
自然语言处理在电力智能问答领域的应用研究
2021-04-29 03:22田丽洪福斌
科技与创新 2021年8期
田丽,洪福斌
自然语言处理在电力智能问答领域的应用研究
田丽,洪福斌
(国网电子商务有限公司,北京 100053;国网雄安金融科技集团有限公司,河北 保定 071000)
利用自然语言处理技术和机器学习技术,结合电力常识和居民用电侧知识积累(包含用电安全、用电常识、用电政策、应急预案等内容),构建电力行业知识库,在用户侧提供智能在线客服。智能在线客服支持用户通过文本或语音输入,系统识别客户真实意图,通过引导交互式地问询,为居民用户提供问题解答,问题涵盖生活用电方面的常识、电力政策、停电信息、办电流程等,既能显著节约客服中心的工作量,提高工作效率,又能丰富客服系统功能,提升用户体验。
自然语言处理;机器学习;知识库构建;智能问答
1 引言
电力领域目前对用户的问题诉求处理仍采用传统的呼叫模式:以电话→坐席受理→问题解答→坐席回访为主[1],用户的问题涵盖了故障报修、停电信息查询、电量电费查询、投诉举报、电动车联网等业务类型,客服中心为了保证能够随时解答用户提出的问题,提供7×24 h服务,投入了大量的人力资源。尽管如此,业务知识更新速度快,业务人员的知识储备和学习能力不一,人力成本不断增加,而且电话客服通过语音菜单对客户进行分类引流,虽然一定程度上提高了匹配程度和应答效率,但是相对复杂的客服流程却无形中增加了用户和客服之间的沟通门槛,造成不佳的用户体验。因此,如何减轻客服压力,降低人力成本,打造功能更加丰富、体验更好的客服系统,是急需解决的问题。
人工智能是目前研究的热点和技术发展趋势,智能问答作为人工智能的一种典型表现形式,允许用户口语化表达,并为用户直接返回所需的答案,提高了沟通效率,节省了人力资源,具有较强的应用需求和研究价值。
目前在智能问答方面的研究主要有三方面:文献[2-3]提出基于语法分析的问答系统构建方法,文献[4-6]提出基于复杂神经网络词向量技术可提高信息检索的速度以及准确率,文献[7-8]提出深度学习技术、Learning to Rank以及基于用户反馈信息调整检索答案技术。
综上所述,构建一套问答系统,既需要理解自然语言问句,还需要构建海量的知识库,因此,本文通过对自然语言问句的理解和研究,设计一套智能问答系统,实现两个目标:一是能更好地理解用户的上下文语境和语义,提升对问题的理解能力;二是系统自身具备更强大的知识库和自我学习的能力,通过问答训练和算法调优,不断提升答案的匹配精准度。本文提到的智能问答系统,主要结合电力常识和公司居民用电侧知识积累(包含用电安全、用电常识、用电政策、应急预案等内容),构建电力行业知识库,在用户侧提供智能在线客服,通过语音识别和语义分析技术,识别客户真实意图,通过引导交互式地服务,为居民用户提供生活用电方面的常识、电力政策、停电信息、办电流程等问题的解答。
2 自然语言处理方法研究
自然语言处理是一门交叉学科,涉及语言学、数学、计算机科学、信息学、电子科学、心理科学、认知科学、神经科学等,而作为专业领域内的研究,还需要加入该专业的领域知识[9-11]。本文所设计的智能问答系统关键模块主要包含知识库创建、问题理解、问题检索,涉及的技术主要包含语料清洗、中文分词、特征工程、模型训练。
2.1 语料清洗
把不感兴趣或者无用的,视为噪音的内容进行删除,如针对原始文本,提取标题、摘要、正文等信息,对于爬取的网页内容,去除广告、标签、HTML、JS等代码和注释。
2.2 中文分词
汉语以字为基本书写单位,词语之间没有明显的区分标记,分词技术是知识库搜索查询过程中的第一步,分词实现效果的好坏对系统问答结果的影响非常大[12]。中文分词后,给每个词或者词语进行词性标注,如给词语打上形容词、动词、名词等标签;去停用词指对文本特征没有任何贡献作用的字词进行删除,比如标点符号、语气、人称等;命名实体识别指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
2.3 特征工程
把分词之后的字和词语表示成计算机能够计算的类型。把中文分词的字符串转换成数字,主要运用的技术为词向量技术,词向量是一种将单词表征成为高维空间的向量表示方法。词向量技术最初用于在语言模型技术中,将单词词典作为一个向量,词典中所含词的个数即为向量的维度,某个单词的向量即为单词在词典中出现的位置。本文所述智能问答系统所使用的词向量技术来源于谷歌发布的Word2vec开源工具[13]。其主要包含两个模型,即跳字模型(Skip-Gram)和连续词袋模型(Continuous Bag of Words,简称CBOW),以及两种高效训练的方法,即负采样(Negative Sampling)和层序Softmax(Hierarchical Softmax)。Word2Vec词向量可以较好地表达不同词之间的相似和类比关系。
2.4 模型训练
卷积神经网络是人工神经网络的一种,卷积神经网络包含至少六层的神经网络,包含输入层、特征表示层、卷积层、下采样层、隐藏层和输出层[12]。在分类模型的建立上,本文选择使用的是卷积神经网络CNN。CNN最大的优势在特征提取方面。由于CNN的特征检测层通过训练数据进行学习,避免了显示的特征抽取,而是隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,相比于传统的Randomforest或是Xgboost等经典分类模型,CNN具有发现更多难以察觉的局部特征的能力,而不是像传统的方法最终的结果始终要受到特征工程好坏的限制。
3 电力智能问答系统研究与实现
3.1 系统整体设计
电力智能问答系统产品功能流程如图1所示,用户通过语音方式或者文本方式将问答语句输入,如果用户输入为语音,需要通过语音识别技术将其转化为文字,并通过语义识别技术将其转换为表达式,自然语言处理模块理解表达式,将其转化并输入至对话管理模块,对话管理模块采取特定的算法进行回复,然后再生成自然语言,完成文字至语音的输出。
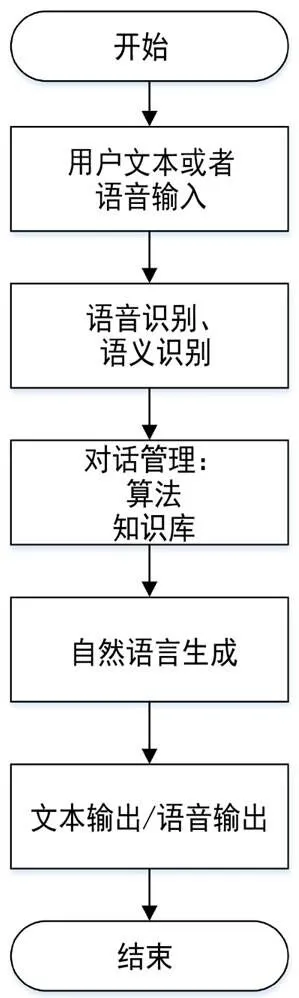
图1 电力智能问答系统产品功能流程
本文电力智能问答系统体系架构如图2所示,最下层为数据获取层,往上分别为知识库构建、智能问答处理及应用模块。
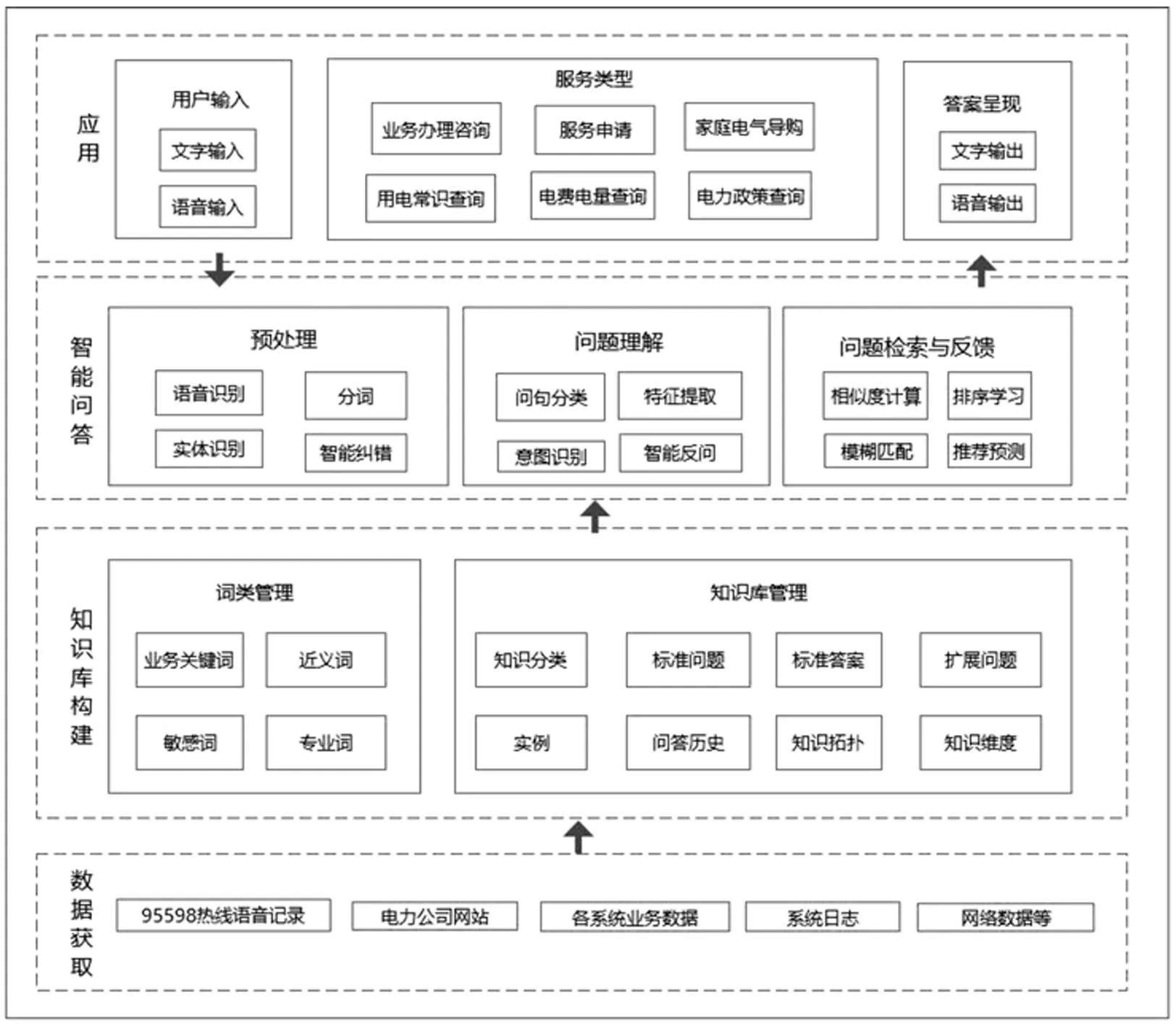
图2 电力智能问答系统体系架构
知识库构建模块:通过数据爬取、人工标注、关系抽取、知识分类、规则构建等一系列过程,形成知识库。
智能问答处理模块:用户以语音或者文字输入后,主要经过预处理、问题理解、问题检索和反馈,最终以文字或者语音形式输出给用户。
应用模块:在智能问答核心技术的支撑下产生的各种应用和服务,可提供业务办理咨询、服务申请、家庭电气导购、电费电量查询、用电常识查询、电力政策查询、停电通知等服务,同时可和传统人工坐席相结合,在智能问答无法回答的情况下,再呼叫人工坐席。
3.2 数据获取
智能应答系统首先要有数据来构建知识库,数据可以来自于互联网爬取,也可是现有的知识库或者特定的语料库。
数据源:95598热线业务范围覆盖故障报修、业务咨询、投诉、举报、建议、意见、表扬、服务申请等业务类型,经过多年运营已经形成了海量、翔实的数据积累[14]。另外,数据源还可包括电力公司网站、营业厅、供电所、电管家等各业务数据,国网各业务系统日志数据以及百度、论坛等网络数据。
数据获取:网络爬虫、人工维护录入、第三方开放平台接口。
数据挖掘:对所获取的数据按一定的结构和规则,通过数据挖掘技术挖掘成有用的信息或结构化信息[15]。
电力智能问答系统的数据获取与挖掘如图3所示。
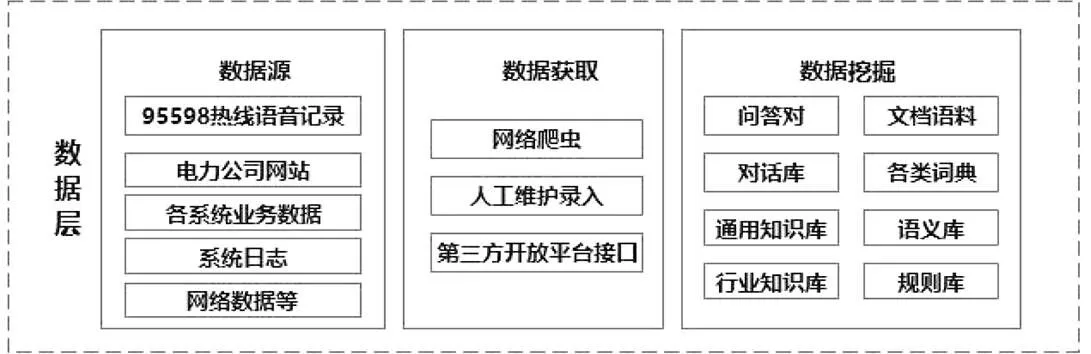
图3 电力智能问答系统的数据获取与挖掘
3.3 知识库构建
知识库有通用领域的知识库和专用领域知识库,针对电力领域智能问答领域,通用领域的知识库已不能满足需求,需要构建专用领域知识库,获取数据后,可以进行知识库构建,知识库构建模块主要分为词类管理、知识库管理和问答历史管理。
3.3.1 词类管理
词类管理模块实现对业务关键词、近义词、敏感词、专业词、前后缀和拼音词的处理。特定领域内部有许多领域内术语,需要人工设置领域内关键词,用以区分和精确匹配答案,词类管理通过人工手动添加的方式,增加词类信息。
3.3.2 知识库管理
知识库是智能问答系统的知识中枢,由知识分类、标准问题、扩展问题、标准答案、实例、属性组成。其中知识分类是运营人员或客户预先对知识库的各个问答对标注的分类信息,实例是指一个针对同一答案的不问问法的集合,属性是另一种分类信息。标准问题和标准答案是指客户给出的常用知识问答对,扩展问题是指运营人员针对同一标注答案提供不同问法。
3.3.3 问答历史管理
问答历史模块记录所有用户跟系统的聊天记录,基于此可以重点关注未解决问题,分析、改进系统的智能化程度。
3.4 智能问答
智能问答主要包括预处理、问题理解、问题检索3个模块,预处理模块将用户输入的查询语句通过智能分词、命名实体标注等方法转换为关键字、词序列。问题理解模块明确用户提出的问题,问题检索模块指系统提供根据用户提出的问题进行查询以及排序并返回结果的过程。
3.4.1 预处理
预处理包括智能分词、命名实体识别、智能反问模块。
智能分词模块:将用户输入的查询语句进行分词,分词时将词类管理中生成的特殊词以及词组添加入分词词典,并保持更新。
命名实体识别模块[16]:主要负责将语句中的人名、地名以及事先标注好的实体名识别出,并加以特殊标记。
智能反问模块:在检索不到用户答案时,判断用户是不是表意不清,反问用户是不是想要咨询另一问题。
3.4.2 问题理解
问题分析模块主要通过分类器识别、分析用户问题的意图,在问题分析模块中,使用基于词向量的卷积神经网络模型对用户意图进行分类。其中词向量技术主要用于解决文本表示的问题,而卷积神经网络实现文本特征的删选和构建分类模型。
3.4.3 问题检索与反馈
数据库中存储一些常用用户问题和标准问题的问答,通过一个分布式的内存数据库实现,主要解决用户最常用的问题,例如“电费电量查询”等。检索模块主要根据问题分析模块分析得到的词,去分布式索引库中检索问题相关的问题。与此同时,为了更精准地理解用户以及扩大知识范围,问题通过推荐模块对用户进行相应的推荐,推荐模块通过业务逻辑树实现分层次的业务推荐。另外,为了更好地完成与用户的会话信息,系统还会对用户Session进行维护,使之能够实现业务与操作的自动补全。
系统在完善业务相关问答的同时,还可以回答客户的一些非业务问题,基于机器学习技术的情感分析模块可以对用户的情感进行判断,使系统能人性化地对用户的投诉等问题进行针对性的回答。
3.5 创新点
3.5.1 上下文理解
系统通过用户ID维护对话Session,自动记录用户的相关信息,如有要处理的业务以及要进行的操作,在Session可以实现对用户业务和操作的自动补全。此外还包括对话上下文理解、对话流控制。同时具有多用户状态管理功能,维护多用户对话记录上下文,追踪和控制多用户之间不同的状态。
3.5.2 智能推荐
为了使系统给出的答案更加多样化,系统对Query进行了推荐,该模块通过处理用户的问询,结合用户之前的提问内容,补全上下文信息,结合关键词匹配技术,为用户提供语义相关、多维度的信息服务,实现推荐信息最大化。同时开通了以业务逻辑树为主体的推荐平台,该平台通过提取业务关键词之间的逻辑关系,建立业务之间的多层分支结构,为推荐平台多维度、精细化语义匹配推荐算法的实现提供基础。
3.5.3 情感分析
系统通过已有数据进行特征提取,找到表示具有情感倾向性的特征词,通过机器学习方法对大量数据进行建模,训练模型,判断问题的情感倾向,以此判断当前用户的情感倾向性,如高兴、愤怒等,对用户进行针对性的回答。
4 结束语
本文提出的基于自然语言处理处理技术和机器学习技术构建电力领域智能问答系统,为居民用电测提供智能在线客服,既能显著节约人工客服的工作量,更能满足业务需求,提高客户体验,有着非常重要的应用前景,另外,由于自然语言和领域知识的复杂性,当前限定领域的问答系统的实现在技术上还有很多难点需要解决,需要进一步研究语义理解、语境识别、指代消解、自学习等技术,提升问答系统的效率和准确率。
[1]游绍华,张羿,段红刚,等.智能客服在电网呼叫中心的应用[J].科技传播,2018(1):57-59.
[2]BERNAT J,CHOU A,ROY F,et al.Semantic parsing on freebase from question-answer pairs[C]//The 2013 conference on empirical methods on natural language processing,seattle:association fbr computational linguistics,2013:1533-1544.
[3]BERANT J,LIANG P.Semantic parsing via paraphrasing[C]//The 52nd annual meeting of the association for computational linguistics,baltimore: association for computational linguistics,2014:479-485.
[4]MIKOLOV T,CHEN K,CORRADO G,et al.Efficient estimation of word representations in vctor space[J/OL].[2021-03-23].https://www.oalib.com/paper/4057741.
[5]MIKOLOV T,SUTSKEVER I,CHEN K ,et al. Distributed representations of words and phrases and their compo sitionality[J]. Advances in neural information processing systems,2013(26):3111-3119.
[6]MAAS A L,DALY R E,PHAM P T,et al.Learning word vectors for sentiment analysis[C]//49th annual meeting of the association for computational Linguistics:human language technologies,2011.
[7]LEI Y,HERMANN K M,BLUNSOM P,et al.Deep learning for answer sentence selection[J/OL].[2021-03-23].https://www.oalib.com/paper/4067539.
[8]CHELARU S,ORELLANA-RODRIGUEZ C,ALTINGOVDE I S.How useful is social feedback for learning to rank YouTube videos?[J]. World wide web,2013,17(5):997-1025.
[9]MANNING C D.Computational linguistics and deep learning[J].Computational linguistics,2015,41(4):1-7.
[10]JURAFSKY D,MARTIN J H.Speech and Language processing:an introduction to natural language processing,computational linguistics,and speech recognition[M]. NJ:Prentice Hall,Upper Saddle River,2008.
[11]MANNING C D,SCHIITZE H.Foundations of statistical natural language processing[M].London:The MIT Press,1999.
[12]王蕾.面向医疗健康领域的智能问答系统的设计与实现[D].北京:北京邮电大学,2018.
[13]邢超.智能问答系统的设计与实现[D].北京:北京交通大学,2015.
[14]游绍华,张羿,段红刚,等.智能客服在电网呼叫中心的应用[J].科技传播,2018(1):57-59.
[15]邱剑.电力中文文本数据挖掘技术及其在可靠性中的应用研究[D].杭州:浙江大学,2016.
[16]杨燕.面向电商领域的智能问答系统若干关键技术研究[D].上海:华东师范大学,2016.
TP391.1
A
10.15913/j.cnki.kjycx.2021.08.002
2095-6835(2021)08-0005-04
田丽(1992—),女,本科,主要研究方向为自然语言处理技术的主要模型及算法及其在语音识别、搜索引擎、知识图谱等方面的应用。
〔编辑:王霞〕
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
校园英语·月末(2021年13期)2021-03-15
读者·原创版(2020年2期)2020-02-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
故事会(2016年21期)2016-11-10
爆笑show(2015年12期)2016-01-07
爆笑show(2015年1期)2015-03-26
——基于与QuestionPoint的对比
新世纪图书馆(2014年11期)2014-02-23
读写算·高年级(2009年3期)2009-11-16
