
基于深度特征融合的肺炎影像识别研究*
2021-04-13 03:06冯翔康文清吴瀚王风云王星皓季超
生物医学工程研究 2021年1期
冯翔,康文清,吴瀚,王风云,王星皓,季超
(1.潍坊医学院生命科学与技术学院,潍坊 261000;2.潍坊市益都中心医院,潍坊 262500)
1 引 言
新冠肺炎(COVID-19)主要依靠检测试剂、影像诊断等方式筛查。肺炎影像筛查需经验丰富的放射科医生、临床医生等逐级阅读、诊断、分析,尤其在疑似病例大量激增的情况下,难以短时间内处理。同时,长时间阅片、分析也在一定程度上加重医生身心负担,易造成漏诊、误诊。
近年来,以深度学习为代表的人工智能技术在医学图像分析领域飞速发展,其可减轻医生的工作量,避免主观因素影响,提高诊断准确率。Shen等[1]提出一种多尺度融合的卷积网络,融合不同尺度感受野特征来增强网络特征提取能力,识别率达到86.8%;张弛名等[2]引入迁移学习方法实现肺结节的辅助诊断,准确率达91.44%;张物华等[3]利用多模型融合策略来诊断肺炎X光图像,准确率为89.08%;吴柯薇等[4]基于深度残差网络对冠状动脉CT血管造影图像斑块进行识别,取得86.82%的准确度。实际应用中,由于CT、X光片等影像数据相对匮乏且难以获取,上述深度模型往往面临训练难、易过拟合等问题。医学图像分类中涉及更多的是细粒度图像分类,其难点在于图像所属的类别粒度更加精细。常规医学图像中病变组织与正常组织间往往仅在纹理、边缘等细微处存在差异,肉眼识别存在诸多非客观因素,尤其对经验不足的医师来说,疫情背景下对医学图像的诊断面临巨大心理挑战。
针对该问题,本研究构建了一种新的基于跨层连接机制的多主干网络特征融合卷积模型,利用多尺度感受野融合思想来捕获医学图像局部细节,实现COVID-19医学影像的筛查,提高诊断准确率。仿真中引入COVID-19的X光数据集及CT数据集来验证所提算法及模型的性能;实验表明所提方法能够提升影像诊断的准确率。
2 基于跨层连接机制的多主干网络特征融合卷积模型构建
传统图像特征提取往往采用人工干预的方式,如Sobel、Robert等算子提取边缘特征,LBP算子提取纹理特征等思路[5-6]。该方式通常针对某一属性特征,难以兼顾像素点及区域特征的多模态性,无法表征图像整体特性。而基于卷积神经网络的图像特征提取技术能够自主分析像素联系,无需顾虑图像背景或亮度的变化,体现了自适应性。
2.1 引入跨层连接模型思路
传统卷积网络模型中因网络层间缺乏跨层式信息互通,经多层卷积、池化后信息损失也越来越多,尤其是医学影像中的细小纹理特征易被忽略,影响诊断。本研究借鉴UNet模型[7],在第3层卷积层后进行反卷积(Deconv)操作,并将反卷积特征与第2层的卷积特征相融合,得到跨层连接的融合特征。对于医学图像的分类,涉及较多的是细粒度分类,反卷积通过将各像素点分离,可更好地提取病变部位的细节信息。最后通过Concat操作将大、小尺度特征信息融合,即使较浅层次网络也能达到较好的分类效果。跨层连接模型见图1。

图1 跨层连接模型示意图Fig.1 Schematic diagram of cross-layer connection model
2.2 引入多主干网络组合的特征融合模型
现有卷积网络模型采用主干网络来提取深层特征,其分类器性能在很大程度上取决于主干网络所提取的特征;故通常做法是增加卷积层数目,如ResNet、DenseNet等可训练至上千层[8-9]。但医学图像中数据维度相对较少,过度增加卷积层易导致过拟合现象。由文献[10]知,扩增主干网络并行处理性能可提高分类器的准确率。在此,基于跨层连接机制,引入一种多主干网络并行组合的特征融合分类模型,见图2。
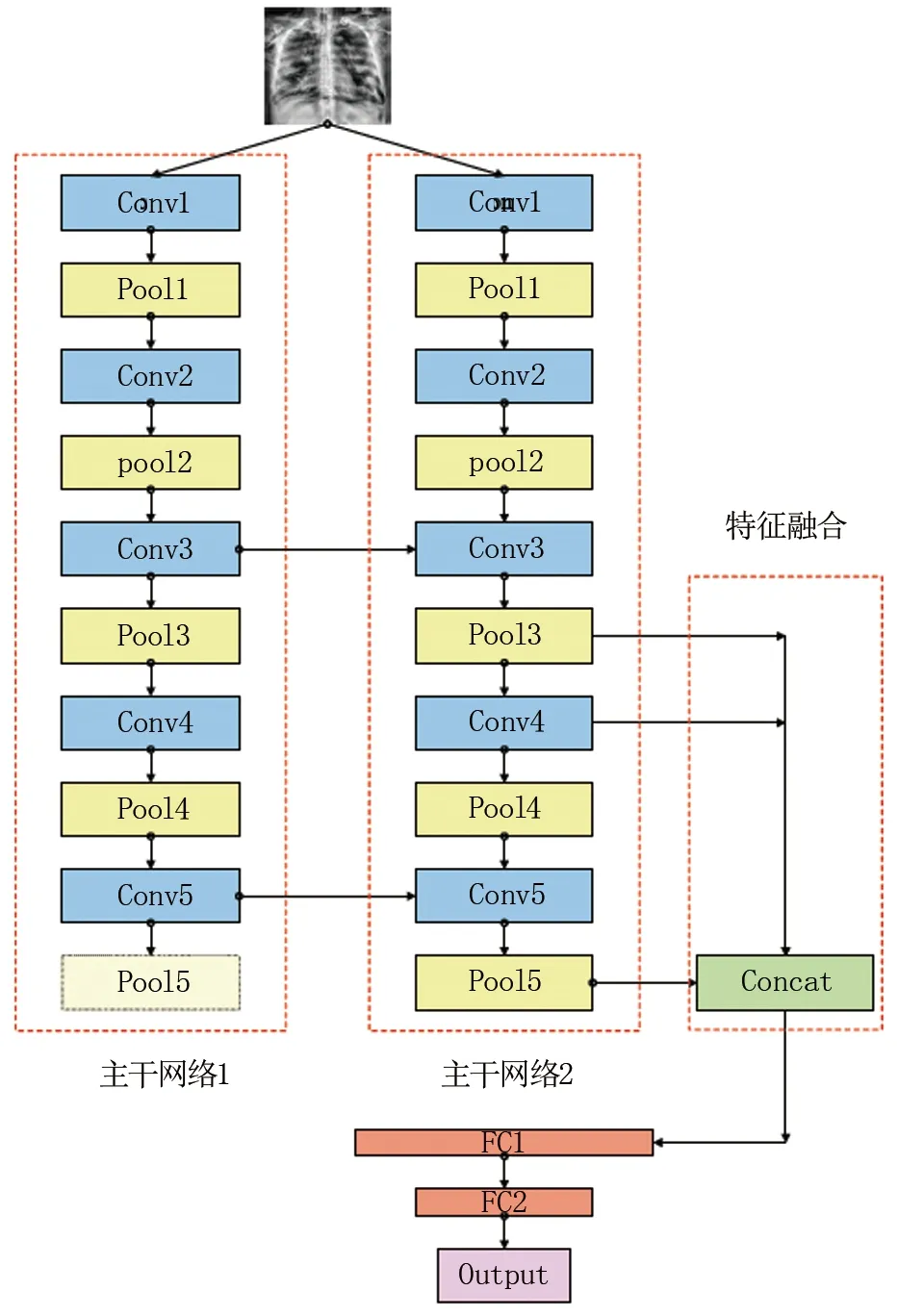
图2 基于跨层连接多主干网络组合的特征融合模型
图2中采用双主干网络,两个网络结构完全相同,将主干网络1的特征图与网络2的对应特征图叠加之后继续传递给网络2,同时将部分深层、浅层特征一起传递给全连接层。若将每一层特征图都进行融合,将导致计算量暴增。因此,为降低计算量,仅对第3、4、5层的池化层特征融合,同时将第3、5层的池化特征一起传递给全连接层,深层、浅层的语义信息互通交流,增强了模型的抽象能力。
3 数据集介绍与预处理
肺炎患者影像早期主要是多发的小斑片状影及间质性改变,多以肺外侧带为主,进而发展成两肺多发的磨玻璃状影以及浸润影[11];由文献[12]知,新型冠状病毒肺炎影像与正常肺部影像的典型区别在于其纹理特征;该特征作为一种全局信息,可用卷积神经网络来深度分析。本研究所用数据集来源分为两部分,见图3,其中COVID-19为新型冠状病毒检测成阳性患者的影像[13],Normal为新型冠状病毒检测成阴性患者的影像[14]。原始图像尺寸大小不一,首先对数据集进行归一化,并调整其尺寸为244×244。
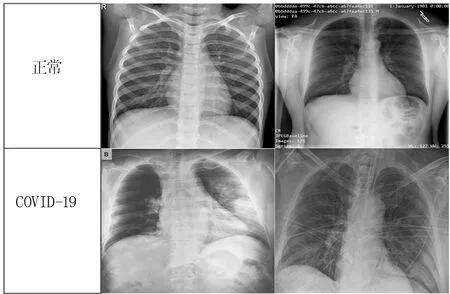
图3 数据集示例Fig.3 The data set sample
另考虑到医学影像成像过程中的机器噪声、组织、脂肪覆盖、脏器重叠导致各类的噪声,以及灰度对比不突出等问题,都可能严重影响后续分类器性能,本研究先采取自适应直方图均衡、高斯滤波等思路对医学图像进行预处理,然后再构建卷积网络进行训练识别。
3.1 自适应直方图均衡化
本研究将图像划分成几个区域分别对其进行直方图均衡化操作,然后再利用线性插值法来减弱各个区域边界处的区块效应,优化均衡化的效果,保留医学图像中更多的细节信息,见图4。
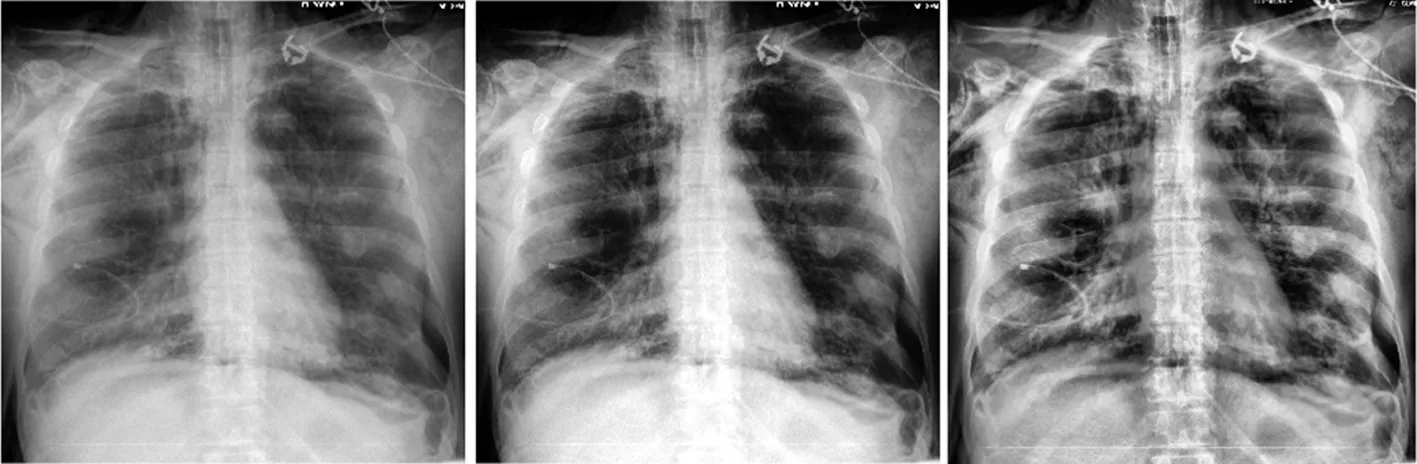
(a)原始图像 (b)直方图均衡化 (c)自适应直方图均衡化图4 图像处理比较示意图Fig.4 Comparison of image processing
3.2 高斯滤波
高斯滤波过程主要是对输入图像计算加权平均,滤波后图像像素值均为原像素值和掩膜内的像素值加权平均所得,滤波后的图像更加平滑柔和,有效避免了振铃效应;同时,滤波后每一像素点的权值随着到中心点的距离单调变化,靠近中心的像素值的权重也更高,可更好地保留图像的边缘信息,且平滑程度随高斯方差参数的变化而变化,通过调节参数可在图像特征过分模糊、过多突变量间取折中,见图5。
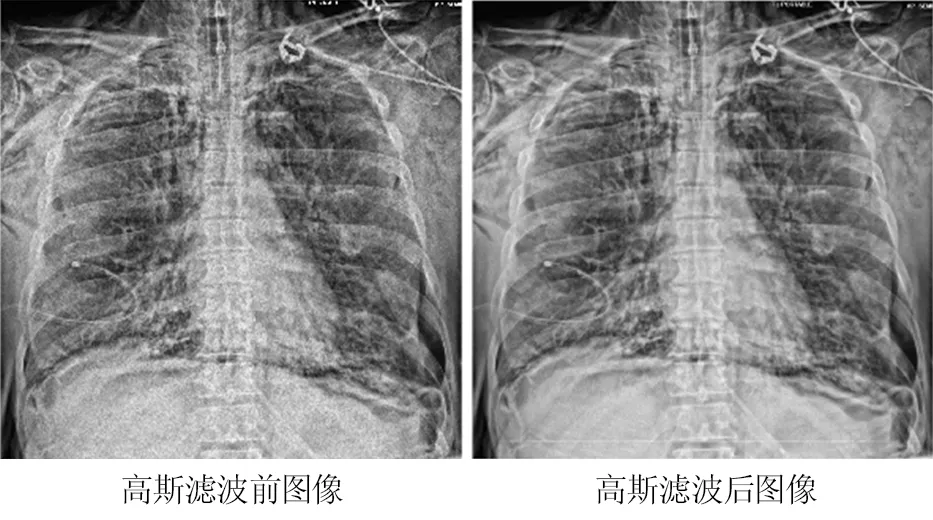
图5 高斯滤波前后图像比较
4 仿真实验与结果分析
本研究在CAFFE深度学习环境进行,使用NVidia GTX 1050ti 4GB进行GPU加速,最大迭代次数(iteration)设置为3000次,基础学习率(base_lr)为0.001,学习率(lr)下降策略为inv,Gamma(γ)为0.0001,power为0.75,学习率下降公式如下:
lr=base_lr·(γ·Iteration+1)-power
(1)
4.1 不同模型的准确率
首先,比较LeNet模型、跨层连接模型、多主干网络以及嵌入跨层连接机制的多主干特征融合网络模型对新冠肺炎影像的识别准确率随训练迭代次数变化,见图6。

图6 不同模型识别准确率Fig.6 The recognition accuracy of different models
由图6可看出,3 000次迭代下4种模型中LeNet识别准确率最低,仅为92.7%;而其他3种模型趋于95%左右,可见跨层连接模型、多主干网络以及嵌入跨层机制的多主干特征融合模型对于肺部特征的抽取能力更好。对比这几种模型发现,跨层连接的多主干网络特征融合模型在较少的迭代次数下达到更高的准确率,迭代次数1 000次左右时,就已达到了95%以上的识别准确率,而单纯的多主干网络、跨层连接模型的识别准确率仅为90%左右,表明前者对于深层和浅层的语义信息利用更加丰富,是一种抽象能力更强的模型。
4.2 不同学习率以及全连接层神经元个数对模型性能的影响
其次,对于所提模型设置不同的全连接神经元个数以及不同的基础学习率进行训练,可观察到相关参数对模型性能影响,见图7—图9。
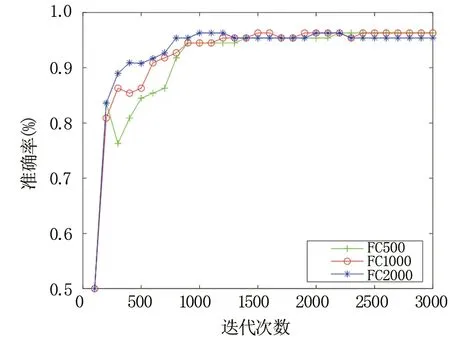
图7 不同全连接层神经元个数对准确率的影响Fig.7 The impact of neurons number in FC layers on the accuracy
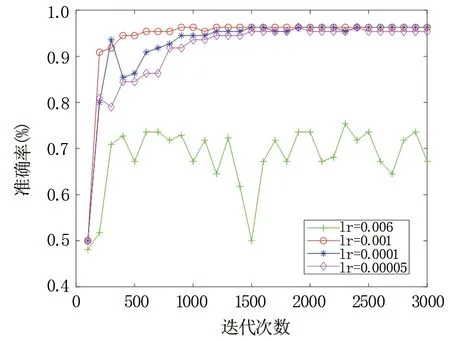
图8 不同基础学习率对准确率的影响Fig.8 The impact of different basic learning rates on the accuracy
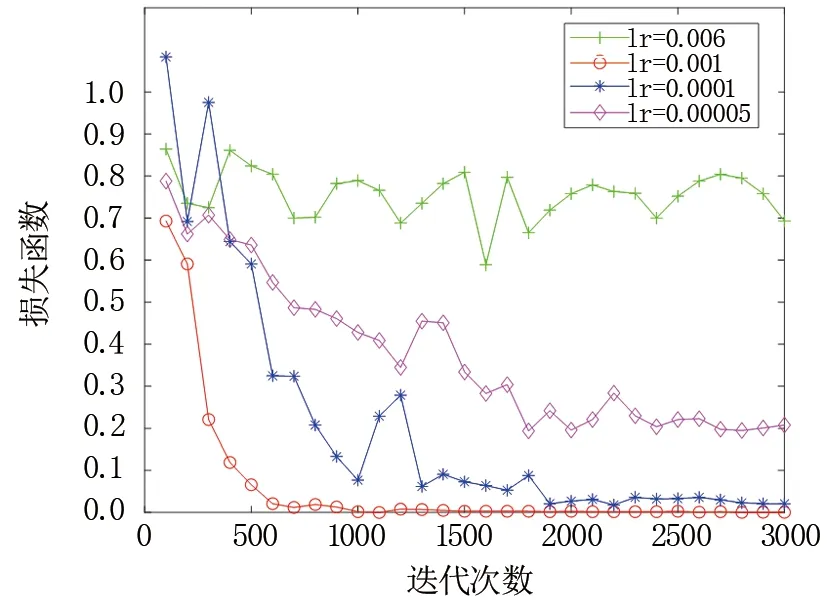
图9 不同基础学习率对损失函数的影响Fig.9 The impact of different basic learning rates on the loss function
图7中观察不同全连接层神经元个数对模型准确率的影响可发现,当神经元个数较少时,在训练开始阶段(500迭代以内)准确率相对较低;而当神经元个数较多时,训练初始阶段准确率略高,但在训练后期相较其他两种较少神经元个数的准确率有所下降。这是因为全连接层的神经元个数增加时,一定程度上可提高网络模型对于复杂函数的拟合性能,但是过多神经元个数也可能导致过拟合现象,因此需设置合适的全连接层神经元个数,或采用Dropout技术来抑制过拟合。
由图8和图9观察不同基础学习率对模型性能的影响可发现,当学习率过高时(lr=0.006),模型准确率没有提升,且损失函数也在震荡,无法收敛;表明过高的学习率无法得到模型最优解。而当学习率过低时(lr=0.00005),模型损失函数收敛速度缓慢,训练时间过长,表明过低学习率难以在短时间内收敛。因此,只有在合适范围内选择相对较高的学习率,在相同迭代次数下可达到更高准确率,且模型可在更短的时间内得到全局最优解。
4.3 模型在其他医学影像数据集中的表现
将跨层机制的多主干网络特征融合模型应用于COVID-19 CT数据集,设置基础学习率为 0.0005,其准确率和损失函数随迭代次数的变化,见图10。
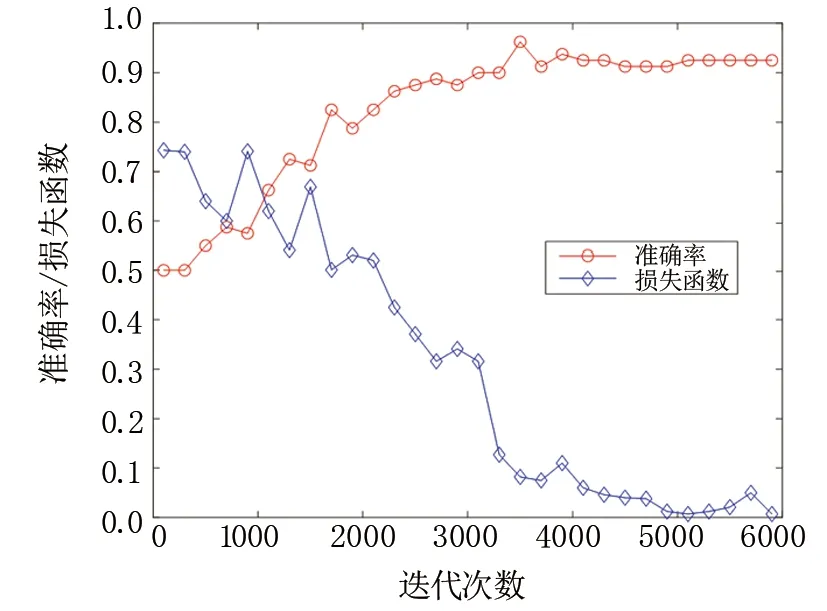
图10 多主干网络组合的特征融合模型在新冠肺炎CT数据集中的表现Fig.10 Performance of multi-backbone network feature fusion model in CT data set
由图10可看出,该模型在COVID-19 CT数据集中也取得了较高识别准确率,达到92.5%,且损失函数在6 000次训练迭代下明显下降,具有较强的稳健性。
综上,本研究所提网络模型利用融合思想将不同隐含层的特征融合为具有多视角层次的特征,在特征融合过程中实现了深浅层特征的互通交流,使得多种局部特征可优势互补,消除了不同特征集间的冗余信息,通过将CNN特征进行高阶综合,该“粗细结合”的方式可更好地把握细粒度特征。另外,本研究采取多主干策略,其分支在开始训练时处于随机初始化状态,使得不同主干的同一层权重也不尽相同,模型自适应性、稳健性大大增强。
5 结论
本研究构建了一种新的基于跨层连接机制的多主干网络特征融合卷积模型,利用多尺度感受野挖掘融合思想来捕获医学图像局部细节,仿真中引入COVID-19 X光数据集及CT数据集来验证所提算法及模型的性能。实验证明,本研究所提模型能够大幅提升医学影像诊断的准确率,对于解决COVID-19疫情背景下的快速、准确、高效诊断具有重大的社会意义。
猜你喜欢
广东教育·高中(2022年1期)2022-03-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
现代装饰(2018年5期)2018-05-26
中华心脏与心律电子杂志(2017年2期)2017-10-20
中国心血管杂志(2016年4期)2016-09-15
中国生化药物杂志(2015年4期)2015-07-07
中国交通信息化(2015年2期)2015-06-05
