
基于深度神经网络的中国移动营业厅人流量统计研究
2021-06-07 04:50:33陈乐丁戈肖忠良
现代信息科技 2021年24期
关键词:深度神经网络
陈乐 丁戈 肖忠良

摘 要:文章提出深度神经网络的方法,将分治策略引入到人流量统计问题中。这个方法以VGG16作为特征编码网络,UNet作为解码网络,将人流量统计变成一个可拆解的任务。在统计图片上人数时,总可以把图片分解成多个子区域,使得每个区域的人流量计数都是在之前训练集上所见过的人数类别。然后再把每个子区域上面的人数加起来,就是统计结果。在对广州某个中国移动营业厅的人流量统计的实验中,预测的速度能达到实时监测的速度和高精确度。
关键词:分治策略;人流量统计;深度神经网络;VGG16;UNet
中图分类号:TP18 文献标识码:A文章编号:2096-4706(2021)24-0084-05
Abstract: In this paper, the method of deep neural network is proposed, and the divide and conquer strategy is introduced into the problem of people flow statistics. This method takes VGG16 as the feature coding network and UNet as decoding network, which turns the people flow statistics into a detachable task. When counting the number of people on the pictures, we can always decompose the picture into multiple sub-regions, so that the people flow count in each area is the number of people seen on the previous training set. Then add up the number of people in each sub-region, which is the result of statistics. In the experiment of people flow statistics in a China mobile business hall in Guangzhou, the predicted speed can reach real-time monitoring speed, and has high accuracy.
Keywords: divide and conquer strategy; people flow statistics; deep neural network; VGG16; UNet
0 引 言
截止2021年6月底,中国移动客户达到9.46亿户,线下营业厅遍布中国的每个大大小小的城市。5G套餐客户达到2.51亿户,稳居三大运营商之首[1]。面对如此庞大的客户群体,营业厅员工在多用户咨询和办理业务繁忙的时候,难免会出现服务不周到,工作效率下降的情况。而且在新冠疫情的影响下,每个营业厅的人数也要得到相应的控制。而且客户能得到精确的每个营业厅的人數,能帮助他们选择人数相对较少的营业厅办理业务。在提高中国移动的员工服务质量和精准控制营业厅人数来更好的进行防疫工作的压力之下,本文章提出了一种基于神经网络和分治策略的精准和实时的人流量统计的方法。首先,该方法需要先训练一个可以计数0到10个人的深度神经网络模型。然后再利用判别器来判断该子区域是否需要继续进行切割,若子区域的人数大于10人的时候需要继续切割。最后合并不同的子区域的结果[2]。该预测网络的整体结构是以VGG16作为特征编码器的主干网络,参考UNet作为解码器,一个计数分类器,一个划分判别器。网络结构的各个部分各司其职,相互作用,提高了模型的预测速度和准确率。
1 人流量统计算法
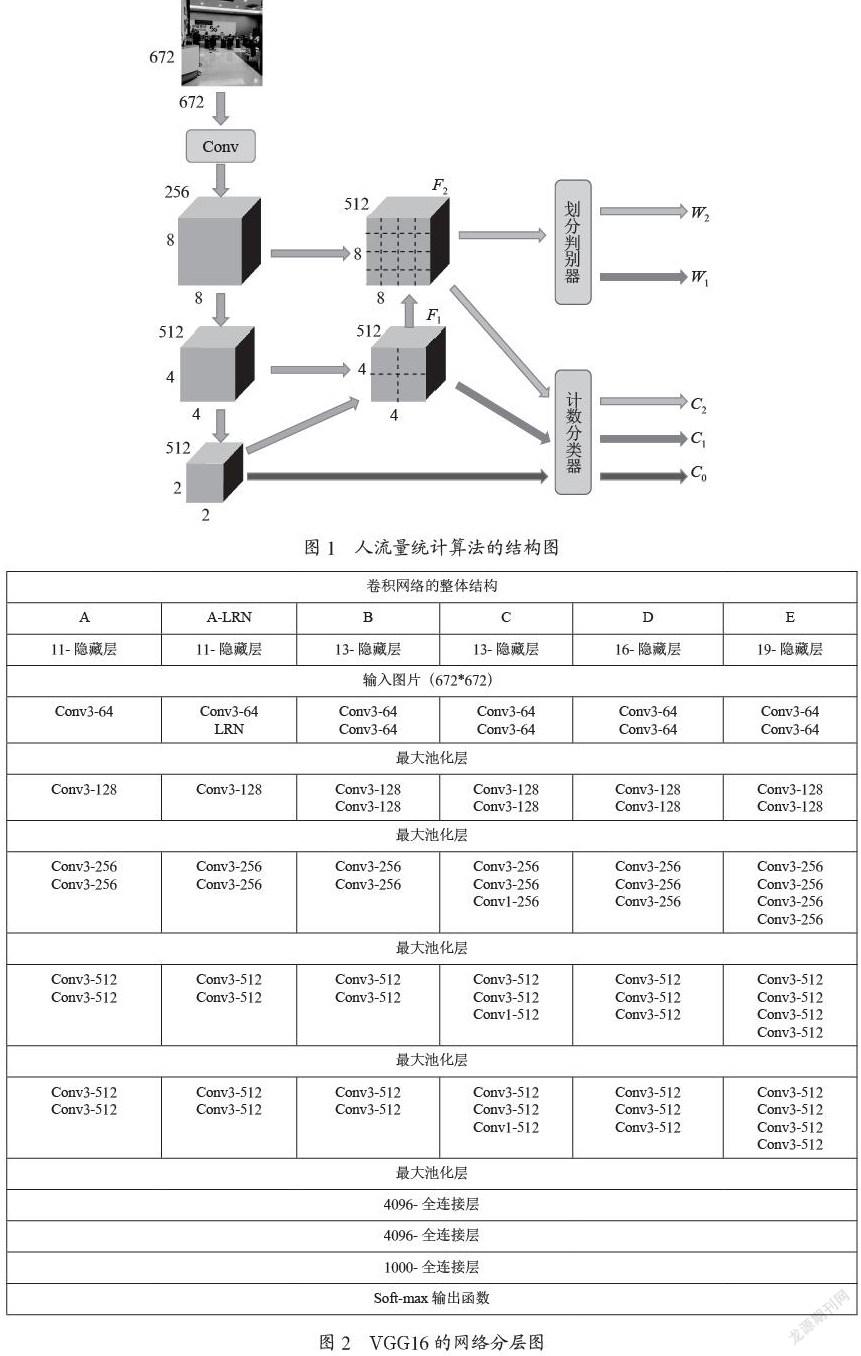
1.1 人流量统计算法的结构图
算法的整体结构如图1所示,由一个VGG16特征编码器,一个UNet型的解码器,一个计数分类器和一个划分判别器构成的。左边的Conv3,Conv4和Conv5是参考VGG16的网络进行的下采样卷积操作。中间有格子划分的F2和F1是通过上采样得到的。F1是通过F0上采样的得到的,F2是通过F1上采样得到的,它们的步长都是2。这个部分是参考UNet型的解码器得到的。F1和F2划分出来的区域就是子区域。这时划分判别器就需要判断是否要继续进行上采样,让子区域划分得更加小来满足子区域人数小于10的要求。W1和W2的值就只有(0,1),来判断是否需要继续进行“错误!未找到索引项。”上采样。最后再把特征图中的每个子区域让训练好的计数分类器来判断里面有多少人,是属于(0,10)中的哪一个类别,得到C0,C1和C2[3]。
1.2 VGG16的特征编码器
图2是原先的VGG16的网络结构层图。由图结构可知,总共有13个卷积层和3个全连接层。其中的池化部分都是用了max pooling,激活函数是用了ReLU函数。卷积核的大小都是3×3的[4]。文章人流量统计算法中的结构,就是去掉了VGG16中所有全连接层,Conv5就是上图结构中除了全连接层中的最后的输出特征图,也就是原图中的输入图片下采样32倍得到的输出特征图。Conv5的结果直接通过计数分类器,预测出C0。C0就是当前整体图片的预测输出结果,也相当于由普通的VGG16网络预测得到的结果。
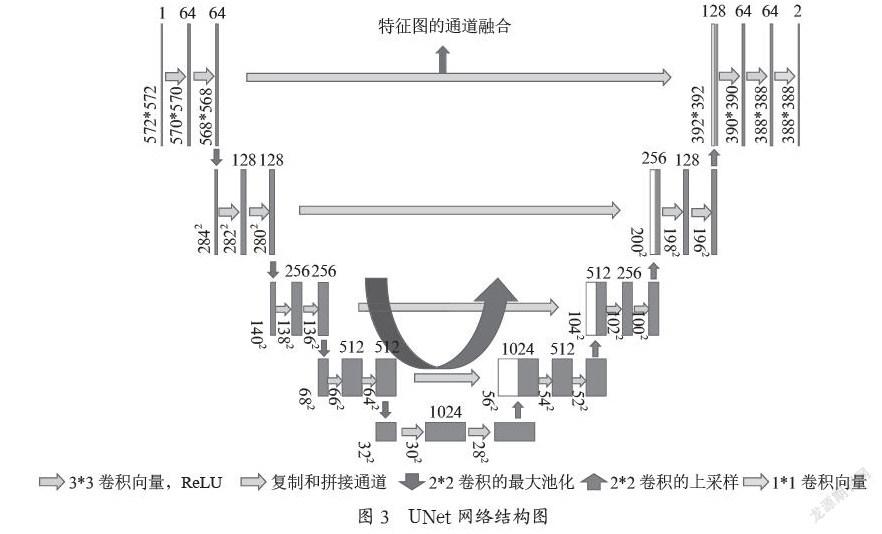
1.3 UNet的解码器
图3就是UNet网络的整个网络结构图,这个网络的左半部分是由两个3×3的卷积层和两个最大池化层,步长为2组成的,激活函数是ReLU函数[5]。左边结构每进行一次下采样,通道数都会乘以2。这个网络的右半部分是由一个2×2的上采样卷积,激活函数是ReLU函数。右边的网络通道,是由左边对应的特征图通道和经过上采样得到的特征图通道叠加的,最后得到的特征图,有一半包含了左边对应特征图的信息。因为这个池化的方式是最大池化,所以一定程度上进行下采样,都会损失了很多图片中的信息。这里的通道融合的方式,能将浅层低维度的特征图和在深层高维度的特征图的信息进行融合,让最终的特征图中蕴含着更加丰富的图片信息,让图像的预测更加的全面和准确。
1.4 划分判别器和计数分类器
划分判别器是用来判断经过特征通道融合的特征图是否需要继续进行上采样操作。图中F1的特征图就是把64×64像素的原图分为了四个子区间,每个子区间对应着16×16,但是它的感受野是整张原图。如果这个子区间的人数大于10的话,则划分判别器会让该特征图继续进行步长为2的上采样操作,直到子区间人数小于10为止[6]。划分判别器由一个2×2的平均池化层(步长为2),一个512个通道的1×1卷积和一个1个1×1输出卷积构成的,最后通过一个sigmoid函數输出0或者1。
计数分类器是一个21个类别的训练好的分类器,区间范围是0到10,间隔是0.5。该分类器是Resnet50,通过对21个类别的2 000张图片进行训练得到的具有权重的模型。如图2,F1特征图所示,里面有4个区间,这4个子区间分别作为输入,输入给计数分类器进行预测。最后将四个子区间的预测结果相加,向下取整即为最终的输出结果。
1.5 人流量统计算法的损失函数
这是人流量统计算法的损失函数:,由两个部分组合而成。左边部分是多个交叉熵损失函数,是用来监督在对子区域人数统计的不同级别的分类问题。右边部分是用来监督最终划分输出的函数。该网络可以支持多任务网络的训练方式,所以才有一个关于N次的求和[7]。
2 模型算法实验
2.1 中国移动营业厅采集数据
历时两个星期,在广州天府路中国移动营业厅用手机采集图片。采集方式是在营业时间段,每隔半个小时在营业厅的各个角度采集若干张含有人群信息的图片。然后总共采集了大概200张左右的有效图片,人数范围在10~70人左右。最后在网上开源的ShanghaiTech的数据集中融入了100张左右的图片,组成了最后400张左右的数据集,部分图片如图4所示。
2.2 生成人群热力图的标签方式
人群流量的标签方式一般有两种,一种是对人头进行检测框的标记,另外一种是直接对图片生成热力图,如图5所示。对于采集到的数据集,需要标记它们的真实标签即图片中的真实人数。标签方式是生成人群热力图,然后人群流量统计就变成了对热力图的积分计算,甚至可以计算每平方米的人数和聚集程度,来判断相应的需求[8]。原图上的标注方式是,在人头所在的像素点上标记一个红点,然后再根据红点生成相应的人群热力图[9]。
2.3 训练网络
本文采用深度神经网络的方法来预测中国移动营业厅的真实实时人数。采用将原图区域进行划分成若干个子区域,再在子区域进行预测人数的方式来预测真实人数。该方法训练网络的步骤如下:步骤一:数据预处理,对采集好的图片进行降噪和除去黑白噪点的操作。使得图片更加的平滑,过滤掉无效信息的图片。步骤二:数据增强,因为采集的数据不是特别的充足,所以对图片进行随机裁剪和翻转的操作增强数据集的数量。步骤三:根据标记好的红点,生成每一张图片的人群密度热力图。步骤四:模型训练,把数据集按照8:1:1的比例,将数据集分为训练集、验证集和测试集。随机初始化网络中的所有参数,batch size设置为64,把每一批的数据集喂给模型进行正向传播和反向传播进行参数的更新。训练次数设置为100,最后选取训练了至少50次的损失函数值最小的模型为最佳的训练模型。
3 模型预测结果分析
3.1 中国移动营业厅数据集的标签人数分布
从经历半个月左右的时间在中国移动营业厅收集到的数据,图6可见,营业厅大部分的人流数量集中在20人到60人。有时候比较繁忙的时候能达到100人左右。由于这种人数,所以训练分类网络的时候,把子区域的人群计数分类定为了0-10人的范围。
3.2 损失函数和预测效果评估
人流量统计模型的损失函数由分类的交叉熵损失和回归函数共同组成,所以选用最小二乘法的梯度下降训练方法。损失函数一般是用来测试训练模型的时候真实值和预测值的差异的,一般来说损失函数的值越低,模型的预测效果越好。但是一般来说会选择验证集中,真实值和预测值最小的模型作为最终的模型参数输出[10]。图7就是训练模型时候的损失函数和准确率。
在测试集中测试模型性能的方法是平均绝对误差,即真实值和预测值的差值的绝对值和的平均值。平均绝对误差的公式:[11]。在测试集上的结果是,平均绝对误差:0.27即每次预测只差了0.27个人数的统计。结果的准确率(误差少于1)为98.87%。从结果上来看,模型预测的准确度还是十分可观的。而且模型在一秒钟内可以预测大概30张到40张的图片,满足的实时监测的需求。
4 结 论
本文提出一种基于分治策略,将原图分割成若干个子区域进行区域计数的人流量统计的深度神经网络模型。该网络模型参考了传统神经网络VGG16作为特征提取的主干网络和UNet网络作为解码器。在测试和预测真实的中国移动营业厅时,模型的人数准确率基本保障不会出现错误而且能达到实时更新营业厅人数的效果。这很好的满足的让营业厅的营业员精准定位服务,而且能让客户根据每个营业厅的实时人数来选择人数更少的营业厅办理业务。在疫情管控营业厅的实时人数时,可以起到监督和监控的作用。
参考文献:
[1] 中国移动.营运数据 [EB/OL].[2021-09-25].https://www.chinamobileltd.com/sc/ir/operation_q.php.
[2] SAM D B,SAJJAN N N,BABU R V,et al. Divide and Grow:Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE:Salt Lake City,2018:3618-3626.
[3] BADRINARAYANAN V,KENDALL A,CIPOLLA R. SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation [J/OL].arXiv:1511.00561 [cs.CV].(2015-11-02).https://arxiv.org/abs/1511.00561.
[4] HE K M,ZHANG X Y,REN S Q,et al. Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification [J/OL].arXiv:1502.01852 [cs.CV].(2015-02-06).https://arxiv.org/abs/1502.01852.
[5] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].(2014-09-04).https://arxiv.org/abs/1409.1556.
[6] LEMPITSKY C,ZISSERMAN A. Learning To count objects in images [C]//NIPS10:Proceedings of the 23rd International Conference on Neural Information Processing Systems.Red Hook:Curran Associates,2010:1324-1332.
[7] LI R B,XIAN K,SHEN C H,et al. Deep attention-based classification network for robust depth prediction [J/OL].arXiv:1807.03959 [cs.CV].(2018-07-11).https://arxiv.org/abs/1807.03959.
[8] NIU Z X,ZHOU M,WANG L,et al. Ordinal Regression with Multiple Output CNN for Age Estimation [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:4920-4928.
[9] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[10] IDREES H,TAYYAB M,ATHREY K,et al. Composition Loss for Counting,Density Map Estimation and Localization in Dense Crowds [J/OL].arXiv:1808.01050 [cs.CV].(2018-08-02).https://arxiv.org/abs/1808.01050.
[11] MASKA M,ULMAN V,SVOBODA D,et al. A benchmark for comparison of cell tracking algorithms [J].Bioinformatics,2014,30(11):1609-1617.
作者簡介:陈乐(1982—),男,汉族,重庆人,项目总监,硕士研究生,研究方向:AIOps、业务支撑系统运营支撑;丁戈(1995—),男,汉族,广东广州人,项目经理,硕士研究生,研究方向:AIOps算法;肖忠良(1986—),男,汉族,广东广州人,项目经理,硕士研究生,研究方向:AIOps、业务支撑系统运营支撑。
猜你喜欢
计算机应用(2019年2期)2019-08-01 01:57:38
现代电子技术(2019年13期)2019-07-08 05:33:51
软件工程(2019年5期)2019-07-03 02:31:14
电脑知识与技术(2019年2期)2019-03-15 13:31:28
现代电子技术(2018年24期)2018-12-14 09:05:06
无线互联科技(2018年6期)2018-06-25 07:34:40
现代电子技术(2018年6期)2018-03-13 22:28:09
科教导刊·电子版(2017年13期)2017-07-24 08:26:51
电子技术与软件工程(2017年4期)2017-03-27 21:51:30
电脑知识与技术(2016年22期)2016-10-31 20:23:56
