
基于枢轴语言的汉越神经机器翻译伪平行语料生成*
2021-04-06 10:48:28贾承勋余正涛文永华于志强
计算机工程与科学 2021年3期
贾承勋,赖 华,余正涛,文永华,于志强
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
神经机器翻译NMT(Neural Machine Translation)是目前机器翻译领域的热点研究方法,相较于统计机器翻译SMT(Statistical Machine Translation)[1],神经机器翻译在大量的平行句对上取得了更好的翻译效果[2,3],但是神经机器翻译在平行语料匮乏的低资源环境下,效果并不理想[4]。为缓解语料缺乏困境,早期研究者们利用人工标注方式扩充语料,然而人工标注具有周期长、成本高的缺点,因此研究者们开始关注语料的自动扩充方法[5]。汉语-越南语是典型的低资源语言对,汉越神经机器翻译同样面临数据稀缺问题[6],这一问题严重影响神经机器翻译在实际中的应用,因此如何通过语料扩充手段改善汉越神经机器翻译的性能是值得研究的问题。
目前通过生成伪平行数据缓解数据稀疏问题,是低资源神经机器翻译的一个重要研究方向[7]。对于伪平行数据扩充的研究,目前主要有2种方式:抽取式和生成式。抽取式是根据一定规则从可比语料、枢轴语料或者2种语言的单语语料中抽取伪平行语料[8 - 11];生成式是在已有小规模平行语料的前提下,通过词的替换、单语数据回译[12]和建立枢轴模型等方法,生成更多的伪平行数据[12 - 14]。
目前基于生成式的伪平行数据扩充方法的有效性已经得到了充分验证,但缺少对这些方法融合利用方面的研究。
因此,本文针对汉越神经机器翻译任务,对基于词的替换、单语数据回译和基于枢轴语言3种生成式方法的融合利用进行研究。在基于枢轴语言方法的基础上,将词替换和回译2种方法融合进来,在枢轴方法生成伪平行数据的过程中,生成质量更优的汉越伪平行数据,然后利用语言模型对生成的伪平行数据进行筛选,优化伪平行数据的质量。实验表明,本文方法相比单一的生成式方法性能有明显提高。
2 相关工作
近年来,国内外相关研究人员针对小规模平行语料进行伪平行语料生成的方法进行了广泛研究,并取得了一系列成果。目前在神经机器翻译中能有效生成伪平行数据的方法主要有3种。
第1种是基于词的替换方法。Fadaee等人[15]利用基于词替换的翻译数据增强技术TDA(Translation Data Augmentation),通过将平行句对中的高频词替换为平行句对中的低频词,从而得到新的伪平行句对,但是当出现一词多译的情况时效果不佳,且易出现噪声;蔡子龙等人[16]首先对句子进行分块,找出句子中的最小翻译单元MTU(Minimum Translation Unit),然后找到句子中最相似的2个模块,通过对调他们的位置生成新的伪平行句对,但是容易产生语法语义上的错误,使伪平行数据质量不佳。
第2种是利用单语数据进行回译的方法。Sennrich等人[12]利用现有的神经机器翻译模型提出了回译方法(Back-Translation),通过利用已有的小规模平行句对训练2个不同翻译方向的神经机器翻译模型,将目标端单语数据翻译成源语言,从而构成伪平行数据。此方法有效提高了翻译性能,但是严重依赖于小规模平行句对的质量,并且不能解决零资源语言的数据稀疏问题。
第3种是利用枢轴语言连接源语言和目标语言的方法[17,18],使用源-枢轴模型将源语言翻译成枢轴语言,然后使用枢轴目标模型将枢轴语言翻译成目标语言,具体流程如图1所示。Johnson等人[5]对基于枢轴的神经机器翻译方法进行了改进,并表明基于枢轴的神经机器翻译的翻译性能比无需增量训练的通用模型更好,该方法有效解决了零资源或只有小规模平行语料语言的数据稀疏问题。李强等人[19]在统计机器翻译上将枢轴方法分为系统级、语料级和短语级3种方法,通过扩大生成训练数据的规模以及优化词对齐质量的方式来提高翻译性能。Wu等人[20]通过对双语数据中的单语语料进行翻译的方法直接优化最终的翻译性能,即语料级的枢轴方法中,翻译模型中所有参数的调优直接通过优化汉语至低资源语言的翻译来完成,翻译过程如图2所示。
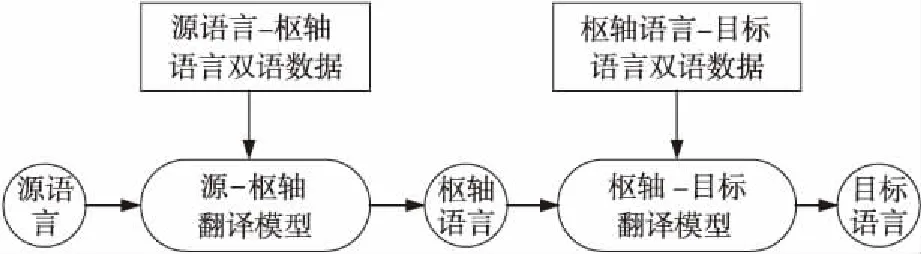
Figure 1 Flowchart of traditional pivot language method
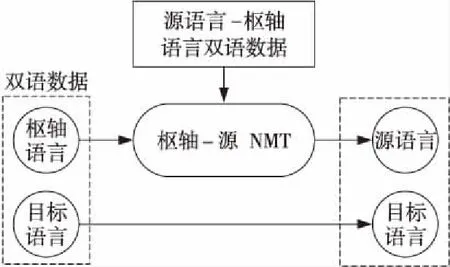
Figure 2 Flowchart of corpus-level approach to pivot translation
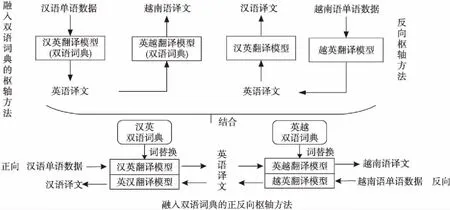
Figure 3 Flowchart of the method for generating pseudo-parallel data
在生成伪平行语料的方法中,使用枢轴语言连接源语言和目标语言是一个重要方向,由于其简单有效,在传统的统计机器翻译中也被广泛使用[18]。在神经机器翻译中,基于枢轴语言的方法已经普遍用于伪平行数据的生成,但这种基于枢轴的方法通常需要将解码过程分成2个步骤,第一个模型中出现翻译错误,会直接影响到下一个模型的训练效果,从而增加数据的模糊性。
目前3种生成式方法都有各自的优势和不足,目前还没有将这些方法进行融合的研究,因此本文在将生成式方法相结合的基础上,提出了融入双语词典的正反向枢轴方法。首先,针对基于枢轴的方法存在许多无法有效翻译的词和短语,会使翻译错误连续传递,影响生成的伪平行数据的质量,同时无法在所有的翻译任务上都获得最优的翻译性能的问题,本文对源语言单语数据进行一次正向的枢轴语言翻译生成伪平行数据后,再对目标语言的单语数据进行一次反向的传统枢轴语言方法的翻译过程,以此实现枢轴语言方法和回译方法的结合;其次,在上述改进的基础上,通过构建双语词典[21]进行稀有词的替换,将双语词典输入到源-枢轴和枢轴-目标的神经机器翻译模型中训练,将枢轴方法、回译和词替换3种方法结合并生成更多的伪平行数据;最后将生成的伪平行数据通过语言模型进行筛选,将筛选后的伪平行数据与原始数据混合进行模型训练。
3 汉越伪平行数据生成方法
目前在神经机器翻译的枢轴语言方法中,并没有在词级上对枢轴方法进行分析,针对其存在的问题,本文结合了词替换的思想,在枢轴方法的基础上融入利用稀有词构建的双语词典,减小了词和短语翻译错误的几率,从而缓解错误传播的问题;针对零资源语言的数据稀疏问题,将枢轴方法与回译方法相结合,进行一次反向的枢轴翻译过程,即按照目标→枢轴→源的方向再次对数据进行扩充;融入双语词典的正反向枢轴方法是一种将词替换方法、回译方法和枢轴语言方法结合利用的方法。枢轴语言的选择对基于枢轴语言的方法有着至关重要的影响,需要选择同时与源语言和目标语言都具有大量可利用数据资源的语言作为枢轴语言。本文源语言为汉语,目标语言为越南语,由于汉英、英越机器翻译可以获得大规模高质量的平行语料,因此以英语作为枢轴语言对汉越伪平行语料生成方法展开研究。
图3中汉英翻译模型和英汉翻译模型为利用同一训练数据训练的神经机器翻译模型,同理英越和越英翻译模型。本文结合了词替换的思想,在枢轴方法的基础上融入了利用稀有词构建的双语词典,减小了词和短语翻译错误的几率,从而缓解错误传递问题;针对零资源语言数据稀疏问题,在枢轴方法的基础上与回译方法相结合,在正向枢轴翻译后再利用额外的越南语数据进行反向的枢轴翻译,即按照目标→枢轴→源的方向再次对数据进行扩充;而在此方法基础上将双语词典结合进来,在翻译数据的过程中进行稀有词的替换,这便是本文提出的融入双语词典的正反向枢轴方法。
3.1 融入双语词典的枢轴方法
本文利用稀有词,即常规词表以外的词来构建双语词典。使用GIZA++工具对语料进行对齐处理得到对齐结果,排除常规词表内的词来构建双语词典,对于一词多译的情况,只保留对齐概率最大的词。本文使用Li等人[22]的方法在模型翻译过程中融入双语词典进行词的替换。
在传统的枢轴语言方法中采取2种不同的方式结合双语词典,第1种是利用现有数据构建出源到枢轴的双语词典SP(Source to Pivot)和枢轴到目标语言的双语词典PT(Pivot to Target),将2个双语词典直接融入到相应的模型中;第2种是在第1种方法的基础上,将2个双语词典相结合,将其中英语部分相同的词保留,对不包含在原词典的英语词进行人工整理。例如,“Monday”这个词既存在词典SP中又存在于词典PT中,则保留,而“Jesus”这个词只存在于词典PT中,则将其人工添加到词典SP中,如图4所示。整合后得到的双语词典命名为SPT(Source to Pivot add Target)和PTS(Pivot to Target add Source),然后将其融入到相应的模型中。
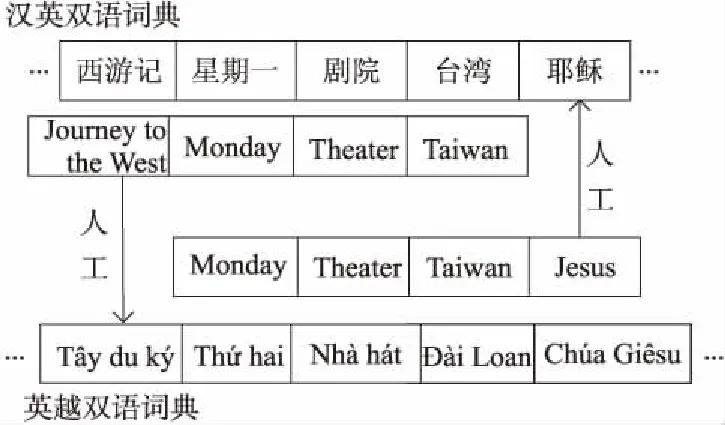
Figure 4 Building integrated bilingual dictionary
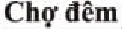
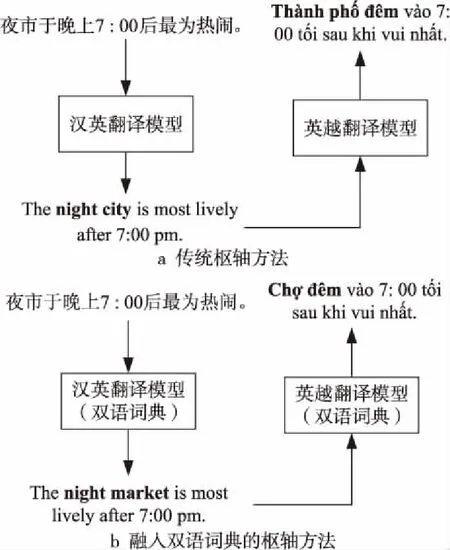
Figure 5 Comparison of traditional pivot language method and integrated bilingual dictionary pivot method
3.2 反向枢轴方法
在对生成伪平行数据的方法进行结合时,为了进一步提升生成数据的数量,本文将结合回译的思想。在执行原枢轴方向的基础上,直接进行目标到源语言的回译会受到2种语言之间数据稀缺性和形态差异的影响,因此也可以将这个过程分为2个简单的步骤。原枢轴方向为源→枢轴→目标,进行回译的反向枢轴即为目标→枢轴→源方向,如图6所示。
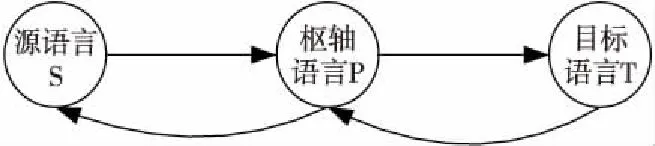
Figure 6 Combination of pivot and back-translation
首先将目标语言单语数据翻译为枢轴语言,然后再将其翻译为源语言,形成伪平行数据,最后与正向枢轴生成的伪数据混合。此方法的优点是可以直接建模,并且不需修改模型框架及参数,存在大量的目标语言T到枢轴语言P的双语数据集,可以利用目标语言单语数据生成更多的伪平行数据。图7为利用越南语句子反向枢轴生成伪平行句子的流程示例。
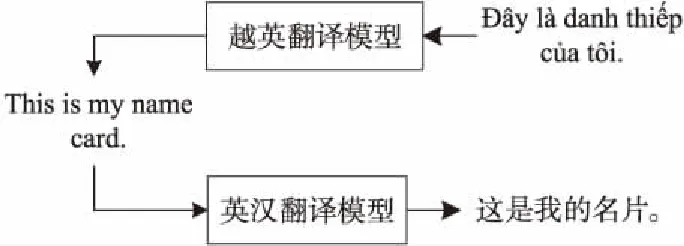
Figure 7 Example of reverse pivot process
利用越英翻译模型将越南语单语数据翻译成英语,然后通过英汉翻译模型将其翻译成汉语数据,以此反向枢轴生成伪平行数据,并与正向枢轴方法生成的伪平行数据一起与原始数据混合进行模型训练。
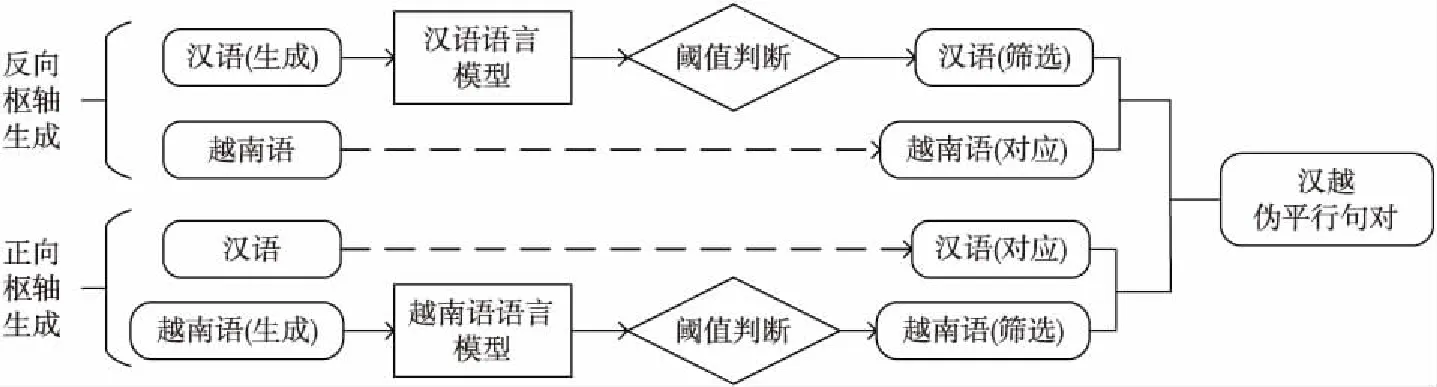
Figure 8 Filtering pseudo-parallel sentences by language model
3.3 融入双语词典的正反向枢轴方法
对于词替换、回译和枢轴3种方法的结合,是在枢轴方法融入双语词典的基础上,执行反向枢轴的翻译过程,与单纯的反向枢轴方法不同的是,此次结合在反向枢轴的过程中融入了双语词典,可以较好地利用源语言和目标语言单语数据,同时可以有效地减少两步翻译的错误传递,提升反向枢轴生成的伪平行数据的质量,以此生成更多质量较高的伪数据,与正向枢轴翻译生成的数据混合,然后进行模型训练。
本文方法的整体流程如图3所示,将双语词典分别融入到对应的模型中,然后将汉语单语数据通过汉英翻译模型翻译为英语译文,再通过英越翻译模型翻译为越南语译文,以此正向枢轴方法生成伪平行数据;其次将越南语单语数据通过越英翻译模型翻译为英语译文,再通过英汉翻译模型翻译为汉语译文,以此反向枢轴生成伪平行数据。最后将生成的伪平行数据与原始数据混合训练汉越神经机器翻译模型。
3.4 基于语言模型的伪平行数据筛选
通过融入双语词典的正反向枢轴方法可以生成新的伪平行数据,但在低资源环境中很难有效地训练良好的回译模型,并且引入枢轴方法可能会产生部分语义问题,难免会增加数据的噪声,噪声的存在可能会降低源语言-目标低资源语言的翻译性能。为改善这一问题,本文利用语言模型对生成的伪平行数据进行筛选。由于循环神经网络RNN(Recurrent Neural Network)可以将每个词映射到一个紧凑的连续向量空间,该空间使用相对小的参数集合并使用循环连接来建模长距离上下文依赖,因此本文选用循环神经网络语言模型RNNLM(Recurrent Neural Network Language Model)[23]进行伪平行数据的筛选,具体流程如图8所示。
首先利用大量汉语和越南语分别训练汉语语言模型和越南语语言模型,通过训练的语言模型对翻译生成的句子进行打分,利用预先训练的汉语语言模型对反向枢轴生成的伪平行句对中的汉语句子进行打分,利用训练的越南语语言模型对正向枢轴方法生成的伪平行句对中的越南语句子进行打分,通过设置一个合理的阈值,将评分低于此值的句子删除,以此实现伪平行数据的筛选,从而可以减少训练模型的计算次数,同时降低时间复杂度。用筛选后得到的伪平行数据与原始数据一起训练最终的汉越神经机器翻译模型。
4 实验及结果分析
4.1 实验设置
实验中传统枢轴方法和语料级方法中使用的汉英双语数据均来自WMT2017(Workshop on Machine Translation 2017),使用的英越双语数据同样来自WMT2017,生成汉越伪平行数据使用的汉语单语数据来自TED2013(Technology Entertainment Design 2013)中汉语数据的前10万句,反向枢轴中使用的越南语单语数据来自Wikipedia。实验枢轴语言均为英语,其中各个实验步骤的数据如表1所示。
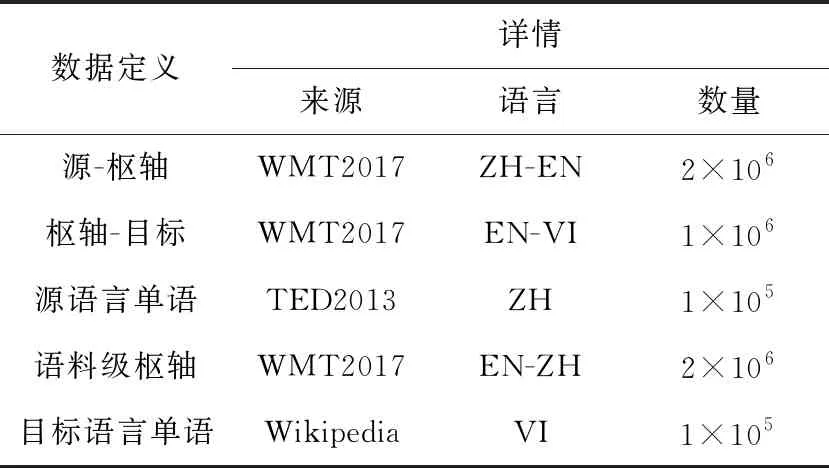
Table 1 Experimental data
通过网络爬虫获取汉越数据,在进行实验之前对语料做了清洗和Tokenizaiton处理,除去空行并过滤长度大于50的句子,最终获得183 000个汉越双语平行句对。使用结巴分词工具对汉语数据进行分词处理,从原始双语数据中分别随机抽取1 500个平行句对作为实验的验证集和测试集。并将与伪平行数据一起训练翻译模型的原始数据分为10万和18万分别进行实验,采用原始数据直接训练的回译方法、词典替换方法和传统枢轴方法作为基准实验(baseline),其中词表大小设置为30 000,为防止出现过拟合现象,在多次实验调整后将迭代损失值设置为0.1,批大小为128,隐藏单元大小为512,轮次为20,训练步长为2×105,使用BLEU4作为评测指标。
4.2 实验结果
实验均利用Transformer模型架构进行本文所有翻译模型的训练。传统的枢轴方法利用汉英200万平行语料和英越100万平行语料训练模型,回译和词典替换方法则使用10万原始汉越双语语料进行训练。为了验证生成的伪平行数据的有效性,利用语言模型对生成的伪平行数据进行筛选,然后与原始数据混合打乱一起训练最终的汉越神经机器翻译模型,为了测试与不同语料规模的数据混合生成的伪平行数据的有效性,还设置了在18万规模的数据集中添加伪平行数据的对比实验。为了保证实验结果的可靠性,每组的实验结果的BLEU值都是利用相同测试集进行实验得到的,实验结果如表2所示。
实验结果可分为2个部分,第1~5行是基准实验,第6~9行是利用语言模型对本文方法生成的伪平行数据进行筛选后与不同规模的平行双语数据进行混合训练的实验结果,是对汉越神经机器翻译性能提升效果的验证。由实验结果可知,利用融入双语词典并结合回译的枢轴方法生成的伪平行数据进行训练,提升效果最好,经过语言模型筛选后,性能获得了进一步提升。第6行为融入双语词典的枢轴方法,在10万的数据集上比传统枢轴方法的BLEU值高0.33,相比直接训练的模型提高了0.61,在18万的数据集上相比直接训练的模型的BLEU值提高了0.48;第7行为融入了整合后双语词典的枢轴方法,效果比传统枢轴方法的BLEU值提高了0.43,并且在10万和18万的数据集上的对比都具有较好的改进效果;第8行为反向枢轴的方法,同样具有较好的改进效果,但由于反向枢轴生成的伪平行数据质量不佳,因此提升效果相对于单回译方法略低一点;第9行为融入双语词典的正反向枢轴方法,使用的汉语和越南语单语数据均为10万,相比传统枢轴方法的BLEU值提升了0.64,在18万的数据集上依然可以取得较好的提升,相对于直接训练BLEU值提升了0.89,取得了最好的翻译效果。
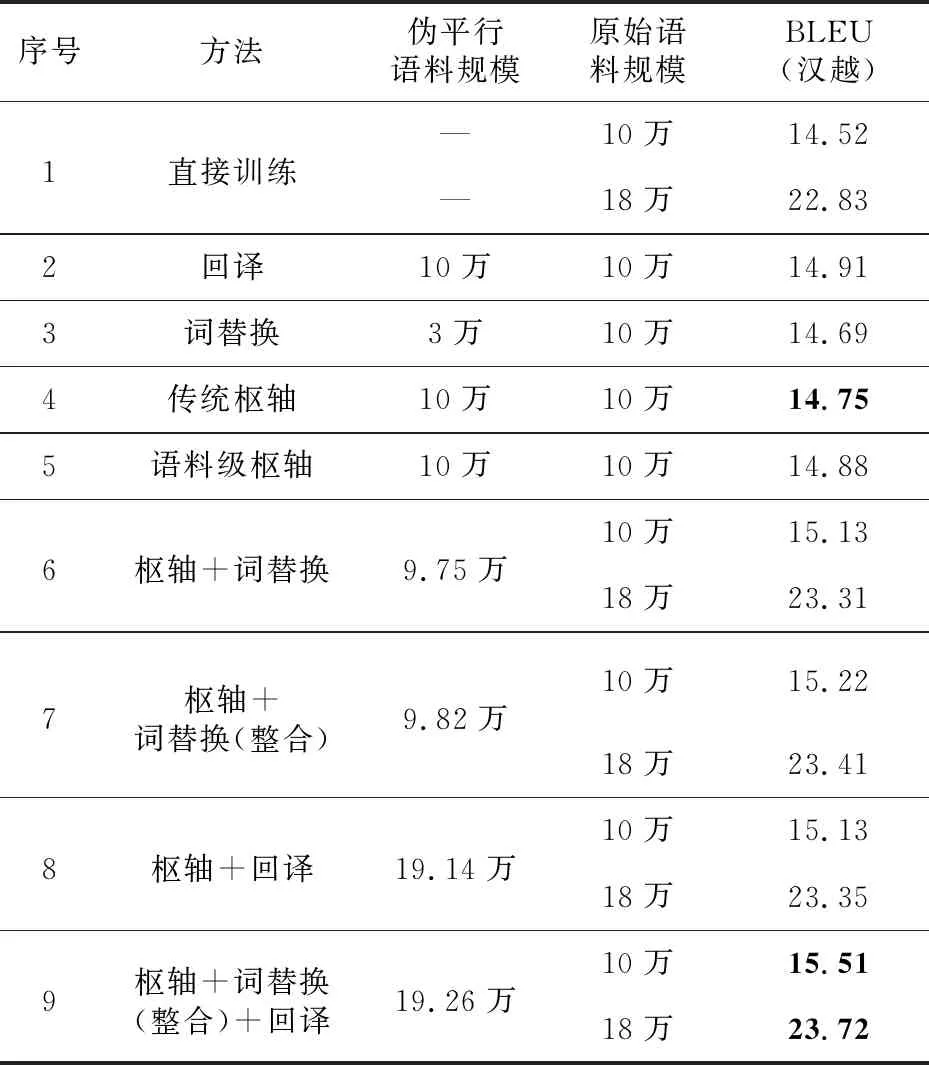
Table 2 Experimental results comparison between the generative methods and proposed method
4.3 实验对比分析
由实验结果可知,在枢轴语言方法中融入双语词典后翻译性能总体都有所提升,将双语词典进行整合后融入枢轴翻译方法中,可以进一步提升汉越神经机器翻译模型的性能。翻译性能与训练数据的数量、质量以及语言本身的差异性息息相关,为了更好地分析本文方法生成的伪平行数据提升翻译性能的原因,本文对生成的伪平行数据进行了分析评估。
4.3.1 困惑度分析
为了检验生成的伪平行数据的可用性,利用循环神经网络语言模型RNNLM和生成的伪平行数据训练语言模型,通过测试其困惑度PPL(PerPLexity),对生成句对的流利性进行评估,检测伪平行数据的质量。此实验中训练语言模型的数据均为生成的汉越伪平行数据,结果如表3所示。
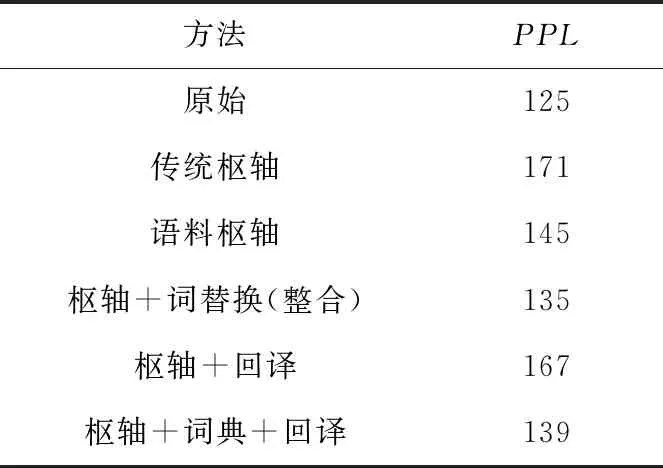
Table 3 Evaluation results of Chinese-Vietnamese pseudo-parallel data perplexity
实验中均使用同一测试集进行评价,其句子都是正常的句子,给测试集中的句子赋予较高正确概率值的语言模型较好,当语言模型训练完之后,训练好的语言模型在测试集上的正确概率越高越好。语言模型困惑度的评判标准是,困惑度越小,句子正确的概率越大,语言模型就越好。由表3所示实验结果可知,本文方法可以降低困惑度,提高伪平行数据的语义流畅性。
4.3.2 句子打分
为了评测生成的伪数据的语法语义的准确性,利用语言模型来对生成的汉越伪数据进行句子打分,以此对伪平行数据的质量进行评估。对语言模型打分实质上是评估这个句子出现的概率,数据较少的情况下分数一般都很小。分数是对句子概率取对数后的结果,因此分值一般为负数,分数越高这个句子出现的可能性越高,即语法语义正确的可能性更高。通过设置一个阈值,能够有效地将语法语义有误的句子筛选出来,因此本实验依然使用语言模型的得分评价生成的汉越伪平行语料在语法语义上的正确性。
首先利用循环神经网络语言模型对汉语和越南语的单语语料中的句子进行打分,以原始语料中句子的语法语义为基准;然后分别计算出汉语单语语料和越南语单语语料中句子的平均分,并将其作为基准分数;最后同样使用语言模型对生成的汉越伪平行句子分别进行打分,这里使用的测试集包含1 000句语句,计算出其平均分,与基准分数进行比较,表4所示为生成的越南语句子的评价结果,表5所示为反向枢轴生成的汉语句子的评价结果。

Table 4 Scoring results of generated Vietnamese sentence

Table 5 Scoring results of generated Chinese sentence
由打分结果可以看出,生成的汉越伪平行句对的分数都略低于汉语和越南语测试集的基准分数,而融入整合后双语词典的枢轴方法生成的越南语数据和融入整合双语词典的正反向枢轴方法生成的汉语数据的句子打分结果最接近基准分数,因此我们认为在枢轴方法基础上将词替换和回译进行结合的方式,使生成的汉越伪平行句对语法语义正确的可能性较高。
4.3.3 翻译对比分析
通过例举本文方法生成伪平行数据的典型句子样例,对同一汉语句子所生成的伪平行数据进行对比,可以直观地观察效果,对比样例如表6所示。

Table 6 Example comparison of generating pseudo-parallel data
5 结束语
在汉越神经机器翻译任务上,针对资源稀缺型语言的训练数据稀缺问题,将3种生成伪平行数据的方法进行融合,提出了一种融入双语词典的正反向枢轴方法,以此生成汉越伪平行数据,经过语言模型筛选后与原始数据混合训练模型。实验结果表明,这种方法与单一的生成方法相比,可以在资源稀缺型神经机器翻译中更好地缓解数据稀疏问题。接下来我们将继续针对低资源神经机器翻译数据稀疏问题,对枢轴方法进行模型层面的融合研究。
猜你喜欢
科技创新与应用(2023年35期)2023-12-08 11:03:12
计算机工程与应用(2022年16期)2022-08-19 08:20:18
唐山师范学院学报(2022年3期)2022-07-28 02:14:34
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
海外华文教育(2016年1期)2017-01-20 08:21:58
电网与清洁能源(2015年5期)2015-12-29 11:53:03
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
