
面向语句分值的C程序静态评分方法
2021-05-20 06:50舒新峰贾敬霞何孝敏付稳稳
计算机工程与设计 2021年5期
舒新峰,贾敬霞,何孝敏,付稳稳
(西安邮电大学 计算机学院,陕西 西安 710121)
0 引 言
随着互联网技术在“C程序设计”教学过程中的应用,一些高校引入C程序在线考试系统实现自动阅卷[1-3],而现有的考试系统主要采用动态评测和静态分析两类技术。动态评测通过编译运行待判定程序并输入测试用例集,根据程序输出结果与预期结果是否一致来评分[4-6]。当程序存在语法错误而无法运行时,此类系统会给予0分成绩,评分结果较为粗糙,不符合实际教学需求。
静态分析方法通过分析待判定程序的结构及语义特征获取评分结果,主要分为两种。一种通过统计程序代码行数、函数、循环结构等程序属性特征的数量给出评分[7],但因没有考虑程序语义而导致评分结果比较粗糙。另一种将学生程序和答案程序转化为中间形式,如控制流图[8,9]、抽象语法树[10,11]、系统依赖图[12,13]等,然后比较两者的相似度进行评分,但现有的中间表示形式不能准确表达程序结构及语句依赖关系,降低了评分的准确性。
针对上述问题,本文提出面向语句分值的C程序静态评分方法,通过在答案程序中标注描述评分细则的语句分值,引入能够准确描述语句控制、数据依赖关系的程序语句依赖图作为中间表示结构。评分过程如图1所示,首先对待判定C程序进行标准化,消除表达多样性问题,具体策略见参考文献[10];其次构造带有语句分值的程序语句依赖图;最后匹配待判定程序和答案程序间路径片段集合实现程序评分。

图1 静态评分过程
1 答案程序中语句分值的设置
为支持命题教师准确描述评分细则,根据知识点、语句的重要性对答案程序中的语句片段设置不同分值,即对答案程序中的单行、多行语句设定不同注释方式来描述考察的知识点及分值权重。当一个分值表示多行语句时,在这些语句的第一条源码后面标注/*ktype_symbol- -score*/表示分值的开始,最后一条语句标注/*ktype_symbol*/表示该分值所表示语句范围结束;而分值表示一条语句时,则在这条语句后标注/*- -score*/表示;此外用/*sum- -score*/表示整个答案程序的分值。其中ktype_symbol表示知识点符号,具体取值见表1,score为分值。例如,“求π值问题”答案程序中语句分值的标注情况如图2所示。

图2 “求π值问题”的答案程序
2 程序语句依赖图
针对现有的评分方法不能精确表示程序语句间执行次序及依赖关系、选择/循环的语法结构,对系统依赖图[12,13]进行改进,引入了程序语句依赖图(program statement dependency graph,PSDG)来描述待判定程序的语法结构。
2.1 程序语句依赖图定义
PSDG基本策略是将C程序递归描述为复合语句的集合,每个复合语句由复合语句名称和复合语句体构成,复合语句体为语句及其数据/控制依赖关系构成的有向图,图3为PSDG的结构。第一层为函数复合语句,复合语句名称(圆形顶点)为函数名,复合语句体为函数体语句(方形顶点)构成的有向图,图中的弧

图3 程序语句依赖
根据上述策略,PSDG的形式化定义如图4所示。PSDG 定义为复合语句集合ComStmtSet;每个复合语句ComStmt为一个有向图,其中nameNode为复合语句名称顶点,varRefSet、nodeSet、arcSet分别表示复合语句中的变量集、顶点集和弧集。nameNode中的name为复合语句名称。顶点Node中的NodeType标识语句类型,取值type_Var、type_Expr、type_If、type_Loop、type_InOut、type_Return分别表示变量声明、赋值、分支、循环、输入/输出、返回;expTree为语法子树表示的语句内容;若Node为if/while语句时,Yes/No分支对应的复合语句存储在subComStmtSet。变量VarRef的dataType和varName分别表示变量类型和名称,而refNode表示最近一次引用变量的语句顶点。

图4 PSDG的形式化定义
为了描述程序中包含的语句分值,给PSDG每个顶点设置flag、weight、gather、fchange属性。其中flag表示语句分值所指的范围,取值为1表示该顶点所代表的语句为分值的起始位置,为0表示语句为分值结束位置,其余顶点的flag值为2;weight表示分值的大小,在flag=1的顶点位置时weight值为score,否则为0;用gather表示分值所属范围,同属于一个分值的顶点gather值相同;特别地,当一个分值所包含的语句范围内另嵌套分值时,则用属性fchange记录分值间的嵌套关系。另外给每个为main的复合语句名称顶点设置“sum”属性用于记录程序的总分。nameNode、Node中的pathSet存放下节评分过程中与该顶点相关的路径片段集合。
2.2 程序语句依赖图构造算法
根据PSDG的递归定义,PSDG的构造算法CreatePSDG如图5所示。算法以C程序源代码Source_Code作为入口参数,首先初始化图G,递归遍历Source_Code的每一个函数源代码建立复合语句的有向图,函数名为复合语句名称顶点nameNode,函数体使用算法CreatComStmt构造为复合语句体子图并将子图添加到G中,算法结束后返回Source_Code的PSDG。

图5 程序语句依赖图构造算法
构造复合语句体子图的算法CreatComStmt以复合语句体ComStmt_Code以及复合语句体子图ComStmt作为入口参数,递归遍历ComStmt_Code的每一条语句,根据语句类型及语句间的数据/控制依赖关系建立ComStmt。其构造过程如下所示:
(1)如果语句为变量声明类型时,新建一个图顶点node,将语句类型、内容存入node,使用AddNode函数将语句顶点添加到复合语句体子图中,使用AddArc建立nameNode和语句间的弧连接,新建一个varRef,获取该语句中的变量类型及名称存入varRef中,并将node存入varRef的reFnode中作为最近一次使用node中所包含变量的顶点。最后将varRef加入到变量集varRefSet中。
(2)如果语句为变量赋值类型时,将语句存入新建的一个图顶点node中,并将该顶点添加到ComStmt中。使用GetVarSet获取语句中的变量集合varSet;遍历varSet获取每一个变量名varName,使用GetRefNode函数获取varRefSet中最近一次使用varName的顶点,即refNode中的存放顶点,建立该顶点与node的弧连接。获取node中被赋值的变量,并用node替换最近一次使用被赋值的变量的顶点即使用UpdateRefNode,将node存入varRefSet的reFnode中,实现varRefSet的更新。
(3)特别地,if/while结构需作为一个整体处理。将if条件表达式作为一个语句顶点node;递归建立if结构中Yes分支、No分支复合语句的子图存入subComStmtSet。获得子图中使用的变量集合,在varRefSet中获取最近一次使用变量集合的顶点,添加这些顶点与node的连接;获取子图中被更改的变量集合,用node替换最近一次使用这些变量的顶点,完后varSet更新。while结构采用同样的方法处理。
(4)如果语句为输入/输出类型时,将语句存放在新建的图顶点node中,获取该语句中的变量,添加node与最近使用该变量的顶点间弧连接,并用node替换该变量的reFnode存放的结点。
(5)如果语句为返回类型,将语句存入新建的node中,获取varRefSet的refond中所有顶点集合staNodeSet;建立node与staNodeSet中顶点的弧连接,然后用node替换staNodeSet中的顶点完后varRefSet更新。
2.3 语句分值在PSDG中表示
在获得源程序Source_Code的程序语句依赖图G后,递归遍历Source_Code的每一个函数及函数中的每条语句code,在获取语句分值s后,根据语句及G中顶点间的对应关系,将语句分值标注在表示code的顶点属性中。此外在每个函数内部,一个语句分值会对应一个集合gather,不在任一语句分值区域的code归为一个gather(需更改首尾句flag值),这时一个函数划分为若干个集合,多个函数形成多个集合。具体步骤如下所示:
(1)如果程序中包含s,即“/*sum- -score*/”,则将name为main顶点的属性sum设置为score。
(2)如果s为“/*ktype_symbol- -score*/”,需将语句所对应顶点node的flag置1,weight的值为score,gather为当前所属集合,fchange为当前所嵌套gather的集合。
(3)如果s为“/*ktype_symbol*/”,此时node为所属分值的最后一行,故flag、weight为0,而gather、fchange保持不变。
(4)如果顶点node属于语句分值范围内,node的flag为2、weight为0,而gather、fchange保持不变。若s为“/*- -score*/”采用同样的方法处理,但node的weight值需变为s中的score。
(5)特别地,一些语句并不在“/*ktype_ symbol--score*/”和“/*ktype_symbol*/”范围内,需变更gather、fchange的值,并将这些语句的gather、fchange保持一致,并设置这些语句顶点的flag值,令weight为0。
图6给出图2所描述题目的PSDG表示,而部分带有分值的语句在PSDG中的表示见表2。

表2 语句分值在PSDG每个顶点中的表示
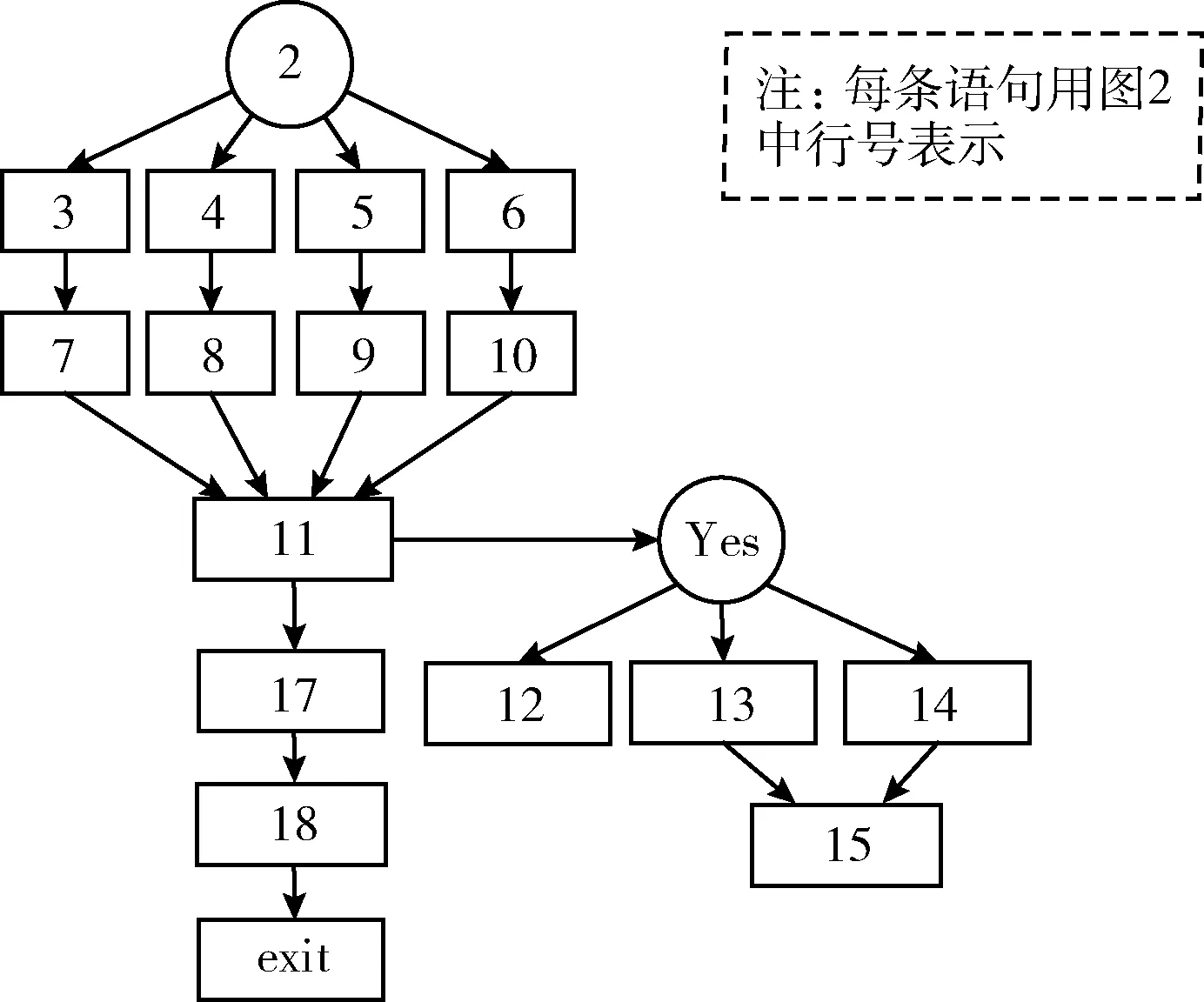
图6 “求π的值”程序语句依赖
3 程序评分
在获得标有语句分值的PSDG后,首先标准化程序语句依赖图的标识符命名;其次依据语句分值的位置、程序中语句依赖关系将PSDG划分为由路径片段构成的集合;最后遍历每个集合,依据待判定、答案程序间同集合路径相匹配原则,计算待判定程序路径片段的相似度,完成待判定程序评分。
3.1 划分答案程序
3.1.1 答案程序路径片段集合划分
在获得答案程序的PSDG后,依据PSDG中每个顶点的gather值及顶点间的偏序依赖关系划分路径片段集合,算法如图7所示。具体说明如下:

图7 划分答案程序路径片段集合算法
从起始顶点出发,遍历PSDG的每个顶点,寻找其直接后继顶点。若两个顶点的gather值相同,则寻找直接后继顶点的后继顶点,直至直接后继顶点gather值为另一个集合值(gather值不相等),此时获得从起始顶点出发的一条路径片段;然后从起始顶点出发遍历其余直接后继顶点,获取其余后继顶点所在的路径片段;这些路径片段存储在一个集合中。然后从未访问顶点出发按照上述思路寻找其余集合,这样PSDG就会被划分为由路径片段构成的集合。
3.1.2 计算答案程序中集合分值
答案程序中存在一个语句分值Wi包含另一个语句分值Wj的情况(被包含的分值Wj属于Wi的一部分),而在集合划分时Wi并没有包含Wj中的语句,因此需更改Wi的分值。即依据分值注释间的嵌套关系,从最外层出发,用嵌套集合的分值减去所有直接被嵌套集合的分值,即父集合Wi的分值weight为其减去所有子集合Wj的分值后剩余的分值。其算法如图8所示。

图8 计算答案程序集合分值算法
在完成上步计算后,有些集合因教师未设置语句分值导致该类集合没有分值,其计算方法如式(1)所示,其中题目总分为sum、已知分值的集合分值为score(共m个)、未给分值的集合数量Mnum、未给分值的集合分值为Nscore
(1)
3.2 待判定程序路径片段集合划分
由于答案程序中语句分值间存在嵌套关系,故需从答案程序被嵌套的路径集合出发,依据待判定、答案程序的顶点间相似度标注待判定程序PSDG中每个顶点所属集合值,直至每个顶点被访问过一遍,然后按照上述方法从答案程序的嵌套集合出发标注剩余顶点的gather值,算法如图9所示,其中Zhangshasha为顶点间相似度计算函数,具体算法见文献[14]。

图9 划分待判定程序路径片段集合
首先将待判定程序每个顶点与答案程序路径集合中每个路径片段的起始顶点对比,若两个顶点相似度为1,则两个顶点属性gather值相同,此时该顶点为待判定程序PSDG某一集合内路径起始顶点;遍历该顶点的直接后继顶点,对比直接后继顶点与上述答案程序相应路径片段中的结束顶点(无后继顶点)直至相似度为1,此时获取的顶点为待判定程序路径的结束顶点,此时一条路径片段形成(过程中设置两个顶点属性gather值相同),否则继续对比该后继顶点的直接后继顶点直至该顶点为PSDG结束顶点(即无后继顶点的顶点),也没有找到相似度为1的顶点,则该条路径放弃。
此时继续对比顶点的其余直接后继顶点划分路径片段,形成集合中的其余路径片段,直至每个顶点都被访问过,此时待判定程序的第一个路径片段集合寻找完毕;然后从未被访问的顶点出发按照上述思路寻找其余路径片段集合。上述步骤形成的所有集合为待判定程序PSDG的路径片段集合。
3.3 总成绩
(1)路径相似度及顶点分值计算:一条路径上所有顶点的相似度之和与该条路径上顶点数量的比值为路径的相似度。特别地,若待判定程序的一个顶点i与答案程序的顶点j匹配时,顶点间相似度为Psimilar,且j有分值score,此时需用式(2)计算i的分值Pscore,否则不单独计算顶点分值
Pscore=Psimilar*score
(2)
(2)匹配路径/集合:答案程序S与待判定程序路径片段集合T对比时,采用同集合(集合名相同)路径相匹配的策略选择待匹配的路径,而集合中路径匹配时则采用KM算法[15]找到每条路径的匹配路径。
集合M的一条路径Mi与T中路径相匹配时,先找到使Mi有相似度最大的路径Tj(相似度为maxij),然后对比M中每条路径与Tj的路径匹配结果,若存在使Tj相似度最大的路径Mk则比较maxij和maxkj的大小,若maxij≥maxkj则将Tj作为Mi的匹配路径,否则Tj不作为Mi的匹配路径并继续寻找使Mi有相似度次N大的路径Tn直至满足maxin≥maxnn,此时将Tn作为Mi的匹配路径。按照上述算法递归寻找M和T中路径的匹配对直至M或T中的每条路径都找到匹配路径,同时匹配对的顶点相似度作为待判定答案的顶点相似度。
(3)待判定集合分值计算:在获取待判定程序每个集合内路径的匹配路径后,运用式(3)计算每个集合的分值Gscore,其中每个顶点的相似度为Psimilar、Num为一个集合内总的顶点数量、Tscore为答案程序中匹配集合的分值
(3)
若集合内一些顶点已获得分值,需通过式(4)计算该集合的分值:即已知顶点的分值和与未知顶点分数之和相加即为集合分值Gscore

(4)
其中,n代表已获得分值的顶点总数,m代表未获得分值的顶点总数、顶点的相似度为Psimilar、答案程序中集合和顶点的分值分别为Tscore和TPscore。
4 实 验
从2017届本校200位大一学生C语言课程的课后作业中,选取5道编程题作为检测本文方法的实验题目。编程题目1~5分别为“求π的值”、“猴子吃桃问题”、“求1!+2!+…100!”、“求圆环的面积”和“汉诺塔问题”,每题满分均为25分,其中题目1考察的知识点为函数、表达式、循环结构,题目2考察的知识点为函数、循环结构,题目3考察的知识点为函数、表达式、循环结构,题目4考察的知识点为函数、输入、输出结构,题目5考察的知识点为函数、选择结构。题目1的答案程序赋予表达式和循环结构知识点权重分别为8分和14分;题目2、题目3每个语句平分题目分值;题目4赋予函数、输入/输出知识点权重分别为15分、5分;题目5赋予函数、选择结构知识点权重分别为10分、13分。
从200位学生中随机抽取50名学生提交的程序作为实验对象,通过搜集运用动态评分、统计属性特征的结构规模评分、使用LCS算法[16]获得语句相似度的程序静态评分、采用本文策略的自动评分、人工评分5种方式对5道实验题目评分点及评分的结果进行对比,验证本文方法的有效性。
首先以“求π的值”(图2)为例,结合人工评分方式、结构评分策略,使用式(5)计算50个学生采用结构规模、LCS、自动评分方式,找到知识点、语句被准确评分的误差率。该题考察知识点为1个函数、4个表达式、1个while结构,并设置4个标有语句分值的区域。其中SeR表示误差率、Psum表示人工评分时统计的数量、Ssum代表某种评分方式统计结果。由于动态评分是通过程序的运行结果评分,所以这里不对其进行误差率计算。误差率计算结果见表3

表3 知识点及语句被准确评分的误差率计算结果/%
SeR=(|Psum-Ssum|)/Psum*100%
(5)
由表3可知,基于LCS的静态评分采用LCS算法,匹配语句间相似度来判断知识点正确性,因此会产生较高误差率;结构规模评分则是考虑整个程序中包含的知识点数量与题目考查知识点的差距,该方法会计算注释区域之外的知识点数量,且其并不考虑语句的内容,因此存在误差;而自动评分是在语句分值范围内获取知识点,通过匹配路径片段相似度获取评分,所以其总体误差率要优于其它两种评分方式。
其次,采用式(6)计算4种评分结果与人工评分之间的误差率,结果见表4。其中ER表示评分的误差率、Pscore表示人工评分结果、Sscore代表某种评分方式获得的结果
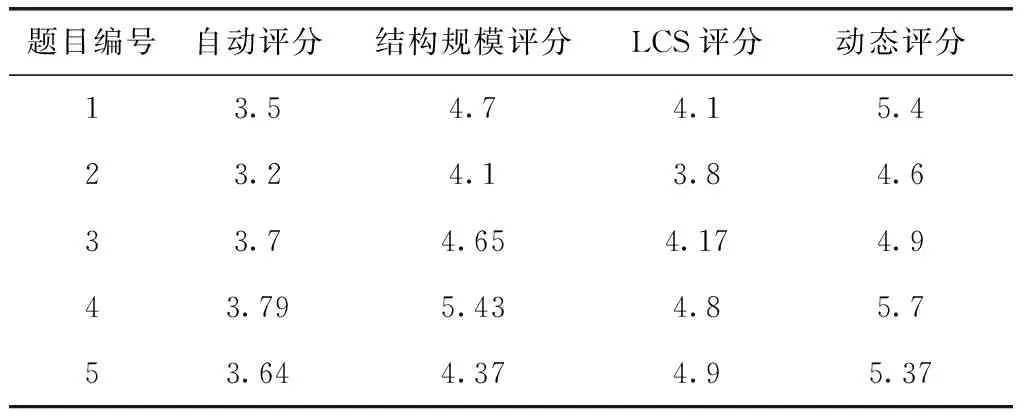
表4 各种方式的评分结果对比/%
ER=(|Pscore-Score|)/Pscore*100%
(6)
由表4可知:LCS评分和自动评分误差率接近,但该方法评分时采用LCS算法计算语句相似度,且没有按照教师标注的语句分值进行评分,故其整体误差率高于自动评分;而结构规模评分由于没有考虑待判定程序的语句内容是否符合答案程序,使得误差率高于自动评分;动态评分因其在待判定程序编写错误,导致不能运行时会给予0分,故其误差率高于自动评分。另外,在题目编号为2、3,设置语句平分答案程序分值时,自动评分和其余3种评分误差率存在较小差距;题目编号为1、4、5,设置语句不同分值权重时,自动评分和其余3种评分误差率存在的差距总体变大,故本文依据答案程序中设置的语句分值及PSDG实现的评分方法相比于其它方法明显提升了评分准确度,更接近人工评分结果。
另外,通过实验结果可以看到本文方法的评测结果和人工评测之间还存在一些差异。为寻找原因,对学生提交的程序进行了进一步检查分析,发现凡是人工评判正确解答得满分的程序,本文方法也为满分;而对于存在一些错误的程序,本文方法评测结果和人工方法部分结果存在1-2分内的差异。究其原因,主要是当人工评测存在主观性因素,当评分规则粒度较粗时评分尺度不是完全一致,另外对于多处类似细微错误按同一个错误扣分,而本文算法则是按照评分规则固定计算。
5 结束语
针对现有C程序静态评分方法存在的缺陷,本文提出一种面向语句分值的C程序静态评分方法,通过运用程序语句依赖图描述源程序及程序中教师标注的语句分值,根据语句间的依赖关系和语句分值将答案及待判定程序划分为路径片段集合,对比两者集合相似度完成待判定程序评分,评测结果接近人工评分,能更好满足实际教学需要。但本文方法会受到答案程序的影响,当学生采用答案程序中不包含的正确解题思路时,不能够正确识别和评分;另外,人工评分时对于程序中的多处类似错误一般仅扣除一次分值,而本文方法按实际出现次数进行扣分。这些问题需要在未来的研究中进行解决。
猜你喜欢
中等数学(2021年9期)2021-11-22
新世纪智能(语文备考)(2020年4期)2020-07-25
健康大视野(2020年1期)2020-03-02
科技创新与应用(2019年26期)2019-10-24
山东科学(2018年6期)2018-12-20
电脑知识与技术(2017年2期)2017-04-25
中小企业管理与科技·中旬刊(2016年6期)2016-06-20
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
中学生数理化·高一版(2009年6期)2009-08-31
