
融合用户长短期偏好的基于强化学习的推荐算法
2021-04-25 05:23杜子文
现代计算机 2021年6期
杜子文
(四川大学计算机学院,成都610065)
0 引言
随着科技的进步与互联网的蓬勃发展,推荐系统在人们的生活中占据了重要的地位[7-10]。其中基于强化学习的推荐系统由于具有灵活的推荐策略以及考虑了用户的长期交互体验从而吸引了越来越多的研究者的关注。例如,用户在TikTok 上浏览视频,推荐系统根据用户的浏览记录来改变推荐视频的策略,从而推荐出不同的视频,同时提高了用户的浏览体验,以便尽可能地将用户留在TikTok 中。
基于强化学习的推荐算法的关键就是要捕捉用户的偏好[1-4]。现有的基于强化学习的推荐算法编码用户的近期交互记录来得到用户的短期偏好并且将用户的人口统计信息作为用户的长期偏好[10-11],从而将短期偏好和长期偏好进行融合得到用户的动态偏好。这种做法存在以下两个问题:
(1)忽略了用户的长期偏好是在随着用户的交互记录的变化而变化的。
(2)没有细粒度的建模用户的长期偏好,即用户每个时期的偏好对用户当前交互的商品产生的影响是不同的。
因此本文提出一种细粒度地建模用户长期偏好并且融合用户长短期偏好的基于强化学习的推荐模型,名称为LSR。本模型使用分层注意力的方法[5]首先在底层编码用户对不同商品的关注度,融合每个时期加权后的商品嵌入得到用户的每个时期的偏好,然后在高层编码用户对不同时期偏好的关注度,再融合加权后的每个时期的偏好进而得到用户的长期偏好;同时使用自注意力的方法融合用户近期交互的商品得到用户的短期偏好,最终将短期偏好和长期偏好融合得到用户的动态偏好,即用户的状态,然后采用深度Q 网络的方法[6]将推荐的商品与用户的状态融合送入多层感知机,得到累积奖励值。我们的贡献主要有以下三个:
(1)我们提出了一个融合用户长短期偏好的基于强化学习的推荐模型,该模型可以细粒度地建模用户的长期偏好,从而提高模型的推荐效果。
(2)我们采用分层注意力的方法来区分用户对不同商品的关注度以及对不同时期偏好的关注度,细粒度地建模用户的长期偏好。
(3)我们在真实的数据集上与baseline 进行对比,验证了本模型的有效性。
1 强化学习
1.1 马尔科夫决策过程
基于强化学习的推荐算法将推荐任务视为一个马尔科夫决策过程,通过try-error 机制来获取最优的推荐策略。我们可以用一个五元组来描述马尔科夫决策过程:
(1)状态空间S:状态st代表用户u在t时刻的偏好。st={Il,Is},其中Il代表了用户的长期偏好,Il中包含了用户在当前会话之前的所有会话中交互的商品。Is代表了用户的短期偏好,Is中包含了用户在当前会话中交互的所有商品。两个集合中的商品都是按照时间顺序排列的。
(2)动作空间A:动作at表示推荐系统在t时刻向用户u推荐的一个商品it。
(3)状态转移概率P:当用户u交互商品it后,我们就将这个商品it添加到Is集合中,得到下一个状态st+1。
(4)当前奖励值rt:用户u会对商品it有不同的反馈,例如点击、收藏、购买等,用户通过不同的反馈行为来评价这次推荐系统推荐商品it的效果。我们根据用户给出的反馈计算得到当前的奖励值rt。
(5)折扣因子γ:折扣因子γ衡量当前奖励值rt在累积奖励值Q中占据的比重。折扣因子γ的取值范围为[0,1],当折扣因子越接近1,表示当前奖励值rt在累积奖励值Q中占据的比重越小;当折扣因子越接近0,表示当前奖励值rt在累积奖励值Q中占据的比重越大。其中Q=rt+γrt+1+γ2rt+2+…。
1.2 问题定义
根据用户u在t时刻的交互记录st,我们的模型LSR 需要向用户u推荐一个商品it,这个商品it可以使得推荐平台获得的累积奖励值Q最大。
2 模型
在下文中,我们首先对模型进行概括描述,然后介绍模型中编码用户短期偏好和编码用户长期偏好以及深度Q 网络的技术细节。
2.1 模型概述
图1 展示我们的模型的整体结构。为了得到用户动态的长期偏好,我们将用户在当前会话之前的所有会话中交互的商品进行融合得到随着用户交互历史记录改变而发生变化的长期偏好。为了细粒度地对用户的长期偏好建模,我们采用分层注意力的方法编码用户对不同商品的关注度,得到用户对不同会话的偏好{pS1,…,pSj,…,pSn},其中pSj是用户的第Sj会话的嵌入向量,用户的长期交互记录中一共有Sn个会话。然后我们编码用户对不同会话的关注度,从而细粒度地建模得到了用户的长期偏好plong。同时,我们仍采用注意力的方法对用户当前会话中的商品进行融合得到用户的动态的短期偏好pcur。然后将长期偏好plong和短期偏好pcur进行融合得到用户的动态偏好,即用户的状态st。然后我们采用一般的深度Q-learning 方法[6]中的ϵ-greedy策略来选择推荐系统要执行的动作at,即推荐系统向用户推荐的商品it,然后将用户状态st和商品it送入到深度Q-network 神经网络得到在状态st下采取动作it所获得的累积奖励值Q(st,at;θ)。然后将商品it加入到当前会话中得到下个时刻的状态st+1。

图1 模型
2.2 编码用户短期偏好
由于用户对当前会话中的商品具有不同的关注度,因此我们采用自注意力的方法[5]对当前会话中的商品{i1,…,it-1}进行融合得到用户的短期偏好pcur。自注意力的方法包含三部分,分别是查询矩阵qn×d,索引矩阵kn×d和值矩阵vn×d。自注意力的计算公式如下:
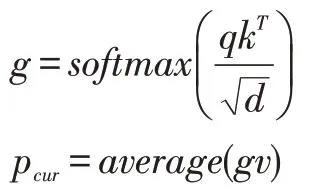
其中,d是商品的嵌入维度大小,n是当前会话中用户交互商品的个数。g是计算得到的注意力系数,g∈Rn×d。pcur是 用 户 的 短 期 偏 好 嵌 入 向 量,pcur∈R1×d,average(∙)为求平均操作。在本文中查询矩阵q,索引矩阵k和值矩阵v都是相同的,即都是包含了当前会话中用户已交互的商品的嵌入,如下:

其中,i1×d是商品的嵌入向量。在本文中,我们将每个商品作为一个单词,每个会话作为一个句子,采用Word2Vec 的方法[12]对商品进行预训练得到低维的稠密的商品嵌入向量i。
2.3 编码用户长期偏好
考虑到用户对历史会话中的商品的关注度不同,于是我们仍然采用自注意力的方式对不同会话内的商品进行融合得到用户不同会话的嵌入表达{pS1,…,pSj,…,pSn}。融合用户对不同会话中商品的关注度的计算公式如下:

其中d是商品i的嵌入维度,l∈R|Sj|×d,pSj是用户的第Sj会话的嵌入向量,pSj∈R1×d,由于用户对不同会话的关注度也是不同的,于是我们再次采用注意力的方法建模用户短期偏好对于不同会话的关注度。我们将短期偏好pcur作为查询向量,将不同会话的嵌入向量作为索引向量和值向量,计算得到用户对于不同会话的注意力得分α,然后将注意力得分α与每个会话的偏好进行融合得到用户的长期偏好plong∈R1×d。计算公式如下:

2.4 Q-network
在得到用户的长期偏好plong和短期偏好pshort后,我们将长期偏好和短期偏好进行拼接操作得到用户的动态偏好,也就是用户的状态st∈R1×2d。然后将用户的状态st和推荐系统向用户推荐的商品it一起送入深度Q-network 神经网络中,计算得到在状态st下,执行动作at,所获得的累积奖励值Q∈R。我们采用一般的DQN 的五层全连接神经网络来得到累积奖励值Q(st,at;θ),其中θ为网络的参数。
2.5 损失函数
在真实的推荐系统中,状态空间和动作空间是巨大的,因此对于每一个状态-动作对,估计其状态值函数Q(s,a)是很困难的。另外很多状态-动作对并没有出现过,因此很难去得到这些状态-动作对所对应的状态值函数。因此,我们需要使用近似函数来估计状态值函数,即Q( )s,a≈Q(s,a;θ)。由于状态动作值函数是高度非线性的,于是我们采用深度神经网络作为近似函数。在本文中,我们利用贝尔曼方程来训练模型。我们采用随机梯度下降的方法最小化下面的损失函数:
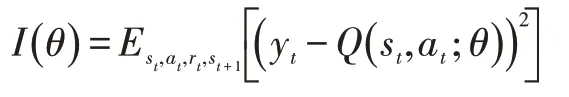
其中yt=Est+1[rt+γQ(st+1,at+1;θ)|st,at]。rt是根据用户的反馈计算得到的当前奖励值。
2.6 训练过程
本模型采用基本的DQN 的训练过程,我们的训练过程可以分为两个部分,分别是样本存储阶段和采样训练阶段。我们首先介绍样本存储阶段:在t时刻,推荐系统观察用户的交互记录st,根据用户u 的交互记录,采用ε-greedy策略,以小概率随机选择一个商品进行推荐或者以一个大概率推荐对应累积奖励值最大的商品。接着用户给出反馈,例如点击、收藏、购买等行为。我们将反馈计算得到奖励值。然后我们将商品添加到用户的交互记录中更新用户的状态,得到用户的下一个时刻的状态,并将样本(st,at,rt,st+1)存储起来;采样训练阶段:在训练样本存储后,我们随机选择batch size 大小的训练样本,然后采用随机梯度下降的方法最小化损失函数。
3 实验
3.1 实验目的
我们在两个真实的数据集上进行了实验,并验证了两个问题:
(1)我们的模型与baseline 相比,推荐效果如何。
(2)我们的模型中细粒度建模用户长期偏好的有效性。
我们首先介绍实验的设置,然后我们会根据实验结果回答以上两个问题,最后我们研究了模型中关键超参数的影响。
3.2 实验设置
我们采用了MovieLens(1M)数据集和MovieLens(100k)数据集。数据集的统计信息如表1。

表1 实验数据集说明
由于我们的模型没有解决冷启动的问题,因此我们过滤掉了交互商品数量少于3 个的用户。过滤后的每个数据集我们都选取80%的数据作为训练集,剩余20%的数据作为测试集。我们将每个商品作为一个单词,每个会话作为一个句子,采用Word2Vec 的方法预训练得到商品的低维稠密的嵌入向量,其中我们按天数来划分会话,每一天都是一个会话。折扣因子γ=0.99 。我们将用户对商品的评分作为当前奖励值rt。
(1)Baselines
①GRU4Rec[13]:该模型使用循环神经网络的方法将用户交互的商品进行融合,然后给用户推荐商品。
②DQN[6]:该模型融合了用户的短期偏好,并且使用深度神经网络来近似获得累积奖励值。
③DEERS[10]:该模型使用GRU 分别对用户的正反馈信息和负反馈信息融合得到用户的短期偏好,利用DQN 的训练方式来进行训练。
④LSR-short:该模型是我们LSR 模型的变体。该模型没有考虑用户的长期偏好,只采用注意力的方式融合了用户当前会话交互过的商品。
⑤LSR-long:该模型是我们LSR 模型的变体。该模型没有细粒度地建模用户对不同会话时期的偏好,而是将用户的每个会话的偏好以求平均的方式得到用户的长期偏好。在建模短期偏好时,方法和LSR-short保持一致。
(2)评价指标
本文采用了两个评价指标来衡量模型的推荐效果,分别是Recall和MRR。Recall评价的是所有测试样例中真实样例在top-k 列表中出现次数的情况的比例。MRR评价的是所有测试样例中真实样例在top-k列表中被正确排序的情况的比例。这两个评价指标的计算公式如下:
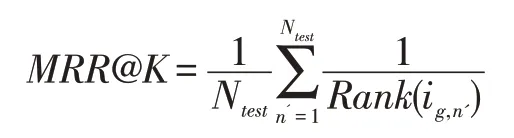
其中Rank(ig,n')是商品ig在第n' 个测试会话中的排名。

其中Ntest和#hit分别是测试会话的数量和测试商品出现在top-k 推荐列表的个数。值得注意的是,所有的评价指标的取值范围都是[0,1],值越大表示推荐效果越好,值越小表示推荐效果越差。
3.3 实验结果
实验结果展示在表2 和表3 中。我们从表中有以下的发现:
(1)我们的模型LSR 在两个数据集上的表现是最好的。LSR 模型的效果比GRU4Rec 模型的效果好,表明强化学习优秀的序列决策能力以及融合用户长期短期偏好可以提高模型的推荐效果。LSR 模型比DQN模型和DEERS 模型的效果好,表明了融合用户长短期偏好可以提高模型的推荐效果。
(2)DQN 模型的效果比GRU4Rec 模型的效果好,说明了强化学习的优秀的序列决策能力可以提高模型的推荐效果。
(3)DEERS 模型的效果比DQN 模型的效果好,表明了融合用户的负反馈信息得到用户的短期偏好可以提高模型的推荐效果。
(4)LSR-short 模型效果比DEERS 效果差,因为LSR-short 模型没有考虑用户的长期偏好以及没有融合用户的负反馈信息,因此效果差。但是LSR-short 模型比DQN 模型效果好,因为LSR-short 模型采用注意力的方法,编码了用户对不同商品的关注度,但是DQN模型是将不同商品平等看待,没有区分不同商品对当前用户的贡献不同。
(5)LSR-long 模型效果比DEERS 效果差,因为LSR-long 模型没有细粒度的建模用户的长期偏好。从LSR-long 模型的效果比LSR-short 模型的效果好可以看出,建模用户的长期偏好是可以提高模型的推荐效果的。
(6)LSR 模型的效果比LSR-short 模型的效果好,说明融合用户长短期偏好可以提高模型推荐效果。LSR 模型比LSR-long 模型效果好,说明细粒度地建模用户的长短期偏好可以提高模型的推荐效果。这也验证了我们实验的两个目的。
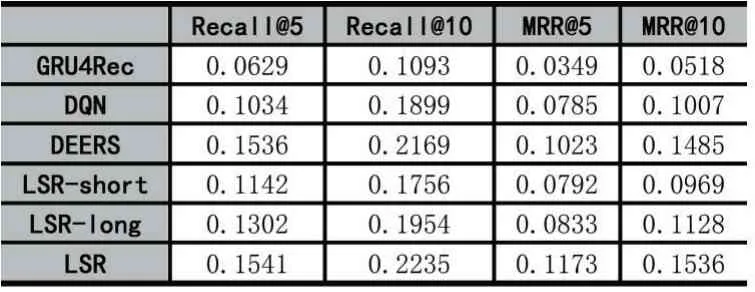
表2 所有模型在MovieLens(1M)数据集上的表现

表3 所有模型在MovieLens(100k)数据集上的表现
3.4 超参数分析
我们在这个章节验证了超参数商品维度d对模型效果的影响。结果如图2 所示。
从图2 可以看出商品的维度d可以影响到模型的效果。随着d的增大,模型的效果先提高再下降。当d比较小的时候,网络的参数少,模型会出现欠拟合的问题,从而导致最后的效果不好;当d过大时,网络的参数会增多,模型会出现过拟合的问题,因此模型的效果会降低。从图2 可以看出,对于MovieLens(1M)数据集来说,d=100 时,模型的效果表现最好;对于Movie Lens(100k)数据集来说,当d=128 时,模型的效果表现最好。

图2 超参数分析——d 是商品的嵌入维度
4 结语
本文提出了一个融合用户长短期偏好的基于强化学习的推荐模型,该模型细粒度地建模了用户的长期偏好,从而提高了模型的推荐效果。本模型编码了用户对于不同商品的关注度以及不同会话的偏好关注度。在实际应用中,商品还有很多属性信息,因此如何编码用户对商品不同的属性的关注度是本文的未来的关注点。
猜你喜欢
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
长江丛刊(2020年17期)2020-11-19
初中生世界·九年级(2020年2期)2020-04-10
小雪花·成长指南(2016年11期)2016-12-07
考试周刊(2016年82期)2016-11-01
商(2016年1期)2016-03-03
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
