
基于学习向量量化在蜂蜜LIF光谱图像识别的应用*
2021-06-03 08:36周孟然
重庆工商大学学报(自然科学版) 2021年3期
汤 超, 周孟然
(安徽理工大学 电气与信息工程信息学院,安徽 淮南 232001)
0 引 言
当今社会,人们对蜂蜜的需求越来越大,但是近几年来蜂蜜以次充好的问题愈发严重,因此对蜂蜜的检测与分类就愈发重要。目前,蜂蜜分类鉴定的常用方法包括液相色谱法和气相色谱法、电子舌法、红外光谱法、稳定同位素技术等。液相色谱法与气相色谱法虽然具有简单、快速等特点,但是在实验前需要对样本进行处理;电子舌法[1-2]是通过构建电子舌系统,通过系统对蜂蜜中的测试物质的响应获得数据识别蜂蜜的类型,电子舌法虽然具有识别速度快等特点,但是受到传感器阵列限制,识别的准确率较低;红外光谱法[3-5]是通过红外光对蜂蜜照射获取红外光谱数据,再利用红外光谱数据对蜂蜜类型进行分析识别,红外光谱法虽然具有鉴定速度快,无污染等特点,但是其灵敏度低;佘僧[6]利用稳定同位素技术对蜂蜜进行分类识别,稳定同位素技术虽然识别准确率高,但其灵敏度低,价格昂贵且不能广泛被应用。
激光诱导荧光(Laser Induced Fluorescence,LIF)技术的特点包含灵敏度高、快速检测、易推广等;而学习向量量化(LVQ)算法的特点包含其算法简单、方便、可以抑制噪音干扰。因此提出一种基于LIF技术与LVQ算法有机结合的方法对蜂蜜进行分类识别。该方法可以解决目前蜂蜜检测技术不能快速准确鉴定的问题,能够满足对蜂蜜快速准确鉴定的要求。
1 实验与方法
1.1 实验仪器
蜂蜜的荧光光谱是在蜂蜜检测实验平台上采集的,图1为激光诱导荧光光谱实验系统框图。实验使用的激光诱导荧光光谱仪是USB200+的微型光纤光谱仪,实验中使用的激光源是一个405 nm的蓝紫色半导体激射器,实验中设置入射激光功率为120 mw,实验将鉴定的荧光光谱范围设置为340-1 021 nm,分辨率设置为0.5 nm。实验所用于蜂蜜鉴定的探针设置为FPB-405-v3沉浸式激光激发荧光探针,可直接放入待测蜂蜜中,获得实时光谱数据。实验的光纤接口是SMA905接头。采集的蜂蜜的荧光光谱在经过滤除无用波段的荧光处理后,将直接通过光纤送到光谱仪中,最后,利用光谱套件软件采集并记录蜂蜜在光谱波段范围内的荧光光谱。
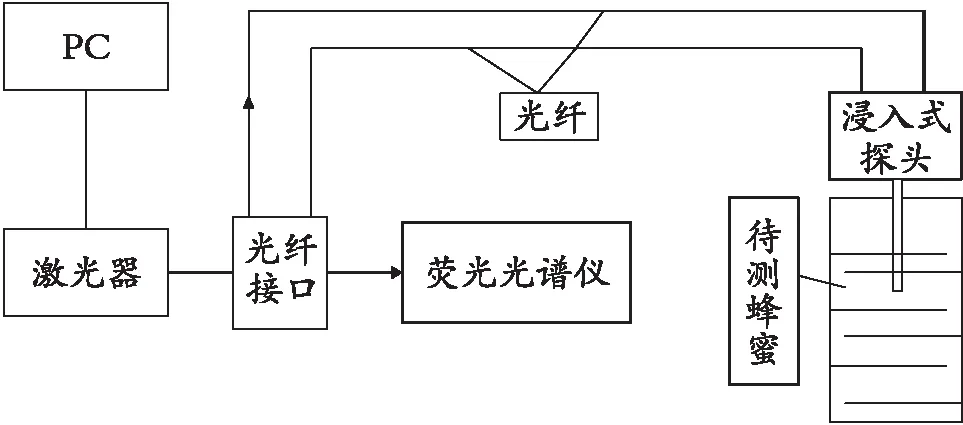
图1 实验系统框图Fig. 1 Experimental system block diagram
1.2 蜂蜜采集
蜂蜜有很多种,例如从百种花中采集的百花蜜;源于八叶五加或者鹅掌柴的冬蜜;稀有蜜种龙眼蜜等。选取常见的4种蜂蜜类型为实验样本,分别命名为蜂蜜A、B、C、D,其中蜂蜜A样本为洋槐蜜,蜂蜜B样本为紫云英蜜,蜂蜜C样本为椴树蜜,蜂蜜D样本为百花蜜。这4种蜂蜜的特性如表1所示。

表1 蜂蜜的种类与参数Table 1 Types and parameters of honey
1.3 实验方法
1.3.1 LIF技术
LIF是利用激光作为激发光照射能产生荧光的物质,产生荧光并对其荧光进行分析,与目前常用的荧光分析方法相比,激光诱导荧光法是利用激光作为荧光物质的激发光源,因此激光诱导荧光法具有灵敏度更高、检测效果更好的特点。LIF技术具有灵敏度高和快速检测的特点,故LIF被广泛应用在医疗、化工、生物等场合。例如,来文豪[7]将多元宇宙优化(MVO)算法与无监督学习算法(DBSCAN)和LIF有机结合用于煤矿突水的鉴定;周孟然等[8]将LIF与iPLS算法有机结合对煤矿突水进行鉴定;李大同等[9]将AdaBoost算法于LIF结合对矿井突水水源进行识别,武桂芬等[10]将激光诱导荧光技术用于疾病诊断中;万文博等[11]将激光诱导荧光应用于植物寿命的校正。
1.3.2 主成分分析法
特征提取是对研究对象的分析和变化,改变研究对象的测量值,比较研究对象的前后差异,突出研究对象代表性特征的一种方法。研究与比较改变测量值前后的研究对象,可以从研究对象中提取可以代表研究对象特征的方法。实验所采集的4种不同蜂蜜的荧光光谱图是由不同的波段荧光强度组成,其所采集的光谱图的维度高,因此将会对所采集的光谱图进行特征提取。笔者将主成分分析法(Principal Component Analysis,PCA)用于对蜂蜜分类鉴定,其算法是目前运用最广泛的一种降维算法,完全不需要对其进行参数设置。假定有m个样本数据,其样本数据有n个变量;并且X∈Rm×n,故
相关系数矩阵R的公式为
其中,rij(i=1,2,…,m;j=1,2,…,n)是xi与xj的相关系数。通过特征方程|λE-R|=0(E为单位向量)的公式,可以获取矩阵特征值λj(j=1,2,…,n)并且矩阵特征值要满足以下公式:λ1≥λ2≥…≥λn≥0,矩阵特征值λj对应的特征向量是αj(j=1,2,…,n)。在通过对特征向量αj相应的计算与变化,就可以获取主成分累积贡献率,其累计贡献率只要达到95%时,就可以获取对应的主成分个数P(p≤n)。
1.3.3 学习向量量化
学习向量量化神经网络是从Kohonen竞争算法演变过来的。人们利用竞争网络结构的基础,通过一系列的变化,演变出了LVQ网络算法,该算法有机地结合了竞争学习和监督学习的优点,消除了竞争学习和监督学习的缺点。LVQ神经网络具有网络结构简单、易于操作的特点。故该算法被大量运用在对研究对象进行识别和分类的场合,如通过对腕部运动肌电信号[12]数据进行识别来判断是否有肌肉疾病;LVQ神经网络也被大量应用于对图像[13-14]的处理上;LVQ通过对获取的种子数据[15-16]进行处理,筛选出优良的种子。LVQ神经网络结构如图2所示,由图2可知,学习向量量化包含输入层、竞争层、输出层。
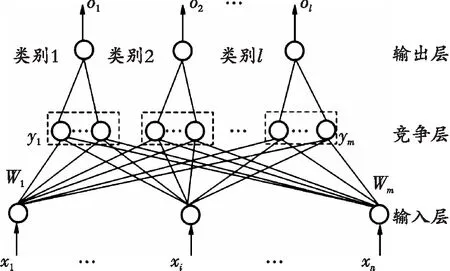
图2 LVQ神经网络网络结构Fig. 2 LVQ neural network network structure
LVQ学习算法的步骤如下所示:
(1) 假设有一训练样本为A,训练样本X=[x1,x2,…,xn]T,X的种类将用l表示,输出层的神经元m初始值的矢量将用Wm表示,学习率为η(0),T表示网络可以迭代的最大次数,实验允许误差为ε。
(2) 输入向量X,在神经网络的输出阵列中,将寻找和X匹配神经元,其神经元要求为与X距离最近,其表示为i,神经元i的种类为Ci。
(3) 根据LVQ分类的结果是否正确来确定调整获胜神经元的权值,即假如l=Ci,则:Wi(t+1)=Wi(t)+η(t)[X-Wi(t)];假如l≠Ci,则:Wi(t+1)=Wi(t)-η(t)[X-Wi(t)]。其中,学习率η(t)的大小在区间(0,1),其学习率具有对网络权值过大时进行抑制的作用。
(4) 通过对训练样本的观察,择取下一个输入矢量,将其输入矢量带入到LVQ分类学习模型中,返回步骤(2),重复以上过程,直到全部的矢量都可以在LVQ分类学习模型中运行一遍。
(5) 对神经网络的结束条件进行鉴定,看是否满足结束条件,假如满足结束训练,就会结束训练,否则就会降低学习率η(t),继续返回步骤(2),重新开始进行训练。
1.4 算法流程
利用PCA算法与LVQ算法有机结合,对蜂蜜的光谱数据进行识别,算法流程如图3所示:LIF获取蜂蜜的光谱图;蜂蜜光谱图预处理;PCA对数据进行特征提取;建立蜂蜜的特征数据库;将建立好的数据库分成训练集与测试集,并将训练集输入LVQ进行训练;将测试集输入训练好的LVQ网络,进行结果分析。
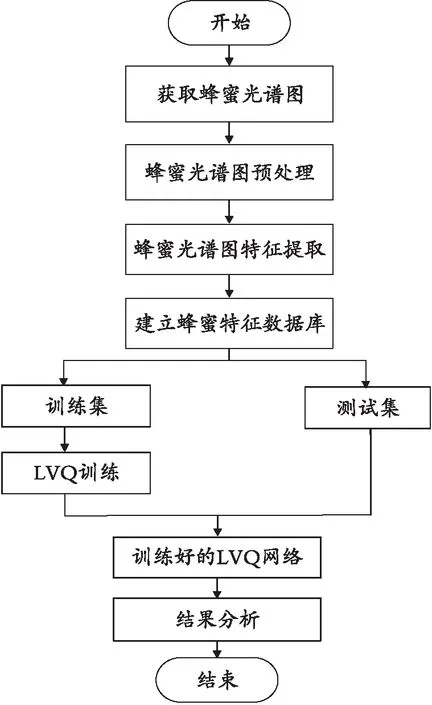
图3 算法流程图Fig. 3 Algorithm flow chart
2 实验过程与分析
2.1 蜂蜜的荧光光谱图
在图1所示的实验平台上进行采集蜂蜜光谱的实验。为了采集的光谱数据的准确性,减少无关因素对实验造成的影响,采集蜂蜜光谱数据的实验是在安静无光、温度相对恒定的实验室中进行的。在实验中,4种蜂蜜类型各采集了50组光谱数据,即4种蜂蜜类型样本总共采集了200组光谱数据,所有的光谱数据采集是在一次实验中完成的。为了蜂蜜光谱图显示得更加清晰,故采集后的蜂蜜荧光光谱图经SG方法预处理后,将选择在340 nm~1 021 nm 波段中进行绘制,绘制的4种蜂蜜样本的荧光光谱图如图4所示。图4中曲线从上到下依次是洋槐蜜、紫云英蜜、椴树蜜、百花蜜。
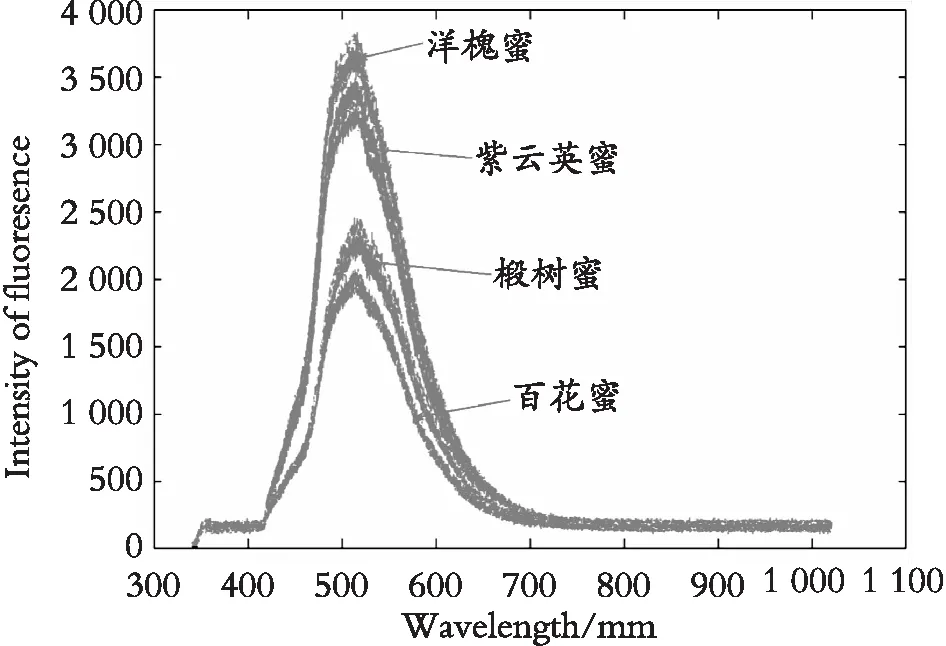
图4 实验蜂蜜原始荧光光谱图Fig. 4 Original fluorescence spectrum of experimental honey
2.2 PCA降维数据
实验中,用于蜂蜜光谱数据采集的USB200+光谱仪的像素为2 048,即每次采集的蜂蜜光谱曲线有2 048个波长点。要用LVQ神经网络算法在激光诱导荧光光谱进行识别,需要对原始的光谱图进行特征提取,运用PCA算法对原始的蜂蜜光谱图进行特征提取,即可以提高蜂蜜识别的准确率并且还可以减少算法运行的时间。将利用LIF技术采集的蜂蜜荧光光谱图数据输入PCA算法中,将PCA的累计贡献率设置为95%,对应的主成分的个数为2;将PCA的累计贡献率设置为99%,对应的主成分的个数为3,如图5所示。通过PCA将蜂蜜的光谱图的2 048维数据降到了3维数据,在不损失蜂蜜的重要特征的前提下,利用PCA算法降低数据的维度,可以减少算法运行时间,提高算法的准确率。
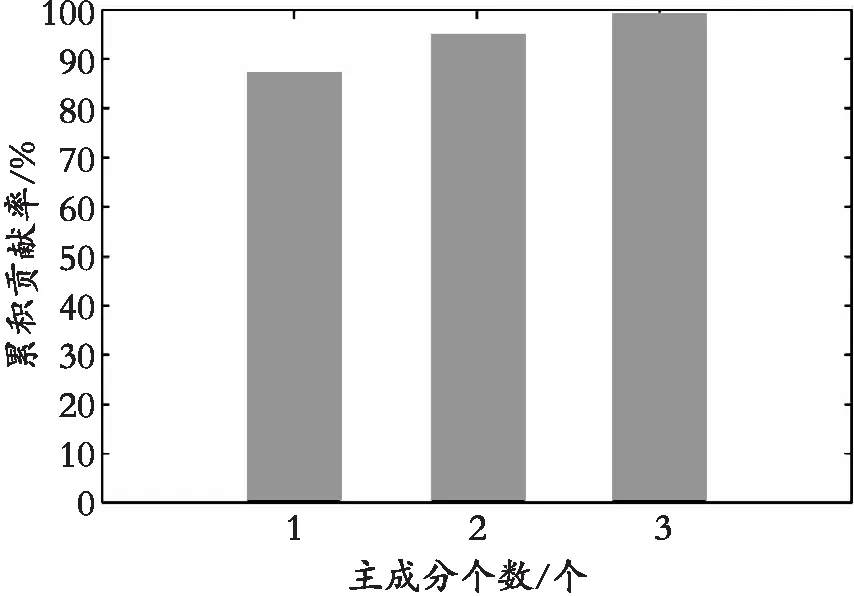
图5 主成分累计贡献率
2.3 学习向量量化的参数设置
将经过PCA算法降维后的光谱数据输入LVQ学习分类模型中,对蜂蜜进行识别分类,在进行LVQ神经网络分类学习过程中,需将原始的激光诱导荧光光谱图数据归一化到[-1,1]区间中,再通过PCA算法对原始的激光诱导荧光光谱图数据进行降维操作,并将其降维后的特征信息映射到特征空间。采集200组蜂蜜激光诱导荧光光谱数据,现随机抽取120组蜂蜜激光诱导荧光光谱数据作为训练集,其余80组作为测试集。然后将通过PCA算法降维后取得的数据作为LVQ神经网络分类的输入,在训练集上通过LVQ神经网络分类学习获得分类模型,然后再将80组数据在测试集上进行测试,以此来验验证分类的效果。
在LVQ神经网络分类学习过程中,需要对LVQ神经网络进行参数设置。即需确定LVQ神经网络的输入层、竞争层、输出层的节点个数。蜂蜜的原始光谱图经SG方法预处理后,将其进行PCA降维,有图5可知,提取的特征信息个数为3,即LVQ输入层的节点个数设置为3;把4种类型的蜂蜜进行1分类,故LVQ神经网络的输出层节点个数设置为4;在LVQ神经网络竞争层的节点个数设置中,笔者将利用5折交叉验证法。通过100次试验验证选择最优的竞争层的节点个数。当LVQ算法与PCA有机结合时,竞争层的节点个数最优为12个,当LVQ单独进行分类学习时,竞争层的节点数最优为9个。LVQ神经网络的参数设置如下:最大训练次数设置为200次;显示频率设置为10;训练目标最小误差设置为0.01;学习率为0.01。
3 实验结果与总结
采用了LVQ神经网络算法,并与PCA算法有机结合建立分类学习模型,对蜂蜜进行分类识别,并且与LVQ分类模型、PCA+BP分类模型相互比较。3种分类模型都是在Matlab 2019环境中运行的,其算法运行的硬件环境为Core i5-5200U 2.2GHz CPU,RAM 4 GB。针对蜂蜜的光谱样本,3种分类模型各运行了100次,记录3种分类模型平均的训练时间、平均分类准确率和标准差,比较3种分类模型的性能,如表2所示。
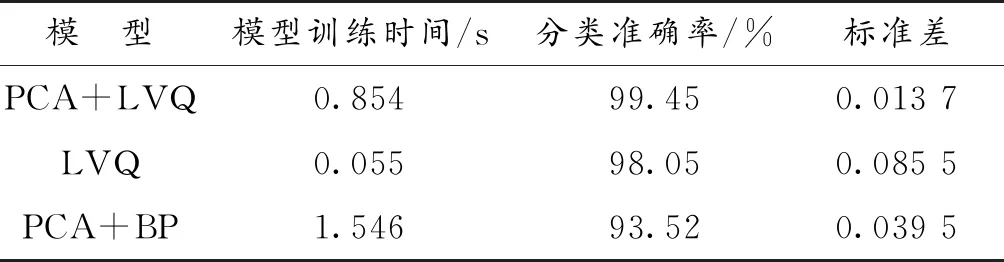
表2 LVQ与BP分类模型的性能比较Table 2 Performance comparison of LVQ and BP classification models
3种分类模型的平均分类准确率效果都比较好,都在93%以上,即表明3种分类的模型对蜂蜜的样本都有较好的分类学习能力。在多次实验中,LVQ的平均训练时间最短,且远低于其他两种分类模型,平均一次训练时间只有0.055 s,PCA+BP分类模型的平均训练时间最长,一次训练时间要达1.546 s;由图6(b)可知,LVQ的分类准确率的稳定性较差,LVQ的最高准确率达98%,最低的准确率只有78%,PCA+LVQ的训练时间虽然只有0.8 s左右,但是由图6可以看出PCA+LVQ分类模型较LVQ分类模型的分类准确率的稳定性更好。由表3可知,PCA+LVQ的平均分类准确率最高,已经达到99.45%,高于其他两种的分类模型,PCA+BP分类模型的平均准确率最低。表中PCA+LVQ、PCA+BP、LVQ的标准差分别为0.013 7、0.039 5、0.085 5。综上所述,虽然LVQ的平均训练时间最短,但是PCA+LVQ的平均准确率比LVQ高,分类性能的稳定性比LVQ好,从而说明PCA+LVQ分类模型具有很好的泛化能力。
由图6和表2可知,PCA+BP分类模型稳定性比PCA+LVQ分类模型的稳定性要差,其平均分类准确率也比PCA+LVQ分类模型要低,并且其平均训练时间要远远大于PCA+LVQ分类模型,故PCA+BP分类模型无法满足蜂蜜分类的快速性与稳定性的要求。LVQ分类模型的平均训练时间虽然可以很好地满足蜂蜜分类的快速性要求,但是它的稳定性比PCA+LVQ较差,无法满足蜂蜜分类的稳定性要求,故PCA+LVQ分类模型在最大程度上保证在蜂蜜识别的实时性要求下,可以更好地满足蜂蜜种类识别的准确率要求和泛化要求。
3种分类模型的分类准确率比较如图6所示,可以很清楚地看出PCA+LVQ的分类准确率极大部分聚集在100%这一点上,再次说明了PCA+LVQ分类模型分类的稳定性好,平均准确率高,更好地满足了蜂蜜识别的稳定性要求。
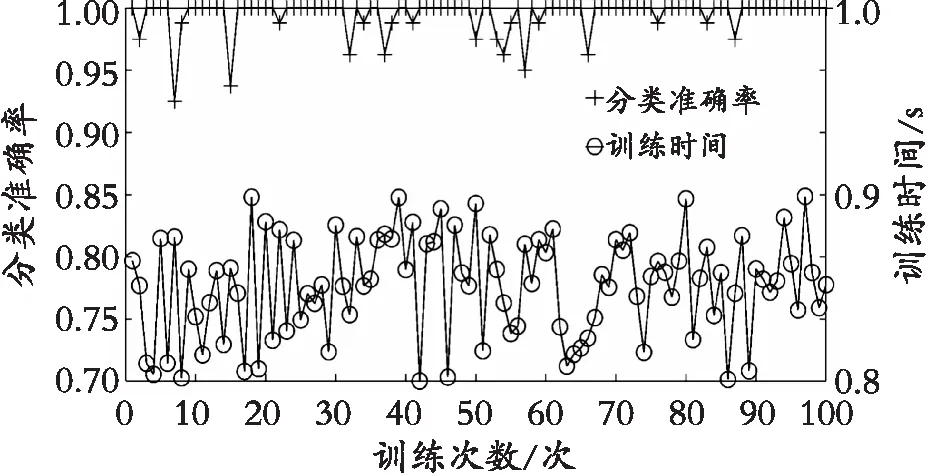
(a) PCA+LVQ模型
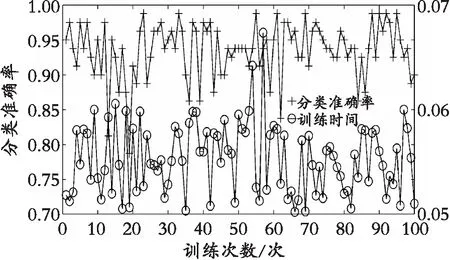
(b) LVQ模型
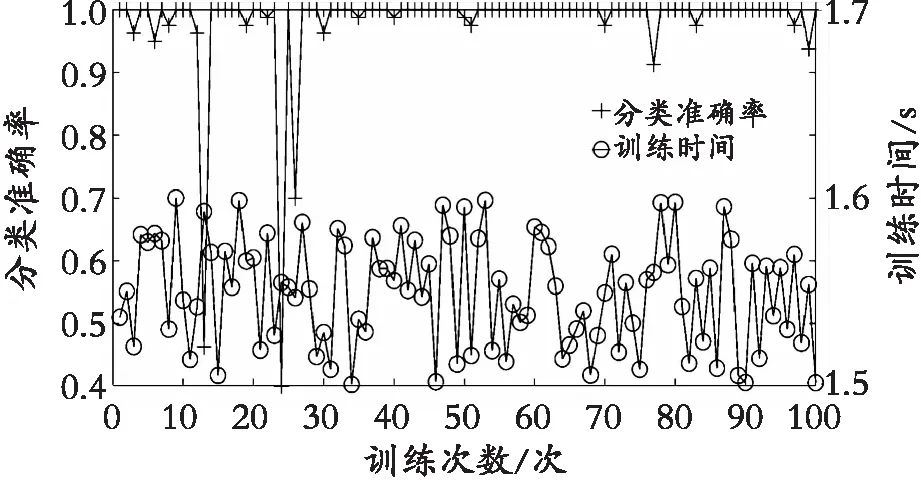
(c) PCA+BP模型
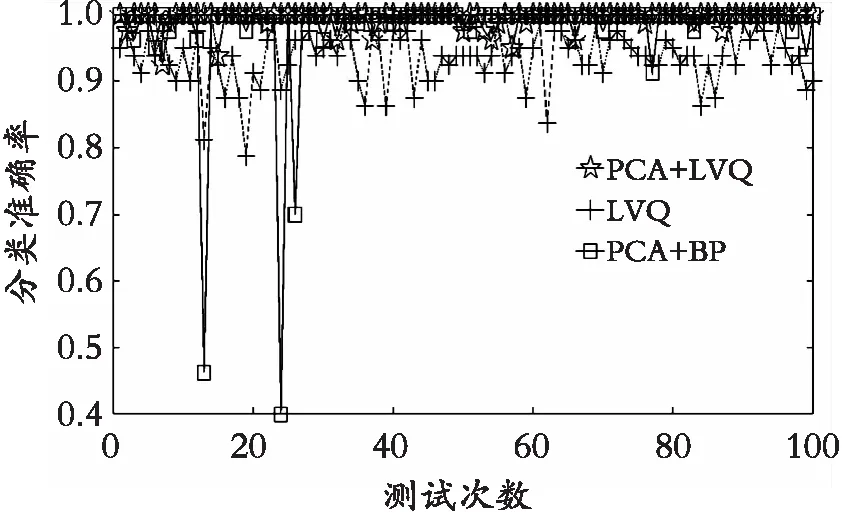
(d) 分类准确率对比图
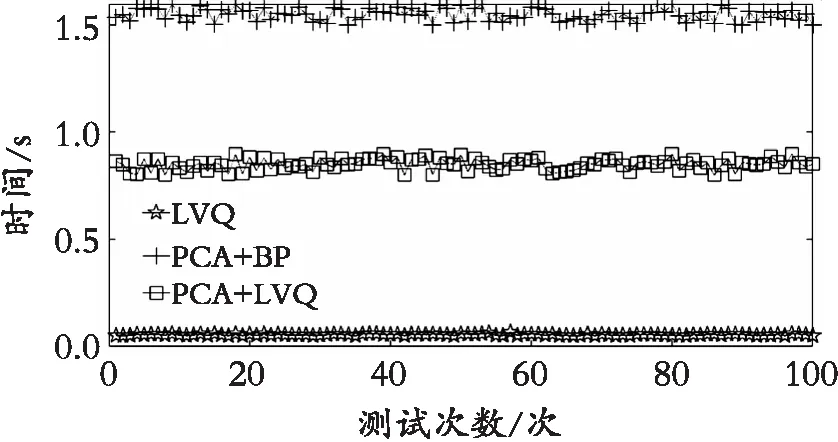
(e) 训练时间对比图
4 结束语
针对蜂蜜检测技术存在的无法快速、准确识别的问题,利用PCA与LVQ有机结合的方法和LIF技术相结合,提出快速、准确识别蜂蜜的方法。其中利用LIF技术对蜂蜜的样本进行处理,获取蜂蜜的荧光光谱图,而PCA与LVQ有机地结合对获取的蜂蜜光谱图进行识别分类。结合以上两种技术可以对蜂蜜进行识别分类;首先使用LIF技术对蜂蜜样本进行处理获取蜂蜜光谱图,再利用PCA+LVQ的分类特性对蜂蜜光谱图进行分类,从而达到蜂蜜快速准确识别的要求。另外,还可以推广到煤矿的突水的研究,可以更好地帮助人们防治煤矿突水;还可以推广到假酒的治理中,帮助人们喝到“放心酒”。综上所述,不但可以应用于蜂蜜的检测,还可以应用于其他多种场合,具有一定的普遍性和社会价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
学生天地(2019年28期)2019-08-25
中国生殖健康(2019年2期)2019-08-23
意林·全彩Color(2018年11期)2018-12-03
中国交通信息化(2018年5期)2018-08-21
小猕猴学习画刊(2018年4期)2018-04-28
中国光学(2015年5期)2015-12-09
