
边缘计算系统中基于UCBM算法的缓存预取优化*
2021-04-11 12:46:06郭祖华
河南工学院学报 2021年5期
孙 波,郭祖华
(1.河南工学院 计算机科学与技术学院,河南 新乡 453003;2.河南工学院 教学质量监控与评估中心,河南 新乡 453003)
0 引言
边缘计算是一种使计算机数据存储更接近需要位置的分布式计算模式,它能够在网络边缘端为接近终端用户提供计算、存储资源等服务[1],目前已广泛应用于众多领域,例如实时数据处理、自动驾驶、虚拟现实和智能家居等。随着智能终端设备和云服务的高速发展,网络边缘端会产生海量的数据,如果将所有数据上传至云端,那么从终端设备传输数据到云服务器将会产生长时间的延迟,而某一种单独的云计算模式往往并不能起到良好的效果[2]。
预取技术是一种通过预测将要访问的数据并将其提前读取到缓存中的技术,缓存预取是提高存储系统性能的重要手段,已经被证明是一种扩展边缘计算能力的有效方法,如程小辉[3]等提出了一种基于马尔可夫链的内存预测分配算法,该算法利用内存分配的转移量统计信息及其概率矩阵对嵌入式系统内存动态分配进行预测,减少了内存创建的时间,但该方法在缓存命中率方面存在不足;石星[4]采用深度学习设计了缓存预取算法,以存储块相关研究为基础提出挖掘技术,同时预测数据序列,将顺序预测与数据序列预测有效结合以完成算法设计,但该方法存在精度不高的问题;王朝[5]等提出一种基于博弈论的数据协作缓存策略,首先多区域划分边缘计算环境,然后区域之间相互协作缓存数据资源,对不同区域的缓存价值进行计算与对比,制定缓存策略,该方法整体策略较好,但缓存精度有待提高;CESELLI[6]等为移动接入网络提出了一种全面的移动边缘云网络设计框架,从整体视角研究了雾计算、移动边缘计算和移动云计算的边缘范式,并且分析了这些边缘范式存在的安全威胁、挑战和机制;HU[7]等针对通过WiFi接入点辅助的电视点播内容,提出了一种基于学习的内容预取方法,用以解决边缘网络中服务器负载的时变问题,但存在预取动态性较差、预取命中率低以及带宽利用率不足等问题;WANG[8]等研究了移动网络中的缓存相关技术,并且提出了一种基于以内容为中心网络或者以信息为中心网络概念的新的边缘缓存策略,但对于研究数据的覆盖不够全面。
针对终端用户希望加速数据访问和减少用户感知延时的相关请求,本文提出一种在边缘计算环境中基于贝叶斯网络和马尔可夫链的用户分类(User Classification based on Bayesian network and Markov chain,UCBM)算法的缓存预取优化策略,该策略可以提前将所需文件置于边缘服务器缓存中,并能提高预取的精确率、覆盖率,从而有效地降低时延,加速终端用户访问[9-12]。
1 基于UCBM的边缘计算系统模型
在基于UCBM的边缘计算系统模型中,预取技术的主要任务是来预测用户的访问对象。在这种模型中,通过贝叶斯网络和马尔可夫链对用户的下一步访问对象进行分类与预测。
1.1 用户访问假设
在预测模型中,用户的访问行为被看作一项任务,依据其访问的特征,执行访问一系列相关文件的任务。设计两个用户访问假设如下:
假设1:依据不同用户在请求访问文件时的不同情况,用户可以分为K个类别,集合U={u1,u1…uk}用来表示一类用户。然后,P=(U=uk)是具体用户属于分类uk的概率。根据以上内容,公式1可以定义为:
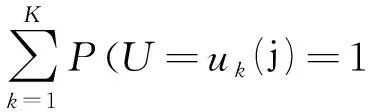
(1)
假设2:相同类型用户的浏览进程将会以不同的方式显示相同或相似的特征,并且他们的浏览过程是一种随机过程,可以描述为一种同构离散的马尔可夫链。
基于以上两种假设,研究者建立了贝叶斯网络用来对用户浏览行为进行预测,并构建了马尔可夫链模型用来通过用户分类进行文件缓存预取。
1.2 基于马尔可夫链模型的用户分类
基于马尔可夫链模型的用户分类可以用一个五元组表示:
(2)
假设(x1,x2,…,xl)是用户访问序列,用来预测用户的下一个状态,包括用户分类判断和任务预测。在判断用户类别时,依据贝叶斯理论,确定用户是否属于某一类别的概率表示为:
(3)
其中P(x1,x2…,xl)是对于任意用户浏览序列的概率,这个概率定义为:
(4)
其中P(x1,x2…,xl|U=uk)代表在用户分类uk浏览序列中的发生概率:
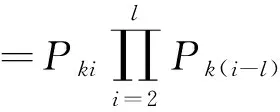
(5)

为了实现任务预测,可以对用户进行分类之后,通过马尔可夫链描述用户的浏览特征。同时,为了提高模型的预测精度,研究者在模型中引入用户在请求访问过程中的历史信息,并利用多阶加权组合进行预测:
V(t)=w1H(t-1)×A1+w2H(t-1)×A2…+whH(t-1)×Ah
(6)
然后引入一个新的变量Ah来表示马尔可夫链的h阶转换矩阵,wi是权值,并且满足等式w1+w2…+wh=1。设置阈值γ,如果V(t)≥γ,将这个任务视为主要任务,由此完成用户分类。
1.3 缓存预取过程设计
用户分类完成后,通过用户请求,系统在完成一个访问任务后再继续执行下一个任务,该过程中产生的变量称为任务的转移概率Ak。当前的访问任务是tv(t),系统会将拥有最高转移概率的任务作为预取任务。然后将预测任务的相应文件预取至缓存,从而减少重复请求延迟,提高系统访问效率。因此研究者设计了根据用户任务预测提前将所需文件进行缓存的方式,从而提高预取效率,实现缓存预取。具体缓存预取过程如下。
首先,通过分析字节网络,计算具体用户浏览序列的发生可能性,然后将预取文件加入缓存中。如果没有足够的缓存空间,一些文件将通过替换策略被移除出去。缓存预取的过程如图1所示。

图1 缓存预取过程图
在缓存得到所需文件后,若长时间不发生预取行为则需要进行替换。具体执行过程为:在被替换之前,如果预取文件在时间间隔Tphc之间从没有被访问,预取命中率的效率将会降低。通过分析,新的预取文件将替换之前在时间间隔Tphc从来未被访问的预取文件。为了优化缓存过程,研究者设置了以下规则:
将一个计数器分配给一个文件。计数器的值counte是一个变量,用来记录缓存命中数量,并且设初始值为零。如果文件预取命中缓存,这个文件的counte加1。CreateTime是预取文件的创建时间,AccessTime是访问预取文件的最近时间,ReplaceTime是缓存替换执行的时间。
如果预取文件可以处理用户请求,文件预取将会命中缓存。此时这个预取文件的counte是1,这个预取文件的CreateTime是当前时间,并且这个预取文件的AccessTime为空。当缓存空间不足,有两种可能:如果AccessTime-Createtime 在历史执行任务基础上,任务预测算法预测出下一个将执行的任务。然后找到任务要访问的所有文件。对于每一个文件,本算法计算出缓存的成本-利润和垃圾收集成本,选择拥有更高缓存利益和更低垃圾回收成本的文件作为预取文件。 本文所用的UCBM算法是通过伪代码来描述任务预测和文件过滤的。首先,在历史执行任务的基础上,通过UCBM算法预测下一个将要执行的任务,然后找出任务要访问的所有文件(算法的第2—3行)。对于每个文件,计算缓存成本-收益和垃圾收集成本(算法的第5—6行)。选择缓存收益高、垃圾回收成本低的文件作为预取文件(算法的第7—9行)。算法要避免驱逐从未被使用过的预取文件并满足某些特定条件(算法的第12—27行)。UCBM算法的伪代码具体描述如下: Input: 历史任务集:Z={z1,z2,…,zn}. Output:预取文件:f={f1,f2,…,fm},FileContent.∥FileContent包括count,Createtime和AccessTime 1 1.初始化历史任务集 {z1,z2,…,zn} 2zc←通过UC模型预测下一个要执行的任务 3F←通过UCBM算法预测下一个执行任务zc对应的候选预取文件 4count=0 5foreachf'∈Fdoes 6CPf′=Pr*(tloc+tread) ∥f'的缓存成本-收益 9f←f'∥f'是选择的预取文件 10endif 11endfor 12foreachf”∈Fdoes 13if(f″isincachefile)then∥f″是用户访问文件 14f″.count=1 15f″.CreateTime=now 16f″.AccessTime=null 17else 18f″.count++ 19f″.CreateTime=null 20 21endif 22endfor 23if(缓存空间不足)then 24foreach(f″是预取文件) 25if(f″.AccessTime-f”.CreateTime≥T)then 26 基于替换策略来替换f” 27endif 28endfor 29if(f″.AccessTime-f″.CreateTime 30f″←cache.find Min Countmax Access Time( ) 31f″ 32endif 33endif 在整个算法执行过程中,边缘服务器先要对数据进行预处理操作,即通过UCBM算法对接入用户进行分类,确定预取文件,然后再计算每个候选预取文件的缓存成本-收益和垃圾收集成本。如果预取的文件在内存缓存中,用户的需求将得到响应;否则,预取的文件将从云端缓存到边缘服务器,暂时不响应用户需求。 本实验通过构建校园网中的边缘计算系统来验证缓存预取的优化策略的有效性。整个系统包含一个作为主节点的边缘协调器(EO),负责边缘服务器管理和计算服务协调;多个作为仆从节点的边缘服务器(ESs),拥有计算/存储资源并且提供边缘计算服务。 边缘协调器的配置为Intel(R) Core W(TM) i7-9700K@3.60GHz CPU和32GB RAM。每一个边缘服务器的配置为Intel(R) Core (TM) i5-9600KF@3.7GHz CPU和8GB RAM。终端用户通过邻近部署的边缘服务器请求服务。研究者部署Apache Hadoop3.2.1作为边缘计算系统的基础系统,每个节点都有Java JDK11.0.5运行在Ubuntu14.04.1 LTS之上,基本开发环境设置为Linux Eclipse 4.5.0。 实验使用工作负载合成工具Hibench生成五组工作负载套件(Bin1—Bin5),它们作为终端用户提交到边缘计算服务器的计算任务数据。表1描述了这五组工作负载套件的特点。 表1 工作负载套件特征值 这些工作负载套件中的精确率、覆盖率指标可以验证基于UCBM算法的缓存预取的性能。 本文提出的评估测度策略可以分析算法的预测性能。该策略的评估指标包括精确率、覆盖率。 3.3.1 预取精确率 精确率是指正确被缓存预取的文件集合与实际缓存预取的文件集合的比值,定义为Accuracy=R-LS/LS。 3.3.2 覆盖率 覆盖率是指用户访问的文件集合与预测系统文件的比值,可定义为coverage=R-LS/RS。 研究者在评估基于预测的缓存预取算法时使用了上述的五组工作负载套件,这些工作负载套件由Hibench同步。为了展示本文算法的相关性能,实验分别与文献[4]所使用的——结合“最近使用流行度”替换策略的基于马尔可夫链的缓存命中率算法和文献[5]所使用的——基于深度学习的预取算法进行了测试对比。 3.5.1 预取精确率 图2和图3分别显示了训练数据集文件大小和文件数量对精确率的影响。如图2所示,横坐标为Filesize to cache size(缓存文件大小)、纵坐标为Prefetching Accuracy Rate(预取精确率)。随着文件的增大,精确率下降。因为缓存空间有限,访问文件越大,预测系统文件中可容纳的访问文件数越小,因此系统精确率越低。本文算法比文献[4]和文献[5]算法有更好的精确率,平均精确率分别提高48.3%和13.95%。 如图3所示,横坐标为File size to cache(缓存文件大小)、纵坐标为Prefetching Accuracy Rate(预取精确率)。随着训练数据集中文件数量的增加,不同算法的精确率均得到提升,并且当文件数量达到一定值时趋于稳定。这是因为训练数据集中包含的文件越多,可以从缓存中获取的文件就越多,因此精确率也就越高。从图中可以明显看出,本文算法的最低精确率为0.66,最高精确率为0.78,而其他两种算法的最高精确率均不超过0.7,明显低于本文算法。因此,本文算法的性能明显优于文献中的两种算法。 图2 文件大小对预取精确率的影响 图3 文件数量对预取精确率的影响 3.5.2 覆盖率 图4和图5分别显示了文件大小和文件数量对覆盖率的影响。如图4所示,横坐标为File Size to Cache(缓存文件大小)、纵坐标为Coverage Rate(覆盖率)。当文件增大,覆盖率下降。因为缓存空间有限,访问文件越大,在预测系统文件中可以提供的访问文件数量越少,因此系统精确率越低。对比文献[4]和文献[5]的算法,本文算法拥有更好的覆盖率,最低覆盖率为0.52,而其他两种算法的最低覆盖率为0.4和0.3。这是因为在文件预取之前,本文算法通过预测和扫描已经过滤掉了一些不必要的文件,只有下一次执行任务并且满足预定义预取条件的文件才能预取到缓存中,因此占用的内存最少。 如图5所示,横坐标为The Number of Files(文件数量)、纵坐标为Coverage Rate(覆盖率)。随着文件数量的增加,覆盖率增加。这是因为随着任务的执行,系统中被加入缓存的访问文件会越来越多。但是本文算法在预测系统文件集合中能够提供更多的访问文件,通过UCBM预测和预取条件的过滤,避免了不必要的文件预取,因此最高覆盖率达到0.73,具有明显的优势。 图4 文件大小对覆盖率的影响 图5 文件数量对覆盖率的影响 针对从终端设备传输数据到云服务器将会产生长时间延迟的问题,本文提出了一种基于贝叶斯网络和马尔可夫链算法的缓存预取优化策略。在该策略中,预取文件通过马尔可夫链的预测来确定下一个要执行的任务。然后对于缓存效益更高的和垃圾收集成本更低的文件,实施进一步过滤,并确定进行缓存的边缘服务器,如果缓存空间不足,会进行缓存替换。在边缘计算系统中对算法的性能进行了评价。实验结果表明,与已有算法相比,本文算法有效地提高了预取精确率和覆盖率,最高精确率为0.78,最高覆盖率达到了0.73,具有明显的优势。 由于本文所提出的策略是基于响应式方法,这对于分布式决策是适用的,但对于集中式缓存决策适用性不高。未来将改进替换策略,对缓存预取做进一步的优化。2 UCBM算法描述

3 实验过程及结果分析
3.1 实验环境
3.2 数据来源

3.3 评价指标
3.4 进行过程
3.5 结果分析


4 结论
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16今日农业(2021年21期)2021-11-26 05:07:00通信产业报(2016年44期)2017-03-13 08:41:45数学理论与应用(2016年3期)2016-05-17 04:50:14西南交通大学学报(2016年6期)2016-05-04 04:13:05核科学与工程(2015年3期)2015-09-26 11:58:25哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:33电视技术(2014年19期)2014-03-11 15:38:07计算机工程(2014年6期)2014-02-28 01:28:03雕塑(1999年2期)1999-06-28 05:01:42
