
单张图像超分辨率重建技术研究及在开放大学招生中的应用
2021-06-08 08:57杨建华
安徽开放大学学报 2021年2期
杨建华
(安徽开放大学,合肥 230022)
一、引言
2020年初,为应对新冠肺炎疫情,国家开放大学招生管理系统增设学员线上、线下报名功能。学员可以自己上传个人人脸、身份证、毕业证书等照片,也可以通过身份证读卡器获取学员人脸照片。但学员上传的照片经常存在分辨率过低、关键部分不清晰,给工作人员的辨识带来困难;身份证读卡器获取的身份证中人脸图像的大小为:宽102像素、高126像素,在后期用此图像与学员本人进行人脸识别匹配时,会因图像的分辨率过低导致人脸识别效果不佳。通常情况下,当人们遇到低分辨率的小图像时,一般是采用一些图像处理软件对其放大,但这样会造成图像失真,如图像边缘出现锯齿状,图像模糊。为此,本文引入基于深度学习的单张图像超分辨率(Single Image Super-Resolution,SISR)重建技术,来解决上述问题。
图像超分辨率(Image Super-Resolution,SR)重建技术,是指利用一张或多张低分辨率(Low Resolution,SR)图像,通过软件处理,生成一张具有较高分辨率(High Resolution,HR)图像的技术。在安保监控、卫星图像遥感、显微成像、数字高清、视频复原和医学影像等领域都有非常重要的实用价值。与通过升级硬件设备的成像精度来提高图像分辨率相比,SR技术具有成本低、速度快的明显优势。
二、深度学习的单张图像超分辨率重建技术
(一)图像超分辨率重建技术
该技术首次由Harris与Goodman于20世纪60年代提出,采取的方法是在单帧图像上进行线性插值或样条函数插值,虽然能提高单幅图像的分辨率,但图像中的很多高频细节易丢失。这一时期图像超分辨率重建技术主要停留在理论研究阶段,没有具体实现方法。直到1984年,由RY Tsai与TS Huang利用多帧低分辨率图像通过傅里叶变换,得到单张高分辨率图像,这是科研人员第一次利用软件技术将图像超分重建思想变成现实,标志着图像超分辨率重建进入了实践发展时期。
2006年,随着Hinton等人提出了神经网络中的深度学习概念,其核心卷积神经网络(Convolutional Neural Network,CNN)在计算机视觉领域取得极快发展,一系列以卷经神经网络为基础的网络模型不断被提出,如: AlextNet、GoogleNet、VGGNet、ResNet等,网络的学习能力也由弱变强,在图像分类、检测方面取得了越来越优秀的成绩。很自然地,人们想到可以用训练深度卷积神经网络来学习低分辨率图像与高分辨率图像之间的映射关系。2014年,香港中文大学的Dong等人最先提出基于CNN的图像超分模型(Super-Resolution Convolutional Neural Networks, SRCNN),该网络模型由特征提取层、非线性映射层、重建层三层构成,取得了优于传统方法的效果,奠定了基于深度学习的图像超分辨重建技术在图像超分研究领域的主流地位。
(二)深度学习的单张图像超分辨率重建技术研究现状
单张图像超分辨率重建技术早期主要研究方法有三类,基于插值的方法、基于模型重建的方法、基于机器学习的方法。当前以基于深度学习的单张图像超分辨率重建技术为主流研究方向,按使用的网络类型可细分为基于标准的卷积神经网络结构SR模型、基于残差的网络结构SR模型、基于生成对抗 (Generative Adversarial Networks,GAN)的网络结构SR模型。
以标准卷积神经网络(CNN)为基础的模型主要有SRCNN网络、快速超分辨率卷积神经网络(Fast Super-Resolution Convolutional Neural Networks, FSRCNN)、高效的亚像素卷积神经网络(Efficient Sub-Pixel Convolutional Neural Network,ESPCN)三种网络模型。
以残差神经网络(ResNet)为基础的模型主要有深度超分辨率卷积神经网络、用于图像超分辨率的深度递归卷积网络、拉普拉斯金字塔超分辨率网络(Laplacian Pyramid Super-Resolution Networks ,LapSRN)、增强深度超分辨率重建网络(Enhanced Deep Super-Resolution Network , EDSR)、级联残差超分辨率网络、残差信道注意网络等网络模型。
以生成对抗网络(GAN)为基础的模型主要有超分辨率生成对抗网络模型、具有特征识别的单图像超分辨率网络模型、双GAN网络模型。
(三)四种主流图像超分模型的研究
在上述诸多网络模型中,比较经典与主流的模型有FSRCNN、ESPCN、LapSRN、EDSR四种。如在开源的计算机视觉库OpenCV(Open Source Computer Vision Library)中,也提供了这四种训练好的模型调用接口,用于实现基于深度学习的图像超分,能对图像进行2~4倍的超分。
1.FSRCNN模型
FSRCNN模型是2016年由香港中文大学的汤晓鸥团队提出,它是对原SRCNN模型的改进。SRCNN模型是深度学习在图像超分辨重建上的首次应用,其网络结构如图1所示,网络使用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练,主要过程为:
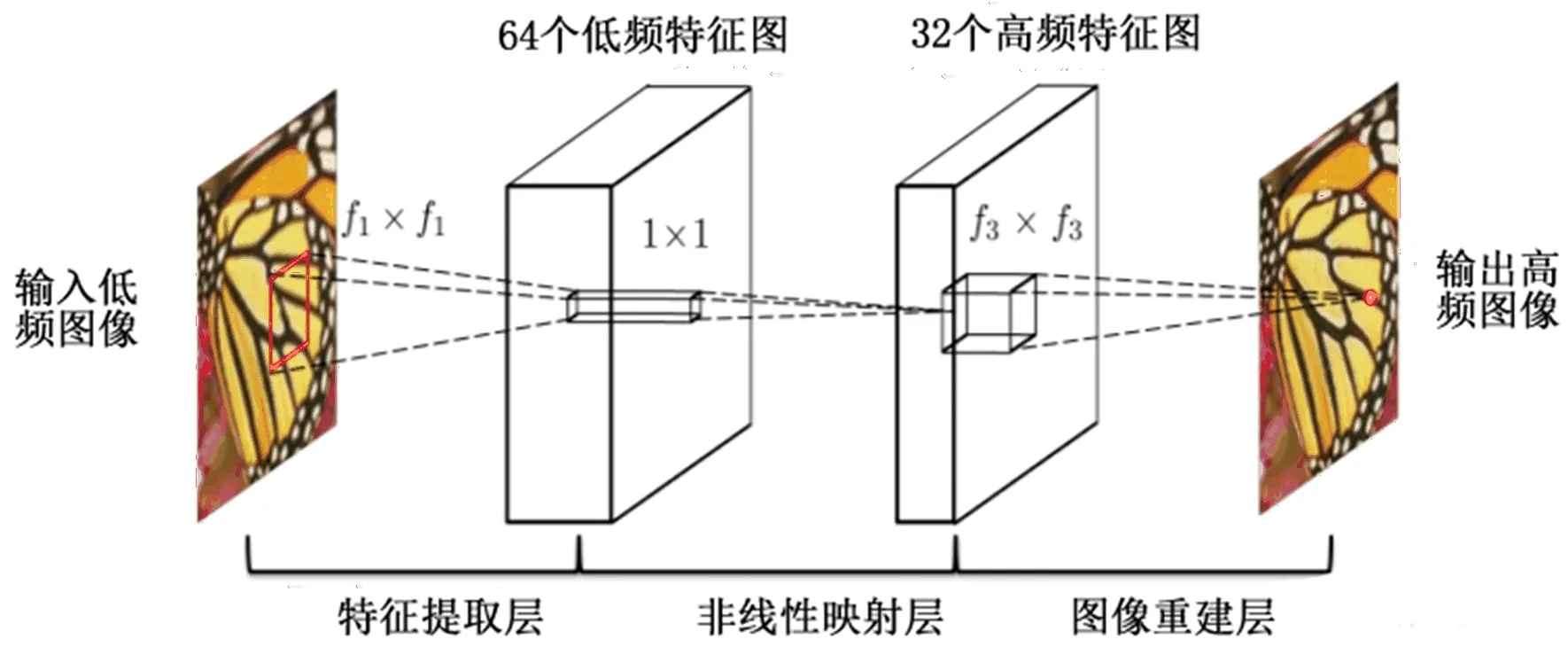
图1 SRCNN模型的网络结构
Step1:对数据集进行预处理,如对原始训练(Trai)数据集中的91张图像进行分割,按步长14,大小21*21进行裁剪,作为标签(Label)数据;对Train数据集进行下采样(缩小)后再进行上采样(放大)到原始大小,再按步长14,大小33*33进行裁剪,作为训练集数据,这样得到2万多组样本数据与标签数据。
Step2:构建三层的卷积神经网络,三层卷积核大小分别分9*9、1*1、5*5,前两层卷积后使用Relu作激活函数,输出特征个数分别为64和32,用均方差作为损失函数(loss)进行训练,公式如下:
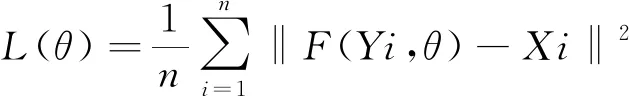
(1)
Step3:训练结束保存现场参数,测试时选用整张图像,卷积操作时填充模式选择“SAME”,图像尺寸保持不变。
FSRCNN模型主要通过增加网络深度与减小卷积核对SRCNN模型进行了运算加速,图2为其与SRCNN模型的结构对比图,能直观地反映两者之间的差异,主要表现在:
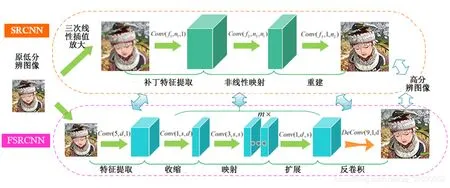
图2 FSRCNN与SRCNN网络结构对比
(1)FSRCNN直接采用低分辨的图像作为输入,而SRCNN需要先对低分辨率的图像进行双三次插值,对放大后的图像进行切块,将图像块作为输入;
(2)FSRCNN在网络的最后采用反卷积操作实现图像放大,运算更高效;
(3)FSRCNN中用收缩、映射和扩展操作来替代非线性映射;
(4)FSRCNN选择更小尺寸的卷积核和更深的网络结构,减少运算参数的同时提升了网络的学习能力。
FSRCNN的损失函数不变,仍采用公式(1),但激活函数选用了团队定义的PRelu函数,避免了网络反向传播时,可能会由Relu函数引起梯度为零的情况,PRelu公式为:
f(x
)
=max(x
,
0)
+a
min(0,x
)(2)
2.ESPCN模型
ESPCN模型是由推特(Twitter)的Shi等人在2016年提出,其主要贡献在于提出了一种直接在低分辨率图像上进行特征提取再转换成高分辨率图像的有效卷积方法。其网络结构如图3所示,网络的输入仍是原低分辨率图像,隐藏层通过l
个卷积操作得到r
个与原图像大小一样的特征图,亚像素卷积层将图像上每个像素的r
个通道按一定规则重新排列组合成一个r*r
大小的子图块,
于是大小为r
个W
×H
的特征图像被重新排列组合成一个rW
×rH
尺寸的高分辨率图像。通过使用亚像素卷积操作,图像从LR到HR放大的过程中,低SR图像与HR图像之间的映射关系隐式地包含在前面的隐藏卷积层中,可以通过一系列的学习得到,最后才对图像大小进行转换,由于前面的卷积运算都是在低分辨率图像上进行的,参与运算的数据量小,从而效率更高。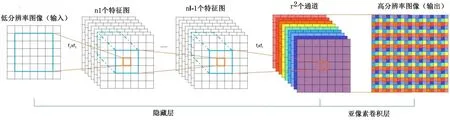
图3 ESPCN模型的网络结构
3.LapSRN模型
LapSRN模型是由美国加州大学默赛德分校的Lai等人在2017年提出,该模型能逐步重建不同尺度的高分辨率图像,特别是在8倍超分时也取得了良好的重建效果。其网络模型结构如图4所示,从图中可以观察到模型由特征提取与图像重建两个分支构成,图像特征提取与图像重建同步进行。首先,输入的LR图像经过一系列卷积操作进行特征提取,学习的是残差部分信息,再经过解卷积操作进行2倍的放大,并与重建分支中经过2倍插值放大的原始图像相加,得到2倍的HR重建图像。重复上述过程,得到放大4倍的HR重建图像。以此类推,理论上可以得到放大2倍的HR重建图像。
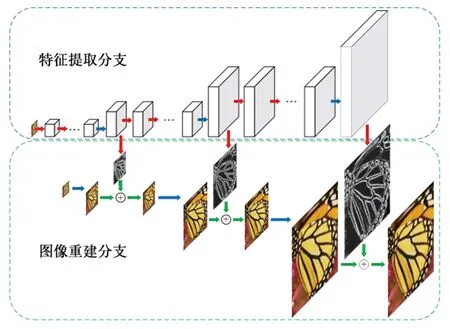
图4 LapSRN模型的网络结构
LapSRN模型与前文提到的SRCNN、FSRCNN、ESPCN模型相比,除了网络结构不同外,另一个不同在于它采用了一种有别于公式(1)的Charbonnier损失函数,其公式表达如下:
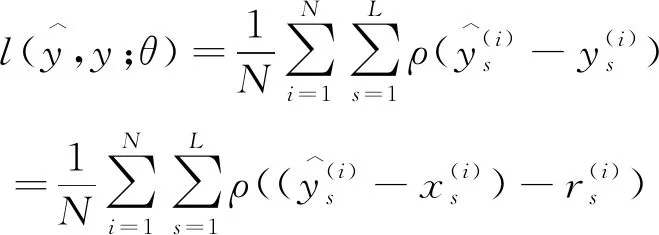
(3)
4.EDSR模型
EDSR模型是由韩国首尔大学的SNU CVLab研究团队在2017年提出,其网络结构如图5所示,可以看作是对SRResNet的改进,去掉网络结构中的一些多余的运算。一是去掉残差块内的批规范化处理(batch normalization, BN)操作,二是去掉残差块外的Relu操作。在文献[15]中作者提到,原始残差网络的提出是为了解决计算机视觉方面的高级(High-level)问题,如图像分类、图像检测、图像的识别等。而图像超分属于低层(Low-level)问题,所以将ResNet结构直接应用到图像超分问题上没有达到最优效果。而BN层的计算量和一个卷积层几乎持平,移除BN层后训练时可以节约大概40%的内存与时间。
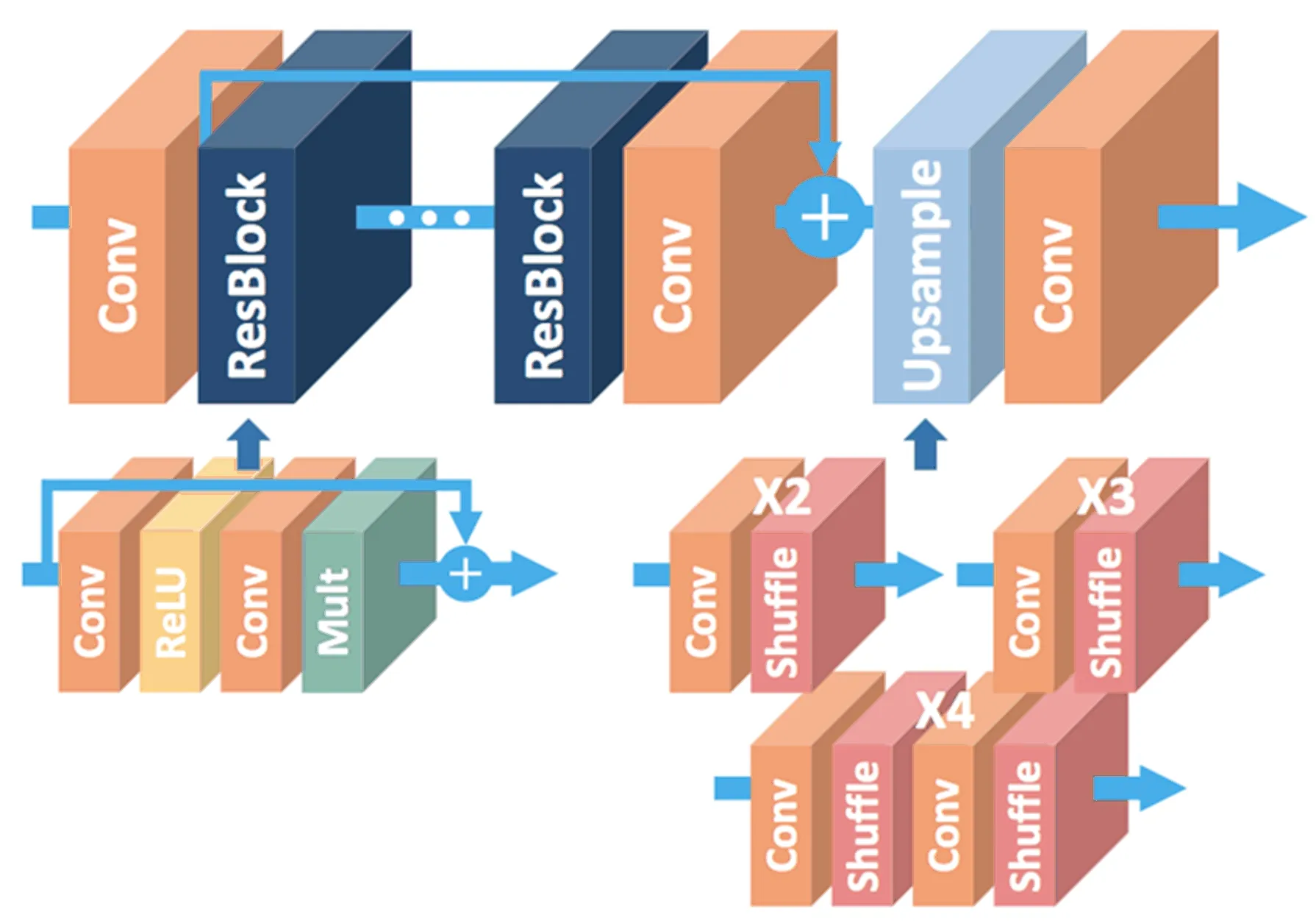
图5 EDSR模型的网络结构
此外,EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,再用训练结果参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练效果会更好,如训练缩放因子为3倍、4倍的EDSR时,可用预训练过的×2的网络来初始化模型参数。这个策略加速了训练并且提升了最后的性能。对于×4,使用预训练×2的模型训练会收敛更快。
三、单张图像超分辨率重建技术在开放大学招生中的应用
(一)招生图像超分时的软硬件环境
硬件配制为:intel i5及以上处理器,内存8G以上的台式机,身份证读卡器,实验时所用的读卡器为精伦品牌IDR210型号。软件开发环境为:Win7操作系统,编程语言为python3.6,工具为Anaconda集成开发平台,用到的软件包有OpenCV、OpencCV-contrib、Numpy。
(二)训练模型数据获取
对上述4种图像超分网络模型,可以通过训练集进行训练,得到收敛后的网络参数模型。在实际图像超分应用时,也可以使用相应网络模型团队训练好的模型。如在招生图像超分时选择了4倍超分模型,训练模型文件从CSDN网站下载,对应的训练模型属性如表1所示。

表1 FSRCNN、ESPCN、LapSRN、EDSR模型4倍超分训练模型属性
(三)python调用训练模型
OpencCV-contrib库中的dnn_superres模块提供了上述训练模型的调用接口,调用过程的python主要代码如表2所示。

表2 python调用训练模型过程
(四)招生图像超分结果
取开放大学招生过程中通过读卡器获取的身份证上人脸图像,作为超分的LR图像,大小为102×126像素,分别使用三次线性插值(bicubic)、FSRCNN、ESPCN、LapSRN、EDSRF进行4倍超分,超分结果如图6所示,直观上可以看出,普通的图像放大,通常采用bicubic方法得到的图像边缘呈锯齿状,效果较差。而采用图像超分技术,能得到较好效果,如LapSRN、EDSR超分结果,可用于入学后的基于人脸识别技术的考生身份证验证场景,进行图像增强,提高人脸识别精度。

图6 身份证人脸图像4倍超分结果
(五)图像超分性能评价
主要对比bicubic,FSRCNN、ESPCN、LapSRN、EDSR方法,进行4倍超分图像超分时的三项指标:所用时间、峰值信噪比(Peak Signal to Noise Ratio,PSNR)值、结构相似性(Structural Similarity,SSIM)值。
PSNR是一种基于像素点误差的图像客观评价指标,应用广泛。它计算无失真图像与超分后图像对应像素点间的误差值,值越大表示超分后的图像失真越小,其公式为:
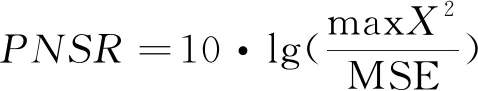
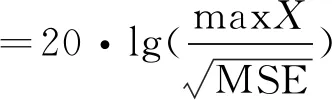
(4)
其中MSE为两幅大小为W×H的RGB三通道图像之间像素值的均方误差,公式为:
MSE=
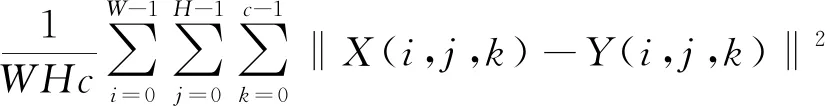
(5)
其中X
为测试时原始无失真HR图像,Y
为X
下采样后得到LR图像,再通过超分模型得到的HR图像,c
为通过数,彩色图像时取值3。SSIM是另一种图像质量评价指标,偏向于人的视觉感受,它主要从无失真图像与超分图像的亮度、对比度、结构三个方面来度量两者的相似性。SSIM取值范围为0~1,值越大,表示两张图像越相似,失真越小;反之,值越小,表示图像失真越大。其公式为:
SSIM(X,Y)=L(X,Y)
*C(X,Y)
*S(X,Y)
(6)
其中,L(X,Y)
是亮度比较,C(X,Y)
是对比度比较,S(X,Y)
是结构比较,其表达式如下: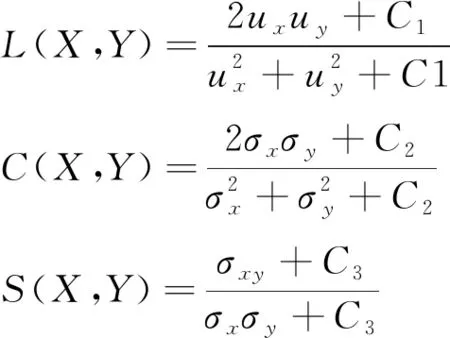
(7)
其中,u
、u
分别表示无失真图像X
与超分后图像Y
的均值,σ
、σ
分别表示两张图像的标准差,σ
表示两张图像之间的协方差。C
、C
、C
为常数,防止分母为0,通常在实际应用时α
、β
、γ
的值取1,C
取C
的一半。实验时取一张412×480大小的HR图像,通过下采样得到一张103×120大小的LR图像,分别对其进行上述五种4倍超分实验,分别统计其用时、PSNR、SSIM三项指标,得到的数据如表3所示。
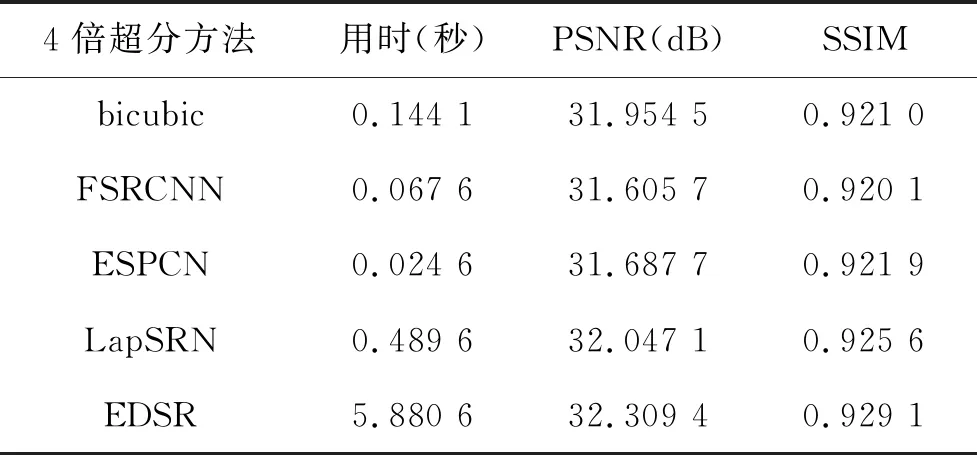
表3 图像四倍超分时各模型的用时、PNSR、SSIM数据
通过对实验结果与实验指标数据分析,可以得出结论,普通的双三次插值,效果差,图像边缘锯齿状,图像模糊,对应的PSNR、SSIM指标值也较小;FSRCNN模型得到的图像在视觉效果上优于双三次插值,且用时也少,但PSNR、SSIM指标与其接近;ESPCN模型用时最少,体现了亚像素卷积操作的优势,且PSNR、SSIM指标也优于前两种模型;LapSRN模型,在用时上接近半秒,但PSNR、SSIM指标上都有很大提升,图像质量优于前三者;EDSR模型由于使用了非常深的网络,模型参数众多,训练模型文件大小接近38 MB,所以超分图像用时最长,接近6秒,但图像超分效果最好,从PNSR与SSIM指标值上也能反映这一点。因此,在实际招生应用时,可采用EDSR模型对低分辨率图像进行超分。若应用场景考虑实时响应,可考虑使用LapSRN模型。
四、 结语
招生是开放大学办学的第一个环节,会采集很多学员的第一手数据信息,数据质量的好坏,将对后续工作产生很大影响。其中,学生提交的相关照片质量尤为重要,引入基于深度学习单张图像超分辨率重建技术,能很好解决招生过程中的低分辨率图像引发的问题。通过对主流的深度学习模型中的FSRCNN、ESPCN、LapSRN、EDSR模型网络结构的研究、4倍超分应用、评价指标分析,可以看出,EDSR模型得到的超分图像质量更高,视觉效果也最好。下一步的研究是将图像超分领域的最新研究成果应用到开放大学的招生实践中,争取获得更好的图像超分效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
河南科技(2021年35期)2021-04-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
CHIP新电脑(2016年3期)2016-03-10
软科学(2014年8期)2015-01-20
微型计算机(2009年4期)2009-12-23
