
基于轨迹大数据的交通拥堵评估和预测
2021-03-29 08:15:44温美玲路鹏远程洋溢
数字制造科学 2021年1期
温美玲,路鹏远,蔡 林,程洋溢
(1.武汉大学 测绘学院,湖北 武汉 430070;2.武汉大学 计算机学院,湖北 武汉 430070)
随着城市的快速发展,城市道路上的车辆逐日增多,留下海量的轨迹数据。这些轨迹数据较传统交通数据具有覆盖面广、实时性高等突出特点,具有巨大的利用潜力。如何使用大规模轨迹数据处理交通和道路问题,是世界各国智能交通领域研究的热点,各种研究成果如雨后春笋般涌现,目前主要应用领域有路网更新[1]、交通决策[2]、道路堵塞疏通[3]、交通拥堵评价[4]、动态交通诱导[5]和城市交通综合评估[6]等。
交通拥堵已成为我国的一个老大难问题,严重影响了人民群众生活,制约了社会经济的发展[7],因此笔者着重探讨轨迹大数据在交通拥堵评估和预测方面的应用,建立了一种基于深度学习的城市短时交通拥堵评估和预测模型。
1 数据处理
1.1 评估参数
笔者采用交通流参数对交通拥堵状况进行评估[8],3个主要的交通流参数分别是交通量f、交通流速度v、交通流密度k。其计算公式为:
f=N/t
(1)
式中:N为通过该路段的车辆数;t为时间。
v=L/t
(2)
式中:L为道路总长度;t为道路上所有车辆穿过道路所用的平均时间。本文对交通流速度的计算采用某段道路上所有车辆速度的平均值。
k=N/L
(3)
式中:N为路段内车辆数,L为路段总长度。
由式(1)~式(3)可得到交通流密度与交通量和交通流速度的关系:
k=f/v
(4)
1.2 数据预处理
研究样本为北京市2012年11月1日到8日的城市出租车交通数据,以市北二环的一条道路为研究目标。数据预处理流程如图1所示。

图1 数据预处理流程图
使用MATLAB R2016a批量读取数据,未经处理的每一天的数据在三千万条左右,将范围锁定在目标道路后,每一天的数据在三百万条左右,每一条数据包括9个数据项,它们分别是车辆标识、触发事件、运营状态、GPS时间、GPS经度、GPS纬度、GPS速度、GPS方向和GPS状态。
由于研究目标为短时交通流,提取每两分钟的数据,因此一天共分为720个时间点。然后求出目标道路每一时间点的交通量f、速度v和密度k,处理结果如表1所示。因原表格过大,此处只截取前5段数据。

表1 交通流部分参数
2 交通状况评估模型
对平均车速v、交通量f和交通流密度k进行权值配置,得到评价交通状况的综合参数,根据评价区间判断道路的交通状况。但3个参数的量纲互不相同,需要对参数进行归一化处理,参照文献[9]的方法对处理后的参数进行权值配置,得到综合参数。
计算出路段在若干时间点的平均车速v、交通量f和交通流密度k,即得到交通状况指标向量F,如式(5)所示。
F={(v1,f1,k1),(v2,f2,k2),…,(vn,fn,kn) }
(5)
对于路段在第i个时间点的平均车速vi、交通量fi和交通流密度ki进行权值配置,权值矩阵B定义如式(6)所示。
B=[b1,b2,b3]=[0.45,0.10,0.45]
(6)
式中:b1为平均车速的权值;b2为交通量的权值;b3为交通流密度的权值。
根据交通状况指标向量F和权值矩阵B可得交通状况综合参数C为:
C=F×BT
(7)
(8)
式中:ci为第i个时间点该路段的交通状况综合参数。
为方便后续数据处理,利用标准函数法对交通状况综合参数C进行归一化处理:
(9)
式中:cmin,cmax分别为综合参数向量C中的最小值和最大值。
城市道路交通拥堵评价指标体系将道路分为城市道路和高速公路,将路段的平均行程速度划分为5个等级,1级表示运行最拥堵,5级表示运行最畅通,如表2所示。

表2 路段平均行程速度等级划分
对北京二环北端路段8天交通数据,以两分钟为时间间隔进行数据采样,利用表2判断道路交通拥堵情况。
根据式(5)~式(9)得到当日北二环交通状况综合参数如图2所示。
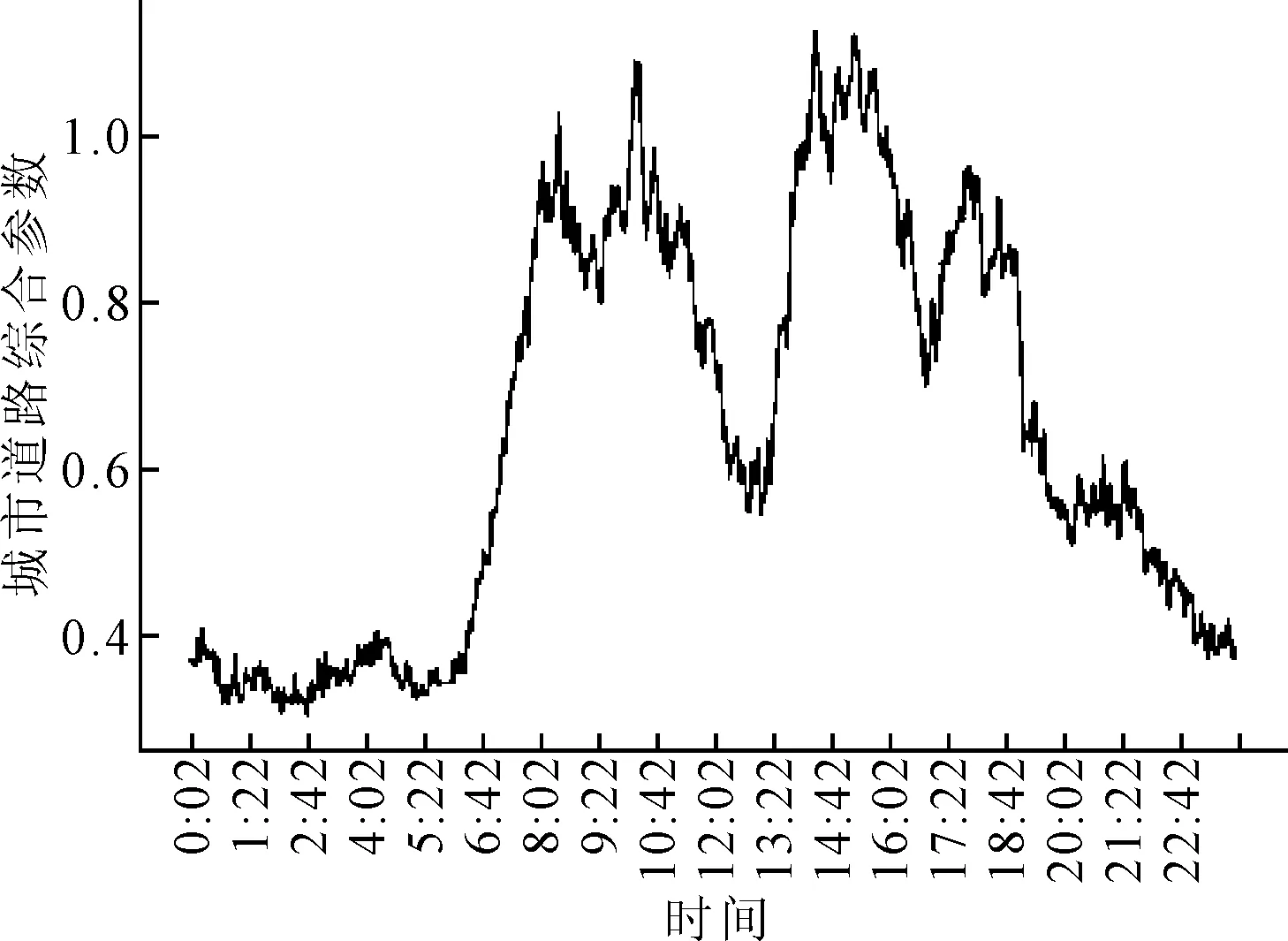
图2 11月8日北京市北二环交通状况综合参数
根据表2可知,在图2中11月8日北京市北二环在0:00~6:40交通较为通畅,在6:40~8:00交通状况逐渐变得拥堵,在8:00~11:00交通较为拥堵,在11:00~13:00拥堵有所缓解,在13:00~19:00交通较为拥堵,在19:00~24:00交通逐渐好转,与日常认知基本一致。同时可以看出北二环在中午最为拥堵,同时存在早晚高峰的情况。
3 交通拥堵预测模型
将北京市北二环11月1日~8日共计8天的交通数据作为数据集,并利用长短期记忆模型(long short-term memory,LSTM)建立交通拥堵预测模型,实现参数向量的数字化表达,通过参数向量一段时间的数据变化预测参数向量的走势。选择均方误差(mean square error,MSE),均方根误差(root mean square error,RMSE),平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percent error,MAPE)作为评价指标,将长短期记忆模型(LSTM)与向量回归模型(support vector regression,SVR)和循环神经网络模型(recurrent neural netwok,RNN)进行对比,最后得出LSTM模型的预测结果并进行评价。
3.1 模型建立
LSTM[10]是一种特殊的RNN网络,LSTM结构的特点是利用遗忘门、输入门和输出门优化RNN网络,有效解决了梯度消失或梯度爆炸的问题。LSTM的相关方程如式(10)~式(15)所示[11]。
ft=σ(Wfht-1+Ufxt+bf)
(10)
it=σ(Wiht-1+Uixt+bi)
(11)
(12)
(13)
ot=σ(Woht-1+Uoxt+bo)
(14)
(15)
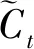
将已有的参数向量数据分为训练集和测试集两部分,训练集用于训练已有的LSTM网络,测试集用于验证LSTM网络的预测效果。具体步骤为:对采集的道路交通数据进行数据预处理并构建数据样本集,将样本集数据送入LSTM循环神经网络进行模型训练,并导出网络参数,建立短期交通拥堵的预测模型。其流程如图3所示。

图3 交通拥堵预测流程图
为避免过拟合,在LSTM层后加入Dropout层,增加每层各个特征之间的正交性,在最后加入输出层。每次将30个数据送入LSTM循环神经网络进行训练,为了提高训练精度,每次将最新的数据带入网络进行更新,使预测结果更加准确。
3.2 预测结果
仿真环境为window10系统(64 bit),Python选用Anaconda下3.7.5版本,编译器为pycharm(2020.2),keras,sklearn的集成开发库。支持向量回归模型选用linearSVR模型,C=1.25。RNN模型中第一层RNN网络神经元数为80,第二层RNN网络神经元数为100,第一层和第二层Dropout网络屏蔽率均为0.2。LSTM模型中第一层LSTM网络神经元数为80,第二层LSTM网络神经元数为100,第一层和第二层Dropout网络屏蔽率均为0.2。
将11月1日~7日的数据作为训练集,8日数据作为预测集,linearSVR模型、RNN模型和LSTM模型的预测效果如表3所示。

表3 各模型交通状况综合参数预测效果
从表3可知,LSTM模型的预测结果在各个指标上均好于linearSVR模型和RNN模型,具有较好的预测效果。
linearSVR模型、RNN模型和LSTM模型的预测结果和实际结果对比如图4~图6所示。通过比较发现,长短期记忆模型(LSTM)具有较好的预测效果,可以为有关部门的决策提供依据,改善交通状况。

图4 linearSVR模型预测结果和实际结果对比图

图5 RNN模型预测结果和实际结果对比图

图6 LSTM模型预测结果和实际结果对比图
4 结论
通过读取海量轨迹数据,获得了平均车速、交通量和交通流密度,并对上述数据进行加权计算得到了交通状况综合参数,建立了合理的交通状况评估模型。将深度学习的方法应用到交通状况预测模型中,分析比较了不同神经网络的精度,并通过比较发现,长短期记忆模型(LSTM)具有较好的预测效果,可为决策分析提供有价值的参考。
猜你喜欢
中国交通信息化(2022年4期)2022-06-17 01:05:00
中国交通信息化(2019年4期)2019-07-13 05:51:36
中国交通信息化(2018年6期)2018-08-29 01:19:34
中国交通信息化(2017年5期)2017-06-06 07:20:05
北方交通(2016年12期)2017-01-15 13:52:51
西南交通大学学报(2016年3期)2016-06-15 20:29:35
中国工程咨询(2016年1期)2016-02-14 06:47:44
地理教学(2015年20期)2015-12-17 15:33:14
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:12
中国交通信息化(2014年7期)2014-06-05 03:18:41
