大多数分类算法的准确率.Kiranyaz等[8]利用一维卷积神经网络(1D-CNN)将特征提取和分类融合统一,可对较长的ECG记录进行有效分类.Al Rahhal等[9]利用深度神经网络(DNN),在网络隐含层顶层加入重构层并采用Softmax激活函数,提高了心律失常的分类效果.这些算法虽然能达到不错的效果,但却忽略了心电信号在时间上的序列关系.Zhang等[10]使用循环神经网络(RNN)与聚类分析技术处理时间序列,实现了在MIT-BIH心率失常数据库的有效心拍识别.然而,心电信号的分类还要考虑局部波形与整体波形的关系,RNN无法解决心电信号的长程依赖问题.长短期记忆网络(LSTM)是对RNN的一种改进,可以较好地解决以上问题.因此,本文基于双向长短期记忆模型的深度学习算法对心拍进行分类.
1 实验方法
1.1 心电信号的预处理
采集的心电信号往往含有基线漂移、工频干扰等噪声[11],严重影响心电信号的特征提取和心拍识别的准确性,需在数据载入训练前进行必要的预处理.信号预处理步骤,如图1所示.

图1 信号预处理步骤Fig.1 Signal preprocessing steps
利用FIR带通滤波去除基线漂移,低通滤波去除工频干扰等噪声.滤波后,P波和T波被明显削弱.采用“双斜率”法[12]处理滤波后的波形,利用QRS波两侧波峰斜率突变的性质,在波峰左右两侧选择平均最大斜率和最小斜率;然后,用前侧最大斜率减去后侧最小斜率,后侧最大斜率减去前侧最大斜率,再取前、后两侧的最大值.经过滤波和“双斜率”法处理后,信号幅度越来越小.为了便于检测,通过滑动窗口积分,增大波形绝对振幅,而波形的幅值仅在纵坐标上变化,对要获取波峰横坐标的位置无明显影响.预处理后的心电信号变成模式单一的波峰信号,波峰对应QRS波,比原始信号更容易检测.预处理前、后的ECG信号,如图2所示.图2中:U为电压;n为心电信号数据点的个数.

(a) 预处理前 (b) 预处理后图2 预处理前、后的ECG信号Fig.2 ECG signal before and after pretreatment
1.2 QRS定位和心拍截取
经典的QRS波群的定位与检测方法有图形识别法、小波变换法、差分阈值法、双阈值法等[13].小波变换法精确度高、滤波突出,但结构较为复杂,抗干扰能力弱.差分阈值法结构简单、运算速度快,但对预处理的滤波要求高.双阈值法[14]的运算速度快、精准度高、抗干扰能力强,但对波形复杂、有干扰的信号检测能力较弱.
采用一种改进的自适应阈值方法,结合差分阈值和双阈值法的优点,使自适应阈值跟随信号实时变化[15],确定和精准定位R波.当心电信号的波形超过低阈值时,即认为检测到一个QRS波;而当心电信号的波形超过高阈值时,则表明要适当调整阈值的数值.为保证能检测到绝大部分的QRS波,要保证阈值区间能自适应波形变换并具有一定的稳健性.具体来说,如果检测到的QRS波峰远高于阈值时,说明阈值设置过低,高阈值基于前面5个QRS波的波峰,设置为平均值的0.7倍,相应的低阈值设置为0.3倍.当波峰处于高阈值与低阈值之间时,保持高阈值不变,调高低阈值,有利于排除不必要的噪声信号.阈值变化是基于不断变化的QRS波具有一定的自适应,自适应阈值调整公式为
(1)
(2)
式(1),(2)中:R表示波峰值;avg表示平均值;fmax为最高阈值;fmin为最低阈值.
心电信号处于不断变换中,每次心拍持续时间和表现波形并不完全一致,很难精准定位每个P波和T波的起点和终点位置.整个心拍周期基本在0.6~0.8 s之间,而MIT-BIH心律失常数据库的采样频率为360 Hz,故对于一个完整心拍,其采样点长度应该在216~288之间.以QRS波为参考位置,分别向前选取100个点和向后选取150个点,共250个点,将其作为一个片段进行分割截取,使其包含完整的心拍.
2 基于双向长短期记忆网络的心拍分类
2.1 长短期记忆(LSTM)网络
LSTM网络是RNN网络中的一种,由Hochreiter等[16]提出,相比于经典的RNN结构,LSTM最大的特点就是引入了门的机制和记忆元组,解决了RNN网络中存在的梯度消失和梯度爆炸问题.LSTM与经典的RNN结构类似,但ECG信号是一维信号,也是一个时间序列,因此,LSTM非常适合处理心电信号.
LSTM的门结构主要由遗忘门、输入门和输出门组成,其网络结构,如图3所示.LSTM通过这3种门对细胞的状态进行控制与保护.遗忘门决定删除哪些信息,它接受上一刻的输出ht-1与当前时刻的输入xt,接着输出遗忘矩阵Ft,从而控制上一时刻的细胞状态Ct-1是否通过.
新的信息传送到细胞的状态中,输入门开始接收ht-1与xt,接着,tanh 层产生候选状态值并对之前的Ct-1进行迭代更新.Ft为遗忘矩阵,Ct-1为之前时刻的状态,it为更新的数值.输出门决定输出的信息,通过输出门(sigmoid层)产生一个输出矩阵Ot,决定输出目前状态Ct的结果,Ct状态通过tanh层与Ot做乘积,输出结果ht.
LSTM的更新公式为
Ft=σ(Wf·[ht-1,xt]+bf),
(3)
it=σ(Wi·[ht-1,xt]+bi),
(4)
(5)
(6)
Ot=σ(Wo·[ht-1,xt]+bo),
(7)
ht=Ot×tanhCt.
(8)
式(3)~(8)中:Wf,Wi,Wc,Wo为各个门的权重参数;bf,bi,bc,bo为偏置参数.
LSTM对RNN进行了改进,使其能获取更长距离的信息元素.但LSTM和RNN都只是单向推进,会出现后面的因素比前面的因素更重要的情况,这是不够准确的.因此,为了提高心拍分类的准确性,提出基于双向长短期记忆网络的方法.
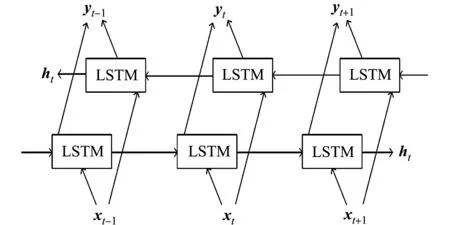
图4 BiLSTM网络结构Fig.4 Network structure of BiLSTM
2.2 双向长短期记忆(BiLSTM)网络
BiLSTM由前向LSTM与后向LSTM组合而成,是LSTM的变种和改进[17].改进的LSTM进行双向推进,把两个方向的LSTM结合起来得到最终的输出yt.BiLSTM网络结构,如图4所示.
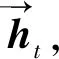
(9)
(10)
采用双向长短期记忆网络,预处理数据后,将单个心拍转变为时间序列输入训练好的网络模型中;分类器输出心拍对应的心律失常类型.基于BiLSTM的心拍分类网络结构,如图5所示.具体有以下3个步骤.
步骤1心拍信号.为了便于截取和操作,向前选取100个点,向后选取150个点,共计250个点(时间约为0.7 s)作为一个完整的心拍,即作为时间序列输入x.
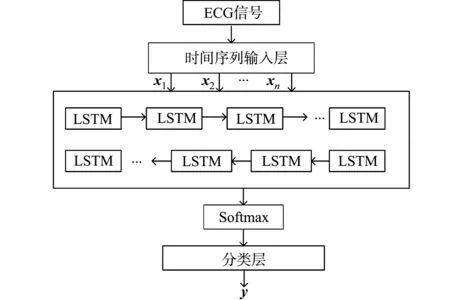
图5 基于BiLSTM的心拍分类网络结构Fig.5 Network structure of heartbeat classification based on BiLSTM
步骤2模型结构训练.训练集的完整心拍经过时间序列输入层后,依次进入双向LSTM层、全连接层、Softmax层.双向LSTM层由前向层和后向层组成,每个时间步骤结合前向和后向层输出,将前向层和后向层输出连接起来送到Softmax层和分类层.
步骤3心拍检测.将经过专家标注的心拍集作为标签,训练好的模型与测试集用于检测分类效果,与真实标签对比检验文中算法的精准度.
3 实验结果与分析
3.1 数据来源
MIT-BIH心率失常数据库是由美国麻省理工学院与贝斯以色列提供的可公开使用的数据库.它包含48条30 min左右的两导联心电信号记录,分别来自47个不同个体(包含25名年龄为32~89岁的男性和22名年龄为23~89岁的女性),心电信号的采样频率为360 Hz[18].
依据ANSI/AAMI EC57:2012[19]标准,将心拍类型划分为正常或束支传导阻滞(N)、室上性异常(S)、心室异常(V)、融合(F)4类.N,V,S,F的心拍数量分别为90 285,7 140,3 002,800,各类型的心拍数量分布十分不均衡.若把获取的各类型心拍数量直接载入网络进行训练,则网络训练的效果必然出现偏差.为了避免数据不平衡带来的影响,以心拍类型数量最少的F类心拍数量为基准,将心拍进行随机排列,分别从N,V,S,F中随机选取10 000,7 000,3 000,800个样本作为本次分类的数据.在20 800个样本中,选取其中90%作为训练集,其余10%作为验证集,训练集与测试集数据交叉验证,避免过拟合.
3.2 训练参数及实验平台
训练时采用Adam优化算法,与默认随机梯度下降法相比具有更好的适应性,其学习率为0.001,一次训练所抓取的数据样本数量为16.
实验平台的硬件为Intel i5-4200H,显卡为GEFORCE-GTX850M,内存为8 GB,操作系统基于Windows10,编程语言为Python,深度学习的框架为Tensorflow,开发工具为MATLAB2018a.
3.3 评价标准
ECG心律失常分类效果的评估指标为特异性(ηspe)、敏感性(ηsen)和准确率(ηacc),这些指标可以通过混淆矩阵呈现.各评估指标的计算式为
(11)
(12)
(13)
式(11)~(13)中:TP,FP,FN,TN分别为样本真阳性、假阳性、假阴性、真阴性的数量.
3.4 分类效果对比
根据ANSI/AAMI EC57-2012中心律失常的评估标准,利用测试集分别检验CNN,LSTM,BiLSTM 3种模型算法的泛化能力,并采用混淆矩阵表示实验分类结果.3种算法对4种心律失常类型的分类结果,如表1所示.

表1 3种算法对4种心律失常类型的分类结果Tab.1 Classification results of four arrhythmia types by three algorithms
由表1可知:3种模型算法对4种心律失常类型的心拍识别准确率平均都能到达94%以上,能够完成分类的任务.
依据统计表和混淆矩阵,输出4种心律失常类型的准确度、灵敏性和特异性,将文中基于BiLSTM模型的深度学习算法与其他算法的分类效果进行对比,结果如表2所示.表2中:GMM为高斯混合模型;HOS为高斯统计分析;WPE为小波熵;RF为随机森林.

表2 基于BiLSTM模型的深度学习算法与其他算法的分类效果对比Tab.2 Comparison of classification effect between deep learning algorithm based on BiLSTM model and other algorithms
由表2可知:GMM+HOS算法的整体准确率虽然达到96.17%,但其对F类敏感性仅有11.86%,存在数据不平衡的情况.此外,在对心电信号进行特征提取过程中,由于GMM+HOS算法的非线性拟合效果受限,通过这种数学方法处理信号时,会损失一些有用的信息,从而对结果产生一定的影响.
WPE+RF算法虽然整体准确率超过了平均水平,但是对S,F类的敏感性仅为20.00%,50.00%,远低于平均水平,不能满足分类的应用要求.基于数学变换的WPE方式使特征的意义不够直观,解释性也不够强;而RF在训练集有噪音时,会出现过拟合的现象,对于特征量不多的数据,分类效果不好.
1D-CNN算法可以利用局部波形与整体心电信号的关系,将波形的低层次变换特征转换成的高层次特征.CNN算法的特点得到了很好的利用:局部连接使网络可提取数据的局部特征;权值共享减小了训练的难度;池化操作和多层结构将低层次特征组合为高层次特征.CNN的滤波器尺寸和数据量不够大,使CNN算法的训练难以充分发挥.从表2可以看出,虽然CNN算法的总体分类效果不错,对V类的敏感性最高为97.15%,但其对F类基本不能识别,而且模型中需要确定的超参数较多,要达到最高的准确率没有具体的规律可循,需要反复实验,耗费大量时间.
GMM+HOS,WPE+RF,1D-CNN算法虽然能完成基本的分类任务,但不能充分发掘和利用心电信号的时间序列中存在的隐藏规律.相比而言,LSTM适用于具有时间特征的心电信号,能够有效提取心电信号的时序特征,利用心电信号前后间的联系,使数据和模型得到更好的结果.由表2可知:LSTM算法的各项评价指标都不是最高,整体效果也不是最好,但是都能达到平均水平以上,而且没有较大的误差和明显的短板.可见LSTM算法能基本满足分类任务的需求.
BiLSTM的模型算法是基于LSTM的改进,由前向LSTM和后向LSTM结合而成,在发挥了LSTM优点的同时,使数据得到更充分的训练,从而减小误差,提高准确性.无论在各类型识别准确的数目上,还是在各类型评价指标上,BiLSTM算法都明显优于LSTM算法,说明BiLSTM算法的改进是有效的.BiLSTM算法对N类的敏感性、特异性和对S类的敏感性分别为98.56%,98.38%,93.33%,比其他4种方法都高;对其他心率失常类型的敏感性和特异性指标也都排在前三位,整体分类准确率也最高,故BiLSTM算法的整体综合指标最好.以上几种分类算法对S类的分类效果会略低于N类和V类,除了选取的样本不够典型造成错误分类外,还因为S类心拍与N类心拍的形态特征十分相似,波形的重合度很高,造成部分S类心拍被错误归类到N类,而把异常心拍归为正常N类.
3.5 分类速度对比
从分类速度方面看,由于GMM+HOS,WPE+RF算法不是基于多层神经网络的模型算法,其计和耗时结果,如表3所示.表3中:N为数据量;ηacc为准确率;t为时间.
算复杂度远低于基于多层神经网络的算法,故耗时明显低于1D-CNN,LSTM和BiLSTM算法.采用3种神经网络算法,对MIT-BIH心律失常数据库中同样的心电数据进行分类,对比其心拍识别的准确率

表3 基于神经网络模型算法的分类速度比较Tab.3 Comparison of classification speed based on neural network model algorithm
由表3可知:基于BiLSTM模型算法虽然耗时多于单向的记忆网络算法,但能够明显提高准确率.
4 结束语
基于双向长短期记忆模型的深度学习算法,在MIT-BIH心律失常数据库下进行分类识别时,整体的准确率达到96.54%,相比于其他几种模型算法具有明显优势.但深度学习的训练往往基于大量的数据输入,而选择的MIT-BIH心律失常数据库的数据有限且心律失常样本内部的数据不平衡,使训练时分类结果容易往数据量大的类型偏移,对分类结果会有一定的影响.在接下来的研究中,可以尝试扩充增强数据量,减少数据不平衡带来的影响,尽可能提高模型的泛化能力,使文中算法能有效地应用于其他数据上.
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
电子技术与软件工程(2022年6期)2022-07-07
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康体检与管理(2022年4期)2022-05-13
雷达学报(2022年2期)2022-04-30
雷达学报(2022年2期)2022-04-30
计算机仿真(2021年11期)2021-12-10
科学与生活(2021年11期)2021-11-10
建材发展导向(2021年23期)2021-03-08
汽车与驾驶维修(维修版)(2020年2期)2020-03-20
