
机器学习方法对新型冠状病毒肺炎的诊断价值
2021-05-26 02:53:08刘巧曾燕王浩林刘博赵文龙王毅
中国医学影像学杂志 2021年4期
刘巧,曾燕,王浩林,刘博,赵文龙,王毅
1.重庆医科大学附属第三医院放射科,重庆 401120;2.重庆医科大学医学信息学院、医学数据研究院,重庆 400016;通讯作者 曾燕 300766@hospital.cqmu.edu.cn
新型冠状病毒肺炎(COVID-19)临床表现为发热、咳嗽、气促等,其病程进展快、传染性极强,且尚无特效药治疗,部分患者可进展为急性呼吸窘迫综合征[1-2]。早发现、早诊断、早隔离、早治疗是提高COVID-19患者治愈率及生存率的关键。随着人工智能(artificial intelligence,AI)技术的发展,通过挖掘医疗信息,构建疾病预测模型,辅助医师对疾病进行预测或诊断成为研究热点。本研究拟通过挖掘COVID-19 电子病历(electronic medical records,EMRs)中的临床表现、实验室检查数据、胸部CT 影像报告等信息,构建基于机器学习(machine learning,ML)的COVID-19 预测诊断模型,并评估各模型对COVID-19的诊断价值,旨在提供一种新方法,以实现早期、快速、准确地诊断COVID-19,进一步提高对COVID-19 的诊治水平。
1 资料与方法
1.1 研究对象 收集重庆医科大学数据研究院所汇聚的7 所附属医院2020年1—5月收集经反转录-聚合酶链反应(RT-PCR)检测新型冠状病毒核酸阳性COVID-19 患者的EMRs,共90例,其中男52例,女38例,年龄3~89 岁。按照1∶4 筛选出360例出院确诊为非COVID-19 患者的EMRs 作为对照组,其中男180例,女180例,年龄3~97 岁。排除标准:①EMRs 中未完整包含症状、体征等临床资料、实验室检查数据及胸部CT 检查报告者;②具有类似肺炎表现的其他疾病,如肺结核、肺肿瘤、肺栓塞。最终将所有纳入研究的EMRs 按7∶3 随机分为训练集315例和验证集135例。
1.2 指标提取 利用基于规则的方法对EMRs 中的临床信息(人口统计学信息、症状、体征等)、实验室检查数据及胸部CT 报告进行指标提取,将语义表达相同或相似的指标进行标准化处理,如“发热”和“发烧”统一名称为“发热”。
1.3 指标筛选及统计学处理 使用SPSS 26.0 软件及Python 3.7.6 进行数据分析及模型构建。符合正态分布的计量资料以±s表示,非正态分布者以M(Qr)表示,组间比较采用Mann-WhitneyU检验。排除缺失比例较高的指标,本研究数据集整体缺失率为14.6%,采用多重插补进行缺失值填补。计数资料比较采用χ2检验或Fisher 确切概率法。对单因素分析中差异显著的指标进行多因素Logistic 回归分析,筛选出与COVID-19 存在独立相关因素的指标作为构建ML 模型的敏感性指标。以P<0.05 为差异有统计学 意义。
1.4 模型构建及评价 将上述筛选出的指标作为输入变量在训练集中构建7 个基于ML 的诊断模型:逻辑回归(Logistic regression,LR)、K 最近邻(k-nearest neighbor,KNN)、决策树(decision tree,DT)、多层感知机(multi-layered perceptron,MLP)、随机森林(random forest,RF)、支持向量机(support vector machine,SVM)及可解释增强机(explainable boosting machine,EBM)。在验证集中采用精确率、召回率、F1 值、受试者工作特征(ROC)曲线及曲线下面积(AUC)对各模型诊断性能进行评价,从整个数据集中随机选取30%验证模型、重复1000 次计算出各AUC 值对应的95%置信区间。本研究使用AUC 及F1值作为模型对比的最终指标。
2 结果
2.1 单因素分析结果 本研究从EMRs 中提取出临床指标28 个、实验室检查指标26 个和CT 影像指标15 个。单因素分析结果显示,临床指标中年龄、吸烟、脉搏、收缩压、舒张压、发热、腹泻、咳嗽、咳嗽干咳、咳嗽无干咳、流涕、气促、头痛头昏、畏寒、胸痛,实验室检查指标中白细胞计数、血红蛋白、血小板计数、中性粒细胞计数、淋巴细胞计数、凝血酶时间、活化部分凝血活酶时间、纤维蛋白原、丙氨酸氨基转移酶、乳酸脱氢酶、天门冬氨酸氨基转移酶、C反应蛋白、尿素、总胆红素、白蛋白、尿酸、总蛋白、碱性磷酸酶、肌酐、肌酸激酶、钾和血小板压积,CT指标中单发、单肺多发、双肺多发、磨玻璃影、实变、胸膜下、支气管血管束周围、右肺下叶、左肺下叶、网格影、空气支气管征和小叶间隔增厚在COVID-19组和非COVID-19 组差异有统计学意义(表1)。
2.2 多因素Logistic回归分析结果 排除缺失值较高的指标,将单因素分析中差异有统计学意义的指标进行多因素Logistic回归分析,结果显示咳嗽、胸痛、肌酐、C反应蛋白、白细胞计数、乳酸脱氢酶、肌酸激酶、磨玻璃影和实变9个指标差异有统计学意义(表2)。
2.3 COVID-19预测模型建立 将多因素Logistic回归分析中筛选出的9个指标作为输入变量构建基于ML的COVID-19诊断模型,并在验证集中对模型诊断性能进行评价,结果显示F1值最高为EBM(0.857),其他依次为MLP(0.852)、RF(0.842)、LR(0.815)、SVM(0.775)、DT(0.755)和KNN(0.745)(表3)。

表1 COVID-19 组与非COVID-19 组临床特征单因素分析结果

续表1

表2 鉴别COVID-19 与非COVID-19 的多因素Logistic回归分析结果
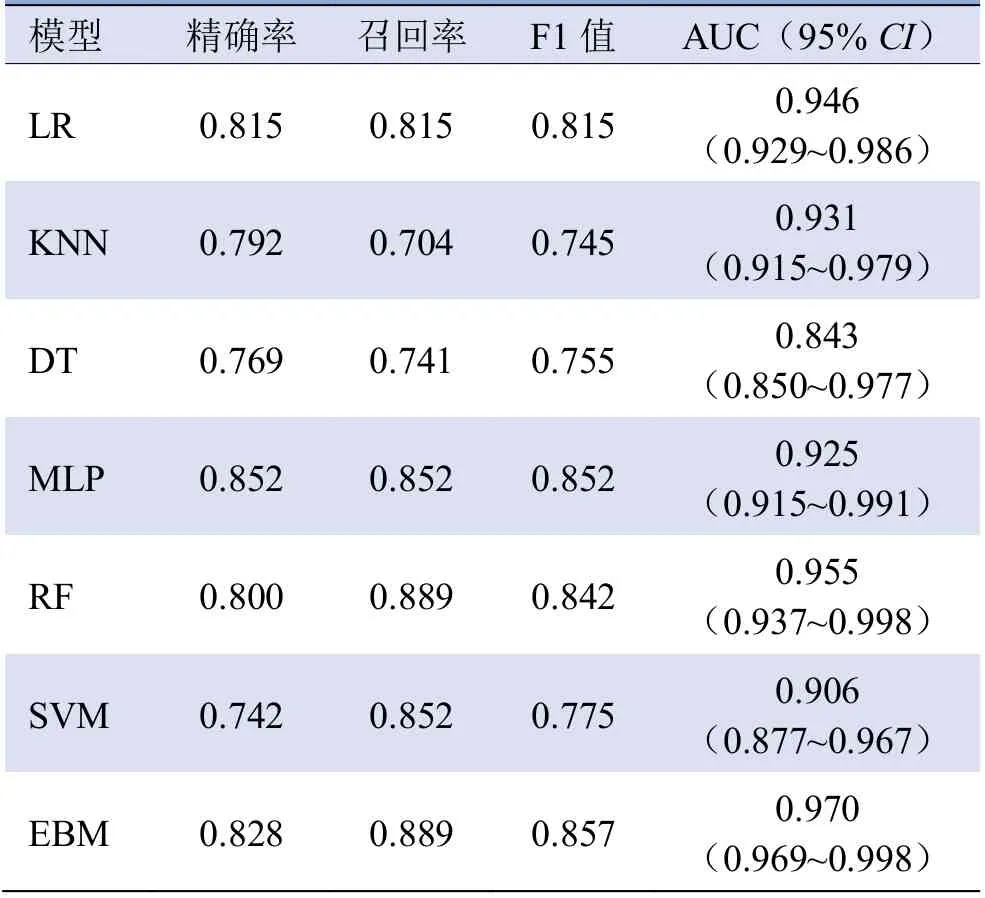
表3 7 种ML 模型的诊断效能
2.4 诊断模型的ROC曲线分析结果 对7种ML诊断模型的ROC曲线及AUC进行比较,结果显示EBM的AUC最大(0.970),其他依次为RF(0.955)、LR(0.946)、KNN(0.931)、MLP(0.925)、SVM(0.906)和DT(0.843)(图1)。综合分析各项指标显示,EBM模型的鉴别诊断效能最佳。EBM模型各指标权重值分别为磨玻璃影2.040、肌酸激酶1.872、C反应蛋白1.333、乳酸脱氢酶1.254、白细胞计数1.054、胸痛0.813、咳嗽0.601、肌酐0.554、实变0.376(图2A)。验证集中随机选取一例COVID-19病例输入EBM模型中,诊断其是否感染COVID-19,模型中各指标权重值分别为磨玻璃影3.651、乳酸脱氢酶3.386、肌酸激酶2.778、白细胞计数1.950、C反应蛋白1.265、胸痛0.485、实变0.260、咳嗽-0.345、肌酐-0.300(图2B)。

图1 7种ML模型的ROC曲线

图2 全局可解释性(A)和局部可解释性(B)
3 讨论
目前COVID-19疫情在国内已经得到良好的控制,并处于常态化防控形势下,但境外输入性病例频发,且全球感染人数仍然不断增加。病毒核酸检测是诊断COVID-19的“金标准”,但部分标本由于采集时间过早、采集方式不规范、采集部位不准确等问题,造成病毒核酸检测多次出现假阴性结果[3]。胸部CT检查在COVID-19诊断中发挥了重要作用,在病变早期的诊断敏感度较高,但特异度较低(25%)[4]。因此,开发一种新方法实现对COVID-19进行快速准确诊断具有重要临床意义。
AI技术具有出色的处理大数据、挖掘复杂医学信息的能力,COVID-19疫情暴发后,大量学者致力于应用AI技术实现COVID-19的快速诊断[5]。Wu等[6]通过ML算法挖掘11个关键血液指标构建COVID-19鉴别诊断模型,在交叉验证集、测试集及外部验证集中分别获得0.9795、0.9697及0.9595的准确率。Li等[7]基于CT图像开发深度学习模型以鉴别COVID-19与社区获得性肺炎,在独立验证集中检测COVID-19的AUC达0.96,检测社区获得性肺炎的AUC达0.95。Ozturk等[8]基于COVID-19的胸部X线片构建深度学习分类模型,结果表明该模型二分类及多分类准确率分别为0.9808和0.8702。以上研究AI模型均表现出良好的诊断性能,但均仅纳入单一指标进行评估分析、参与模型构建(实验室检查指标或胸部影像指标)。本研究结合临床表现、实验室检查、CT等指标综合分析,共同构建基于ML 的COVID-19 预测诊断模型,这更接近COVID-19的实际情况。本研究结果显示,7个模型中EBM的诊断效能最佳,其AUC为0.970,F1值为0.857,表明EBM具有较高的临床应用价值,能够协助医师对COVID-19患者进行快速、准确的诊断。
本研究共筛选出9个指标用于构建ML诊断模型,表明这9个指标与COVID-19的诊断密切相关。其中临床指标为咳嗽、胸痛,COVID-19的临床症状主要表现为发热、咳嗽、肌肉酸痛、胸痛及疲劳等,与本研究结果的一致性较好[9-11]。本研究中实验室检查指标为C反应蛋白、白细胞计数、肌酐、乳酸脱氢酶和肌酸激酶,其中C反应蛋白是一种急性时相反应蛋白,可激活补体,并增强吞噬细胞的吞噬作用[12]。新型冠状病毒通过呼吸道进入肺部,与血管紧张素转化酶-2(ACE2)受体结合侵入人体,引起炎症反应,诱发C反应蛋白等炎症因子释放,同时白细胞参与机体免疫,引起其数量降低。肺细胞可能是新型冠状病毒的主要靶细胞,但ACE2在肾小管细胞中也有较高水平表达[13],因此新型冠状病毒也可感染肾脏,引起肾功能衰竭,导致血液肌酐水平高于其他类型肺炎。此外,Chai等[14]研究表明,新型冠状病毒可能与ACE2阳性胆管细胞结合,引起胆管细胞功能障碍,结合其他原因造成肝脏损伤,影响肝功能,造成乳酸脱氢酶、肌酸激酶水平等异常。本研究中CT指标为磨玻璃影和实变,与目前多数研究一致[15-16],可能原因是病毒侵入肺部早期,引起肺泡腔内蛋白质和纤维素渗出,炎症细胞浸润,肺泡间隔毛细血管扩张充血,CT表现为磨玻璃影,随着病情进展加重,大量炎性物质继续渗出,渗出液跨越肺泡间隔融合成片状或斑片状,病灶密度逐渐增高,CT表现为实变影。
AI技术在医疗领域的应用为解决诸多医疗问题带来了新的机遇和希望,但由于AI模型的不可解释性,使得用户难以理解模型内部工作原理及决策过程,从而降低了医师对AI模型的信任度及接受度,限制了AI产品在医疗领域的发展。因此,构建可解释性AI模型成为近年研究的热点及关键。EBM模型可反映数据间的线性和非线性关系,不仅可表现出精准的预测性能,同时还具有可解释性[17]。EBM模型的可解释性表现为全局可解释性和局部可解释性。全局可解释性表现为EBM模型可以可视化各指标变量在模型中所占权重,以此可以评估各指标在EBM模型中的价值,指标权重值越高,说明该指标的重要性越大,本研究EBM模型构建中磨玻璃影是最重要的指标,权重值为2.04。局部可解释性体现在EBM模型可对具体某一病例诊断的结果做出解释,可以表明哪些指标支持对该疾病的诊断,哪些指标否定对该疾病的诊断,给出诊断依据,有助于对每位患者做个体化预测,进而提供精准化治疗。从验证集中随机选取一例COVID-19病例输入EBM模型中,诊断其是否感染COVID-19,并对其结果进行可视化,结果显示尽管咳嗽及肌酐2个指标否定模型对该患者做出COVID-19的诊断,但其余所有指标均支持对COVID-19的诊断,且整体更加倾向于对患者做出COVID-19阳性诊断,结果与事实相符。
本研究的局限性为:①本研究收集的COVID-19患者样本量较少,可能使得结果不够精确,也限制了构建基于深度学习模型的研究;②样本不够规范化,导致部分指标因缺失值过多而被排除,这可能使得研究结果存在误差。在未来研究中,需要进一步加大样本量并选择更为规范化的样本集证实本研究结果。
总之,通过挖掘EMRs信息,构建可解释性ML模型,可以实现对COVID-19进行快速、准确的诊断,帮助提高患者的治愈率和生存率。
猜你喜欢
冰雪运动(2021年1期)2021-07-28 07:12:46
法律方法(2021年4期)2021-03-16 05:35:16
安徽医专学报(2020年3期)2020-12-25 19:41:17
甘肃科技(2020年20期)2020-04-13 00:30:56
文教资料(2018年30期)2018-01-15 10:25:06
中国科技博览(2018年3期)2018-01-12 11:32:58
传播力研究(2017年5期)2017-03-28 09:08:30
中国宪法年刊(2016年0期)2016-05-20 09:17:00
中国当代医药(2015年21期)2015-03-01 02:04:50
当代体育科技(2015年8期)2015-02-27 06:23:42
