
基于多特征融合与极限学习机的植物叶片分类方法*
2021-04-06 10:48:24火元莲李俞利
计算机工程与科学 2021年3期
火元莲,李俞利
(西北师范大学物理与电子工程学院,甘肃 兰州 730070)
1 引言
植物作为生态系统的重要组成部分,与人类的生命活动息息相关。对植物类别的精准分类,有利于加速农业自动化发展,同时也可为生态学研究做出很大贡献。叶片作为植物的重要器官之一,包含有形状、纹理和颜色等多种具有辨识度的信息,因此通过对植物叶片的分类来判断植物的种类,成为一种形象有效且可行性高的分类方法。
对于植物叶片的分类,由于计算机无法理解图像,因此需要通过分析图像的形状、纹理和颜色等来将其转化为叶片图像特征[1]。基于叶片的形状特征SF(Shape Feature),Lee等人[2]提出了一种基于叶片轮廓和质心的植物分类和叶片识别系统的实现方法。Mahdikhanlou等人[3]提出了一种利用质心距离和最小惯性轴法的叶片分类方法,从对质心与叶轮廓上所有点之间的距离的快速傅里叶变换中提取10个特征和相位,再结合4种基本几何特征和5种叶脉特征共同组成特征向量,分类准确率达到95.44%,但是叶片图像的基本几何特征对放缩后图像形状特征的表达效果会低于相对几何特征。张善文等人[4]提出一种基于傅里叶描述子和局部二值模式LBP(Local Binary Patterns)相结合的方法,提高了分类准确率,通过叶片图像提取傅里叶描述子,再结合LBP特征进行分类。在公开叶片图像数据集上进行实验,实验的分类准确率达到了94%,但是由于特征类型单一,在一定程度上对相似图像的分类效果不够好。基于叶片的纹理特征TF(Texture Feature),张宁等人[5]提出了基于克隆选择算法和K近邻的植物叶片识别方法,证实了纹理特征在叶片分类任务中的重要性。 Kolivand等人[6]提出了一种基于新的叶脉检测技术的分类方法,实验结果表明了所提出的方法在高精度形状分类中的有效性。Codizar等人[7]提出一种基于脉序和形状的人工神经网络植物叶片识别方法,有效地提高了识别准确率。基于分类器的改进,陈筱勇等人[8]提出了基于Gabor特征多分类器融合的植物叶片识别方法,利用多个分类器的识别结果构造D-S分配函数并通过D-S融合输出最后结果,识别准确率可以达到91.7%。近年来使用深度学习方法进行植物叶片分类取得了傲人的成果,Tan等人[9]利用叶脉形态计量学对植物物种分类进行了深入研究,利用预训练的卷积神经网络模型对叶片图像进行预处理和特征提取,然后利用机器学习技术对这些特征进行分类,分类准确率达到93%。
单一的特征种类不能准确地描述叶片特征,也不利于相似叶片的准确分类;复杂多维特征在一定程度上会增加准确降维处理的难度,同时也会增加分类计算的难度。本文提出了一种基于极限学习机的多特征融合的植物叶片分类方法。首先,对植物叶片彩色样本图像进行预处理获得二值图像和灰度图像;然后从二值图像中提取叶片的形状特征和不变矩特征MF(invariant Moment Feature),计算灰度图像的灰度共生矩阵GLCM(Gray Level Co-occurrence Matrix)参数并将其作为叶片的纹理特征,共得到28维的特征参数;最后,采用极限学习机对特征参数进行训练和测试,实现对植物叶片的有效分类。
2 图像预处理
在植物叶片分类过程中,叶片图像的预处理是叶片分类过程的重要基础,是特征提取的必要准备工作。通过图像预处理过程,可以保留或增强有效信息,同时削弱或去除无用信息,保证在后续的特征提取过程中提取到更准确的特征信息。
植物叶片的颜色会随着季节或环境的变化而不同,因此叶片的颜色特征是一个不稳定的特征,为了在去除叶片颜色特征的同时尽可能保留原始叶片图像的其它特征信息,本文对叶片图像分别进行二值化和灰度化处理,预处理过程的输出为用于特征提取的二值图像和灰度图像,预处理过程如图1所示。
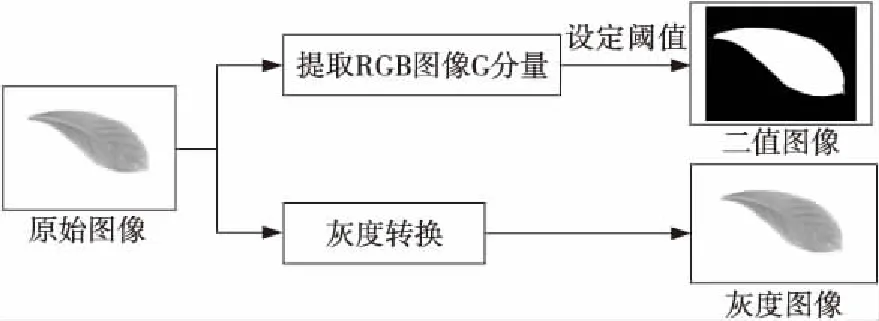
Figure 1 Process of image preprocessing
首先对原始RGB图像提取其G分量,通过设置合适的阈值将叶片图像二值化,从而得到二值图像。二值图像可以将叶片区域与背景区域区分开来,可以有效表示叶片图像区域。其次利用加权平均法在去除颜色特征的同时对原始RGB图像进行灰度转换处理得到灰度图像。
3 特征提取
对于输入的植物叶片图像,计算机并不能直接对叶片图像进行分类,所以需要对叶片图像进行特征提取,将提取出来的特征组合作为叶片图像的代表,由计算机进行分类。因此,提取出最具有代表性和辨识度高的特征是提高分类准确率的直接途径。本文对图像进行多特征提取,包括形状特征、纹理特征和不变矩特征。
3.1 形状特征提取
同类植物叶片的形状具有极高的相似性,而不同类叶片之间在形状方面存在不同程度上的差异,所以植物叶片的形状是叶片最形象、最直接、最具有辨识度的代表特征,而且叶片的形状不会因为季节和生长周期的不同而变化,是一种非常稳定的特征。
本文对预处理得到的二值图像提取11个形状特征参数,其中包括4个基本形状特征:长轴(M)、短轴(N)、边界区域周长(P)、面积(A)和7个推算形状特征:高宽比(R)、形状因子(F)、边轴和比(S)、随机性(E)、边轴比(G)、矩形度(T)、不规则性(I)。推算形状特征参数计算公式分别如式(1)~式(7)所示:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
式(7)中的W和L分别代表图像区域的包围半径和内圆半径。因此,叶片的推算形状特征是一个相对值,对于不同大小的同类叶片图像,推算形状特征参数值不会受到影响。表1为实验数据集中13类标签样本的11个形状特征参数值。
3.2 纹理特征提取
纹理特征是植物识别系统的重要特征之一,它可以根据植物叶片的表面结构来表征植物叶片,是不同图像强度的非一致空间分布模式,需要在包含多个像素点的区域中进行统计计算。纹理特征提取的主要目的是通过计算来表达对纹理的直观感知,对图像的灰度变化的特征进行量化,纹理特征能够很好地描述图像内容的表面特征信息。本文采用灰度共生矩阵特征来表示对叶片图像预处理得到的灰度图像的纹理特征。
灰度共生矩阵GLCM定义为像素对的联合分布概率,是一个对称矩阵,能够反映图像灰度在相邻方向、相邻间隔以及变化幅度上的综合信息,同时能够反映相同灰度级像素之间的位置分布特征,在此基础之上计算纹理特征量,刻画纹理的假设是所有的纹理信息都包含在灰度共生矩阵中[10,11]。本文采用在灰度共生矩阵基础上定义的5个描述能力强的特征统计量(对比度、齐次性、相关性、能量和熵)来组成纹理特征,以上5个纹理特征参数计算公式分别如式(8)~式(15)所示,式中P(i,j)表示灰度共生矩阵第i行、第j列元素的值,k为灰度级。
对比度主要反映图像纹理的清晰度和纹理线的深浅:
(8)
齐次性主要反映图像纹理局部变化程度:
(9)
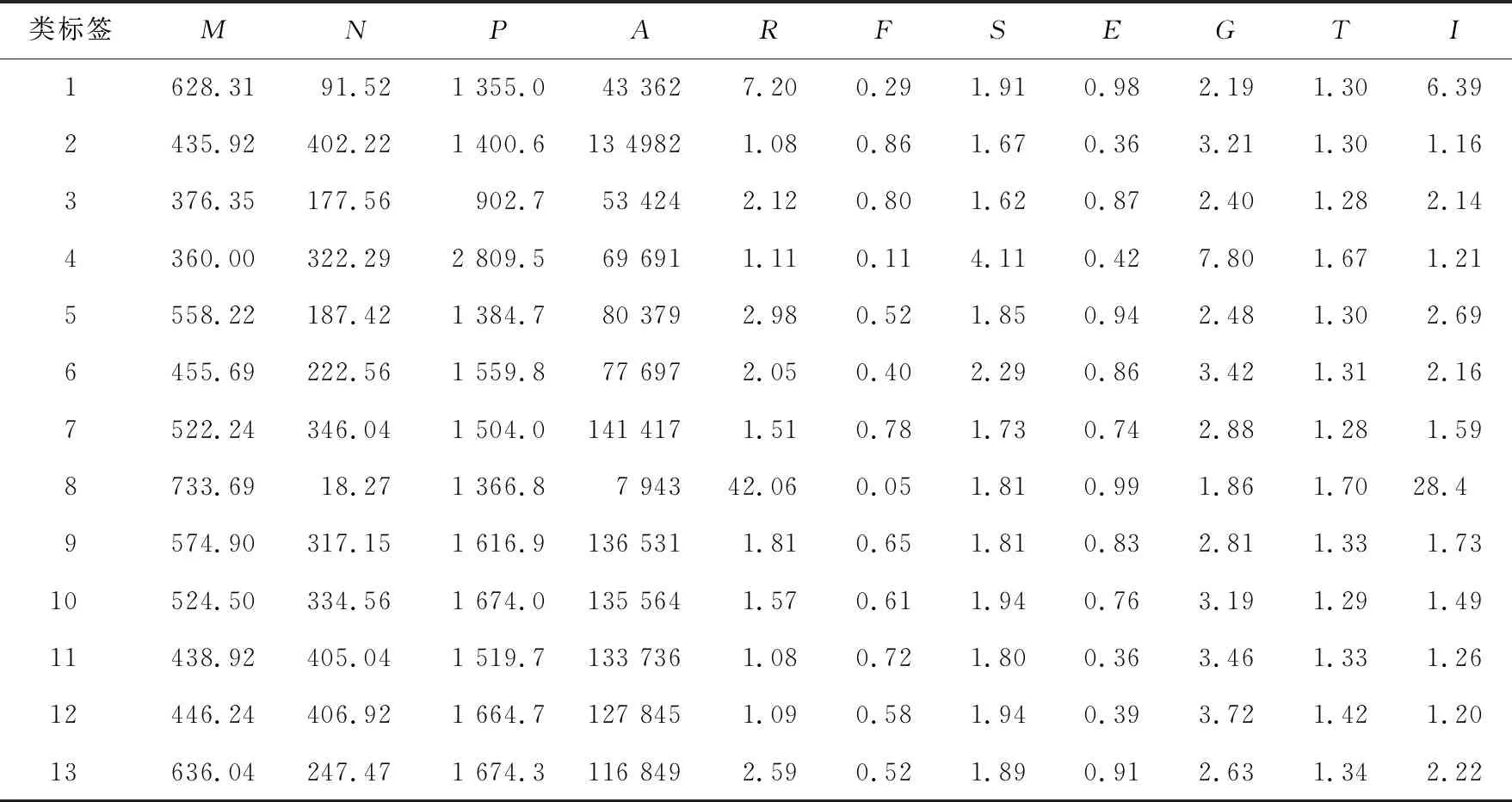
Table 1 Shape feature values of experimental leaf samples
相关性用来度量图像的灰度级在行或列方向上的相似程度:
(10)
其中,μi,μj分别为矩阵第i行、第j列元素的均值;σi,σj分别为矩阵第i行、第j列元素的标准差,其计算如式(11)~式(13)所示:
(11)
(12)
(13)
能量是矩阵元素值的平方和,反映图像纹理的灰度变化稳定程度:
(14)
熵是对图像包含信息的随机性度量,对应地反映出图像纹理的复杂程度:
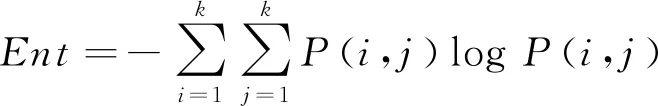
(15)
图2表示归一化后的13类标签样本的纹理特征的特征值分布,图中纵坐标为13类标签样本的纹理特征的特征值,横坐标1~5号特征序列依次代表对比度、齐次性、相关性、能量和熵5个特征参数。
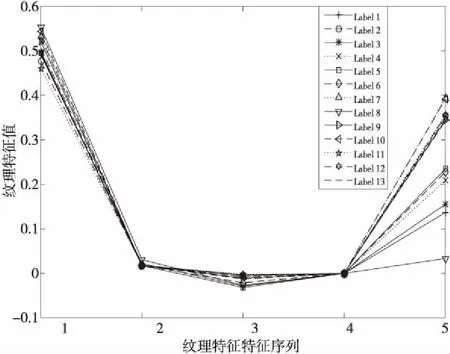
Figure 2 Texture feature distribution of experimental leaf samples
3.3 不变矩特征提取
在植物叶片分类过程中,对叶片的形状轮廓信息的描述十分重要,不变矩特征最大的优点就是能够全面表达叶片的轮廓特点。为了保证图像在旋转、平移和缩放后仍然具有较高的可识别度,本文采用Zernike矩和hu矩来表示叶片图像的不变矩特征。
3.3.1 Zernike矩特征
Zernike矩是一种正交矩,具有旋转和缩放不变性。 Zernike矩可以看作是图像B(i,j)在一组Zernike多项式核函数上的投影。对于归一化到单位圆上的离散化图像函数B(i,j),它的m阶n次Zernike矩可以表示为[12,13]:
(16)
其中,Vmn(i,j)为核函数,*为共轭符号,m和n为整数,且m≥0,满足(m-|n|)为偶数。
本文对叶片二值图像计算9个Zernike矩参数,分别包括Z00,Z11,Z20,Z22,Z31,Z33,Z40,Z42和Z44,经过归一化处理后得到的参数值如图3中1~9号特征序列所示。
3.3.2 hu矩特征
hu矩具有旋转、平移和缩放不变性,利用二阶和三阶归一化中心矩构造了7个矩不变量[14],归一化中心距定义为:
(17)
其中,p表示x方向对应的阶数,q表示y方向对应的阶数,ρ=1+(p+q)/2。
本文计算叶片图像的前3个hu矩参数,经过归一化处理后得到的参数值如图3中10~12号特征序列所示。
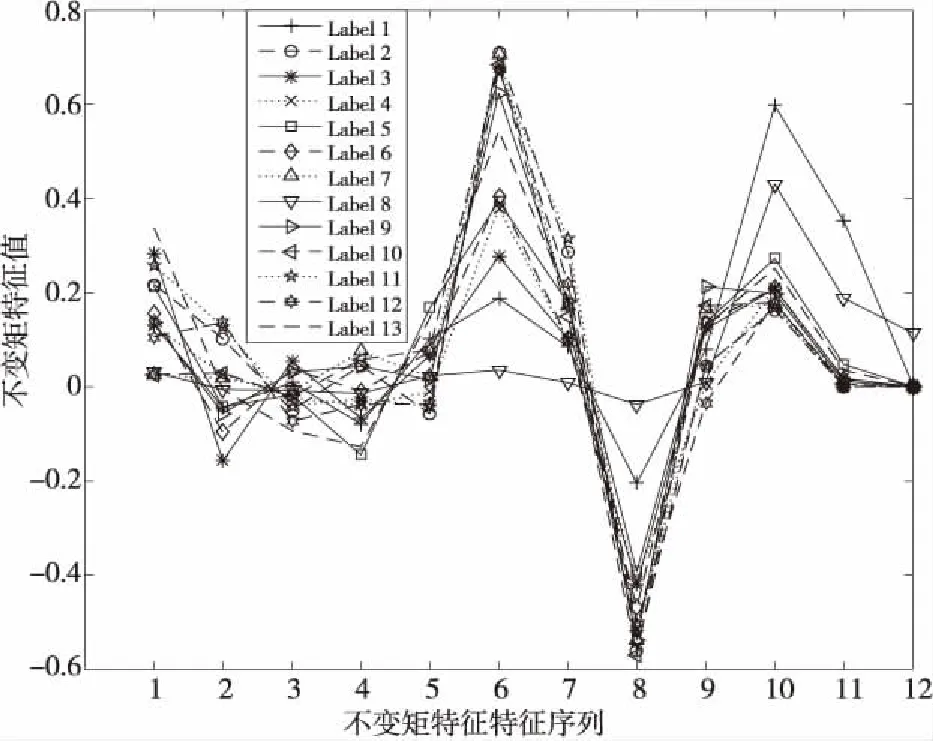
Figure 3 Invariant moment feature distribution of experimental leaf samples
综上所述,本文从叶片二值图像中提取了11个形状特征SF和12个不变矩特征MF,从叶片灰度图像提取了5个纹理特征TF;然后对这些特征分别进行归一化处理并融合组成植物叶片的28维的鉴别特征[15]。本文采用早期融合的方法对提取的特征进行连接形成融合特征,特征融合过程如图4所示。
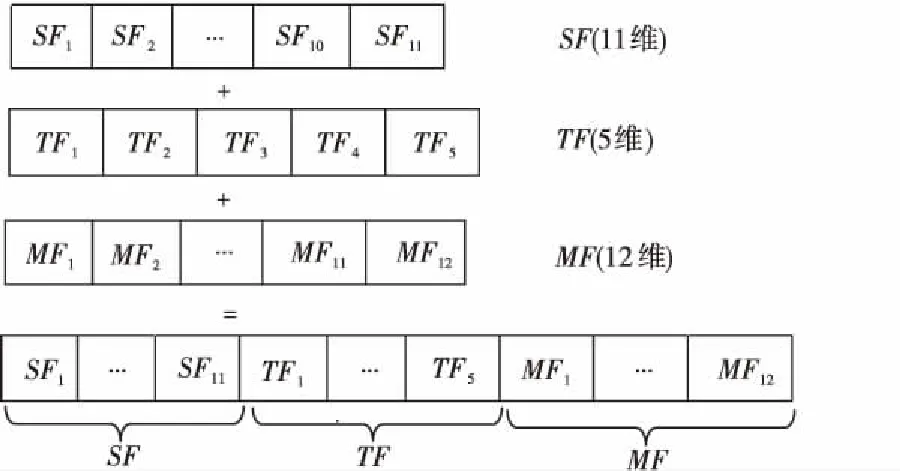
Figure 4 Schematic diagram of feature fusion
4 基于极限学习机的分类策略
极限学习机ELM(Extreme Learning Machine)是一种基于单隐含层的前馈神经网络构建的机器学习方法,其工作效率高、结果准确率高且泛化能力强,结构与BP等传统神经网络结构相似[16]。与传统网络不同的是:极限学习机输入层到隐含层的权重以及隐含层的偏置可以随机初始化,不需要迭代修正,因此可以减少一般的运算量;而隐含层到输出层的权重通过求解矩阵方程得到。通过这样的规则,模型的泛化性能很好,速度也会有所提高。极限学习机由输入层、隐含层和输出层组成,如图5所示。
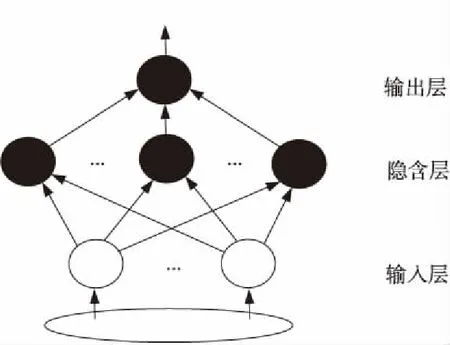
Figure 5 Structure of extreme learning machine
4.1 ELM原理
假设一个带标签的有N个任意样本的样本集为(X,T)={(Xi,Ti)|1≤i≤N},此处X定义为输入样本矩阵,T为X对应的期望输出矩阵,Xi=[xi1,…,xi2,…,xin]T表示X中第i个输入样本,n表示输入样本维数(与叶片特征维数相等)。ti=[ti1,ti2,…,tim]T表示第i个输入样本的期望输出,m表示期望的输出向量维数(与叶片的类别数相等)。一个有L个隐含层节点的单隐层神经网络的输出可以表示为:
(18)
其中,G(x)为激活函数,Wi=[wi,1,wi,2,…wi,n]T为输入权重,βi为输出层权重,Bi是第i个隐含层单元的偏置,Wi*Xj表示Wi和Xj的内积,oj为网络输出。单隐含层神经网络学习的目标是使得输出的误差最小,即存在βi,Wi和Bi使得:
Hβ=T
(19)
其中,
H(W1,…,WL,B1,…,BL,X1,…,XN)=
H是隐含层节点的输出,T为期望输出。
在分类过程中,一旦Wi和Bi被随机确定,那么隐含层的输出矩阵H就被唯一确定,并且有:
(20)
其中H+是矩阵的Moore-penrose广义逆[17]。因此,可以得到极限学习机的数学模型为:
(21)
其中,W是输入权重,B是隐含层偏置。
4.2 分类方法流程
本文采用ELM进行分类的方法主要包含特征数据集的处理与分类器的训练2个部分,流程如下所示:
输入:特征数据集,隐含层神经元个数和激活函数。
输出:训练准确率和测试准确率。
步骤1特征数据集载入与预处理,确定隐含层神经元个数,随机产生输入权重和隐含层偏置。
步骤2分类任务前数据编码。
步骤3预定义期望输出矩阵。行是分类类别,列是分类对象,每个对象(列)所在真实类(行)置1,其余为-1。
步骤4计算隐含层输出。
步骤5计算输出层权重。
步骤6计算输出。若输出类别标签与真实标签相等,正确计数加1。
步骤7计算准确率。
本文实验的激活函数选用Sigmoid函数,Sigmoid函数的数学图像如图6所示。由图6可以看出Sigmoid函数的输出有界,所以数据在传递过程中不容易发散。另外,Sigmoid能有效地将范围内的信号光滑地映射到(0,1),并且对于中间值信号的增益大,对极端值信号的增益不明显。本文在训练极限学习机分类模型时,对实验叶片数据进行参数寻优,得到在隐含层节点数为200时,分类结果为最佳。
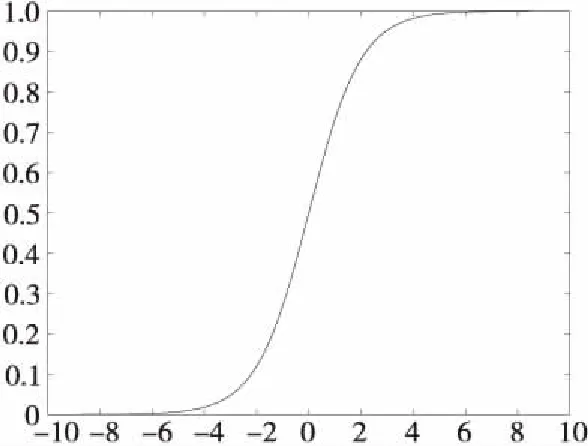
Figure 6 Sigmoid function image
5 实验与结果分析
5.1 实验环境与数据集
本文的仿真环境为Matlab 2017,所使用的电脑CPU配置为Intel(R) Core(TM) i5-3770,内存为1 GB,操作系统为Windows 10。实验数据集是公开的Flavia数据集[18],该数据集中共有32种植物叶片,每一种叶片图像有50~77幅,并且都是以白色为背景。本文选取其中的13种叶片图像进行实验,为了丰富实验数据集,对其中的一些图像进行了旋转处理,使得每一种叶片图像有100幅,13种共1 300幅叶片图像组成本文实验的数据集,其中的80%作为训练集,剩下的20%作为测试集。数据集中的叶片种类如图7所示。

Figure 7 13 samples for leaf classification
本文采用准确率来对分类方法性能进行评价,其计算方法如式(22)所示:

(22)
5.2 实验过程与结果分析
首先采用ELM分类器对本文提取的单一特征和融合特征的不同情况分别进行实验,结果如图8所示。图8中SF+ELM为形状特征方法,TF+ELM为纹理特征方法,MF+ELM为不变矩特征方法,SF+TF+MF+ELM为多特征融合方法。由图8可以看出,多特征融合的方法对叶片的训练集分类准确率和测试集分类准确率都是最高的。

Figure 8 Classification accuracy of different feature combinations
然后将本文多特征融合分类方法和文献[2,4,8,9,19,20]共6种较新的分类方法进行比较,结果如表2所示。

Table 2 Classification results of different methods
由表2可知,本文方法的分类准确率是最高的,准确率达到了98%以上。其中,本文方法与文献[19,20]方法的提取特征种类较为接近,文献[19]通过提取叶片图像的几何、结构、hu矩和GLCM等6种共2 183维特征向量对叶片进行特征描述,再对特征向量降维处理至31维后使用支持向量机实现分类。但是,数据降维时需要设置或调整方差的阈值,如果阈值不合适,可能导致降维处理过程中存在有效信息丢失的问题。所以,本文方法在提取的特征向量的维数略少于文献[19]方法降维后特征向量维数的情况下,分类准确率却有所提高。文献[20]对实验叶片提取几何、hu矩2类共15维的特征向量,使用移动中心超球分类器实现分类。文献[20]中的几何特征多为基本形状特征的简单比值,欠缺对特征表达的准确性,而本文方法分类的准确率更高,表明本文分类方法提取的特征能够更好地表达叶片的特征信息,分类效果更佳。
表3为基于本文方法对选取的13种植物叶片的分类结果,从中可以看出容易出现分类错误的有2种叶片,这2种叶片的错误分类结果如表4所示。结合表3和表4可以看出:错误分类次数最多的是第11类叶片,错误次数一共是4次,其中被错误分类为第2类3次,被错误分类为第7类1次,分析其错误的原因是以上3类叶片在形状上非常相似,都属于心形轮廓叶片,导致计算的形状相对参数存在极大的相似性。另外,以上3种叶片的纹理都属于较为清晰又非常均匀的形状,导致在纹理上的区分性也不高。而第9类叶片被错误分类为第6类1次,可以看出第9类叶片的边缘多有微小的波动形状,而第6类叶片的锯齿边状较为明显,究其原因为本文方法对锯齿形边缘形状的描述不够准确,所以本文提取的特征对锯齿边缘形状方面的表达能力还需进一步改进。
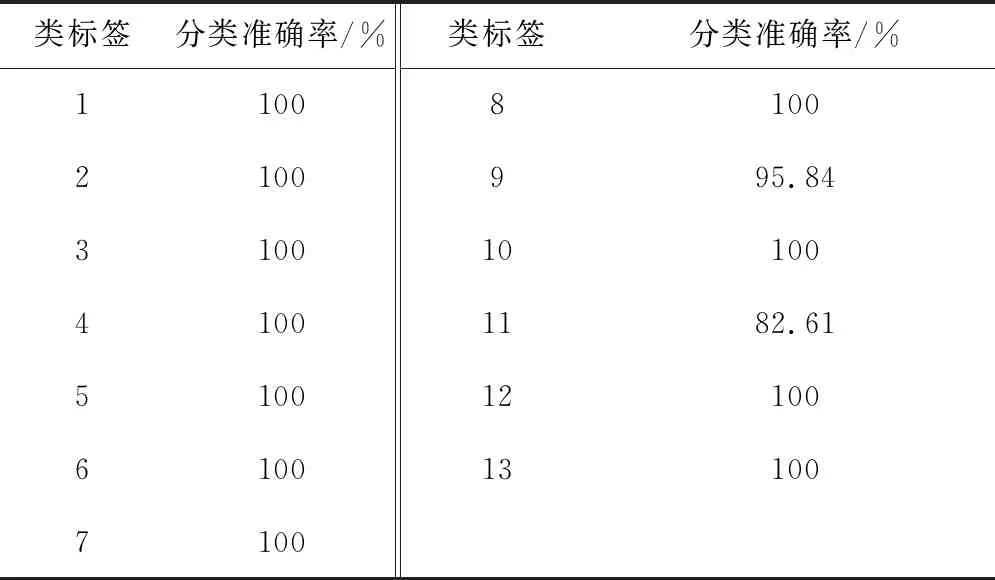
Table 3 Classification results of each experimental leaf
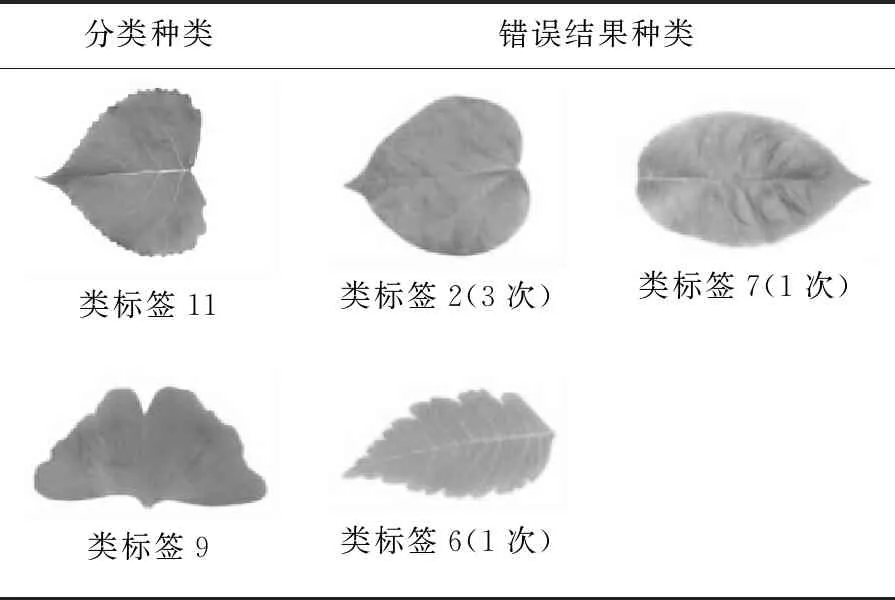
Table 4 Types of classification errors
6 结束语
在植物叶片的分类方法中,图像特征向量的构成多种多样,如何能提取出植物叶片表征性能较好的特征信息,是提高植物叶片分类准确率的关键。本文提出了一种基于多特征融合与极限学习机的植物叶片分类方法,首先提取了植物叶片包括形状、纹理和不变矩共28维的特征参数作为特征向量;然后采用特征向量对极限学习机的分类策略进行训练和测试,在公开的植物叶片图像数据集Flavia上进行实验,并就不同特征融合的分类效果、不同方法的分类效果分别进行了对比分析,结果表明本文所提方法能有效提高植物叶片图像分类的准确率。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
北京航空航天大学学报(2022年6期)2022-07-02 02:00:02
高技术通讯(2021年3期)2021-06-09 06:57:48
软件(2020年3期)2020-04-20 01:45:18
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
Coco薇(2017年8期)2017-08-03 15:23:38
自动化学报(2017年5期)2017-05-14 06:20:56
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
光学精密工程(2016年1期)2016-11-07 09:01:59
