
面向神经机器翻译的枢轴方法研究综述
2022-08-19 08:20:18黎家全王丽清蒋晓敏徐永跃
计算机工程与应用 2022年16期
黎家全,王丽清,李 鹏,蒋晓敏,徐永跃
1.云南大学 信息学院,昆明 650091
2.云南广播电视台,昆明 650500
近年来,神经机器翻译(neural machine translation,NMT)发展迅速[1-4],已替代统计机器翻译(statistical machine translation,SMT)成为机器翻译领域的主流方法。但神经机器翻译过度依赖于大量的平行训练数据,在低资源语言的翻译任务上,神经机器翻译的性能会急剧下降[5-6]。因此,低资源神经机器翻译(low-resource neural machine translation)一直是神经机器翻译领域的一项重大挑战[7]。
针对低资源机器翻译的数据匮乏问题,基于枢轴的方法(pivot-based methods)为此提供了思路。基于枢轴的方法曾经在SMT 中得以应用[8-11],目前也作为零资源NMT的一个强基线存在。它通过引入一种语料资源丰富的第三方语言作为枢轴,利用枢轴语言的平行语料来桥接源语言和目标语言[12],在一定程度上缓解了因数据匮乏带来的机器翻译质量差的问题。
最经典的枢轴策略也就是枢轴翻译(pivot translation),是先从源语言翻译到枢轴语言,再从枢轴语言翻译到目标语言,最终得到目标语言的翻译结果。虽然该方法简单有效,但需要经过两步翻译,既造成了错误传递问题[13],又增倍了解码时间。
因而,又有了将枢轴思想应用于扩充训练数据的伪平行数据生成(pivot-based pseudo-parallel data generation),以及应用到模型训练和构建中的迁移学习和多语言翻译模型构建的方法。
根据枢轴思想在神经机器翻译中的不同应用,本文从直接取得翻译结果的枢轴翻译、基于枢轴的伪平行数据生成和基于枢轴的模型构建三方面,通过对不同方法的概述、总结、比较和分析,归纳不同方法的优点、局限性和应用场景,并对未来可能的研究趋势和关键技术问题进行展望,为相关研究提供参考。
1 枢轴翻译
枢轴翻译,也被称为级联方法(cascaded approach)[14]。如图1所示,该方法使用一种语料丰富的语言作为中间桥梁,通过枢轴语言将源-枢轴和枢轴-目标翻译模型连接起来。这样,就可以借助于枢轴语言的平行语料间接地实现源语言到目标语言的翻译,进而达到提高低资源语言翻译质量的目的。

图1 枢轴翻译Fig.1 Pivot translation
枢轴翻译从结构上,属于间接方式,并没有得到源和目标之间的直接翻译模型,也因此导致错误传递问题。尤其是在枢轴语言的平行语料缺乏的情况下,错误传递问题会更加突出,此时枢轴翻译的质量甚至比直接翻译的更差[15]。同时,这种两步翻译的方式也增倍了解码时间。针对这个问题,目前的主要解决方法可分为三种。
(1)减少源-枢轴的翻译错误
一方面,通过增加源-枢轴一侧的训练数据[16-17],提高源-枢轴模型的翻译质量。另一方面,还可以利用枢轴翻译与模型结构无关的特点,将枢轴-目标模型扩展为多源NMT[18-20],尽可能地消除在源-枢轴翻译中所带来的翻译歧义。但在上述两种方法中,两个翻译模型仍然是分开训练的,而且在训练期间没有任何关联。
(2)增加源-枢轴与枢轴-目标两个模型的关联
为了进一步缓解错误传递问题,提出了对源-枢轴和枢轴-目标模型进行联合优化的方法[21-23],以加强两个翻译模型在训练期间的关联。Cheng[22]通过共享枢轴语言的词嵌入,联合训练两个模型,使得两个模型在训练过程中相互促进。相对于传统的枢轴翻译方法,联合训练方法减少了错误累积,翻译质量有所提升。Ren 等[23]在此基础上,又提出了一种双向的期望最大化(expectationmaximization,EM)算法,来直接训练源-目标模型,并在四个翻译方向上进行联合的迭代训练,进一步提高了质量。
(3)选择相似度更高的枢轴语言
除了平行语料规模外,语言相似性也会影响枢轴翻译的质量。一般而言,枢轴语言跟源语言和目标语言的语言相似性越高,对枢轴翻译就越有利[24-25]。Leng 等[26]综合平行语料规模和语言相似性两个因素,设计了一种学习路由算法,该算法可以自动选择一种或多种枢轴语言来进行多跳翻译,有效地改善了无监督翻译在远程语言之间的翻译质量。
总体来说,枢轴翻译由于本质上依赖于所选枢轴语言与源和目标之间的语料数据、语言相似度,以及两个模型本身的性能,其间接生成结果的方式是导致错误传递问题的根本原因。因此,提出了利用枢轴思想进行数据增强以及直接构建模型的方法。
2 基于枢轴的伪平行数据生成
基于枢轴的伪平行数据生成是以枢轴语言作为中间桥梁,生成源语言和目标语言之间的伪平行数据,用于数据增强。通过训练数据的扩充,实现对翻译系统进一步的改进。但不足在于伪平行数据的质量不能保证,当伪平行数据包含过多的数据噪声时,反而会损害翻译的质量。
从分类上,主要有利用平行语料和利用单语语料的生成方法。
2.1 基于平行语料的生成
按照生成方向的不同,利用枢轴语言的平行语料库来生成伪平行数据可以分为:源端伪数据生成和目标端伪数据生成。源端伪数据生成是利用回译方法(backtranslation)[27],将枢轴-目标平行语料的枢轴语言一侧反向翻译为源语言[28]。
目标端伪数据生成是将源-枢轴平行语料的枢轴语言一侧正向翻译为目标语言[29]。最后将翻译结果与原有语料组合,进而形成源语言-目标语言的伪平行数据。利用平行语料的生成方法如图2所示。
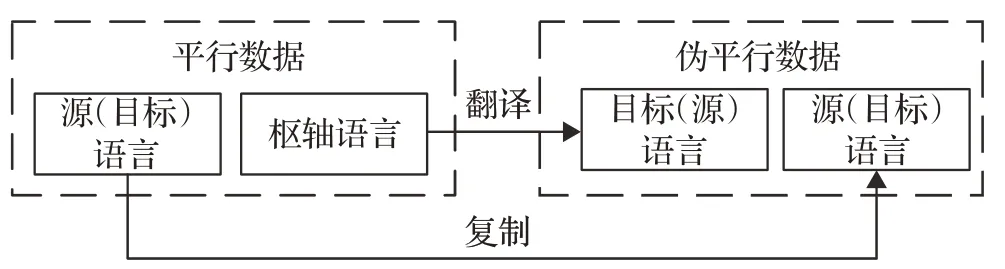
图2 利用平行语料的生成方法Fig.2 Generation method based on parallel corpus
伪平行数据给低资源语言的机器翻译带来了一定程度的质量提升。文献[30-31]将枢轴语言回译到源语言,扩充了大量的伪平行语料,并与原有语料混合,提高了低资源语言对的翻译质量。Park 等[32]生成源端和目标端的伪数据并混合,同时增强了编码器和解码器的能力,相比只生成源端或目标端伪数据的方法取得了更好的数据增强效果。
但利用平行语料的生成方法需要依赖一个翻译模型,因此该翻译模型的质量越高,生成的伪平行数据质量就越高,对源-目标翻译模型的质量提升也就越大[33]。如果该翻译模型的质量较低,生成的伪数据会包含过多的数据噪声,以致损害最终翻译系统的性能[34-35]。因此,选择生成源端还是目标端的伪数据,主要根据生成伪平行数据的翻译模型质量来选择。
尽管利用平行语料的生成方法避免了错误传递问题,但受数据噪声的影响,可能会取得比枢轴翻译更差的翻译性能。为了减弱数据噪声对源-目标翻译模型的影响,可以在数据生成阶段进行优化。通过最大期望似然估计(maximum expected likelihood estimation)方法最大化合成源语言句子的期望[36],或者加强在单词级别的数据生成[37-38],均可有效减少伪数据生成过程中产生的翻译错误,比直接生成伪数据的方法及枢轴翻译方法获得更高的BLEU分数。
2.2 基于单语语料的生成
与基于平行语料的生成方法类似,基于单语语料的生成方法也有两个生成方向,即分别基于反向和正向的枢轴翻译方法,生成源端伪数据和目标端伪数据。除此之外,由于枢轴语言的单语语料在三种语言中往往是资源最丰富并且质量最高的,Currey等[39]还将枢轴语言分别翻译到源语言和目标语言,生成了更多高质量的伪平行数据。
同样是利用目标语言的单语语料,直接回译的方法没有足够的源-目标平行语料训练回译模型,而经过枢轴语言间接回译到源语言,则可利用枢轴语言的平行语料训练两个质量较高的回译模型,得到比直接回译更好的结果[40-41]。
一般而言,单语语料比平行语料更容易获取,因此利用单语语料的生成方法可以扩充更多的伪平行数据,给翻译模型带来更大的增益[39,42]。然而,利用单语语料的生成方法需要依赖于两个翻译模型,只要存在一个模型的质量较低时,生成的伪平行数据就会存在大量的数据噪声,反而导致结果质量更差[43]。
因此,无论是利用平行语料还是单语语料的生成方法,都对生成伪数据的翻译模型质量有着较高的要求。相对于利用平行语料的生成方法,由于单语语料规模更大,利用单语语料可以生成更多的伪平行数据。但也因为利用单语语料的生成方法需要依赖于两个翻译模型,所以生成的伪平行数据质量也更差。
3 基于枢轴的模型构建
基于枢轴的模型构建(pivot-based model construction)是将枢轴思想与迁移学习或多语言神经机器翻译等技术结合起来,直接对源-目标翻译模型进行训练,省去了生成伪平行数据的步骤,弱化了数据噪声的影响,最终得到的是源-目标的翻译模型。
基于枢轴的迁移学习和枢轴结合多语言神经机器翻译方法均可利用源-枢轴和枢轴-目标翻译模型的参数,将枢轴语言的翻译知识迁移到源-目标的翻译中。两者的不同在于,前者采取迁移参数的方式,将两个预训练模型的参数迁移到最终的模型上并进行微调。后者则采取共享参数的方式,为所有的语言对联合训练一个通用的模型,省略了微调的步骤。
3.1 基于枢轴的迁移学习
在低资源语言翻译中,迁移学习技术是将高资源语言对的模型参数迁移到低资源语言对上[44],使低资源语言对获取到高资源语言对的翻译知识。
与基于枢轴的方法类似,迁移学习也引入了一种第三方语言(称为辅助语言)。但两者的不同在于,迁移学习通常只利用源语言-辅助语言和辅助语言-目标语言平行语料库中的一个[45-46],并没有同时使用两个平行语料库来对源语言和目标语言进行桥接。
为了能同时利用源-枢轴和枢轴-目标平行语料,Kim等[47]将枢轴策略应用到迁移学习中,提出了基于枢轴的迁移学习方法,如图3所示。该方法首先预训练源-枢轴和枢轴-目标翻译模型,然后直接将源语言编码器和目标语言编码器组合起来,最后经过微调得到最终模型。
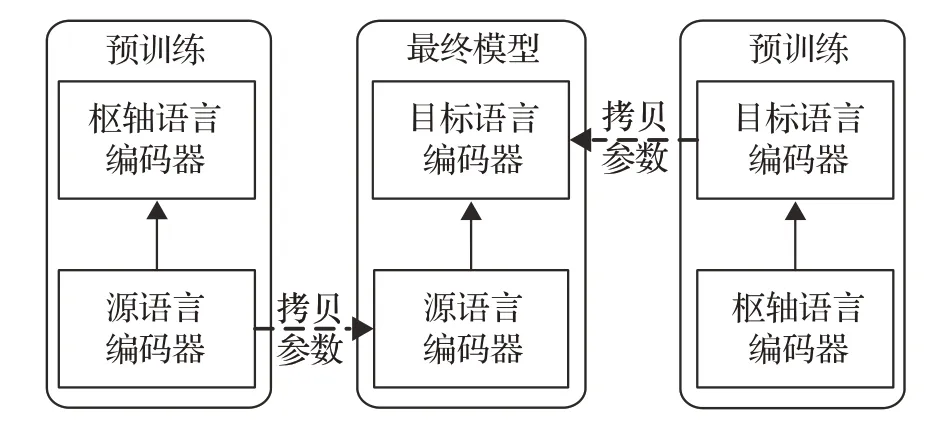
图3 基于枢轴的迁移学习方法Fig.3 Pivot-based transfer learning method
这种方法的优势体现在:源-枢轴翻译模型的编码器和解码器不是随机初始化的,而是分别从两个预训练模型迁移过来,这为源-目标翻译模型提供了一个良好的训练起点,使编码器和解码器在微调之前就学习到了一些翻译知识。因此,无论是低资源语言对还是高资源语言对,都能从枢轴语言的知识迁移中获益,并取得比直接翻译更高的翻译质量[48-49]。Yu等[50]还研究了语言相关性对迁移学习的影响,结果表明枢轴语言与源语言或目标语言之间的相似性越高,对迁移学习也越有利。
然而,源-目标翻译模型的编码器和解码器分别来自两个不同的预训练模型,这会导致编码器和解码器之间的输入/输出不一致,从而放大了预训练模型与最终模型之间的差异。
为了减小差异,主要的改进思路是让源语言和枢轴语言共享同一个编码器,使得枢轴语言能更平滑地桥接预训练的源语言编码器和目标语言解码器。一种方法是冻结源语言编码器,并使用源语言和枢轴语言的联合词表,使得编码器能有效地表示这两种语言[47]。另一种方法是利用源-枢轴平行语料和源语言单语语料,通过跨语言预训练技术,直接预训练一个源语言和枢轴语言的通用编码器[51]。结果表明,以上两种方法均比图3 的方法取得了更好的迁移效果。
3.2 枢轴语言结合多语言神经机器翻译
多语言神经机器翻译(multilingual neural machine translation,MNMT)是通过参数共享,在一个通用模型上实现多个语言对的翻译[52-54]。在低资源语言翻译中,由于缺乏可用的平行语料,MNMT中的源语言和目标语言采用了枢轴语言实现桥接。本文仅从MNMT的枢轴语言机制,以及如何更好地利用枢轴语言的角度进行分析。
MNMT 可以看作一个隐式的枢轴系统,因为在多语言翻译模型训练和翻译的期间,枢轴语言都是不可见的。因此,这种利用枢轴语言的方式也被称为隐式桥接(implicit bridging)[55]。隐式桥接通过共享编码器、解码器以及中间的注意力机制来实现[56-57]。这样,受益于跨语言的知识迁移[58],低资源语言可以从高资源语言中学习翻译知识,从而提高低资源语言对的翻译质量。在枢轴语言选择上,现有研究大多采用英语作为枢轴语言[59-60],使用以英语为中心的语料库训练多语言翻译模型。
与传统的枢轴翻译方法相比,MNMT 可以直接实现未经训练的语言对之间的翻译,即零样本翻译,避免了错误传递和时间增倍的问题。但有研究表明,MNMT在零样本翻译场景下的性能不佳,而且通常落后于枢轴翻译方法[61-62]。
为了提高MNMT 的零样本翻译质量,研究者们提出了一种多桥模型(mutil-bridge models)[63]。该模型加入了非英语语言对的平行语料训练,利用多种枢轴语言的数据来改善低资源语言翻译的质量。例如,Rios等[64]仅添加了少量的非英语平行语料,就使6个零样本翻译方向的BLEU 平均提高了3.1 个百分点。Fan 等[65]利用语言相似性对语言进行分组,在使用英语作为枢轴语言的同时,又在每个语言组中选取1~3种高资源语言来桥接组内之间的语言,提高了多个非英语低资源语言对的翻译质量。
4 主要枢轴方法的对比分析
针对枢轴思想在神经机器翻译领域的应用,表1从不同方法的机制、适用场景、优点、局限性等方面进行了分析和比较。
从表1中可以看出,枢轴翻译和基于枢轴的伪平行数据生成都属于间接建模的方法,这分别带来了错误传递问题和数据噪声问题。虽然枢轴翻译方法简单方便,但其两步翻译的过程既造成了错误传递问题,又增倍了解码时间。
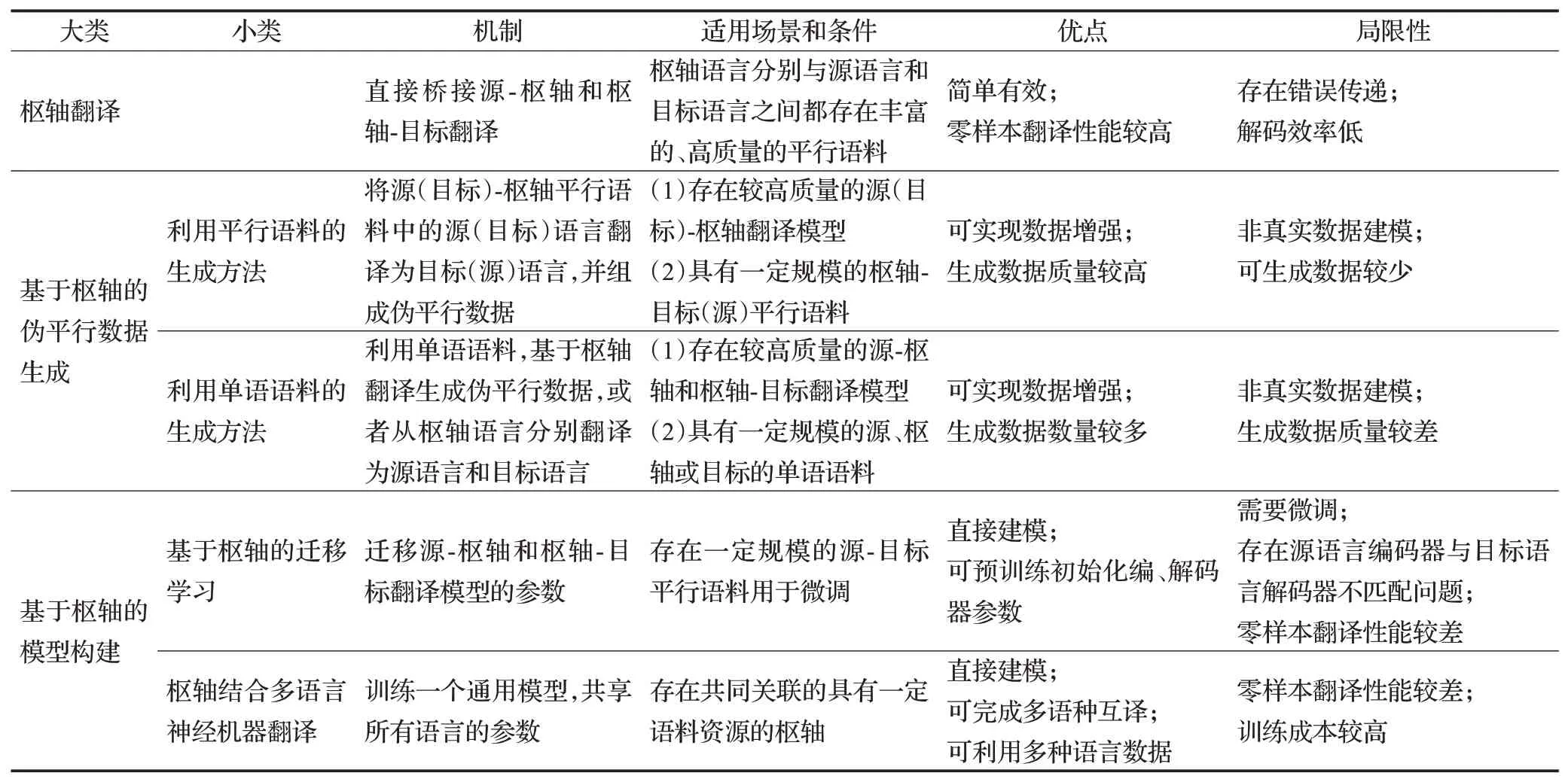
表1 主要枢轴方法对比Table 1 Comparison of pivot-based methods
基于枢轴的伪平行数据生成则利用伪平行数据训练源-目标翻译模型,避免了错误传递。但生成的伪平行数据质量不能保证,如果存在过多的数据噪声,反而会对翻译模型的质量产生负面影响。
基于枢轴的模型构建则通过利用源-枢轴与枢轴-目标翻译模型的参数,直接对源-目标翻译模型建模,在避免错误传递的同时,也弱化了数据噪声的影响。但此类方法在零样本翻译场景下性能不佳,甚至比不过传统的枢轴翻译方法。基于枢轴的迁移学习由于没有可用的源-目标平行语料用于微调,使得迁移后的最终模型难以适应源-目标翻译任务。枢轴结合多语言神经机器翻译则共享所有语言的参数,因此可以从更多的语言中获取知识,一定程度上提高了零样本翻译的性能。
尽管如此,枢轴结合多语言神经机器翻译方法仍然成为了目前的研究热点,并拥有着广阔的研究前景。主要原因有:第一,能在单个通用模型上进行多个语言对之间的翻译,因此被广泛应用于谷歌翻译等多语种翻译引擎中;第二,可以有效利用多种语言的数据,进一步解决了平行语料匮乏的问题。
5 结束语
基于枢轴的方法为解决目前低资源语言的机器翻译问题提供了思路,有效地缓解了训练语料匮乏的问题,提高了低资源语言神经机器翻译的质量。然而,基于枢轴的方法仍然存在一些问题和挑战,需要未来进一步研究和探索。
(1)错误传递问题
枢轴翻译在零样本翻译场景下仍然具有竞争力,但错误传递问题限制了其性能提升。因此,如何更好地减少错误传递来改善枢轴翻译,仍有待进一步的研究。
(2)非真实数据建模
受限于生成伪平行数据的翻译模型质量,基于枢轴生成的伪平行数据的质量不能得到保证,还可能面临生成数量较少的问题。因此,考虑提升伪平行数据的质量,以及将基于枢轴的伪平行数据生成方法与其他数据增强方法结合使用,扩大伪平行数据的数量,是非常有意义的研究方向。
(3)源语言编码器与目标语言解码器不匹配问题
在基于枢轴的迁移学习中,由于源语言编码器与目标语言解码器来自两个不同的预训练模型,导致两者在输入/输出方面的不一致性。研究枢轴语言与源语言或目标语言之间通用空间表示的可能性,或者研究选用相似性高的枢轴语言,为这个问题的研究提供了思路。
(4)枢轴语言语料匮乏
对于一些资源极度匮乏的低资源语言而言,与枢轴语言之间的平行语料也将变得难以获取。因此,结合多语言NMT 利用多种枢轴语言的数据,或者考虑利用图像和音译等多模态数据作为枢轴[66-69],有待进一步研究和探索。
总之,未来如何将枢轴思想应用在更多渠道、更大规模、更高质量的数据生成和增强,以及基于模型的生成和泛化方面,仍有待学者们进一步地创新和研究,以期为低资源神经机器翻译的研究提供更多的思路和参考。
猜你喜欢
科技创新与应用(2023年35期)2023-12-08 11:03:12
唐山师范学院学报(2022年3期)2022-07-28 02:14:34
露天采矿技术(2021年1期)2021-12-30 04:25:41
河南教育·高教(2019年3期)2019-04-11 01:16:14
北方文学(2018年18期)2018-09-14 10:55:22
文理导航(2017年25期)2017-09-07 15:38:18
速读·下旬(2016年7期)2016-07-20 08:50:28
电网与清洁能源(2015年5期)2015-12-29 11:53:03
考试周刊(2015年36期)2015-09-10 15:03:38
读与写·教育教学版(2015年6期)2015-06-30 20:44:40
