
基于信息熵与词长信息改进的TFIDF算法
2021-03-29 03:24金燕,黄杰
浙江工业大学学报 2021年2期
金 燕,黄 杰
(浙江工业大学 信息工程学院,浙江 杭州 310023)
文本分类是自然语言处理、数据挖掘、搜索等领域中不可缺少的技术。文本分类中以提取到的特征词与计算得到的特征词权重来表达文本,表达后的文本给分类器训练,训练好的分类器可以将未知类别的文本识别为分类器已知类别的文本。在文本分类中,文本的表达方法有向量空间模型(VSM)、布尔模型[1]与概率模型。Salton等[2]提出的向量空间模型(VSM)是常用的文本表达方法,以文本中各个特征词的权重为向量来表示文本。分类任务中常用KNN、朴素贝叶斯、SVM[3]、神经网络[4]等算法作分类器,神经网络不仅在图像识别[5]任务中有着较好的识别结果,而且在文本分类中仍然有不错的分类效果。
为了保证Web文本信息准确度高的特点,要求文本分类具有较高准确率的分类效果[6-7],而分类准确率很大程度受到特征提取效果的影响。在文本分类中特征提取的方法有互信息[8]、卡方检验[9]、信息增益[10]与TFIDF[11]等。其中,Jones[12]提出的TFIDF算法是最常用的文本特征提取算法,TFIDF涉及到两个概念:特征词在文本中的频率与特征词的逆文本频率。传统的TFIDF算法存在着严重的缺陷,学者们针对传统TFIDF算法的不足提出了改进。为了解决文本集偏斜带来的问题,How等[13]提出了描述类别词的方法,用特征词在类别中的总频数代替TFIDF的词频因子。针对传统算法中没有考虑到类别间的信息,徐冬冬等[14]引入描述类别因子,提出了包含类别信息的改进算法,提高了分类的平均准确度。周炎涛等[15]引入词条信息熵,描述词条在类别间的分布,解决了IDF忽略文本数据集中特征分散的问题。一些研究者将文本中特征词的位置[16]、长度等因素加入到权重计算中,杨彬等[17]提出特征词的长度不同能够表达的信息也不相同,提出了一种结合词长信息改进的TFIDF算法(TFIDFL),相比于传统的TFIDF算法,加入词长信息后的算法在分类性能上有了提升。但是,文献[17]中使用的方法不能准确地描述词长特征,并且以上的改进方法都缺少了词条在文本中的分布特征。笔者改进文献[17]中描述词长信息的因子并以文本内词条信息熵反映特征词在文本中的分布特征来改进传统的TFIDF算法,改进后的算法通过使用不同的分类器,使得文本分类在多个性能指标方面得到较大提升。
1 相关研究
1.1 TFIDF算法
TFIDF的核心思想是词条t在该文本内出现的频率大,文本集中包含词条t的文本数量少,则认为该词条可以清楚地区分文本。TFIDF算法为
(1)
式中:tf为词条t在文本中出现的频数;n为包含词条t的文本个数,加0.01是为了防止分母为0;N为总的文本数量。在文本长度不同的情况下,仅以词频来度量特征词在文本内的权重会出现偏差,为了避免词频对长文本的偏袒问题,将词频除以文本长度对词频进行规范化,得到规范化后的计算式为
(2)
式中:m为词条t在文本中出现的个数;s为文本中词条的总数量。TFC[18]是最为广泛使用的TFIDF算法,目前对TFIDF算法的研究都是基于TFC进行的,它是将式(2)中的算法进行了归一化,归一化后的计算式为
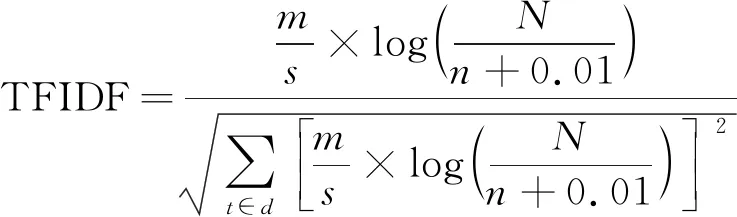
(3)
式中:t为文本中的词条;d为文本;分母为归一化因子。
1.2 TFIDF存在的问题
1) TFIDF中仅以词频TF与逆文档频率IDF为计算权重的因子,忽略了词长信息,不同的词长能够表达的信息也不一样,而传统算法中缺少了这个重要的因子。实验证明缺少词长因子严重地影响了分类器的分类准确性。
2) 传统的TFIDF算法中仅以词频来表达特征词在文本中的权重是不准确的,它忽略了文本中特征词的分布特征,导致了分类准确率低。实验证明词条信息熵可以准确地反映文本中特征词的分布特征。
2 改进的TFIDF算法
2.1 信息熵
熵是热力学中表达系统混乱程度的度量,香农将熵引入信息论中来表示信源的不确定性,它是对一个随机事件发生不确定性的度量[19],熵越大表示不确定性越大。信息熵的计算式为
(4)
式中:G为系统的信息熵;pk为词条的分布概率,分布越平均的词条,其对应的信息熵也越大。周炎涛等[15]引入信息熵,描述词条在类别间的分布,将词条信息熵的倒数叠加到TFIDF算法中得到了TFIDFu算法,然而TFIDFu算法对分类性能的提升并不明显。笔者以引入词条信息熵来反映特征词在文本内的分布特征的方法改进TFIDF算法,给出文本中词条信息熵的计算式为
(5)
式中:H(t)为文本内的词条信息熵;p(t)为词条t在文本中的分布概率。加入词条信息熵后的改进TFIDF算法为
(6)
通过实验,HIDF算法与传统的TFIDF算法相比,在分类的准确率、查全率以及F值上都有了较大的提升。使用相同的训练集与测试集,在逻辑回归分类器上,TFIDF算法的平均准确率为85.73%,改进算法HIDF的平均准确率达到92.02%,比TFIDF高出6.29%,表明引入信息熵的思想能够有效地改进TFIDF算法的不足,提升文本分类的准确度。
2.2 词长信息
传统的TFIDF算法中并未考虑到词长信息,它将所有长度不同的词条都统一对待,算法损失了词长信息这一重要的部分。叶雪梅等[20]也提到,词条短的词能够包含的信息少,词条长的词能够包含的信息多,词长也是衡量特征词权重的关键因素。实验证明了加入词长信息后的算法能够提升文本分类的各项性能指标。笔者提出了衡量词条长度信息的重要因子为
Lt=log(a×l+b)
(7)
式中:Lt为词条t的词长权重;l为词条t的长度;a为控制词长信息增长快慢的因子;b为偏置。经过10组的调参实验,最终将a确定为1.2,b确定为5,此时算法能够达到较优的效果。在式(3)的基础上加入词长信息后的算法计算式为
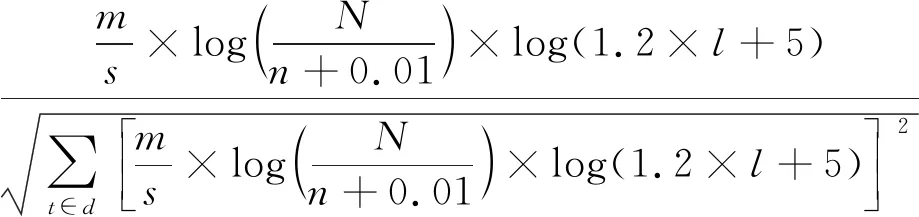
(8)
式中:m为词条t在文本中的数量;s为文本词条的总数量;N为文本总数;n为包含词条t的文本数;d为文本。加入词长因子Lt的TFIDFLT算法在逻辑回归分类器上,平均准确率达到了89.42%,杨彬等[17]提出的算法在逻辑回归分类器上,平均准确率达到了87.08%。实验证明:TFIDFLT算法提出的描述词长信息的方法更为合理,并弥补了TFIDF词长信息缺陷的问题。
通过同时结合词条信息熵与加入词长因子,提出了一种改进的TFIDF算法,其计算式为
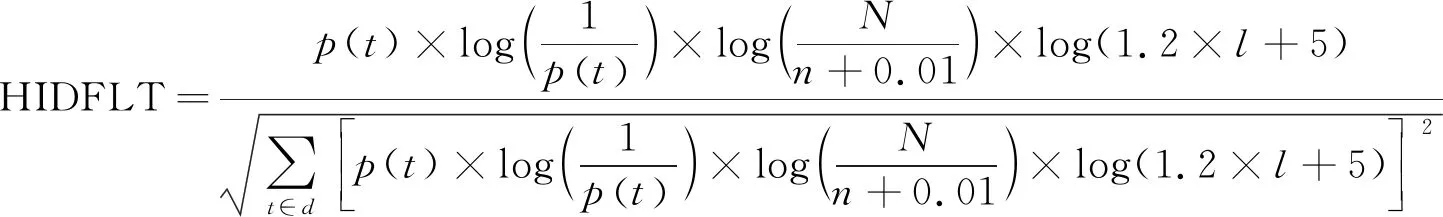
(9)
式中:p(t)为词条t在文本中的分布概率;N为总的文本数量;n为包含词条t的文本数量;l为词条t的长度;d为文本。通过实验验证了式(9)算法优于HIDF、TFIDFLT算法。
2.3 算法复杂度分析
对笔者的HIDFLT算法进行时间复杂度与空间复杂度分析,假设文本长度为M,文本总数为N。式(9)中HIDFLT算法由特征词的信息熵H、词长因子LT与逆文本频率IDF组成。H与LT因子可以同时进行计算即H×LT,遍历文本求得特征词的频率,根据式(5,7)求得H×LT,此时算法的时间复杂度为O(M×1)。求IDF时需对所有文本进行遍历,同时判断文本中是否包含所求特征词,计算出包含所求特征词的文本个数,最终求得IDF,遍历所有文本的时间复杂度为O(N),判断文本中是否包含所求特征词的时间复杂度为O(M),故求IDF时的时间复杂度为O(MN)。HIDFLT算法的时间复杂度为O(M)+O(MN)。若所有文本中的词都相同,则算法额外的空间复杂度为O(1),若文本中的所有词都不同,则算法额外的空间复杂度为O(MN),HIDFLT算法的空间复杂度介于O(1)与O(MN)之间。传统TFIIDF算法的时间复杂度与空间复杂度的分析过程与分析结果与HIDFLT算法相同,改进后的算法复杂度没有增加,并对文本分类有更好的分类结果。
3 实 验
3.1 实验环境
实验用电脑硬件配置为CPU为Intel i7-5500U、内存为8 G,编译环境为jupyter notebook,编译语言python3.7,使用的分类器为python3.7下sklearn中的逻辑回归、KNN和多项式朴素贝叶斯等分类器,分类器的参数设置为默认参数。实验数据集选用了10 个类别分别的文本,分别为教育、家居、时尚、体育、财经、科技、时政、游戏、房产和娱乐等,每个类别有400 个文本,总共4 000 个文本作为训练数据集,测试集有10 000 个文本,分成10 个小测试集,每个测试集有1 000 个文本,测试集中每个类别有100 个文本。
3.2 实验流程
文本分类的过程包括语料预处理、文本分词、去停用词、特征提取和分类器等训练,如图1所示。
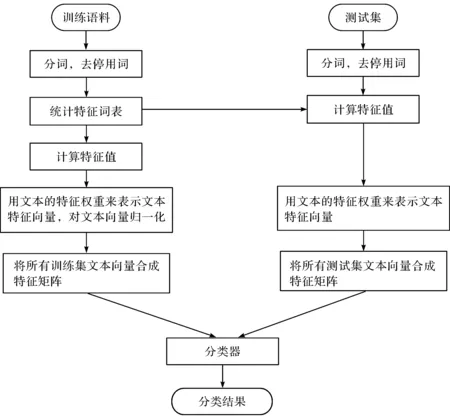
图1 文本分类流程图
实验流程如图1所示,对训练文本预处理,使用jieba分词对文本分词,分完词后的文本消去停用词,将一些无意义的词、符号与表情等消去。用处理完的文本统计出特征词表,按照特征词表的顺序,使用特征提取算法计算文本中特征词的特征值。使用文本的各个特征值组成特征向量来表示文本,对文本向量归一化,将训练集中的所有文本向量合成特征矩阵,把特征矩阵输入给分类器训练。测试集使用训练集中的特征词表对测试集文本提取特征,最后将得到的特征矩阵输入分类器,得到分类结果。
实验纵向对比了已有的传统的TFIDF算法与笔者提出的改进算法TFIDFLT、HIDF和HIDFLT的分类性能,实验结果证明了对传统的TFIDF算法的改进能够提升分类性能。横向对比方面,将笔者提出的HIDFLT算法与已有的TFIDF、TFIDFL和TFIDFu算法进行来了对比实验,结果证明了笔者提出的HIDFLT算法在逻辑回归、KNN和朴素贝叶斯分类器上的分类性能相比其他算法有了较大的提升。
3.3 评价指标
评价文本分类性能的指标有准确率、查准率(precision)、查全率(recall)、F值[21],准确率为分类正确的文本数除以总的文本数,文本分类结果指标如表1所示。

表1 分类结果指标
查准率为分类器正确地判断为该类的文本数量与判断为该类的文本总数的比值,体现了分类结果的准确性,其计算式为
precision=A/(A+B)
(10)
查全率是正确的判断为该类的文本数与实际上该类的总文本数的比值,体现出了分类结果的完备性,其计算式为
recall=A/(A+C)
(11)
查准率与查全率是相互制衡的,而F值则是调和查准率与查全率的,文本分类中常用F值来衡量分类性能的好坏,其计算式为
F=2×precision×recall/(precision+recall)
(12)
4 实验结果与分析
4.1 纵向对比实验
纵向对比实验是将已有的传统的TFIDF算法与笔者提出的改进算法TFIDFLT、HIDF和HIDFLT的分类结果作对比,实验使用了相同的环境与数据集,实验结果得到10 组测试集的平均准确率、查全率以及F值,查准率如表2所示。
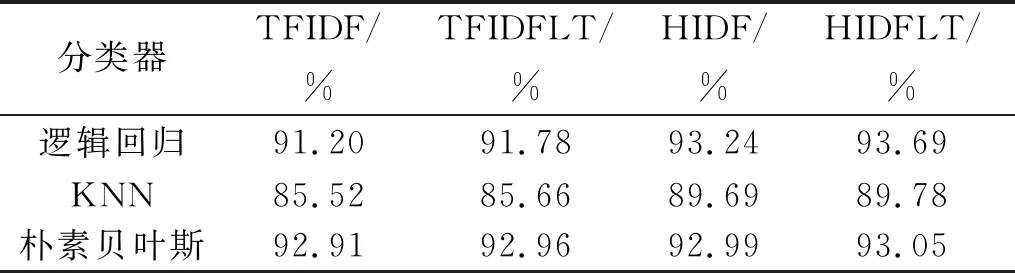
表2 纵向对比实验的查准率
观察表2,针对传统的TFIDF算法的改进算法TFIDFLT、HIDF和HIDFLT在逻辑回归、KNN和朴素贝叶斯分类器上的查准率都比TFIDF高,加入词长信息和引入词条信息熵能够提升分类结果的查准率,同时加入词长因子与引入词条信息熵的HIDFLT算法在多个分类器上的准确率都是最高的,证明HIDFLT算法能够有效地提高分类的查准率。
图2为纵向对比的分类准确率,对TFIDF算法逐一改进后,在不同的分类器上分类准确率都有提升。TFIDFLT在TFIDF算法上加入了词长信息因子后,可以发现文本的分类准确率在逻辑回归上有较明显的提升,在KNN与朴素贝叶斯分类器也有略微的提升,证明了词长信息是特征提取中不可缺少的重要因素。对比HIDF与TFIDF算法,在逻辑回归与KNN分类器上HIDF的平均准确率有较为明显的提升,在朴素贝叶斯上有略微的提升,结果证明了引入的词条信息熵能够准确地反映特征词在文本中的分布特征。
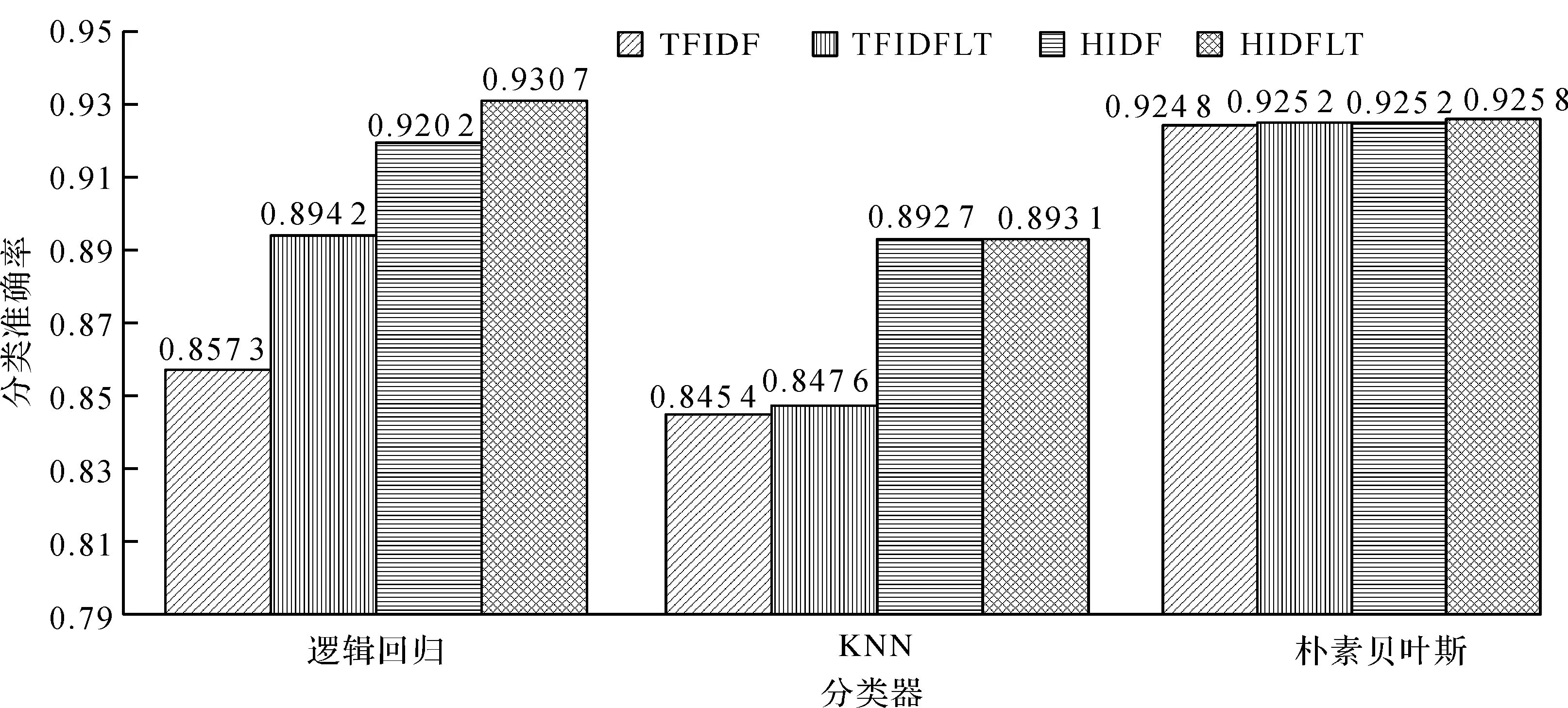
图2 纵向对比的分类准确率
纵向对比实验的查全率如表3所示,针对TFIDF缺陷改进的算法TFIDFLT、HIDF和HIDFLT的查全率全都比TFIDF算法的高。在TFIDF算法基础上加入词长因子与引入词条信息熵能够有效地提升分类结果的查全率。同时加入词长因子与引入词条信息熵的HIDFLT算法在多个分类器上的查全率都是最高的,证明了HIDFLT算法改进的有效性。
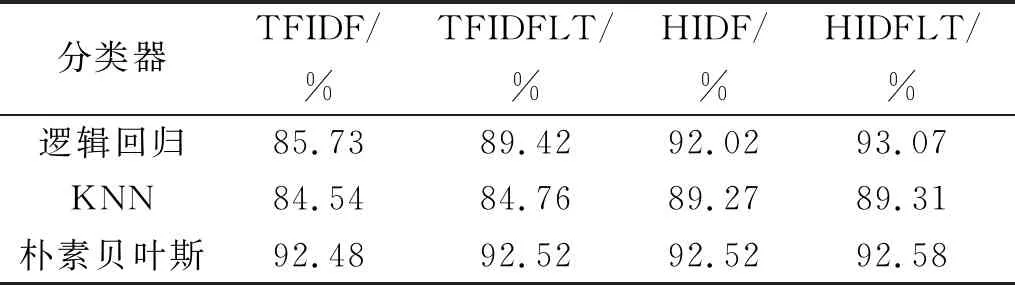
表3 纵向对比实验的查全率
结合表4与图2可以观察到:引入词条信息熵与词长因子的HIDFLT算法的平均准确率与综合性能F值都高于TFIDF、HIDF与TFIDFLT算法,实验结果充分证明了引入词条信息熵与词长信息的思想能够弥补传统TFIDF算法的缺陷,提升算法的性能。
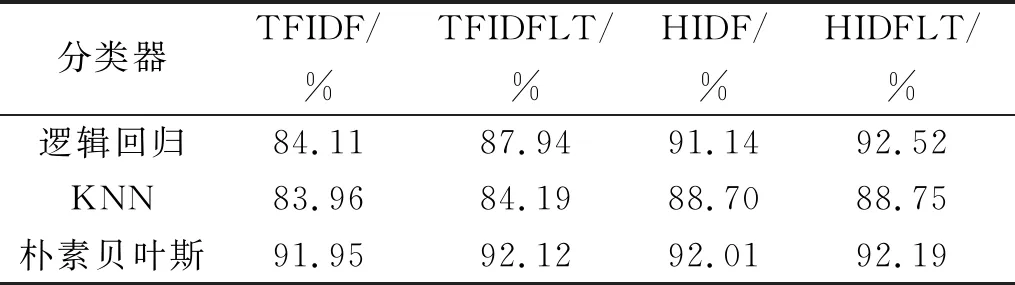
表4 纵向对比实验的F值
4.2 横向对比实验
使用TFIDF、TFIDFL、TFIDFu与HIDFLT等特征提取算法对10 组测试集进行多分类,分类的平均准确率、查全率与F值的结果如图3所示。
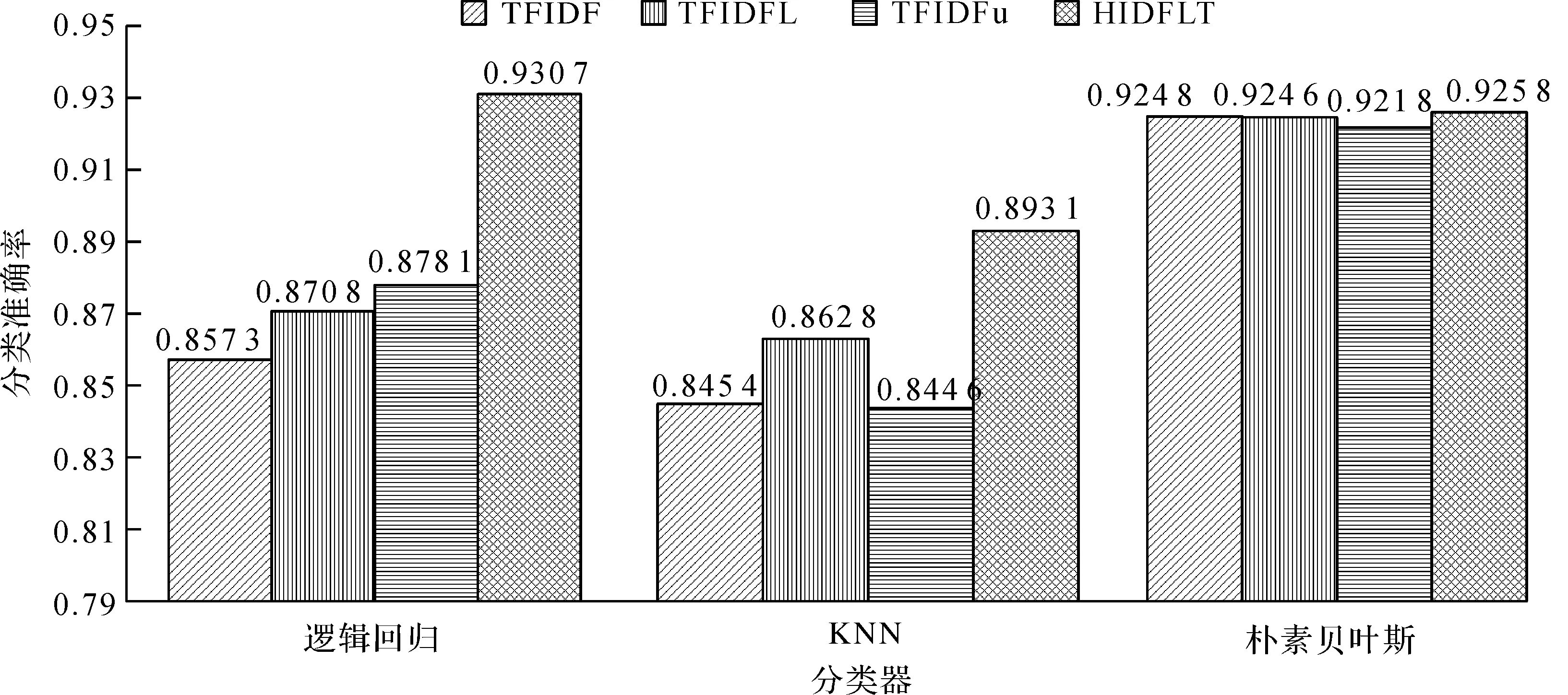
图3 横向对比的分类准确率
观察图3,HIDFLT算法在多个分类器上的分类准确率都比其他的特征提取算法的分类准确率要高。在逻辑回归分类器上,HIDFLT算法的分类准确率比TFIDF算法高了7.34%,比文献[17]提出的TFIDFL算法高了5.99%,比文献[15]提出的TFIDFu算法高了5.26%。在KNN分类器上,HIDFLT算法的分类准确率比TFIDF算法高了4.77%,比TFIDFL高了3.03%,比TFIDFu高了4.85%。在朴素贝叶斯分类器上,HIDFLT与对比的特征提取算法的分类准确率相差无几,HIDFLT仍然能够达到最高的92.58%。实验结果表明:引入词条信息熵与词长信息的HIDFLT算法相比与其他改进的算法有着较优的准确率。
表5为横向对比实验的查准率,笔者改进的算法HIDFLT与现有的TFIDF、TFIDFL和TFIDFu算法在多个分类器上对比,HIDFLT算法的查准率是最高的,证明了同时引入词条信息熵与加入词长信息改进TFIDF算法较于其他已有算法有较优的查准率。
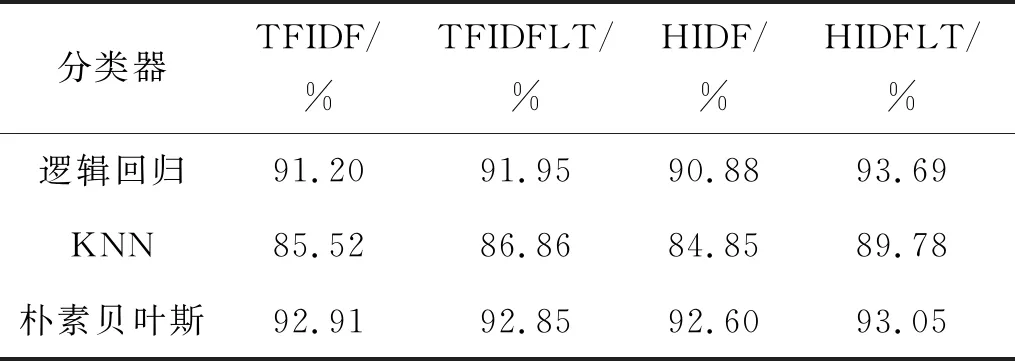
表5 横向对比实验的查准率
表6是横向对比实验的查全率,观察表6可知HIDFLT算法在多个分类器上的查全率都是最高的。在逻辑回归分类器与KNN上HIDFLT算法的查全率明显的高于其他的特征提取算法,在朴素贝叶斯分类器上的查全率,各特征提取算法没有明显的差别,HIDFLT算法的查全率仍然是最高的,HIDFLT算法对比其他特征提取算法的分类结果更加完备。文本分类中,常用F值来衡量分类的综合性能,对比实验的平均F值如表7所示。
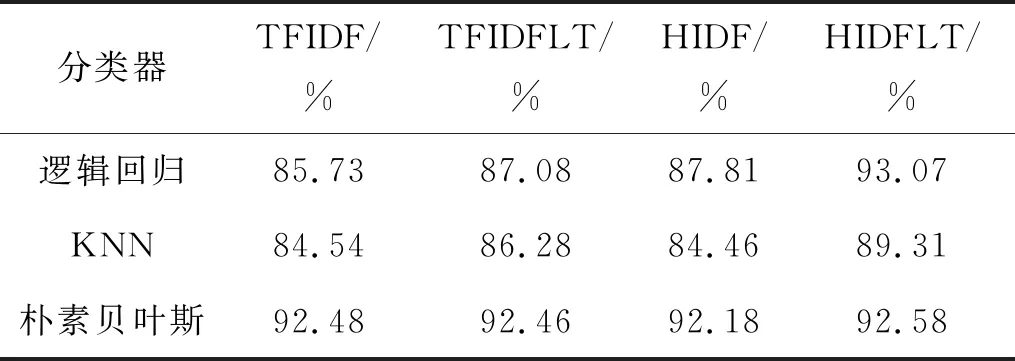
表6 横向对比实验的查全率
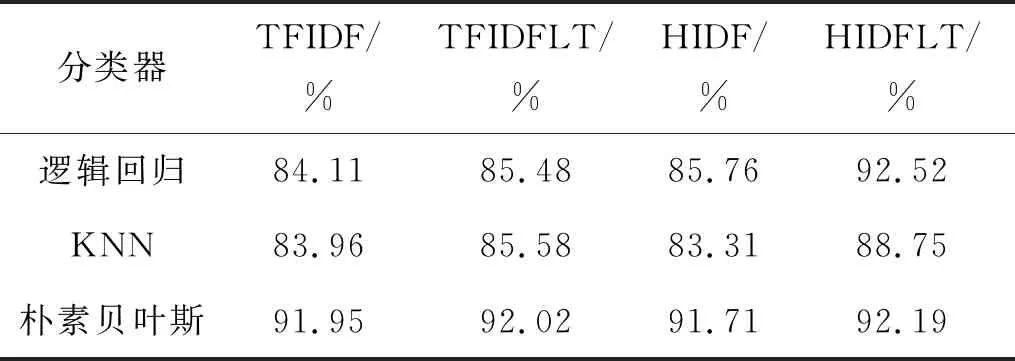
表7 横向对比实验的F值
结合F值、查全率与准确率,可以发现HIDFLT算法在分类结果的各项性能指标上都比其他算法高。从纵向实验与横向实验的结果看:HIDFLT算法不仅改进了TFIDF算法的缺陷,而且对比其他算法有着较优的分类性能。
5 结 论
面临大数据时代,不管在数据挖掘、自然语言处理还是推荐系统领域中,文本分类对于日常的工作与学习有着很大的帮助,而文本分类过程中特征提取算法对文本分类的结果有较大的影响,将笔者提出的HIDFLT算法在文本分类中与其他改进的算法进行了对比,分析了算法间的优缺点并证明了该算法拥有较高的性能效果。自然语言处理领域中,不仅仅只有文本分类需要提取文本的特征信息,在情感分析中也需要对情感信息进行特征提取,接下来的工作将改进的算法应用于情感分析中并对其作出适合于情感分析的改变,对用户的情感信息有较真实的反馈。在搜索与推荐领域中,特征提取也较大地影响着推荐的效果,性能较好的特征提取算法为用户带来较准确的推荐结果,为用户带来良好的体验。TFIDF使用的领域较宽广,对不同的落地场景作出最适合的改变,以提高最后使用的性能。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
电脑知识与技术·经验技巧(2020年3期)2020-05-07
现代信息科技(2020年18期)2020-02-22
现代电子技术(2018年20期)2018-10-24
计算机应用与软件(2018年1期)2018-02-27
现代情报(2018年11期)2018-01-07
中国管理信息化(2009年10期)2009-06-19
