
基于Kaldi的语音识别算法
2019-03-15 13:31杨胜捷朱灏耘冯天祥陈宇
电脑知识与技术 2019年2期
关键词:语音识别
杨胜捷 朱灏耘 冯天祥 陈宇


摘 要:为了改善传统语音识别算法识别不够准确且消耗时间较大的问题,本文提出了一种基于Kaldi的子空间高斯混合模型与深度神经网络相结合的算法进行语音识别。针对声音频率信号识别率较低的问题,本文采用了快速傅立叶变换和动态差分的方法进行MFCC特征提取。实验证明,相比于单独的SGMM、SGMM+MMI等语音识别算法,该算法对语音识别的错误率更低,对语音识别的研究具有重大意义。
关键词: 语音识别;Kaldi;子空间高斯混合模型;深度神经网络
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2019)02-0163-04
Speech Recognition Algorithm Based on Kaldi
YANG Sheng-jie ,ZHU Hao-yun , FENG Tian-xiang, CHEN Yu*
(School of Information and Computer Science, Northeast Forestry University, Harbin 150040, China)
Abstract: In order to improve the problem that the traditional speech recognition algorithm is not accurate enough and consumes a lot of time, this paper proposes a Kaldi-based subspace Gaussian mixture model combined with deep neural network for speech recognition. Aiming at the problem that the recognition rate of sound frequency signal is low, this paper adopts the method of fast Fourier transform and dynamic difference to extract MFCC features. Experiments show that compared with the speech recognition algorithms such as SGMM and SGMM+MMI alone, the algorithm has a lower error rate for speech recognition, which is of great significance for speech recognition research.
Key words: Speech recognition; Kaldi; subspace Gaussian mixture model; deep neural network
随着互联网技术的高速发展,实现人与计算机之间的自由交互变得尤为重要,作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。
语音识别(Automatic Speech Recognition, ASR)是指利用计算机实现从语音到文字自动转换的任务[1]。在实际的应用过程中,语音识别通常与自然语言理解、自然语言生成和语音合成等技术结合在一起,提供一个基于语音的人与计算机之间的自由交互方法。
语音识别最早起源于1952年的贝尔实验室,它是世界上第一个能够识别10个英文发音的识别实验系统,早期的语音识别系统是简单的孤立词识别系统,在20世纪60年代以后计算机的广泛应用推动了语音识别技术的蓬勃发展,到了20世纪80年代,语音识别的研究中心从孤立词识别进步到了连接词的识别,隐马尔科夫模型(Hidden Markov Model,HMM)[2]的理論和方法得到了长足的发展,语音识别研究产生了巨大的突破,进入90年代以后,由于HMM整体框架设计以及模型的自适应方面取得了一些突破性进展,人工神经网络技术也得到发展,因此这个时期的语音识别技术突飞猛进,语音识别系统也从实验室走向实际应用。
在我国,语音识别的研究工作一直紧跟国际发展潮流。最早,由中国科学院声学研究所的马大猷院士领导的科研小组对汉语的语音信号进行了系统研究,到70年代末期取得突破性进展。在20世纪80年代,研究语音识别的人越来越多,很多科学家和科研院所都投入其中,然后汉语的全音节语音识别技术取得了相当大的进展,同时清华大学的教授提出了基于段长分布的HMM语音识别模型,极大推动了我国的语音识别技术的发展。到了新世纪,汉语语音识别技术相关应用进入蓬勃发展阶段,涌现了很多的相关企业,如中科信利、科大讯飞、中科模识、微信等等。语音识别技术历经长足的发展,慢慢趋于成熟,现在更是大数据与深度神经网络的时代,许多实际应用的产品也由此产生。所以,让人机进行语音的交互已经变得可能,让高可靠性的便捷人机交互能直接服务人类的工作和生活,从而使人们的生活能够更加舒适方便。
本文采用的是使用Kaldi开源语音识别工具箱作为语音识别的平台,采用子空间高斯混合模型(Subspace Gaussian Mixture Model, SGMM)、深度适配网络(Deep Adaptation Netowrk, DAN)与深度神经网络(Deep Neural Network, DNN)算法相结合对语音进行识别。Kaldi是一个基于C++编写的用于语音识别的开源工具箱,Kaldi一般被用于进行语音识别的研究者和相关人士。子空间高斯混合模型的每一个状态依然对应一个混合高斯函数 (GMM),只是该混合高斯函数的均值、方差,权重通过一个向量分别和均值、方差、权重的映射矩阵计算得到,该向量与当前状态相关,然而参数的映射矩阵被所有状态共享,这使得在有限的训练数据下,模型参数能够得到更加充分的训练。由于深度特征随着网络层数的增加由一般转变到特殊,特征的可迁移能力在网络比较高的层次就会急剧下滑,增加了域之间的差异性。因此为了提高特征层的可迁移能力显得尤为重要,所以本文采用深度适配网络(DAN)来减少域之间的差异性,DAN作为深度迁移学习的代表性方法,充分利用了深度网络的可迁移特性,使得语音识别的学习型更强,迁移能力更好。实验表明,采用子空间高斯混合模型、深度适配网络与深度神经网络相结合的算法能够使得语音识别的错误率更低。
1 基本理论
1.1 深度学习
深度学习(Deep Learning)[3]是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。
深度学习的基础是机器学习中的分散表示(Distributed Representation)。分散表示假定观测值是由不同因子相互作用生成。在此基础上,深度学习进一步假定这一相互作用的过程可分为多个层次,代表对观测值的多层抽象。深度学习运用了这分层次抽象的思想,更高层次的概念从低层次的概念学习得到。这一分层结构常常使用贪婪算法逐层构建而成,并从中选取有助于机器学习的更有效的特征。至今已有数种深度学习框架,如深度神经网络、卷积神经网络和深度置信网络和递归神经网络已被应用在计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。
1.2 深度神经网络
神经网络技术起源于20世纪五、六十年代,当时叫作感知器[4-5],拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果,但是由于它对一些复杂函数的处理无能为力,所以深度神经网络就诞生了。深度神经网络内部的神经网络层可以分为三类:输入层、隐藏层和输出层,一般来说第一层是输入层,最后一层是输出层,中间的层数都叫作隐藏层,如下图所示:
在DNN中层与层是全连接的,虽然看起来很复杂,但是从小的局部模型来说,是跟感知器一样,是一个线性关系:
[y=f(W?x+b)] (1)
在公式(1)中,[y]代表输出向量,[x]代表输入向量,[W]代表权重矩阵,[f]代表激活函数,[b]代表偏移向量。
深度神经网络与大多数传统的机器学习算法不同,它无须人工干预即可执行自动特征提取,在对未标记数据进行训练时,深层网络中的每个节点层通过重复尝试重建从中抽取样本的输入来自动学习特征,尝试最小化网络猜测与输入数据本身的概率分布之间的差异。例如,受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[6]以这种方式创建所谓的重建。深度神经网络处理和学习大量未标记数据的能力相比较于以前的算法,还是有很大的优势,但也同样具有一定的缺陷,深度神经网络在训练模型时耗时太长,训练成本太高。
1.3 子空间高斯混合模型
高斯混合模型(Gaussian Mixture Model, GMM)是单一高斯概率密度函数的延伸,GMM能够平滑地近似任意形状的密度分布。高斯混合模型种类有单高斯模型(Single Gaussian Model, SGM)和高斯混合模型(Gaussian Mixture Model, GMM)两类。类似于聚类,根据高斯概率密度函数(Probability Density Function, PDF)参数不同,每一个高斯模型可以看作一种类别,输入一个样本x,即可通过PDF计算其值,然后通过一个阈值来判断该样本是否属于高斯模型。很明显,由于高斯混合模型中参数数量非常大,因此提出了子空间高斯混合模型(Subspace Gaussian Mixture Model, SGMM)[7],SGMM的拓扑结构与GMM的拓扑结构大致相同,只是在输出概率的参数上有所差异,SGMM的输出概率公式如下:
[p(x|j)=i=1IwjiN(x;μji,i)] (2)
[μji=Mivj] (3)
[wji=expwiTvji'=1Iexpwi'Tvj] (4)
这里[x]是特征向量,[j]是状态的索引,所有的状态均有[I]个高斯,每个高斯的均值,权重通过与每个状态相关的矢量[vj]映射得到。在这里,“子空间”的意思就是GMM的参数是整个[I]维混合模型的子空间。式(4)中权重在进行了归一化处理以确保它们的和为[1]。
1.4 Kaldi语音识别系统
Kaldi语音识别工具主要关注子空间高斯混合模型的建模,是一个开源的语音识别系统,主要用C++实现。Kaldi的目标是提供一个易于理解和拓展的更先进的识别语音系统。Kaldi通过SourceForge发布更新,它可以在通用的类Unix环境和Windows环境下编译[8]。Kaldi具备了如下几个重要的特性:整合了线性代数拓展、整合了有限状态转换器、代码设计易于扩展、开放开源协议、完整的语音识别系统搭建工具。Kaldi系统框架如下图所示:
Kaldi主要依赖两个外部开源库:BLAS/LAPACK和OpenFST[9]。Kaldi本身的模块可以划分为两个部分,这两个部分都只能依赖外部库。这两个部分通过Decodable接口连接。
通过C++编写的命令行工具可以访问库函数,一般通过编写脚本文件来构造语音识别系统[10]。每一个命令行工具都能完成特定的任务,并且只有少量的参数。除此之外,所有的工具都支持从管道读写,这使得每个工具之间的输入输出更方便衔接。
2 实验过程及结果
2.1实验过程
本实验采用TIMIT(The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus)语音数据库作为语音识别的实例,TIMIT语音库是IT和MIT合作音素级别标注的语音库,用于自动语音识别系统的发展和评估,包括来自美式英语,8个地区方言,630个人。每个人读10个句子,每个发音都是音素级别、词级别文本标注,16kHz、16bit。
TIMIT官方文档建议按照7:3的比例将数据集划分为训练集(70%)和测试集(30%),训练集(Training)包括由462个人所讲的3696个句子,全部测试集(Complete test set)包括由168个人所讲的1344個句子,核心测试集(Core test)包括由24个所讲的192个句子,训练集和测试集没有重合。具体如下表所示:
选择实例完毕后,采用上文提到的方法对TIMIT进行语音识别,通过(SGMM+DAN+DNN)对其进行训练和测试并得到实验结果。基于Kaldi的语音识别的实验流程如下图所示:
2.2实验结果
实验过程中,用快速傅立叶变换(FFT)对所选的样本进行特征提取,特征提取后,生成语音模型文件,将一部分的数据作为测试数据,一部分数据留作检验精度。接下来采用DNN+SGMM算法对提取出来的MFCC特征数据进行训练和测试,实验过程中,将TIMIT数据集分成两组,一组作为训练数据,一组作为测试数据进行特征提取,共有两类数据,初始化参数,得到错误率%WER。
为了对比深度学习网络的识别率,我们选用相同的验证样本和测试样本并用不同的分类算法进行分类,分别使用SGMM、SGMM和MMI算法相结合进行实验。从图5中可以看出,SGMM+MMI算法相对较差,SGMM单独训练结果较好,但是最终的效果都不如SGMM+DNN学习网络,说明SGMM+DNN算法在语音识别中错误率最低,效果显著。
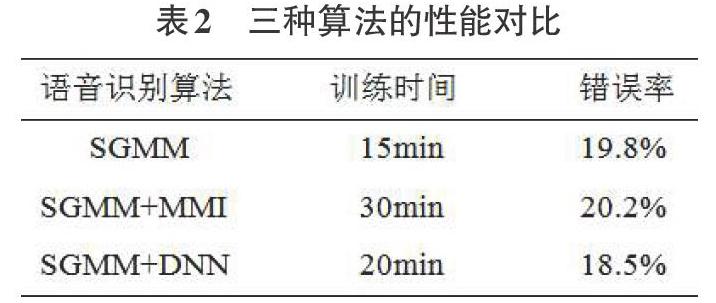
在用相同的测试集样本数据并用三个语音识别算法分别进行实验时,同时记录下每个语音识别算法的训练时间。可以得到表2中的结果,从结果中我们可以看出,SGMM+DNN的训练时间相比SGMM+MMI较长。但是从识别效果上来说,要远比其他算法更强。
另外在选取若干样本,分别用SGMM、SGMM+MMI和SGMM+DNN对其进行语音识别,分别测出验证集和测试集的错误率,可以得到如表3中的数据:
由表3中可以看出三种语音识别算法的验证集的错误率明显低于测试集,这是由两类样本的数据规模决定的,验证集的数据规模较小,所以错误率低。但是SGMM+DNN的识别效果比较稳定,证明SGMM+DNN语音识别效果更好。
3 结论
本文提出了用子空间高斯混合模型与深度神经网络学习算法对语音进行识别,通过快速傅里叶变换对语音MFCC进行特征提取,提取动态差分的参数,可以大量节省计算机硬件的运算和存储消耗,将特征矩阵输入到深度神经网络,用深度学习算法对其进行训练和解码。经过实验,相比于单独的SGMM和SGMM与MMI相结合,用本文提出的方法能够实现对语音的识别。所以,SGMM+DNN算法应用在语音识别中,取得了明显的效果,为语音识别方向开拓了新的视野。
参考文献:
[1] 何湘智.语音识别的研究与发展[J]. 计算机与现代化, 2002(3):3-6.
[2] 吴义坚.基于隐马尔科夫模型的语音合成技术研究[D]. 中国科学技术大学, 2006.
[3] 毛勇华,桂小林, 李前,等. 深度学习应用技术研究[J]. 计算机应用研究, 2016, 33(11):3201-3205.
[4] Wright H Z, Lee S C, Wright S, et al. Outreach in Armenia: chronic disease awareness, prevention and management[J]. Annals of Global Health, 2015, 81(1):103-104.
[5] 李伟林,文剑, 马文凯. 基于深度神经网络的语音识别系统研究[J]. 计算机科学, 2016, 43(s2):45-49.
[6] Gao X, Fei L I, Wan K. Accelerated Learning for Restricted Boltzmann Machine with a Novel Momentum Algorithm[J]. Chinese Journal of Electronics, 2018, 27(3):483-487.
[7] 付强.基于高斯混合模型的语种识别的研究[D]. 中国科学技术大学, 2009.
[8] 胡文君,傅美君,潘文林.基于Kaldi的普米语语音识别[J]. 计算机工程, 2018(1):199-205.
[9] 李平.远距离混合语音识别方法的研究[D]. 辽宁工业大学, 2016.
[10] 张强.大詞汇量连续语音识别系统的统计语言模型应用研究[D]. 西南交通大学, 2009.
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
