
基于图神经网络和异构信息的兴趣点分类
2021-04-25 05:22任成森杨易扬郝志峰
现代计算机 2021年6期
任成森,杨易扬,郝志峰,2
(1.广东工业大学计算机学院,广州510006;2.佛山科学技术学院,佛山528225)
0 引言
近年来,随着移动智能终端的普及,用户的注意力从固定设备转移到掌上移动设备,并随着3G、4G 网络的普及,众多移动应用开始推出可以记录用户位置的地理位置、兴趣点推荐的应用,例如美团、饿了么、支付宝口碑。为了给用户推荐更合适的兴趣点,进而带动该地点的消费,众多企业和研究团队都花费了大量的精力研究基于地理位置的各种应用。其中,兴趣点分类是众多下游应用的基础。大公司能够利用雄厚的财力来推广并获取海量的用户评论信息,能够简单地在大数据的基础上将兴趣点分类转化为文本分类,再加上足够的兴趣点标注预算,使得普通的文本分类模型也能进行精准分类。但这些数据和模型都是闭源的,新公司、新研究团队无法在有限的条件下快速实现能够适合生产的兴趣点分类模型。在这个背景下,如何在已有数据和有限标注成本的情况下,提高兴趣点的分类成为了研究重点。为了达到这个目的,我们需要解决以下问题:如何充分利用兴趣点的已有信息?
图卷积神经网络(Graph Convolutional Networks,GCNs)[1]作为一个半监督学习框架,在不规则场景获得了大量的关注。在众多的领域获得了大量的应用[2],如自然语言处理[3]、计算机视觉[4]、网络分析[5]等等。对于深度神经网络来说,复杂的结构往往能够带来准确率上的提升。而复杂结构的GCN 却会引入新的问题:领域指数增加[6]。也就是说,假设要计算第L 层的一个节点的损失值,则需要获得第L-1 层的k 个节点(k 为邻接节点的数量,且每个节点的k 值都不固定),如此类推到更多的网络层上,这就意味着随着GCNs 的迭代网络层的增加,计算量也会成倍地增加,但模型预测效果反而降低。特别是在兴趣点这一类包含大量节点的任务中,深层的GCNs 网络并不适用,但GCNs 能够利用兴趣点之间的关联信息,是一种很强大的特征融合/传播工具。
除了网络层的深度,有不少研究在图结构上对GCNs 进行了进一步扩展。文本图卷积网络(Text Graph Convolutional Networks,TextGCN)[7]就是从节点类型来扩展GCNs 的模型,它把文本和单词分别视为不同类型的节点,从而有两种类型的边:文本-单词,单词-单词。前者的权重是通过词频-逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)来计算,后者则是通过点互信息(Pointwise Mutual Infor⁃mation,PMI)给出。不同类型的两种节点和边整合到一个图上,从而融合了异构信息,这就考虑了,进而使用GCNs 来处理。这种扩展了信息融合的维度,同时考虑了单词节点之间的共现信息和文本-单词之间类主题信息。本文模型借鉴了TextGCN 的文本-单词结构,构建出兴趣点-单词(来自评论文本)的异构网络。但原始的TextGCN 并直接应用在兴趣点上并不合适,而且会导致性能上的损失。
所以本文所提出的模型基于GCNs,并通过构建兴趣点-兴趣点、兴趣点-评论单词之间的连接,得到一个高鲁棒性的图网路结构,即保证了特征的高效融合/传播,也保证了与基准模型相近的准确率,甚至在Macro-F1 评价标准上超出了基准模型。本文的主要贡献如下:
(1)将兴趣点分类任务转化为节点分类任务,利用兴趣点和评论文本之间的单词关系,构建兴趣点-单词异构网络,并通过实验证明TextGCN 在兴趣点分类任务上的性能差异,使得原本只适用于文档分类的模型改造成适合兴趣点分类的模型。
(2)利用兴趣点的名称,构建兴趣点之间的相似性,使得模型在保证其准确率不下降的情况下,大幅降低其训练速度。
(3)在现实世界的真实数据上的两个城市进行测试,并在不同的参数下测试了其鲁棒性,证明了本文算法的有效性。
1 算法
本节将给出具体的算法实现步骤,分别为异构图网络的构建和模型的构建。
1.1 异构图网络的构建
给定n 个兴趣点,每个兴趣点有诺干篇评论。通过汇总评论进行清理和切割,获得m 个单词。把这n兴趣点和m 个单词视为异构图网络中两种节点,其中该图网络的总节点数为|V|=n+m,其节点特征为单位矩阵。也就是说单个节点时,其特征只考虑自身,所以其对应的特征向量设置为独热编码。本文的任务就是要将这n 个兴趣点分成c 类。
其中兴趣点和单词之间的边的权重由使用TFIDF 算法来计算,这部分和TextGCN 类似。我们在实验中发现,TextGCN 中的单词-单词之间的边,在新闻、疾病文摘这一类中等长度的文本语料上会帮助Text⁃GCN 提高效果,但是其在短文本和超长文本上,则效果式微。表2 中的对比实验也展示了其在兴趣点分类上的效果,在不考虑单词-单词之间的边的情况下,准确率、Macro-F1 下降幅度有限,但大幅降低了训练时间。所以本文不考虑传统的单词-单词结构连接。
虽然在单词-单词之间的边带来的提升效果有限,但去除了却会导致模型略微的降低。本文考虑了兴趣点信息的多样性,利用兴趣点名称作为信息来源之一来考虑。虽然兴趣点名称广义上也属于文本数据,但其来源不同、结构各异,所以并不能上面处理评论数据的方法来处理兴趣点名称。
本文先统计兴趣点名称中的单词词频,把少于2次出现的单词去除,同时也把单词长度少于2 个字符的单词也删除。这主要是因为只出现过一次的单词,对兴趣点之间的相似性并没有积极作用,反而会加大单词列表提高计算成本。构建了兴趣点名称单词列表后,将把每个兴趣点构建其名称的独热编码。有了名称独热编码,通过计算两两兴趣点的名称独热编码的余弦相似性,构建兴趣点和兴趣点之间边,其核心思想在于兴趣点名称中有相似单词的,会认为具有一定的业务相似性,也就是其类别有可能是相似的。其构建公式如下:
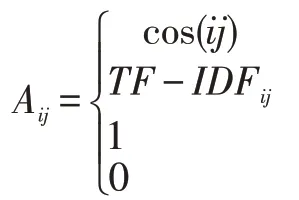
其中,cos(ij)表示兴趣点i 和兴趣点j 的名称独热编码的余弦相似度。TF-IDFij表示兴趣点i 和单词j的TF-IDF 值。则是为了和GCNs 保持一致,对角线元素设置为1,即i=j 的情况,表示节点的自环。其他情况则设为0。用邻接矩阵构建了兴趣点-兴趣点、兴趣点-单词之间的关系后,需要进一步正则化,正则后的邻接矩阵表达为:
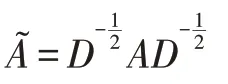
其中,Dii=∑j Ai j。
1.2 模型的构建
本文模型的构建和TextGCN 一样,也是使用了标准的GCNs 模型。一旦兴趣点异构图构建好,就可以输入到一个简单的两层GCNs 模型。第二层节点的模型输出纬度等于兴趣点的类别数c。

其中ReLU(∙)=max(0,∙)是激活函数,σ是softmax算子,θ(1)和θ(2)分别是第一层网络和第二层网络的权重矩阵。模型的损失函数定义已标注兴趣点上的交叉熵损失,其具体定义如下:
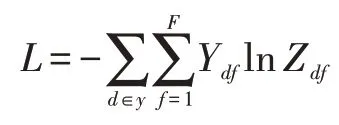
其中y 是已经有标签的兴趣点,F 是模型输出特征的维度。
2 数据与实验
本文在Yelp 2019 数据集①https://www.yelp.com/dataset上进行了对比实验,评估了本文的模型和基准模型TextGCN 之间的性能差异。使用分类任务中常用的评价标准准确率和Macro-F1 来评价模型的表现,其中也给出了训练时间(用秒来计算),来评价各模型的训练效率。
2.1 Yelp数据集
本文采用的Yelp 数据集,来自美国Yelp 公司提供的开源真实兴趣点数据,包含了美国2019 年截止的兴趣点数据。因为实验环境所限,本文抽取了其中两个具有代表性的城市:夏洛特(用Char 来替代)和凤凰城(用Ph 来替代)。其中Char 包含5842 个兴趣点,平均每个兴趣点的评论长度为1754 个单词;而Ph 包含11125 个兴趣点,平均每个兴趣点的评论长度为2146个单词。实验的城市包含了大城市和小城市,已确保实验上的有效性。

表1 Yelp 2019 数据集下两个城市的数据情况
2.2 数据预处理
对于评论数据的处理,将按照TextCNN[8]的文本处理方法,以保证其公平性。先去除在NLTK 定义的停留词,词频低于5 次的单词。对于兴趣点名称数据,因为兴趣点名称的单词数过于简短,一般为2 到5 个单词,所以本文先对兴趣点名称进行按单词切割,统计其单词频率,把只出现过一次的单词和单词长度少于3个字符的单词去除。从而留下的单词作为词表,为每个兴趣点构建其独热编码(one hot)。
2.3 实验设置
本文使用PyTorch 框架来实现。所有的都在相同的硬件配置下进行:64 位Ubuntu 18.04.2 系统,Intel Core i7-6850K CPU(6 核3.60GHz),32GB 内存,和NVIDIA GeForce RTX 1080Ti 显卡(11GB 显存)。中间隐含层的维度均设置为200 维,所有模型的学习率均设置为0.02,Dropout Rate 为0.5,最大迭代次数为200次,使用Adam 优化器进行优化,如果模型在验证集上的损失值不再下降(10 次迭代内),则提前停止训练。本文的数据集划分,遵循7:3 比例,即70%的兴趣点作为训练集、30%的兴趣点作为测试集。其中,为了调整超参数,从训练集中随机抽出了10%的兴趣点作为验证集。
2.4 实验分析
本章在Yelp 2019 数据集上的两个城市进行了对比实验,评估了本算法的有效性,并结合实验结果分析了本文分类算法的优势。
TextGCN 则是原论文的模型,而TextGCN-WW 则是保留文档-单词图,去掉单词-单词共现图下的模型。从表2 可以看出,在准确率上,三种模型的准确率都差不多,证明了单词-单词的共现信息在超长文本上的作用较小,而且大幅度增加了其训练时间,增加了大约6~7 倍的训练时间。随着单词列表增加,这个训练时间还会进一步提高。而本文的模型在保证其准确率上,依然获得了更高的训练效率,可以看到本文模型的有效性。
在Macro-F1 方面,这是一个在准确率的基础上衡量预测标签多样性的指标,我们可以看到,在小城市上,即兴趣点和评论数都少的情况下,本文模型的效果反而有所提升。这就说明了使用兴趣点所构建的兴趣点-兴趣点网络具备一定的信息传递能力,弥补了部分特征单词缺失的兴趣点的缺陷。
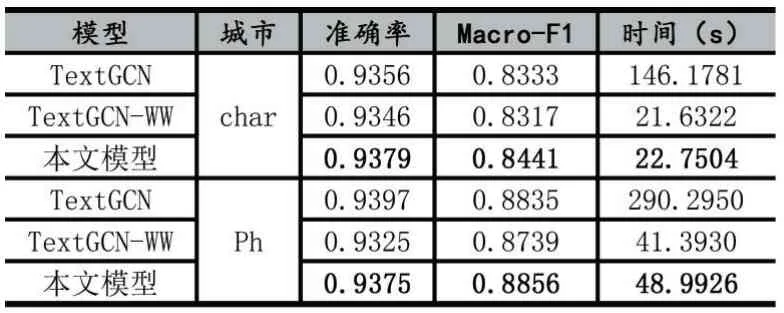
表2 本文模型与基准模型TextGCN、TextGCN-WW 的对比实验
本文即一步探讨其超参数的相关性,以评价本文模型的鲁棒性。因为兴趣点评论文本具有较大的不确定性,而且Yelp 数据集所面向的用户有着各种语言习惯、语言分割、语言种类。探索词的种类有利于衡量模型的鲁棒性,使得模型应用更广泛。
本文分别调整低频词和高频词来调节单词的种类,从而从词频的角度来控制单词的种类,如表3 所示。可以看到,低频词对于分类的多样性非常重要,大量的词虽然只在不到一百篇文章里出现过,但其对分类的多样性非常重要,可以看到删除词频低于50 到100 的单词,基线模型会出现了2%的准确率下降,Macro-F1 更是下降了0.06 个点。本文模型则体现出了其鲁棒性,虽然也有相同趋势的下降,但整体效果还是超过了基线模型,这证明了利用兴趣点名称构建兴趣点网络的有效性。
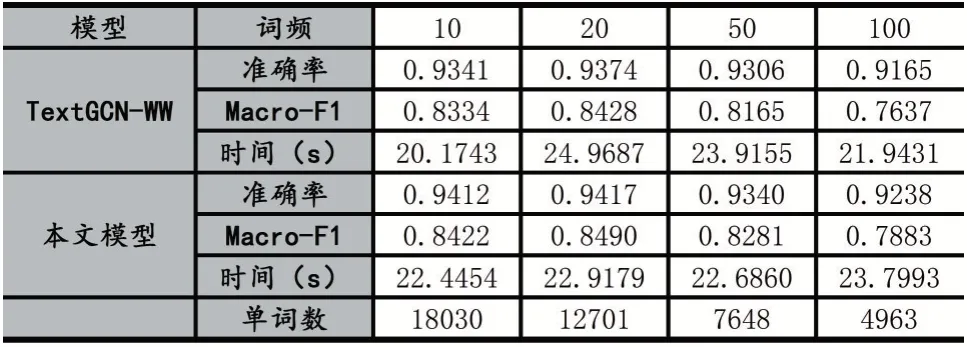
表3 低频词保留情况及模型的相应表现
与低频词不一样的是,高频词在数据中的占比非常少,即使减少到1%,也只是减少了大约1 千个单词。在这里,可以看到两个趋势:
(1)虽然单词数量减少有限,但其能降低其训练时间;
(2)当高频词限制在2%以内时,基准模型的性能则开始下滑。
单词越高频,在图网络中,意味着该单词节点连接的兴趣点节点就越多;在信息融合角度上,意味着该单词节点融合的信息就越多,但从特征传播的角度,信息融合得越多,其特征显著性就越低,传播的效率就越低,而且连接的节点越多,其传播的影响力就越小,因为其边权重会正则化使得每一条边的权重占比更低;在卷积的角度,会增加其卷积的范围,模型在正向/反向传播时,则需要更多的计算资源。这三个角度解释了为什么减少的节点的数量有限,训练速度的提高却如此明显;而且效果却不怎么下降。

表4 高频词限制下本文模型的表现
3 相关工作
图卷积神经网络作为卷积神经网络在不规则图形上的扩展,近年来获得了大量的关注和应用。TextGCN把文本和单词视为节点来构建异构图,使用标准的GCNs 来进行文本分类。但TextGCN 并不能充分利用文本信息,例如忽略了文本之间的语序信息。同时,TextGCN 为了提升效果,引入了单词-单词共现图,但这也导致TextGCN 所需的计算资源快速上涨。同时结合原论文的实验和我们的实验,TextGCN 并不适合短文本分类和超长文本分类。这是因为短文本分类的单词数量较少,且比较注重语序结构;而超长文本,例如本文的评论文本,众多的词汇信息,使得超长文本仅凭单词信息就能获得足够的分类特征,从而无需额外的单词共现信息来弥补单词信息不足的缺陷,这也是本文模型在去除单词共现矩阵后依然有不错的效果的原因。除了语料的处理,TensorGCN[9]则是增加网络的多样性来弥补TextGCN 的不足,包括使用LSTM[10]来保留语序信息、使用CoreNLP 来抽取单词的关系树。但这种做法的问题在于增加了计算复杂度;计算量是Text⁃GCN 的几倍,而准确率则是略有提高。图网络的复杂结构同时也决定了这样的神经网络难以训练和调试。
兴趣点分类的工作则是比较少,因为这一类工作往往转化成文本分类来实现。通过评论文本的分类来实现对兴趣点的分类。但这也的做法也是存在缺陷的,一是没有考虑兴趣点信息的多样性,例如同样是文本信息,兴趣点名称和兴趣点评论则有着不同的来源渠道和语言特征。而Yelp 数据集大多数是用来进行评论情感分类和兴趣点推荐。POIC-ELM 模型则是对POI 进行另一种分类[11]:每日签到POI,每周签到POI,每月签入POI 和年度签入POI。使得模型能够预测推荐的兴趣点是否与用户形成某种生活上的关系,这是从用户和推荐的角度来进行兴趣点分类。
4 结语
综合以上实验,本文提出的模型的确能增强图卷积神经网络在兴趣点分类上的鲁棒性,充分利用了兴趣点上的异构信息。因为Yelp 数据集是来自现实世界真实数据,其评论均来自于真实用户,所以该数据集上的噪音更大,所以在该数据集上解决兴趣点相关的任务更具有挑战性。但是本文的模型算法在这个数据集上,而且是在减少大量边信息的情况下,依然有效而且提高了训练效率。兴趣点分类是一项基础研究任务,精准地为兴趣点进行分类,有利于下游任务,例如兴趣点推荐、社区划分,等等。而兴趣点分类不同于文本分类,其评论数量是动态增加的、不确定性的,而文本分类的样本是固定的,没有时间维度。这就造成了兴趣点分类更容易受新加入的评论影响而使得模型准确性无法保证。
针对以上问题,本文利用图卷积神经网络,针对兴趣点的数据特点,把兴趣点名称作为新的信息补充,通过打通兴趣点之间的信息流通和减少了非关键节点之间的信息流通,大大提高了模型的稳定性和运行效率。充分利用了兴趣点中存在的异构数据。本文设计的实验也进一步证明了本算法的有效性,并在同等条件下获得准确率和训练效率上的提高。虽然本文针对的是兴趣点分类任务,但可以本文的算法适用其他有着异构数据的任务。
目前利用评论和兴趣点名称获得不错的效果,但兴趣点的还包含着地理信息、用户信息和时间信息,但这部分信息更难处理且包含更多的噪音。所以这是一个有待解决的挑战。本文接下来的工作将进一步深入挖掘兴趣点的其他信息。
猜你喜欢
现代电子技术(2022年4期)2022-02-21
智能计算机与应用(2021年4期)2021-06-05
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
