
金融领域中文命名实体识别研究进展
2021-03-14 13:35:01徐秋荣朱鹏罗轶凤董启文
华东师范大学学报(自然科学版) 2021年5期
徐秋荣 朱鹏 罗轶凤 董启文

摘要:命名实体识别(Named Entity Recognition, NER)作为自然语言处理的基本任务之一,一直以来都 是国内外研究的热点.随着金融互联网的快速发展,迄今为止,金融领域中文NER不断进步,并得以应用 到其他金融业务中.为了方便研究者了解金融领域中文NER方法的发展状况和未来发展趋势,进行了一 项相关方法的研究和总结.首先,介绍了 NER的相关概念和金融领域中文NER的特点;然后,按照金融领 域中文NER的发展历程,将研究方法分为基于字典和规则的方法、基于统计机器学习的方法和基于深度 学习的方法,并详细介绍了每类方法的特点和典型模型;接下来,简要概括了金融领域中文NER的公开数 据集和工具、评估方法及其应用;最后,向读者阐述了目前面临的挑战和未来的发展趋势.
关键词:自然语言处理;中文命名实体识别;金融领域
中图分类号:TP399 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.001
Research progress in Chinese named entity recognition in the financial field
XU Qiurong, ZHU Peng, LUO Yifeng, DONG Qiwen
(School of Data Science and Engineering, East China Normal University, Shanghai 200062, China)
Abstract: As one of the basic components of natural language processing, named entity recognition (NER) has been an active area of research both domestically in China and abroad. With the rapid development of financial applications, Chinese NER has improved over time and been applied successfully throughout the financial industry. This paper provides a summary of the current state of research and future development trends for Chinese NER methods in the financial field. Firstly, the paper introduces concepts related to NER and the characteristics of Chinese NER in the financial field. Then, based on the development process, the paper provides an overview of detailed characteristics and typical models for dictionary and rule-based methods, statistical machine learning-based methods, and deep learning-based methods. Next, the paper summarizes public data collection tools, evaluation methods, and applications of Chinese NER in the financial industry. Finally, the paper explores current challenges and future development trends. Keywords: natural language processing; Chinese named entity recognition; financial field
0引 言
在日常生活中,隨着科技的进步和互联网的快速发展,网页新闻、研报、论坛、公众号、微博等信 息不断实时更新,使得网络信息量呈爆炸式增长,海量的结构化、半结构化、非结构化文本数据为自 然语言处理任务提供了数据来源,并促进自然语言处理技术的快速发展.面对结构各异、信息冗杂的
收稿日期:2021-08-17
基金项目:国家自然科学基金(U1711262, 6207218(5)
通信作者:罗轶凤,男,副教授,硕士生导师,研究方向为文本数据挖掘与知识图谱.E-mail: yfluo@dase.ecnu.edu.cn
文本数据,如何提取出关键性的有价值信息,是一项有意义的科研工作,信息抽取技术便应运而生.命 名实体识别作为信息抽取的子任务之一,是指从文本中识别出实体及其类别,这些实体类型包括人 名、地名、机构名、专有名词和时间等.同时,作为自然语言处理中的关键技术之一,命名实体识别为 其他自然语言处理任务,诸如信息检索、知识问答系统、文本摘要、知识图谱、关系抽取等奠定了基 础,因此得到国内外科研工作者的广泛关注.
命名实体识别的研究可以追溯到1991年,Rau[1]最初开展的是从文本中识别并抽取企业名称的工 作,随后有研究者将专有名词也加入有待识别实体.美国NIST自动内容抽取(Automatic Content Extraction, ACE)评测中根据实体在文本中的引用把它分为命名性指称、名词性指称和代词性指称. “命名实体”(Named Entity, NE)这一术语是在MUC-6中提出的,是针对ACE中的“名词性指称”称 呼,后来MUC-6组织了 NERC这项评测任务,即命名实体识别和分类(Named Entity Recognition and Classification, NERC).人们将人名、地名和组织机构名这3类实体进一步细化,例如,将地名细 化为洲、国家、城市、州、自然景观区域等.在计算自然语言学习会议(Conference on Computational Natural Language Learning,CoNLL)评测会议中扩大了专有名词的范围,如书籍名、电影名、产品 名、医药名等[2]. NER发展至今,已经衍生了许多解决该任务的方法,模型效果也在逐渐提升,研究语 言包括但不限于英语、中文、阿拉伯语、德语、法语等.NER的应用已经渗入商业、金融、电子病历、 网络安全、生物医学、军事、生态治理、农业等多种垂直领域中.
自21世纪初期,我国金融科技行业逐渐由手工转为互联网金融信息化,人工智能技术与金融业 务不断融合,许多学者投入通过命名实体识别将文本和金融业务中的实体信息关联起来的科研工作 中,其科研成果为用户提供了更优质的金融智能化服务[3].相比于通用领域中文NER,金融领域中文 NER除了人名、地名、机构名的识别以外,还包含属于专业领域的金融实体,如金融公司名、公司名 简称、金融产品名称、金融项目名称、金融专业名词等.金融领域中文NER的新挑战在于3点.其一 是组织机构名的识别:金融文本中的组织机构名长度变化大,并且机构名实体中经常含有人名、地名 和未登录词,构成嵌套实体问题;对于同一个机构的表达方式多样,从全称中抽取个别字组成新的不 同简称,甚至有一些网络昵称,如腾讯的昵称为“鹅厂”;金融领域的组织机构名的命名规则变化多样, 没有统一的格式进行约束.其二是金融术语的识别:金融术语是一种复杂类型实体并且存在较多的新 实体,常用的分词工具难以较好地切分专业名词的边界;金融文本中经常出现中文、英文和数字混合 组成的实体名;术语的口语化表述方式造成歧义识别;领域性含义的实体,如轨道、杠杆、板块等.其 三是缺乏实体丰富且有质量的金融领域数据集供实验研究.随着互联网日新月异的变化,金融实体的 数量也在不断大量增长,并且金融实体在文本中内容分散、数据稀疏、无结构化等特点,使得通用领 域的NER模型直接应用在金融领域中文NER数据集上的效果不显著,需要根据金融文本特征探索 新方法.
近年来,有不少文献对NER的国内外研究方法进行了梳理.Li等详细整理了针对英文语料的 NER方法,尤其是基于深度学习的模型;李嘉欣等问详细整理了针对中文语料的NER方法;Nadeau 等[6]主要介绍了统计学习方法在NERC中的應用.在金融领域中,中文命名实体识别作为金融文本的 其他自然语言处理任务的基石,用科学技术促使金融业务变得更加智能化.然而,针对中文命名实体 识别在金融领域中应用的综述几乎没有,这促使本文进行一项有关金融领域中文命名实体方法的调 查,阐述相关技术的研究现状,梳理并总结现有科学技术在金融领域中文NER中的效果,以发现金融 领域中文NER仍然存在的问题以及其他可探索的研究方法.
本文深入调查了中文命名实体识别在金融领域中的应用.首先介绍NER的有关概念及其在金融 领域中的特点,然后将金融领域中文NER方法分为3大类:基于规则和字典的方法、基于统计机器学 习的方法、基于深度学习的方法.基于深度学习的方法按照模型的训练模式分为单任务学习和多任务 联合学习,对金融领域中文NER公开数据集和工具进行简单介绍,之后详细阐述有关的评估方法.此 外,本文还搜集了金融领域命名实体识别的应用,最后介绍金融领域中文NER仍然面临的挑战和未 来的发展方向,并对本文做出总结.
1概念
首先介绍NER的有关概念,包括NER的定义、NER的标注方法、金融领域中文NER的特点.
1.1 NER的定义
NER,即命名实体识别,是指从非结构化的自然语言文本中识别出具有特定意义的实体并将这个 实体归为预先设定好的类别中实体通常代表一个具体的事物,通用领域中的实体主要包括人名、地 名、机构名、专有名词、时间、日期和货币等.
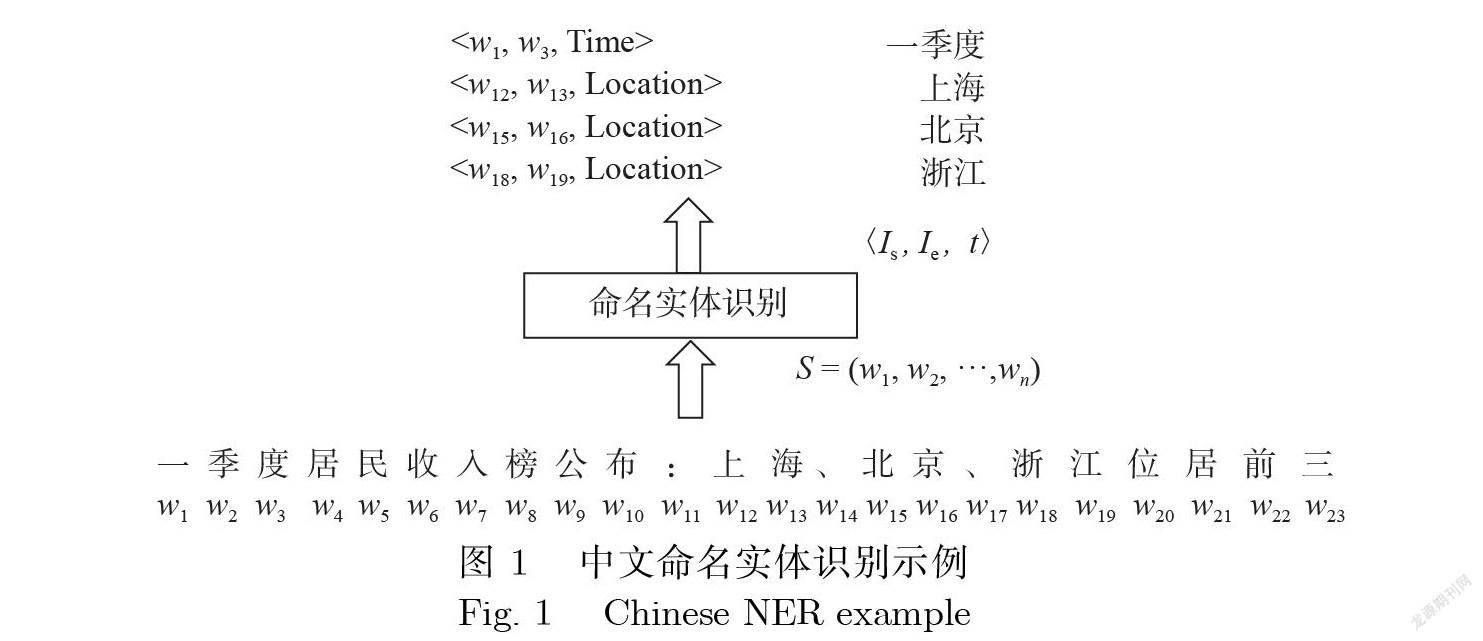
NER的形式化定义是指给定一段文字序列(叫,奶,..+,叫),识别出1组元组1个 元组代表1个实体,其中叫表示1个输入的字或词,is表示实体的开始下标,ie表示实体的结束下标, 尤表示实体的类型[4].如图1所示是1个NER任务示例,对给定的序列通过NER识别输出4个实体, 分别是“一·季度”(Time)、“上海”(Location)、“北京"(Location)和“浙江"(Location).
通常把传统的NER当作序列标注任务处理,即每个字都被打上一个对应的标签.根据实体之间 的嵌套关系,衍生出嵌套NER任务'如“上海市人民政府”是一个机构实体,但“上海市”是一个地名 实体.根据实体所属的类别集合,又衍生出细粒度实体分类任务[9],实体所属的类别之间具有层级关 系.例如,人名实体按照行业分为教育工作者、医者、艺术家等,教育工作者按照职称又分为教授、副 教授、研究员等.而本文不对后两者做过多介绍,主要关注的是传统的NER任务.
1.2 NER的标注方法
最常见的标注方法有BIO、BIOES、BMES,方法中各个字符所代表的含义如表1所示.
1.3金融领域中文NER的特点
金融领域是一个具有高度专业性的领域,很多词汇不能从字面意思理解,需要结合金融的背景和 语境去理解其背后的特殊含义,自然语言处理的所有子任务在金融领域中都有一个独特的理解方式. 金融具有成本低、效率高、覆盖面广、风险高的特点,命名实体识别作为自然语言处理最基础的任务 之一,识别效果严重影响下游任务的效果,所以在金融领域中,命名实体识别结果是否准确间接决定 着金融经济产业链的效益.相对于通用领域的中文NER,本文总结了金融领域中文NER的主要特点 并将其归为3大类.
(1)文本数据量大,内容复杂,更新快.金融经济发展迅速,互联网金融的时代下,每日不断更新大 量的实时新闻,文本内容质量参差不齐,不同来源的报道表述格式不一,而且里面还会出现大量冗余 信息,使得很难全部识别出其中的实体.
(2)异常的表达方式,专业名词多.
a)金融是一个专业背景强的领域,金融领域的术语往往有着特殊的含义,即使是人工,有时候也 需要具有专业背景的人员才能理解,比如产品实体“对冲基金”“白骑士”等,分词工具难以准确分词.
b)高频存在不规则的实体缩写,如“中国农业银行股份有限公司”是一个公司名,而“农业银行” “农行”两个简称也是一个公司名.
c)股票代码和股票简称.
d)专业词典不完善.
以上这些因素给机器识别命名实体带来许多挑战.
(3)实体内层嵌套多,边界不易识别.如“深圳市腾讯计算机系统有限公司”应该从整体名称上归 为公司名,而在机器识别的时候,可能会识别为3个实体:“深圳市”(地名)、“腾讯”(公司名)、“计算 机系统有限公司”(公司名).
2金融领域中文NER方法
金融领域中文NER是中文NER在垂直领域上的具体应用,本文把金融领域的中文NER方法分 为3类:基于字典和规则的方法、基于统计机器学习的方法和基于深度学习的方法.
2.1基于字典和规则的方法
在NER任务提出之后,早期的NER系统通常是基于人工构建的字典知识库和手工制定的规则, 可以根据通用领域或者垂直领域指定合适的知识库,根据句法-词法模式制定规则,然后从文本中寻 找和这些字典、规则相匹配的字符串.在金融领域中文数据中,人们最早开始研究的实体仅仅是机构 名(包括公司名)及其缩写[1。-12].王宁等[10]总结了中文机构名的特征和名称的上下文信息,用人工的方 式创建了 6个知识库,然后经过两次遍历搜索匹配完成实体的识别.实验结果表明,在封闭测试中机 构名的召回率达到89.3%,可见这是一个不错的结果.沈嘉懿等[11]和Xu等[12]在不同主题的语料库上 基于复杂的规则映射的方法识别中文机构名称,均取得了较高的精确率和召回率.此外,Burdick 等[13]还利用基于规则的文本抽取平台System T开发了两种金融机构名称实体识别工具:Org-NER 和 Dict-NER.
当通用字典或者领域字典数量足够充足、制定的规则足以覆盖实体特征的时候,往往可以得到很 好的精确率,而这种方法的局限性也在于此,不完备的字典和规则,往往会导致较低的召回率,也就是 说,预测的实体数量和实际的实体数量具有一定的差距.对一种领域的实体类型的规则也无法移植到 另一领域的实体类型的预测.另外,这种方法耗费大量时间,对金融领域专业背景要求强.因此,研究 人员把研究目光转向了统计机器学习方法上.
2.2基于统计机器学习的方法
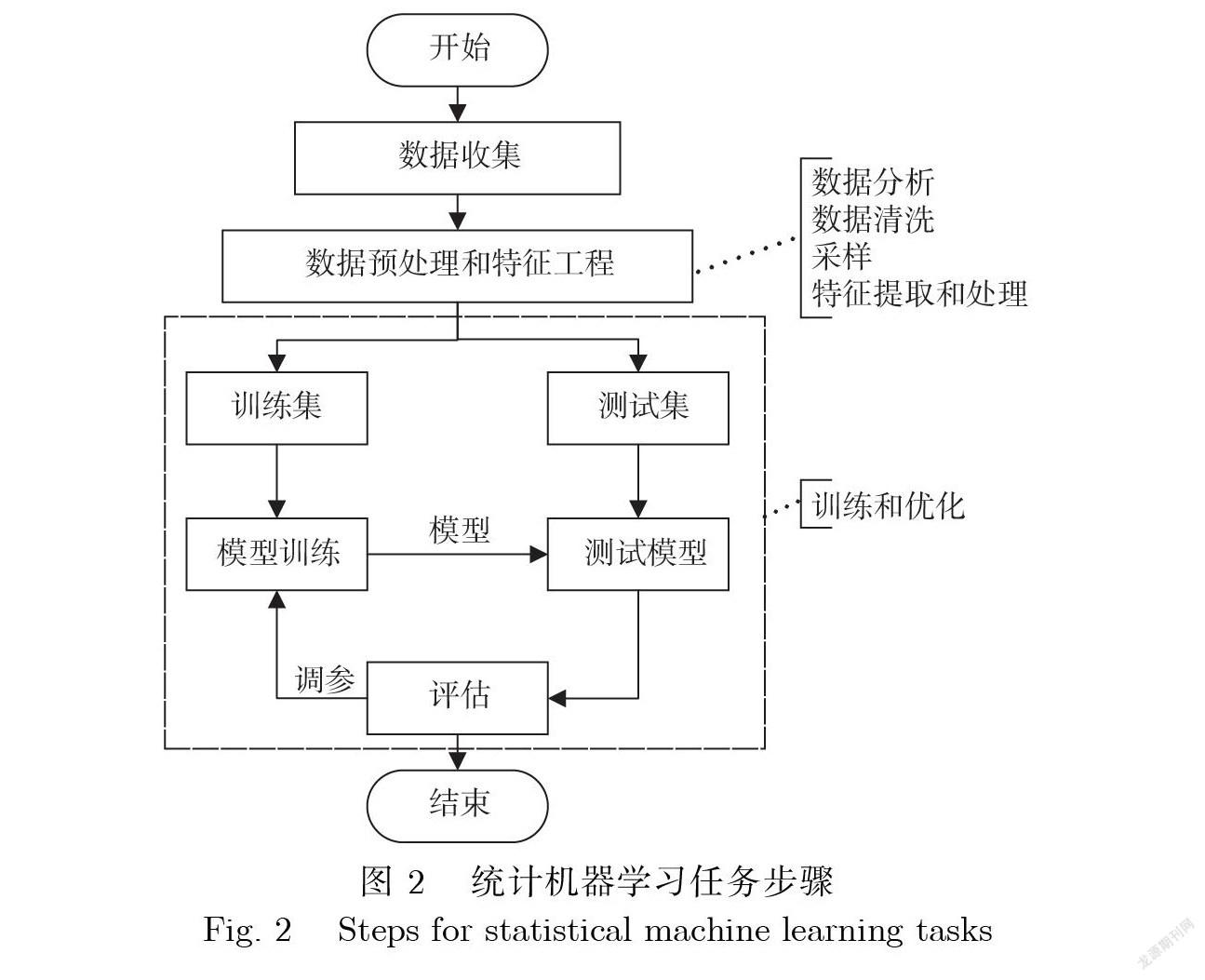
统计机器学习方法是基于特征工程的方法,统计机器学习任务的一般步骤如图2所示.有监督学 习是统计机器学习的一种,是指从有标签的样本数据中学习出预测函数,并运用到未知样本数据预测 出结果.常用于命名实体识别的方法有隐马尔可夫模型(Hidden Markov Model, HMM)[14]、最大熵模 型(Maximum Entropy Model, ME)[15]、支持向量机(Support Vector Machine, SVM)[16]、条件随机场 (Conditional Random Field, CRF)[17]和决策树(Decision Tree, DT)[18].
数据分析数据清洗采样
特征提取和处理
基于统计的方法在通用领域的NER数据集上取得了很好的效果,但是在金融领域中文NER中, 对于金融命名实体(Financial Named Entity, FNE)尤其是FNE缩写的抽取有困难,现有的有监督学 习方法往往和金融文本中实体的规则相结合训练的效果更好.Shen等[19]提出的中文机构名称及其缩 写的识别方法中,右边界是借助机构的后缀字典识别,而左边界则是由基于贝叶斯概率模型的最佳 规则识别,识别出机构名称后,根据缩写规则获取候选缩写.Wang等[21]提出了一种基于条件随机场 和互信息与信息熵[22]的金融命名实体识别方法,股票名称在金融文本中会经常出现,作者首先用领域 字典识别股票名称,为了高效地识别实体的边界,将机构名后缀(如有限公司)、地名前缀(如深圳)、 职务词汇(如董事长)、前驱谓词(如收购)、后续词(如日前)、词性等规则特征融入一个线性CRF分类 器中识别完整的FNE,其中机构名后缀、职务词汇和后续词可以决定机构实体的右边界,地名前缀和 前驱谓词可以决定机构实体的左边界,而对于金融文本中存在的格式丰富的金融命名实体缩写, CRF序列标注算法难以处理,通过引入互信息和边界信息熵特征提高FNE缩写的识别率,并用候选 集与股票名称进行相似度计算,用来进一步验证候选集中正确的缩写,实验结果显示加入互信息和信 息熵后的模型准确率提升了约6%,也说明性能的改善得益于FNE的識别.
和以前的方法相比,虽然金融领域中文NER在基于统计机器学习的模型上的效果有所提高,但是庞大的特征工程仍然需要很高的人工和时间的成本.
2.3基于深度学习的方法
深度学习是机器学习的一个分支,它由多个处理层组成,可以学习到抽象的文本语义关系.2015年深度学习重新崛起,除了统计机器学习中的CRF常常用在新模型中,人们更多地聚焦在深度学习 方法上.因其强大的学习能力,近年来不断被运用到包括命名实体识别在内的自然语言处理领域.基 于深度学习的方法共分为3个步骤:
(1)文本数据的分布式表达作为输入;
(2)选择合适的神经网络模型作为特征提取器,即编码器;
(3)选择合适的分类或者序列标注模型获得标签结果,即解码器.
2003年,Bengio等[23]提出的神经语言模型中诞生了词向量这个概念,它是指把字或者词通过模型 训练的方式得到它们的分布式表达——可供计算机识别的数值化表示,即输入数据,从而替代了统计 机器学习方法中繁重的特征工程,这个优势引发了学者们对词向量的研究兴趣.常见的预训练模型有 Google Word2vec[24](包括 CBOW 和 Skip-Gram 两个模型)、Facebook fastText[25]、Stanford Glove[26]、 AllenNLP ELMO1271、OpenAI GPT1281、Google BERT1291、CMU&Google XLNet1301、THU ERNIE1311 等.目 前主流的神经网络模型包括3种:卷积神经网络模型CNN[32]及其变形空洞卷积神经网络IDCNN[33];循 环神经网络模型 RNN1341 及其变形 LSTM1351、BiLSTM1361 和 GRU1371;基于 Attention 机制的 Transformer1381. 当把NER视为多分类任务时,可以使用多层感知机作为解码器.当把NER视为序列标注任务时,常 常使用CRF作为解码器,而当实体类型数量很大时,RNN作为解码器的性能要优于CRF,并且训练 速度更快139].但是,通常情况下,CRF是表现较好的解码器.
本文把基于深度学习的金融领域中文NER方法分为两类,一类是单任务学习,另一类是多任务联合学习.
2.3.1单任务学习
单任务学习,即仅仅为金融领域中文NER这一种任务而设计的训练模型,这种模型学习任务唯 一且目标明确.
李昱昕1401采用网易财经网的上市公司公告作为数据源,这种文本语法结构单一,含有大量准确无 误的公司名,采用通用领域NER标注工具和人工纠正的方法标注数据集.考虑到金融机构命名实体 特征的特殊性,除了构建常见的词特征和词性特征外,和Wang等1211类似,作者也构建了职位词、前驱 词和后续词、后缀词、地名、人名特征.此外,作者还把表格形式的结构化金融文本数据处理成一个小 型的金融领域知识图谱,将知识图谱中的实体作为外部知识加入特征集合中,利用大量丰富的无监督 金融文本数据使用Word2vec的CBOW模型训练蕴含领域知识的金融领域词向量,然后使用 BiLSTM对词向量进行编码,最后使用CRF结构对编码序列进行解码.CRF层是对BiLSTM层提取 的词特征的一种再利用,从全局角度充分利用了文本中蕴含的信息,提高了标注的准确性.这种领域 词向量结合BiLSTM-CRF的模型相比于CRF、BiLSTM和BiLSTM-CRF算法明显提升了识别效果.
彭小钰1411提出的面向金融领域的命名实体识别算法中,为了更好地表达字与字之间的语义关系, 融合了字向量、Word2vec词向量和词性向量这3种向量特征作为输入句子的分布式表示,然后编码 器——解码器使用的模型架构是双层BiLSTM-CRF.与通用领域NER任务不同的是,作者同时考虑到 金融领域的应用场景和模型的通用性,词向量的训练语料中同时加入了金融领域的文本和百度百科 的通用语料文本.在金融领域数据集上对比了哈工大ltp、BiLSTM、BiLSTM-CRF模型,作者提出的 模型准确率、召回率和巧值均高于这三者.
Liu等1421针对互联网金融新实体发现问题提出了一个基于BERT和Bootstrapping的半监督方 法,该任务及其一万条数据集来自2019年CCF BDCI (CCF大数据与计算智能大赛,https://www. datafountain.cn/competitions/36(1),预训练模型BERT训练词向量,用于捕捉词语之间的语义信息, BiLSTM-CRF作为模型架构训练NER任务,而作者任务中使用的金融领域的数据集标签不足的问 题限制了 BiLSTM-CRF模型的表现效果,作者采用Bootstrapping方法解决了数据集中标签不足问 题.实验证明,加入BERT预训练模型后巧值提升了约0.11,加上Bootsrapping后巧值再次提升约 0.05.
刘宇瀚等[43]提出结合字向量和中文汉字五笔字形嵌入作为模型整体的输入,同样选择了 BiLSTM-CRF的编码器-解码器的结构.特殊的是,作者将这种模型作为子模型进行迭代学习,并且在 后一轮训练的输入中嵌入上一轮输出结果的标签编码,这种方法考虑到了字符上下文标签之间的潜 在关系,通过迭代学习不断改进标签预测的结果,提高了实体标注的性能.可见,在金融领域中文 NER中BiLSTM-CRF仍然是很有效的模型架構.
2.3.2多任务联合学习
多任务联合学习,即将NER任务和其他任务共同训练,多个任务通过底层共享信息互相帮助学 习,训练出一个更优化的模型.
Zhou等[44]针对金融领域实体关系抽取问题,提出了一种新的双向GRU注意力机制联合模型 (Bigru Attention-Joint-Model, BGAJM).该模型将实体识别和关系提取作为一个整体进行学习和 训练,避免了传统的实体识别和关系提取作为两个不同的子任务引起的错误传播问题,两个任务共享 字级别的词向量层、BiGRU层和Attention层,而在NER模型解码器端,通过大量的实验选择了 CNN作为NER解码器.在数据集上测试Word2vec和Glove6b两个预训练模型,选择准确率更高的 Glove6b作为词嵌入.BiGRU与注意机制的结合消除了传统的实体词位置特征信息的添加,利用注意 机制的自动获取特征,从一定程度上解决了因金融信息量大而人工特征选择困难的问题,提高了计算 效率.
Zhao等[45]为在线金融文本的挖掘和社交媒体的舆情分析问题提出了一个基于RoBERTa的情感 分析和关键实体检测方法.为解决深度学习应用于金融文本挖掘时金融领域标签训练数据缺乏的问 题,Liu等|46]基于BERT架构搭建了首个金融领域的预训练模型FinBERT,单纯使用Word2vec或者 BERT预训练不能有效地应用于金融数据,金融文本中词汇、语义、句子顺序和句子之间的接近度等 都包含更多的语言知识和语义信息,作者构建了包括NER在内的6个覆盖更多知识的自监督预训练 任务,通过多任务学习有效地捕获了大规模预训练语料库中的语言知识和语义信息,作者用大量的实 验证明了 FinBERT的有效性和鲁棒性.
3金融领域中文NER公开数据集和工具
介绍了金融领域中文NER的方法之后,下面将对现有公开数据集和工具进行简要介绍.
3.1公开数据集
本文介绍一个金融领域中文NER公开数据集BosonNLP_NER_6C (http://static.bosonnlp. com/resources/BosonNLP_NER_6C.zip),此数据集由玻森数据收集并整理,发布于2014年12月29 日,共包含2000条数据,10953个句子,22429个实体,实体类型分为人名(person_name)、地名 (location)、时间(time)、机构名(org_name)、公司名(company_name)、产品名(product _name).原 始数据的标注格式如图3所示,每个实体的格式统一为“{{实体类型名:实体名}}”.在使用过程中,需 要把原始数据转为1.2节介绍的标注格式,以BIO格式为例,遍历一条数据,若遍历到的是实体,即当 遍历到“{{”时,将其标记为新实体的开始字符,当遇到字符“ }}”时,将其标记为新实体的结尾字符, 开始字符和结尾字符之间的字符串中冒号后的实体名的第一个字符标注成“ B-实体类型名”,除第一 个字符之外的字符标注成“I-实体类型名”;若遍历到的不是实体,即非相邻“{{”和“ }}”之间的字符, 则将其标注为“O”.
{{product_name:新华08网}}{{location:北京}}{{time:11月29日}}电{{org_name:银监会}}副主席{{person_name:蔡鄂生}}在 接受{{product _name:和讯网}}独家访谈时表示,{{location:中国}}银行业实施{{product_name:巴塞尔协议III}}是由{{org_ name:国务院}}批准的,全球银行业对于即将到来的{{time:2013年}}并不是那么期待的。根据{{org _name:巴塞尔委员会}}此前的规定,{{time:2013年1月1日}}开始,巴塞尔协议成员国银行业必须开始实施{{product_name:《巴塞尔协议ffl》}},并将于{time:2019年}}全部落实。{{time:今年上半年}}, {{org_name:国务院}}常务会议通过新版{{product_name:《商业银 行资本管理办法试行》}},这个被称为{{location:中国}}版的{{product_name:巴塞尔协议III}}中明确规定,系统重要性银行 和其他银行的资本充足率监管要求分别为11.5%和10.5%,与国内现行监管要求保持一致。该办法将于{{time:2013年1月1日 }}起实施。截至{{time:今年 10月}},只有包括{{location:中国}}、{{location:日本}}、{{location:印度}}和{{location:瑞士}}在内的8个国家公布了最终的新资本金监管规定
3.2工具
本文介绍一种金融领域中文NER工具BosonNLP(http://docs.bosonnlp.com/ner.html),是由玻森 团队研发的玻森中文语义开放平台,提供了一个简单、功能强大、性能可靠的中文自然语言分析服务. BosonNLP的命名实体识别功能识别的实体包括时间(time)、地点(location)、人名(person _name)、 组织名(org _name)、公司名(company _name)、产品名(product _name)、职位(job—title),输入可以 是已分词或未分词的文本,输出包括实体三元组〈实体起始下标,实体末尾下标,实体类别〉、分词结 果、分词结果中每个词组的词性.
4评估方法
对模型的预测结果进行全面的评估十分重要,许多技术根据文本识别能力对模型进行评估, MUC、ACE、CoNLL、SIGHAN Bakeoff、IREX、SemEval,13 等会议均对 NER 任务的不同评测技术做 出过定义和解释.本文介绍的是一种基于实体边界和实体类型的评估方法.
命名实体识别的目标是识别实体的边界并对其类型分类,基于实体边界和实体类型的评估方法 有精确率(Percision)、召回率(Recall)和巧值(巧-score),它们也是其他自然语言处理任务广泛使用 的评测指标.通常在测试集中,把要关注的实例看作正例(Positive),其他实例看作负例(Negative),同 样,预测结果也分為正例和负例两种类型.真实类别和预测类别的“混淆矩阵”如表2所示.
下面对混淆矩阵中的4种分类结果做一个详细说明:TP (真正例),真实类型是正例,模型预测结 果为正例的个数nTP; FP (假正例),真实类型是负例,模型预测结果为正例的个数~p; FN (假负例), 真实类型是正例,模型预测结果为负例的个数n?; TN (真负例),真实类型是负例,模型预测结果为 负例的个数《tn.
精确率(Percision,P)巧又称查准率,是衡量预测为正例结果中有多少是被预测对的指标.计算公式为
召回率(Recall,R)均又称查全率,是衡量全部真实的正例中有多少被预测出来的指标.计算公式为
可以看出P和R况这两个指标是矛盾的,当P偏高时,况往往偏低.相反地,当P偏低时,况往往偏 高.巧值便综合考虑两者,是两者的调和均值.计算公式为
在命名实体识别中,实体是由一个字或多个字组成的词语构成,因此首先关注的是实体的边界是 否正确,然后判断实体的类型的正确性,因此考虑到实体边界和实体类型的匹配程度,将上述3个 评测指标细分为完全匹配和部分匹配两种情况[4],区别在于混淆矩阵中的4种分类的统计结果会有所 不同.
(1)完全匹配.预测结果和测试集真实实体边界和类型完全匹配分为3种情况:
a)实体边界和实体类型均匹配正确,才被视为正确;
b)预测出的实体在测试集中不存在;
c)测试集中的实体没有被预测出来.
(2)部分匹配.预测结果和测试集真实实体边界和类型部分匹配分为3种情况:
d)实体边界正确,类型不正确;
e)实体边界有重叠,即可视为正确;
f)实体边界无重叠,即边界错误,类型也错误.
部分匹配比完全匹配的要求更为宽泛,完全匹配中只有情况a)才被视为真正例(TP),而在部分 匹配中满足情况e)即可被接受为真正例(TP).
5金融领域中文NER的应用
金融领域中文NER作为一个底层的基础任务,已经被应用到其他多个金融领域自然语言处理任 务中,下面将分别介绍金融领域中文NER在中文文本中金融事件抽取、金融知识图谱和金融文本分 类的技术应用.
5.1金融事件抽取
事件抽取旨在从一个句子或者从文档中的多个句子中抽取事件,一个事件涉及多个角色,如一个产权冻结事件一般会涉及的事件参数有“股东名称”“冻结股票编号”“冻结机构”“冻结开始日期”“冻 结结束日期金融文本中命名实体对于从文档中提取事件具有很大的帮助.Yang等[47]提出了名为DCFEE的框架,该框架从结构化文本财务事件知识数据库和结构化文本公司公告中自动标记事件参 数,这些参数就是一个个实体,然后基于自动标记的训练数据从公告中提取文档级事件,并用实验证 明了系统的有效性,已经成功地将系统联机,用户可以通过它快速地从财务公告中获取事件信息.
5.2金融知识图谱
知识图谱的基本思想是获取大范围的数据,清洗并结构化,形成大规模的语义网络,包含实体、概念及其之间的语义关系,并以可视化的形式展现出来,目前已经发展成为人工智能的核心技术[48].目 前,知识图谱成为智能金融浪潮中的热点,在金融领域赋能越来越多的业务.比如,在智能投研、智能 投顾、智能风控、智能客服、智能监管、智能运营等场景中都得以应用.知识图谱构建中最基础的一个 过程就是知识抽取,NER系统便是从文本中识别出有意义或者指代性非常强的实体.除了常见的人 名、地名、机构名、专有名词外,根据业务需求可以拓展更多的实体,如产品名称、型号、价格等.陈晓军等[49]构建了一个企业风险知识图谱,其中知识抽取使用HanLP开源工具包、自定义词典和特殊规则相结 合的方法有效识别语料中的命名实体.吕华揆等[50]利用金融数据构建了金融股权知识图谱,其中知识 抽取采用的是规则和基于机器学习的结合方法抽取机构名和人名.Cheng等[51]利用NER抽取的知识 构建了一个基于知识图的金融量化投资事件嵌入框架.
5.3金融文本分类
文本分类是指为文本单元,如句子、段落、文档等自动分配到预定义的类别中的过程,可以实现 文本数据的有效筛选和管理,也是自然语言处理的基本任务之一,为推荐系统、事件监测等任务提供 了基础.金融领域的文本分类有利于对投研分析、量化投资做出合理的投资决策.在金融文本中,有大 量的领域知识,这些垂直领域的实体对文本分类起着十分重要的作用,有利于专业领域中文本分类效 果的提升.Fan等[52]提出的一种融合全局领域信息和局部语义信息的方法对金融文档进行分类,其中 在全局领域信息的异构图是由公司、人名、地点、时间、产品等实体来构建的,多篇文章通过它们共同 拥有的实体相联系,构成链接关系,从而更加高效地对金融文本进行细粒度分类.
6挑战和未来方向
目前,针对金融领域中文NER任务,现有的方法在一定程度上已经取得了不错的成绩,但是仍然 面临着许多挑战,下面将对有关挑战进行总结,并提出一些未来可发展的方向.
6.1挑战
针对金融领域面临的挑战,将从5个方面进行阐述,包括缺乏金融领域有质量的公开数据集、边 界歧义、机构名缩写构词灵活、金融专业领域词汇的识别和嵌套实体.
6.1.1缺乏金融领域有质量的公开数据集
数据集是模型训练过程中最重要最基础的一环,在调研过程中发现很难找到金融领域用于中文 NER任务的数据集,金融领域的自然语言处理任务一般由金融行业背景的企业来做,数据集由企业 内部自己构建的,并将其应用到商业中,这些涉及商业机密的数据集不会公开,数据源的缺乏给学术 界做金融领域的中文NER任务带来了挑战.有不少研究者是自己从各大金融财经网站爬取新闻资讯, 经过筛选、清洗、标注等过程之后作为实验的数据集.因此,构建一组有质量的用于金融领域中文 NER的数据集,将为未来科研人员研究金融领域的中文NER问题省去不少人力.
6.1.2边界歧义
自然语言的歧义性一直是困扰研究者的一个问题.一个最常见的歧义是多种划分,如“兄弟科技 和花园生物均实现翻倍”可以划分为“兄弟/科技/和/花园/生物/均/实现/翻倍/”,也可以划分为“兄弟 科技/和/花园生物/均/实现/翻倍第一种划分是没有实体的,而第二种划分有“兄弟科技”和“花园 生物”两个实体,这种边界歧义问题会影响金融领域中文NER的精确度和召回率,虽然深度学习对歧 义的消解有明显优势,但是常会遇到对新词的边界把握模糊的问题.
6.1.3机构名缩写构词灵活
机构名缩写即机构的简称,通常是由全称中的几个关键字组成的表达,这种缩写不符合中国构词 规范,机构名的简称个数可能不止一个,缩写简称也属于机构名实体的一部分,比如“华东师范大学” 的简称有“华东师大”和“华师大如果对机构名缩写识别不准确,在实验结果上会降低金融领域中 文NER的召回率,在工业上会影响到该机构有关的信息的准确性,如该机构有关的事件数、关联公司 等信息会被遗漏.这种灵活的构词结构增加了机构名识别的困难.
6.1.4金融专业领域词汇的识别
金融领域的中文NER问题不仅要以汉语语言的语法规范为依据,还要兼顾词语在金融领域知识 中的特殊含义,虽然字典是一种解决问题的途径,但是大量的未登录词或者罕见词汇仍然给NER带来很大的难度.
6.1.5 嵌套实体
通常要处理的是边界距离最长的实体,也就是非嵌套实体.而实际应用中,嵌套实体非常多,会使 原本属于一个整体的实体,被划分为多个不同类型的实体,导致实体边界和实体类型预测错误.
6.2 未来方向
下面将从边界检测、融合专业知识、多特征学习和结合多任务学习等4个方面介绍金融领域中文 NER的未来发展方向.
6.2.1边界检测
边界检测的正确与否直接影响着实体整体的识别效果.边界检测错误时,即使检测出的左右边界 确实构成一个实体且实体类型正確,但它也不是数据集中原本标注的实体类型.当实体由多个词构成 时,一旦一个词识别错误,后续的多个词识别的正确率也会受到影响.目前,主流的方法往往是把 NER视为一个序列标注任务相当于对每个字都进行一个分类,没有考虑到每个字对实体边界的贡献 程度,而实体边界正确率的提高可以有效提高NER的精确率和召回率.另外,研究发现,现在已经有 研究者在关注研究通用领域的嵌套实体识别,因此,在金融领域将可以往边界检测和嵌套实体的方向 进行研究.
6.2.2融合专业知识
特定的专业知识往往可以提高识别的准确率,特别是在垂直领域的NER任务,对于一些罕见的 词,或者多义词,结合领域背景才会正确理解其含义.在金融领域,通过专家介入,加强未登录词检测 和指定丰富的规则将会帮助NER提升效果.
6.2.3多特征学习
深度学习方法在金融中文NER的效果是显著的,而且降低了人力成本,在深度学习中词向量扮 演了重要的角色.作为一项基础的任务,对NER任务建模不需要太过复杂,可以从多特征入手,如字 特征、词特征、词性特征、句法特征、笔画特征等,增强文本的词嵌入表达.
6.2.4结合多任务学习
多任务学习使用多个有关联的任务中的有用信息帮助每一个任务得到更为准确的学习器[53].根据 任务的性质划分,多任务又分为多任务有监督学习、多任务无监督学习、多任务主动学习、多任务强 化学习、多任务迁移学习.根据NER的定义,NER本身就可分解为两个任务来学习,一个是实体边界 识别,另一个是实体类型识别;当然,也可以将NER与其他自然语言处理任务同时学习,如金融领域 文本分类、事件抽取等.因此,多任务学习也是未来的一个发展方向.
7 总结
命名实体识别自提出起,就不断受到国内外研究者的关注,在为其他自然语言处理任务和垂直领 域做出贡献的同时自身也在不断改进,金融领域中文NER已经被众多企业用于金融文本处理,智能 投研、智能投资等业务中.本文根据金融领域中文NER的研究进展分别从研究背景与意义、基本概念、研究方法、公开数据集与工具、评估方法、在其他金融领域自然语言处理任务中的应用、挑战和 未来方向進行了介绍,得出如下结论.
(1)端到端的模型架构是金融领域中文NER的主流方法,融合BiLSTM和CRF的模型因为可以 捕捉双向语义特征的长距离依赖和标签上下文信息,在金融领域中文NER表现出非常好的效果.
(2)在金融领域中文NER中,有效的文本的特征表示十分重要,除了对金融文本进行字嵌入和词 嵌入,加入专业领域字典有助于领域专业实体识别的准确性.
(3)针对金融领域中文NER公开的数据集和工具很少.
(4)在金融领域中文NER中精确率、召回率和巧值一直是最常用的评估方法.
(5)虽然现有的模型在金融领域中文NER问题上取得了不错的进展,但挑战依然存在,作为金融 业务中的一个NLP底层任务,还有很大的研究价值.
本文对金融领域中文NER的特点和研究进展进行的梳理和总结,希望可以为对该方向有兴趣的 研究人员提供参考价值和研究思路.
[参考文献]
[1]RAU L F. Extracting company names from text [C] // Proceedings of the Seventh IEEE Conference on Artificial Intelligence Application. IEEE, 1991.
[2]宗成庆.统计自然语言处理[M]. 2版.北京:清华大学出版社,2013: 510-512.
[3] 巴曙松,白海峰.金融科技的发展历程与核心技术应用场景探索[J].清华金融评论,2016(1(1): 99-103.
[4]LI J, SUN A, HAN J, et al. A survey on deep learning for named entity recognition [EB/OL]. (2020-03-18) [2021-09-22]. https://arxiv.org/pdf/1812.09449.pdf.
[5]李嘉欣,王平.中文命名实体识别研究方法综述[J].计算机时代,2021(4): 18-21.
[6]NADEAU D, SEKINE S. A survey of named entity recognition and classification [J]. Lingvisticae Investigationes, 2007, 30(1): 3-26.
[7]SHARNAGAT R. Named entity recognition: A literature survey [EB/OL]. (2014-06-30) [2021-09-22]. https://www.cfilt.iitb.ac.in/resources/surveys/rahul-ner-survey.pdf.
[8]KATIYAR A, CARDIE C. Nested named entity recognition revisited [C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1. New Orleans, Louisiana: Association for Computational Linguistics, 2018: 861-871.
[9]LING X, WELD D. Fine-grained entity recognition [C]//Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence. California: AAAI Press, 2012: 94-100.
[10]王宁,葛瑞芳,苑春法,等.中文金融新闻中公司名的识别[J].中文信息学报,2002, 16(2): 1-6.
[11]沈嘉懿,李芳,徐飞玉,等.中文组织机构名称与简称的识别[J].中文信息学报,2007, 21(6): 17-21.
[12]XU Z, BURDICK D, RASCHID L. Exploiting lists of names for named entity identification of financial institutions from unstructured documents [EB/OL]. (2016-06-07) [2021-09-22]. https://arxiv.org/pdf/1602.04427.pdf.
[13]BURDICK D, DE S, RASCHID L, et al. resMBS: Constructing a financial supply chain from prospectus [C]//Proceedings of the Second International Workshop on Data Science for Macro-Modeling. 2016: 1-6.
[14]EDDY S R. Hidden markov models [J]. Current Opinion in Structural Biology, 1996, 6(3): 361-365.
[15]KAPUR J N. Maximum-entropy models in science and engineering [J]. International Biometric Society, 1992, 48(1): 333-334.
[16]HEARST M A, DUMAIS S T, OSUNA E, et al. Support vector machines [J]. IEEE Intelligent Systems and Their Applications, 1998, 13(4): 18-28.
[17]LAFFERTY J, MCCALLUM A, PEREIRA F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data [C]//Proceedings of the Eighteenth International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc, 2001: 282-289.
[18]QUINLAN J R. Induction of decision trees [J]. Machine Learning, 1986, 1(1): 81-106.
[19]SHEN J Y, LI F, XU F Y, et al. Recognition of chinese organization names and abbreviations [J]. Journal of Chinese Information Processing, 2007, 21(6): 17-21.
[20]KASS R E, RAFTERY A E. Bayes factors [J]. Journal of the American Statistical Association, 1995, 90(430): 773-795.
[21]WANG S, XU R, LIU B, et al. Financial named entity recognition based on conditional random fields and information entropy
[C]//2014 International Conference on Machine Learning and Cybernetics. Lanzhou: IEEE, 2014: 838-843.
[22]NUNEZ J A, CINCOTTA P M, WACHLIN F C. Information entropy [J]. Celestial Mechanics and Dynamical Astronomy, 1996, 64: 43-53.
[23]BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J] . The Journal of Machine Learning Research, 2003(3): 1137-1155.
[24]MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL]. (2013-09- 07)[2021-09-22]. https://arxiv.org/pdf/1301.3781.pdf.
[25]JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification [EB/OL]. (2016-08-09) [2021-08-19]. https://arxiv.org/pdf/1607.01759.pdf.
[26]PENNINGTON J, SOCHER R, MANNING C D. Glove: Global vectors for word representation [C]//EMNLP. 2014: 1532-1543.
[27]PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [EB/OL]. (2018-03-2(2) [2021-08-26]. https://arxiv.org/pdf/1802.05365.pdf.
[28]RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL].
[2021-08-26]. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_
猜你喜欢
时代金融(2017年3期)2017-03-09 16:54:46
电子技术与软件工程(2016年24期)2017-02-23 11:47:35
计算机应用(2016年12期)2017-01-13 01:24:36
中国经贸(2016年20期)2016-12-20 15:25:44
求知导刊(2016年30期)2016-12-03 09:06:35
中国市场(2016年9期)2016-06-20 09:06:32
电脑知识与技术(2016年10期)2016-06-16 21:16:32
中国市场(2016年16期)2016-05-16 08:50:09
求知导刊(2016年10期)2016-05-01 14:09:25
电脑知识与技术(2016年5期)2016-04-14 11:12:38
