
基于条件生成对抗网络的水下图像增强算法*
2021-05-20 07:17杨国亮赖振东
传感器与微系统 2021年5期
杨国亮, 王 杨, 赖振东
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引 言
随着陆地资源的大量消耗,对海洋资源的探索就显得尤为重要。但是光在水中传播时受到水介质的影响,往往拍摄到的水下图像存在着模糊不清,颜色失真等问题,对后续的目标识别及分割造成不利的影响。近年来,各种水下图像修复与增强的方法层出不穷,图像修复方面如Chiang J Y等人[1]提出的通过暗通道先验的方法进行水下图像增强模型。Wen H等人[2]通过分析光的衰减特性,从图像蓝绿通道中的信息求取暗原色通道,同时对红色通道的折射率进行估计,实现水下图像的修复。李黎等人[3]通过改进的暗原色先验算法消除散射光以及白平衡算法对颜色进行校正,在水下图像修复方面取得不错效果。图像增强方面有Singh K等人[4]提出的基于基于递归直方图均衡化的水下图像增强方法,随着深度学习的飞速发展,在图像的识别[5]、分割[6]以及超分辨重建[7]等方面取得巨大的进展,徐岩等人[8]提出了基于卷积神经网络(convolutional neural networks,CNN)的水下图像增强方法,通过颜色失真与图像模糊化方法建立水下图像库.成功将CNN应用于水下图像增强。
本文提出了一种基于条件生成对抗网络(conditional generation adversarial networks,CGAN)的水下图像增强算法,通过改进生成器与判别器模型,利用CGAN模型,将完全配对的输入与输出图像作为输入,生成器模型采用U-net[9]网络架构同时在原始生成对抗网络(generative adversarial networks,GAN)[10]损失函数中引入了L1loss进行修正。结果表明,训练出的模型对水下图像有明显的增强效果。
1 相关理论
GAN最早是在2014年由Goodfellow I提出。GAN可看作是一个从随机噪声Z到输出图像的映射的模型,生成器模型G,通过输入一个随机的噪声Z产生一些生成数据并将其传递给判别器,判别器D的工作是同时接收生成器所产生的数据以及真实的数据,并判断其接收的数据是来自真实数据或是来自生成器伪造的样本,并将结果反馈回生成器。GAN的目标函数就是生成器G与判别器D的极小极大值博弈,其目标函数V(D,G)为式(1)所示
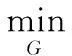
Ex~pz(z)[log(1-D(G(z)))]
(1)
式中Pdata(x)为真实数据分布,Pz(z)为生成的数据分布。
2 基于CGAN的水下图像增强
2.1 CGAN
CGAN在GAN的基础上在生成网络与判别网络中加入额外的标签信息条件,使用额外条件信息对模型增加条件,可以指导数据的生成过程。实验中将水下图像作为条件信息与随机噪声Z同时输入到生成器中,模型通过学习输入的原始水下图像和随机噪声Z到清晰图像之间的映射关系,达到水下图像增强的效果。CGAN的目标函数V(D,G)如式(2)所示
Ex~pz(z)[log(1-D(x,G(x,z)))]
(2)
式中 函数D(x,y)为输入到判别器D的图像属于真实图像的概率,函数D(x,G(x,z))为输入到判别器D的图像属于生成器G生成的概率。
2.2 生成器
本文主要采用的是CGAN 的网络结构,为了尽量地保存图片的原始信息,生成器G采用的是U-Net网络而不是传统的CNN,其结构与编码解码器相似,不过与传统的编码解码器不同的是U-Net网络采用了跳跃链接技巧,结构如图1所示。U-Net网络将低层与高层特征图信息相结合,能够有效地保留更多图像细节信息。
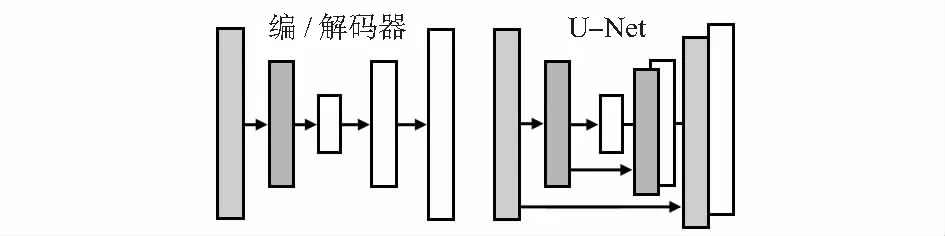
图1 U-Net与编/解码器结构
其中模型生成器G总共包含15层,其中前8层为卷积层,后7层反卷积层。生成器G的前半部分可以看作一个编码器,对输入的原始水下图像进行卷积下采样操作,进行特征提取,对提取到的特征使用批归一化(BN)处理同时使用LeakyReLU函数作激活函数。而生成器G的后半部分相当于对应的解码器,采用反卷积网络,对输入的低维特征进行上采样操作,将低维特征还原到最初的尺寸,得到清晰的水下图像,以达到端到端的学习。为防止过拟合现象的出现,对每层反卷积的特征采用BN与Droupout操作,采用Relu函数对网络进行激活操作,最后与tanh函数连接。本文生成器G的网络模型如图2所示。
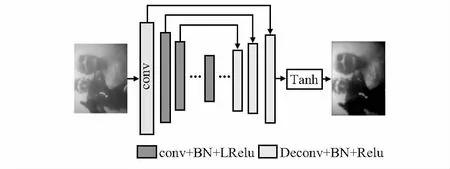
图2 生成器G网络结构
2.3 判别器
判决器D主要是对接收到的生成器G生成的图像与真实图像做出判断。实验中判别器D模型采用了一个5层的卷积网络,将生成的水下图像与清晰图像作为判别器D的输入,所有的卷积层都采用BN层与LeakyReLU激活层,在网络的最后一层采用Sigmod激活函数,将判别结果映射到[0,1]区间,输出为1,则代表清晰的水下图像,0则代表生成器G所生成的水下图像,判别器D的网络模型如图3所示。
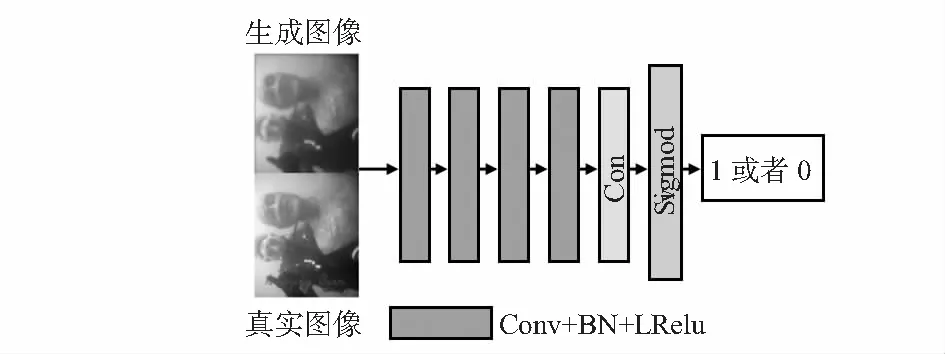
图3 判别器D网络结构
2.4 损失函数
实验模型除了引用标准的CGAN的损失函数外,由于输入和输出之间共享了很多信息,为了保证输入图像与输出图像的相似度,还加入了L1的损失函数。标准的CGAN网络的损失函数为
LCGAN(G,D)=
Ex,y[logD(x,y)+Ex,z[log(1-D(x,G(x,z))]
(3)
式中G为生成器,D为判别器,x为输入的水下图像,y为真实图像(清晰图像)。为了得到更多的低频信息,增加生成图像的清晰度,对G施加L1惩罚,即
LL1(G)=Ex,y,z[‖y-G(X,Z)‖]
(4)
同时为了平衡两个损失函数,加入超参数λ进行调节(λ设为100),这样标准CGAN损失能够捕捉到图像的高频特征,而L1损失则负责捕捉低频特征,使得生成的结果更加真实与清晰。最终本文所采用的的损失函数为
(5)
3 实验分析
3.1 数据增强
由于只能提供少量水下与清晰图像对,无法满足训练要求,本实验通过对无水图像进行模糊化以及颜色衰减处理,模拟同一情景下的水下图像,获得水下图像与相匹配的清晰图像对。同时为保证训练效果,本文通过数据增强的方式对样本进行增加。通过对图像旋转,水平垂直方向的翻转、平移变换等方法对训练数据进行增强。由于所获图像分辨率各有不同,所以将所有图像压缩至256像素×256像素,并进行归一化处理,同时将相对应的水下图像与清晰图像进行拼接。
3.2 实验设置
本次实验是基于Tensorflow深度学习框架下完成,计算机配置为inter Core i5—6300HQ处理器,NVIDIA GTX 1060显卡,8 GB RAM。在模型训练中,由于样本数据较少,将batchsize设置为1,对于训练大规模样本,可适当提高相应的batchsize值。模型epoch的值设为200,在GPU加速下,总耗时8 h完成本次模型训练。模型采用Adam算法进行网络优化,实验中Adam算法的学习率设为0.000 2。
3.3 实验结果
为了验证本文算法的实际应用效果,利用水下真实场景的图像对网络进行评测并与其他算法进行对比。如图4所示。从图中看出,文献[1]的方法能够有效地增加水下图像的对比度,但是色彩失真依旧严重。文献[2]的方法由于只考虑蓝绿通道的衰减信息,导致增强后的图像整体偏暗红色。文献[3]通过改进的暗原色先验与颜色校正后得到的图像在对比度与颜色失真方面明显优于前两种方法。最后是通过本文算法增强的图像,可以看出图像所包含的噪声较少,画面比较清晰,同时在颜色校正的效果也比较好。

图4 真实场景下不同方法的增强
为了更好地说明本算法对水下图像增强的有效性,本文采用图像质量评价标准信息熵(information entropy)与峰值信噪比(PSNR)对不同算法进行客观评测。信息熵是衡量图像所包含信息的一个重要指标,而峰值信噪比是对图像压缩等领域中信号重建质量的主要测量方法,两者的值越大则代表图像包含的信息越多,噪声越少,图像质量越高。评价结果如表1所示,结合主观视觉感受和表1数据可以看出本文所提算法对水下图像有着明显的增强效果。
4 结 论
针对水下图像存在的颜色失真以及由于水浊度不同所产生的图像模糊问题,本文结合深度学习,提出了一种基于
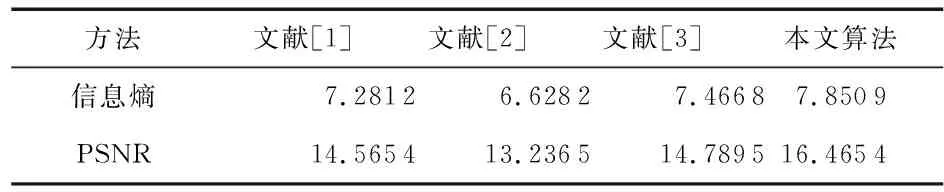
表1 不同方法的客观评价
CGAN的水下图像增强算法,采用U-Net网络结构,引入L1损失改进生成网络,通过端到端的学习,实现了水下图像到清晰图像之间的转换。与传统的方法相比,本文方法更加智能,同时具有更好的增强效果,解决了人工提取特征难的问题。最后通过结果分析与客观评测,证实本文方法能够有效地增强水下图像。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
燃气涡轮试验与研究(2021年6期)2021-08-01
数学小灵通·3-4年级(2021年5期)2021-07-16
海洋信息技术与应用(2020年4期)2021-01-18
中国生物医学工程学报(2019年5期)2019-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年3期)2017-11-23
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
